The Stream DSL describes linear sequences of data flowing through the system. For example, in the stream definition http | transformer | cassandra, each pipe symbol connects the application on the left to the one on the right. Named channels can be used for routing and to fan out data to multiple messaging destinations.
Taps can be used to ‘listen in’ to the data that if flowing across any of the pipe symbols. Taps can be used as sources for new streams with an in independent life cycle.
For an application that will consume events, Spring Cloud stream exposes a concurrency setting that controls the size of a thread pool used for dispatching incoming messages. See the Consumer properties documentation for more information.
A common pattern in stream processing is to partition the data as it moves from one application to the next. Partitioning is a critical concept in stateful processing, for either performance or consistency reasons, to ensure that all related data is processed together. For example, in a time-windowed average calculation example, it is important that all measurements from any given sensor are processed by the same application instance. Alternatively, you may want to cache some data related to the incoming events so that it can be enriched without making a remote procedure call to retrieve the related data.
Spring Cloud Data Flow supports partitioning by configuring Spring Cloud Stream’s output and input bindings. Spring Cloud Stream provides a common abstraction for implementing partitioned processing use cases in a uniform fashion across different types of middleware. Partitioning can thus be used whether the broker itself is naturally partitioned (e.g., Kafka topics) or not (e.g., RabbitMQ). The following image shows how data could be partitioned into two buckets, such that each instance of the average processor application consumes a unique set of data.
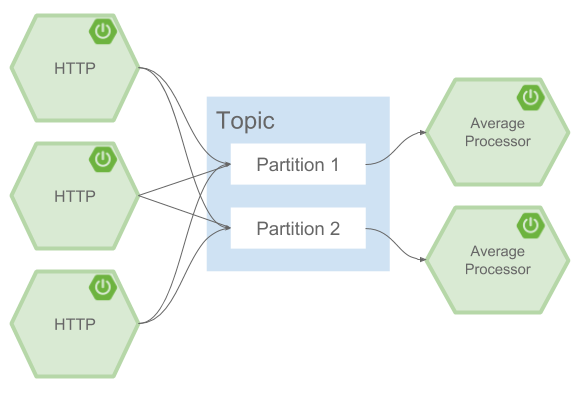
To use a simple partitioning strategy in Spring Cloud Data Flow, you only need set the instance count for each application in the stream and a partitionKeyExpression producer property when deploying the stream. The partitionKeyExpression identifies what part of the message will be used as the key to partition data in the underlying middleware. An ingest stream can be defined as http | averageprocessor | cassandra (Note that the Cassandra sink isn’t shown in the diagram above). Suppose the payload being sent to the http source was in JSON format and had a field called sensorId. Deploying the stream with the shell command stream deploy ingest --propertiesFile ingestStream.properties where the contents of the file ingestStream.properties are
deployer.http.count=3 deployer.averageprocessor.count=2 app.http.producer.partitionKeyExpression=payload.sensorId
will deploy the stream such that all the input and output destinations are configured for data to flow through the applications but also ensure that a unique set of data is always delivered to each averageprocessor instance. In this case the default algorithm is to evaluate payload.sensorId % partitionCount where the partitionCount is the application count in the case of RabbitMQ and the partition count of the topic in the case of Kafka.
Please refer to Section 23.2.6, “Passing stream partition properties during stream deployment” for additional strategies to partition streams during deployment and how they map onto the underlying Spring Cloud Stream Partitioning properties.
Also note, that you can’t currently scale partitioned streams. Read the section Section 11.3, “Scaling at runtime” for more information.
Streams are composed of applications that use the Spring Cloud Stream library as the basis for communicating with the underlying messaging middleware product. Spring Cloud Stream also provides an opinionated configuration of middleware from several vendors, in particular providing persistent publish-subscribe semantics.
The Binder abstraction in Spring Cloud Stream is what connects the application to the middleware. There are several configuration properties of the binder that are portable across all binder implementations and some that are specific to the middleware.
For consumer applications there is a retry policy for exceptions generated during message handling. The retry policy is configured using the common consumer properties maxAttempts, backOffInitialInterval, backOffMaxInterval, and backOffMultiplier. The default values of these properties will retry the callback method invocation 3 times and wait one second for the first retry. A backoff multiplier of 2 is used for the second and third attempts.
When the number of retry attempts has exceeded the maxAttempts value, the exception and the failed message will become the payload of a message and be sent to the application’s error channel. By default, the default message handler for this error channel logs the message. You can change the default behavior in your application by creating your own message handler that subscribes to the error channel.
Spring Cloud Stream also supports a configuration option for both Kafka and RabbitMQ binder implementations that will send the failed message and stack trace to a dead letter queue. The dead letter queue is a destination and its nature depends on the messaging middleware (e.g in the case of Kafka it is a dedicated topic). To enable this for RabbitMQ set the consumer properties republishtoDlq and autoBindDlq and the producer property autoBindDlq to true when deploying the stream. To always apply these producer and consumer properties when deploying streams, configure them as common application properties when starting the Data Flow server.
Additional messaging delivery guarantees are those provided by the underlying messaging middleware that is chosen for the application for both producing and consuming applications. Refer to the Kafka Consumer and Producer and Rabbit Consumer and Producer documentation for more details. You will find extensive declarative support for all the native QOS options.