Spring Cloud Data Flow simplifies the development and deployment of applications focused on data processing use-cases. The major concepts of the architecture are Applications, the Data Flow Server, and the target runtime.
Applications are Long lived Stream applications where an unbounded amount of data is consumed or produced via messaging middleware.
Depending on the runtime, applications can be packaged in two ways
- Spring Boot uber-jar that is hosted in a maven repository, file, http or any other Spring resource implementation.
- Docker
The runtime is the place where applications execute. The target runtimes for applications are platforms that you may already be using for other application deployments.
The supported runtimes are
- Cloud Foundry
- Apache YARN
- Kubernetes
- Apache Mesos
- Local Server for development
There is a deployer Service Provider Interface (SPI) that enables you to extend Data Flow to deploy onto other runtimes, for example to support Hashicorp’s Nomad or Docker Swarm. Contributions are welcome!
The component that is responsible for deploying applications to a runtime is the Data Flow Server. There is a Data Flow Server executable jar provided for each of the target runtimes. The Data Flow server is responsible for interpreting
- A stream DSL that describes the logical flow of data through multiple applications.
- A deployment manifest that describes the mapping of applications onto the runtime. For example, to set the initial number of instances, memory requirements, and data partitioning.
As an example, the DSL to describe the flow of data from an http source to an Apache Cassandra sink would be written as “http | cassandra”. These names in the DSL are registered with the Data Flow Server and map onto application artifacts that can be hosted in Maven or Docker repositories. Many source, processor, and sink applications for common use-cases (e.g. jdbc, hdfs, http, router) are provided by the Spring Cloud Data Flow team. The pipe symbol represents the communication between the two applications via messaging middleware. The two messaging middleware brokers that are supported are
- Apache Kafka
- RabbitMQ
In the case of Kafka, when deploying the stream, the Data Flow server is responsible to create the topics that correspond to each pipe symbol and configure each application to produce or consume from the topics so the desired flow of data is achieved.
The interaction of the main components is shown below
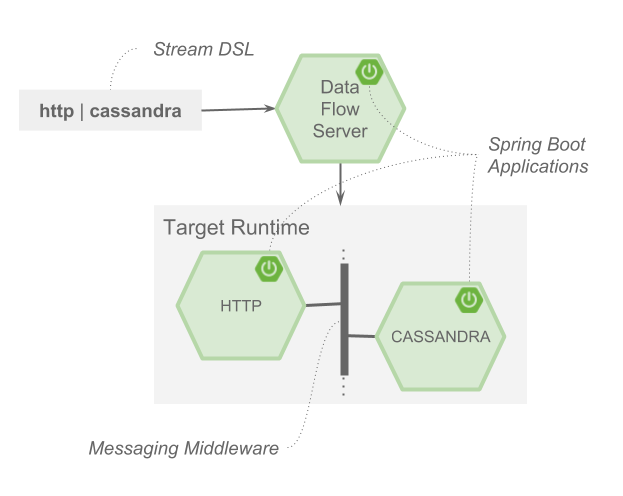
In this diagram a DSL description of a stream is POSTed to the Data Flow Server. Based on the mapping of DSL application names to Maven and Docker artifacts, the http source and cassandra sink application are deployed on the target runtime.