This guide walks you through building a simple Spring Boot application using Spring’s Cache Abstraction backed by Apache Geode as the caching provider for Inline Caching.
It is assumed that the reader is familiar with the Spring programming model. No prior knowledge of Spring’s Cache Abstraction or Apache Geode is required to utilize caching in your Spring Boot applications.
Additionally, this Sample builds on the concepts from the Look-Aside Caching with Spring guide. Therefore, it would be helpful to have read that guide before proceeding through this guide.
Let’s begin.
| Refer to the Inline Caching section, and specifically the Synchronous Inline Caching, in the Caching with Apache Geode chapter of the reference documentation for more information. |
1. Background
Caching, and in particular, Look-Aside Caching, is useful in cases where the output of an operation yields the same results when given the same input. If an expensive operation is frequently invoked with the same input, then it will benefit from caching, especially if the operation is compute intensive, IO bound, such as by accessing data over a network, and so forth.
Consider a very simple mathematical function, the factorial. A factorial is defined as factorial(n) = n!.
For example, if I call factorial(5), then the computation is 5 * 4 * 3 * 2 * 1 and the result will be 120.
If I call factorial(5) over and over, the result will always be the same. The factorial calculation is
a good candidate for caching.
While a factorial might not be that expensive to compute, it illustrates the characteristics of an operation that would benefit from caching.
In most Look-Aside Caching use cases, the cache is not expected to be the "source of truth". That is, the application is backed by some other data source, or System of Record (SOR), such as a database. The cache merely reduces resource consumption and contention on the database by keeping frequently accessed data in memory for quick lookup when the data is not changing constantly.
It is not that the data cannot or does not ever change, only that the data is read far more than it is written, and when it is written, the cache entry is simply invalidated and reloaded, either lazily when data is next needed by the application, or the data can be eagerly loaded, if necessary. Either way, the cache is not the "source of truth" and therefore does not strictly need to be consistent with the database.
| Do not take "inconsistency" between the cache and database to mean that the application will read stale data. It simply means there will be a penalty to reload/refresh the data the next time the data is requested. |
But, this guide is not about Look-Aside Caching, it is about Inline Caching. While Inline Caching can take several forms, the form of Inline Caching we present here will be an extension to the Look-Aside Cache pattern.
This particular form of Inline Caching is useful in cases where:
-
Consistency between the Cache and Database is important, or…
-
Having access to the latest, most up-to-date information from the backend SOR is crucial (e.g. time sensitive).
-
Multiple, discrete & disparate applications are sharing the same data source (contrary to Microservices design).
-
The application is distributed across multiple sites.
There maybe other reasons.
Spring’s Cache Abstraction offers a basic form of Inline Caching if you consider the overloaded
Cache.get(Object key, Callable<T> valueLoader):T
method. The overloaded Cache.get(..) method accepts a Callable argument, which serves the purpose of loading a value
from an external data source, as defined by the Callable, on a cache miss. If a value for the given key is not present
in the cache, then the Callable will be invoked to load a value for the given key.
This form of Inline Caching is very basic since 1) most application developers are not interfacing with Spring’s
Cache Abstraction in their application by using the org.springframework.cache.Cache API directly. Most of the time,
application developers will use the Spring cache annotations (e.g. @Cacheable), or alternatively, the JSR-107,
JCache API annotations, as documented. 2) Second, while
Cache.get(..) satisfies read-through to the backend, external data source, there is no equivalent operation
in the Cache API for write-through, i.e. when using Cache.put(key, value) to put a value into the cache
in addition to writing back to the external data source.
With Inline Caching, the read & write through to/from the backend data source are intrinsic characteristics
of Inline Caching. Additionally, on write-through, the cache op (i.e. put(key, value)) does not succeed
unless the backend data source has been updated. In essence, the cache and backend data source are kept in-sync
and therefore consistent.
| There are still moments when the cache could be observed in an inconsistent state relative to the backend database, such as between a database update and a cache refresh on a cache hit. This means the value was in the cache but may not have been the latest value when requested since the database may have been updated by some other means (e.g. another application updating the database directly, not using Inline Caching with a synchronous write-through). To keep the cache and database consistent, then all data access operations must involve the cache. That is, you must strictly adhere to and be diligent in your use of Inline Caching. |
Inline Caching can be depicted in the following diagram:
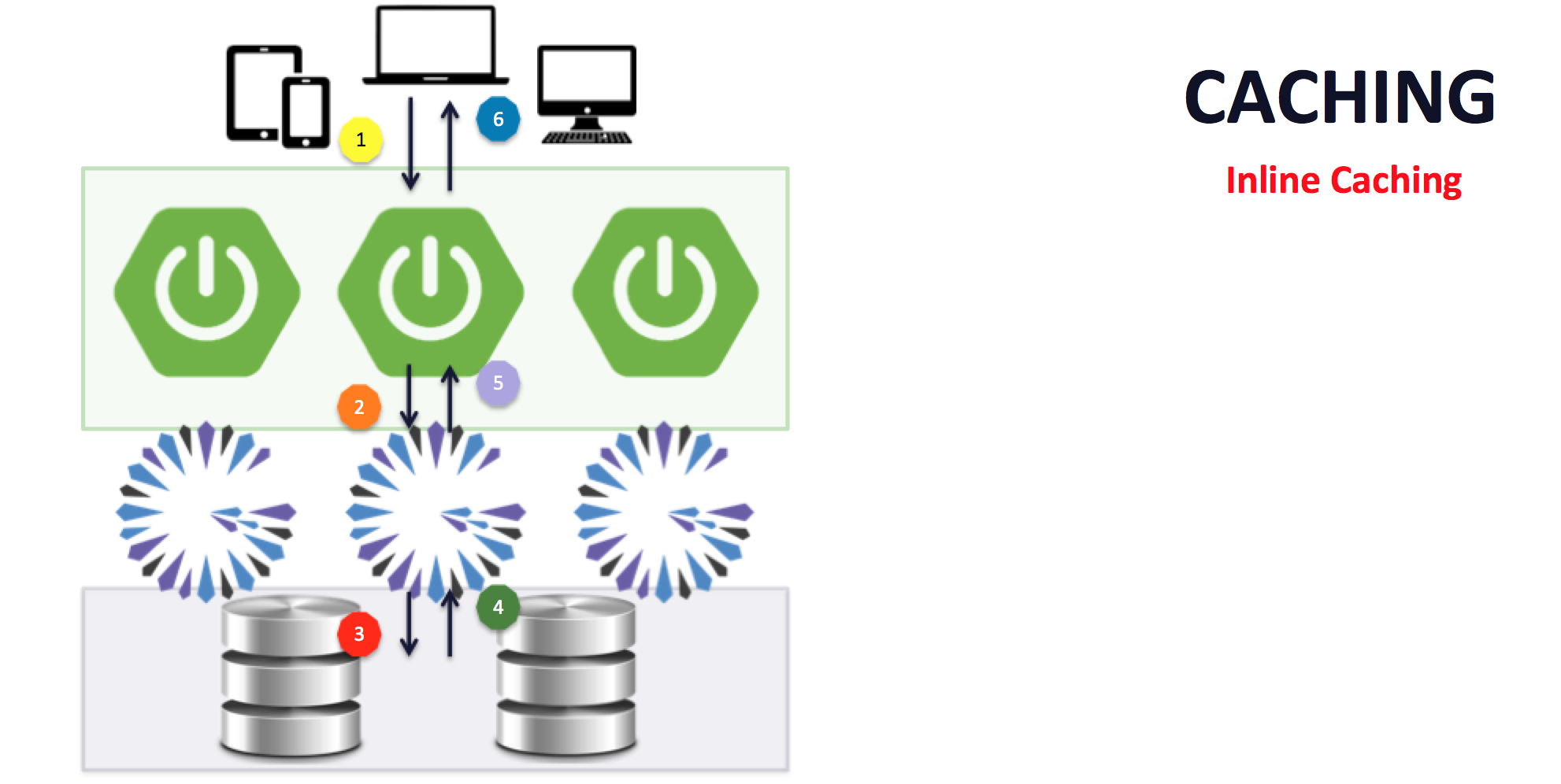
In the diagram above, there are 2 flows: 1 for read-through (right-side) and another for write-through (left-side). Both can occur in a single operation, on a read.
When a client sends a request for data (#6) the request invokes the appropriate application (@Cacheable) service
method, which is immediately forwarded to the cache to determine if the results for the given input have already been
computed (#5). If the result is cached (a cache hit), then the result is simply returned to the caller. However,
if a result had not been previously computed, or the result expired, or was evicted, then before the cacheable service
method is invoked, an additional lookup is performed (#4) to determine whether the computed value may have already
been persisted to the backend database. If the value exists in the database, then it is loaded into the cache
and returned to the caller. Only when the computed value is not present in the cache nor exists in the database is the
cacheable service method invoked. Once the service method finishes and returns the result, the value is cached as part
of the contract of @Cacheable and will also be written through to the backend database.
During a client request to compute some value regardless of the cache or database state (#1), the service method is
always invoked (as specified in the contract for the @CachePut annotation). Upon completing the computation,
the result is cached (#2) and additionally persisted to the database (#3), which describes the write-through.
If the database INSERT/UPDATE is not successful on write, then the cache will not contain the value.
Now it is time to make all of this a bit more concrete with an example.
2. Example
For our example, we will develop a calculator application that performs basic mathematical functions, such as
factorial. Again, not that practical, but a useful and simple demonstration allowing us to focus on
our primary concern, which is to enable and use Inline Caching.
2.1. Caching-enabled CalculatorService
We start by defining the supported mathematical functions in a CalculatorService class.
@Service
public class CalculatorService extends AbstractCacheableService {
@Cacheable(value = "Factorials", keyGenerator = "resultKeyGenerator")
public ResultHolder factorial(int number) {
this.cacheMiss.set(true);
Assert.isTrue(number >= 0L,
String.format("Number [%d] must be greater than equal to 0", number));
simulateLatency();
if (number <= 2) {
return ResultHolder.of(number, Operator.FACTORIAL, number == 2 ? 2 : 1);
}
int operand = number;
int result = number;
while (--number > 1) {
result *= number;
}
return ResultHolder.of(operand, Operator.FACTORIAL, result);
}
@Cacheable(value = "SquareRoots", keyGenerator = "resultKeyGenerator")
public ResultHolder sqrt(int number) {
this.cacheMiss.set(true);
Assert.isTrue(number >= 0,
String.format("Number [%d] must be greater than equal to 0", number));
simulateLatency();
int result = Double.valueOf(Math.sqrt(number)).intValue();
return ResultHolder.of(number, Operator.SQUARE_ROOT, result);
}
}The CalculatorService is annotated with Spring’s @Service stereotype annotation so that it will be picked up by
the Spring Container’s classpath component scan process, which has been carefully configured by Spring Boot.
The class also extends the AbstractCacheableService base class, inheriting a couple boolean methods that signal
whether cache access resulted in a hit or miss.
In addition, the CalculatorService contains two mathematical functions: factorial and sqrt (square root).
Each method caches the result of the computation using the input (operand) and operator as the key. If the method
is called 2 or more times with the same input, the cached result will be returned, providing the cache entry has not
expired or been evicted. We neither configure eviction nor expiration for this example, however.
Both the factorial(..) and sqrt(..) methods have been annotated with Spring’s @Cacheable annotation to demarcate
these methods with caching behavior. Of course, as explained in SBDG’s documentation,
caching with Spring’s Cache Abstraction using Apache Geode as the caching provider is enabled by default.
Therefore, there is nothing more you need do to start leverage caching in your Spring Boot applications than to annotate
the service methods with the appropriate Spring or JSR-107, JCache API annotations. Simple!
It is worth noting that we are starting with the same applied pattern of caching as you would when using the Look-Aside Caching pattern. This is key to minimizing the invasive nature of Inline Caching. There is a subtle difference, though, and that will be apparent in the additional configuration we supply as part of our Spring Boot application.
Let’s look at that next.
2.2. Inline Caching Configuration
The following illustrates the additional configuration required to enable Inline Caching:
@Configuration
@EnableCachingDefinedRegions(clientRegionShortcut = ClientRegionShortcut.LOCAL)
@EntityScan(basePackageClasses = ResultHolder.class)
@SuppressWarnings("unused")
public class CalculatorConfiguration {
@Bean
InlineCachingRegionConfigurer<ResultHolder, ResultHolder.ResultKey> inlineCachingForCalculatorApplicationRegionsConfigurer(
CalculatorRepository calculatorRepository) {
Predicate<String> regionBeanNamePredicate = regionBeanName ->
Arrays.asList("Factorials", "SquareRoots").contains(regionBeanName);
return new InlineCachingRegionConfigurer<>(calculatorRepository, regionBeanNamePredicate);
}
@Bean
KeyGenerator resultKeyGenerator() {
return (target, method, arguments) -> {
int operand = Integer.parseInt(String.valueOf(arguments[0]));
Operator operator = "sqrt".equals(method.getName())
? Operator.SQUARE_ROOT
: Operator.FACTORIAL;
return ResultHolder.ResultKey.of(operand, operator);
};
}
}The pertinent part of the configuration that enables Inline Caching for our Calculator application is contained in
the inlineCachingForCalculatorApplicationRegionsConfigurer bean definition.
SBDG provides the InlineCachingRegionConfigurer class used in the bean definition to configure and enable the caches
(a.k.a. as Regions in Apache Geode terminology) with Inline Caching behavior.
The Configurer’s job is to configure the appropriate Spring Data (SD) Repository used as a Region’s CacheLoader
for "read-through" behavior as well as configure the same SD Repository for a Region’s CacheWriter for
"write-through" behavior. This "read/write-through" behavior is the "inlining" component of Inline Caching,
i.e. the second lookup opportunity we talked about in the Background
section above.
The CacheLoader/Writer also ensures consistency between the cache and the backend data store, such as a database.
The Repository plugged in by our application configuration is the CalculatorRepository:
public interface CalculatorRepository
extends CrudRepository<ResultHolder, ResultHolder.ResultKey> {
Optional<ResultHolder> findByOperandEqualsAndOperatorEquals(Number operand, Operator operator);
}
Spring Data’s Repository abstraction is used rather than providing direct access to some DataSource for
the backend data store since 1) Spring Data Repository abstraction supports a wide-array
of backend data stores uniformly and 2) it is easy to compose multiple Spring Data Repositories as one (using
the Composite pattern) if you want to write to multiple backend
data stores and 3) Spring Data has a very consistent and intuitive API, based on the
Data Access Object (DAO) pattern
for defining basic CRUD and simple query data access operations. Typically, the DataSource must be wrapped
by a higher-level API to make use of the backend data store in Java anyway, like JDBC for databases, or even higher,
such as by using an ORM tool (e.g. JPA with Hibernate).
|
The second argument in the configuration for the InlineCachingRegionConfigurer includes a required Predicate
used to target the specific caches (Regions) on which Inline Caching should be enabled and used. You can target
all regions by simply supplying the following Predicate:
Predicate<String> predicate = () -> regionBeanName -> true;In our case, we only want to target the Regions that have been used as "caches" as identified in the service methods
annotated with Spring’s @Cacheable annotation, to be enabled with and use Inline Caching.
The Predicate allows you to target different Regions using different Spring Data Repositories, and by extension
different backend data stores, for different purposes, depending on your application uses cases.
For example, you may have a cache Region X containing data that needs to be stored in MongoDB (use Spring Data MongoDB), where as another cache Region Y may contain data that needs to be written to Neo4j and represented as a graph (use Spring Data Neo4j’s), and yet another cache Region Z containing data that needs to be written back to a database (use Spring Data JDBC or Spring Data JPA).
This is what makes the Spring Data Repository pattern so ideal. It is very flexible and has a highly consistent
API across a disparate grouping of data stores. And due to that uniformity, it is easy to "adapt" the
Apache Geode CacheLoader/CacheWriter interfaces to use a SD Repository under-the-hood. Indeed, that is
exactly what SBDG has done for you!
We will circle back to the resultKeyGenerator bean definition after we talk about the application domain model.
Also notice the use of the @EnableCachingDefinedRegions annotation.
Whenever you use a caching provider like Apache Geode or Redis, you must explicitly define or declare your caches
in some manner. This is inconvenient since you have basically already declared the caches required by your application
when using Spring’s, or alternatively, the JSR-107, JCache API annotations (e.g. @Cacheable). Why should you have to
do this again? Well, using SBDG, you don’t. You simply have to declare the @EnableCachingDefinedRegions annotation
and SBDG will take care of defining the necessary Apache Geode Regions backing the caches for you.
Regions for caches are not auto-configured for you because there are many different ways to "define" a Region, with different configuration, such as eviction and expiration polices, memory requirements, application callbacks, etc. The Region may already exist and have been created some other way. Either way, you may not want SBDG to auto-configure these Regions for you.
| If you have not done so already, you should definitely read about SBDG’s support for Inline Caching in the Inline Caching section. |
To learn more about how Apache Geode’s data loading functionality works, or specifically, how to
"Keep the Cache in Sync with Outside Data Sources"
follow the link. You may also learn more by reading the Javadoc for CacheLoader
and CacheWriter.
|
To learn more about @EnableCachingDefinedRegions, see the Spring Data for Apache Geode
documentation.
|
2.3. Backend DataSource Configuration
While we used Spring Data’s Repository abstraction as the way to access data in the backend data store used for Inline Caching, we have not shown how the data source for the backend data store was configured.
Obviously, the data source connecting the application to the backend data store varies from data store to data store.
Clearly, when using a database, you would configure a javax.sql.DataSource using the JDBC API. That DataSource is
then plugged into a higher-level data access API like JDBC, or Spring’s JdbcTemplate, or JPA, to perform data access.
With MongoDB or Redis, again you would configure the data source, or connection factory, appropriate for those stores
and plug that into the data access API of your choice (e.g. Spring Data MongoDB or Spring Data Redis).
Though it is not immediately apparent in our example, we simply 1) used an embedded, in-memory database (i.e. HSQLDB) and 2) relied on Spring Boot’s auto-configuration to bootstrap the embedded database on startup.
| To learn more about bootstrapping an embedded database and the embedded databases that can be auto-configured by Spring Boot, follow the link. |
In a nutshell, we only need to declare a dependency on spring-jdbc and the embedded database we want to use
as the backend data store for Inline Caching, like so:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.hsqldb</groupId>
<artifactId>hsqldb</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>The spring-jdbc dependency is transitively pulled in by org.springframework.boot:spring-boot-starter-data-jpa,
which also pulls in Spring Data JPA. Therefore, we are using JPA, and specifically, the Hibernate JPA provider,
to back our Spring Data Repository (i.e. CalculatorRepository) in this example.
With these dependencies declared on the application’s classpath, Spring Boot auto-configures a DataSource to
an embedded HSQLDB database, bootstraps HSQLDB, finds our application CalculatorRepository interface declaration,
and backs it with a Spring Data JPA implementation using Hibernate as the provider. Very powerful!
Additionally, we configure our embedded HSQLDB database by including a SQL script with DDL statements to initialize the schema (i.e. create the "CALCULATIONS" table):
CREATE TABLE IF NOT EXISTS calculations (
operand INTEGER NOT NULL,
operator VARCHAR(256) NOT NULL,
result INTEGER NOT NULL,
PRIMARY KEY (operand, operator)
);We also include a SQL script containing DML statements to populate the database with some existing data (i.e. mathematical calculations) in order to simulate cache hits:
INSERT INTO calculations (operand, operator, result) VALUES (5, 'FACTORIAL', 120);
INSERT INTO calculations (operand, operator, result) VALUES (7, 'FACTORIAL', 5040);
INSERT INTO calculations (operand, operator, result) VALUES (9, 'FACTORIAL', 362880);
INSERT INTO calculations (operand, operator, result) VALUES (16, 'SQUARE_ROOT', 4);
INSERT INTO calculations (operand, operator, result) VALUES (64, 'SQUARE_ROOT', 8);
INSERT INTO calculations (operand, operator, result) VALUES (256, 'SQUARE_ROOT', 16);By simply including schema.sql and the complimentary data.sql files in the classpath of the application, Spring Boot
will automatically detect these files and apply them to the database during startup.
| To learn more about embedded, in-memory database initialization applied by Spring Boot, see here. |
2.4. Application and Data Modeling
The final component of our application up for discussion is the application domain model (as compared to the data model). There is not a whole lot of difference; the structure and mapping is relatively 1-to-1.
The results from the mathematical calculations are captured in an instance of the ResultHolder class:
@Entity
@Getter
@IdClass(ResultHolder.ResultKey.class)
@EqualsAndHashCode(of = { "operand", "operator" })
@RequiredArgsConstructor(staticName = "of")
@Table(name = "Calculations")
public class ResultHolder implements Serializable {
@Id @NonNull
private Integer operand;
@Id
@NonNull
@Enumerated(EnumType.STRING)
private Operator operator;
@NonNull
private Integer result;
protected ResultHolder() { }
@Override
public String toString() {
return getOperator().toString(getOperand(), getResult());
}
@Getter
@EqualsAndHashCode
@RequiredArgsConstructor(staticName = "of")
public static class ResultKey implements Serializable {
@NonNull
private Integer operand;
@NonNull
private Operator operator;
protected ResultKey() { }
}
}This class uses Project Lombok to simplify the implementation.
It is also a JPA persistent entity as designated by the javax.persistence.Entity annotation.
We also define a composite, primary key (i.e. ResultHolder.ResultKey), which consists of the operand to
the mathematical function along with the Operator, which has been defined as an enumerated type and is
the mathematical function being computed (e.g. factorial).
This is also why, as briefly alluded to back in the section on Inline Caching Configuration,
the resultKeyGenerator bean definition was important:
@Bean
KeyGenerator resultKeyGenerator() {
return (target, method, arguments) -> {
int operand = Integer.parseInt(String.valueOf(arguments[0]));
Operator operator = "sqrt".equals(method.getName())
? Operator.SQUARE_ROOT
: Operator.FACTORIAL;
return ResultHolder.ResultKey.of(operand, operator);
};
}This custom KeyGenerator was applied in the caching annotations of the service method like so:
@Service
class CalculatorService {
@Cacheable(keyGenerator="resultKeyGenerator")
public int factorial(int number) { }
}Basically, the keys between the cache and the database (i.e. the primary key) must match. This is because the cache key
is used as the identifier in all data access operations performed against the backend database using the
CalculatorRepository (e.g. calculatorRepository.findById(cacheEntry.getKey()), specifically in the cache loader’s
(i.e. the read-through) case).
If a custom KeyGenerator had not been provided, then the "key" would have been the @Cacheable service method
parameter only (i.e. the integer number or operand in the mathematical function), and as I already stated, the primary
key in the database table is a composite key consisting of both the operand and the operator. This was deliberate
because…
The most fundamental difference between the application domain model and the database model is that while the application keeps the mathematical calculations in 2 separate, distinct caches (Regions), as seen in the `@Cacheable annotation on the individual service methods:
@Service
class CalculatorService {
@Cacheable(name = "Factorials")
public int factorial(int number) { }
@Cacheable(name = "SquareRoots")
public int sqrt(int number) { }
}The database, on the other hand, stores all mathematical calculations in the same table. That is, both factorials and square roots are stored together in the "CALCULATIONS" table.
This is also why the operand cannot be used as the primary key by itself. If a user of our Calculator application
performed both factorial(4) = 24 and sqrt(4) = 2, how do we know which result the user wants just by looking
at the operand when performing the cache lookup. You dons’t. You need to know the operator, too.
While the individual CalculatorService methods for the mathematical functions determine which operator is in play,
and even while the results of the calculations are kept separately in distinct caches, and therefore, there can only be
one result per entry (i.e. operand) in the individual caches, the database table is not like the cache
or the application.
Again, this design was very deliberate in order to show the flexibility you have in modeling your application, your cache and your database, independently of each other. After all, you may be building a new application for an existing database who’s data model cannot be changed. However, it does not mean your application model needs to strictly match the database model if that is not the most efficient way to access and process the data.
The point is, you have options, and you can make the best choice for your application’s needs.
3. Run the Example
Now it is time to run the example.
The example can be run from the command-line using the gradlew command as follows:
gradlew$ gradlew :spring-geode-samples-caching-inline:bootRunAlternatively, you can run the BootGeodeInlineCachingApplication class in your IDE (e.g. IntelliJ IDEA). Simply create
a run profile configuration and run it. No additional JVM arguments, System Properties or program arguments
are required.
The observant reader will have noticed that the CalculatorService uses int as the data type for the input
and output of the mathematical functions. You should never use int to implement any mathematical calculations for any
enterprise applications, ever. Instead, you should use either java.math.BigDecimal or java.math.BitInteger.
One of many reasons for this, especially in factorial’s case, is that it is very easy to "overflow" the allowed
values of an int type, which is 32 bits. In fact, with factorial(13) you exceed the range of allowed integer values
represented by an int. Even long is not sufficient in most cases. Therefore, the CalculatorService is very
limited in its utility. int was used primarily to minimize type conversions between store types and keep the example
as simple as possible.
|
The Calculator application includes a CalculatorController, which is a Spring Web MVC @RestController,
containing the following Web service endpoints:
| REST API call | Description |
|---|---|
|
Returns the home page. Defaults to |
|
Heartbeat endpoint returning "PONG". |
|
Computes the factorial of the |
|
Computes the square root of the |
Keep in mind that the following data set has been loaded into the backend database already, which is indirectly treated as "cached" data:
INSERT INTO calculations (operand, operator, result) VALUES (5, 'FACTORIAL', 120);
INSERT INTO calculations (operand, operator, result) VALUES (7, 'FACTORIAL', 5040);
INSERT INTO calculations (operand, operator, result) VALUES (9, 'FACTORIAL', 362880);
INSERT INTO calculations (operand, operator, result) VALUES (16, 'SQUARE_ROOT', 4);
INSERT INTO calculations (operand, operator, result) VALUES (64, 'SQUARE_ROOT', 8);
INSERT INTO calculations (operand, operator, result) VALUES (256, 'SQUARE_ROOT', 16);If you call http://localhost:8080/caculator/factorial/4, you will see the following output:
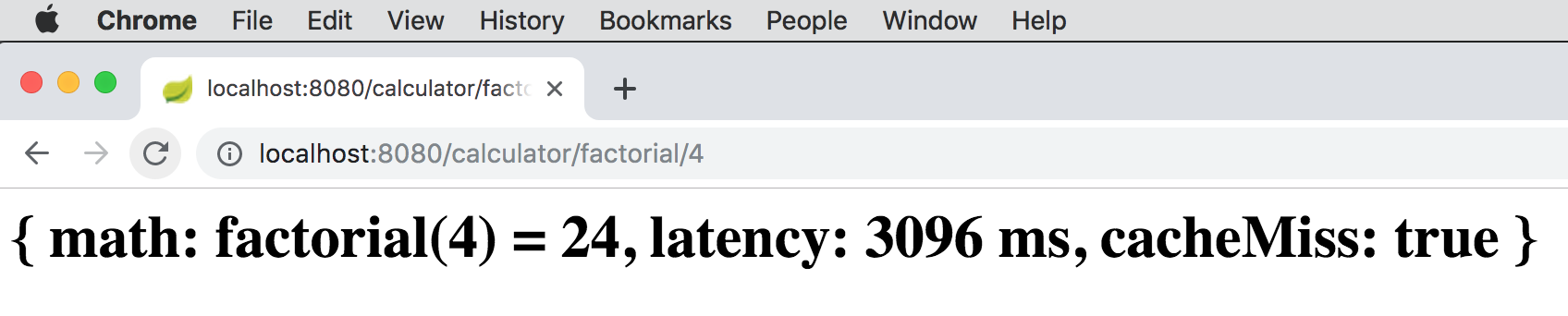
The output shows the result of factorial(4) is 24, that the calculation took 3096 milliseconds and the operation
resulted in a cache miss. However, now that we computed factorial(4), the result was put into the "cache"
as well as INSERTED into the backend (embedded, in-memory HSQLDB) database. So, if we run the operation again,
the latency drops to zero (and cacheMiss is false):
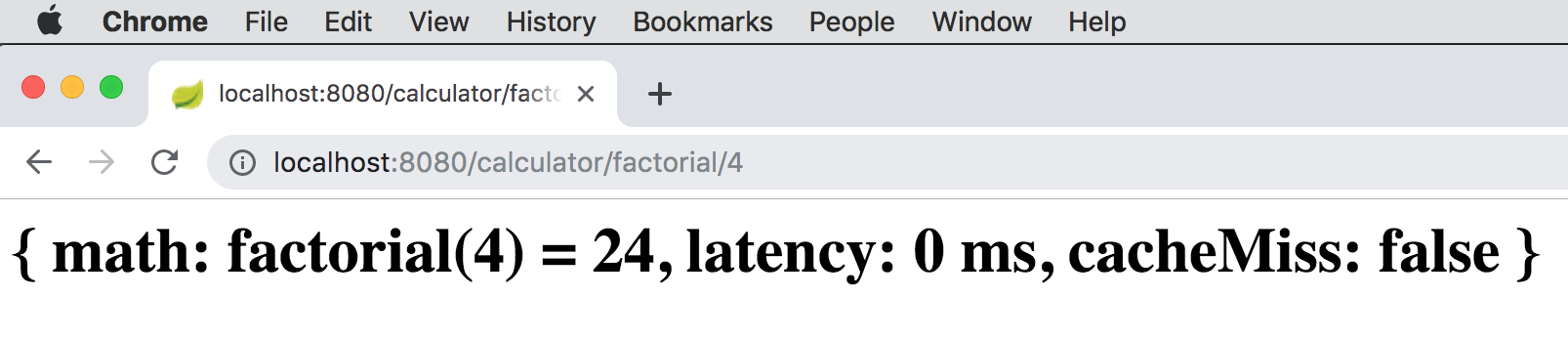
That is because the result (i.e. 24) of factorial(4) is "cached" in Apache Geode (as well as persisted to
the database; write-through) and therefore, the CaculatorService.factorial(:int) method is not called.
The result, however, is pulled from the cache, not the database.
To see the effects of the factorial(:int) method involving the database as part of the inline cache lookup, you can
call http://localhost:8080/caculator/factorial/5. 5 is stored in the database, but is not currently present
in the cache:
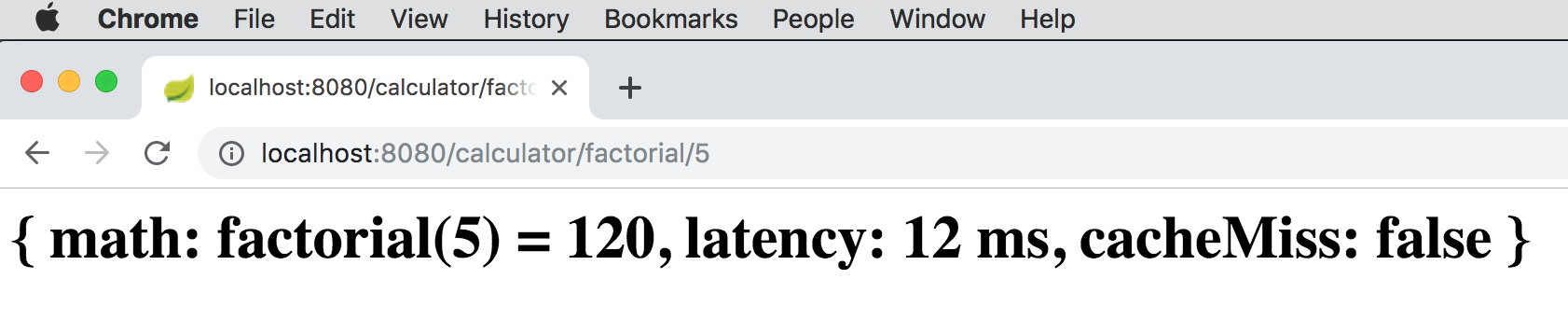
While the latency is much better than invoking the factorial function, it is still not as fast as pulling the result from the cache.
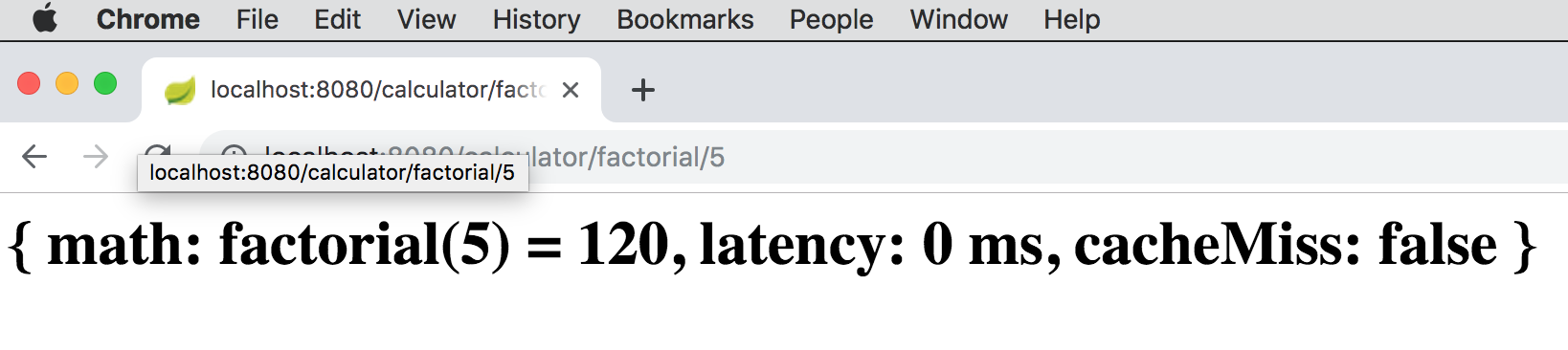
Now, if you hit refresh in your browser, the application will get the result of factorial(5) from the cache since
the result was loaded from the database and put into the cache (read-through) during the first request. Therefore,
we see that the latency drops from 12 ms to 0 ms. However, in both cases, the cacheMiss was false
because the value was found (in the database) without invoking the CalculatorService.factorial(:int) method:
You can play around with the square root operation to see the same effects of Inline Caching.
4. Tests
The Calculator application includes an Integration Test class with tests asserting the behavior demonstrated above in the example. The test class is available here:
5. Summary
Inline Caching is a powerful caching pattern when you have an external, backend data store that doubles as the application’s System of Record (SOR) and you need to keep the cache and database relatively in-sync with each other.
Inline Caching enables immediate read-through and write-through behavior that keeps the cache and database consistent. While the database can serve as a fallback option for priming the cache, the cache will serve an important role in reducing the contention and load on the backend database.
As you have seen in this guide, the configuration of Inline Caching is very simple to do with Spring Boot for Apache Geode (SBDG) when using Spring’s Cache Abstraction along with Apache Geode as the caching provider.