This guide walks you through building a simple Spring Boot application using Spring’s Cache Abstraction backed by Apache Geode as the caching provider for Asynchronous Inline Caching.
It is assumed that the reader is familiar with the Spring programming model. No prior knowledge of Spring’s Cache Abstraction or Apache Geode is required to utilize caching in your Spring Boot applications.
Additionally, this Sample builds on the concepts from the Inline Caching with Spring and Look-Aside Caching with Spring guides. Therefore, it would be helpful to have read those guides before proceeding through this guide.
Let’s begin.
| Refer to the Inline Caching section, and specifically, Asynchronous Inline Caching, in the Caching with Apache Geode chapter of the reference documentation for more information. |
1. Background
In Synchronous Inline Caching, data is immediately read from or written to the primary data source, (a.k.a. the System of Record (SOR)), before the cache is modified, thereby guaranteeing a degree of consistency between the cache and the backend data source. The "synchronous" arrangement of the Inline Caching pattern is commonly referred to as "Read/Write-Through".
With Asynchronous Inline Caching, data changes are written to the primary data source asynchronously, after the cache has already been modified. The "asynchronous" arrangement of the Inline Caching pattern is commonly referred to as "Write-Behind". The cache entry is modified, then, and only then, will the primary data source reflect the changes sometime later.
Due to the asynchronous nature of Asynchronous Inline Caching, it is possible for the primary data source (i.e. System of Record (SOR)) and cache to be out-of-sync. Additionally, the primary data source may contain information that the cache does not. That is, another application may be updating the primary data source and not using the cache. Conversely, a cache entry change may not be promptly written to the primary data source until the "Write-Behind" operation is triggered, which is often implementation dependent. A data change could violate a database constraint, fail to commit and be rolled back. All sorts of reasons can cause the primary data source and the cache to get out-of-sync, or become inconsistent.
For this reason, throughput and latency are the primary application concerns and motivation, rather than consistency, when using the Asynchronous Inline Caching pattern.
The general pattern of Inline Caching is depicted as follows:
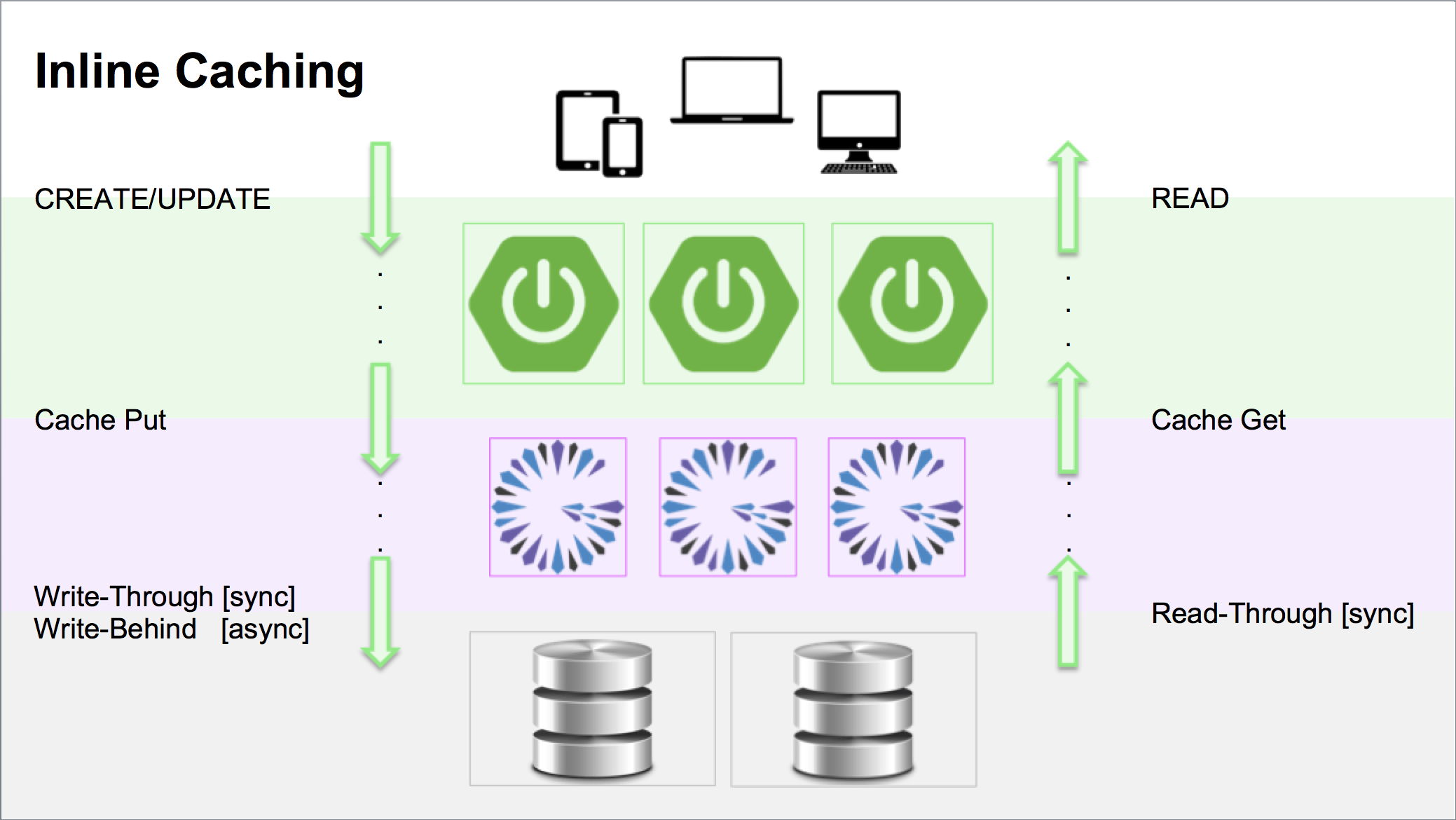
The layer in the application/system architecture involving the Inline Caching logic sits between the cache and the primary data source:
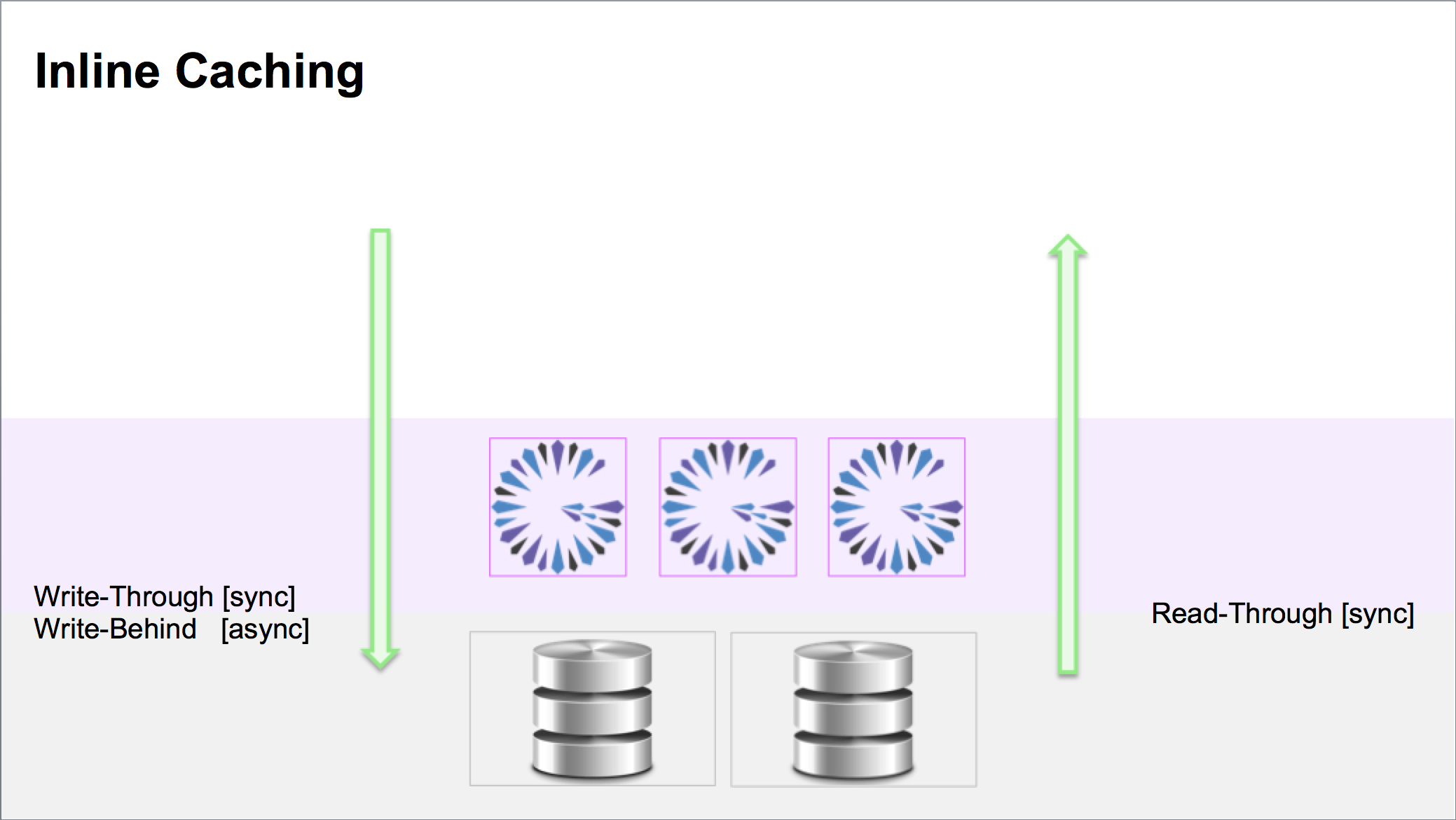
In Synchronous, Read/Write-Through, Inline Caching, the system/application architecture appears as follows:
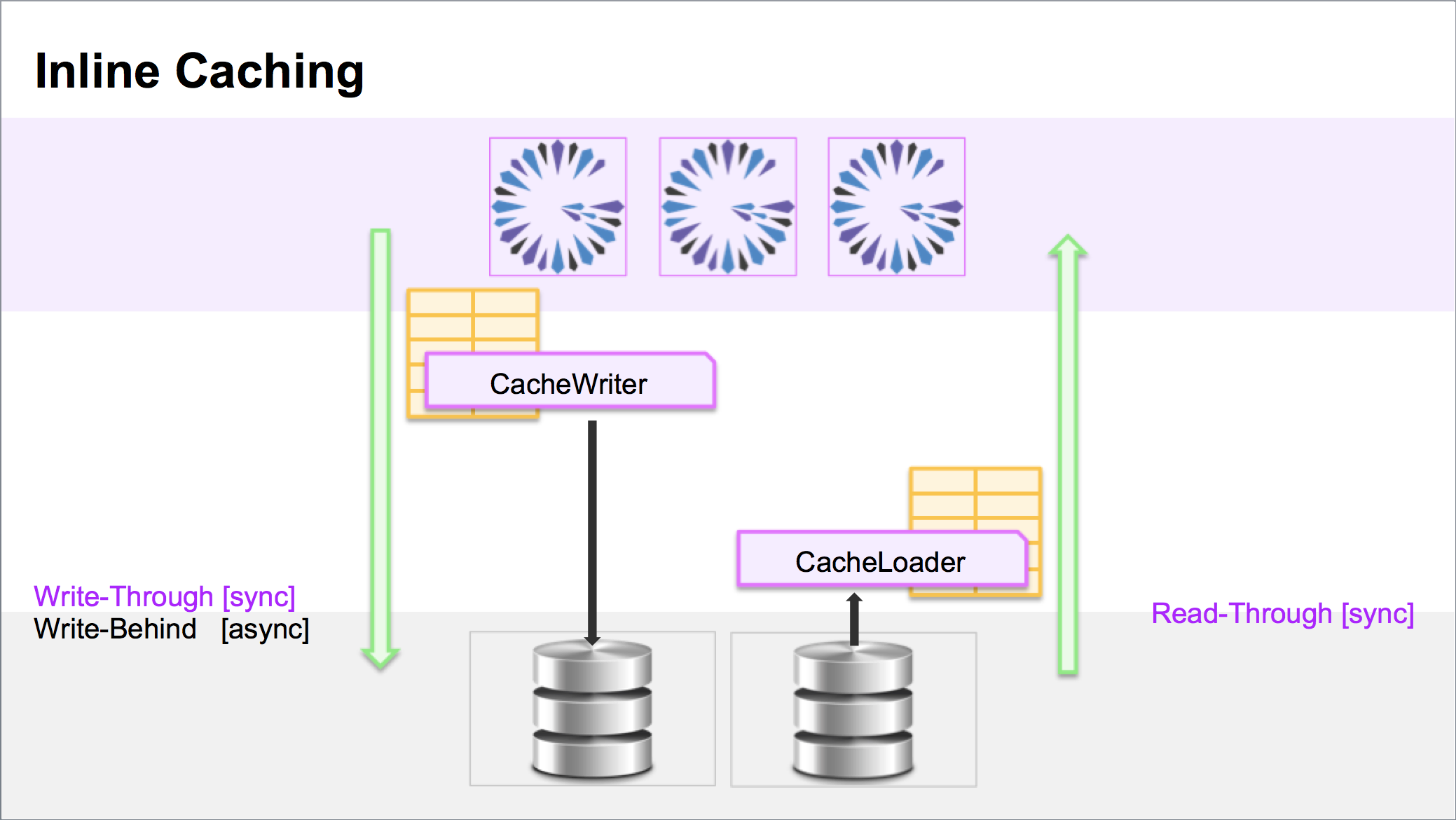
With Asynchronous, Write-Behind, Inline Caching, the system/application architecture would instead appear as:
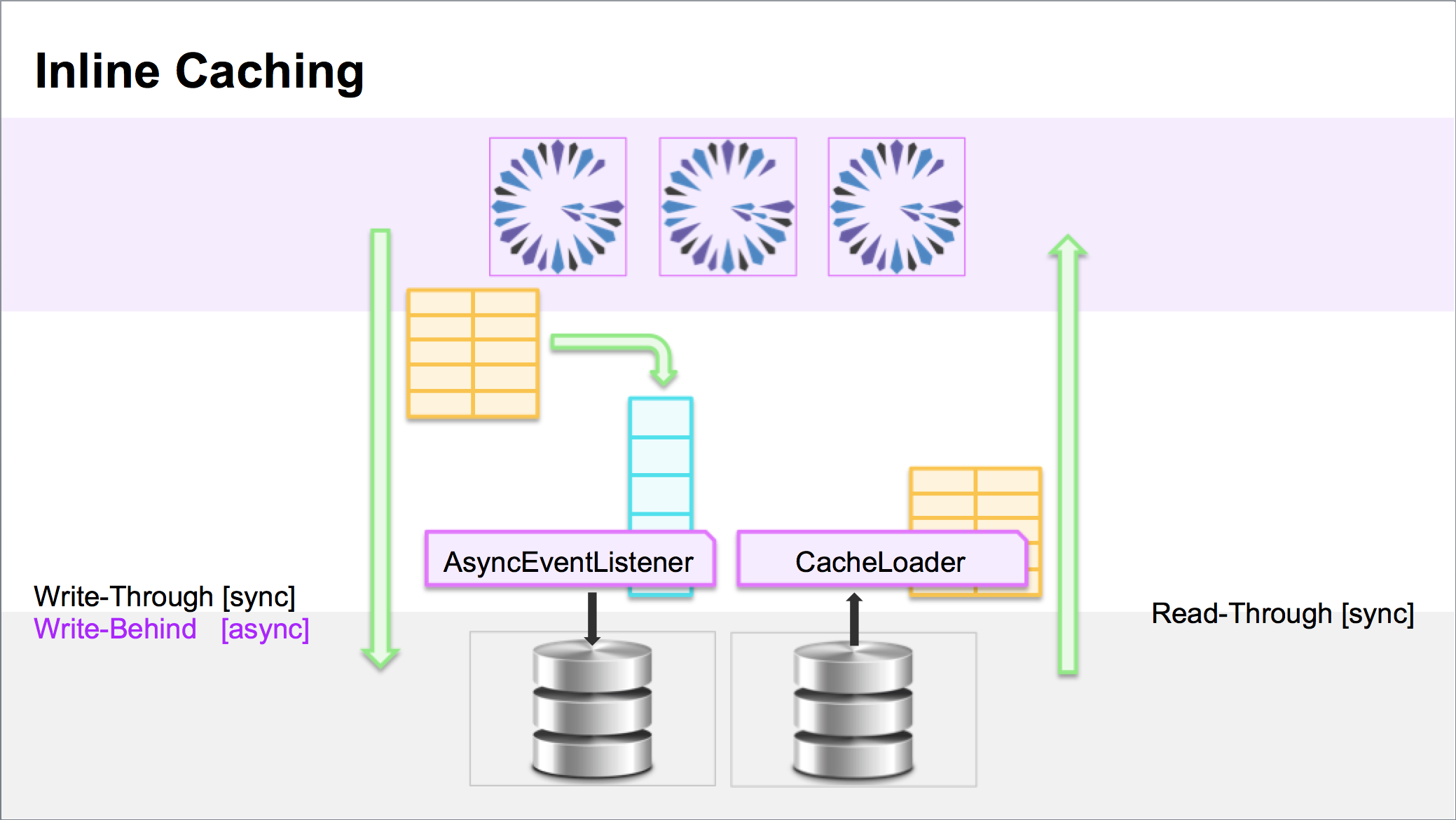
IMPLEMENTATION
As readers should know or will learn, the application cache is backed by an Apache Geode Region.
In Synchronous, Read-Through and/or Write-Through, Inline Caching, a CacheLoader is configured for the Region
and used to "Read-Through" to the backend/primary data source on a cache miss. When a cache entry is written, a
configured CacheWriter for the Region is invoked to "Write-Through" to the backend/primary data source. The cache
is only modified if the CacheWriter was successful in modifying the backend/primary data source.
Both the CacheLoader and CacheWriter are optional. That is, you can configure just one side of
Synchronous Inline Caching or the other, either "Read-Through" or "Write-Through", both, or neither.
With Asynchronous, Write-Behind, Inline Caching, you (may) configure the Region with an associated AsyncEventQueue
(AEQ) and registered AsyncEventListener. When the cache is written to, the entry event is then forwarded and stored
on the AEQ, where at some time later, the registered AsyncEventListener for the AEQ will be invoked to process the
(batch of) AsyncEvents, which can then asynchronously modify the backend/primary data source.
Unlike Synchronous Inline Caching, Asynchronous Inline Caching does not have an equivalent for "Read-Through", such as "Read-Behind", particularly in a Reactive sense.
| At some point later, we may consider the development of "Read-Behind" with with use of Reactive Programming and the Reactive Spring Data Repository abstraction. |
| It should also be intuitive that the listener registered on the AEQ attached to the (cache) Region does not have to process the events by writing to a backend data store. It could write to a message queue, to the file system, or do just about anything a user desires. However, OOTB SBDB provides support to inject a Spring Data Repository into an AEQ listener to write to any backend data store supported by the Spring Data Repository abstraction. |
2. Example
For our example, we have built a Golf Tournament application that runs a simulation with a set of professional golfers playing at The Masters. The (12) golfers play 18 holes of golf in pairs and proceed from hole 1 to hole 18 in under a minute. For each hole played, their score of the hole is calculated. At the end of the round, each golfer’s final score is calculated relative to par for the golf course (72).
The Golf Tournament application is a Spring Boot application using Apache Geode to cache the golfers score in realtime as the players complete each hole. However, to make the play "official", the golfer’s score is recorded to a backend database (RDBMS), asynchronously using Asynchronous, Write-Behind, Inline Caching. It is assumed that there is additional validation required (e.g. signing scorecards) that goes on before the final score is accepted and recorded to the System of Record (SOR), in the "history books", so to speak.
Now that the problem context has been established, let’s review a few of the application classes.
| Each of the application domain classes are code snippets or simply a preview of the actual class, and not actual code. See the actual Sample code for more detail. |
We start by defining our Golf Tournament application domain model types, starting with the Golfer class. Essentially,
the Golfer class models a person who plays golf and is defined as:
Golfer class.@Entity
@Table(name = "golfers")
public class Golfer implements Comparable<Golfer> {
@javax.persistence.Id @Id
private String name;
private Integer hole = 0;
private Integer score = 0;
}The Golfer class has been annotated with JPA’s @Entity annotation making it a proper (persistent) entity class.
The Golfer class is also annotated with @Table to persist instances of Golfer into the "golfers" table
of the database.
The application also defines a non-entity, GolfCourse class to model the golf course, which requires a name
and List of pars for each hole (all 18 holes) of the golf course:
GolfCourse classclass GolfCourse {
private final String name;
private final List<Integer> parForHole = new ArrayList<>(18);
}Next, a non-entity, GolfTournament class has been defined to model the golf tournament being played. It expects a name
for the tournament, the GolfCourse where the tournament is held and played, and a Set of Golfers (players)
registered to play.
Additionally, the GolfTournament class contains an inner class, the Pairing class, to group the registered players
into pairs to play a round.
GolfTournament classclass GolfTournament implements Iterable<Pairing> {
private final String name;
private GolfCourse golfCourse;
private final List<Pairing> pairings = new ArrayList<>();
private final Set<Golfer> players = new ArrayList<>();
public static class Pair {
private final Golfer playerOne;
private final Golfer playerTwo;
}
}The GolfTournament.Pairing class serves as a composite acting on both players in the pair, such as to advance
the hole of play.
The GolfTournament class has additional builder methods to register players, build pairings, enable the tournament
to be played and determine when the tournament is finished (i.e. when all pairs complete all 18 holes of play).
There is a GolferRepository interface extending the JpaRepository interface to persist the state of each Golfer
to the backend database:
GolferRepository interfaceinterface GolferRepository extends JpaRepository<Golfer, String> { }
While GolferRepository extends from the JpaRepository interface directly, it is recommended to extend
the CrudRepository interface instead, keeping your application SD Repositories agnostic from the underlying
data store. The reason GolferRepository extends from the JpaRepository interface directly, is to make it absolutely
clear that the Golfer state will be persisted to a backend database (RDBMS) with JPA using Hibernate as the provider.
|
The GolferRepository will be used by SBDG’s Asynchronous Inline Caching framework and infrastructure components.
The Repository is injected into and used by the AsyncEventListener registered on the AEQ attached to the "Golfers"
Region to perform Asynchronous, Write-Behind, Inline Caching, operations to the backend database
and System of Record (SOR).
We’ll see in a moment how this association is made and how Asynchronous Inline Caching is setup, made simple by SBDG.
To encapsulate the application logic and provide a (possibly transactional) facade to the Golfer’s state,
a GolferService class has been defined:
GolferService class@Service
class GolferService {
@CachePut(cacheNames = "Golfers", key = "#golfer.name")
public Golfer update(Golfer golfer) {
return golfer;
}
public List<Golfer> getAllGolfersFromCache() {
// Use SDG GemfireTemplate to access the "Golfers" Region
}
public List<Golfer> getAllGolfersFromDatabase() {
// Use the GolfersRepository to access the "Golfers" stored in the database.
}
}The GolferService class has been marked as a application service using Spring’s @Service stereotype annotation.
Along with the GolferService the application uses a PgaTourService class to manage and run a (single)
GolfTournament. Its primary method used to run a GolfTournament is the play() method:
PgaTourService class, play() method @Scheduled(initialDelay = 5000L, fixedDelay = 2500L)
public void play() {
GolfTournament golfTournament = this.golfTournament;
if (isNotFinished(golfTournament)) {
playHole(golfTournament);
finish(golfTournament);
}
}This is a Spring @Scheduled service method called every 2.5 seconds after an initial delay of 5 seconds. Essentially,
the service method iterates through the pairings and each Golfer plays all 18 holes. Their scores are calculated
and recorded for each hole until the round is completed, where the players score is then calculated relative to par
for the golf course and recorded to the cache, which eventually updates the database.
To get everything started, a Spring Boot application class (i.e. a class annotated with the @SpringBootApplication
annotation) is used to bootstrap the Golf Tournament application.
BootGeodeAsyncInlineCachingClientApplication class@SpringBootApplication
@SuppressWarnings("unused")
public class BootGeodeAsyncInlineCachingClientApplication {
private static final String APPLICATION_NAME = "GolfClientApplication";
public static void main(String[] args) {
SpringApplication.run(BootGeodeAsyncInlineCachingClientApplication.class, args);
}
@Configuration
@EnableScheduling
static class GolfApplicationConfiguration {
@Bean
ApplicationRunner runGolfTournament(PgaTourService pgaTourService) {
return args -> {
GolfTournament golfTournament = GolfTournament.newGolfTournament("The Masters")
.at(GolfCourseBuilder.buildAugustaNational())
.register(GolferBuilder.buildGolfers(GolferBuilder.FAVORITE_GOLFER_NAMES))
.buildPairings()
.play();
pgaTourService.manage(golfTournament);
};
}
}
@Configuration
@UseMemberName(APPLICATION_NAME)
@EnableCachingDefinedRegions(serverRegionShortcut = RegionShortcut.REPLICATE)
static class GeodeConfiguration { }
@PeerCacheApplication
@Profile("peer-cache")
@Import({ AsyncInlineCachingConfiguration.class, AsyncInlineCachingRegionConfiguration.class })
static class PeerCacheApplicationConfiguration { }
}The GolfTournament is kicked off in the ApplicationRunner.
ApplicationRunner bean in the GolfApplicationConfiguration class @Configuration
@EnableScheduling
static class GolfApplicationConfiguration {
@Bean
ApplicationRunner runGolfTournament(PgaTourService pgaTourService) {
return args -> {
GolfTournament golfTournament = GolfTournament.newGolfTournament("The Masters")
.at(GolfCourseBuilder.buildAugustaNational())
.register(GolferBuilder.buildGolfers(GolferBuilder.FAVORITE_GOLFER_NAMES))
.buildPairings()
.play();
pgaTourService.manage(golfTournament);
};
}
}As the golf tournament progresses (in the @Scheduled, PgaTourService.play() service method), updates to the Golfers
in the pairs are written to the "Golfers" cache (i.e. "Golfers" Region) by calling
the GolferService.update(:Golfer) service method:
GolferService class, update(:Golfer) method @CachePut(cacheNames = "Golfers", key = "#golfer.name")
public Golfer update(Golfer golfer) {
return golfer;
}This service method simply "puts" the Golfer in the cache (i.e. "Golfers" Region) mapped to the Golfer’s name
(as a key/value cache entry).
The cache/Region entry put operation results in cache event being added to the AEQ, which will eventually trigger
the SBDG framework-provided AsyncEventListener with our injected GolferRepository to write the Golfer’s state
to the backend database.
The configuration of the "Golfers" Region (cache) with an AEQ and listener using the GolferRepository is defined
as follows:
AsyncInlineCachingConfiguration class@Configuration
@SuppressWarnings("unused")
public class AsyncInlineCachingConfiguration {
protected static final String GOLFERS_REGION_NAME = "Golfers";
@Bean
@Profile("queue-batch-size")
AsyncInlineCachingRegionConfigurer<Golfer, String> batchSizeAsyncInlineCachingConfigurer(
@Value("${spring.geode.sample.async-inline-caching.queue.batch-size:25}") int queueBatchSize,
GolferRepository golferRepository) {
return AsyncInlineCachingRegionConfigurer.create(golferRepository, GOLFERS_REGION_NAME)
.withQueueBatchConflationEnabled()
.withQueueBatchSize(queueBatchSize)
.withQueueBatchTimeInterval(Duration.ofMinutes(15))
.withQueueDispatcherThreadCount(1);
}
@Bean
@Profile("queue-batch-time-interval")
AsyncInlineCachingRegionConfigurer<Golfer, String> batchTimeIntervalAsyncInlineCachingConfigurer(
@Value("${spring.geode.sample.async-inline-caching.queue.batch-time-interval-ms:5000}") int queueBatchTimeIntervalMilliseconds,
GolferRepository golferRepository) {
return AsyncInlineCachingRegionConfigurer.create(golferRepository, GOLFERS_REGION_NAME)
.withQueueBatchSize(1000000)
.withQueueBatchTimeInterval(Duration.ofMillis(queueBatchTimeIntervalMilliseconds))
.withQueueDispatcherThreadCount(1);
}
}The Spring @Configuration class used to enable Async Inline Caching consists of 2 different AEQ configurations
and bean definitions.
The first is a AEQ configured with a "preference" for being triggered on the batch size, i.e. the number of events present in the AEQ:
@Bean
@Profile("queue-batch-size")
AsyncInlineCachingRegionConfigurer<Golfer, String> batchSizeAsyncInlineCachingConfigurer(
@Value("${spring.geode.sample.async-inline-caching.queue.batch-size:25}") int queueBatchSize,
GolferRepository golferRepository) {
return AsyncInlineCachingRegionConfigurer.create(golferRepository, GOLFERS_REGION_NAME)
.withQueueBatchConflationEnabled()
.withQueueBatchSize(queueBatchSize)
.withQueueBatchTimeInterval(Duration.ofMinutes(15))
.withQueueDispatcherThreadCount(1);
}The second AEQ configuration uses a "preference" for being triggered based on a batch time interval, i.e. after a period of time has elapsed, such as 5 seconds.
@Bean
@Profile("queue-batch-time-interval")
AsyncInlineCachingRegionConfigurer<Golfer, String> batchTimeIntervalAsyncInlineCachingConfigurer(
@Value("${spring.geode.sample.async-inline-caching.queue.batch-time-interval-ms:5000}") int queueBatchTimeIntervalMilliseconds,
GolferRepository golferRepository) {
return AsyncInlineCachingRegionConfigurer.create(golferRepository, GOLFERS_REGION_NAME)
.withQueueBatchSize(1000000)
.withQueueBatchTimeInterval(Duration.ofMillis(queueBatchTimeIntervalMilliseconds))
.withQueueDispatcherThreadCount(1);
}| The default AEQ batch time interval in Apache Geode is 5 milliseconds (5 ms). However, to demonstrate the asynchronous nature of the cache to database updates, a much longer delay was used. Likewise, the default AEQ batch size in Apache Geode is 100. |
In both AEQ configurations and bean definitions, the batch size and batch time interval have been set (overriding the Apache Geode defaults) in order to show the effects of each AEQ configuration independently. As you can imagine, particularly in a highly concurrent and transactional application with frequent updates, it would be hard to determine whether the AEQ event processing (via the listener) was triggered by the batch time interval or the batch size. And, with a default 5 millisecond batch time interval, it is hard to witness the asynchronous nature of the cache to database updates to begin with.
We will have more to say on the AEQ configuration below, in the conclusion.
The final class in the golf application is a GolferController class annotated with Spring’s @RestController
annotation in order to expose our golf application functionality as an API in a REST-ful interface:
GolferService class, update(:Golfer) method@RestController
@RequestMapping("/api/golf/tournament")
@SuppressWarnings("unused")
public class GolferController {
private final GolferService golferService;
public GolferController(@NonNull GolferService golferService) {
Assert.notNull(golferService, "GolferService must not be null");
this.golferService = golferService;
}
protected @NonNull GolferService getGolferService() {
return this.golferService;
}
@GetMapping("/cache")
public List<Golfer> getGolfersFromCache() {
return getGolferService().getAllGolfersFromCache();
}
@GetMapping("/database")
public List<Golfer> getGolfersFromDatabase() {
return getGolferService().getAllGolfersFromDatabase();
}
}The Spring Web MVC @RestController class exposes two REST-ful API web service endpoints returning JSON data:
-
http://localhost:8080/api/golf/tournament/cache - used to get the current state of the
Golfersfrom the cache -
http://localhost:8080/api/golf/tournament/database - used to get the current state of the
Golfersfrom the database
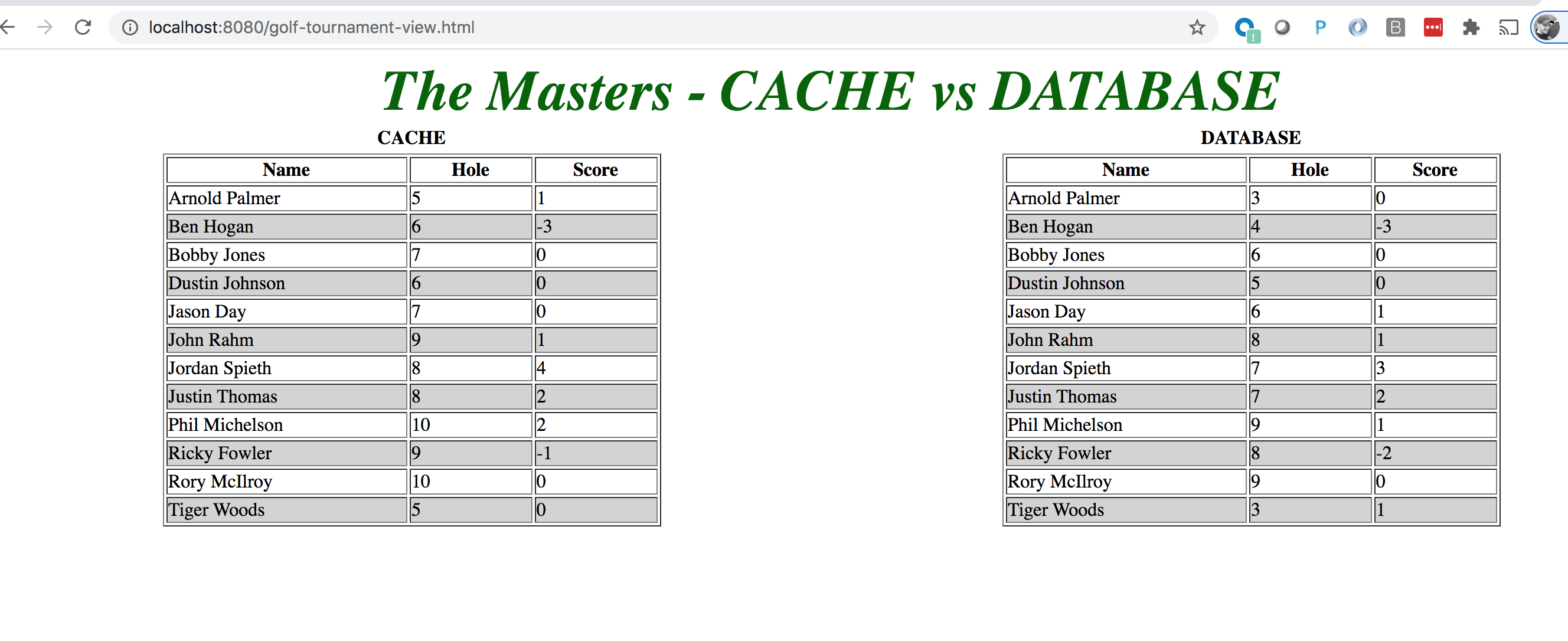
Both web service endpoints are consumed by the golf-tournament-view.html page, which uses jQuery and AJAX to make
periodic HTTP requests to refresh the page.
3. Run the Example
To run the example, there are few more configuration details we need to cover.
While it is possible to run this example using an Apache Geode client/server topology, we keep things simple
by running the example using a single Spring Boot application class, namely the
BootGeodeAsyncInlineCachingClientApplication along with a peer cache configuration.
That is, in our BootGeodeAsyncInlineCachingClientApplication class, we also apply the
PeerCacheApplicationConfiguration by enabling the Spring Profile, "peer-cache":
PeerCacheApplicationConfiguration class @PeerCacheApplication
@Profile("peer-cache")
@Import({ AsyncInlineCachingConfiguration.class, AsyncInlineCachingRegionConfiguration.class })
static class PeerCacheApplicationConfiguration { }It should be noted that AEQs can only be created and registered on Regions existing on the server-side of an Apache Geode system. That is, you cannot add an AEQ to a client-side Region. Therefore, in all your Async Inline Caching Uses Cases (UC), synchronous or asynchronous, it will be the servers in an Apache Geode cluster that are responsible for Write-Behind functionality to the backend data store, not a Spring Boot, Apache Geode client application.
However, for demonstration purposes, we override SBDG’s auto-configuration providing a ClientCache instance
by default simply by enabling the "peer-cache" Spring Profile, which replaces the ClientCache instance with
a peer Cache instance instead.
Finally, when running this application, you must decide on your AEQ management strategy.
For example, do you want the AEQ listener to be triggered by batch size (i.e. the number of cache events) or using the batch time interval. Each strategy can be enabled using a Spring Profile, either "queue-batch-size" or "queue-batch-time-interval". This allows you to experiment with different AEQ management strategies and observe the effects.
In total, the Spring Profiles you need to enable would appear as follows:
-Dspring.profiles.active=peer-cache,queue-batch-size,serverOf course, you can replace "queue-batch-size" with "queue-batch-time-interval".
The final run configuration of the Spring Boot application, as seen in IntelliJ IDEA is:
To access the golf application, simply navigate to:
You should see a web page similar to:
You can also run this example using the SBDG Gradle build from the command-line like so:
$ gradlew --no-daemon :spring-geode-sample-caching-inline-async:bootRunThis is convenient since the Spring Profiles are already configured for you.
However, when you switch to using the "queue-batch-time-interval" you will see a similar effect and behavior, but on a slightly different schedule for the database updates, i.e. at a fixed 5 second interval.
4. Conclusion
Asynchronous Inline Caching can be a powerful pattern of caching applied to your Spring Boot application workflows depending on the use case and requirements.
If throughput and latency are absolutely critical to your application design in order to achieve the necessary responsiveness and quality of experience your users' expect, and consistency (i.e. between the cache and the backend System of Record (SOR), or database) is not as important of a concern, then you might want to consider Asynchronous Inline Caching.
There are many factors to consider in the configuration of the AEQ that is at the heart of the Asynchronous Inline Caching pattern, such as the appropriate batch size and batch time interval. Neither setting is exclusive from the other, in fact. Both settings are considered when Apache Geode makes a decision of when to trigger the listener registered on the AEQ to process the events for operations originating from the Region to which the AEQ is attached.
You must decide on the batch size, based on how many events might occur in a given period of time. If the frequency is quite high, then you might need a smaller batch size, for instance. The AEQ is in-memory after all, therefore you must be conscious of memory constraints on your system, especially during peak loads. Of course, the AEQ can be configured to overflow events to disk and even persist events between restarts, but ideally you want these events to be processed in as near realtime as possible.
However, when the load on your application is low and events occur sporadically, you must also be mindful that the events do not sit in the AEQ for too long. If you have batch size of 1000, and there are currently only 20 events (well, any number of events less than 1000) sitting in the AEQ waiting to be processed, then the batch time interval becomes important, especially so that these remaining events (less than the configured batch size) don’t wait in the queue indefinitely. The configured Queue Dispatcher Thread count plays into this as well.
Other factors to consider are whether you can conflate the events in the AEQ. This minimizes the number of events for
a single logical Object to the latest update. Additionally, do you need to overflow events to disk after the configured
maximum queue memory is reached, or should events simply be discarded? Do you need to maintain the events in the queue
between restarts (i.e. configure the AEQ to be persistent)? Do the disk writes for overflow and/or persistence need to
be synchronous? Do the events in the queue need to be ordered based on some OrderPolicy? Do the events need to be
filtered? How many dispatcher threads do you require? Etc. Etc.
There are many important things consider in the configuration of the AEQ when using Asynchronous Inline Caching for Write-Behind capabilities. Usually, it is safe to start with the defaults and adjust as needed, and as your measurements and tests dictate.
We hope that you found this guide useful and informative when tackling difficult problems, the kind of application problems where the Asynchronous Inline Caching pattern can be applied with immediate benefits.