Ambari basically automates YARN installation instead of requiring user to do it manually. Also a lot of other configuration steps are automated as much as possible to easy overall installation process.
There is no difference on components deployed into ambari comparing of a manual usage with a separate YARN cluster. With ambari we simply package needed dataflow components into a rpm package so that it can be managed as an ambari service. After that ambari really only manage a runtime configuration of those components.
Generally it is only needed to install scdf-plugin-hdp plugin into
ambari server which adds needed service definitions.
[root@ambari-1 ~]# yum -y install ambari-server [root@ambari-1 ~]# ambari-server setup -s [root@ambari-1 ~]# wget -nv http://repo.spring.io/yum-snapshot-local/scdf/1.1.2/scdf-snapshot-1.1.2.repo -O /etc/yum.repos.d/scdf-snapshot-1.1.2.repo [root@ambari-1 ~]# yum -y install scdf-plugin-hdp [root@ambari-1 ~]# ambari-server start
![[Note]](images/note.png) | Note |
|---|---|
Ambari plugin only works for redhat6/redhat7 and related centos based systems for now. |
When you create your cluster and choose a stack, make sure that
redhat6 or/and redhat7 sections contains repository named
SCDF-1.1.2 and that it points to
repo.spring.io/yum-snapshot-local/scdf/1.1.2.
Ambari 2.4 contains major rewrites for stack definitions and how it
is possible to integrate with those from external contributions. Our
plugin will eventually integrate via extensions or management packs,
but for now you need to choose stack marked as a Default Version
Definition which contains correct yum repository. For example with
HDP 2.5 you have two default choices, HDP-2.5.0.0 and HDP-2.5
(Default Version Definition). As mentioned you need to pick latter.
With older ambari versions you don’t have these new options.
From services choose Spring Cloud Data Flow and Kafka. Hdfs,
Yarn and Zookeeper are forced dependencies.
| Note |
|---|---|
With |
Then in Customize Services what is really left for user to do is to customise settings if needed. Everything else is automatically configured. Technically it also allows you to switch to use rabbit by leaving Kafka out and defining rabbit settings there. But generally use of Kafka is a good choice.
| Note |
|---|---|
We also install H2 DB as service so that it can be accessed from every node. |
servers.yml file is also used to store common configuration with
Ambari. Settings in Advanced scdf-site and Custom scdf-site are
used to dynamically create a this file which is then copied over to
hdfs when needed application files are deployd.
Every additional entry added via Custom scdf-site is added into
servers.yml as is and overrides everything else in it.
![[Important]](images/important.png) | Important |
|---|---|
If ambari configuration is modified, you need to delete
|
Ambari managed service defaults to H2 database. We currently support
using MySQL, PostgreSQL and HSQLDB as external datasources.
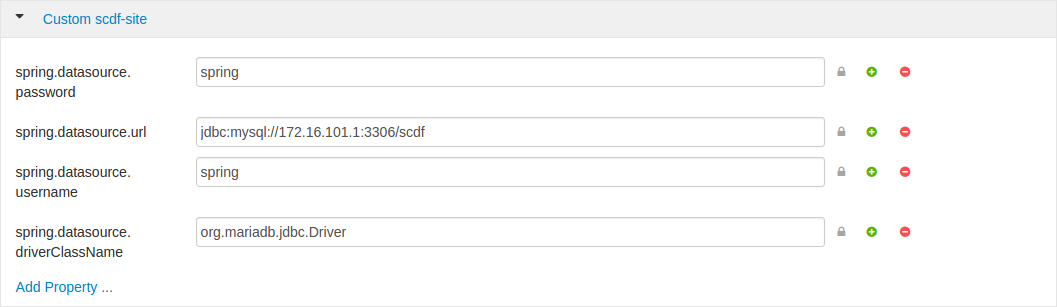
Custom datasource configuration can be applied via Custom scdf-site
as shown in below screenshot. After these settings are modified, all
related services needs to be restarted.
| Note |
|---|---|
Managed service SCDF H2 Database can be stopped and put in a maintenance mode after custom datasource settings has been added. |