Many applications within the enterprise domain require bulk processing to perform business operations in mission critical environments. These business operations include automated, complex processing of large volumes of information that is most efficiently processed without user interaction. These operations typically include time based events (e.g. month-end calculations, notices or correspondence), periodic application of complex business rules processed repetitively across very large data sets (e.g. insurance benefit determination or rate adjustments), or the integration of information that is received from internal and external systems that typically requires formatting, validation and processing in a transactional manner into the system of record. Batch processing is used to process billions of transactions every day for enterprises.
Spring Batch is a lightweight, comprehensive batch framework designed to enable the development of robust batch applications vital for the daily operations of enterprise systems. Spring Batch builds upon the productivity, POJO-based development approach, and general ease of use capabilities people have come to know from the Spring Framework, while making it easy for developers to access and leverage more advance enterprise services when necessary.
Spring Batch provides reusable functions that are essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management. It also provides more advance technical services and features that will enable extremely high-volume and high performance batch jobs though optimization and partitioning techniques. Simple as well as complex, high-volume batch jobs can leverage the framework in a highly scalable manner to process significant volumes of information.
Spring Batch is part of the Spring Portfolio.
Spring Batch is designed with extensibility and a diverse group of end users in mind. The figure below shows a sketch of the layered architecture that supports the extensibility and ease of use for end-user developers.
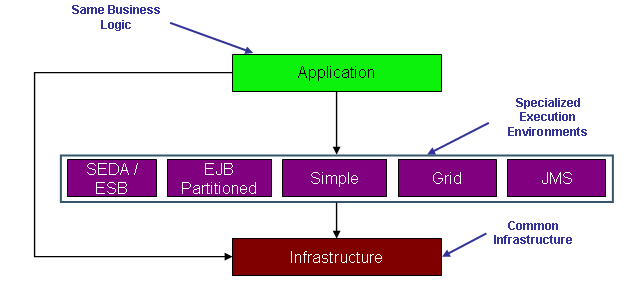
The initial release provides an Infrastructure layer in the form of low level tools. There is also a simple execution environment, using the infrastructure in its implementation. The execution environment provides robust features for traceability and management of the batch lifecycle. A key goal is that the management of the batch process (locating a job and its input, starting, scheduling, restarting, and finally processing to created results) should be as easy as possible for developers.
The Infrastructure provides the ability to batch operations together, and to retry an piece of work if there is an exception. Both requirements have a transactional flavour, and similar concepts are relevant (propagation, synchronisation). They also both lend themselves to the template programming model common in Spring, c.f. TransactionTemplate, JdbcTemplate, JmsTemplate.
The Core module is the batch-focused domain and implementation. It provides a robust set of integrated features including job processing statistics, job launch and restart to enable the management of the full lifecycle of traditional batch processing.
A number of sample jobs are packaged in a separate Samples module to more clearly articulate the usage and capabilities of the Core module.
The runtime dependencies of infrastructure and core are shown in the figure below.
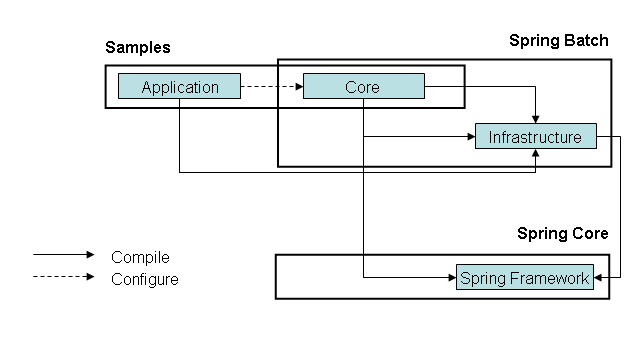
Once the framework is released it can be used immediately to simplify batch optimisations and automatic retries. The framework is oriented around application developers not needing to know any details of the framework - there are a few application developer interfaces that can be used for convenient construction of data processing pipelines, but apart from that we support as close to a POJO programming model as is practical. This is similar to the approach taken in Spring Core in the area of DAO implementation.
A partitioned step execution strategy is also being developed that will provide alternate scaling solutions. This will provide more advanced technical services and features to enable extremely high-volume and high performance batch jobs though proven optimization and partitioning techniques. Proven scaling techniques will be provided as partitioned strategies allowing users to spread the load across a pool of clustered J2EE application servers. There are also discussions to leverage grid technologies as an alternate scaling solution.
Matt Welsh's work shows that SEDA has enormous benefits over more rigid processing architectures, and messaging environments give us a lot of resilience out of the box. So we also want to provide a more SEDA flavoured execution environments, as well as supporting the more traditional ETL style approach. There might be a tie in with Mule and/or other ESB tools here, giving the benefit of a very scalable architecture, where the choice of transport and distribution strategy can be made as late as possible. The same application code could be used in principle for a standalone tool processing a small amount of data, and a massive enterprise-scale bulk-processing engine.
While open source software projects and associated communities have focused greater attention on web-based and SOA messaging-based architecture frameworks, there has been a notable lack of focus on reusable architecture frameworks to accommodate Java-based batch processing needs, despite continued needs to handle such processing within enterprise IT environments. The lack of a standard, reusable batch architecture has resulted in the proliferation of many one-off, in-house solutions developed within client enterprise IT functions.
SpringSource and Accenture are collaborating to change this. Accenture's hands-on industry and technical experience in implementing batch architectures, SpringSource's depth of technical experience, and Spring's proven programming model together mark a natural and powerful partnership to create high-quality, market relevant software aimed at filling an important gap in enterprise Java. Both companies are also currently working with a number of clients solving similar problems developing Spring-based batch architecture solutions. This has provided some useful additional detail and real-life constraints helping to ensure the solution can be applied to the real-world problems posed by clients. For these reasons and many more, SpringSource and Accenture have teamed to collaborate on the development of Spring Batch.
Accenture is contributing previously proprietary batch processing architecture frameworks -- based upon decades worth of experience in building batch architectures with the last several generations of platforms (i.e., COBOL/Mainframe, C++/Unix, and now Java/anywhere) -- to the Spring Batch project along with committer resources to drive support, enhancements, and the future roadmap.
The collaborative effort between Accenture and SpringSource aims to promote the standardization of software processing approaches, frameworks, and tools that can be consistently leveraged by enterprise users when creating batch applications. Companies and government agencies desiring to deliver standard, proven solutions to their enterprise IT environments will benefit from Spring Batch.