Version 1.3.0.RELEASE
© 2012-2017 Pivotal Software, Inc.
Copies of this document may be made for your own use and for distribution to others, provided that you do not charge any fee for such copies and further provided that each copy contains this Copyright Notice, whether distributed in print or electronically.
Getting started
1. System Requirements
The Spring Cloud Data Flow server deploys streams (collections of long lived applications) and short lived tasks to Cloud Foundry. The server can run on Cloud Foundry itself or on your laptop but it is common to run the server in Cloud Foundry. This section covers the required services in Cloud Foundry that are needed to support the server and deploying streams and tasks.
1.1. Provision a Redis service instance on Cloud Foundry
Use cf marketplace to discover which plans are available to you, depending on the details of your Cloud Foundry setup.
For example when using Pivotal Web Services:
cf create-service rediscloud 30mb redisA redis instance is required for analytics apps, and would typically be bound to such apps when you create an analytics stream using the per-app-binding feature.
1.2. Provision a Rabbit service instance on Cloud Foundry
Use cf marketplace to discover which plans are available to you, depending on the details of your Cloud Foundry setup.
For example when using Pivotal Web Services:
cf create-service cloudamqp lemur rabbitRabbit is typically used as a messaging middleware between streaming apps and would be bound to each deployed app
thanks to the SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_SERVICES setting in Data Flow configuration or SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[pws]_DEPLOYMENT_SERVICES setting in Skipper.
1.3. Provision a MySQL service instance on Cloud Foundry
Use cf marketplace to discover which plans are available to you, depending on the details of your Cloud Foundry setup.
For example when using Pivotal Web Services:
cf create-service cleardb spark my_mysqlAn RDBMS is used to persist Data Flow state, such as stream definitions and deployment ids. It can also be used for tasks to persist execution history.
2. Cloud Foundry Installation
Starting 1.3.x, the Data Flow Server can run in either skipper or classic (non-skipper) modes.
The modes can be specified when starting the Data Flow server using the property spring.cloud.dataflow.features.skipper-enabled.
By default, the classic mode is enabled.
-
Download the Data Flow server and shell applications
wget http://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-server-cloudfoundry/1.3.0.RELEASE/spring-cloud-dataflow-server-cloudfoundry-1.3.0.RELEASE.jar wget http://repo.spring.io/release/org/springframework/cloud/spring-cloud-dataflow-shell/1.3.0.RELEASE/spring-cloud-dataflow-shell-1.3.0.RELEASE.jar -
Optionally, download Skipper if you want the added features of upgrading and rolling back Streams since Data Flow delegates to Skipper for those features.
wget http://repo.spring.io/release/org/springframework/cloud/spring-cloud-skipper-server/1.0.2.RELEASE/spring-cloud-skipper-server-1.0.2.RELEASE.jarPush Skipper to Cloud Foundry only if you want to run Spring Cloud Data Flow server in
skippermode. Here is a sample manifest for Skipper.--- applications: - name: skipper-server host: skipper-server memory: 1G disk_quota: 1G instances: 1 timeout: 180 path: <PATH TO THE DOWNLOADED SKIPPER SERVER UBER-JAR> env: SPRING_APPLICATION_NAME: skipper-server SPRING_CLOUD_SKIPPER_SERVER_ENABLE_LOCAL_PLATFORM: false SPRING_CLOUD_SKIPPER_SERVER_STRATEGIES_HEALTHCHECK.TIMEOUTINMILLIS: 300000 SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[pws]_CONNECTION_URL: https://api.run.pivotal.io SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[pws]_CONNECTION_ORG: {org} SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[pws]_CONNECTION_SPACE: {space} SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[pws]_CONNECTION_DOMAIN: cfapps.io SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[pws]_CONNECTION_USERNAME: {email} SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[pws]_CONNECTION_PASSWORD: {password} SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[pws]_DEPLOYMENT_SERVICES: {middlewareServiceName} SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[pws]_CONNECTION_SKIP_SSL_VALIDATION: false SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[pws]_CONNECTION_STREAM_ENABLE_RANDOM_APP_NAME_PREFIX: falseYou need to fill in {org}, {space}, {email}, {password} and {middlewareServiceName} before running these commands. Once you have the desired config values in the
manifest.yml, you can runcf pushcommand to provision the skipper-server.Only set 'Skip SSL Validation' to true if you’re running on a Cloud Foundry instance using self-signed certs (e.g. in development). Do not use for production. -
Configure and run the Data Flow Server
One of the most important configurations is providing providing credentials to the Cloud Foundry instance so that the server can spawn applications itself. Any Spring Boot compatible configuration mechanism can be used (passing program arguments, editing configuration files before building the application, using Spring Cloud Config, using environment variables, etc.), although some may prove more practicable than others depending how you typically deploy applications to Cloud Foundry.
In this next section we will show how to deploy Data Flow using environment variables or a Cloud Foundry manifest. However, there are some general configuration details you should be aware of in either approach.
2.1. General Configuration
| You must use a unique name for your app; an app with the same name in the same organization will cause your deployment to fail |
| The recommended minimal memory setting for the server is 2G. Also, to push apps to PCF and obtain application property metadata, the server downloads applications to Maven repository hosted on the local disk. While you can specify up to 2G as a typical maximum value for disk space on a PCF installation, this can be increased to 10G. Read the maximum disk quota section for information on how to configure this PCF property. Also, the Data Flow server itself implements a Last Recently Used algorithm to free disk space when it falls below a low water mark value. |
If you are pushing to a space with multiple users, for example on PWS, there may already be a route taken for the
applicaiton name you have chosen. You can use the options --random-route to avoid this when pushing the server application.
|
| By default, the application registry in Spring Cloud Data Flow’s Cloud Foundry server is empty. It is intentionally designed to allow users to have the flexibility of choosing and registering applications, as they find appropriate for the given use-case requirement. Depending on the message-binder of choice, users can register between RabbitMQ or Apache Kafka based maven artifacts. |
| If you need to configure multiple Maven repositories, a proxy, or authorization for a private repository, see Maven Configuration. |
2.2. Deploying using environment variables
The following configuration is for Pivotal Web Services. You need to fill in {org}, {space}, {email} and {password} before running these commands.
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_URL https://api.run.pivotal.io
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_ORG {org}
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SPACE {space}
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_DOMAIN cfapps.io
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_SERVICES rabbit
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_SERVICES my_mysql
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_USERNAME {email}
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_PASSWORD {password}
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SKIP_SSL_VALIDATION false
If you are going to use Skipper to deploy Streams, deploy Skipper first and then configure the uri location of where the Skipper server is running and set the server to be in 'skipper mode
|
cf set-env dataflow-server SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI https://<skipper-host-name>/api cf set-env dataflow-server SPRING_CLOUD_DATAFLOW_FEATURES_SKIPPER_ENABLED true
The Spring Cloud Data Flow server does not have any default remote maven repository configured. This is intentionally designed to provide the flexibility the users, so they can override and point to a remote repository of their choice. The out-of-the-box applications that are supported by Spring Cloud Data Flow are available in Spring’s repository, so if you want to use them, set it as the remote repository as listed below.
cf set-env dataflow-server SPRING_APPLICATION_JSON '{"maven": { "remote-repositories": { "repo1": { "url": "https://repo.spring.io/libs-release" } } } }'where repo1 is the alias name for the remote repository.
| Only set 'Skip SSL Validation' to true if you’re running on a Cloud Foundry instance using self-signed certs (e.g. in development). Do not use for production. |
| If you are deploying in an environment that requires you to sign on using the Pivotal Single Sign-On Service, refer to the section Authentication and Cloud Foundry for information on how to configure the server. |
You can issue now cf push command and reference the Data Flow server .jar.
cf push dataflow-server -b java_buildpack -m 2G -k 2G --no-start -p spring-cloud-dataflow-server-cloudfoundry-1.3.0.RELEASE.jar
cf bind-service dataflow-server redis
cf bind-service dataflow-server my_mysql2.3. Deploying using a Manifest
As an alternative to setting environment variables via cf set-env command, you can curate all the relevant env-var’s
in manifest.yml file and use cf push command to provision the server.
Following is a sample template to provision the server on PCFDev.
---
applications:
- name: data-flow-server
host: data-flow-server
memory: 2G
disk_quota: 2G
instances: 1
path: {PATH TO SERVER UBER-JAR}
env:
SPRING_APPLICATION_NAME: data-flow-server
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_URL: https://api.local.pcfdev.io
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_ORG: pcfdev-org
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SPACE: pcfdev-space
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_DOMAIN: local.pcfdev.io
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_USERNAME: admin
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_PASSWORD: admin
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_SERVICES: rabbit
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_SERVICES: mysql
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SKIP_SSL_VALIDATION: true
SPRING_APPLICATION_JSON {"maven": { "remote-repositories": { "repo1": { "url": "https://repo.spring.io/libs-release"} } } }
services:
- mysql
If you are going to use Skipper to deploy Streams, deploy Skipper first and then configure the uri location of where the Skipper server is running and set the feature toggle to use skipper.
|
applications:
env:
SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI: https://<skipper-host-name>/api
SPRING_CLOUD_DATAFLOW_FEATURES_SKIPPER_ENABLED: trueOnce you’re ready with the relevant properties in this file, you can issue cf push command from the directory where
this file is stored.
3. Local Installation
To run the server application locally, on your laptop or desktop, and target your Cloud Foundry installation, configure the Data Flow server by setting the following environment variables.
export SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_URL=https://api.run.pivotal.io
export SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_ORG={org}
export SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SPACE={space}
export SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_DOMAIN=cfapps.io
export SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_USERNAME={email}
export SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_PASSWORD={password}
export SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SKIP_SSL_VALIDATION=false
export SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_SERVICES=rabbit
# The following is for letting task apps write to their db.
# Note however that when the *server* is running locally, it can't access that db
# task related commands that show executions won't work then
export SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_SERVICES=my_mysqlYou need to fill in {org}, {space}, {email} and {password} before running these commands.
| Only set 'Skip SSL Validation' to true if you’re running on a Cloud Foundry instance using self-signed certs (e.g. in development). Do not use for production. |
If you are going to use Skipper to deploy Streams, deploy Skipper first and then configure the uri location of where the Skipper server is running and enable the Skipper feature toggle..
|
Since Skipper is a Spring Boot application, you can also pass the configuration properties as command line options instead of environment variables. SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_SERVICES becomes --spring.cloud.deployer.cloudfoundry.stream.services.
|
export SKIPPER_CLIENT_HOST https://<skipper-host-name>/api export SPRING_CLOUD_DATAFLOW_FEATURES_SKIPPER_ENABLED true
Now we are ready to start the server application:
java -jar spring-cloud-dataflow-server-cloudfoundry-1.3.0.RELEASE.jar
Of course, all other parameterization options that were available when running the server on Cloud Foundry are
still available. This is particularly true for configuring defaults for applications. Just
substitute cf set-env syntax with export.
|
4. Data Flow Shell
Launching the Data Flow shell requires the appropriate data flow server mode to be specified.
To start the Data Flow Shell for the Data Flow server running in classic mode:
$ java -jar spring-cloud-dataflow-shell-1.3.0.RELEASE.jar5. Deploying Streams
-
Import Apps
By default, the application registry will be empty. If you would like to register all out-of-the-box stream applications built with the RabbitMQ binder in bulk, you can with the following command. For more details, review how to register applications.
dataflow:>app import --uri http://bit.ly/Celsius-SR1-stream-applications-rabbit-mavenThere are two options for deploying Streams. The "traditional" way that Data Flow has always used and a new way that delegates to the Skipper server. Deploying using Skipper will enable you to update and rollback the streams while the traditional way will not.
-
Create Streams without skipper
Create a simple stream with an HTTP source and a log sink.
dataflow:> stream create --name httptest --definition "http | log" --deployYou will need to wait a little while until the apps are actually deployed successfully before posting data. Tail the log file for each application to verify the application has started. Now post some data. The URL will be unique to your deployment, the following is just an example
dataflow:> http post --target http://dataflow-AxwwAhK-httptest-http.cfapps.io --data "hello world"Look to see if
hello worldended up in log files for thelogapplication. -
Create Streams with Skipper This section assumes you have deployed Skipper and configured the Data Flow server’s
SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URIproperty to reference the Skipper server.dataflow:> stream create --name httptest --definition "http | log" dataflow:> stream deploy --name httptest --platformName pwsLook to see if
hello worldended up in log files for thelogapplication.Skipper includes the concept of platforms, so it is important to define the "accounts" based on the project preferences. In the above YAML file, the accounts map to
pwsas the platform. This can be modified, and of course, you can have any number of platform definitions. More details are in Spring Cloud Skipper reference guide.You can read more about the general features of using Skipper to deploy streams in the section Stream Lifecycle with Skipper and how to upgrade a streams in the section Updating a Stream.
6. Deploying Streams using Skipper
We will proceed with the assumption that Spring Cloud Data Flow, Spring Cloud Skipper, RDBMS, and desired messaging middleware is up and running in PWS.
$ cf apps ✭
Getting apps in org ORG / space SPACE as [email protected]...
OK
name requested state instances memory disk urls
skipper-server started 1/1 1G 1G skipper-server.cfapps.io
dataflow-server started 1/1 1G 1G dataflow-server.cfapps.ioStart the Data Flow Shell for the Data Flow server running in skipper mode:
$ java -jar spring-cloud-dataflow-shell-1.3.0.RELEASE.jar --dataflow.mode=skipperIf the Data Flow Server and shell are not running on the same host, point the shell to the Data Flow server URL:
server-unknown:>dataflow config server http://dataflow-server.cfapps.io
Successfully targeted http://dataflow-server.cfapps.io
dataflow:>Alternatively, pass in the command line option --dataflow.uri. The shell’s command line option --help shows what options are available.
Verify the available platforms in Skipper.
dataflow:>stream platform-list
╔═══════╤════════════╤═════════════════════════════════════════════════════════════════════════════════════╗
║ Name │ Type │ Description ║
╠═══════╪════════════╪═════════════════════════════════════════════════════════════════════════════════════╣
║pws │cloudfoundry│org = [scdf-ci], space = [space-sabby], url = [https://api.run.pivotal.io] ║
╚═══════╧════════════╧═════════════════════════════════════════════════════════════════════════════════════╝Let’s start with deploying a stream with the time-source pointing to 1.2.0.RELEASE and log-sink pointing
to 1.1.0.RELEASE. The goal is to rolling upgrade the log-sink application to 1.2.0.RELEASE.
dataflow:>app register --name time --type source --uri maven://org.springframework.cloud.stream.app:time-source-rabbit:1.2.0.RELEASE --force
Successfully registered application 'source:time'
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.1.0.RELEASE --force
Successfully registered application 'sink:log'
dataflow:>app info source:time
Information about source application 'time':
Resource URI: maven://org.springframework.cloud.stream.app:time-source-rabbit:1.2.0.RELEASE
dataflow:>app info sink:log
Information about sink application 'log':
Resource URI: maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.1.0.RELEASE-
Create stream.
Use a unique name, one that might not be taken by another application on PCF/PWS.
dataflow:>stream create ticker-314 --definition "time | log"
Created new stream 'ticker-314'+
-
Deploy stream.
dataflow:>stream deploy ticker-314 --platformName pws Deployment request has been sent for stream 'ticker-314'While deploying the stream, we are supplying
--platformNameand that indicates the platform repository (i.e.,pws) to use when deploying the stream applications via Skipper. -
List apps.
$ cf apps [1h] ✭ Getting apps in org ORG / space SPACE as [email protected]... name requested state instances memory disk urls ticker-314-log-v1 started 1/1 1G 1G ticker-314-log-v1.cfapps.io ticker-314-time-v1 started 1/1 1G 1G ticker-314-time-v1.cfapps.io skipper-server started 1/1 1G 1G skipper-server.cfapps.io dataflow-server started 1/1 1G 1G dataflow-server.cfapps.io -
Verify logs.
$ cf logs ticker-314-log-v1 ... ... 2017-11-20T15:39:43.76-0800 [APP/PROC/WEB/0] OUT 2017-11-20 23:39:43.761 INFO 12 --- [ ticker-314.time.ticker-314-1] log-sink : 11/20/17 23:39:43 2017-11-20T15:39:44.75-0800 [APP/PROC/WEB/0] OUT 2017-11-20 23:39:44.757 INFO 12 --- [ ticker-314.time.ticker-314-1] log-sink : 11/20/17 23:39:44 2017-11-20T15:39:45.75-0800 [APP/PROC/WEB/0] OUT 2017-11-20 23:39:45.757 INFO 12 --- [ ticker-314.time.ticker-314-1] log-sink : 11/20/17 23:39:45 -
Verify the stream history.
dataflow:>stream history --name ticker-314 ╔═══════╤════════════════════════════╤════════╤════════════╤═══════════════╤════════════════╗ ║Version│ Last updated │ Status │Package Name│Package Version│ Description ║ ╠═══════╪════════════════════════════╪════════╪════════════╪═══════════════╪════════════════╣ ║1 │Mon Nov 20 15:34:37 PST 2017│DEPLOYED│ticker-314 │1.0.0 │Install complete║ ╚═══════╧════════════════════════════╧════════╧════════════╧═══════════════╧════════════════╝ -
Verify the package manifest in Skipper. The
log-sinkshould be at 1.1.0.RELEASE.dataflow:>stream manifest --name ticker-314 --- # Source: log.yml apiVersion: skipper.spring.io/v1 kind: SpringCloudDeployerApplication metadata: name: log spec: resource: maven://org.springframework.cloud.stream.app:log-sink-rabbit version: 1.1.0.RELEASE applicationProperties: spring.cloud.dataflow.stream.app.label: log spring.cloud.stream.metrics.properties: spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.* spring.cloud.stream.bindings.applicationMetrics.destination: metrics spring.cloud.dataflow.stream.name: ticker-314 spring.metrics.export.triggers.application.includes: integration** spring.cloud.stream.metrics.key: ticker-314.log.${spring.cloud.application.guid} spring.cloud.stream.bindings.input.group: ticker-314 spring.cloud.dataflow.stream.app.type: sink spring.cloud.stream.bindings.input.destination: ticker-314.time deploymentProperties: spring.cloud.deployer.indexed: true spring.cloud.deployer.group: ticker-314 --- # Source: time.yml apiVersion: skipper.spring.io/v1 kind: SpringCloudDeployerApplication metadata: name: time spec: resource: maven://org.springframework.cloud.stream.app:time-source-rabbit version: 1.2.0.RELEASE applicationProperties: spring.cloud.dataflow.stream.app.label: time spring.cloud.stream.metrics.properties: spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.* spring.cloud.stream.bindings.applicationMetrics.destination: metrics spring.cloud.dataflow.stream.name: ticker-314 spring.metrics.export.triggers.application.includes: integration** spring.cloud.stream.metrics.key: ticker-314.time.${spring.cloud.application.guid} spring.cloud.stream.bindings.output.producer.requiredGroups: ticker-314 spring.cloud.stream.bindings.output.destination: ticker-314.time spring.cloud.dataflow.stream.app.type: source deploymentProperties: spring.cloud.deployer.group: ticker-314 -
Let’s update
log-sinkfrom 1.1.0.RELEASE to 1.2.0.RELEASE. First we need to register the version 1.2.0.RELEASE.dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.1.0.RELEASE --force Successfully registered application 'sink:log'If you execute the
app listcommand for the log sink, you will now see that two versions are registered.dataflow:>app list --id sink:log ╔══════╤═════════╤═════════════════════╤════╗ ║source│processor│ sink │task║ ╠══════╪═════════╪═════════════════════╪════╣ ║ │ │> log-1.1.0.RELEASE <│ ║ ║ │ │log-1.2.0.RELEASE │ ║ ╚══════╧═════════╧═════════════════════╧════╝The greater than and less than signs,
> log-1.1.0.RELEASE <indicate that this is the default version that will be used when matchinglogin the DSL for a stream definition. You can change the default version using the commandapp defaultdataflow:>stream update --name ticker-314 --properties version.log=1.2.0.RELEASE Update request has been sent for stream 'ticker-314' -
List apps.
± cf apps [1h] ✭ Getting apps in org ORG / space SPACE as [email protected]... Getting apps in org scdf-ci / space space-sabby as [email protected]... OK name requested state instances memory disk urls ticker-314-log-v2 started 1/1 1G 1G ticker-314-log-v2.cfapps.io ticker-314-log-v1 stopped 0/1 1G 1G ticker-314-time-v1 started 1/1 1G 1G ticker-314-time-v1.cfapps.io skipper-server started 1/1 1G 1G skipper-server.cfapps.io dataflow-server started 1/1 1G 1G dataflow-server.cfapps.ioNotice that there are two versions of the
log-sinkapplications. Theticker-314-log-v1application instance is going down (route already removed) and the newly spawnedticker-314-log-v2application is bootstrapping. The version number is incremented and the version-number (v2) is included in the new application name. -
Once the new application is up and running, let’s verify the logs.
$ cf logs ticker-314-log-v2 ... ... 2017-11-20T18:38:35.00-0800 [APP/PROC/WEB/0] OUT 2017-11-21 02:38:35.003 INFO 18 --- [ticker-314.time.ticker-314-1] ticker-314-log-v2 : 11/21/17 02:38:34 2017-11-20T18:38:36.00-0800 [APP/PROC/WEB/0] OUT 2017-11-21 02:38:36.004 INFO 18 --- [ticker-314.time.ticker-314-1] ticker-314-log-v2 : 11/21/17 02:38:35 2017-11-20T18:38:37.00-0800 [APP/PROC/WEB/0] OUT 2017-11-21 02:38:37.005 INFO 18 --- [ticker-314.time.ticker-314-1] ticker-314-log-v2 : 11/21/17 02:38:36 -
Let’s look at the updated package manifest persisted in Skipper. We should now be seeing
log-sinkat 1.2.0.RELEASE.skipper:>stream manifest --name ticker-314 --- # Source: log.yml apiVersion: skipper.spring.io/v1 kind: SpringCloudDeployerApplication metadata: name: log spec: resource: maven://org.springframework.cloud.stream.app:log-sink-rabbit version: 1.2.0.RELEASE applicationProperties: spring.cloud.dataflow.stream.app.label: log spring.cloud.stream.metrics.properties: spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.* spring.cloud.stream.bindings.applicationMetrics.destination: metrics spring.cloud.dataflow.stream.name: ticker-314 spring.metrics.export.triggers.application.includes: integration** spring.cloud.stream.metrics.key: ticker-314.log.${spring.cloud.application.guid} spring.cloud.stream.bindings.input.group: ticker-314 spring.cloud.dataflow.stream.app.type: sink spring.cloud.stream.bindings.input.destination: ticker-314.time deploymentProperties: spring.cloud.deployer.indexed: true spring.cloud.deployer.group: ticker-314 spring.cloud.deployer.count: 1 --- # Source: time.yml apiVersion: skipper.spring.io/v1 kind: SpringCloudDeployerApplication metadata: name: time spec: resource: maven://org.springframework.cloud.stream.app:time-source-rabbit version: 1.2.0.RELEASE applicationProperties: spring.cloud.dataflow.stream.app.label: time spring.cloud.stream.metrics.properties: spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.* spring.cloud.stream.bindings.applicationMetrics.destination: metrics spring.cloud.dataflow.stream.name: ticker-314 spring.metrics.export.triggers.application.includes: integration** spring.cloud.stream.metrics.key: ticker-314.time.${spring.cloud.application.guid} spring.cloud.stream.bindings.output.producer.requiredGroups: ticker-314 spring.cloud.stream.bindings.output.destination: ticker-314.time spring.cloud.dataflow.stream.app.type: source deploymentProperties: spring.cloud.deployer.group: ticker-314 -
Verify stream history for the latest updates.
dataflow:>stream history --name ticker-314 ╔═══════╤════════════════════════════╤════════╤════════════╤═══════════════╤════════════════╗ ║Version│ Last updated │ Status │Package Name│Package Version│ Description ║ ╠═══════╪════════════════════════════╪════════╪════════════╪═══════════════╪════════════════╣ ║2 │Mon Nov 20 15:39:37 PST 2017│DEPLOYED│ticker-314 │1.0.0 │Upgrade complete║ ║1 │Mon Nov 20 15:34:37 PST 2017│DELETED │ticker-314 │1.0.0 │Delete complete ║ ╚═══════╧════════════════════════════╧════════╧════════════╧═══════════════╧════════════════╝ -
Rolling-back to the previous version is just a command away.
dataflow:>stream rollback --name ticker-314 Rollback request has been sent for the stream 'ticker-314' ... ... dataflow:>stream history --name ticker-314 ╔═══════╤════════════════════════════╤════════╤════════════╤═══════════════╤════════════════╗ ║Version│ Last updated │ Status │Package Name│Package Version│ Description ║ ╠═══════╪════════════════════════════╪════════╪════════════╪═══════════════╪════════════════╣ ║3 │Mon Nov 20 15:41:37 PST 2017│DEPLOYED│ticker-314 │1.0.0 │Upgrade complete║ ║2 │Mon Nov 20 15:39:37 PST 2017│DELETED │ticker-314 │1.0.0 │Delete complete ║ ║1 │Mon Nov 20 15:34:37 PST 2017│DELETED │ticker-314 │1.0.0 │Delete complete ║ ╚═══════╧════════════════════════════╧════════╧════════════╧═══════════════╧════════════════╝
7. Deploying Tasks
To run a simple task application, you can register all the out-of-the-box task applications with the following command.
dataflow:>app import --uri http://bit.ly/Clark-GA-task-applications-mavenNow create a simple timestamp task.
dataflow:>task create mytask --definition "timestamp --format='yyyy'"Tail the logs, e.g. cf logs mytask and then launch the task in the UI or in the Data Flow Shell
dataflow:>task launch mytaskYou will see the year 2017 printed in the logs. The execution status of the task is stored
in the database and you can retrieve information about the task execution using the shell commands
task execution list and task execution status --id <ID_OF_TASK> or though the Data Flow UI.
| The current underlying PCF task capabilities are considered experimental for PCF version versions less than 1.9. See Feature Togglers for how to disable task support in Data Flow. |
Applications
A selection of pre-built stream and task/batch starter apps for various data integration and processing scenarios to facilitate learning and experimentation. For more details, review how to register applications
Architecture
8. Introduction
Spring Cloud Data Flow simplifies the development and deployment of applications focused on data processing use cases. The major concepts of the architecture are Applications, the Data Flow Server, and the target runtime.
Applications come in two flavors:
-
Long-lived Stream applications where an unbounded amount of data is consumed or produced through messaging middleware.
-
Short-lived Task applications that process a finite set of data and then terminate.
Depending on the runtime, applications can be packaged in two ways:
-
Spring Boot uber-jar that is hosted in a maven repository, file, or HTTP(S).
-
Docker image.
The runtime is the place where applications execute. The target runtimes for applications are platforms that you may already be using for other application deployments.
The supported platforms are:
-
Cloud Foundry
-
Apache YARN
-
Kubernetes
-
Apache Mesos
-
Local Server for development
There is a deployer Service Provider Interface (SPI) that lets you extend Data Flow to deploy onto other runtimes. There are community implementations of Hashicorp’s Nomad and RedHat Openshift. We look forward to working with the community for further contributions!
There are two mutually exclusive options that determine how applications are deployed to the platform.
-
Select a Spring Cloud Data Flow Server executable jar that targets a single platform.
-
Enable the Spring Cloud Data Flow Server to delegate the deployment and runtime status of applications to the Spring Cloud Skipper Server, which has the capability to deploy to multiple platforms.
Selecting the Spring Cloud Skipper option also enables the ability to update and rollback applications in a Stream at runtime.
The Data Flow server is also responsible for:
-
Interpreting and executing a stream DSL that describes the logical flow of data through multiple long-lived applications.
-
Launching a long-lived task application.
-
Interpreting and executing a composed task DSL that describes the logical flow of data through multiple short-lived applications.
-
Applying a deployment manifest that describes the mapping of applications onto the runtime - for example, to set the initial number of instances, memory requirements, and data partitioning.
-
Providing the runtime status of deployed applications.
As an example, the stream DSL to describe the flow of data from an HTTP source to an Apache Cassandra sink would be written using a Unix pipes and filter syntax " http | cassandra ". Each name in the DSL is mapped to an application that can that Maven or Docker repositories. You can also register an application to an http location. Many source, processor, and sink applications for common use cases (such as JDBC, HDFS, HTTP, and router) are provided by the Spring Cloud Data Flow team. The pipe symbol represents the communication between the two applications through messaging middleware. The two messaging middleware brokers that are supported are:
-
Apache Kafka
-
RabbitMQ
In the case of Kafka, when deploying the stream, the Data Flow server is responsible for creating the topics that correspond to each pipe symbol and configure each application to produce or consume from the topics so the desired flow of data is achieved. Similarly for RabbitMQ, exchanges and queues are created as needed to achieve the desired flow.
The interaction of the main components is shown in the following image:
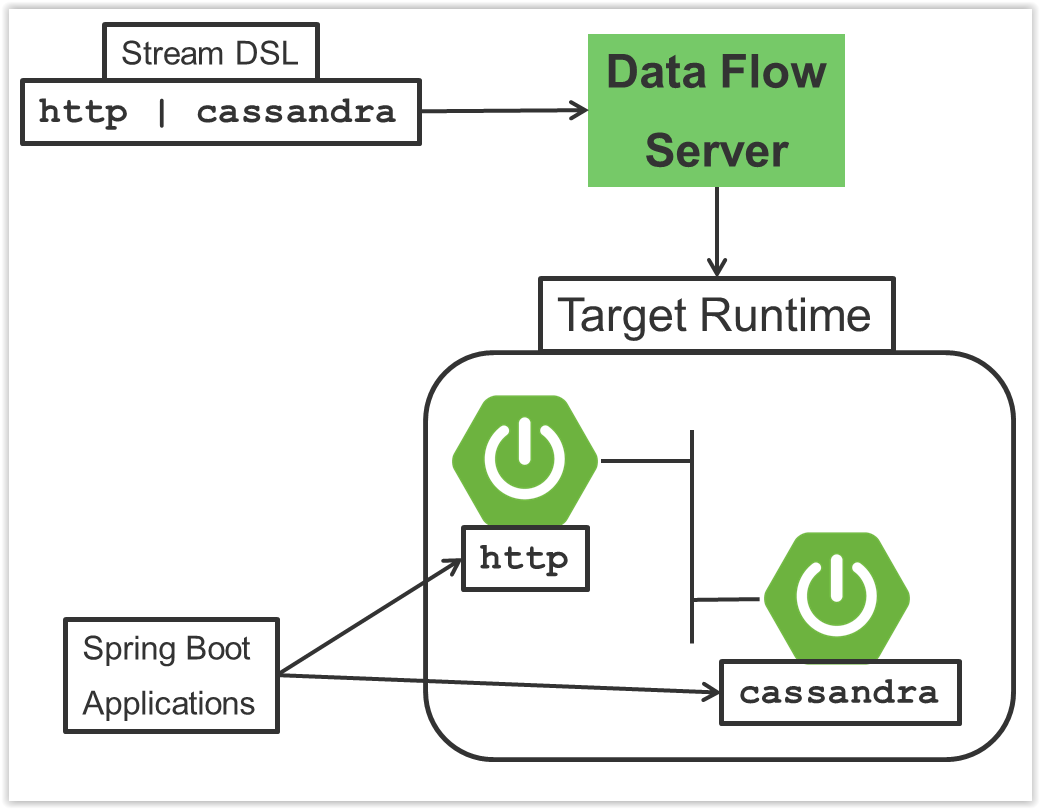
In the preceding diagram, a DSL description of a stream is POSTed to the Data Flow Server. Based on the mapping of DSL application names to Maven and Docker artifacts, the http-source and cassandra-sink applications are deployed on the target runtime. Data that is posted to the HTTP application will then be stored in Cassandra. The Samples Repository shows this use case in full detail.
9. Microservice Architectural Style
The Data Flow Server deploys applications onto the target runtime that conform to the microservice architectural style. For example, a stream represents a high-level application that consists of multiple small microservice applications each running in their own process. Each microservice application can be scaled up or down independently of the other and each has its own versioning lifecycle. Using Data Flow with Skipper enables you to independently upgrade or rollback each application at runtime.
Both Streaming and Task-based microservice applications build upon Spring Boot as the foundational library. This gives all microservice applications functionality such as health checks, security, configurable logging, monitoring, and management functionality, as well as executable JAR packaging.
It is important to emphasize that these microservice applications are 'just apps' that you can run by yourself by using java -jar and passing in appropriate configuration properties. We provide many common microservice applications for common operations so you need not start from scratch when addressing common use cases that build upon the rich ecosystem of Spring Projects, such as Spring Integration, Spring Data, and Spring Batch. Creating your own microservice application is similar to creating other Spring Boot applications. You can start by using the Spring Initializr web site to create the basic scaffolding of either a Stream or Task-based microservice.
In addition to passing the appropriate application properties to each applications, the Data Flow server is responsible for preparing the target platform’s infrastructure so that the applications can be deployed. For example, in Cloud Foundry, it would bind specified services to the applications and execute the cf push command for each application. For Kubernetes, it would create the replication controller, service, and load balancer.
The Data Flow Server helps simplify the deployment of multiple, relatated, applications onto a target runtime, setting up necessary input and output topics, partitions, and metrics functionality. However, one could also opt to deploy each of the microservice applications manually and not use Data Flow at all. This approach might be more appropriate to start out with for small scale deployments, gradually adopting the convenience and consistency of Data Flow as you develop more applications. Manual deployment of Stream- and Task-based microservices is also a useful educational exercise that can help you better understand some of the automatic application configuration and platform targeting steps that the Data Flow Server provides.
9.1. Comparison to Other Platform Architectures
Spring Cloud Data Flow’s architectural style is different than other Stream and Batch processing platforms. For example in Apache Spark, Apache Flink, and Google Cloud Dataflow, applications run on a dedicated compute engine cluster. The nature of the compute engine gives these platforms a richer environment for performing complex calculations on the data as compared to Spring Cloud Data Flow, but it introduces the complexity of another execution environment that is often not needed when creating data-centric applications. That does not mean you cannot do real-time data computations when using Spring Cloud Data Flow. Refer to the section Analytics, which describes the integration of Redis to handle common counting-based use cases. Spring Cloud Stream also supports using Reactive APIs such as Project Reactor and RxJava which can be useful for creating functional style applications that contain time-sliding-window and moving-average functionality. Similarly, Spring Cloud Stream also supports the development of applications in that use the Kafka Streams API.
Apache Storm, Hortonworks DataFlow, and Spring Cloud Data Flow’s predecessor, Spring XD, use a dedicated application execution cluster, unique to each product, that determines where your code should run on the cluster and performs health checks to ensure that long-lived applications are restarted if they fail. Often, framework-specific interfaces are required in order to correctly “plug in” to the cluster’s execution framework.
As we discovered during the evolution of Spring XD, the rise of multiple container frameworks in 2015 made creating our own runtime a duplication of effort. There is no reason to build your own resource management mechanics when there are multiple runtime platforms that offer this functionality already. Taking these considerations into account is what made us shift to the current architecture, where we delegate the execution to popular runtimes, which you may already be using for other purposes. This is an advantage in that it reduces the cognitive distance for creating and managing data-centric applications as many of the same skills used for deploying other end-user/web applications are applicable.
10. Data Flow Server
The Data Flow Server provides the following functionality:
10.1. Endpoints
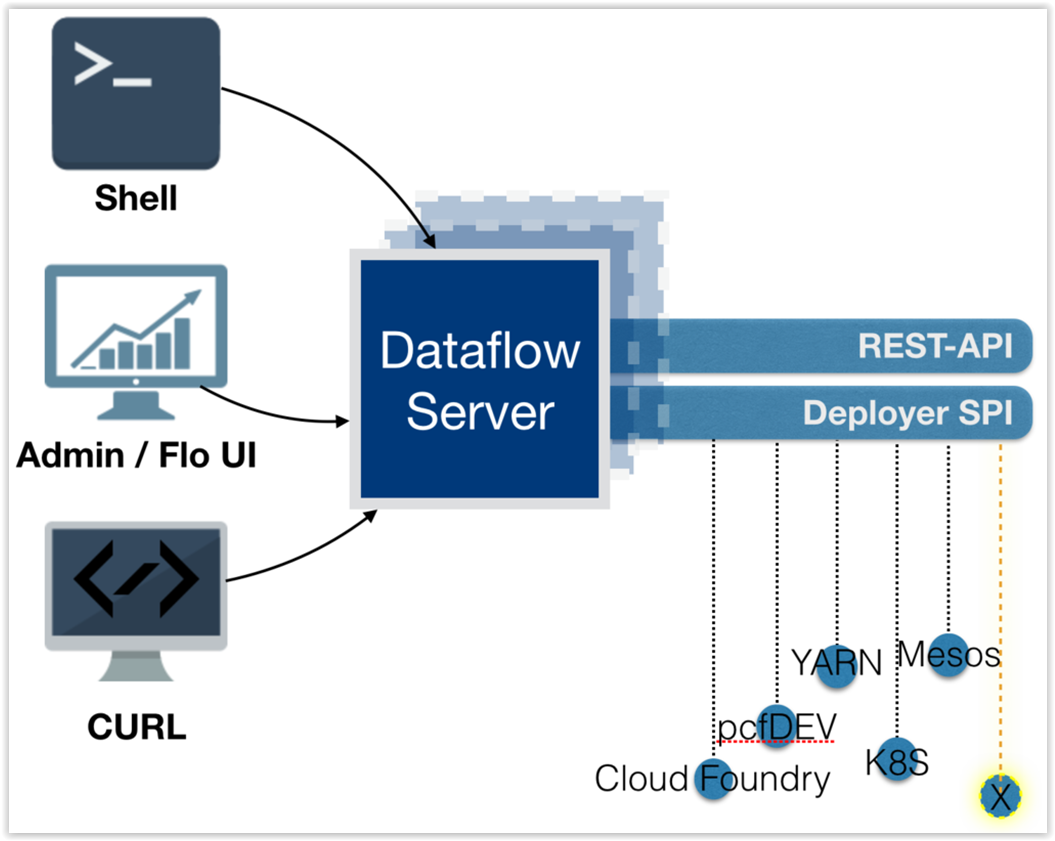
The Data Flow Server uses an embedded servlet container and exposes REST endpoints for creating, deploying, undeploying, and destroying streams and tasks, querying runtime state, analytics, and the like. The Data Flow Server is implemented by using Spring’s MVC framework and the Spring HATEOAS library to create REST representations that follow the HATEOAS principle, as shown in the following image:
10.2. Security
The Data Flow Server executable jars support basic HTTP, LDAP(S), File-based, and OAuth 2.0 authentication to access its endpoints. Refer to the security section for more information.
11. Streams
11.1. Topologies
The Stream DSL describes linear sequences of data flowing through the system. For example, in the stream definition http | transformer | cassandra, each pipe symbol connects the application on the left to the one on the right. Named channels can be used for routing and to fan in/fan out data to multiple messaging destinations.
The concept of a tap can be used to ‘listen’ to the data that is flowing across any of the pipe symbols. "Taps" are just other streams that use an input any one of the "pipes" in a target stream and have an independent life cycle from the target stream.
11.2. Concurrency
For an application that consumes events, Spring Cloud Stream exposes a concurrency setting that controls the size of a thread pool used for dispatching incoming messages. See the Consumer properties documentation for more information.
11.3. Partitioning
A common pattern in stream processing is to partition the data as it moves from one application to the next. Partitioning is a critical concept in stateful processing, for either performance or consistency reasons, to ensure that all related data is processed together. For example, in a time-windowed average calculation example, it is important that all measurements from any given sensor are processed by the same application instance. Alternatively, you may want to cache some data related to the incoming events so that it can be enriched without making a remote procedure call to retrieve the related data.
Spring Cloud Data Flow supports partitioning by configuring Spring Cloud Stream’s output and input bindings. Spring Cloud Stream provides a common abstraction for implementing partitioned processing use cases in a uniform fashion across different types of middleware. Partitioning can thus be used whether the broker itself is naturally partitioned (for example, Kafka topics) or not (RabbitMQ). The following image shows how data could be partitioned into two buckets, such that each instance of the average processor application consumes a unique set of data.
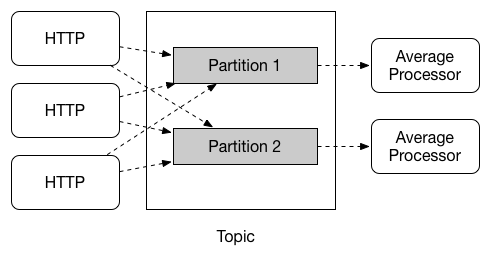
To use a simple partitioning strategy in Spring Cloud Data Flow, you need only set the instance count for each application in the stream and a partitionKeyExpression producer property when deploying the stream. The partitionKeyExpression identifies what part of the message is used as the key to partition data in the underlying middleware. An ingest stream can be defined as http | averageprocessor | cassandra. (Note that the Cassandra sink is not shown in the diagram above.) Suppose the payload being sent to the HTTP source was in JSON format and had a field called sensorId. For example, consider the case of deploying the stream with the shell command stream deploy ingest --propertiesFile ingestStream.properties where the contents of the ingestStream.properties file are as follows:
deployer.http.count=3
deployer.averageprocessor.count=2
app.http.producer.partitionKeyExpression=payload.sensorIdThe result is to deploy the stream such that all the input and output destinations are configured for data to flow through the applications but also ensure that a unique set of data is always delivered to each averageprocessor instance. In this case, the default algorithm is to evaluate payload.sensorId % partitionCount where the partitionCount is the application count in the case of RabbitMQ and the partition count of the topic in the case of Kafka.
Please refer to Passing Stream Partition Properties for additional strategies to partition streams during deployment and how they map onto the underlying Spring Cloud Stream Partitioning properties.
Also note that you cannot currently scale partitioned streams. Read Scaling at Runtime for more information.
11.4. Message Delivery Guarantees
Streams are composed of applications that use the Spring Cloud Stream library as the basis for communicating with the underlying messaging middleware product. Spring Cloud Stream also provides an opinionated configuration of middleware from several vendors, in particular providing persistent publish-subscribe semantics.
The Binder abstraction in Spring Cloud Stream is what connects the application to the middleware. There are several configuration properties of the binder that are portable across all binder implementations and some that are specific to the middleware.
For consumer applications, there is a retry policy for exceptions generated during message handling. The retry policy is configured by using the common consumer properties maxAttempts, backOffInitialInterval, backOffMaxInterval, and backOffMultiplier. The default values of these properties retry the callback method invocation 3 times and wait one second for the first retry. A backoff multiplier of 2 is used for the second and third attempts.
When the number of retry attempts has exceeded the maxAttempts value, the exception and the failed message become the payload of a message and are sent to the application’s error channel. By default, the default message handler for this error channel logs the message. You can change the default behavior in your application by creating your own message handler that subscribes to the error channel.
Spring Cloud Stream also supports a configuration option for both Kafka and RabbitMQ binder implementations that sends the failed message and stack trace to a dead letter queue. The dead letter queue is a destination and its nature depends on the messaging middleware (for example, in the case of Kafka, it is a dedicated topic). To enable this for RabbitMQ set the republishtoDlq and autoBindDlq consumer properties and the autoBindDlq producer property to true when deploying the stream. To always apply these producer and consumer properties when deploying streams, configure them as common application properties when starting the Data Flow server.
Additional messaging delivery guarantees are those provided by the underlying messaging middleware that is chosen for the application for both producing and consuming applications. Refer to the Kafka Consumer and Producer and Rabbit Consumer and Producer documentation for more details. You can find extensive declarative support for all the native QOS options.
12. Stream Programming Models
While Spring Boot provides the foundation for creating DevOps-friendly microservice applications, other libraries in the Spring ecosystem help create Stream-based microservice applications. The most important of these is Spring Cloud Stream.
The essence of the Spring Cloud Stream programming model is to provide an easy way to describe multiple inputs and outputs of an application that communicate over messaging middleware. These input and outputs map onto Kafka topics or Rabbit exchanges and queues. Common application configuration for a Source that generates data, a Processor that consumes and produces data, and a Sink that consumes data is provided as part of the library.
12.1. Imperative Programming Model
Spring Cloud Stream is most closely integrated with Spring Integration’s imperative "one event at a time" programming model. This means you write code that handles a single event callback, as shown in the following example,
@EnableBinding(Sink.class)
public class LoggingSink {
@StreamListener(Sink.INPUT)
public void log(String message) {
System.out.println(message);
}
}In this case, the String payload of a message coming on the input channel is handed to the log method. The @EnableBinding annotation is used to tie the input channel to the external middleware.
12.2. Functional Programming Model
However, Spring Cloud Stream can support other programming styles, such as reactive APIs, where incoming and outgoing data is handled as continuous data flows and how each individual message should be handled is defined. With many reactive AOIs, you can also use operators that describe functional transformations from inbound to outbound data flows. Here is an example:
@EnableBinding(Processor.class)
public static class UppercaseTransformer {
@StreamListener
@Output(Processor.OUTPUT)
public Flux<String> receive(@Input(Processor.INPUT) Flux<String> input) {
return input.map(s -> s.toUpperCase());
}
}13. Application Versioning
Application versioning within a Stream is now supported when using Data Flow together with Skipper. You can update application and deployment properties as well as the version of the application. Rolling back to a previous application version is also supported.
14. Task Programming Mdoel
The Spring Cloud Task programming model provides:
-
Persistence of the Task’s lifecycle events and exit code status.
-
Lifecycle hooks to execute code before or after a task execution.
-
The ability to emit task events to a stream (as a source) during the task lifecycle.
-
Integration with Spring Batch Jobs.
See the Tasks section for more information.
15. Analytics
Spring Cloud Data Flow is aware of certain Sink applications that write counter data to Redis and provides a REST endpoint to read counter data. The types of counters supported are as follows:
-
Counter: Counts the number of messages it receives, optionally storing counts in a separate store such as Redis.
-
Field Value Counter: Counts occurrences of unique values for a named field in a message payload.
-
Aggregate Counter: Stores total counts but also retains the total count values for each minute, hour, day, and month.
Note that the timestamp used in the aggregate counter can come from a field in the message itself so that out-of-order messages are properly accounted.
16. Runtime
The Data Flow Server relies on the target platform for the following runtime functionality:
16.1. Fault Tolerance
The target runtimes supported by Data Flow all have the ability to restart a long-lived application. Spring Cloud Data Flow sets up health probes are required by the runtime environment when deploying the application. You also have the ability to customize the health probes.
The collective state of all applications that make up the stream is used to determine the state of the stream. If an application fails, the state of the stream changes from ‘deployed’ to ‘partial’.
16.2. Resource Management
Each target runtime lets you control the amount of memory, disk, and CPU allocated to each application. These are passed as properties in the deployment manifest by using key names that are unique to each runtime. Refer to each platform’s server documentation for more information.
16.3. Scaling at Runtime
When deploying a stream, you can set the instance count for each individual application that makes up the stream. Once the stream is deployed, each target runtime lets you control the target number of instances for each individual application. Using the APIs, UIs, or command line tools for each runtime, you can scale up or down the number of instances as required.
Currently, scaling at runtime is not supported with the Kafka binder, as well as with partitioned streams, for which the suggested workaround is redeploying the stream with an updated number of instances. Both cases require a static consumer to be set up, based on information about the total instance count and current instance index.
Server Configuration
In this section you will learn how to configure Spring Cloud Data Flow server’s features such as the relational database to use and security. You will also learn how to configure Spring Cloud Data Flow shell’s features.
17. Feature Toggles
Data Flow server offers specific set of features that can be enabled/disabled when launching. These features include all the lifecycle operations, REST endpoints (server, client implementations including Shell and the UI) for:
-
Streams
-
Tasks
-
Analytics
One can enable, disable these features by setting the following boolean properties when launching the Data Flow server:
-
spring.cloud.dataflow.features.streams-enabled -
spring.cloud.dataflow.features.tasks-enabled -
spring.cloud.dataflow.features.analytics-enabled
By default, all the features are enabled.
Note: Since analytics feature is enabled by default, the Data Flow server is expected to have a valid Redis store available as analytic repository as we provide a default implementation of analytics based on Redis.
This also means that the Data Flow server’s health depends on the redis store availability as well.
If you do not want to enabled HTTP endpoints to read analytics data written to Redis, then disable the analytics feature using the property mentioned above.
The REST endpoint /features provides information on the features enabled/disabled.
18. Deployer Properties
You can also set other optional properties that alter the way Spring Cloud Data Flow will deploy stream and task apps to Cloud Foundry:
-
The default memory and disk sizes for a deployed application can be configured. By default they are 1024 MB memory and 1024 MB disk. To change these, as an example to 512 and 2048 respectively, use
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_MEMORY 512 cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_DISK 2048 -
The default number of instances to deploy is set to 1, but can be overridden using
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_INSTANCES 1 -
You can set the buildpack that will be used to deploy each application. For example, to use the Java offline buildback, set the following environment variable
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_BUILDPACK java_buildpack_offline -
The health check mechanism used by Cloud Foundry to assert if apps are running can be customized using the environment variable
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_HEALTH_CHECK. Current supported options arehttp(the default),portandnone.There are also environment variables to specify the the http based health check endpoint and timeout,
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_HEALTH_CHECK_ENDPOINTandSPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_HEALTH_CHECK_TIMEOUT. These default to/health(the Spring Boot default location` and120seconds. -
You can also specify deployment properties using the dsl. For instance if you want to set the allocated memory for the
httpapp to 512m and also bind a mysql service to thejdbcapplication.
dataflow:> stream create --name mysqlstream --definition "http | jdbc --tableName=names --columns=name"
dataflow:> stream deploy --name mysqlstream --properties "deployer.http.memory=512, deployer.jdbc.cloudfoundry.services=mysql"|
These settings can be configured separately for stream and task apps. To alter settings for tasks, simply
substitute |
All the properties mentioned above are @ConfigurationProperties of the
Cloud Foundry deployer. See CloudFoundryDeploymentProperties.java for more information.
|
19. Application Names and Prefixes
To help avoid clashes with routes across spaces in Cloud Foundry, a naming strategy to provide a random prefix to a
deployed application is available and is enabled by default. The default configurations
are overridable and the respective properties can be set via cf set-env commands.
For instance, if you’d like to disable the randomization, you can override it through:
cf set-env dataflow-server SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_ENABLE_RANDOM_APP_NAME_PREFIX false20. Custom Routes
As an alternative to random name, or to get even more control over the hostname used by the deployed apps, one can use custom deployment properties, as such:
dataflow:>stream create foo --definition "http | log"
sdataflow:>stream deploy foo --properties "deployer.http.cloudfoundry.domain=mydomain.com,
deployer.http.cloudfoundry.host=myhost,
deployer.http.cloudfoundry.route-path=my-path"This would result in the http app being bound to the URL myhost.mydomain.com/my-path. Note that this is an
example showing all customization options available. One can of course only leverage one or two out of the three.
21. Docker Applications
Starting with version 1.2, it is possible to register and deploy Docker based apps as part of streams and tasks using Data Flow for Cloud Foundry.
If you are using Spring Boot and RabbitMQ based Docker images you can provide a common deployment property
to facilitate the apps binding to the RabbitMQ service. Assuming your RabbitMQ service is named rabbit you can provide the following:
cf set-env dataflow-server SPRING_APPLICATION_JSON '{"spring.cloud.dataflow.applicationProperties.stream.spring.rabbitmq.addresses": "${vcap.services.rabbit.credentials.protocols.amqp.uris}"}'For Spring Cloud Task apps, something similar to the following could be used, if using a database service instance named mysql:
cf set-env SPRING_DATASOURCE_URL '${vcap.services.mysql.credentials.jdbcUrl}'
cf set-env SPRING_DATASOURCE_USERNAME '${vcap.services.mysql.credentials.username}'
cf set-env SPRING_DATASOURCE_PASSWORD '${vcap.services.mysql.credentials.password}'
cf set-env SPRING_DATASOURCE_DRIVER_CLASS_NAME 'org.mariadb.jdbc.Driver'For non-Java or non-Boot apps, your Docker app would have to parse the VCAP_SERVICES variable in order to bind to any available services.
|
Passing application properties
When using non-boot apps, chances are that you want the application properties passed to your app using traditional
environment variables, as opposed to using the special |
22. Application Level Service Bindings
When deploying streams in Cloud Foundry, you can take advantage of application specific service bindings, so not all services are globally configured for all the apps orchestrated by Spring Cloud Data Flow.
For instance, if you’d like to provide mysql service binding only for the jdbc application in the following stream
definition, you can pass the service binding as a deployment property.
dataflow:>stream create --name httptojdbc --definition "http | jdbc"
dataflow:>stream deploy --name httptojdbc --properties "deployer.jdbc.cloudfoundry.services=mysqlService"Where, mysqlService is the name of the service specifically only bound to jdbc application and the http
application wouldn’t get the binding by this method.
If you have more than one service to bind, they can be passed as comma separated items
(eg: deployer.jdbc.cloudfoundry.services=mysqlService,someService).
23. User Provided Services
In addition to marketplace services, Cloud Foundry supports User Provided Services (UPS). Throughout this reference manual, regular services have been mentioned, but there is nothing precluding the use of UPSs as well, whether for use as the messaging middleware (e.g. if you’d like to use an external Apache Kafka installation) or for ad hoc usage by some of the stream apps (e.g. an Oracle Database).
Let’s review an example of extracting and supplying the connection credentials from an UPS.
-
A sample UPS setup for Apache Kafka.
cf create-user-provided-service kafkacups -p '{”brokers":"HOST:PORT","zkNodes":"HOST:PORT"}'-
The UPS credentials will be wrapped within
VCAP_SERVICESand it can be supplied directly in the stream definition like the following.
stream create fooz --definition "time | log"
stream deploy fooz --properties "app.time.spring.cloud.stream.kafka.binder.brokers=${vcap.services.kafkacups.credentials.brokers},app.time.spring.cloud.stream.kafka.binder.zkNodes=${vcap.services.kafkacups.credentials.zkNodes},app.log.spring.cloud.stream.kafka.binder.brokers=${vcap.services.kafkacups.credentials.brokers},app.log.spring.cloud.stream.kafka.binder.zkNodes=${vcap.services.kafkacups.credentials.zkNodes}"24. Maximum Disk Quota
By default, every application in Cloud Foundry starts with 1G disk quota and this can be adjusted to a default maximum of 2G. The default maximum can also be overridden up to 10G via Pivotal Cloud Foundry’s (PCF) Ops Manager GUI.
This configuration is relevant for Spring Cloud Data Flow because every stream and task deployment is composed of applications (typically Spring Boot uber-jar’s) and those applications are resolved from a remote maven repository. After resolution, the application artifacts are downloaded to the local Maven Repository for caching/reuse. With this happening in the background, there is a possibility the default disk quota (1G) fills up rapidly; especially, when we are experimenting with streams that are made up of unique applications. In order to overcome this disk limitation and depending on your scaling requirements,you may want to change the default maximum from 2G to 10G. Let’s review the steps to change the default maximum disk quota allocation.
24.1. PCF’s Operations Manager
From PCF’s Ops Manager, Select "Pivotal Elastic Runtime" tile and navigate to "Application Developer Controls" tab. Change the "Maximum Disk Quota per App (MB)" setting from 2048 to 10240 (10G). Save the disk quota update and hit "Apply Changes" to complete the configuration override.
25. Scale Application
Once the disk quota change is applied successfully and assuming you’ve a running application,
you may scale the application with a new disk_limit through CF CLI.
→ cf scale dataflow-server -k 10GB
Scaling app dataflow-server in org ORG / space SPACE as user...
OK
....
....
....
....
state since cpu memory disk details
#0 running 2016-10-31 03:07:23 PM 1.8% 497.9M of 1.1G 193.9M of 10G→ cf apps
Getting apps in org ORG / space SPACE as user...
OK
name requested state instances memory disk urls
dataflow-server started 1/1 1.1G 10G dataflow-server.apps.io25.1. Configuring target free disk percentage
Even when configuring the Data Flow server to use 10G of space, there is the possibility of exhausting the available space on the local disk. The server implements a least recently used (LRU) algorithm that will remove maven artifacts from the local maven repository. This is configured using the following configuration property, the default value is 25.
# The low water mark percentage, expressed as in integer between 0 and 100, that triggers cleanup of
# the local maven repository
# (for setting env var use SPRING_CLOUD_DATAFLOW_SERVER_CLOUDFOUNDRY_FREE_DISK_SPACE_PERCENTAGE)
spring.cloud.dataflow.server.cloudfoundry.freeDiskSpacePercentage=2526. Application Resolution Alternatives
Though we highly recommend using Maven Repository for application resolution and registration in Cloud Foundry, there might be situations where an alternative approach would make sense. Following alternative options could come handy for resolving applications when running on Cloud Foundry.
-
With the help of Spring Boot, we can serve static content in Cloud Foundry. A simple Spring Boot application can bundle all the required stream/task applications and by having it run on Cloud Foundry, the static application can then serve the Über-jar’s. From the Shell, you can, for example, register the app with the name
http-source.jarvia--uri=http://<Route-To-StaticApp>/http-source.jar. -
The Über-jar’s can be hosted on any external server that’s reachable via HTTP. They can be resolved from raw GitHub URIs as well. From the Shell, you can, for example, register the app with the name
http-source.jarvia--uri=http://<Raw_GitHub_URI>/http-source.jar. -
Static Buildpack support in Cloud Foundry is another option. A similar HTTP resolution will work on this model, too.
-
Volume Services is another great option. The required Über-jar’s can be hosted in an external file-system and with the help of volume-services, you can, for example, register the app with the name
http-source.jarvia--uri=file://<Path-To-FileSystem>/http-source.jar.
27. Security
By default, the Data Flow server is unsecured and runs on an unencrypted HTTP connection. You can secure your REST endpoints,
as well as the Data Flow Dashboard by enabling HTTPS and requiring clients to authenticate.
For more details about securing the
REST endpoints and configuring to authenticate against an OAUTH backend (i.e: UAA/SSO running on Cloud Foundry), please
review the security section from the core reference guide. The security configurations can be configured in dataflow-server.yml or passed as environment variables through cf set-env commands.
27.1. Authentication and Cloud Foundry
Spring Cloud Data Flow can either integrate with Pivotal Single Sign-On Service (E.g. on PWS) or Cloud Foundry User Account and Authentication (UAA) Server.
27.1.1. Pivotal Single Sign-On Service
When deploying Spring Cloud Data Flow to Cloud Foundry you can simply bind the application to the Pivotal Single Sign-On Service. By doing so, Spring Cloud Data Flow takes advantage of the Spring Cloud Single Sign-On Connector, which provides Cloud Foundry specific auto-configuration support for OAuth 2.0.
Simply bind the Pivotal Single Sign-On Service to your Data Flow Server app and Single Sign-On (SSO) via OAuth2 will be enabled by default.
Authorization is similarly support as for non-Cloud Foundry security scenarios. Please refer to the security section from the core Data Flow reference guide.
As the provisioning of roles can vary widely across environments, we assign by default all Spring Cloud Data Flow roles to users.
This can be customized by providing your own AuthoritiesExtractor.
One possible approach to set the custom AuthoritiesExtractor on the UserInfoTokenServices could be this:
public class MyUserInfoTokenServicesPostProcessor
implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) {
if (bean instanceof UserInfoTokenServices) {
final UserInfoTokenServices userInfoTokenServices = (UserInfoTokenServices) bean;
userInfoTokenServices.setAuthoritiesExtractor(ctx.getBean(AuthoritiesExtractor.class));
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
return bean;
}
}And you simply declare it in your configuration class:
@Bean
public BeanPostProcessor myUserInfoTokenServicesPostProcessor() {
BeanPostProcessor postProcessor = new MyUserInfoTokenServicesPostProcessor();
return postProcessor;
}27.1.2. Cloud Foundry UAA
The availability of this option depends on the used Cloud Foundry environment.
In order to provide UAA integration, you have to manually provide the necessary
OAuth2 configuration properties, for instance via the SPRING_APPLICATION_JSON
property.
{
"security.oauth2.client.client-id": "scdf",
"security.oauth2.client.client-secret": "scdf-secret",
"security.oauth2.client.access-token-uri": "https://login.cf.myhost.com/oauth/token",
"security.oauth2.client.user-authorization-uri": "https://login.cf.myhost.com/oauth/authorize",
"security.oauth2.resource.user-info-uri": "https://login.cf.myhost.com/userinfo"
}By default, the property spring.cloud.dataflow.security.cf-use-uaa is set to true. This property will activate a special
AuthoritiesExtractor CloudFoundryDataflowAuthoritiesExtractor.
If CloudFoundry UAA is not used, then make sure to set spring.cloud.dataflow.security.cf-use-uaa to false.
Under the covers this AuthoritiesExtractor will call out to the Cloud Foundry Apps API and ensure that users are in fact Space Developers.
If the authenticated user is verified as Space Developer, all roles will be assigned, otherwise no roles whatsoever will be assigned. In that case you may see the following Dashboard screen:

28. Configuration Reference
The following pieces of configuration must be provided. These are Spring Boot @ConfigurationProperties so you can set
them as environment variables or by any other means that Spring Boot supports. Here is a listing in environment
variable format as that is an easy way to get started configuring Boot applications in Cloud Foundry.
# Default values cited after the equal sign.
# Example values, typical for Pivotal Web Services, cited as a comment
# url of the CF API (used when using cf login -a for example), e.g. https://api.run.pivotal.io
# (for setting env var use SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_URL)
spring.cloud.deployer.cloudfoundry.url=
# name of the organization that owns the space above, e.g. youruser-org
# (For Setting Env var use SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_ORG)
spring.cloud.deployer.cloudfoundry.org=
# name of the space into which modules will be deployed, e.g. development
# (for setting env var use SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SPACE)
spring.cloud.deployer.cloudfoundry.space=
# the root domain to use when mapping routes, e.g. cfapps.io
# (for setting env var use SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_DOMAIN)
spring.cloud.deployer.cloudfoundry.domain=
# username and password of the user to use to create apps
# (for setting env var use SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_USERNAME and SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_PASSWORD)
spring.cloud.deployer.cloudfoundry.username=
spring.cloud.deployer.cloudfoundry.password=
# Whether to allow self-signed certificates during SSL validation
# (for setting env var use SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SKIP_SSL_VALIDATION)
spring.cloud.deployer.cloudfoundry.skipSslValidation=false
# Comma separated set of service instance names to bind to every stream app deployed.
# Amongst other things, this should include a service that will be used
# for Spring Cloud Stream binding, e.g. rabbit
# (for setting env var use SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_SERVICES)
spring.cloud.deployer.cloudfoundry.stream.services=
# Health check type to use for stream apps. Accepts 'none' and 'port'
spring.cloud.deployer.cloudfoundry.stream.health-check=
# Comma separated set of service instance names to bind to every task app deployed.
# Amongst other things, this should include an RDBMS service that will be used
# for Spring Cloud Task execution reporting, e.g. my_mysql
# (for setting env var use SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_SERVICES)
spring.cloud.deployer.cloudfoundry.task.services=
# Timeout to use, in seconds, when doing blocking API calls to Cloud Foundry.
# (for setting env var use SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_API_TIMEOUT
# and SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_API_TIMEOUT)
spring.cloud.deployer.cloudfoundry.stream.apiTimeout=360
spring.cloud.deployer.cloudfoundry.task.apiTimeout=360
# Timeout to use, in milliseconds, when querying the Cloud Foundry API to compute app status.
# (for setting env var use SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_STATUS_TIMEOUT
# and SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_STATUS_TIMEOUT)
spring.cloud.deployer.cloudfoundry.stream.statusTimeout=5000
spring.cloud.deployer.cloudfoundry.task.statusTimeout=5000Note that you can set the following properties spring.cloud.deployer.cloudfoundry.services,
spring.cloud.deployer.cloudfoundry.buildpack or the Spring Cloud Deployer standard
spring.cloud.deployer.memory and spring.cloud.deployer.disk
as part of an individual deployment request by using the deployer.<app-name> shortcut. For example
>stream create --name ticktock --definition "time | log"
>stream deploy --name ticktock --properties "deployer.time.memory=2g"will deploy the time source with 2048MB of memory, while the log sink will use the default 1024MB.
29. Debugging
If you want to get better insights into what is happening when your streams and tasks are being deployed, you may want to turn on the following features:
-
Reactor "stacktraces", showing which operators were involved before an error occurred. This is helpful as the deployer relies on project reactor and regular stacktraces may not always allow understanding the flow before an error happened. Note that this comes with a performance penalty, so is disabled by default.
spring.cloud.dataflow.server.cloudfoundry.debugReactor = true -
Deployer and Cloud Foundry client library request/response logs. This allows seeing detailed conversation between the Data Flow server and the Cloud Foundry Cloud Controller.
logging.level.cloudfoundry-client = DEBUG
30. Spring Cloud Config Server
Spring Cloud Config Server can be used to centralize configuration properties for Spring Boot applications. Likewise, both Spring Cloud Data Flow and the applications orchestrated using Spring Cloud Data Flow can be integrated with config-server to leverage the same capabilities.
30.1. Stream, Task, and Spring Cloud Config Server
Similar to Spring Cloud Data Flow server, it is also possible to configure both the stream and task applications to resolve the centralized properties from config-server.
Setting the property spring.cloud.config.uri for the deployed applications is a common way to bind to the Config Server.
See the Spring Cloud Config Client reference guide for more information.
Since this property is likely to be used across all applications deployed by the Data Flow server, the Data Flow Server’s property spring.cloud.dataflow.applicationProperties.stream for stream apps and spring.cloud.dataflow.applicationProperties.task for task apps can be used to pass the uri of the Config Server to each deployed stream or task application. Refer to the section on Common application properties for more information.
If you’re using applications from the App Starters project, note that these applications already embed the spring-cloud-services-starter-config-client dependency.
If you’re building your application from scratch and want to add the client side support for config server, simply add a reference dependency reference to the config server client library. A maven example snippet follows:
...
<dependency>
<groupId>io.pivotal.spring.cloud</groupId>
<artifactId>spring-cloud-services-starter-config-client</artifactId>
<version>CONFIG_CLIENT_VERSION</version>
</dependency>
...Where, CONFIG_CLIENT_VERSION can be the latest release of Spring Cloud Config Server
client for Pivotal Cloud Foundry.
You will observe a WARN logging message if the application that uses this library can not connect to the config
server when the applicaiton starts and whenever the /health endpoint is accessed.
You can disable the client library if you know that you are not using config server functionality by setting the
environment variable SPRING_CLOUD_CONFIG_ENABLED=false.
Another, more drastic option, is to disable the platform health check with the environment variable
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_HEALTH_CHECK=none
|
30.2. Sample Manifest Template
Following manifest.yml template includes the required env-var’s for the Spring Cloud Data Flow server and deployed
apps/tasks to successfully run on Cloud Foundry and automatically resolve centralized properties from my-config-server
at the runtime.
---
applications:
- name: data-flow-server
host: data-flow-server
memory: 2G
disk_quota: 2G
instances: 1
path: {PATH TO SERVER UBER-JAR}
env:
SPRING_APPLICATION_NAME: data-flow-server
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_URL: https://api.local.pcfdev.io
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_ORG: pcfdev-org
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SPACE: pcfdev-space
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_DOMAIN: local.pcfdev.io
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_USERNAME: admin
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_PASSWORD: admin
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_SERVICES: rabbit,my-config-server
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_SERVICES: mysql,my-config-server
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SKIP_SSL_VALIDATION: true
SPRING_APPLICATION_JSON: '{"maven": { "remote-repositories": { "repo1": { "url": "https://repo.spring.io/libs-release"} } } }'
services:
- mysql
- my-config-serverWhere, my-config-server is the name of the Spring Cloud Config Service instance running on Cloud Foundry. By binding the
service to both Spring Cloud Data Flow server as well as all the Spring Cloud Stream and Spring Cloud Task applications
respectively, we can now resolve centralized properties backed by this service.
30.3. Self-signed SSL Certificate and Spring Cloud Config Server
Often, in a development environment, we may not have a valid certificate to enable SSL communication between clients and the backend services. However, the config-server for Pivotal Cloud Foundry uses HTTPS for all client-to-service communication, so it is necessary to add a self-signed SSL certificate in environments with no valid certificates.
Using the same manifest.yml template listed in the previous section, for the server, we can provide the self-signed
SSL certificate via: TRUST_CERTS: <API_ENDPOINT>.
However, the deployed applications also require TRUST_CERTS as a flat env-var (as opposed to being wrapped inside
SPRING_APPLICATION_JSON), so we will have to instruct the server with yet another set of tokens SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_USE_SPRING_APPLICATION_JSON: false
and SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_USE_SPRING_APPLICATION_JSON: false for stream and task applications
respectively. With this setup, the applications will receive their application properties as regular environment variables
Let’s review the updated manifest.yml with the required changes. Both the Data Flow server and deployed applications
would get their config from the my-config-server Cloud Config server (deployed as a Cloud Foundry service)
---
applications:
- name: test-server
host: test-server
memory: 1G
disk_quota: 1G
instances: 1
path: spring-cloud-dataflow-server-cloudfoundry-VERSION.jar
env:
SPRING_APPLICATION_NAME: test-server
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_URL: <URL>
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_ORG: <ORG>
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_SPACE: <SPACE>
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_DOMAIN: <DOMAIN>
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_USERNAME: <USER>
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_PASSWORD: <PASSWORD>
MAVEN_REMOTE_REPOSITORIES_REPO1_URL: https://repo.spring.io/libs-release
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_SERVICES: my-config-server #this is so all stream applications bind to my-config-server
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_SERVICES: config-server #this for so all task applications bind to my-config-server
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_STREAM_USE_SPRING_APPLICATION_JSON: false #this is for all the stream applications
SPRING_CLOUD_DEPLOYER_CLOUDFOUNDRY_TASK_USE_SPRING_APPLICATION_JSON: false #this is for all the task applications
TRUST_CERTS: <API_ENDPOINT> #this is for the server
spring.cloud.dataflow.applicationProperties.stream.TRUST_CERTS: <API_ENDPOINT> #this propagates to all streams
spring.cloud.dataflow.applicationProperties.task.TRUST_CERTS: <API_ENDPOINT> #this propagates to all tasks
services:
- mysql
- my-config-server #this is for the serverShell
This section covers the options for starting the shell and more advanced functionality relating to how the shell handles white spaces, quotes, and interpretation of SpEL expressions. The introductory chapters to the Stream DSL and Composed Task DSL are good places to start for the most common usage of shell commands.
31. Shell Options
The shell is built upon the Spring Shell project. There are command line options generic to Spring Shell and some specific to Data Flow. The shell takes the following command line options
unix:>java -jar spring-cloud-dataflow-shell-1.2.1.RELEASE.jar --help
Data Flow Options:
--dataflow.uri=<uri> Address of the Data Flow Server [default: http://localhost:9393].
--dataflow.username=<USER> Username of the Data Flow Server [no default].
--dataflow.password=<PASSWORD> Password of the Data Flow Server [no default].
--dataflow.credentials-provider-command=<COMMAND> Executes an external command which must return an
OAuth Bearer Token (Access Token prefixed with 'Bearer '),
e.g. 'Bearer 12345'), [no default].
--dataflow.skip-ssl-validation=<true|false> Accept any SSL certificate (even self-signed) [default: no].
--spring.shell.historySize=<SIZE> Default size of the shell log file [default: 3000].
--spring.shell.commandFile=<FILE> Data Flow Shell executes commands read from the file(s) and then exits.
--help This message.The spring.shell.commandFile option can be used to point to an existing file that contains
all the shell commands to deploy one or many related streams and tasks. This is useful when creating some scripts to
help automate deployment.
Also, the following shell command helps to modularize a complex script into multiple independent files:
dataflow:>script --file <YOUR_AWESOME_SCRIPT>
32. Listing Available Commands
Typing help at the command prompt gives a listing of all available commands.
Most of the commands are for Data Flow functionality, but a few are general purpose.
! - Allows execution of operating system (OS) commands
clear - Clears the console
cls - Clears the console
date - Displays the local date and time
exit - Exits the shell
http get - Make GET request to http endpoint
http post - POST data to http endpoint
quit - Exits the shell
system properties - Shows the shell's properties
version - Displays shell versionAdding the name of the command to help shows additional information on how to invoke the command.
dataflow:>help stream create
Keyword: stream create
Description: Create a new stream definition
Keyword: ** default **
Keyword: name
Help: the name to give to the stream
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: definition
Help: a stream definition, using the DSL (e.g. "http --port=9000 | hdfs")
Mandatory: true
Default if specified: '__NULL__'
Default if unspecified: '__NULL__'
Keyword: deploy
Help: whether to deploy the stream immediately
Mandatory: false
Default if specified: 'true'
Default if unspecified: 'false'33. Tab Completion
The shell command options can be completed in the shell by pressing the TAB key after the leading --. For example, pressing TAB after stream create -- results in
dataflow:>stream create --
stream create --definition stream create --nameIf you type --de and then hit tab, --definition will be expanded.
Tab completion is also available inside the stream or composed task DSL expression for application or task properties. You can also use TAB to get hints in a stream DSL expression for what available sources, processors, or sinks can be used.
34. White Space and Quoting Rules
It is only necessary to quote parameter values if they contain spaces or the | character. The following example passes a SpEL expression (which is applied to any data it encounters) to a transform processor:
transform --expression='new StringBuilder(payload).reverse()'
If the parameter value needs to embed a single quote, use two single quotes, as follows:
scan --query='Select * from /Customers where name=''Smith'''34.1. Quotes and Escaping
There is a Spring Shell-based client that talks to the Data Flow Server and is responsible for parsing the DSL. In turn, applications may have applications properties that rely on embedded languages, such as the Spring Expression Language.
The shell, Data Flow DSL parser, and SpEL have rules about how they handle quotes and how syntax escaping works. When combined together, confusion may arise. This section explains the rules that apply and provides examples of the most complicated situations you may encounter when all three components are involved.
|
It’s not always that complicated
If you do not use the Data Flow shell (for example, you use the REST API directly) or if application properties are not SpEL expressions, then the escaping rules are simpler. |
34.1.1. Shell rules
Arguably, the most complex component when it comes to quotes is the shell. The rules can be laid out quite simply, though:
-
A shell command is made of keys (
--something) and corresponding values. There is a special, keyless mapping, though, which is described later. -
A value cannot normally contain spaces, as space is the default delimiter for commands.
-
Spaces can be added though, by surrounding the value with quotes (either single (
') or double (") quotes). -
If surrounded with quotes, a value can embed a literal quote of the same kind by prefixing it with a backslash (
\). -
Other escapes are available, such as
\t,\n,\r,\fand unicode escapes of the form\uxxxx. -
The keyless mapping is handled in a special way such that it does not need quoting to contain spaces.
For example, the shell supports the ! command to execute native shell commands. The ! accepts a single keyless argument. This is why the following works:
dataflow:>! rm something
The argument here is the whole rm something string, which is passed as is to the underlying shell.
As another example, the following commands are strictly equivalent, and the argument value is something (without the quotes):
dataflow:>stream destroy something dataflow:>stream destroy --name something dataflow:>stream destroy "something" dataflow:>stream destroy --name "something"
34.1.2. DSL Parsing Rules
At the parser level (that is, inside the body of a stream or task definition) the rules are as follows:
-
Option values are normally parsed until the first space character.
-
They can be made of literal strings, though, surrounded by single or double quotes.
-
To embed such a quote, use two consecutive quotes of the desired kind.
As such, the values of the --expression option to the filter application are semantically equivalent in the following examples:
filter --expression=payload>5 filter --expression="payload>5" filter --expression='payload>5' filter --expression='payload > 5'
Arguably, the last one is more readable. It is made possible thanks to the surrounding quotes. The actual expression is payload > 5 (without quotes).
Now, imagine that we want to test against string messages. If we want to compare the payload to the SpEL literal string, "something", we could use the following:
filter --expression=payload=='something' (1) filter --expression='payload == ''something''' (2) filter --expression='payload == "something"' (3)
| 1 | This works because there are no spaces. It is not very legible, though. |
| 2 | This uses single quotes to protect the whole argument. Hence, the actual single quotes need to be doubled. |
| 3 | SpEL recognizes String literals with either single or double quotes, so this last method is arguably the most readable. |
Please note that the preceding examples are to be considered outside of the shell (for example, when calling the REST API directly). When entered inside the shell, chances are that the whole stream definition is itself inside double quotes, which would need to be escaped. The whole example then becomes the following:
dataflow:>stream create something --definition "http | filter --expression=payload='something' | log" dataflow:>stream create something --definition "http | filter --expression='payload == ''something''' | log" dataflow:>stream create something --definition "http | filter --expression='payload == \"something\"' | log"
34.1.3. SpEL Syntax and SpEL Literals
The last piece of the puzzle is about SpEL expressions. Many applications accept options that are to be interpreted as SpEL expressions, and, as seen above, String literals are handled in a special way there, too. The rules are as follows:
-
Literals can be enclosed in either single or double quotes.
-
Quotes need to be doubled to embed a literal quote. Single quotes inside double quotes need no special treatment, and the reverse is also true.
As a last example, assume you want to use the transform processor.
This processor accepts an expression option which is a SpEL expression. It is to be evaluated against the incoming message, with a default of payload (which forwards the message payload untouched).
It is important to understand that the following statements are equivalent:
transform --expression=payload transform --expression='payload'
However, they are different from the following (and variations upon them):
transform --expression="'payload'" transform --expression='''payload'''
The first series evaluates to the message payload, while the latter examples evaluate to the literal string, payload, (again, without quotes).
34.1.4. Putting It All Together
As a last, complete example, consider how one could force the transformation of all messages to the string literal, hello world, by creating a stream in the context of the Data Flow shell:
dataflow:>stream create something --definition "http | transform --expression='''hello world''' | log" (1) dataflow:>stream create something --definition "http | transform --expression='\"hello world\"' | log" (2) dataflow:>stream create something --definition "http | transform --expression=\"'hello world'\" | log" (2)
| 1 | In the first line, there are single quotes around the string (at the Data Flow parser level), but they need to be doubled because they are inside a string literal (started by the first single quote after the equals sign). |
| 2 | The second and third lines, use single and double quotes respectively to encompass the whole string at the Data Flow parser level. Consequently, the other kind of quote can be used inside the string. The whole thing is inside the --definition argument to the shell, though, which uses double quotes. Consequently, double quotes are escaped (at the shell level) |
Streams
This section goes into more detail about how you can create Streams, which are collections of Spring Cloud Stream applications. It covers topics such as creating and deploying Streams.
If you are just starting out with Spring Cloud Data Flow, you should probably read the Getting Started guide before diving into this section.
35. Introduction
A Stream is are a collection of long-lived Spring Cloud Stream applications that communicate with each other over messaging middleware. A text-based DSL defines the configuration and data flow between the applications. While many applications are provided for you to implement common use-cases, you typically create a custom Spring Cloud Stream application to implement custom business logic.
The general lifecycle of a Stream is:
-
Register applications.
-
Create a Stream Definition.
-
Deploy the Stream.
-
Undeploy or Destroy the Stream.
-
Upgrade or Rollack applications in the Stream.
If you use Skipper, you can upgrade or rollback applications in the Stream.
There are two options for deploying streams:
-
Use a Data Flow Server implementation that deploys to a single platform.
-
Configure the Data Flow Server to delegate the deployment to a new server in the Spring Cloud ecosystem named Skipper.
When using the first option, you can use the Local Data Flow Serfver to deploy streams to your local machine, the Data Flow Server for Cloud Foundry to deploy streams to a single org and space on Cloud Foundry. Similarly, you can use Data Flow for Kuberenetes to deploy a stream to a single namespace on a Kubernetes cluster. See the Spring Cloud Data Flow project page for a list of Data Flow server implementations.
When using the second option, you can configure Skipper to deploy applications to one or more Cloud Foundry orgs and spaces, one or more namespaces on a Kubernetes cluster, or to the local machine. When deploying a stream in Data Flow using Skipper, you can specify which platform to use at deployment time. Skipper also provides Data Flow with the ability to perform updates to deployed streams. There are many ways the applications in a stream can be updated, but one of the most common examples is to upgrade a processor application with new custom business logic while leaving the existing source and sink applications alone.
35.1. Stream Pipeline DSL
A stream is defined by using a unix-inspired Pipeline syntax.
The syntax uses vertical bars, also known as “pipes” to connect multiple commands.
The command ls -l | grep key | less in Unix takes the output of the ls -l process and pipes it to the input of the grep key process.
The output of grep in turn is sent to the input of the less process.
Each | symbol connects the standard output of the command on the left to the standard input of the command on the right.
Data flows through the pipeline from left to right.
In Data Flow, the Unix command is replaced by a Spring Cloud Stream application and each pipe symbol represents connecting the input and output of applications over messaging middleware, such as RabbitMQ or Apache Kafka.
Each Spring Cloud Stream application is registered under a simple name. The registration process specifies where the application can be obtained (for example, in a Maven Repository or a Docker registry). You can find out more information on how to register Spring Cloud Stream applications in this section. In Data Flow, we classify the Spring Cloud Stream applications as Sources, Processors, or Sinks.
As a simple example, consider the collection of data from an HTTP Source writing to a File Sink. Using the DSL, the stream description is:
http | file
A stream that involves some processing would be expressed as:
http | filter | transform | file
Stream definitions can be created by using the shell’s create stream command, as shown in the following example:
dataflow:> stream create --name httpIngest --definition "http | file"
The Stream DSL is passed in to the --definition command option.
The deployment of stream definitions is done through the shell’s stream deploy command.
dataflow:> stream deploy --name ticktock
The Getting Started section shows you how to start the server and how to start and use the Spring Cloud Data Flow shell.
Note that the shell calls the Data Flow Servers' REST API. For more information on making HTTP requests directly to the server, consult the REST API Guide.
35.2. Application properties
Each application takes properties to customize its behavior. As an example, the http source module exposes a port setting that allows the data ingestion port to be changed from the default value.
dataflow:> stream create --definition "http --port=8090 | log" --name myhttpstream
This port property is actually the same as the standard Spring Boot server.port property.
Data Flow adds the ability to use the shorthand form port instead of server.port.
One may also specify the longhand version as well, as shown in the following example:
dataflow:> stream create --definition "http --server.port=8000 | log" --name myhttpstream
This shorthand behavior is discussed more in the section on Whitelisting application properties.
If you have registered application property metadata you can use tab completion in the shell after typing -- to get a list of candidate property names.
The shell provides tab completion for application properties. The shell command app info <appType>:<appName> provides additional documentation for all the supported properties.
Supported Stream <appType> possibilities are: source, processor, and sink.
|
36. Stream Lifecycle
The lifecycle of a stream, in "classic" mode, goes through the following stages:
36.1. Register a Stream App
You can register a Stream App with the App Registry by using the Spring Cloud Data Flow Shell
app register command. You must provide a unique name, an application type, and a URI that can be
resolved to the app artifact. For the type, specify source, processor, or sink.
Here are a few examples:
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.1-SNAPSHOT
dataflow:>app register --name myprocessor --type processor --uri file:///Users/example/myprocessor-1.2.3.jar
dataflow:>app register --name mysink --type sink --uri http://example.com/mysink-2.0.1.jarWhen providing a URI with the maven scheme, the format should conform to the following:
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>For example, if you would like to register the snapshot versions of the http and log
applications built with the RabbitMQ binder, you could do the following:
dataflow:>app register --name http --type source --uri maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.1.BUILD-SNAPSHOT
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.1.BUILD-SNAPSHOTIf you would like to register multiple apps at one time, you can store them in a properties file
where the keys are formatted as <type>.<name> and the values are the URIs.
For example, if you would like to register the snapshot versions of the http and log
applications built with the RabbitMQ binder, you could have the following in a properties file (for example, stream-apps.properties):
source.http=maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.1.BUILD-SNAPSHOT
sink.log=maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.1.BUILD-SNAPSHOTThen to import the apps in bulk, use the app import command and provide the location of the properties file with the --uri switch, as follows:
dataflow:>app import --uri file:///<YOUR_FILE_LOCATION>/stream-apps.properties36.1.1. Register Supported Applications and Tasks
For convenience, we have the static files with application-URIs (for both maven and docker) available for all the out-of-the-box stream and task/batch app-starters. You can point to this file and import all the application-URIs in bulk. Otherwise, as explained previously, you can register them individually or have your own custom property file with only the required application-URIs in it. It is recommended, however, to have a “focused” list of desired application-URIs in a custom property file.
The following table lists the available Stream Application Starters:
| Artifact Type | Stable Release | SNAPSHOT Release |
|---|---|---|
RabbitMQ + Maven |
bit.ly/Celsius-BUILD-SNAPSHOT-stream-applications-rabbit-maven |
|
RabbitMQ + Docker |
bit.ly/Celsius-BUILD-SNAPSHOT-stream-applications-rabbit-docker |
|
Kafka 0.10 + Maven |
bit.ly/Celsius-BUILD-SNAPSHOT-stream-applications-kafka-10-maven |
|
Kafka 0.10 + Docker |
bit.ly/Celsius-BUILD-SNAPSHOT-stream-applications-kafka-10-docker |
The following table lists the available Task Application Starters:
| Artifact Type | Stable Release | SNAPSHOT Release |
|---|---|---|
Maven |
||
Docker |
You can find more information about the available task starters in the Task App Starters Project Page and related reference documentation. For more information about the available stream starters, look at the Stream App Starters Project Page and related reference documentation.
As an example, if you would like to register all out-of-the-box stream applications built with the Kafka binder in bulk, you can use the following command:
$ dataflow:>app import --uri http://bit.ly/Celsius-SR1-stream-applications-kafka-10-mavenAlternatively you can register all the stream applications with the Rabbit binder, as follows:
$ dataflow:>app import --uri http://bit.ly/Celsius-SR1-stream-applications-rabbit-mavenYou can also pass the --local option (which is true by default) to indicate whether the
properties file location should be resolved within the shell process itself. If the location should
be resolved from the Data Flow Server process, specify --local false.
|
When using either Note, however, that, once downloaded, applications may be cached locally on the Data Flow server, based on the resource
location. If the resource location does not change (even though the actual resource bytes may be different), then it
is not re-downloaded. When using Moreover, if a stream is already deployed and using some version of a registered app, then (forcibly) re-registering a different app has no effect until the stream is deployed again. |
| In some cases, the Resource is resolved on the server side. In others, the URI is passed to a runtime container instance where it is resolved. Consult the specific documentation of each Data Flow Server for more detail. |
36.1.2. Whitelisting application properties
Stream and Task applications are Spring Boot applications that are aware of many Common Application Properties, such as server.port but also families of properties such as those with the prefix spring.jmx and logging. When creating your own application, you should whitelist properties so that the shell and the UI can display them first as primary properties when presenting options through TAB completion or in drop-down boxes.
To whitelist application properties, create a file named spring-configuration-metadata-whitelist.properties in the META-INF resource directory. There are two property keys that can be used inside this file. The first key is named configuration-properties.classes. The value is a comma separated list of fully qualified @ConfigurationProperty class names. The second key is configuration-properties.names, whose value is a comma-separated list of property names. This can contain the full name of the property, such as server.port, or a partial name to whitelist a category of property names, such as spring.jmx.
The Spring Cloud Stream application starters are a good place to look for examples of usage. The following example comes from the file sink’s spring-configuration-metadata-whitelist.properties file:
configuration-properties.classes=org.springframework.cloud.stream.app.file.sink.FileSinkPropertiesIf we also want to add server.port to be white listed, it would become the following line:
configuration-properties.classes=org.springframework.cloud.stream.app.file.sink.FileSinkProperties
configuration-properties.names=server.port|
Make sure to add 'spring-boot-configuration-processor' as an optional dependency to generate configuration metadata file for the properties. |
36.1.3. Creating and Using a Dedicated Metadata Artifact
You can go a step further in the process of describing the main properties that your stream or task app supports by creating a metadata companion artifact. This jar file contains only the Spring boot JSON file about configuration properties metadata and the whitelisting file described in the previous section.
The following example shows the contents of such an artifact, for the canonical log sink:
$ jar tvf log-sink-rabbit-1.2.1.BUILD-SNAPSHOT-metadata.jar
373848 META-INF/spring-configuration-metadata.json
174 META-INF/spring-configuration-metadata-whitelist.propertiesNote that the spring-configuration-metadata.json file is quite large. This is because it contains the concatenation of all the properties that
are available at runtime to the log sink (some of them come from spring-boot-actuator.jar, some of them come from
spring-boot-autoconfigure.jar, some more from spring-cloud-starter-stream-sink-log.jar, and so on). Data Flow
always relies on all those properties, even when a companion artifact is not available, but here all have been merged
into a single file.
To help with that (you do not want to try to craft this giant JSON file by hand), you can use the following plugin in your build:
<plugin>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-app-starter-metadata-maven-plugin</artifactId>
<executions>
<execution>
<id>aggregate-metadata</id>
<phase>compile</phase>
<goals>
<goal>aggregate-metadata</goal>
</goals>
</execution>
</executions>
</plugin>
This plugin comes in addition to the spring-boot-configuration-processor that creates the individual JSON files.
Be sure to configure both.
|
The benefits of a companion artifact include:
-
Being much lighter. (The companion artifact is usually a few kilobytes, as opposed to megabytes for the actual app.) Consequently, they are quicker to download, allowing quicker feedback when using, for example,
app infoor the Dashboard UI. -
As a consequence of being lighter, they can be used in resource constrained environments (such as PaaS) when metadata is the only piece of information needed.
-
For environments that do not deal with Spring Boot uber jars directly (for example, Docker-based runtimes such as Kubernetes or Mesos), this is the only way to provide metadata about the properties supported by the app.
Remember, though, that this is entirely optional when dealing with uber jars. The uber jar itself also includes the metadata in it already.
36.1.4. Using the Companion Artifact
Once you have a companion artifact at hand, you need to make the system aware of it so that it can be used.
When registering a single app with app register, you can use the optional --metadata-uri option in the shell, as follows:
dataflow:>app register --name log --type sink
--uri maven://org.springframework.cloud.stream.app:log-sink-kafka-10:1.2.1.BUILD-SNAPSHOT
--metadata-uri=maven://org.springframework.cloud.stream.app:log-sink-kafka-10:jar:metadata:1.2.1.BUILD-SNAPSHOTWhen registering several files by using the app import command, the file should contain a <type>.<name>.metadata line
in addition to each <type>.<name> line. Strictly speaking, doing so is optional (if some apps have it but some others do not, it works), but it is best practice.
The following example shows a Dockerized app, where the metadata artifact is being hosted in a Maven repository (retrieving
it through http:// or file:// would be equally possible).
...
source.http=docker:springcloudstream/http-source-rabbit:latest
source.http.metadata=maven://org.springframework.cloud.stream.app:http-source-rabbit:jar:metadata:1.2.1.BUILD-SNAPSHOT
...36.1.5. Creating Custom Applications
While there are out-of-the-box source, processor, sink applications available, you can extend these applications or write a custom Spring Cloud Stream application.
The process of creating Spring Cloud Stream applications with Spring Initializr is detailed in the Spring Cloud Stream documentation. It is possible to include multiple binders to an application. If doing so, see the instructions in Passing Spring Cloud Stream properties for how to configure them.
For supporting property whitelisting, Spring Cloud Stream applications running in Spring Cloud Data Flow may include the Spring Boot configuration-processor as an optional dependency, as shown in the following example:
<dependencies>
<!-- other dependencies -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
</dependencies>|
Make sure that the |
Once a custom application has been created, it can be registered as described in Register a Stream App.
36.2. Creating a Stream
The Spring Cloud Data Flow Server exposes a full RESTful API for managing the lifecycle of stream definitions, but the easiest way to use is it is through the Spring Cloud Data Flow shell. Start the shell as described in the Getting Started section.
New streams are created with the help of stream definitions. The definitions are built from a simple DSL. For example, consider what happens if we execute the following shell command:
dataflow:> stream create --definition "time | log" --name ticktockThis defines a stream named ticktock that is based off the DSL expression time | log. The DSL uses the "pipe" symbol (|), to connect a source to a sink.
36.2.1. Application Properties
Application properties are the properties associated with each application in the stream. When the application is deployed, the application properties are applied to the application through command line arguments or environment variables, depending on the underlying deployment implementation.
The following stream can have application properties defined at the time of stream creation:
dataflow:> stream create --definition "time | log" --name ticktockThe shell command app info <appType>:<appName> displays the white-listed application properties for the application.
For more info on the property white listing, refer to Whitelisting application properties
The following listing shows the white_listed properties for the time app:
dataflow:> app info source:time
╔══════════════════════════════╤══════════════════════════════╤══════════════════════════════╤══════════════════════════════╗
║ Option Name │ Description │ Default │ Type ║
╠══════════════════════════════╪══════════════════════════════╪══════════════════════════════╪══════════════════════════════╣
║trigger.time-unit │The TimeUnit to apply to delay│<none> │java.util.concurrent.TimeUnit ║
║ │values. │ │ ║
║trigger.fixed-delay │Fixed delay for periodic │1 │java.lang.Integer ║
║ │triggers. │ │ ║
║trigger.cron │Cron expression value for the │<none> │java.lang.String ║
║ │Cron Trigger. │ │ ║
║trigger.initial-delay │Initial delay for periodic │0 │java.lang.Integer ║
║ │triggers. │ │ ║
║trigger.max-messages │Maximum messages per poll, -1 │1 │java.lang.Long ║
║ │means infinity. │ │ ║
║trigger.date-format │Format for the date value. │<none> │java.lang.String ║
╚══════════════════════════════╧══════════════════════════════╧══════════════════════════════╧══════════════════════════════╝The following listing shows the white-listed properties for the log app:
dataflow:> app info sink:log
╔══════════════════════════════╤══════════════════════════════╤══════════════════════════════╤══════════════════════════════╗
║ Option Name │ Description │ Default │ Type ║
╠══════════════════════════════╪══════════════════════════════╪══════════════════════════════╪══════════════════════════════╣
║log.name │The name of the logger to use.│<none> │java.lang.String ║
║log.level │The level at which to log │<none> │org.springframework.integratio║
║ │messages. │ │n.handler.LoggingHandler$Level║
║log.expression │A SpEL expression (against the│payload │java.lang.String ║
║ │incoming message) to evaluate │ │ ║
║ │as the logged message. │ │ ║
╚══════════════════════════════╧══════════════════════════════╧══════════════════════════════╧══════════════════════════════╝The application properties for the time and log apps can be specified at the time of stream creation as follows:
dataflow:> stream create --definition "time --fixed-delay=5 | log --level=WARN" --name ticktockNote that, in the preceding example, the fixed-delay and level properties defined for the apps time and log are the "'short-form'" property names provided by the shell completion.
These "'short-form'" property names are applicable only for the white-listed properties. In all other cases, only fully qualified property names should be used.
36.2.2. Common Application Properties
In addition to configuration through DSL, Spring Cloud Data Flow provides a mechanism for setting common properties to all
the streaming applications that are launched by it.
This can be done by adding properties prefixed with spring.cloud.dataflow.applicationProperties.stream when starting
the server.
When doing so, the server passes all the properties, without the prefix, to the instances it launches.
For example, all the launched applications can be configured to use a specific Kafka broker by launching the Data Flow server with the following options:
--spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.brokers=192.168.1.100:9092
--spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.zkNodes=192.168.1.100:2181Doing so causes the properties spring.cloud.stream.kafka.binder.brokers and spring.cloud.stream.kafka.binder.zkNodes
to be passed to all the launched applications.
Properties configured with this mechanism have lower precedence than stream deployment properties.
They are overridden if a property with the same key is specified at stream deployment time (for example,
app.http.spring.cloud.stream.kafka.binder.brokers overrides the common property).
|
36.3. Deploying a Stream
This section describes how to deploy a Stream when the Spring Cloud Data Flow server is responsible for deploying the stream. The following section, Stream Lifecycle with Skipper, covers the new deployment and upgrade features when the Spring Cloud Data Flow server delegates to Skipper for stream deployment. The description of how deployment properties applies to both approaches of Stream deployment.
Give the ticktock stream definition:
dataflow:> stream create --definition "time | log" --name ticktock
To deploy the stream, use the following shell command:
dataflow:> stream deploy --name ticktock
The Data Flow Server resolves time and log to maven coordinates and uses those to launch the time and log applications of the stream, as shown in the following listing:
2016-06-01 09:41:21.728 INFO 79016 --- [nio-9393-exec-6] o.s.c.d.spi.local.LocalAppDeployer : deploying app ticktock.log instance 0
Logs will be in /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/ticktock-1464788481708/ticktock.log
2016-06-01 09:41:21.914 INFO 79016 --- [nio-9393-exec-6] o.s.c.d.spi.local.LocalAppDeployer : deploying app ticktock.time instance 0
Logs will be in /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/ticktock-1464788481910/ticktock.timeIn the preceding example, the time source sends the current time as a message each second, and the log sink outputs it by using the logging framework.
You can tail the stdout log (which has an <instance> suffix). The log files are located within the directory displayed in the Data Flow Server’s log output, as shown in the following listing:
$ tail -f /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/ticktock-1464788481708/ticktock.log/stdout_0.log
2016-06-01 09:45:11.250 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:11
2016-06-01 09:45:12.250 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:12
2016-06-01 09:45:13.251 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:13You can also create and deploy the stream in one step by passing the --deploy flag when creating the stream, as follows:
dataflow:> stream create --definition "time | log" --name ticktock --deployHowever, it is not very common in real-world use cases to create and deploy the stream in one step.
The reason is that when you use the stream deploy command, you can pass in properties that define how to map the applications onto the platform (for example, what is the memory size of the container to use, the number of each application to run, and whether to enable data partitioning features).
Properties can also override application properties that were set when creating the stream.
The next sections cover this feature in detail.
36.3.1. Deployment Properties
When deploying a stream, you can specify properties that fall into two groups:
-
Properties that control how the apps are deployed to the target platform. These properties use a
deployerprefix and are referred to asdeployerproperties. -
Properties that set application properties or override application properties set during stream creation and are referred to as
applicationproperties.
The syntax for deployer properties is deployer.<app-name>.<short-property-name>=<value>, and the syntax for application properties app.<app-name>.<property-name>=<value>. This syntax is used when passing deployment properties through the shell. You may also specify them in a YAML file, which is discussed later in this chapter.
The following table shows the difference in behavior between setting deployer and application properties when deploying an application.
| Application Properties | Deployer Properties | |
|---|---|---|
Example Syntax |
|
|
What the application "sees" |
|
Nothing |
What the deployer "sees" |
Nothing |
|
Typical usage |
Passing/Overriding application properties, passing Spring Cloud Stream binder or partitioning properties |
Setting the number of instances, memory, disk, and others |
Passing Instance Count
If you would like to have multiple instances of an application in the stream, you
can include a deployer property called count with the deploy command:
dataflow:> stream deploy --name ticktock --properties "deployer.time.count=3"Note that count is the reserved property name used by the underlying deployer. Consequently, if the application also has a custom property named count, it is not supported
when specified in 'short-form' form during stream deployment as it could conflict with the instance count deployer property. Instead, the count as a custom application property can be
specified in its fully qualified form (for example, app.something.somethingelse.count) during stream deployment or it can be specified by using the 'short-form' or the fully qualified form during the stream creation,
where it is processed as an app property.
Inline Versus File-based Properties
When using the Spring Cloud Data Flow Shell, there are two ways to provide deployment properties: either inline or through a file reference. Those two ways are exclusive.
Inline properties use the --properties shell option and list properties as a comma separated
list of key=value pairs, as shown in the following example:
stream deploy foo
--properties "deployer.transform.count=2,app.transform.producer.partitionKeyExpression=payload"File references use the --propertiesFile option and point it to a local .properties, .yaml or .yml file
(that is, a file that resides in the filesystem of the machine running the shell). Being read
as a .properties file, normal rules apply (ISO 8859-1 encoding, =, <space> or
: delimiter, and others), although we recommend using = as a key-value pair delimiter,
for consistency. The following example shows a stream deploy command that uses the --propertiesFile option:
stream deploy something --propertiesFile myprops.propertiesAssume that myprops.properties contains the following properties:
deployer.transform.count=2
app.transform.producer.partitionKeyExpression=payloadBoth of the properties are passed as deployment properties for the something stream.
If you use YAML as the format for the deployment properties, use the .yaml or .yml file extention when deploying the stream, as shown in the following example:
stream deploy foo --propertiesFile myprops.yamlIn that case, the myprops.yaml file might contain the following content:
deployer:
transform:
count: 2
app:
transform:
producer:
partitionKeyExpression: payloadPassing application properties
The application properties can also be specified when deploying a stream. When specified during deployment, these application properties can either be specified as
'short-form' property names (applicable for white-listed properties) or as fully qualified property names. The application properties should have the prefix app.<appName/label>.
For example, consider the following stream command:
dataflow:> stream create --definition "time | log" --name ticktockThe stream in the precedig example can also be deployed with application properties by using the 'short-form' property names, as shown in the following example:
dataflow:>stream deploy ticktock --properties "app.time.fixed-delay=5,app.log.level=ERROR"Consider the following example:
stream create ticktock --definition "a: time | b: log"When using the app label, the application properties can be defined as follows:
stream deploy ticktock --properties "app.a.fixed-delay=4,app.b.level=ERROR"Passing Spring Cloud Stream properties
Spring Cloud Data Flow sets the required Spring Cloud Stream properties for the applications inside the stream. Most importantly, the spring.cloud.stream.bindings.<input/output>.destination is set internally for the apps to bind.
If you want to override any of the Spring Cloud Stream properties, they can be set with deployment properties.
For example, consider the following stream definition:
dataflow:> stream create --definition "http | transform --expression=payload.getValue('hello').toUpperCase() | log" --name ticktockIf there are multiple binders available in the classpath for each of the applications and the binder is chosen for each deployment, then the stream can be deployed with the specific Spring Cloud Stream properties, as follows:
dataflow:>stream deploy ticktock --properties "app.time.spring.cloud.stream.bindings.output.binder=kafka,app.transform.spring.cloud.stream.bindings.input.binder=kafka,app.transform.spring.cloud.stream.bindings.output.binder=rabbit,app.log.spring.cloud.stream.bindings.input.binder=rabbit"| Overriding the destination names is not recommended, because Spring Cloud Data Flow internally takes care of setting this property. |
Passing Per-binding Producer and Consumer Properties
A Spring Cloud Stream application can have producer and consumer properties set on a per-binding basis.
While Spring Cloud Data Flow supports specifying short-hand notation for per-binding producer properties such as partitionKeyExpression and partitionKeyExtractorClass (as described in Passing Stream Partition Properties), all the supported Spring Cloud Stream producer/consumer properties can be set as Spring Cloud Stream properties for the app directly as well.
The consumer properties can be set for the inbound channel name with the prefix app.[app/label name].spring.cloud.stream.bindings.<channelName>.consumer.. The producer properties can be set for the outbound channel name with the prefix app.[app/label name].spring.cloud.stream.bindings.<channelName>.producer..
Consider the following example:
dataflow:> stream create --definition "time | log" --name ticktockThe stream can be deployed with producer and consumer properties, as follows:
dataflow:>stream deploy ticktock --properties "app.time.spring.cloud.stream.bindings.output.producer.requiredGroups=myGroup,app.time.spring.cloud.stream.bindings.output.producer.headerMode=raw,app.log.spring.cloud.stream.bindings.input.consumer.concurrency=3,app.log.spring.cloud.stream.bindings.input.consumer.maxAttempts=5"The binder-specific producer and consumer properties can also be specified in a similar way, as shown in the following example:
dataflow:>stream deploy ticktock --properties "app.time.spring.cloud.stream.rabbit.bindings.output.producer.autoBindDlq=true,app.log.spring.cloud.stream.rabbit.bindings.input.consumer.transacted=true"Passing Stream Partition Properties
A common pattern in stream processing is to partition the data as it is streamed. This entails deploying multiple instances of a message-consuming app and using content-based routing so that messages with a given key (as determined at runtime) are always routed to the same app instance. You can pass the partition properties during stream deployment to declaratively configure a partitioning strategy to route each message to a specific consumer instance.
The following list shows variations of deploying partitioned streams:
-
app.[app/label name].producer.partitionKeyExtractorClass: The class name of a
PartitionKeyExtractorStrategy(default:null) -
app.[app/label name].producer.partitionKeyExpression: A SpEL expression, evaluated against the message, to determine the partition key. Only applies if
partitionKeyExtractorClassis null. If both are null, the app is not partitioned (default:null) -
app.[app/label name].producer.partitionSelectorClass: The class name of a
PartitionSelectorStrategy(default:null) -
app.[app/label name].producer.partitionSelectorExpression: A SpEL expression, evaluated against the partition key, to determine the partition index to which the message is routed. The final partition index is the return value (an integer) modulo
[nextModule].count. If both the class and expression are null, the underlying binder’s defaultPartitionSelectorStrategyis applied to the key (default:null)
In summary, an app is partitioned if its count is > 1 and the previous app has a
partitionKeyExtractorClass or partitionKeyExpression (partitionKeyExtractorClass takes precedence).
When a partition key is extracted, the partitioned app instance is determined by
invoking the partitionSelectorClass, if present, or the partitionSelectorExpression % partitionCount.
partitionCount is application count, in the case of RabbitMQ, or the underlying
partition count of the topic, in the case of Kafka.
If neither a partitionSelectorClass nor a partitionSelectorExpression is
present, the result is key.hashCode() % partitionCount.
Passing application content type properties
In a stream definition, you can specify that the input or the output of an application must be converted to a different type.
You can use the inputType and outputType properties to specify the content type for the incoming data and outgoing data, respectively.
For example, consider the following stream:
dataflow:>stream create tuple --definition "http | filter --inputType=application/x-spring-tuple
--expression=payload.hasFieldName('hello') | transform --expression=payload.getValue('hello').toUpperCase()
| log" --deployThe http app is expected to send the data in JSON and the filter app receives the JSON data
and processes it as a Spring Tuple.
In order to do so, we use the inputType property on the filter app to convert the data into the expected Spring Tuple format.
The transform application processes the Tuple data and sends the processed data to the downstream log application.
Consider the following example of sending some data to the http application:
dataflow:>http post --data {"hello":"world","something":"somethingelse"} --contentType application/json --target localhost:<http-port>;
At the log application, you see the content as follows:
INFO 18745 --- [transform.tuple-1] log.sink : WORLD
Depending on how applications are chained, the content type conversion can be specified either as an --outputType in the upstream app or as an --inputType in the downstream app.
For instance, in the above stream, instead of specifying the --inputType on the 'transform' application to convert, the option --outputType=application/x-spring-tuple can also be specified on the 'http' application.
For the complete list of message conversion and message converters, please refer to Spring Cloud Stream documentation.
Overriding Application Properties During Stream Deployment
Application properties that are defined during deployment override the same properties defined during the stream creation.
For example, the following stream has application properties defined during stream creation:
dataflow:> stream create --definition "time --fixed-delay=5 | log --level=WARN" --name ticktockTo override these application properties, you can specify the new property values during deployment, as follows:
dataflow:>stream deploy ticktock --properties "app.time.fixed-delay=4,app.log.level=ERROR"36.4. Destroying a Stream
You can delete a stream by issuing the stream destroy command from the shell, as follows:
dataflow:> stream destroy --name ticktock
If the stream was deployed, it is undeployed before the stream definition is deleted.
36.5. Undeploying a Stream
Often you want to stop a stream but retain the name and definition for future use. In that case, you can undeploy the stream by name.
dataflow:> stream undeploy --name ticktock
dataflow:> stream deploy --name ticktockYou can issue the deploy command at a later time to restart it.
dataflow:> stream deploy --name ticktock
37. Stream Lifecycle with Skipper
An additional lifecycle stage of Stream is available if you run in "skipper" mode.
Skipper is a server that you discover Spring Boot applications and manage their lifecycle on multiple Cloud Platforms.
Applications in Skipper are bundled as packages that contain the application’s resource location, application properties and deployment properites.
You can think Skipper packages as analogous to packages found in tools such as apt-get or brew.
When Data Flow deploys a Stream, it will generate and upload a package to Skipper that represents the applications in the Stream. Subsequent commands to upgrade or rollback the applications within the Stream are passed through to Skipper. In addition, the Stream definition is reverse engineered from the package and the status of the Stream is also delegated to Skipper.
37.1. Register a Versioned Stream App
Skipper extends the Register a Stream App lifecycle with support of multi-versioned stream applications. This allows to upgrade or rollback those applications at runtime using the deployment properties.
Register a versioned stream application using the app register command. You must provide a unique name, application type, and a URI that can be resolved to the app artifact.
For the type, specify "source", "processor", or "sink". The version is resolved from the URI. Here are a few examples:
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.1
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.2
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.3
dataflow:>app list --id source:mysource
╔══════════════════╤═════════╤════╤════╗
║ source │processor│sink│task║
╠══════════════════╪═════════╪════╪════╣
║> mysource-0.0.1 <│ │ │ ║
║mysource-0.0.2 │ │ │ ║
║mysource-0.0.3 │ │ │ ║
╚══════════════════╧═════════╧════╧════╝The application URI should conform to one the following schema formats:
-
maven schema
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>
-
http schema
http://<web-path>/<artifactName>-<version>.jar
-
file schema
file:///<local-path>/<artifactName>-<version>.jar
-
docker schema
docker:<docker-image-path>/<imageName>:<version>
The URI <version> part is compulsory for the versioned stream applications
|
Multiple versions can be registered for the same applications (e.g. same name and type) but only one can be set as default. The default version is used for deploying Streams.
The first time an application is registered it will be marked as default. The default application version can be altered with the app default command:
dataflow:>app default --id source:mysource --version 0.0.2
dataflow:>app list --id source:mysource
╔══════════════════╤═════════╤════╤════╗
║ source │processor│sink│task║
╠══════════════════╪═════════╪════╪════╣
║mysource-0.0.1 │ │ │ ║
║> mysource-0.0.2 <│ │ │ ║
║mysource-0.0.3 │ │ │ ║
╚══════════════════╧═════════╧════╧════╝The app list --id <type:name> command lists all versions for a given stream application.
The app unregister command has an optional --version parameter to specify the app version to unregister.
dataflow:>app unregister --name mysource --type source --version 0.0.1
dataflow:>app list --id source:mysource
╔══════════════════╤═════════╤════╤════╗
║ source │processor│sink│task║
╠══════════════════╪═════════╪════╪════╣
║> mysource-0.0.2 <│ │ │ ║
║mysource-0.0.3 │ │ │ ║
╚══════════════════╧═════════╧════╧════╝If a --version is not specified, the default version is unregistered.
|
All applications in a stream should have a default version set for the stream to be deployed.
Otherwise they will be treated as unregistered application during the deployment.
Use the |
app default --id source:mysource --version 0.0.3
dataflow:>app list --id source:mysource
╔══════════════════╤═════════╤════╤════╗
║ source │processor│sink│task║
╠══════════════════╪═════════╪════╪════╣
║mysource-0.0.2 │ │ │ ║
║> mysource-0.0.3 <│ │ │ ║
╚══════════════════╧═════════╧════╧════╝The stream deploy necessitates default app versions to be set.
The stream update and stream rollback commands though can use all (default and non-default) registered app versions.
dataflow:>stream create foo --definition "mysource | log"This will create stream using the default mysource version (0.0.3). Then we can update the version to 0.0.2 like this:
dataflow:>stream update foo --properties version.mysource=0.0.2|
Only pre-registered applications can be used to |
An attempt to update the mysource to version 0.0.1 (not registered) will fail!
37.2. Creating and Deploying a Stream
You create and deploy a stream by using Skipper in two steps:
-
Creating the stream definition.
-
Deploying the stream.
The following example shows the two steps in action:
dataflow:> stream create --name httptest --definition "http --server.port=9000 | log"
dataflow:> stream deploy --name httptestThe stream info command shows useful information about the stream, including the deployment properties, as shown (with its output) in the following example:
dataflow:>stream info httptest
╔══════════════════════════════╤══════════════════════════════╤════════════════════════════╗
║ Name │ DSL │ Status ║
╠══════════════════════════════╪══════════════════════════════╪════════════════════════════╣
║httptest │http --server.port=9000 | log │deploying ║
╚══════════════════════════════╧══════════════════════════════╧════════════════════════════╝
Stream Deployment properties: {
"log" : {
"spring.cloud.deployer.indexed" : "true",
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:log-sink-rabbit" : "1.1.0.RELEASE"
},
"http" : {
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:http-source-rabbit" : "1.1.0.RELEASE"
}
}There is an important optional command argument (called --platformName) to the stream deploy command.
Skipper can be configured to deploy to multiple platforms.
Skipper is pre-configured with a platform named default, which deploys applications to the local machine where Skipper is running.
The default value of the command line argument --platformName is default.
If you commonly deploy to one platform, when installing Skipper, you can override the configuration of the default platform.
Otherwise, specify the platformName to one of the values returned by the stream platform-list command.
37.3. Updating a Stream
To update the stream, use the command stream update which takes as a command argument either --properties or --propertiesFile.
You can pass in values to these command arguments in the same format as when deploy the stream with or without Skipper.
There is an important new top level prefix available when using Skipper, which is version.
If the Stream http | log was deployed, and the version of log which registered at the time of deployment was 1.1.0.RELEASE, the following command will update the Stream to use the 1.2.0.RELEASE of the log application.
Before updating the stream with the specific version of the app, we need to make sure that the app is registered with that version.
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.2.0.RELEASE
Successfully registered application 'sink:log'dataflow:>stream update --name httptest --properties version.log=1.2.0.RELEASE|
Only pre-registered application versions can be used to |
To verify the deployment properties and the updated version, we can use stream info, as shown (with its output) in the following example:
dataflow:>stream info httptest
╔══════════════════════════════╤══════════════════════════════╤════════════════════════════╗
║ Name │ DSL │ Status ║
╠══════════════════════════════╪══════════════════════════════╪════════════════════════════╣
║httptest │http --server.port=9000 | log │deploying ║
╚══════════════════════════════╧══════════════════════════════╧════════════════════════════╝
Stream Deployment properties: {
"log" : {
"spring.cloud.deployer.indexed" : "true",
"spring.cloud.deployer.count" : "1",
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:log-sink-rabbit" : "1.2.0.RELEASE"
},
"http" : {
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:http-source-rabbit" : "1.1.0.RELEASE"
}
}37.4. Stream versions
Skipper keeps a history of the streams that were deployed.
After updating a Stream, there will be a second version of the stream.
You can query for the history of the versions using the command stream history --name <name-of-stream>.
dataflow:>stream history --name httptest
╔═══════╤════════════════════════════╤════════╤════════════╤═══════════════╤════════════════╗
║Version│ Last updated │ Status │Package Name│Package Version│ Description ║
╠═══════╪════════════════════════════╪════════╪════════════╪═══════════════╪════════════════╣
║2 │Mon Nov 27 22:41:16 EST 2017│DEPLOYED│httptest │1.0.0 │Upgrade complete║
║1 │Mon Nov 27 22:40:41 EST 2017│DELETED │httptest │1.0.0 │Delete complete ║
╚═══════╧════════════════════════════╧════════╧════════════╧═══════════════╧════════════════╝37.5. Stream Manifests
Skipper keeps a “manifest” of the all the applications, their application properties, and their deployment properties after all values have been substituted. This represents the final state of what was deployed to the platform. You can view the manifest for any of the versions of a Stream by using the following command:
stream manifest --name <name-of-stream> --releaseVersion <optional-version>
If the --releaseVersion is not specified, the manifest for the last version is returned.
The following example shows the use of the manifest:
dataflow:>stream manifest --name httptestUsing the command results in the following output:
# Source: log.yml
apiVersion: skipper.spring.io/v1
kind: SpringCloudDeployerApplication
metadata:
name: log
spec:
resource: maven://org.springframework.cloud.stream.app:log-sink-rabbit
version: 1.2.0.RELEASE
applicationProperties:
spring.metrics.export.triggers.application.includes: integration**
spring.cloud.dataflow.stream.app.label: log
spring.cloud.stream.metrics.key: httptest.log.${spring.cloud.application.guid}
spring.cloud.stream.bindings.input.group: httptest
spring.cloud.stream.metrics.properties: spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*
spring.cloud.dataflow.stream.name: httptest
spring.cloud.dataflow.stream.app.type: sink
spring.cloud.stream.bindings.input.destination: httptest.http
deploymentProperties:
spring.cloud.deployer.indexed: true
spring.cloud.deployer.group: httptest
spring.cloud.deployer.count: 1
---
# Source: http.yml
apiVersion: skipper.spring.io/v1
kind: SpringCloudDeployerApplication
metadata:
name: http
spec:
resource: maven://org.springframework.cloud.stream.app:http-source-rabbit
version: 1.2.0.RELEASE
applicationProperties:
spring.metrics.export.triggers.application.includes: integration**
spring.cloud.dataflow.stream.app.label: http
spring.cloud.stream.metrics.key: httptest.http.${spring.cloud.application.guid}
spring.cloud.stream.bindings.output.producer.requiredGroups: httptest
spring.cloud.stream.metrics.properties: spring.application.name,spring.application.index,spring.cloud.application.*,spring.cloud.dataflow.*
server.port: 9000
spring.cloud.stream.bindings.output.destination: httptest.http
spring.cloud.dataflow.stream.name: httptest
spring.cloud.dataflow.stream.app.type: source
deploymentProperties:
spring.cloud.deployer.group: httptestThe majority of the deployment and application properties were set by Data Flow to enable the applications to talk to each other and to send application metrics with identifying labels.
37.6. Rollback a Stream
You can rollback to a previous version of the stream using the command stream rollback.
dataflow:>stream rollback --name httptestThe optional --releaseVersion command argument adds the version of the stream.
If not specified, the rollback goes to the previous stream version.
37.7. Application Count
The application count is a dynamic property of the system. If, due to scaling at runtime, the application to be upgraded has 5 instances running, then 5 instances of the upgraded application are deployed.
37.8. Skipper’s Upgrade Strategy
Skipper has a simple 'red/black' upgrade strategy. It deploys the new version of the applications, using as many instances as the currently running version, and checks the /health endpoint of the application.
If the health of the new application is good, then the previous application is undeployed.
If the health of the new application is bad, then all new applications are undeployed and the upgrade is considered to be not successful.
The upgrade strategy is not a rolling upgrade, so if five applications of the application are running, then in a sunny-day scenario, five of the new applications are also running before the older version is undeployed.
38. Stream DSL
This section covers additional features of the Stream DSL not covered in the Stream DSL introduction.
38.1. Tap a Stream
Taps can be created at various producer endpoints in a stream. For a stream such as that defined in the following example, taps can be created at the output of http, step1 and step2:
stream create --definition "http | step1: transform --expression=payload.toUpperCase() | step2: transform --expression=payload+'!' | log" --name mainstream --deploy
To create a stream that acts as a 'tap' on another stream requires specifying the source destination name for the tap stream. The syntax for the source destination name is as follows:
:<streamName>.<label/appName>
To create a tap at the output of http in the preceding stream, the source destination name is mainstream.http
To create a tap at the output of the first transform app in the stream above, the source destination name is mainstream.step1
The tap stream DSL resembles the following:
stream create --definition ":mainstream.http > counter" --name tap_at_http --deploy
stream create --definition ":mainstream.step1 > jdbc" --name tap_at_step1_transformer --deployNote the colon (:) prefix before the destination names. The colon lets the parser recognize this as a destination name instead of an app name.
38.2. Using Labels in a Stream
When a stream is made up of multiple apps with the same name, they must be qualified with labels:
stream create --definition "http | firstLabel: transform --expression=payload.toUpperCase() | secondLabel: transform --expression=payload+'!' | log" --name myStreamWithLabels --deploy
38.3. Named Destinations
Instead of referencing a source or sink application, you can use a named destination.
A named destination corresponds to a specific destination name in the middleware broker (Rabbit, Kafka, and others).
When using the | symbol, applications are connected to each other with messaging middleware destination names created by the Data Flow server.
In keeping with the Unix analogy, one can redirect standard input and output using the less-than (<) and greater-than (>) characters.
To specify the name of the destination, prefix it with a colon (:).
For example, the following stream has the destination name in the source position:
dataflow:>stream create --definition ":myDestination > log" --name ingest_from_broker --deploy
This stream receives messages from the destination called myDestination, located at the broker, and connects it to the log app. You can also create additional streams that consume data from the same named destination.
The following stream has the destination name in the sink position:
dataflow:>stream create --definition "http > :myDestination" --name ingest_to_broker --deploy
It is also possible to connect two different destinations (source and sink positions) at the broker in a stream, as shown in the following example:
dataflow:>stream create --definition ":destination1 > :destination2" --name bridge_destinations --deploy
In the precding stream, both the destinations (destination1 and destination2) are located in the broker. The messages flow from the source destination to the sink destination over a bridge app that connects them.
38.4. Fan-in and Fan-out
By using named destinations, you can support fan-in and fan-out use cases. Fan-in use cases are when multiple sources all send data to the same named destination, as shown in the following example:
s3 > :data
ftp > :data
http > :dataThe preceding example directs the data payloads from the Amazon S3, FTP, and HTTP sources to the same named destination called data. Then an additional stream created with the following DSL expression would have all the data from those three sources sent to the file sink:
:data > file
The fan-out use case is when you determine the destination of a stream based on some information that is only known at runtime. In this case, the Router Application can be used to specify how to direct the incoming message to one of N named destinations.
A nice Video showing Fan-in and Fan-out behavior is also available.
39. Stream Java DSL
Instead of using the shell to create and deploy streams, you can use the Java-based DSL provided by the spring-cloud-dataflow-rest-client module.
The Java DSL is a convenient wrapper around the DataFlowTemplate class that enables creating and deploying streams programmatically.
To get started, you need to add the following dependency to your project, as follows:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dataflow-rest-client</artifactId>
<version>1.3.0.RELEASE</version>
</dependency>| A complete sample can be found in the Spring Cloud Data Flow Samples Repository. |
39.1. Overview
The classes at the heart of the Java DSL are StreamBuilder, StreamDefinition, Stream, StreamApplication, and DataFlowTemplate.
The entry point is a builder method on Stream that takes an instance of a DataFlowTemplate.
To create an instance of a DataFlowTemplate, you need to provide a URI location of the Data Flow Server.
Spring Boot auto-configuration for StreamBuilder and DataFlowTemplate is also available. The properties in DataFlowClientProperties can be used to configure the connection to the Data Flow server. The common property to start using is spring.cloud.dataflow.client.uri
Consider the following example, using the definition style.
URI dataFlowUri = URI.create("http://localhost:9393");
DataFlowOperations dataFlowOperations = new DataFlowTemplate(dataFlowUri);
dataFlowOperations.appRegistryOperations().importFromResource(
"http://bit.ly/Celsius-RC1-stream-applications-rabbit-maven", true);
StreamDefinition streamDefinition = Stream.builder(dataFlowOperations)
.name("ticktock")
.definition("time | log")
.create();The create method returns an instance of a StreamDefinition representing a Stream that has been created but not deployed.
This is called the definition style since it takes a single string for the stream definition, same as in the shell.
If applications have not yet been registered in the Data Flow server, you can use the DataFlowOperations class to register them.
With the StreamDefinition instance, you have methods available to deploy or destory the stream.
Stream stream = streamDefinition.deploy();The Stream instance provides getStatus, destroy and undeploy methods to control and query the stream.
If you are going to immediately deploy the stream, there is no need to create a separate local variable of the type StreamDefinition. You can just chain the calls together, as follows:
Stream stream = Stream.builder(dataFlowOperations)
.name("ticktock")
.definition("time | log")
.create()
.deploy();The deploy method is overloaded to take a java.util.Map of deployment properties.
The StreamApplication class is used in the 'fluent' Java DSL style and is discussed in the next section. The StreamBuilder class is returned from the method Stream.builder(dataFlowOperations). In larger applications, it is common to create a single instance of the StreamBuilder as a Spring @Bean and share it across the application.
39.2. Java DSL styles
The Java DSL offers two styles to create Streams.
-
The
definitionstyle keeps the feel of using the pipes and filters textual DSL in the shell. This style is selected by using thedefinitionmethod after setting the stream name - for example,Stream.builder(dataFlowOperations).name("ticktock").definition(<definition goes here>). -
The
fluentstyle lets you chain together sources, processors, and sinks by passing in an instance of aStreamApplication. This style is selected by using thesourcemethod after setting the stream name - for example,Stream.builder(dataFlowOperations).name("ticktock").source(<stream application instance goes here>). You then chain togetherprocessor()andsink()methods to create a stream definition.
To demonstrate both styles, we include a simple stream that uses both approaches. A complete sample for you to get started can be found in the Spring Cloud Data Flow Samples Repository.
The following example demonstrates the definition approach:
public void definitionStyle() throws Exception{
DataFlowOperations dataFlowOperations = createDataFlowOperations();
Map<String, String> deploymentProperties = createDeploymentProperties();
Stream woodchuck = Stream.builder(dataFlowOperations)
.name("woodchuck")
.definition("http --server.port=9900 | splitter --expression=payload.split(' ') | log")
.create()
.deploy(deploymentProperties);
waitAndDestroy(woodchuck)
}The following example demonstrates the fluent approach:
public void fluentStyle() throws Exception {
DataFlowOperations dataFlowOperations = createDataFlowOperations();
StreamApplication source = new StreamApplication("http").addProperty("server.port", 9900);
StreamApplication processor = new StreamApplication("splitter")
.addProperty("producer.partitionKeyExpression", "payload");
StreamApplication sink = new StreamApplication("log")
.addDeploymentProperty("count", 2);
Stream woodchuck = Stream.builder(dataFlowOperations).name("woodchuck")
.source(source)
.processor(processor)
.sink(sink)
.create()
.deploy(deploymentProperties);
waitAndDestroy(woodchuck)
}The waitAndDestroy method uses the getStatus method to poll for the stream’s status, as shown in the following example:
private void waitAndDestroy(Stream stream) throws InterruptedException {
while(!stream.getStatus().equals("deployed")){
System.out.println("Wating for deployment of stream.");
Thread.sleep(5000);
}
System.out.println("Letting the stream run for 2 minutes.");
// Let the stream run for 2 minutes
Thread.sleep(120000);
System.out.println("Destroying stream");
stream.destroy();
}When using the definition style, the deployment properties are specified as a java.util.Map in the same manner as using the shell. The createDeploymentProperties method is defined as follows:
private Map<String, String> createDeploymentProperties() {
Map<String, String> deploymentProperties = new HashMap<>();
deploymentProperties.put("app.splitter.producer.partitionKeyExpression", "payload");
deploymentProperties.put("deployer.log.memory","512");
deploymentProperties.put("deployer.log.count", "2");
return deploymentProperties;
}Is this case, application properties are also overridden at deployment time in addition to setting the deployer property count for the log application.
When using the fluent style, the deployment properties are added by using the method addDeploymentProperty (for example, new StreamApplication("log").addDeploymentProperty("count", 2)), and you do not need to prefix the property with deployer.<app_name>.
In order to create and deploy your streams, you need to make sure that the corresponding apps have been registered in the DataFlow server first.
Attempting to create or deploy a stream that contains an unknown app throws an exception. You can register your application by using the DataFlowTemplate, as follows:
|
dataFlowOperations.appRegistryOperations().importFromResource(
"http://bit.ly/Celsius-RC1-stream-applications-rabbit-maven", true);The Stream applications can also be beans within your application that are injected in other classes to create Streams.
There are many ways to structure Spring applications, but one way is to have an @Configuration class define the StreamBuilder and StreamApplications, as shown in the following example:
@Configuration
public StreamConfiguration {
@Bean
public StreamBuilder builder() {
return Stream.builder(new DataFlowTemplate(URI.create("http://localhost:9393")));
}
@Bean
public StreamApplication httpSource(){
return new StreamApplication("http");
}
@Bean
public StreamApplication logSink(){
return new StreamApplication("log");
}
}Then in another class you can @Autowire these classes and deploy a stream.
@Component
public MyStreamApps {
@Autowired
private StreamBuilder streamBuilder;
@Autowired
private StreamApplication httpSource;
@Autowired
private StreamApplication logSink;
public void deploySimpleStream() {
Stream simpleStream = streamBuilder.name("simpleStream")
.source(httpSource);
.sink(logSink)
.create()
.deploy();
}
}This style lets you share StreamApplications across multiple Streams.
39.3. Using the DeploymentPropertiesBuilder
Regardless of style you choose, the deploy(Map<String, String> deploymentProperties) method allows customization of how your streams will be deployed. We made it a easier to create a map with properties by using a builder style, as well as creating static methods for some properties so you don’t need to remember the name of such properties. If you take the previous example of createDeploymentProperties it could be rewritten as:
private Map<String, String> createDeploymentProperties() {
return new DeploymentPropertiesBuilder()
.count("log", 2)
.memory("log", 512)
.put("app.splitter.producer.partitionKeyExpression", "payload")
.build();
}This utility class is meant to help with the creation of a Map and adds a few methods to assist with defining pre-defined properties.
40. Deploying using Skipper
If you desire to deploy your streams using Skipper, you need to pass certain properties to the server specific to a Skipper based deployment, for example selecting the target platfrom.
The SkipperDeploymentPropertiesBuilder provides you all the properties in DeploymentPropertiesBuilder and adds those needed for Skipper.
private Map<String, String> createDeploymentProperties() {
return new SkipperDeploymentPropertiesBuilder()
.count("log", 2)
.memory("log", 512)
.put("app.splitter.producer.partitionKeyExpression", "payload")
.platformName("pcf")
.build();
}41. Stream Applications with Multiple Binder Configurations
In some cases, a stream can have its applications bound to multiple spring cloud stream binders when they are required to connect to different messaging middleware configurations. In those cases, it is important to make sure the applications are configured appropriately with their binder configurations. For example, consider the following stream:
http | transform --expression=payload.toUpperCase() | log
In this stream, each application connects to messaging middleware in the following way:
-
The HTTP source sends events to RabbitMQ (
rabbit1). -
The Transform processor receives events from RabbitMQ (
rabbit1) and sends the processed events into Kafka (kafka1). -
The log sink receives events from Kafka (
kafka1).
Here, rabbit1 and kafka1 are the binder names given in the spring cloud stream application properties.
Based on this setup, the applications have the following binder(s) in their classpath with the appropriate configuration:
-
HTTP: Rabbit binder
-
Transform: Both Kafka and Rabbit binders
-
Log: Kafka binder
The spring-cloud-stream binder configuration properties can be set within the applications themselves.
If not, they can be passed through deployment properties when the stream is deployed as shown in the following example:
dataflow:>stream create --definition "http | transform --expression=payload.toUpperCase() | log" --name mystream
dataflow:>stream deploy mystream --properties "app.http.spring.cloud.stream.bindings.output.binder=rabbit1,app.transform.spring.cloud.stream.bindings.input.binder=rabbit1,
app.transform.spring.cloud.stream.bindings.output.binder=kafka1,app.log.spring.cloud.stream.bindings.input.binder=kafka1"One can override any of the binder configuration properties by specifying them through deployment properties.
42. Examples
This chapter includes the following examples:
You can find links to more samples in the “[dataflow-samples]” chapter.
42.1. Simple Stream Processing
As an example of a simple processing step, we can transform the payload of the HTTP posted data to upper case by using the following stream definition:
http | transform --expression=payload.toUpperCase() | log
To create this stream enter the following command in the shell
dataflow:> stream create --definition "http | transform --expression=payload.toUpperCase() | log" --name mystream --deploy
The following example uses a shell command to post some data:
dataflow:> http post --target localhost:1234 --data "hello"
The preceding example results in an upper-case 'HELLO' in the log, as follows:
2016-06-01 09:54:37.749 INFO 80083 --- [ kafka-binder-] log.sink : HELLO
42.2. Stateful Stream Processing
To demonstrate the data partitioning functionality, the following listing deploys a stream with Kafka as the binder:
dataflow:>stream create --name words --definition "http --server.port=9900 | splitter --expression=payload.split(' ') | log"
Created new stream 'words'
dataflow:>stream deploy words --properties "app.splitter.producer.partitionKeyExpression=payload,deployer.log.count=2"
Deployed stream 'words'
dataflow:>http post --target http://localhost:9900 --data "How much wood would a woodchuck chuck if a woodchuck could chuck wood"
> POST (text/plain;Charset=UTF-8) http://localhost:9900 How much wood would a woodchuck chuck if a woodchuck could chuck wood
> 202 ACCEPTEDYou should then see the following in the server logs:
2016-06-05 18:33:24.982 INFO 58039 --- [nio-9393-exec-9] o.s.c.d.spi.local.LocalAppDeployer : deploying app words.log instance 0
Logs will be in /var/folders/c3/ctx7_rns6x30tq7rb76wzqwr0000gp/T/spring-cloud-dataflow-694182453710731989/words-1465176804970/words.log
2016-06-05 18:33:24.988 INFO 58039 --- [nio-9393-exec-9] o.s.c.d.spi.local.LocalAppDeployer : deploying app words.log instance 1
Logs will be in /var/folders/c3/ctx7_rns6x30tq7rb76wzqwr0000gp/T/spring-cloud-dataflow-694182453710731989/words-1465176804970/words.logWhen you review the words.log instance 0 logs, you should see the following:
2016-06-05 18:35:47.047 INFO 58638 --- [ kafka-binder-] log.sink : How
2016-06-05 18:35:47.066 INFO 58638 --- [ kafka-binder-] log.sink : chuck
2016-06-05 18:35:47.066 INFO 58638 --- [ kafka-binder-] log.sink : chuckWhen you review the words.log instance 1 logs, you shoul see the following:
2016-06-05 18:35:47.047 INFO 58639 --- [ kafka-binder-] log.sink : much
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : wood
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : would
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : a
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : woodchuck
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : if
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : a
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : woodchuck
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : could
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : woodThis example has shown that payload splits that contain the same word are routed to the same application instance.
42.3. Other Source and Sink Application Types
This example shows something a bit more complicated: swapping out the time source for something else. Another supported source type is http, which accepts data for ingestion over HTTP POSTs. Note that the http source accepts data on a different port from the Data Flow Server (default 8080). By default, the port is randomly assigned.
To create a stream using an http source but still using the same log sink, we would change the original command in the Simple Stream Processing example to the following:
`dataflow:> stream create --definition "http | log" --name myhttpstream --deploy
The preceding command produces the following output from the server:
2016-06-01 09:47:58.920 INFO 79016 --- [io-9393-exec-10] o.s.c.d.spi.local.LocalAppDeployer : deploying app myhttpstream.log instance 0
Logs will be in /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/myhttpstream-1464788878747/myhttpstream.log
2016-06-01 09:48:06.396 INFO 79016 --- [io-9393-exec-10] o.s.c.d.spi.local.LocalAppDeployer : deploying app myhttpstream.http instance 0
Logs will be in /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/myhttpstream-1464788886383/myhttpstream.httpNote that we do not see any other output this time until we actually post some data (by using a shell command). In order to see the randomly assigned port on which the http source is listening, run the following command:
dataflow:> runtime apps
You should see that the corresponding http source has a url property containing the host and port information on which it is listening. You are now ready to post to that url, as shown in the following example:
dataflow:> http post --target http://localhost:1234 --data "hello"
dataflow:> http post --target http://localhost:1234 --data "goodbye"The stream then funnels the data from the http source to the output log implemented by the log sink, yielding output similar to the following:
2016-06-01 09:50:22.121 INFO 79654 --- [ kafka-binder-] log.sink : hello
2016-06-01 09:50:26.810 INFO 79654 --- [ kafka-binder-] log.sink : goodbyeWe could also change the sink implementation. You could pipe the output to a file (file), to hadoop (hdfs), or to any of the other sink applications that are available. You can also define your own applications.
Tasks
This section goes into more detail about how you can work with Spring Cloud Task. It covers topics such as creating and running task applications.
If you are just starting out with Spring Cloud Data Flow, you should probably read the “Getting Started” guide before diving into this section.
43. Introduction
A task executes a process on demand.
In the case of Spring Cloud Task, a task is a Spring Boot application that is annotated with @EnableTask.
A user launches a task that performs a certain process, and, once complete, the task ends.
An example of a task would be a Spring Boot application that exports data from a JDBC repository to an HDFS instance.
Tasks record the start time and the end time as well as the boot exit code in a relational database.
The task implementation is based on the Spring Cloud Task project.
44. The Lifecycle of a Task
Before we dive deeper into the details of creating Tasks, we need to understand the typical lifecycle for tasks in the context of Spring Cloud Data Flow:
44.1. Creating a Task Application
While Spring Cloud Task does provide a number of out-of-the-box applications (at spring-cloud-task-app-starters), most task applications require custom development. To create a custom task application:
-
Use the Spring Initializer to create a new project, making sure to select the following starters:
-
Cloud Task: This dependency is thespring-cloud-starter-task. -
JDBC: This dependency is thespring-jdbcstarter.
-
-
Within your new project, create a new class to serve as your main class, as follows:
@EnableTask @SpringBootApplication public class MyTask { public static void main(String[] args) { SpringApplication.run(MyTask.class, args); } } -
With this class, you need one or more
CommandLineRunnerorApplicationRunnerimplementations within your application. You can either implement your own or use the ones provided by Spring Boot (there is one for running batch jobs, for example). -
Packaging your application with Spring Boot into an über jar is done through the standard Spring Boot conventions. The packaged application can be registered and deployed as noted below.
44.1.1. Task Database Configuration
| When launching a task application, be sure that the database driver that is being used by Spring Cloud Data Flow is also a dependency on the task application. For example, if your Spring Cloud Data Flow is set to use Postgresql, be sure that the task application also has Postgresql as a dependency. |
| When you run tasks externally (that is, from the command line) and you want Spring Cloud Data Flow to show the TaskExecutions in its UI, be sure that common datasource settings are shared among the both. By default, Spring Cloud Task uses a local H2 instance, and the execution is recorded to the database used by Spring Cloud Data Flow. |
44.2. Registering a Task Application
You can register a Task App with the App Registry by using the Spring Cloud Data Flow Shell app register command.
You must provide a unique name and a URI that can be resolved to the app artifact. For the type, specify "task".
The following listing shows three examples:
dataflow:>app register --name task1 --type task --uri maven://com.example:mytask:1.0.2
dataflow:>app register --name task2 --type task --uri file:///Users/example/mytask-1.0.2.jar
dataflow:>app register --name task3 --type task --uri http://example.com/mytask-1.0.2.jarWhen providing a URI with the maven scheme, the format should conform to the following:
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>
If you would like to register multiple apps at one time, you can store them in a properties file where the keys are formatted as <type>.<name> and the values are the URIs.
For example, the followinng listing would be a valid properties file:
task.foo=file:///tmp/foo.jar
task.bar=file:///tmp/bar.jarThen you can use the app import command and provide the location of the properties file by using the --uri option, as follows:
app import --uri /tmp/task-apps.properties
For convenience, we have the static files with application-URIs (for both maven and docker) available for all the out-of-the-box Task app-starters. You can point to this file and import all the application-URIs in bulk. Otherwise, as explained earlier in this chapter, you can register them individually or have your own custom property file with only the required application-URIs in it. It is recommended, however, to have a “focused” list of desired application-URIs in a custom property file.
The following table lists the available static property files:
| Artifact Type | Stable Release | SNAPSHOT Release |
|---|---|---|
Maven |
||
Docker |
For example, if you would like to register all out-of-the-box task applications in bulk, you can do so with the following command:
dataflow:>app import --uri bit.ly/Clark-GA-task-applications-maven
You can also pass the --local option (which is TRUE by default) to indicate whether the properties file location should be resolved within the shell process itself.
If the location should be resolved from the Data Flow Server process, specify --local false.
When using either app register or app import, if a task app is already registered with
the provided name, it is not overridden by default. If you would like to override the
pre-existing task app, then include the --force option.
| In some cases, the Resource is resolved on the server side. In other cases, the URI is passed to a runtime container instance where it is resolved. Consult the specific documentation of each Data Flow Server for more detail. |
44.3. Creating a Task Definition
You can create a task Definition from a task app by providing a definition name as well as
properties that apply to the task execution. Creating a task definition can be done through
the RESTful API or the shell. To create a task definition by using the shell, use the
task create command to create the task definition, as shown in the following example:
dataflow:>task create mytask --definition "timestamp --format=\"yyyy\""
Created new task 'mytask'A listing of the current task definitions can be obtained through the RESTful API or the shell.
To get the task definition list by using the shell, use the task list command.
44.4. Launching a Task
An adhoc task can be launched through the RESTful API or the shell.
To launch an ad-hoc task through the shell, use the task launch command, as shown in the following example:
dataflow:>task launch mytask
Launched task 'mytask'When a task is launched, any properties that need to be passed as command line arguments to the task application can be set when launching the task, as follows:
dataflow:>task launch mytask --arguments "--server.port=8080,--custom=value"
Additional properties meant for a TaskLauncher itself can be passed in by using a --properties option.
The format of this option is a comma-separated string of properties prefixed with app.<task definition name>.<property>.
Properties are passed to TaskLauncher as application properties.
It is up to an implementation to choose how those are passed into an actual task application.
If the property is prefixed with deployer instead of app, it is passed to TaskLauncher as a deployment property and its meaning may be TaskLauncher implementation specific.
dataflow:>task launch mytask --properties "deployer.timestamp.custom1=value1,app.timestamp.custom2=value2"
44.4.1. Common application properties
In addition to configuration through DSL, Spring Cloud Data Flow provides a mechanism for setting common properties to all the task applications that are launched by it.
This can be done by adding properties prefixed with spring.cloud.dataflow.applicationProperties.task when starting the server.
When doing so, the server passes all the properties, without the prefix, to the instances it launches.
For example, all the launched applications can be configured to use the properties prop1 and prop2 by launching the Data Flow server with the following options:
--spring.cloud.dataflow.applicationProperties.task.prop1=value1
--spring.cloud.dataflow.applicationProperties.task.prop2=value2This causes the properties, prop1=value1 and prop2=value2, to be passed to all the launched applications.
Properties configured by using this mechanism have lower precedence than task deployment properties.
They are overridden if a property with the same key is specified at task launch time (for example, app.trigger.prop2
overrides the common property).
|
44.5. Reviewing Task Executions
Once the task is launched, the state of the task is stored in a relational DB. The state includes:
-
Task Name
-
Start Time
-
End Time
-
Exit Code
-
Exit Message
-
Last Updated Time
-
Parameters
A user can check the status of their task executions through the RESTful API or the shell.
To display the latest task executions through the shell, use the task execution list command.
To get a list of task executions for just one task definition, add --name and
the task definition name, for example task execution list --name foo. To retrieve full
details for a task execution use the task display command with the id of the task execution,
for example task display --id 549.
44.6. Destroying a Task Definition
Destroying a Task Definition removes the definition from the definition repository.
This can be done through the RESTful API or the shell.
To destroy a task through the shell, use the task destroy command, as shown in the following example:
dataflow:>task destroy mytask
Destroyed task 'mytask'The task execution information for previously launched tasks for the definition remains in the task repository.
| This does not stop any currently executing tasks for this definition. Instead, it removes the task definition from the database. |
45. Subscribing to Task/Batch Events
You can also tap into various task and batch events when the task is launched.
If the task is enabled to generate task or batch events (with the additional dependencies spring-cloud-task-stream and, in the case of Kafka as the binder, spring-cloud-stream-binder-kafka), those events are published during the task lifecycle.
By default, the destination names for those published events on the broker (Rabbit, Kafka, and others) are the event names themselves (for instance: task-events, job-execution-events, and so on).
dataflow:>task create myTask --definition “myBatchJob"
dataflow:>task launch myTask
dataflow:>stream create task-event-subscriber1 --definition ":task-events > log" --deployYou can control the destination name for those events by specifying explicit names when launching the task, as follows:
dataflow:>task launch myTask --properties "spring.cloud.stream.bindings.task-events.destination=myTaskEvents"
dataflow:>stream create task-event-subscriber2 --definition ":myTaskEvents > log" --deployThe following table lists the default task and batch event and destination names on the broker:
Event |
Destination |
Task events |
|
Job Execution events |
|
Step Execution events |
|
Item Read events |
|
Item Process events |
|
Item Write events |
|
Skip events |
|
46. Composed Tasks
Spring Cloud Data Flow lets a user create a directed graph where each node of the graph is a task application. This is done by using the DSL for composed tasks. A composed task can be created through the RESTful API, the Spring Cloud Data Flow Shell, or the Spring Cloud Data Flow UI.
46.1. Configuring the Composed Task Runner
Composed tasks are executed through a task application called the Composed Task Runner.
46.1.1. Registering the Composed Task Runner
By default, the Composed Task Runner application is not registered with Spring Cloud Data Flow. Consequently, to launch composed tasks, we must first register the Composed Task Runner as an application with Spring Cloud Data Flow, as follows:
app register --name composed-task-runner --type task --uri maven://org.springframework.cloud.task.app:composedtaskrunner-task:<DESIRED_VERSION>
You can also configure Spring Cloud Data Flow to use a different task definition name for the composed task runner.
This can be done by setting the spring.cloud.dataflow.task.composedTaskRunnerName property to the name of your choice.
You can then register the composed task runner application with the name you set by using that property.
46.1.2. Configuring the Composed Task Runner
The Composed Task Runner application has a dataflow.server.uri property that is used for validation and for launching child tasks.
This defaults to localhost:9393. If you run a distributed Spring Cloud Data Flow server, as you would if you deploy the server on Cloud Foundry, YARN, or Kubernetes, you need to provide the URI that can be used to access the server.
You can either provide this dataflow.server.uri property for the Composed Task Runner application when launching a composed task or you can provide a spring.cloud.dataflow.server.uri property for the Spring Cloud Data Flow server when it is started.
For the latter case, the dataflow.server.uri Composed Task Runner application property is automatically set when a composed task is launched.
In some cases, you may wish to execute an instance of the Composed Task Runner through the Task Launcher sink.
In that case, you must configure the Composed Task Runner to use the same datasource that the Spring Cloud Data Flow instance is using.
The datasource properties are set with the TaskLaunchRequest through the use of the commandlineArguments or the environmentProperties switches.
This is because the Composed Task Runner monitors the task_executions table to check the status of the tasks that it is running.
Using information from the table, it determines how it should navigate the graph.
46.2. The Lifecycle of a Composed Task
The lifecycle of a composed task has three parts:
46.2.1. Creating a Composed Task
The DSL for the composed tasks is used when creating a task definition through the task create command, as shown in the following example:
dataflow:> app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:<DESIRED_VERSION>
dataflow:> app register --name mytaskapp --type task --uri file:///home/tasks/mytask.jar
dataflow:> task create my-composed-task --definition "mytaskapp && timestamp"
dataflow:> task launch my-composed-taskIn the preceding example, we assume that the applications to be used by our composed task have not been registered yet.
Consequently, in the first two steps, we register two task applications.
We then create our composed task definition by using the task create command.
The composed task DSL in the preceding example, when launched, runs mytaskapp and then runs the timestamp application.
But before we launch the my-composed-task definition, we can view what Spring Cloud Data Flow generated for us.
This can be done by executing the task list command, as shown (including its output) in the following example:
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│unknown ║
║my-composed-task-mytaskapp│mytaskapp │unknown ║
║my-composed-task-timestamp│timestamp │unknown ║
╚══════════════════════════╧══════════════════════╧═══════════╝In the example, Spring Cloud Data Flow created three task definitions, one for each of the applications that makes up our composed task (my-composed-task-mytaskapp and my-composed-task-timestamp) as well as the composed task (my-composed-task) definition.
We also see that each of the generated names for the child tasks is made up of the name of the composed task and the name of the application, separated by a dash - (as in my-composed-task - mytaskapp).
Task Application Parameters
The task applications that make up the composed task definition can also contain parameters, as shown in the following example:
dataflow:> task create my-composed-task --definition "mytaskapp --displayMessage=hello && timestamp --format=YYYY"
46.2.2. Launching a Composed Task
Launching a composed task is done the same way as launching a stand-alone task, as follows:
task launch my-composed-task
Once the task is launched, and assuming all the tasks complete successfully, you can see three task executions when executing a task execution list, as shown in the following example:
dataflow:>task execution list
╔══════════════════════════╤═══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID │ Start Time │ End Time │Exit Code║
╠══════════════════════════╪═══╪════════════════════════════╪════════════════════════════╪═════════╣
║my-composed-task-timestamp│713│Wed Apr 12 16:43:07 EDT 2017│Wed Apr 12 16:43:07 EDT 2017│0 ║
║my-composed-task-mytaskapp│712│Wed Apr 12 16:42:57 EDT 2017│Wed Apr 12 16:42:57 EDT 2017│0 ║
║my-composed-task │711│Wed Apr 12 16:42:55 EDT 2017│Wed Apr 12 16:43:15 EDT 2017│0 ║
╚══════════════════════════╧═══╧════════════════════════════╧════════════════════════════╧═════════╝In the preceding example, we see that my-compose-task launched and that it also launched the other tasks in sequential order.
All of them executed successfully with Exit Code as 0.
Exit Statuses
The following list shows how the Exit Status is set for each step (task) contained in the composed task following each step execution:
-
If the
TaskExecutionhas anExitMessage, that is used as theExitStatus. -
If no
ExitMessageis present and theExitCodeis set to zero, then theExitStatusfor the step isCOMPLETED. -
If no
ExitMessageis present and theExitCodeis set to any non-zero number, theExitStatusfor the step isFAILED.
46.2.3. Destroying a Composed Task
The command used to destroy a stand-alone task is the same as the command used to destroy a composed task.
The only difference is that destroying a composed task also destroys the child tasks associated with it.
The following example shows the task list before and after using the destroy command:
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│COMPLETED ║
║my-composed-task-mytaskapp│mytaskapp │COMPLETED ║
║my-composed-task-timestamp│timestamp │COMPLETED ║
╚══════════════════════════╧══════════════════════╧═══════════╝
...
dataflow:>task destroy my-composed-task
dataflow:>task list
╔═════════╤═══════════════╤═══════════╗
║Task Name│Task Definition│Task Status║
╚═════════╧═══════════════╧═══════════╝46.2.4. Stopping a Composed Task
In cases where a composed task execution needs to be stopped, you can do so through the:
-
RESTful API
-
Spring Cloud Data Flow Dashboard
To stop a composed task through the dashboard, select the Jobs tab and click the Stop button next to the job execution that you want to stop.
The composed task run is stopped when the currently running child task completes.
The step associated with the child task that was running at the time that the composed task was stopped is marked as STOPPED as well as the composed task job execution.
46.2.5. Restarting a Composed Task
In cases where a composed task fails during execution and the status of the composed task is FAILED, the task can be restarted.
You can do so through the:
-
RESTful API
-
The shell
-
Spring Cloud Data Flow Dashboard
To restart a composed task through the shell, launch the task with the same parameters. To restart a composed task through the dashboard, select the Jobs tab and click the Restart button next to the job execution that you want to restart.
Restarting a Composed Task job that has been stopped (through the Spring Cloud Data Flow Dashboard or RESTful API) relaunches the STOPPED child task and then launches the remaining (unlaunched) child tasks in the specified order.
|
47. Composed Tasks DSL
Composed tasks can be run in three ways:
47.1. Conditional Execution
Conditional execution is expressed by using a double ampersand symbol (&&).
This lets each task in the sequence be launched only if the previous task
successfully completed, as shown in the following example:
task create my-composed-task --definition "task1 && task2"
When the composed task called my-composed-task is launched, it launches the task called task1 and, if it completes successfully, then the task called task2 is launched.
If task1 fails, then task2 does not launch.
You can also use the Spring Cloud Data Flow Dashboard to create your conditional execution, by using the designer to drag and drop applications that are required and connecting them together to create your directed graph, as shown in the following image:
The preceding diagram is a screen capture of the directed graph as it being created by using the Spring Cloud Data Flow Dashboard. You can see that are four components in the diagram that comprise a conditional execution:
-
Start icon: All directed graphs start from this symbol. There is only one.
-
Task icon: Represents each task in the directed graph.
-
End icon: Represents the termination of a directed graph.
-
Solid line arrow: Represents the flow conditional execution flow between:
-
Two applications.
-
The start control node and an application.
-
An application and the end control node.
-
-
End icon: All directed graphs end at this symbol.
| You can view a diagram of your directed graph by clicking the Detail button next to the composed task definition on the Definitions tab. |
47.2. Transitional Execution
The DSL supports fine- grained control over the transitions taken during the execution of the directed graph.
Transitions are specified by providing a condition for equality based on the exit status of the previous task.
A task transition is represented by the following symbol ->.
47.2.1. Basic Transition
A basic transition would look like the following:
task create my-transition-composed-task --definition "foo 'FAILED' → bar 'COMPLETED' → baz"
In the preceding example, foo would launch, and, if it had an exit status of FAILED, the bar task would launch.
If the exit status of foo was COMPLETED, baz would launch.
All other statuses returned by foo have no effect, and the task would terminate normally.
Using the Spring Cloud Data Flow Dashboard to create the same " basic transition " would resemble the following image:
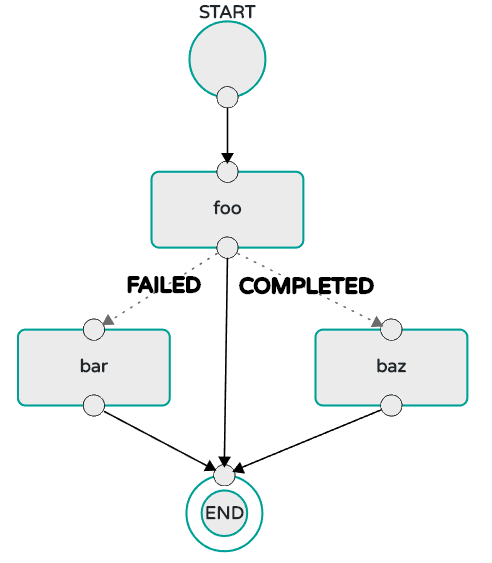
The preceding diagram is a screen capture of the directed graph as it being created in the Spring Cloud Data Flow Dashboard. Notice that there are two different types of connectors:
-
Dashed line: Represents transitions from the application to one of the possible destination applications.
-
Solid line: Connects applications in a conditional execution or a connection between the application and a control node (start or end).
To create a transitional connector:
-
When creating a transition, link the application to each possible destination by using the connector.
-
Once complete, go to each connection and select it by clicking it.
-
A bolt icon appears.
-
Click that icon.
-
Enter the exit status required for that connector.
-
The solid line for that connector turns to a dashed line.
47.2.2. Transition With a Wildcard
Wildcards are supported for transitions by the DSL, as shown in the following:
task create my-transition-composed-task --definition "foo 'FAILED' → bar '*' → baz"
In the preceding example, foo would launch, and, if it had an exit status of FAILED, the bar task would launch.
For any exit status of foo other than FAILED, baz would launch.
Using the Spring Cloud Data Flow Dashboard to create the same “transition with wildcard” would resemble the following image:
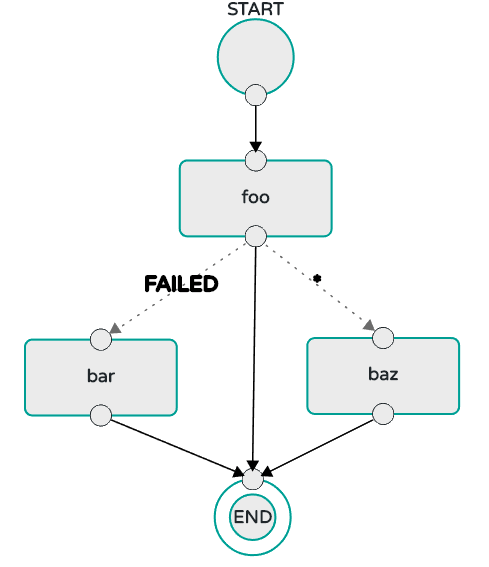
47.2.3. Transition With a Following Conditional Execution
A transition can be followed by a conditional execution so long as the wildcard is not used, as shown in the following example:
task create my-transition-conditional-execution-task --definition "foo 'FAILED' → bar 'UNKNOWN' → baz && qux && quux"
In the preceding example, foo would launch, and, if it had an exit status of FAILED, the bar task would launch.
If foo had an exit status of UNKNOWN, baz would launch.
For any exit status of foo other than FAILED or UNKNOWN, qux would launch and, upon successful completion, quux would launch.
Using the Spring Cloud Data Flow Dashboard to create the same “transition with conditional execution” would resemble the following image:
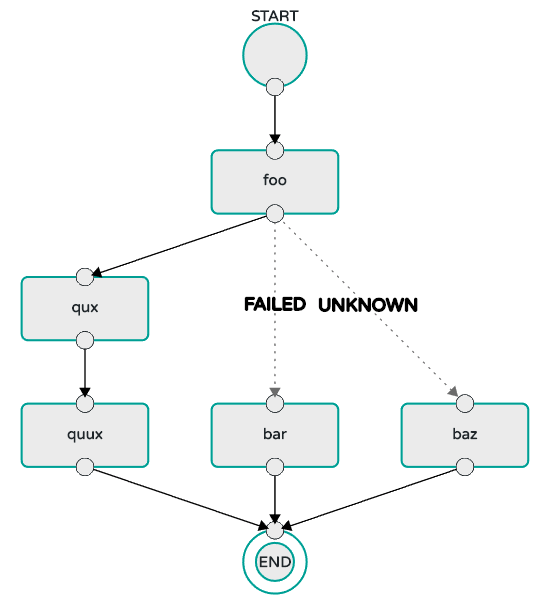
In this diagram we see the dashed line (transition) connecting the foo application to the target applications, but a solid line connecting the conditional executions between foo, qux, and quux.
|
47.3. Split Execution
Splits allow multiple tasks within a composed task to be run in parallel.
It is denoted by using angle brackets (<>) to group tasks and flows that are to be run in parallel.
These tasks and flows are separated by the double pipe || symbol, as shown in the following example:
task create my-split-task --definition "<foo || bar || baz>"
The preceding example above launches tasks foo, bar and baz in parallel.
Using the Spring Cloud Data Flow Dashboard to create the same “split execution” would resemble the following image:
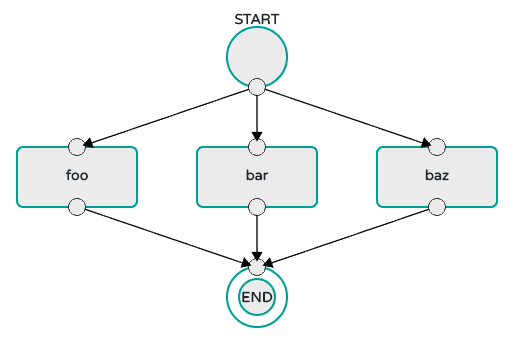
With the task DSL, a user may also execute multiple split groups in succession, as shown in the following example:
`task create my-split-task --definition "<foo || bar || baz> && <qux || quux>"'
In the preceding example, tasks foo, bar, and baz are launched in parallel.
Once they all complete, then tasks qux and quux are launched in parallel.
Once they complete, the composed task ends.
However, if foo, bar, or baz fails, the split containing qux and quux does not launch.
Using the Spring Cloud Data Flow Dashboard to create the same “split with multiple groups” would resemble the following image:
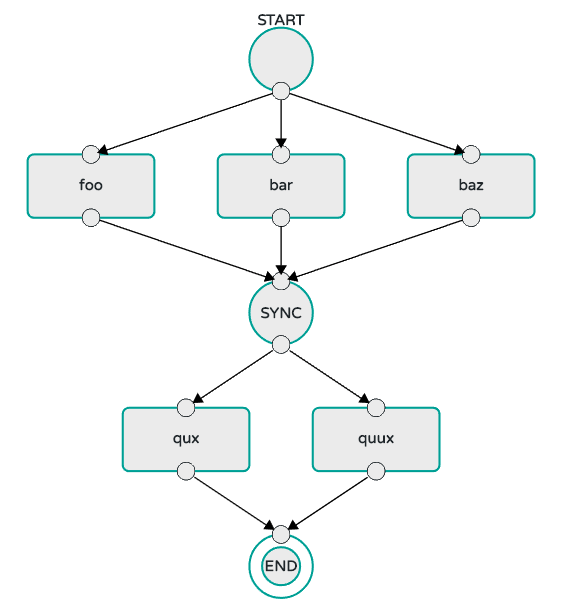
Notice that there is a SYNC control node that is inserted by the designer when
connecting two consecutive splits.
47.3.1. Split Containing Conditional Execution
A split can also have a conditional execution within the angle brackets, as shown in the following example:
task create my-split-task --definition "<foo && bar || baz>"
In the preceding example, we see that foo and baz are launched in parallel.
However, bar does not launch until foo completes successfully.
Using the Spring Cloud Data Flow Dashboard to create the same " split containing conditional execution " resembles the following image:
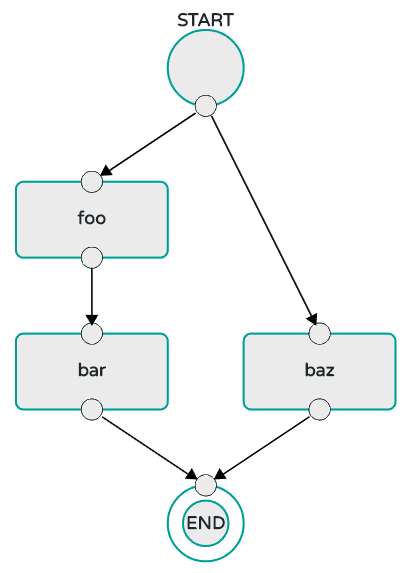
48. Launching Tasks from a Stream
You can launch a task from a stream by using one of the available task-launcher sinks. Currently the platforms supported by the task-launcher sinks are:
task-launcher-local is meant for development purposes only.
|
A task-launcher sink expects a message containing a TaskLaunchRequest object in its payload.
From the TaskLaunchRequest object, the task-launcher obtains the URI of the artifact to be launched, as well as the environment properties, command line arguments, deployment properties, and application name to be used by the task.
The task-launcher-local can be added to the available sinks by executing the app register command, as follows (for the Rabbit Binder, in this case):
app register --name task-launcher-local --type sink --uri maven://org.springframework.cloud.stream.app:task-launcher-local-sink-rabbit:jar:1.2.0.RELEASE
In the case of a Maven-based task that is to be launched, the task-launcher application is responsible for downloading the artifact.
You must configure the task-launcher with the appropriate configuration of Maven Properties, such as --maven.remote-repositories.repo1.url=http://repo.spring.io/libs-milestone" to resolve artifacts (in this case against a milestone repo). Note that this repostory can be different than the one used to register the task-launcher application itself.
48.1. TriggerTask
One way to launch a task with the task-launcher is to use the triggertask source.
The triggertask source emits a message with a TaskLaunchRequest object that contains the required launch information.
The triggertask can be added to the available sources by running the app register command, as follows (for the Rabbit Binder, in this case):
app register --type source --name triggertask --uri maven://org.springframework.cloud.stream.app:triggertask-source-rabbit:1.2.0.RELEASE
For example, to launch the timestamp task once every 60 seconds, the stream implementation would be as follows:
stream create foo --definition "triggertask --triggertask.uri=maven://org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE --trigger.fixed-delay=60 --triggertask.environment-properties=spring.datasource.url=jdbc:h2:tcp://localhost:19092/mem:dataflow,spring.datasource.username=sa | task-launcher-local --maven.remote-repositories.repo1.url=http://repo.spring.io/libs-release" --deployIf you run runtime apps, you can find the log file for the task launcher sink.
By using the tail command on that file, you can find the log file for the launched tasks.
Setting of triggertask.environment-properties establishes the Data Flow Server’s H2 Database as the database where the task executions will be recorded.
You can then see the list of task executions by using the shell command task execution list, as shown (with its output) in the following example:
dataflow:>task execution list
╔════════════════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID│ Start Time │ End Time │Exit Code║
╠════════════════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣
║timestamp-task_26176│4 │Tue May 02 12:13:49 EDT 2017│Tue May 02 12:13:49 EDT 2017│0 ║
║timestamp-task_32996│3 │Tue May 02 12:12:49 EDT 2017│Tue May 02 12:12:49 EDT 2017│0 ║
║timestamp-task_58971│2 │Tue May 02 12:11:50 EDT 2017│Tue May 02 12:11:50 EDT 2017│0 ║
║timestamp-task_13467│1 │Tue May 02 12:10:50 EDT 2017│Tue May 02 12:10:50 EDT 2017│0 ║
╚════════════════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝48.2. TaskLaunchRequest-transform
Another way to start a task with the task-launcher would be to create a stream by using the
Tasklaunchrequest-transform processor to translate a message payload to a TaskLaunchRequest.
The tasklaunchrequest-transform can be added to the available processors by executing the app register command, as follows (for the Rabbit Binder, in this case):
app register --type processor --name tasklaunchrequest-transform --uri maven://org.springframework.cloud.stream.app:tasklaunchrequest-transform-processor-rabbit:1.2.0.RELEASE
The following example shows the creation of a task that includes the tasklaunchrequest-transform:
stream create task-stream --definition "http --port=9000 | tasklaunchrequest-transform --uri=maven://org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE | task-launcher-local --maven.remote-repositories.repo1.url=http://repo.spring.io/libs-release"
48.3. Launching a Composed Task From a Stream
A composed task can be launched with one of the task-launcher sinks as discussed here.
Since we use the ComposedTaskRunner directly, we need to set up the task definitions it uses prior to the creation of the composed task launching stream.
Suppose we wanted to create the following composed task definition: AAA && BBB.
The first step would be to create the task definitions, as shown in the following example:
task create AAA --definition "timestamp"
task create BBB --definition "timestamp"Now that the task definitions we need for composed task definition are ready, we need to create a stream that launches ComposedTaskRunner.
So, in this case, we create a stream with
-
A trigger that emits a message once every 30 seconds
-
A transformer that creates a
TaskLaunchRequestfor each message received -
A
task-launcher-localsink that launches a theComposedTaskRunneron our local machine
The stream should resemble the following:
stream create ctr-stream --definition "time --fixed-delay=30 | tasklaunchrequest-transform --uri=maven://org.springframework.cloud.task.app:composedtaskrunner-task:<current release> --command-line-arguments='--graph=AAA&&BBB --increment-instance-enabled=true --spring.datasource.url=...' | task-launcher-local"In the preceding example, we see that the tasklaunchrequest-transform is establishing two primary components:
-
uri: The URI of the
ComposedTaskRunnerthat is used -
command-line-arguments: To configure the
ComposedTaskRunner
For now, we focus on the configuration that is required to launch the ComposedTaskRunner:
-
graph: this is the graph that is to be executed by the
ComposedTaskRunner. In this case it isAAA&&BBB. -
increment-instance-enabled: This lets each execution of
ComposedTaskRunnerbe unique.ComposedTaskRunneris built by using Spring Batch. Thus, we want a new Job Instance for each launch of theComposedTaskRunner. To do this, we setincrement-instance-enabledto betrue. -
spring.datasource.*: The datasource that is used by Spring Cloud Data Flow, which lets the user track the tasks launched by the
ComposedTaskRunnerand the state of the job execution. Also, this is so that theComposedTaskRunnercan track the state of the tasks it launched and update its state.
Releases of ComposedTaskRunner can be found
here.
|
49. Sharing Spring Cloud Data Flow’s Datastore with Tasks
As discussed in the Tasks documentation Spring Cloud Data Flow allows a user to view Spring Cloud Task App executions. So in this section we will discuss what is required by a Task Application and Spring Cloud Data Flow to share the task execution information.
49.1. A Common DataStore Dependency
Spring Cloud Data Flow supports many database types out-of-the-box,
so all the user typically has to do is declare the spring_datasource_* environment variables
to establish what data store Spring Cloud Data Flow will need.
So whatever database you decide to use for Spring Cloud Data Flow make sure that the your task also
includes that database dependency in its pom.xml or gradle.build file. If the database dependency
that is used by Spring Cloud Data Flow is not present in the Task Application, the task will fail
and the task execution will not be recorded.
49.2. A Common Data Store
Spring Cloud Data Flow and your task application must access the same datastore instance. This is so that the task executions recorded by the task application can be read by Spring Cloud Data Flow to list them in the Shell and Dashboard views. Also the task app must have read & write privileges to the task data tables that are used by Spring Cloud Data Flow.
Given the understanding of Datasource dependency between Task apps and Spring Cloud Data Flow, let’s review how to apply them in various Task orchestration scenarios.
49.2.1. Simple Task Launch
When launching a task from Spring Cloud Data Flow, Data Flow adds its datasource
properties (spring.datasource.url, spring.datasource.driverClassName, spring.datasource.username, spring.datasource.password)
to the app properties of the task being launched. Thus a task application
will record its task execution information to the Spring Cloud Data Flow repository.
49.2.2. Task Launcher Sink
The Task Launcher Sink allows tasks to be launched via a stream as discussed here. Since tasks launched by the Task Launcher Sink may not want their task executions recorded to the same datastore as Spring Cloud Data Flow, each TaskLaunchRequest received by the Task Launcher Sink must have the required datasource information established as app properties or command line arguments. Both TaskLaunchRequest-Transform and TriggerTask Source are examples of how a source and a processor allow a user to set the datasource properties via the app properties or command line arguments.
49.2.3. Composed Task Runner
Spring Cloud Data Flow allows a user to create a directed graph where each node
of the graph is a task application and this is done via the
Composed Task Runner.
In this case the rules that applied to a Simple Task Launch
or Task Launcher Sink apply to the composed task runner as well.
All child apps must also have access to the datastore that is being used by the composed task runner
Also, All child apps must have the same database dependency as the composed task runner enumerated in their pom.xml or gradle.build file.
49.2.4. Launching a task externally from Spring Cloud Data Flow
Users may wish to launch Spring Cloud Task applications via another method (scheduler for example) but still track the task execution via Spring Cloud Data Flow. This can be done so long as the task applications observe the rules specified here and here.
If a user wishes to use Spring Cloud Data Flow to view their
Spring Batch jobs, the user must make sure that
their batch application use the @EnableTask annotation and follow the rules enumerated here and here.
More information is available here.
|
Tasks on Cloud Foundry
50. Version Compatibility
The task functionality depends on the latest versions of PCF for runtime support. This release requires PCF version 1.7.12 or higher to run tasks. Tasks are an experimental feature in PCF 1.7 and 1.8 and a GA feature in PCF 1.9.
51. Tooling
It is important to note that there is no Apps Manager support for tasks as of this release. When running applications as tasks through Spring Cloud Data Flow, the only way is to view them within the context of CF CLI.
52. Task Database Schema
The database schema for Task applications was changed slighlty from the 1.0.x to 1.1.x version of Spring Cloud Task. Since Spring Cloud Data Flow automatically creates the database schema if it is not present upon server startup, you may need to update the schema if you ran a 1.0.x version of the Data Flow server and now are upgrading to the 1.1.x version. You can find the migration scripts here in the Spring Cloud Task Github repository. The documentation for Accessing Services with Diego SSH and this blog entry for connecting a GUI tools to the MySQL Service in PCF should help you to update the schema.
53. Running Task Applications
Running a task application within Spring Cloud Data Flow goes through a slightly different lifecycle than running a stream application. Both types of applications need to be registered with the appropriate artifact coordinates. Both need a definition created via the SCDF DSL. However, that’s where the similarities end.
With stream based applications, you "deploy" them with the intent that they run until they are undeployed. A stream definition is only deployed once (it can be scaled, but only deployed as one instance of the stream as a whole). However, tasks are launched. A single task definition can be launched many times. With each launch, they will start, execute, and shut down with PCF cleaning up the resources once the shutdown has occurred. The following sections outline the process of creating, launching, destroying, and viewing tasks.
53.1. Create a Task
Similar to streams, creating a task application is done via the SCDF DSL or through the dashboard. To create a task definition in SCDF, you’ve to either develop a task application or use one of the out-of-the-box task app-starters. The maven coordinates of the task application should be registered in SCDF. For more details on how to register task applications, review register task applications section from the core docs.
Let’s see an example that uses the out-of-the-box timestamp task application.
dataflow:>task create --name foo --definition "timestamp"
Created new task 'foo'| Tasks in SCDF do not require explicit deployment. They are required to be launched and with that there are different ways to launch them - refer to this section for more details. |
53.2. Launch a Task
Unlike streams, tasks in SCDF requires an explicit launch trigger or it can be manually kicked-off.
dataflow:>task launch foo
Launched task 'foo'53.3. View Task Logs
As previously mentioned, the CL CLI is the way to interact with tasks on PCF,
including viewing the logs. In order to view the logs as a task is executing use the
following command where foo is the name of the task you are executing:
cf v3-logs foo
Tailing logs for app foo...
....
....
....
....
2016-08-19T09:44:49.11-0700 [APP/TASK/bar1/0]OUT 2016-08-19 16:44:49.111 INFO 7 --- [ main] o.s.c.t.a.t.TimestampTaskApplication : Started TimestampTaskApplication in 2.734 seconds (JVM running for 3.288)
2016-08-19T09:44:49.13-0700 [APP/TASK/bar1/0]OUT Exit status 0
2016-08-19T09:44:49.19-0700 [APP/TASK/bar1/0]OUT Destroying container
2016-08-19T09:44:50.41-0700 [APP/TASK/bar1/0]OUT Successfully destroyed container| Logs are only viewable through the CF CLI as the app is running. Historic logs are not available. |
53.4. List Tasks
Listing tasks is as simple as:
dataflow:>task list
╔══════════════════════╤═════════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════╪═════════════════════════╪═══════════╣
║foo │timestamp │complete ║
╚══════════════════════╧═════════════════════════╧═══════════╝53.5. List Task Executions
If you’d like to view the execution details of the launched task, you could do the following.
dataflow:>task execution list
╔════════════════════════╤══╤═════════════════════════╤═════════════════════════╤════════╗
║ Task Name │ID│ Start Time │ End Time │ Exit ║
║ │ │ │ │ Code ║
╠════════════════════════╪══╪═════════════════════════╪═════════════════════════╪════════╣
║foo:cloud: │1 │ Fri Aug 19 09:44:49 PDT │Fri Aug 19 09:44:49 PDT │0 ║
╚════════════════════════╧══╧═════════════════════════╧═════════════════════════╧════════╝53.6. Destroy a Task
Destroying the task application from SCDF removes the task definition from task repository.
dataflow:>task destroy foo
Destroyed task 'foo'
dataflow:>task list
╔═════════╤═══════════════╤═══════════╗
║Task Name│Task Definition│Task Status║
╚═════════╧═══════════════╧═══════════╝53.7. Deleting Task From Cloud Foundry
Currently Spring Cloud Data Flow does not delete tasks deployed on a Cloud Foundry instance once they have been pushed. The only way to do this now is via CLI on a Cloud Foundry instance version 1.9 or above. This is done in 2 steps:
-
Obtain a list of the apps via the
cf appscommand. -
Identify the task app to be deleted and execute the
cf delete <task-name>command.
The task destroy <task-name> only deletes the definition and not the task
deployed on Cloud Foundry.
|
Dashboard
This section describes how to use the dashboard of Spring Cloud Data Flow.
54. Introduction
Spring Cloud Data Flow provides a browser-based GUI called the dashboard to manage the following information:
-
Apps: The Apps tab lists all available applications and provides the controls to register/unregister them.
-
Runtime: The Runtime tab provides the list of all running applications.
-
Streams: The Streams tab lets you list, design, create, deploy, and destroy Stream Definitions.
-
Tasks: The Tasks tab lets you list, create, launch and, destroy Task Definitions.
-
Jobs: The Jobs tab lets you perform batch job related functions.
-
Analytics: The Analytics tab lets you create data visualizations for the various analytics applications.
Upon starting Spring Cloud Data Flow, the dashboard is available at:
For example, if Spring Cloud Data Flow is running locally, the dashboard is available at http://localhost:9393/dashboard.
If you have enabled https, then the dashboard will be located at https://localhost:9393/dashboard.
If you have enabled security, a login form is available at http://localhost:9393/dashboard/#/login.
The default Dashboard server port is 9393.
|
The following image shows the opening page of the Spring Cloud Data Flow dashboard:
55. Apps
The Apps section of the dashboard lists all the available applications and provides the controls to register and unregister them (if applicable). It is possible to import a number of applications at once by using the Bulk Import Applications action.
The following image shows a typical list of available apps within the dashboard:
55.1. Bulk Import of Applications
The Bulk Import Applications page provides numerous options for defining and importing a set of applications all at once. For bulk import, the application definitions are expected to be expressed in a properties style, as follows:
<type>.<name> = <coordinates>
The following examples show a typical application definitions:
task.timestamp=maven://org.springframework.cloud.task.app:timestamp-task:1.2.0.RELEASE
processor.transform=maven://org.springframework.cloud.stream.app:transform-processor-rabbit:1.2.0.RELEASEAt the top of the bulk import page, a URI can be specified that points to a properties file stored elsewhere, it should contain properties formatted as shown in the previous example. Alternatively, by using the textbox labeled “Apps as Properties”, you can directly list each property string. Finally, if the properties are stored in a local file, the “Select Properties File” option opens a local file browser to select the file. After setting your definitions through one of these routes, click Import.
The following image shows the Bulk Import Applications page:
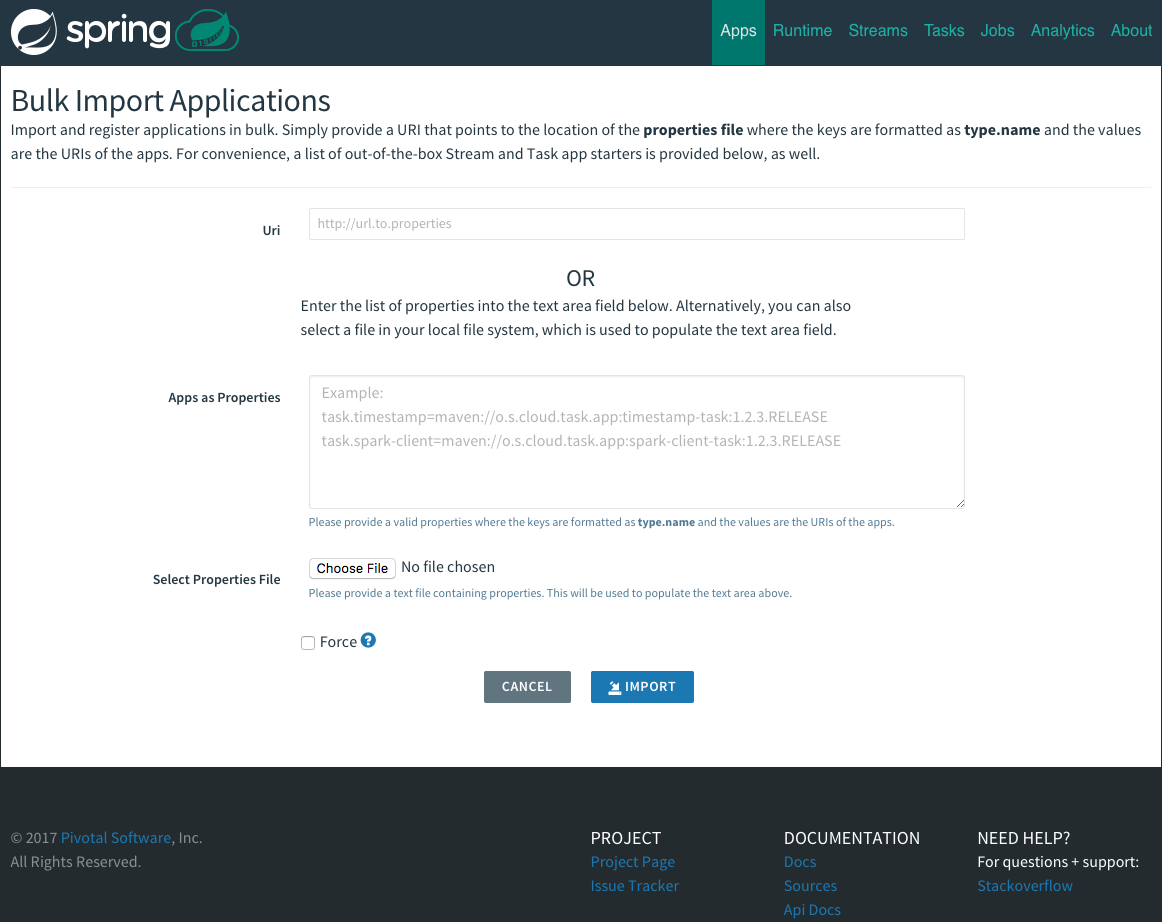
56. Runtime
The Runtime section of the Dashboard application shows the list of all running applications. For each runtime app, the state of the deployment and the number of deployed instances is shown. A list of the used deployment properties is available by clicking on the App Id.
The following image shows an example of the Runtime tab in use:
57. Streams
The Streams tab has two child tabs: Definitions and Create Stream. The following topics describe how to work with each one:
57.1. Working with Stream Definitions
The Streams section of the Dashboard includes the Definitions tab that provides a listing of Stream definitions. There you have the option to deploy or undeploy those stream definitions. Additionally, you can remove the definition by clicking on Destroy. Each row includes an arrow on the left, which you can click to see a visual representation of the definition. Hovering over the boxes in the visual representation shows more details about the apps, including any options passed to them.
In the following screenshot, the timer stream has been expanded to show the visual representation:
If you click the details button, the view changes to show a visual representation of that stream and any related streams.
In the preceding example, if you click details for the timer stream, the view changes to the following view, which clearly shows the relationship between the three streams (two of them are tapping into the timer stream):
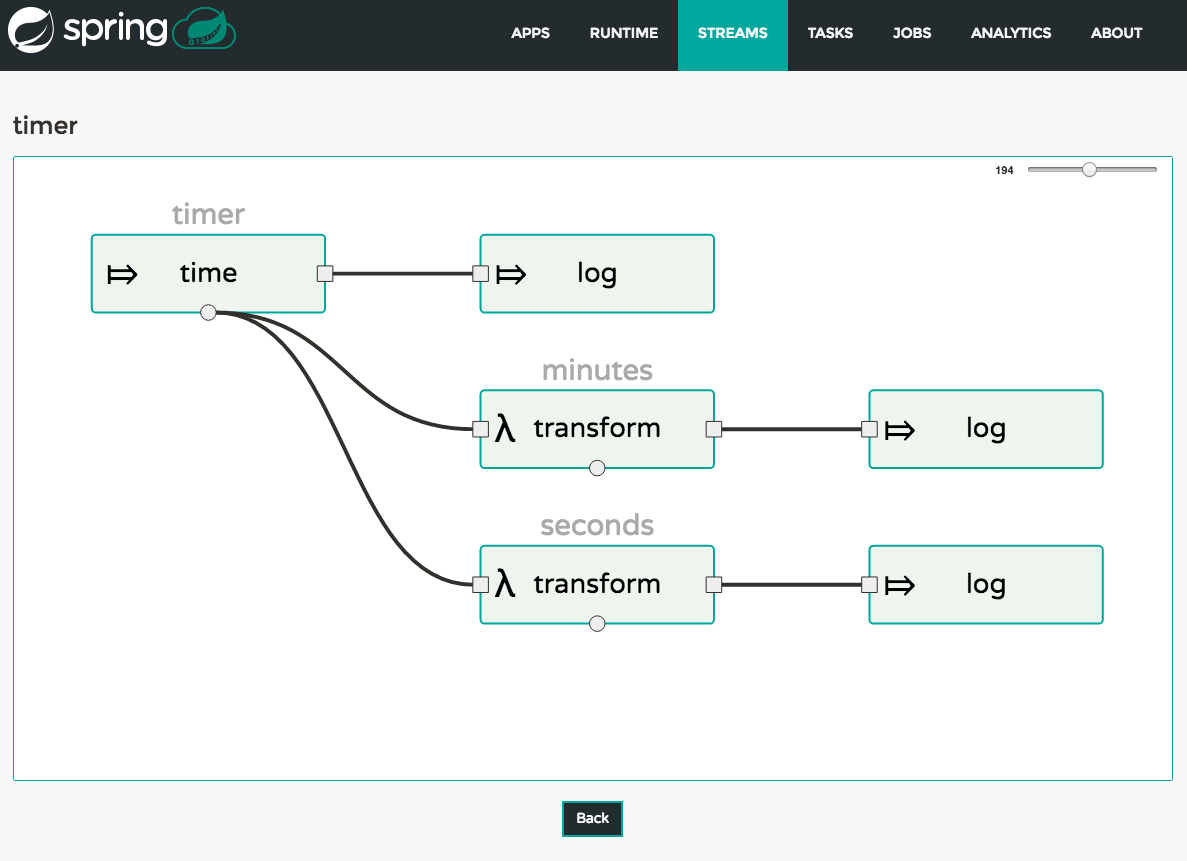
57.2. Creating a Stream
The Streams section of the Dashboard includes the Create Stream tab, which makes available the Spring Flo designer: a canvas application that offers an interactive graphical interface for creating data pipelines.
In this tab, you can:
-
Create, manage, and visualize stream pipelines using DSL, a graphical canvas, or both
-
Write pipelines via DSL with content-assist and auto-complete
-
Use auto-adjustment and grid-layout capabilities in the GUI for simpler and interactive organization of pipelines
You should watch this screencast that highlights some of the "Flo for Spring Cloud Data Flow" capabilities. The Spring Flo wiki includes more detailed content on core Flo capabilities.
The following image shows the Flo designer in use:
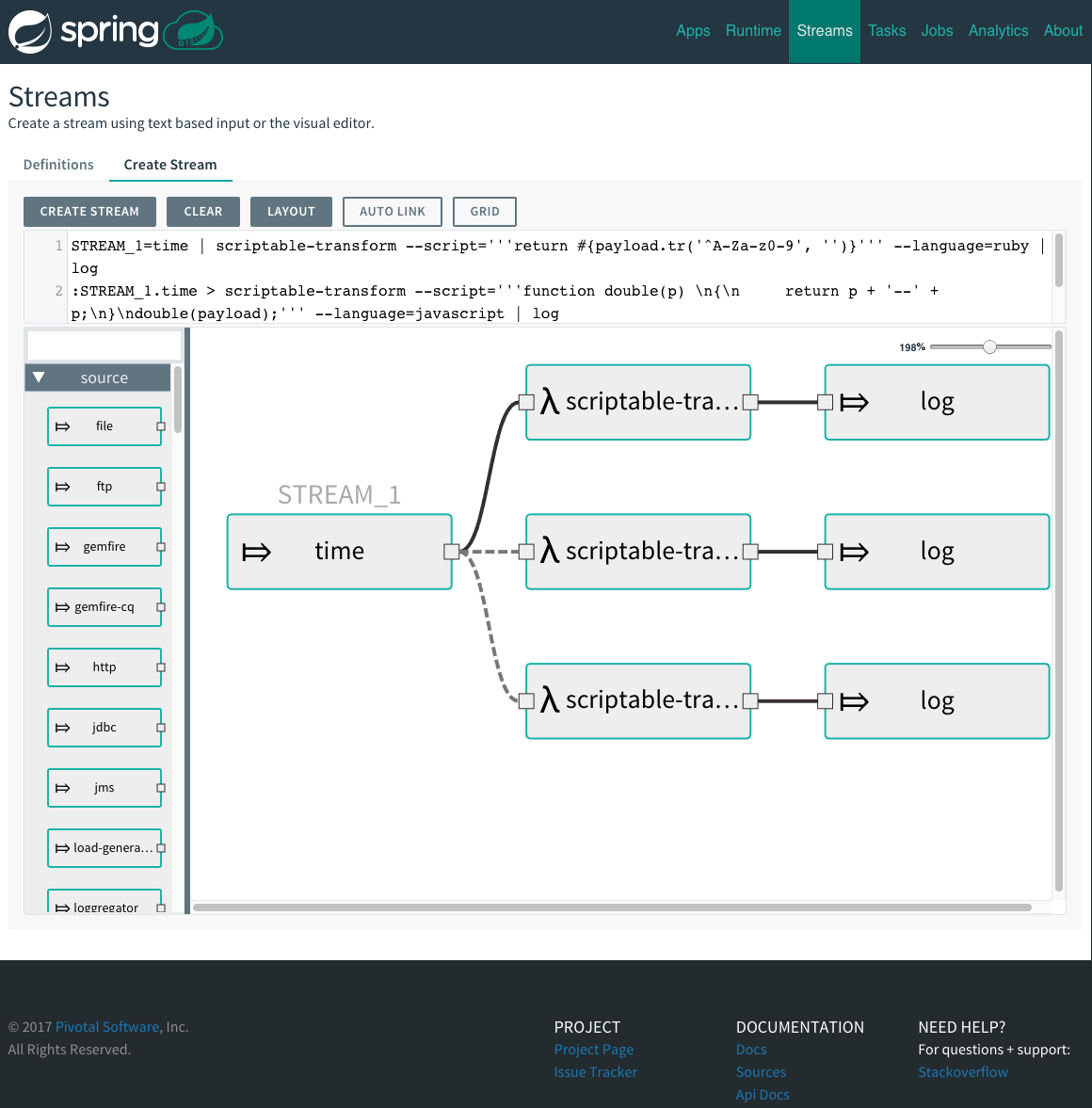
58. Tasks
The Tasks section of the Dashboard currently has three tabs:
58.1. Apps
Each app encapsulates a unit of work into a reusable component. Within the Data Flow runtime environment, apps let users create definitions for streams as well as tasks. Consequently, the Apps tab within the Tasks section lets users create task definitions.
| You can also use this tab to create Batch Jobs. |
The following image shows a typical list of task apps:
On this screen, you can perform the following actions:
-
View details, such as the task app options.
-
Create a task definition from the respective app.
58.1.1. View Task App Details
On this page you can view the details of a selected task app, including the list of available options (properties) for that app.
58.1.2. Create a Task Definition from a Selected Task App
On this screen you can create a new Task Definition. At a minimum, you must provide a name for the new definition. You also have the option to specify various properties that are used during the deployment of the app.
| Each parameter is included only if the Include checkbox is selected. |
58.2. Definitions
This page lists the Data Flow task definitions and provides actions to launch or destroy those tasks. It also provides a shortcut operation to define one or more tasks with simple textual input, indicated by the Bulk Define Tasks button.
The following image shows the Definitions page:
58.2.1. Creating Task Definitions with the Bulk Define Interface
After pressing Bulk Define Tasks, the following screen appears:
It includes a textbox where one or more definitions can be entered and, for each definition, various actions that can be performed. Each line of the text input should be formatted as follows:
<task-definition-name> = <task-application> <options>
For example, the following line defines an a task called demo-timestamp:
demo-timestamp = timestamp --format=hhmmss
After entering any data, a validator runs asynchronously to verify the syntax, that the application name entered is a valid application, and that it supports the options specified. If validation fails, the editor shows the errors with more information available in tooltips.
To make it easier to enter definitions into the text area, content assist is supported. Pressing Ctrl+Space invokes content assist to suggest simple task names (based on the line on which it is invoked), task applications, and task application options. Press Escape to close the content assist window without choosing a selection.
If the validator should not verify the applications or the options (for example, when specifying non-whitelisted options to the applications), you can turn off that part of validation by toggling the checkbox off on the Verify Apps button. The validator then performs only syntax checking. When an app is correctly validated, the Create button becomes clickable. Clicking it causes the creation of each task definition. If there are any errors during creation, then, after creation finishes, the editor shows any lines of input that cannot be used in task definitions. These can then be fixed, and the creation process can be repeated. The Import File button opens a file browser on the local file system, for those cases where the definitions are in a file and it is easier to import than copy and paste.
| Bulk loading of composed task definitions is not currently supported. |
58.2.2. Creating Composed Task Definitions
The dashboard includes the Create Composed Task tab, which provides an interactive graphical interface for creating composed tasks.
In this tab, you can:
-
Create and visualize composed tasks using DSL, a graphical canvas, or both.
-
Use auto-adjustment and grid-layout capabilities in the GUI for simpler and interactive organization of the composed task.
On the Create Composed Task screen, you can define one or more task parameters by entering both the parameter key and the parameter value.
| Task parameters are not typed. |
The following image shows the composed task designer:
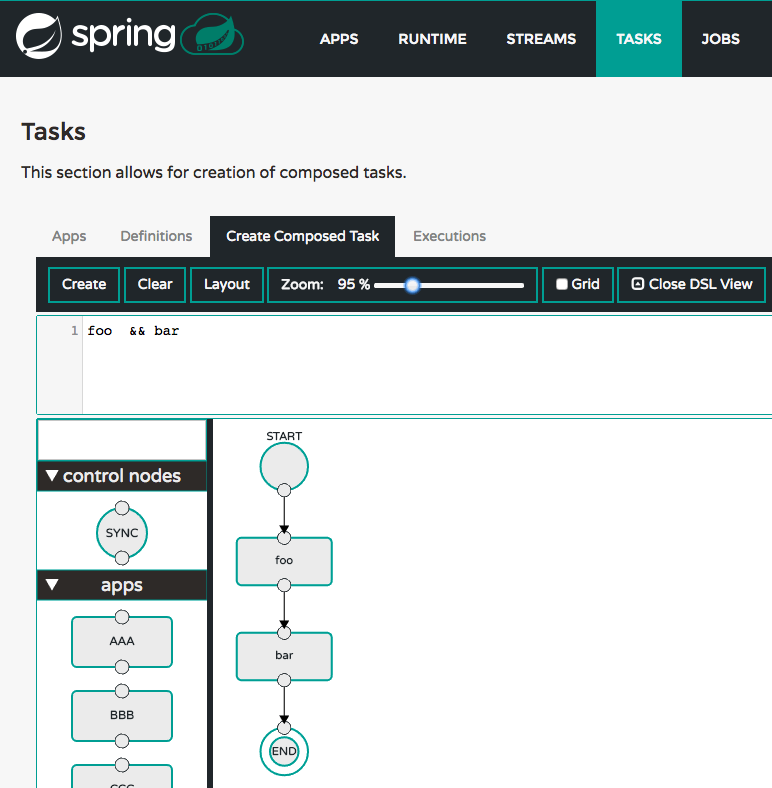
58.2.3. Launching Tasks
Once the task definition has been created, the tasks can be launched through the dashboard.
To do so, click the Definitions tab and select the task you want to launch by pressing Launch.
58.3. Executions
The Executions tab shows the current running and completed tasks.
The following image shows the Executions tab:
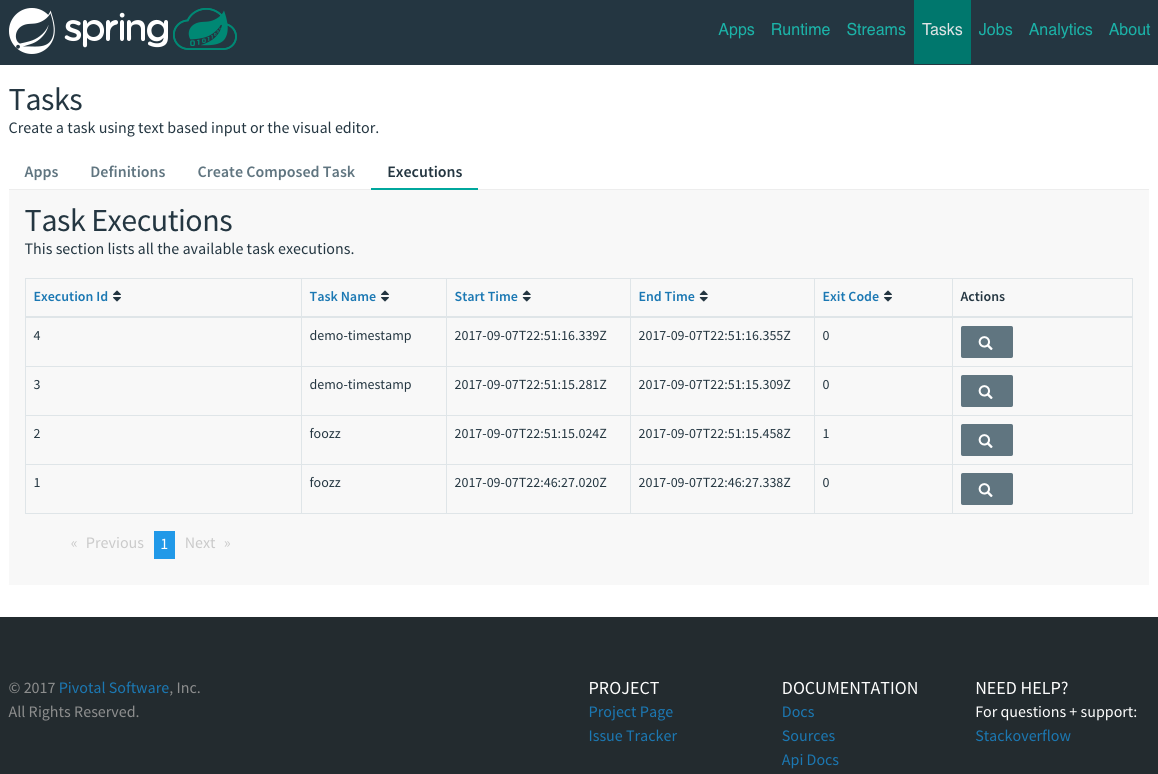
59. Jobs
The Jobs section of the Dashboard lets you inspect batch jobs. The main section of the screen provides a list of job executions. Batch jobs are tasks that each execute one or more batch jobs. Each job execution has a reference to the task execution ID (in the Task Id column).
The list of Job Executions also shows the state of the underlying Job Definition. Thus, if the underlying definition has been deleted, “No definition found” appears in the Status column.
You can take the following actions for each job:
-
Restart (for failed jobs).
-
Stop (for running jobs).
-
View execution details.
Note: Clicking the stop button actually sends a stop request to the running job, which may not immediately stop.
The following image shows the Jobs page:
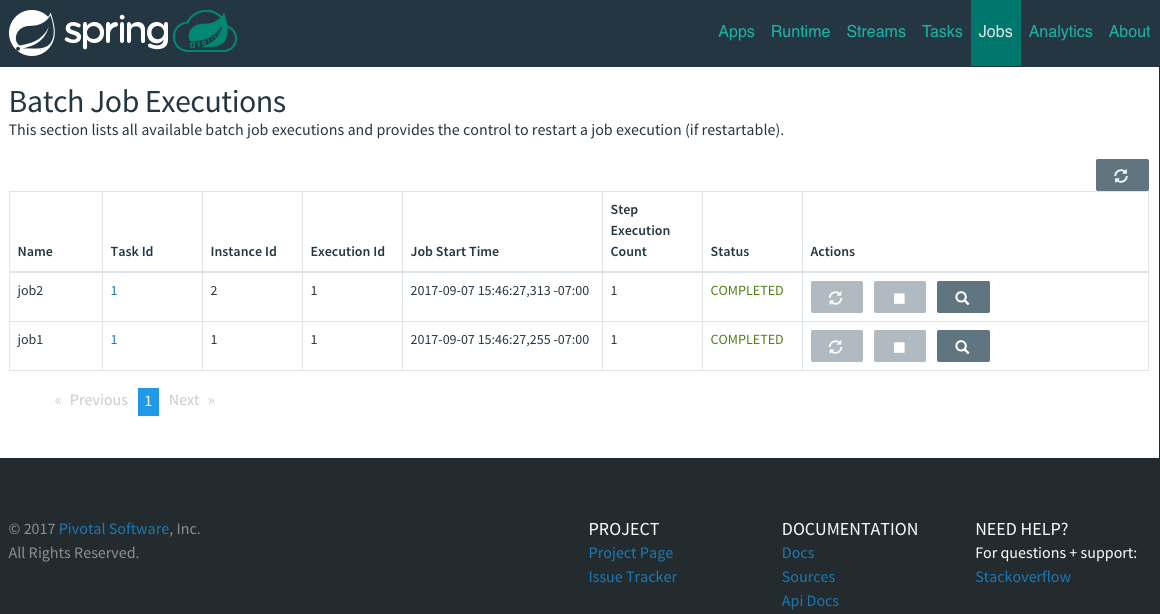
59.1. Job Execution Details
After having launched a batch job, the Job Execution Details page will show information about the job.
The following image shows the Job Execution Details page:
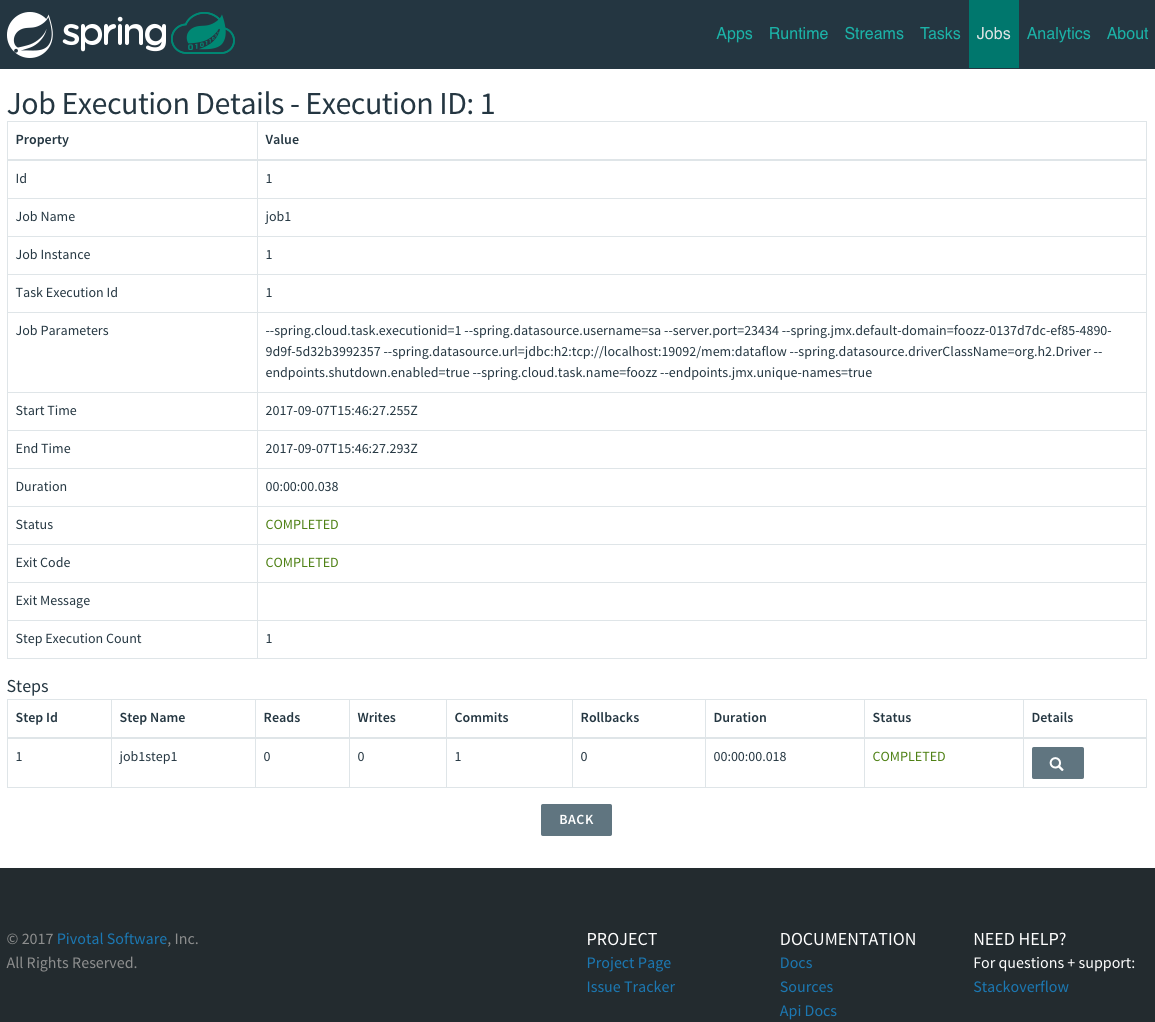
The Job Execution Details page contains a list of the executed steps. You can further drill into the details of each step’s execution by clicking the magnifying glass icon.
59.2. Step Execution Details
The Step Execution Details page provides information about an individual step within a job.
The following image shows the Step Execution Details page:
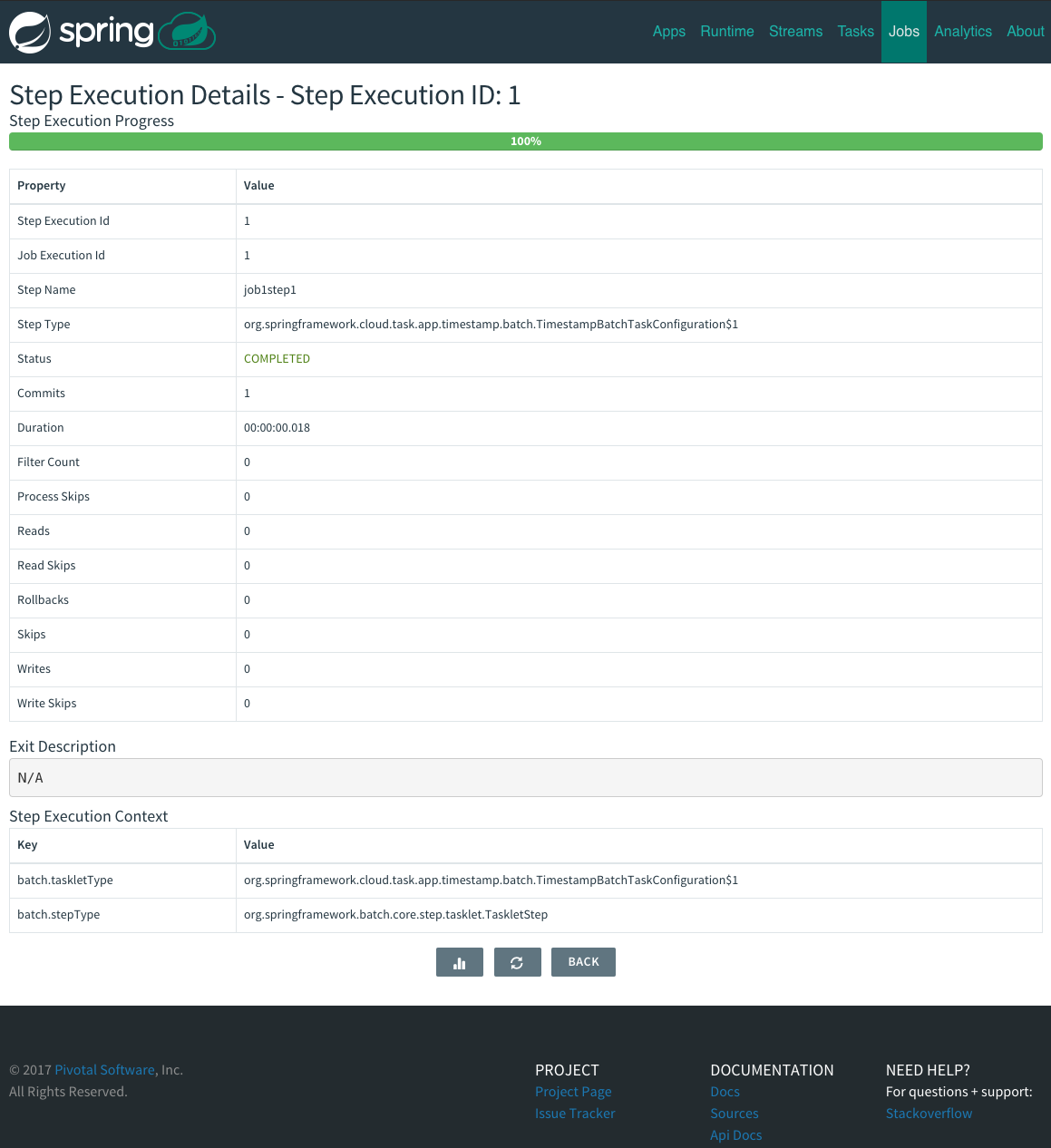
On the top of the page, you can see a progress indicator the respective step, with the option to refresh the indicator. A link is provided to view the step execution history.
The Step Execution Details screen provides a complete list of all Step Execution Context key/value pairs.
| For exceptions, the Exit Description field contains additional error information. However, this field can have a maximum of 2500 characters. Therefore, in the case of long exception stack traces, trimming of error messages may occur. When that happens, refer to the server log files for further details. |
59.3. Step Execution Progress
On this screen, you can see a progress bar indicator in regards to the execution of the current step. Under the Step Execution History, you can also view various metrics associated with the selected step, such as duration, read counts, write counts, and others.
60. Analytics
The Analytics page of the Dashboard provides the following data visualization capabilities for the various analytics applications available in Spring Cloud Data Flow:
-
Counters
-
Field-Value Counters
-
Aggregate Counters
For example, if you create a stream with a Counter application, you can create the corresponding graph from within the Dashboard tab. To do so:
-
Under
Metric Type, selectCountersfrom the select box. -
Under
Stream, selecttweetcount. -
Under
Visualization, select the desired chart option,Bar Chart.
Using the icons to the right, you can add additional charts to the Dashboard, re-arange the order of created dashboards, or remove data visualizations.
REST API Guide
Appendices
Having trouble with Spring Cloud Data Flow, We’d like to help!
-
Ask a question - we monitor stackoverflow.com for questions tagged with
spring-cloud-dataflow. -
Report bugs with Spring Cloud Data Flow at github.com/spring-cloud/spring-cloud-dataflow/issues.
-
Report bugs with Spring Cloud Data Flow for Cloud Foundry at github.com/spring-cloud/spring-cloud-dataflow-server-cloudfoundry/issues.
Appendix A: Data Flow Template
As described in the previous chapter, Spring Cloud Data Flow’s functionality is completely exposed through REST endpoints. While you can use those endpoints directly, Spring Cloud Data Flow also provides a Java-based API, which makes using those REST endpoints even easier.
The central entry point is the DataFlowTemplate class in the org.springframework.cloud.dataflow.rest.client package.
This class implements the DataFlowOperations interface and delegates to the following sub-templates that provide the specific functionality for each feature-set:
| Interface | Description |
|---|---|
|
REST client for stream operations |
|
REST client for counter operations |
|
REST client for field value counter operations |
|
REST client for aggregate counter operations |
|
REST client for task operations |
|
REST client for job operations |
|
REST client for app registry operations |
|
REST client for completion operations |
|
REST Client for runtime operations |
When the DataFlowTemplate is being initialized, the sub-templates can be discovered through the REST relations, which are provided by HATEOAS.[1]
| If a resource cannot be resolved, the respective sub-template results in NULL. A common cause is that Spring Cloud Data Flow offers for specific sets of features to be enabled/disabled when launching. For more information, see “Feature Toggles”. |
A.1. Using the Data Flow Template
When you use the Data Flow Template, the only needed Data Flow dependency is the Spring Cloud Data Flow Rest Client, as shown in the following Maven snippet:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dataflow-rest-client</artifactId>
<version>1.3.0.RELEASE</version>
</dependency>With that dependency, you get the DataFlowTemplate class as well as all the dependencies needed to make calls to a Spring Cloud Data Flow server.
When instantiating the DataFlowTemplate, you also pass in a RestTemplate.
Please be aware that the needed RestTemplate requires some additional configuration to be valid in the context of the DataFlowTemplate.
When declaring a RestTemplate as a bean, the following configuration suffices:
@Bean
public static RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate();
restTemplate.setErrorHandler(new VndErrorResponseErrorHandler(restTemplate.getMessageConverters()));
for(HttpMessageConverter<?> converter : restTemplate.getMessageConverters()) {
if (converter instanceof MappingJackson2HttpMessageConverter) {
final MappingJackson2HttpMessageConverter jacksonConverter =
(MappingJackson2HttpMessageConverter) converter;
jacksonConverter.getObjectMapper()
.registerModule(new Jackson2HalModule())
.addMixIn(JobExecution.class, JobExecutionJacksonMixIn.class)
.addMixIn(JobParameters.class, JobParametersJacksonMixIn.class)
.addMixIn(JobParameter.class, JobParameterJacksonMixIn.class)
.addMixIn(JobInstance.class, JobInstanceJacksonMixIn.class)
.addMixIn(ExitStatus.class, ExitStatusJacksonMixIn.class)
.addMixIn(StepExecution.class, StepExecutionJacksonMixIn.class)
.addMixIn(ExecutionContext.class, ExecutionContextJacksonMixIn.class)
.addMixIn(StepExecutionHistory.class, StepExecutionHistoryJacksonMixIn.class);
}
}
return restTemplate;
}Now you can instantiate the DataFlowTemplate with the following code:
DataFlowTemplate dataFlowTemplate = new DataFlowTemplate(
new URI("http://localhost:9393/"), restTemplate); (1)| 1 | The URI points to the ROOT of your Spring Cloud Data Flow Server. |
Depending on your requirements, you can now make calls to the server. For instance, if you want to get a list of currently available applications you can run the following code:
PagedResources<AppRegistrationResource> apps = dataFlowTemplate.appRegistryOperations().list();
System.out.println(String.format("Retrieved %s application(s)",
apps.getContent().size()));
for (AppRegistrationResource app : apps.getContent()) {
System.out.println(String.format("App Name: %s, App Type: %s, App URI: %s",
app.getName(),
app.getType(),
app.getUri()));
}Appendix B: Spring XD to SCDF
This appendix describes how to migrate from Spring XD to Spring Cloud Data Flow, along with some tips and tricks that may be helpful.
B.1. Terminology Changes
The following table describes the changes in terminology from Spring XD to Spring Cloud Data Flow:
| Old | New |
|---|---|
XD-Admin |
Server (implementations: local, Cloud Foundry, Apache Yarn, Kubernetes, and Apache Mesos) |
XD-Container |
N/A |
Modules |
Applications |
Admin UI |
Dashboard |
Message Bus |
Binders |
Batch / Job |
Task |
B.2. Modules to Applications
If you have custom Spring XD modules, you need refactor them to use Spring Cloud Stream and Spring Cloud Task annotations. As part of that work, you need to update dependencies and build them as normal Spring Boot applications.
B.2.1. Custom Applications
As you convert custom applications, keep the following information in mind:
-
Spring XD’s stream and batch modules are refactored into the Spring Cloud Stream and Spring Cloud Task application-starters, respectively. These applications can be used as the reference while refactoring Spring XD modules.
-
There are also some samples for Spring Cloud Stream and Spring Cloud Task applications for reference.
-
If you want to create a brand new custom application, use the getting started guide for Spring Cloud Stream and Spring Cloud Task applications and as well as review the develeopment guide.
-
Alternatively, if you want to patch any of the out-of-the-box stream applications, you can follow the procedure described here.
B.2.2. Application Registration
As you register your applications, keep the following information in mind:
-
Custom Stream/Task applications require being installed to a Maven repository for local, Yarn, and Cloud Foundry implementations or, as docker images, when deploying to Kubernetes or Mesos. Other than Maven and docker resolution, you can also resolve application artifacts from
http,file, or ashdfscoordinates. -
Unlike Spring XD, you do not have to upload the application bits while registering custom applications anymore. Instead, you need to register the application coordinates that are hosted in the Maven repository or by other means as discussed in the previous bullet.
-
By default, none of the out-of-the-box applications are preloaded. It is intentionally designed to provide the flexibility to register apps as you find appropriate for the given use-case requirement.
-
Depending on the binder choice, you can manually add the appropriate binder dependency to build applications specific to that binder-type. Alternatively, you can follow the Spring Initializr procedure to create an application with binder embedded in it.
B.2.3. Application Properties
As you modify your applications' properties, keep the following information in mind:
-
Counter-sink:
-
The peripheral
redisis not required in Spring Cloud Data Flow. If you intend to use thecounter-sink, thenredisis required, and you need to have your own runningrediscluster.
-
-
field-value-counter-sink:
-
The peripheral
redisis not required in Spring Cloud Data Flow. If you intend to use thefield-value-counter-sink, thenredisbecomes required, and you need to have your own runningrediscluster.
-
-
Aggregate-counter-sink:
-
The peripheral
redisis not required in Spring Cloud Data Flow. If you intend to use theaggregate-counter-sink, thenredisbecomes required, and you need to have your own runningrediscluster.
-
B.3. Message Bus to Binders
Terminology wise, in Spring Cloud Data Flow, the message bus implementation is commonly referred to as binders.
B.3.1. Message Bus
Similar to Spring XD, Spring Cloud Data Flow includes an abstraction that you can use to extend the binder interface. By default, we take the opinionated view of Apache Kafka and RabbitMQ as the production-ready binders. They are available as GA releases.
B.3.2. Binders
Selecting a binder requires providing the right binder dependency in the classpath. If you choose Kafka as the binder, you need to register stream applications that are pre-built with Kafka binder in it. If you to create a custom application with Kafka binder, you need add the following dependency in the classpath:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
<version>1.0.2.RELEASE</version>
</dependency>-
Spring Cloud Stream supports Apache Kafka and RabbitMQ. All binder implementations are maintained and managed in their individual repositories.
-
Every Stream/Task application can be built with the binder implementation of your choice. All the out-of-the-box applications are pre-built for both Kafka and Rabbit and are readily available for use as Maven artifacts (Spring Cloud Stream or Spring Cloud Task) or as Docker images (Spring Cloud Stream or Spring Cloud Task). Changing the binder requires selecting the right binder dependency. Alternatively, you can download the pre-built application from this version of Spring Initializr with the desired “binder-starter” dependency.
B.3.3. Named Channels
Fundamentally, all the messaging channels are backed by pub/sub semantics.
Unlike Spring XD, the messaging channels are backed only by topics or topic-exchange and there is no representation of queues in the new architecture.
-
${xd.module.index}is no longer supported. Instead, you can directly interact with named destinations. -
stream.indexchanges to:<stream-name>.<label/app-name>-
For example,
ticktock.0changes to:ticktock.time.
-
-
“topic/queue” prefixes are not required to interact with named-channels.
-
For example,
topic:mytopicchanges to:mytopic. -
For example,
stream create stream1 --definition ":foo > log".
-
B.3.4. Directed Graphs
If you build non-linear streams, you can take advantage of named destinations to build directed graphs.
Consider the following example from Spring XD:
stream create f --definition "queue:foo > transform --expression=payload+'-sample1' | log" --deploy
stream create b --definition "queue:bar > transform --expression=payload+'-sample2' | log" --deploy
stream create r --definition "http | router --expression=payload.contains('a')?'queue:sample1':'queue:sample2'" --deployYou can do the following in Spring Cloud Data Flow:
stream create f --definition ":foo > transform --expression=payload+'-sample1' | log" --deploy
stream create b --definition ":bar > transform --expression=payload+'-sample2' | log" --deploy
stream create r --definition "http | router --expression=payload.contains('a')?'sample1':'sample2'" --deployB.4. Batch to Tasks
A Task, by definition, is any application that does not run forever, and they end at some point. Tasks include Spring Batch jobs. Task applications can be used for on-demand use cases, such as database migration, machine learning, scheduled operations, and others. With Spring Cloud Task, you can build Spring Batch jobs as microservice applications.
-
Spring Batch jobs from Spring XD are being refactored to Spring Boot applications, also known as Spring Cloud Task applications.
-
Unlike Spring XD, these tasks do not require explicit deployment. Instead, a task is ready to be launched directly once the definition is declared.
B.5. Shell and DSL Command Changes
The following table shows the changes to shell and DSL commands:
| Old Command | New Command |
|---|---|
module upload |
app register / app import |
module list |
app list |
module info |
app info |
admin config server |
dataflow config server |
job create |
task create |
job launch |
task launch |
job list |
task list |
job status |
task status |
job display |
task display |
job destroy |
task destroy |
job execution list |
task execution list |
runtime modules |
runtime apps |
B.6. REST API Changes
The following table shows the changes to the REST API:
| Old API | New API |
|---|---|
/modules |
/apps |
/runtime/modules |
/runtime/apps |
/runtime/modules/{moduleId} |
/runtime/apps/{appId} |
/jobs/definitions |
/task/definitions |
/jobs/deployments |
/task/deployments |
B.7. UI (including Flo)
The Admin-UI is now named Dashboard. The URI for accessing the Dashboard is changed from
localhost:9393/admin-ui to localhost:9393/dashboard.
-
Apps (a new view): Lists all the registered applications that are available for use. This view includes details such as the URI and the properties supported by each application. You can also register/unregister applications from this view.
-
Runtime (was Container): Container changes to Runtime. The notion of
xd-containeris gone, replaced by out-of-the-box applications running as autonomous Spring Boot applications. The Runtime tab displays the applications running in the runtime platforms (implementations: Cloud Foundry, Apache Yarn, Apache Mesos, or Kubernetes). You can click on each application to review relevant details, such as where it is running, what resources it uses, and other details. -
Spring Flo is now an OSS product. Flo for Spring Cloud Data Flow’s “Create Stream” is now the designer-tab in the Dashboard.
-
Tasks (a new view):
-
The “Modules” sub-tab is renamed to “Apps”.
-
The “Definitions” sub-tab lists all the task definitions, including Spring Batch jobs that are orchestrated as tasks.
-
The “Executions” sub-tab lists all the task execution details in a fashion similar to the listing of Spring XD’s Job executions.
-
B.8. Architecture Components
Spring Cloud Data Flow comes with a significantly simplified architecture. In fact, when compared with Spring XD, you need fewer peripherals to use Spring Cloud Data Flow.
B.8.1. ZooKeeper
ZooKeeper is not used in the new architecture.
B.8.2. RDBMS
Spring Cloud Data Flow uses an RDBMS instead of Redis for stream/task definitions, application registration, and for job repositories. The default configuration uses an embedded H2 instance, but Oracle, DB2, SqlServer, MySQL/MariaDB, PostgreSQL, H2, and HSQLDB databases are supported. To use Oracle, DB2, and SqlServer, you need to create your own Data Flow Server by using Spring Initializr and add the appropriate JDBC driver dependency.
B.8.3. Redis
Running a Redis cluster is only required for analytics functionality.
Specifically, when you use the counter-sink, field-value-counter-sink, or aggregate-counter-sink applications, you also need to have a running instance of Redis cluster.
B.8.4. Cluster Topology
Spring XD’s xd-admin and xd-container server components are replaced by stream and task applications that are themselves running as autonomous Spring Boot applications.
The applications run natively on various platforms, including Cloud Foundry, Apache YARN, Apache Mesos, and Kubernetes.
You can develop, test, deploy, scale up or down, and interact with (Spring Boot) applications individually, and they can evolve in isolation.
B.9. Central Configuration
To support centralized and consistent management of an application’s configuration properties, Spring Cloud Config client libraries have been included in the Spring Cloud Data Flow server as well as the Spring Cloud Stream applications provided by the Spring Cloud Stream App Starters. You can also pass common application properties to all streams when the Data Flow Server starts.
B.10. Distribution
Spring Cloud Data Flow is a Spring Boot application. Depending on the platform of your choice, you can download the respective release uber jar and deploy or push it to the runtime platform (Cloud Foundry, Apache Yarn, Kubernetes, or Apache Mesos). For example, if you run Spring Cloud Data Flow on Cloud Foundry, you can download the Cloud Foundry server implementation and do a cf push, as explained in the Cloud Foundry Reference Guide.
B.11. Hadoop Distribution Compatibility
The hdfs-sink application builds upon Spring Hadoop 2.4.0 release, so this application is compatible
with the following Hadoop distributions:
-
Cloudera: cdh5
-
Pivotal Hadoop: phd30
-
Hortonworks Hadoop: hdp24
-
Hortonworks Hadoop: hdp23
-
Vanilla Hadoop: hadoop26
-
Vanilla Hadoop: 2.7.x (default)
B.12. YARN Deployment
Spring Cloud Data Flow can be deployed and used with Apche YARN in two different ways:
B.13. Use Case Comparison
The remainder of this appendix reviews some use cases to show the differences between Spring XD and Spring Cloud Data Flow.
B.13.1. Use Case #1: Ticktock
This use case assumes that you have already downloaded both the XD and the SCDF distributions.
Description: Simple ticktock example using local/singlenode.
The following table describes the differences:
| Spring XD | Spring Cloud Data Flow |
|---|---|
Start an
|
Start a binder of your choice Start a
|
Start an
|
Start
|
Create
|
Create
|
Review |
Review |
B.13.2. Use Case #2: Stream with Custom Module or Application
This use case assumes that you have already downloaded both the XD and the SCDF distributions.
Description: Stream with custom module or application.
The following table describes the differences:
| Spring XD | Spring Cloud Data Flow |
|---|---|
Start an
|
Start a binder of your choice Start a
|
Start an
|
Start
|
Register a custom “processor” module to transform the payload to the desired format
|
Register custom “processor” application to transform payload to a desired format
|
Create a stream with a custom module
|
Create a stream with custom application
|
Review results in the |
Review results by using the |
B.13.3. Use Case #3: Batch Job
This use case assumes that you have already downloaded both the XD and the SCDF distributions.
Description: batch-job.
| Spring XD | Spring Cloud Data Flow |
|---|---|
Start an
|
Start a
|
Start an
|
Start
|
Register a custom “batch job” module
|
Register a custom “batch-job” as task application
|
Create a job with custom batch-job module
|
Create a task with a custom batch-job application
|
Deploy job
|
NA |
Launch job
|
Launch task
|
Review results in the |
Review results by using the |
Appendix C: Building
To build the source, you need to install JDK 1.8.
The build uses the Maven wrapper so that you do not have to install a specific version of Maven. To enable the tests for Redis, run the server before building. More information on how to run Redis appears later in this appendix.
The main build command is as follows:
$ ./mvnw clean install
If you like, you can add '-DskipTests' to avoid running the tests.
You can also install Maven (>=3.3.3) yourself and run the mvn command in place of ./mvnw in the examples below.
If you do that, you also might need to add -P spring if your local Maven settings do not contain repository declarations for Spring pre-release artifacts.
|
You might need to increase the amount of memory available to Maven by setting a MAVEN_OPTS environment variable with a value similar to -Xmx512m -XX:MaxPermSize=128m.
We try to cover this in the .mvn configuration, so, if you find you have to do it to make a build succeed, please raise a ticket to get the settings added to source control.
|
C.1. Documentation
There is a full profile that generates documentation. You can build only the documentation by using the following command:
$ ./mvnw clean package -DskipTests -P full -pl spring-cloud-dataflow-server-cloudfoundry-docs -am
C.2. Working with the Code
If you do not have an IDE preference, we recommend that you use Spring Tools Suite or Eclipse when working with the code. We use the m2eclipse Eclipse plugin for Maven support. Other IDEs and tools generally also work without issue.
C.2.1. Importing into Eclipse with m2eclipse
We recommend the m2eclipe eclipse plugin when working with Eclipse. If you do not already have m2eclipse installed, it is available from the Eclipse marketplace.
Unfortunately, m2e does not yet support Maven 3.3.
Consequently, once the projects are imported into Eclipse, you also need to tell m2eclipse to use the .settings.xml file for the projects.
If you do not do this, you may see many different errors related to the POMs in the projects.
To do so:
-
Open your Eclipse preferences.
-
Expand the Maven preferences.
-
Select User Settings.
-
In the User Settings field, click Browse and navigate to the Spring Cloud project you imported.
-
Select the
.settings.xmlfile in that project. -
Click Apply.
-
Click OK.
Alternatively, you can copy the repository settings from Spring Cloud’s .settings.xml file into your own ~/.m2/settings.xml.
|
C.2.2. Importing into Eclipse without m2eclipse
If you prefer not to use m2eclipse, you can generate Eclipse project metadata by using the following command:
$ ./mvnw eclipse:eclipse
The generated Eclipse projects can be imported by selecting Import existing projects
from the File menu.
Appendix D: Contributing
Spring Cloud is released under the non-restrictive Apache 2.0 license and follows a very standard Github development process, using Github tracker for issues and merging pull requests into master. If you want to contribute even something trivial, please do not hesitate, but follow the guidelines below.
D.1. Sign the Contributor License Agreement
Before we accept a non-trivial patch or pull request, we need you to sign the contributor’s agreement. Signing the contributor’s agreement does not grant anyone commit rights to the main repository, but it does mean that we can accept your contributions, and you will get an author credit if we do. Active contributors might be asked to join the core team and be given the ability to merge pull requests.
D.2. Code Conventions and Housekeeping
None of the following guidelines is essential for a pull request, but they all help your fellow developers understand and work with your code. They can also be added after the original pull request but before a merge.
-
Use the Spring Framework code format conventions. If you use Eclipse, you can import formatter settings by using the
eclipse-code-formatter.xmlfile from the Spring Cloud Build project. If using IntelliJ, you can use the Eclipse Code Formatter Plugin to import the same file. -
Make sure all new
.javafiles have a simple Javadoc class comment with at least an@authortag identifying you, and preferably at least a paragraph describig the class’s purpose. -
Add the ASF license header comment to all new
.javafiles (to do so, copy from existing files in the project). -
Add yourself as an
@authorto the .java files that you modify substantially (more than cosmetic changes). -
Add some Javadocs and, if you change the namespace, some XSD doc elements.
-
A few unit tests would help a lot as well. Someone has to do it, and your fellow developers appreciate the effort.
-
If no one else uses your branch, rebase it against the current master (or other target branch in the main project).
-
When writing a commit message, follow these conventions. If you fix an existing issue, add
Fixes gh-XXXX(where XXXX is the issue number) at the end of the commit message.