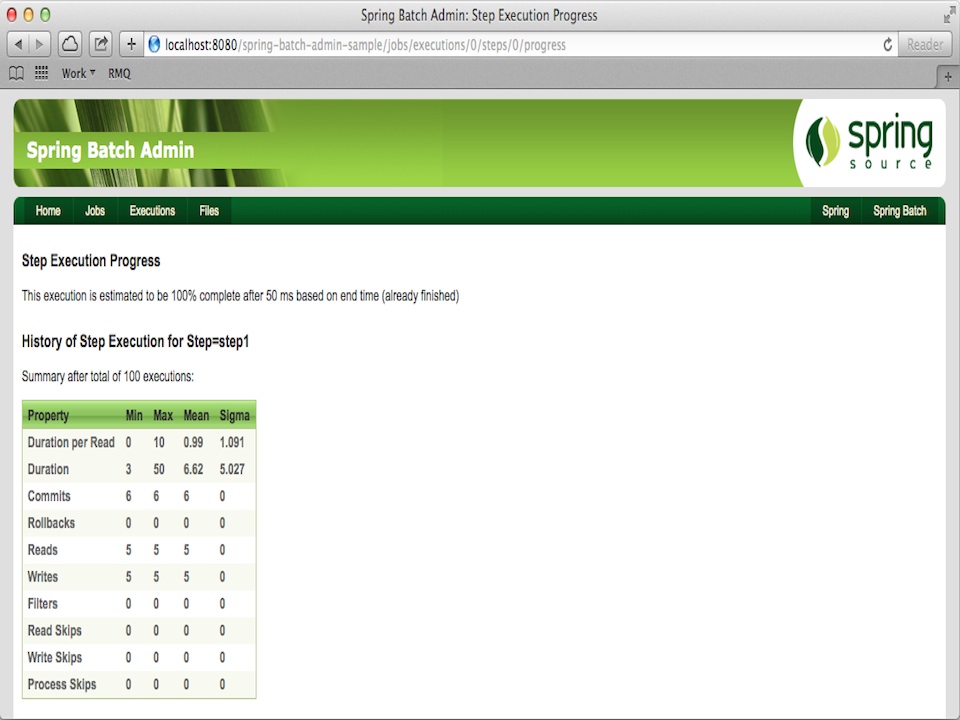
Spring Batch Admin provides some nice features for monitoring and managing Batch jobs remotely using JMX. In addition the standard configuration has JMX MBeans enabled for the Spring Integration components within the application context.
Exposing Metrics for Job and Step Executions
All the basic JMX features are exposed in one place in the Manager jar, in META-INF/spring/batch/bootstrap/manager/jmx-context.xml. The Job and Step metrics come from one bean, which in turn registers a set of MBeans for the Job and Step metrics:
<bean id="batchMBeanExporter" class="org.springframework.batch.admin.jmx.BatchMBeanExporter">
<property name="server" ref="mbeanServer" />
<property name="jobService">
<bean class="org.springframework.aop.framework.ProxyFactoryBean">
<property name="target" ref="jobService" />
</bean>
</property>
<property name="defaultDomain" value="spring.application" />
</bean>If you start the sample application with the usual command line options to expose the MBeanServer, e.g.
-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl.need.client.auth=false
then launch one of the jobs, and look at the MBeans in JConsole or your favourite JMX client, you will see the BatchMBeanExporter. As soon as you inspect its attributes, you will also see Job and Step Executions as well (they are lazily registered only when the basic attributes are first inspected):
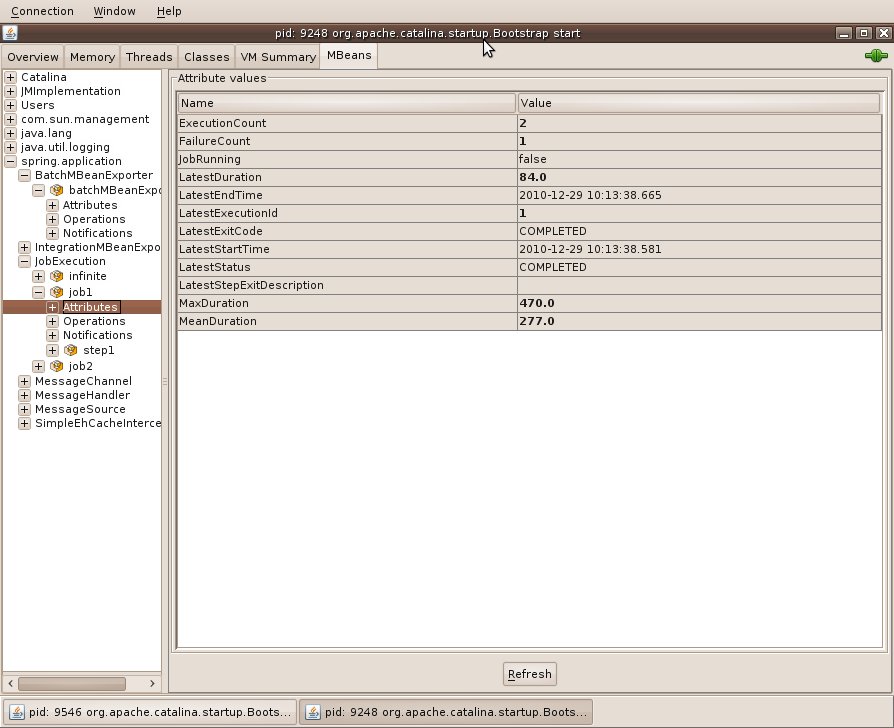
The BatchMBeanExporter needs a reference to the JobService because it uses the JobRepository to extract most of its metrics. It also has a basic cache for the metric data, to prevent it having to go back to the repository every time it is polled. The default cache settings have an expiry timeout of 60 seconds (so new data will show up in JMX every 60 seconds). The cache can be re-configured by overriding the bean definition for the cacheInterceptor bean.
Job Execution Metrics
Once a Job has executed at least once and the BatchMBeanExporter attributes inspected (so the Job execution leaves an imprint on the JobRepository) its metrics will be available to JMX clients. The MBean for these metrics has an ObjectName in the form
spring.application:type=JobExectution,name=job1
where job1 is the job name.
Metrics include information about the latest execution (status, duration, exit description, etc.) and also some basic summary information (number of executions, number of failures etc.).
Step Execution Metrics
Once a step has executed at least once (and left an imprint on the JobRepository) its metrics will be available to JMX clients. The MBean for these metrics has an ObjectName in the form
spring.application:type=JobExectution,name=job1,step=step1
where job1 is the parent job name, and step1>> is the step name. Because of the form of the <<<ObjectName, most JMX clients present step execution metrics as a child of the job they belong to, making them easy to locate.
Metrics include information about the latest execution (status, duration, commit count, read and write counts, etc.) and also some basic summary information (number of executions, number of failures etc.).
Step Execution Timeouts and Monitoring
The metrics above can be used by JMX clients to monitor the performance of an application and send alerts if service levels are not being achieved. Many JMX clients can do this natively with no additional configuration in the Batch application.
In addition, a convenient JMX MonitorMBean is provided in Spring Batch Admin to allow users to receive notifications if a Step execution is overunning. To use this just add a bean definition to your Job configuration context, and refer to the Step you want to monitor e.g.
<bean id="j1.step1.monitor" class="org.springframework.batch.admin.jmx.StepExecutionServiceLevelMonitor">
<property name="jobName" value="job1"/>
<property name="stepName" value="step1"/>
<property name="upperThreshold" value="30000"/>
<property name="defaultDomain" value="spring.application"/>
</bean>This will create an MBean with ObjectName in the form:
spring.application:type=GaugeMonitor,name=job1.step1.monitor
which can be exposed through the MBeanServer using the standard Spring context shortcut:
<context:mbean-export default-domain="spring.application" server="mbeanServer"/>
When a step is taking too long to execute, a JMX notification is sent automatically by the MBeanServer to any clients that have registered for notifications. The notification comes with an embedded event in the form:
javax.management.monitor.MonitorNotification
[source=spring.application:name=job1.step1.monitor,type=GaugeMonitor]
[type=jmx.monitor.gauge.high]
[message=]
where job1.step1.monitor is the name of the Spring bean definition used to define the monitor.