2.2.6.RELEASE
1. Introduction
Spring Cloud Sleuth implements a distributed tracing solution for Spring Cloud.
1.1. Terminology
Spring Cloud Sleuth borrows Dapper’s terminology.
Span: The basic unit of work. For example, sending an RPC is a new span, as is sending a response to an RPC. Spans are identified by a unique 64-bit ID for the span and another 64-bit ID for the trace the span is a part of. Spans also have other data, such as descriptions, timestamped events, key-value annotations (tags), the ID of the span that caused them, and process IDs (normally IP addresses).
Spans can be started and stopped, and they keep track of their timing information. Once you create a span, you must stop it at some point in the future.
The initial span that starts a trace is called a root span. The value of the ID
of that span is equal to the trace ID.
|
Trace: A set of spans forming a tree-like structure.
For example, if you run a distributed big-data store, a trace might be formed by a PUT request.
Annotation: Used to record the existence of an event in time. With Brave instrumentation, we no longer need to set special events for Zipkin to understand who the client and server are, where the request started, and where it ended. For learning purposes, however, we mark these events to highlight what kind of an action took place.
-
cs: Client Sent. The client has made a request. This annotation indicates the start of the span.
-
sr: Server Received: The server side got the request and started processing it. Subtracting the
cstimestamp from this timestamp reveals the network latency. -
ss: Server Sent. Annotated upon completion of request processing (when the response got sent back to the client). Subtracting the
srtimestamp from this timestamp reveals the time needed by the server side to process the request. -
cr: Client Received. Signifies the end of the span. The client has successfully received the response from the server side. Subtracting the
cstimestamp from this timestamp reveals the whole time needed by the client to receive the response from the server.
The following image shows how Span and Trace look in a system, together with the Zipkin annotations:
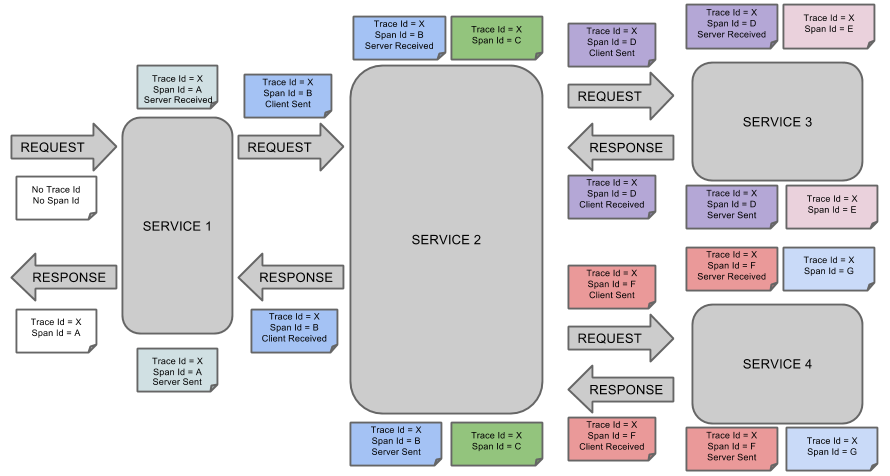
Each color of a note signifies a span (there are seven spans - from A to G). Consider the following note:
Trace Id = X
Span Id = D
Client SentThis note indicates that the current span has Trace Id set to X and Span Id set to D.
Also, the Client Sent event took place.
The following image shows how parent-child relationships of spans look:
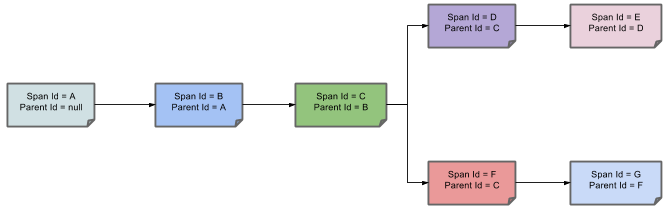
1.2. Purpose
The following sections refer to the example shown in the preceding image.
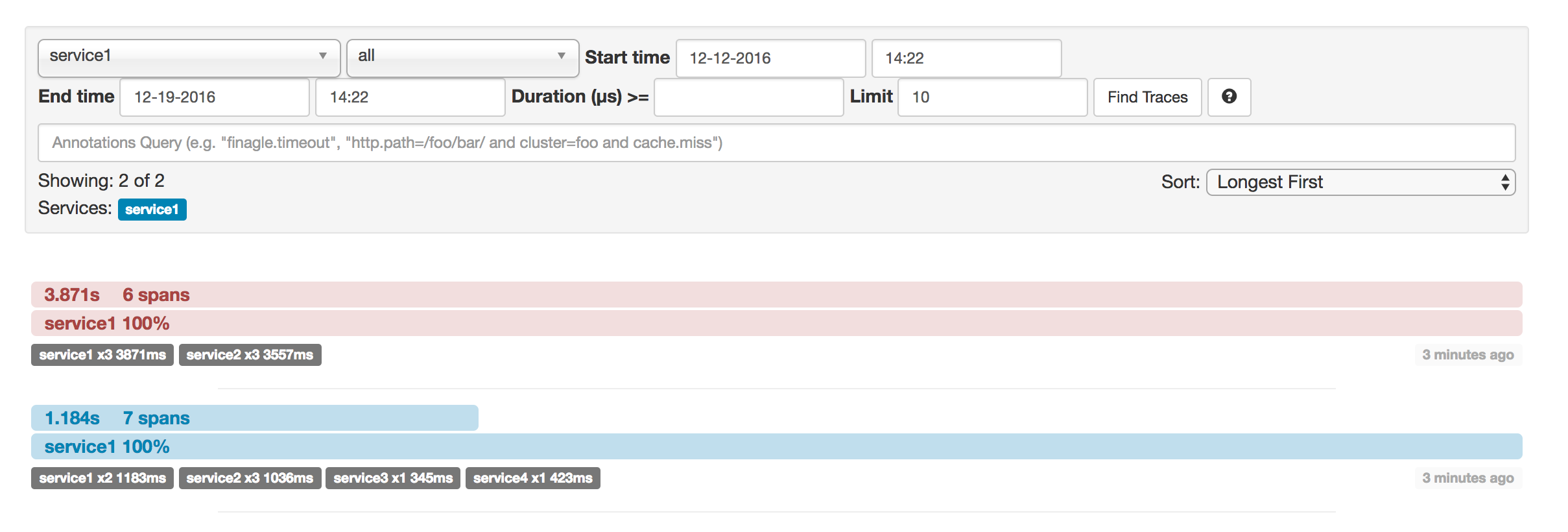
1.2.1. Distributed Tracing with Zipkin
This example has seven spans. If you go to traces in Zipkin, you can see this number in the second trace, as shown in the following image:
However, if you pick a particular trace, you can see four spans, as shown in the following image:
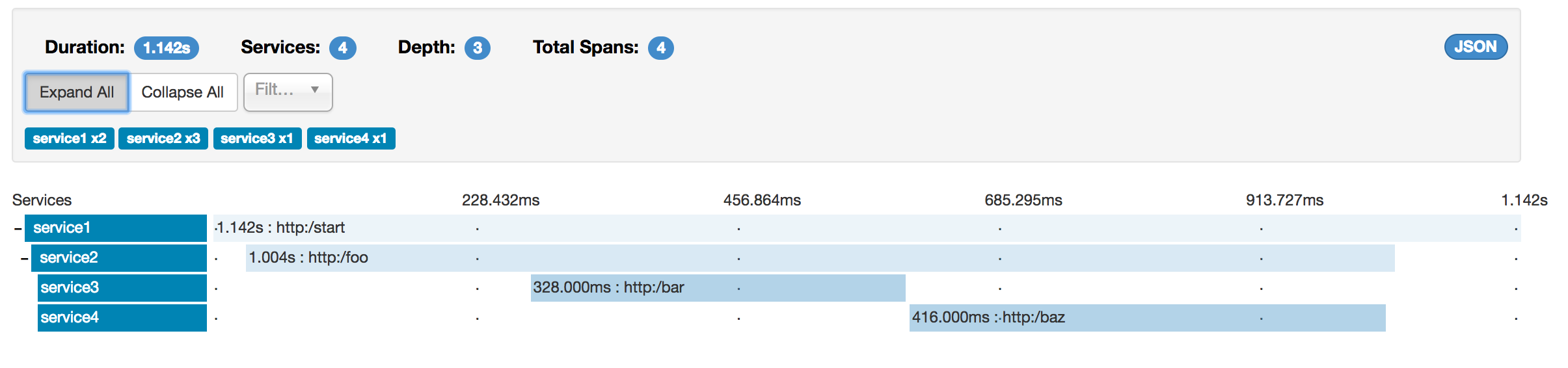
| When you pick a particular trace, you see merged spans. That means that, if there were two spans sent to Zipkin with Server Received and Server Sent or Client Received and Client Sent annotations, they are presented as a single span. |
Why is there a difference between the seven and four spans in this case?
-
One span comes from the
http:/startspan. It has the Server Received (sr) and Server Sent (ss) annotations. -
Two spans come from the RPC call from
service1toservice2to thehttp:/fooendpoint. The Client Sent (cs) and Client Received (cr) events took place on theservice1side. Server Received (sr) and Server Sent (ss) events took place on theservice2side. These two spans form one logical span related to an RPC call. -
Two spans come from the RPC call from
service2toservice3to thehttp:/barendpoint. The Client Sent (cs) and Client Received (cr) events took place on theservice2side. The Server Received (sr) and Server Sent (ss) events took place on theservice3side. These two spans form one logical span related to an RPC call. -
Two spans come from the RPC call from
service2toservice4to thehttp:/bazendpoint. The Client Sent (cs) and Client Received (cr) events took place on theservice2side. Server Received (sr) and Server Sent (ss) events took place on theservice4side. These two spans form one logical span related to an RPC call.
So, if we count the physical spans, we have one from http:/start, two from service1 calling service2, two from service2
calling service3, and two from service2 calling service4. In sum, we have a total of seven spans.
Logically, we see the information of four total Spans because we have one span related to the incoming request
to service1 and three spans related to RPC calls.
1.2.2. Visualizing errors
Zipkin lets you visualize errors in your trace. When an exception was thrown and was not caught, we set proper tags on the span, which Zipkin can then properly colorize. You could see in the list of traces one trace that is red. That appears because an exception was thrown.
If you click that trace, you see a similar picture, as follows:
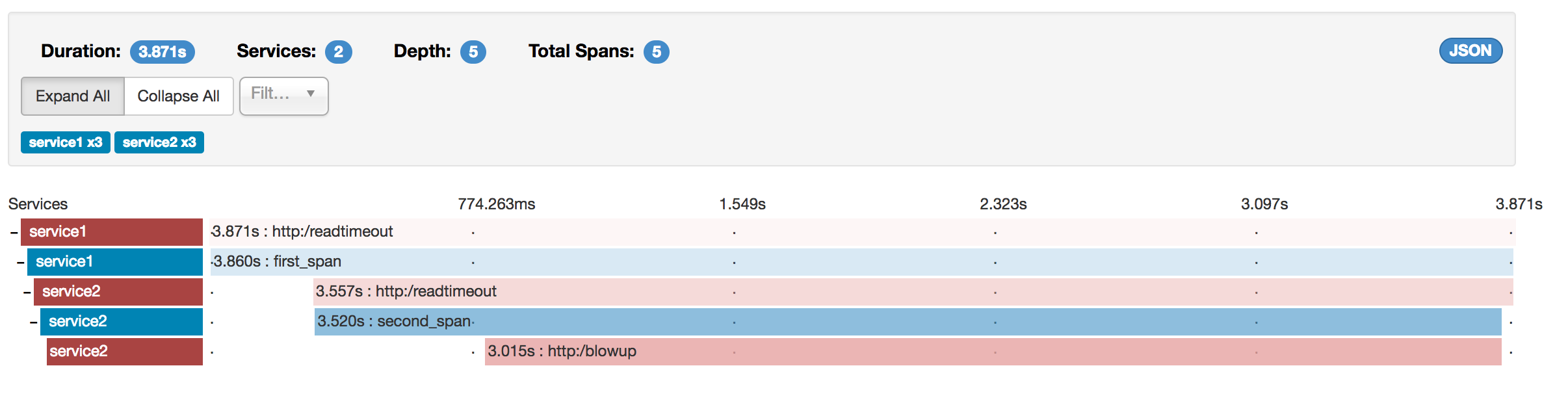
If you then click on one of the spans, you see the following
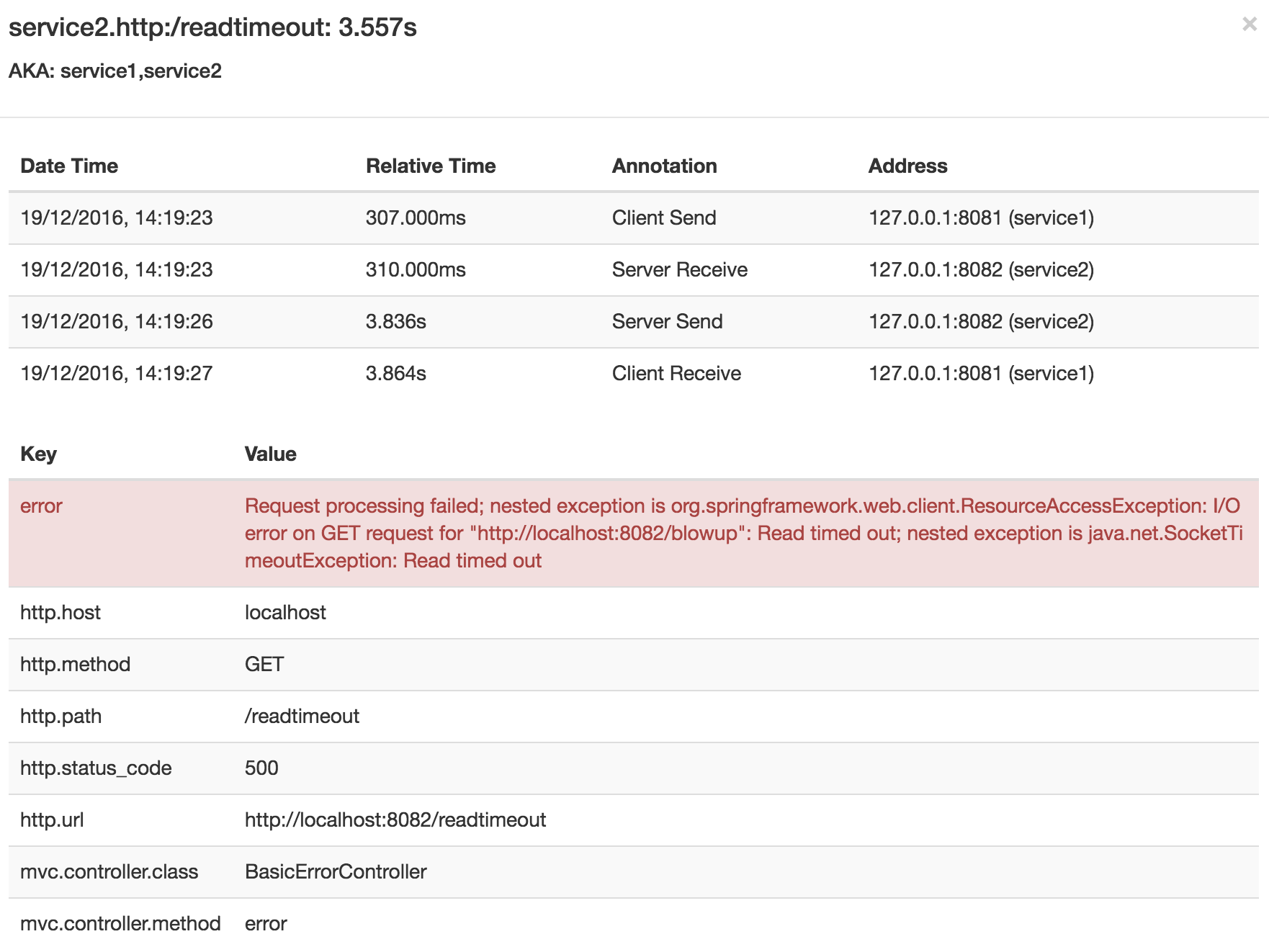
The span shows the reason for the error and the whole stack trace related to it.
1.2.3. Distributed Tracing with Brave
Starting with version 2.0.0, Spring Cloud Sleuth uses Brave as the tracing library.
Consequently, Sleuth no longer takes care of storing the context but delegates that work to Brave.
Due to the fact that Sleuth had different naming and tagging conventions than Brave, we decided to follow Brave’s conventions from now on.
However, if you want to use the legacy Sleuth approaches, you can set the spring.sleuth.http.legacy.enabled property to true.
1.2.4. Live examples

The dependency graph in Zipkin should resemble the following image:

1.2.5. Log correlation
When using grep to read the logs of those four applications by scanning for a trace ID equal to (for example) 2485ec27856c56f4, you get output resembling the following:
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2
service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4
service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3
service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3]
service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4
service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4]
service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]If you use a log aggregating tool (such as Kibana, Splunk, and others), you can order the events that took place. An example from Kibana would resemble the following image:
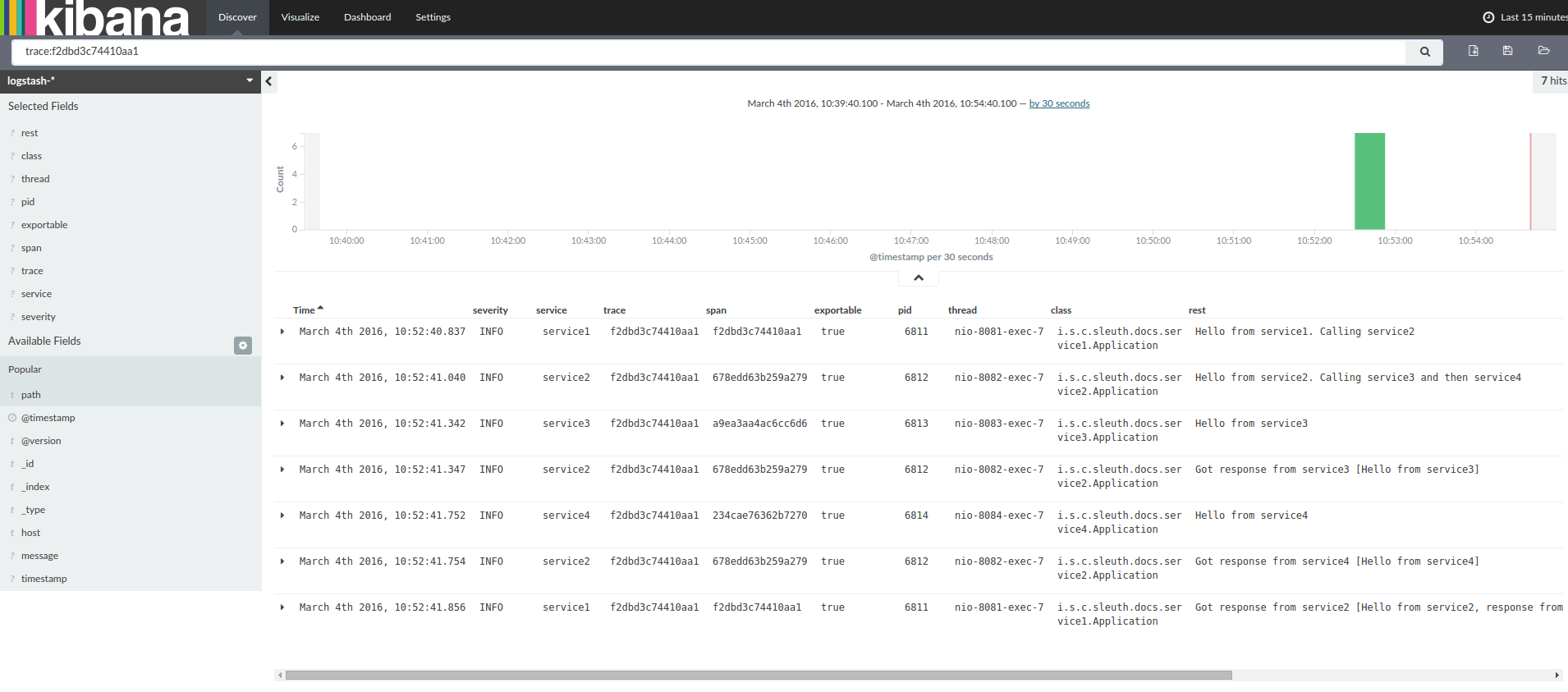
If you want to use Logstash, the following listing shows the Grok pattern for Logstash:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
date {
match => ["timestamp", "ISO8601"]
}
mutate {
remove_field => ["timestamp"]
}
}| If you want to use Grok together with the logs from Cloud Foundry, you have to use the following pattern: |
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
date {
match => ["timestamp", "ISO8601"]
}
mutate {
remove_field => ["timestamp"]
}
}JSON Logback with Logstash
Often, you do not want to store your logs in a text file but in a JSON file that Logstash can immediately pick.
To do so, you have to do the following (for readability, we pass the dependencies in the groupId:artifactId:version notation).
Dependencies Setup
-
Ensure that Logback is on the classpath (
ch.qos.logback:logback-core). -
Add Logstash Logback encode. For example, to use version
4.6, addnet.logstash.logback:logstash-logback-encoder:4.6.
Logback Setup
Consider the following example of a Logback configuration file (named logback-spring.xml).
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{traceId:-}",
"span": "%X{spanId:-}",
"baggage": "%X{key:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs -->
<!--<appender-ref ref="logstash"/>-->
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>That Logback configuration file:
-
Logs information from the application in a JSON format to a
build/${spring.application.name}.jsonfile. -
Has commented out two additional appenders: console and standard log file.
-
Has the same logging pattern as the one presented in the previous section.
If you use a custom logback-spring.xml, you must pass the spring.application.name in the bootstrap rather than the application property file.
Otherwise, your custom logback file does not properly read the property.
|
1.2.6. Propagating Span Context
The span context is the state that must get propagated to any child spans across process boundaries. Part of the Span Context is the Baggage. The trace and span IDs are a required part of the span context. Baggage is an optional part.
Baggage is a set of key:value pairs stored in the span context.
Baggage travels together with the trace and is attached to every span.
Spring Cloud Sleuth understands that a header is baggage-related if the HTTP header is prefixed with baggage- and, for messaging, it starts with baggage_.
| There is currently no limitation of the count or size of baggage items. However, keep in mind that too many can decrease system throughput or increase RPC latency. In extreme cases, too much baggage can crash the application, due to exceeding transport-level message or header capacity. |
The following example shows setting baggage on a span:
Span initialSpan = this.tracer.nextSpan().name("span").start();
ExtraFieldPropagation.set(initialSpan.context(), "foo", "bar");
ExtraFieldPropagation.set(initialSpan.context(), "UPPER_CASE", "someValue");Baggage versus Span Tags
Baggage travels with the trace (every child span contains the baggage of its parent). Zipkin has no knowledge of baggage and does not receive that information.
| Starting from Sleuth 2.0.0 you have to pass the baggage key names explicitly in your project configuration. Read more about that setup here |
Tags are attached to a specific span. In other words, they are presented only for that particular span. However, you can search by tag to find the trace, assuming a span having the searched tag value exists.
If you want to be able to lookup a span based on baggage, you should add a corresponding entry as a tag in the root span.
| The span must be in scope. |
The following listing shows integration tests that use baggage:
spring.sleuth:
baggage-keys:
- baz
- bizarrecase
propagation-keys:
- foo
- upper_caseinitialSpan.tag("foo",
ExtraFieldPropagation.get(initialSpan.context(), "foo"));
initialSpan.tag("UPPER_CASE",
ExtraFieldPropagation.get(initialSpan.context(), "UPPER_CASE"));1.3. Adding Sleuth to the Project
This section addresses how to add Sleuth to your project with either Maven or Gradle.
To ensure that your application name is properly displayed in Zipkin, set the spring.application.name property in bootstrap.yml.
|
1.3.1. Only Sleuth (log correlation)
If you want to use only Spring Cloud Sleuth without the Zipkin integration, add the spring-cloud-starter-sleuth module to your project.
The following example shows how to add Sleuth with Maven:
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>| 1 | We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| 2 | Add the dependency to spring-cloud-starter-sleuth. |
The following example shows how to add Sleuth with Gradle:
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth"
}| 1 | We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| 2 | Add the dependency to spring-cloud-starter-sleuth. |
1.3.2. Sleuth with Zipkin via HTTP
If you want both Sleuth and Zipkin, add the spring-cloud-starter-zipkin dependency.
The following example shows how to do so for Maven:
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>| 1 | We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| 2 | Add the dependency to spring-cloud-starter-zipkin. |
The following example shows how to do so for Gradle:
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
}| 1 | We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| 2 | Add the dependency to spring-cloud-starter-zipkin. |
1.3.3. Sleuth with Zipkin over RabbitMQ or Kafka
If you want to use RabbitMQ or Kafka instead of HTTP, add the spring-rabbit or spring-kafka dependency.
The default destination name is zipkin.
If using Kafka, you must set the property spring.zipkin.sender.type property accordingly:
spring.zipkin.sender.type: kafka
spring-cloud-sleuth-stream is deprecated and incompatible with these destinations.
|
If you want Sleuth over RabbitMQ, add the spring-cloud-starter-zipkin and spring-rabbit
dependencies.
The following example shows how to do so for Gradle:
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency> (3)
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>| 1 | We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| 2 | Add the dependency to spring-cloud-starter-zipkin. That way, all nested dependencies get downloaded. |
| 3 | To automatically configure RabbitMQ, add the spring-rabbit dependency. |
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-zipkin" (2)
compile "org.springframework.amqp:spring-rabbit" (3)
}| 1 | We recommend that you add the dependency management through the Spring BOM so that you need not manage versions yourself. |
| 2 | Add the dependency to spring-cloud-starter-zipkin. That way, all nested dependencies get downloaded. |
| 3 | To automatically configure RabbitMQ, add the spring-rabbit dependency. |
1.4. Overriding the auto-configuration of Zipkin
Spring Cloud Sleuth supports sending traces to multiple tracing systems as of version 2.1.0.
In order to get this to work, every tracing system needs to have a Reporter<Span> and Sender.
If you want to override the provided beans you need to give them a specific name.
To do this you can use respectively ZipkinAutoConfiguration.REPORTER_BEAN_NAME and ZipkinAutoConfiguration.SENDER_BEAN_NAME.
@Configuration
protected static class MyConfig {
@Bean(ZipkinAutoConfiguration.REPORTER_BEAN_NAME)
Reporter<zipkin2.Span> myReporter() {
return AsyncReporter.create(mySender());
}
@Bean(ZipkinAutoConfiguration.SENDER_BEAN_NAME)
MySender mySender() {
return new MySender();
}
static class MySender extends Sender {
private boolean spanSent = false;
boolean isSpanSent() {
return this.spanSent;
}
@Override
public Encoding encoding() {
return Encoding.JSON;
}
@Override
public int messageMaxBytes() {
return Integer.MAX_VALUE;
}
@Override
public int messageSizeInBytes(List<byte[]> encodedSpans) {
return encoding().listSizeInBytes(encodedSpans);
}
@Override
public Call<Void> sendSpans(List<byte[]> encodedSpans) {
this.spanSent = true;
return Call.create(null);
}
}
}2. Additional Resources
You can watch a video of Reshmi Krishna and Marcin Grzejszczak talking about Spring Cloud Sleuth and Zipkin by clicking here.
You can check different setups of Sleuth and Brave in the openzipkin/sleuth-webmvc-example repository.
3. Features
-
Adds trace and span IDs to the Slf4J MDC, so you can extract all the logs from a given trace or span in a log aggregator, as shown in the following example logs:
2016-02-02 15:30:57.902 INFO [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:30:58.372 ERROR [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:31:01.936 INFO [bar,46ab0d418373cbc9,46ab0d418373cbc9,false] 23030 --- [nio-8081-exec-4] ...
Notice the
[appname,traceId,spanId,exportable]entries from the MDC:-
spanId: The ID of a specific operation that took place. -
appname: The name of the application that logged the span. -
traceId: The ID of the latency graph that contains the span. -
exportable: Whether the log should be exported to Zipkin. When would you like the span not to be exportable? When you want to wrap some operation in a Span and have it written to the logs only.
-
-
Provides an abstraction over common distributed tracing data models: traces, spans (forming a DAG), annotations, and key-value annotations. Spring Cloud Sleuth is loosely based on HTrace but is compatible with Zipkin (Dapper).
-
Sleuth records timing information to aid in latency analysis. By using sleuth, you can pinpoint causes of latency in your applications.
-
Sleuth is written to not log too much and to not cause your production application to crash. To that end, Sleuth:
-
Propagates structural data about your call graph in-band and the rest out-of-band.
-
Includes opinionated instrumentation of layers such as HTTP.
-
Includes a sampling policy to manage volume.
-
Can report to a Zipkin system for query and visualization.
-
-
Instruments common ingress and egress points from Spring applications (servlet filter, async endpoints, rest template, scheduled actions, message channels, Zuul filters, and Feign client).
-
Sleuth includes default logic to join a trace across HTTP or messaging boundaries. For example, HTTP propagation works over Zipkin-compatible request headers.
-
Sleuth can propagate context (also known as baggage) between processes. Consequently, if you set a baggage element on a Span, it is sent downstream to other processes over either HTTP or messaging.
-
Provides a way to create or continue spans and add tags and logs through annotations.
-
If
spring-cloud-sleuth-zipkinis on the classpath, the app generates and collects Zipkin-compatible traces. By default, it sends them over HTTP to a Zipkin server on localhost (port 9411). You can configure the location of the service by settingspring.zipkin.baseUrl.-
If you depend on
spring-rabbit, your app sends traces to a RabbitMQ broker instead of HTTP. -
If you depend on
spring-kafka, and setspring.zipkin.sender.type: kafka, your app sends traces to a Kafka broker instead of HTTP.
-
spring-cloud-sleuth-stream is deprecated and should no longer be used.
|
-
Spring Cloud Sleuth is OpenTracing compatible.
The SLF4J MDC is always set and logback users immediately see the trace and span IDs in logs per the example
shown earlier.
Other logging systems have to configure their own formatter to get the same result.
The default is as follows:
logging.pattern.level set to %5p [${spring.zipkin.service.name:${spring.application.name:-}},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]
(this is a Spring Boot feature for logback users).
If you do not use SLF4J, this pattern is NOT automatically applied.
|
3.1. Introduction to Brave
Starting with version 2.0.0, Spring Cloud Sleuth uses
Brave as the tracing library.
For your convenience, we embed part of the Brave’s docs here.
|
In the vast majority of cases you need to just use the Tracer
or SpanCustomizer beans from Brave that Sleuth provides. The documentation below contains
a high overview of what Brave is and how it works.
|
Brave is a library used to capture and report latency information about distributed operations to Zipkin. Most users do not use Brave directly. They use libraries or frameworks rather than employ Brave on their behalf.
This module includes a tracer that creates and joins spans that model the latency of potentially distributed work. It also includes libraries to propagate the trace context over network boundaries (for example, with HTTP headers).
3.1.1. Tracing
Most importantly, you need a brave.Tracer, configured to report to Zipkin.
The following example setup sends trace data (spans) to Zipkin over HTTP (as opposed to Kafka):
class MyClass {
private final Tracer tracer;
// Tracer will be autowired
MyClass(Tracer tracer) {
this.tracer = tracer;
}
void doSth() {
Span span = tracer.newTrace().name("encode").start();
// ...
}
}| If your span contains a name longer than 50 chars, then that name is truncated to 50 chars. Your names have to be explicit and concrete. Big names lead to latency issues and sometimes even thrown exceptions. |
The tracer creates and joins spans that model the latency of potentially distributed work. It can employ sampling to reduce overhead during the process, to reduce the amount of data sent to Zipkin, or both.
Spans returned by a tracer report data to Zipkin when finished or do nothing if unsampled. After starting a span, you can annotate events of interest or add tags containing details or lookup keys.
Spans have a context that includes trace identifiers that place the span at the correct spot in the tree representing the distributed operation.
3.1.2. Local Tracing
When tracing code that never leaves your process, run it inside a scoped span.
@Autowired Tracer tracer;
// Start a new trace or a span within an existing trace representing an operation
ScopedSpan span = tracer.startScopedSpan("encode");
try {
// The span is in "scope" meaning downstream code such as loggers can see trace IDs
return encoder.encode();
} catch (RuntimeException | Error e) {
span.error(e); // Unless you handle exceptions, you might not know the operation failed!
throw e;
} finally {
span.finish(); // always finish the span
}When you need more features, or finer control, use the Span type:
@Autowired Tracer tracer;
// Start a new trace or a span within an existing trace representing an operation
Span span = tracer.nextSpan().name("encode").start();
// Put the span in "scope" so that downstream code such as loggers can see trace IDs
try (SpanInScope ws = tracer.withSpanInScope(span)) {
return encoder.encode();
} catch (RuntimeException | Error e) {
span.error(e); // Unless you handle exceptions, you might not know the operation failed!
throw e;
} finally {
span.finish(); // note the scope is independent of the span. Always finish a span.
}Both of the above examples report the exact same span on finish!
In the above example, the span will be either a new root span or the next child in an existing trace.
3.1.3. Customizing Spans
Once you have a span, you can add tags to it. The tags can be used as lookup keys or details. For example, you might add a tag with your runtime version, as shown in the following example:
span.tag("clnt/finagle.version", "6.36.0");When exposing the ability to customize spans to third parties, prefer brave.SpanCustomizer as opposed to brave.Span.
The former is simpler to understand and test and does not tempt users with span lifecycle hooks.
interface MyTraceCallback {
void request(Request request, SpanCustomizer customizer);
}Since brave.Span implements brave.SpanCustomizer, you can pass it to users, as shown in the following example:
for (MyTraceCallback callback : userCallbacks) {
callback.request(request, span);
}3.1.4. Implicitly Looking up the Current Span
Sometimes, you do not know if a trace is in progress or not, and you do not want users to do null checks.
brave.CurrentSpanCustomizer handles this problem by adding data to any span that’s in progress or drops, as shown in the following example:
Ex.
// The user code can then inject this without a chance of it being null.
@Autowired SpanCustomizer span;
void userCode() {
span.annotate("tx.started");
...
}3.1.5. RPC tracing
| Check for instrumentation written here and Zipkin’s list before rolling your own RPC instrumentation. |
RPC tracing is often done automatically by interceptors. Behind the scenes, they add tags and events that relate to their role in an RPC operation.
The following example shows how to add a client span:
@Autowired Tracing tracing;
@Autowired Tracer tracer;
// before you send a request, add metadata that describes the operation
span = tracer.nextSpan().name(service + "/" + method).kind(CLIENT);
span.tag("myrpc.version", "1.0.0");
span.remoteServiceName("backend");
span.remoteIpAndPort("172.3.4.1", 8108);
// Add the trace context to the request, so it can be propagated in-band
tracing.propagation().injector(Request::addHeader)
.inject(span.context(), request);
// when the request is scheduled, start the span
span.start();
// if there is an error, tag the span
span.tag("error", error.getCode());
// or if there is an exception
span.error(exception);
// when the response is complete, finish the span
span.finish();One-Way tracing
Sometimes, you need to model an asynchronous operation where there is a
request but no response. In normal RPC tracing, you use span.finish()
to indicate that the response was received. In one-way tracing, you use
span.flush() instead, as you do not expect a response.
The following example shows how a client might model a one-way operation:
@Autowired Tracing tracing;
@Autowired Tracer tracer;
// start a new span representing a client request
oneWaySend = tracer.nextSpan().name(service + "/" + method).kind(CLIENT);
// Add the trace context to the request, so it can be propagated in-band
tracing.propagation().injector(Request::addHeader)
.inject(oneWaySend.context(), request);
// fire off the request asynchronously, totally dropping any response
request.execute();
// start the client side and flush instead of finish
oneWaySend.start().flush();The following example shows how a server might handle a one-way operation:
@Autowired Tracing tracing;
@Autowired Tracer tracer;
// pull the context out of the incoming request
extractor = tracing.propagation().extractor(Request::getHeader);
// convert that context to a span which you can name and add tags to
oneWayReceive = nextSpan(tracer, extractor.extract(request))
.name("process-request")
.kind(SERVER)
... add tags etc.
// start the server side and flush instead of finish
oneWayReceive.start().flush();
// you should not modify this span anymore as it is complete. However,
// you can create children to represent follow-up work.
next = tracer.newSpan(oneWayReceive.context()).name("step2").start();4. Sampling
Sampling may be employed to reduce the data collected and reported out of process. When a span is not sampled, it adds no overhead (a noop).
Sampling is an up-front decision, meaning that the decision to report data is made at the first operation in a trace and that decision is propagated downstream.
By default, a global sampler applies a single rate to all traced operations.
Tracer.Builder.sampler controls this setting, and it defaults to tracing every request.
4.1. Declarative sampling
Some applications need to sample based on the type or annotations of a java method.
Most users use a framework interceptor to automate this sort of policy. The following example shows how that might work internally:
@Autowired Tracer tracer;
// derives a sample rate from an annotation on a java method
DeclarativeSampler<Traced> sampler = DeclarativeSampler.create(Traced::sampleRate);
@Around("@annotation(traced)")
public Object traceThing(ProceedingJoinPoint pjp, Traced traced) throws Throwable {
// When there is no trace in progress, this decides using an annotation
Sampler decideUsingAnnotation = declarativeSampler.toSampler(traced);
Tracer tracer = tracer.withSampler(decideUsingAnnotation);
// This code looks the same as if there was no declarative override
ScopedSpan span = tracer.startScopedSpan(spanName(pjp));
try {
return pjp.proceed();
} catch (RuntimeException | Error e) {
span.error(e);
throw e;
} finally {
span.finish();
}
}4.2. Custom sampling
Depending on what the operation is, you may want to apply different policies. For example, you might not want to trace requests to static resources such as images, or you might want to trace all requests to a new api.
Most users use a framework interceptor to automate this sort of policy. The following example shows how that might work internally:
@Autowired Tracer tracer;
@Autowired Sampler fallback;
Span nextSpan(final Request input) {
Sampler requestBased = Sampler() {
@Override public boolean isSampled(long traceId) {
if (input.url().startsWith("/experimental")) {
return true;
} else if (input.url().startsWith("/static")) {
return false;
}
return fallback.isSampled(traceId);
}
};
return tracer.withSampler(requestBased).nextSpan();
}4.3. Sampling in Spring Cloud Sleuth
Sampling only applies to tracing backends, such as Zipkin. Trace IDs appear in logs regardless of sample rate. Sampling is a way to prevent overloading the system, by consistently tracing some, but not all requests.
The default rate of 10 traces per second is controlled by the spring.sleuth.sampler.rate
property and applies when we know Sleuth is used for reasons besides logging. Use a rate above 100
traces per second with extreme caution as it can overload your tracing system.
The sampler can be set by Java Config also, as shown in the following example:
@Bean
public Sampler defaultSampler() {
return Sampler.ALWAYS_SAMPLE;
}
You can set the HTTP header X-B3-Flags to 1, or, when doing messaging, you can set the spanFlags header to 1.
Doing so forces the corresponding trace to be sampled regardless of the sampling configuration.
|
5. Propagation
Propagation is needed to ensure activities originating from the same root are collected together in the same trace. The most common propagation approach is to copy a trace context from a client by sending an RPC request to a server receiving it.
For example, when a downstream HTTP call is made, its trace context is encoded as request headers and sent along with it, as shown in the following image:
Client Span Server Span
┌──────────────────┐ ┌──────────────────┐
│ │ │ │
│ TraceContext │ Http Request Headers │ TraceContext │
│ ┌──────────────┐ │ ┌───────────────────┐ │ ┌──────────────┐ │
│ │ TraceId │ │ │ X─B3─TraceId │ │ │ TraceId │ │
│ │ │ │ │ │ │ │ │ │
│ │ ParentSpanId │ │ Extract │ X─B3─ParentSpanId │ Inject │ │ ParentSpanId │ │
│ │ ├─┼─────────>│ ├────────┼>│ │ │
│ │ SpanId │ │ │ X─B3─SpanId │ │ │ SpanId │ │
│ │ │ │ │ │ │ │ │ │
│ │ Sampled │ │ │ X─B3─Sampled │ │ │ Sampled │ │
│ └──────────────┘ │ └───────────────────┘ │ └──────────────┘ │
│ │ │ │
└──────────────────┘ └──────────────────┘The names above are from B3 Propagation, which is built-in to Brave and has implementations in many languages and frameworks.
Most users use a framework interceptor to automate propagation. The next two examples show how that might work for a client and a server.
The following example shows how client-side propagation might work:
@Autowired Tracing tracing;
// configure a function that injects a trace context into a request
injector = tracing.propagation().injector(Request.Builder::addHeader);
// before a request is sent, add the current span's context to it
injector.inject(span.context(), request);The following example shows how server-side propagation might work:
@Autowired Tracing tracing;
@Autowired Tracer tracer;
// configure a function that extracts the trace context from a request
extractor = tracing.propagation().extractor(Request::getHeader);
// when a server receives a request, it joins or starts a new trace
span = tracer.nextSpan(extractor.extract(request));5.1. Propagating extra fields
Sometimes you need to propagate extra fields, such as a request ID or an alternate trace context. For example, if you are in a Cloud Foundry environment, you might want to pass the request ID, as shown in the following example:
// when you initialize the builder, define the extra field you want to propagate
Tracing.newBuilder().propagationFactory(
ExtraFieldPropagation.newFactory(B3Propagation.FACTORY, "x-vcap-request-id")
);
// later, you can tag that request ID or use it in log correlation
requestId = ExtraFieldPropagation.get("x-vcap-request-id");You may also need to propagate a trace context that you are not using. For example, you may be in an Amazon Web Services environment but not be reporting data to X-Ray. To ensure X-Ray can co-exist correctly, pass-through its tracing header, as shown in the following example:
tracingBuilder.propagationFactory(
ExtraFieldPropagation.newFactory(B3Propagation.FACTORY, "x-amzn-trace-id")
);
In Spring Cloud Sleuth all elements of the tracing builder Tracing.newBuilder()
are defined as beans. So if you want to pass a custom PropagationFactory, it’s enough
for you to create a bean of that type and we will set it in the Tracing bean.
|
5.1.1. Prefixed fields
If they follow a common pattern, you can also prefix fields.
The following example shows how to propagate x-vcap-request-id the field as-is but send the country-code and user-id fields on the wire as x-baggage-country-code and x-baggage-user-id, respectively:
Tracing.newBuilder().propagationFactory(
ExtraFieldPropagation.newFactoryBuilder(B3Propagation.FACTORY)
.addField("x-vcap-request-id")
.addPrefixedFields("x-baggage-", Arrays.asList("country-code", "user-id"))
.build()
);Later, you can call the following code to affect the country code of the current trace context:
ExtraFieldPropagation.set("x-country-code", "FO");
String countryCode = ExtraFieldPropagation.get("x-country-code");Alternatively, if you have a reference to a trace context, you can use it explicitly, as shown in the following example:
ExtraFieldPropagation.set(span.context(), "x-country-code", "FO");
String countryCode = ExtraFieldPropagation.get(span.context(), "x-country-code");
A difference from previous versions of Sleuth is that, with Brave, you must pass the list of baggage keys.
There are the following properties to achieve this.
With the spring.sleuth.baggage-keys, you set keys that get prefixed with baggage- for HTTP calls and baggage_ for messaging.
You can also use the spring.sleuth.propagation-keys property to pass a list of prefixed keys that are propagated to remote services without any prefix.
You can also use the spring.sleuth.local-keys property to pass a list keys that will be propagated locally but will not be propagated over the wire.
Notice that there’s no x- in front of the header keys.
|
In order to automatically set the baggage values to Slf4j’s MDC, you have to set
the spring.sleuth.log.slf4j.whitelisted-mdc-keys property with a list of whitelisted
baggage and propagation keys. E.g. spring.sleuth.log.slf4j.whitelisted-mdc-keys=foo will set the value of the foo baggage into MDC.
| Remember that adding entries to MDC can drastically decrease the performance of your application! |
If you want to add the baggage entries as tags, to make it possible to search for spans via the baggage entries, you can set the value of
spring.sleuth.propagation.tag.whitelisted-keys with a list of whitelisted baggage keys. To disable the feature you have to pass the spring.sleuth.propagation.tag.enabled=false property.
5.1.2. Extracting a Propagated Context
The TraceContext.Extractor<C> reads trace identifiers and sampling status from an incoming request or message.
The carrier is usually a request object or headers.
This utility is used in standard instrumentation (such as HttpServerHandler) but can also be used for custom RPC or messaging code.
TraceContextOrSamplingFlags is usually used only with Tracer.nextSpan(extracted), unless you are
sharing span IDs between a client and a server.
5.1.3. Sharing span IDs between Client and Server
A normal instrumentation pattern is to create a span representing the server side of an RPC.
Extractor.extract might return a complete trace context when applied to an incoming client request.
Tracer.joinSpan attempts to continue this trace, using the same span ID if supported or creating a child span
if not. When the span ID is shared, the reported data includes a flag saying so.
The following image shows an example of B3 propagation:
┌───────────────────┐ ┌───────────────────┐
Incoming Headers │ TraceContext │ │ TraceContext │
┌───────────────────┐(extract)│ ┌───────────────┐ │(join)│ ┌───────────────┐ │
│ X─B3-TraceId │─────────┼─┼> TraceId │ │──────┼─┼> TraceId │ │
│ │ │ │ │ │ │ │ │ │
│ X─B3-ParentSpanId │─────────┼─┼> ParentSpanId │ │──────┼─┼> ParentSpanId │ │
│ │ │ │ │ │ │ │ │ │
│ X─B3-SpanId │─────────┼─┼> SpanId │ │──────┼─┼> SpanId │ │
└───────────────────┘ │ │ │ │ │ │ │ │
│ │ │ │ │ │ Shared: true │ │
│ └───────────────┘ │ │ └───────────────┘ │
└───────────────────┘ └───────────────────┘Some propagation systems forward only the parent span ID, detected when Propagation.Factory.supportsJoin() == false.
In this case, a new span ID is always provisioned, and the incoming context determines the parent ID.
The following image shows an example of AWS propagation:
┌───────────────────┐ ┌───────────────────┐
x-amzn-trace-id │ TraceContext │ │ TraceContext │
┌───────────────────┐(extract)│ ┌───────────────┐ │(join)│ ┌───────────────┐ │
│ Root │─────────┼─┼> TraceId │ │──────┼─┼> TraceId │ │
│ │ │ │ │ │ │ │ │ │
│ Parent │─────────┼─┼> SpanId │ │──────┼─┼> ParentSpanId │ │
└───────────────────┘ │ └───────────────┘ │ │ │ │ │
└───────────────────┘ │ │ SpanId: New │ │
│ └───────────────┘ │
└───────────────────┘Note: Some span reporters do not support sharing span IDs.
For example, if you set Tracing.Builder.spanReporter(amazonXrayOrGoogleStackdrive), you should disable join by setting Tracing.Builder.supportsJoin(false).
Doing so forces a new child span on Tracer.joinSpan().
5.1.4. Implementing Propagation
TraceContext.Extractor<C> is implemented by a Propagation.Factory plugin.
Internally, this code creates the union type, TraceContextOrSamplingFlags, with one of the following:
-
TraceContextif trace and span IDs were present. -
TraceIdContextif a trace ID was present but span IDs were not present. -
SamplingFlagsif no identifiers were present.
Some Propagation implementations carry extra data from the point of extraction (for example, reading incoming headers) to injection (for example, writing outgoing headers).
For example, it might carry a request ID.
When implementations have extra data, they handle it as follows:
-
If a
TraceContextwere extracted, add the extra data asTraceContext.extra(). -
Otherwise, add it as
TraceContextOrSamplingFlags.extra(), whichTracer.nextSpanhandles.
6. Current Tracing Component
Brave supports a "current tracing component" concept, which should only be used when you have no other way to get a reference.
This was made for JDBC connections, as they often initialize prior to the tracing component.
The most recent tracing component instantiated is available through Tracing.current().
You can also use Tracing.currentTracer() to get only the tracer.
If you use either of these methods, do not cache the result.
Instead, look them up each time you need them.
7. Current Span
Brave supports a "current span" concept which represents the in-flight operation.
You can use Tracer.currentSpan() to add custom tags to a span and Tracer.nextSpan() to create a child of whatever is in-flight.
In Sleuth, you can autowire the Tracer bean to retrieve the current span via
tracer.currentSpan() method. To retrieve the current context just call
tracer.currentSpan().context(). To get the current trace id as String
you can use the traceIdString() method like this: tracer.currentSpan().context().traceIdString().
|
7.1. Setting a span in scope manually
When writing new instrumentation, it is important to place a span you created in scope as the current span.
Not only does doing so let users access it with Tracer.currentSpan(), but it also allows customizations such as SLF4J MDC to see the current trace IDs.
Tracer.withSpanInScope(Span) facilitates this and is most conveniently employed by using the try-with-resources idiom.
Whenever external code might be invoked (such as proceeding an interceptor or otherwise), place the span in scope, as shown in the following example:
@Autowired Tracer tracer;
try (SpanInScope ws = tracer.withSpanInScope(span)) {
return inboundRequest.invoke();
} finally { // note the scope is independent of the span
span.finish();
}In edge cases, you may need to clear the current span temporarily (for example, launching a task that should not be associated with the current request). To do tso, pass null to withSpanInScope, as shown in the following example:
@Autowired Tracer tracer;
try (SpanInScope cleared = tracer.withSpanInScope(null)) {
startBackgroundThread();
}8. Instrumentation
Spring Cloud Sleuth automatically instruments all your Spring applications, so you should not have to do anything to activate it.
The instrumentation is added by using a variety of technologies according to the stack that is available. For example, for a servlet web application, we use a Filter, and, for Spring Integration, we use ChannelInterceptors.
You can customize the keys used in span tags.
To limit the volume of span data, an HTTP request is, by default, tagged only with a handful of metadata, such as the status code, the host, and the URL.
You can add request headers by configuring spring.sleuth.keys.http.headers (a list of header names).
Tags are collected and exported only if there is a Sampler that allows it. By default, there is no such Sampler, to ensure that there is no danger of accidentally collecting too much data without configuring something).
|
9. Span lifecycle
You can do the following operations on the Span by means of brave.Tracer:
-
start: When you start a span, its name is assigned and the start timestamp is recorded.
-
close: The span gets finished (the end time of the span is recorded) and, if the span is sampled, it is eligible for collection (for example, to Zipkin).
-
continue: A new instance of span is created. It is a copy of the one that it continues.
-
detach: The span does not get stopped or closed. It only gets removed from the current thread.
-
create with explicit parent: You can create a new span and set an explicit parent for it.
Spring Cloud Sleuth creates an instance of Tracer for you. In order to use it, you can autowire it.
|
9.1. Creating and finishing spans
You can manually create spans by using the Tracer, as shown in the following example:
// Start a span. If there was a span present in this thread it will become
// the `newSpan`'s parent.
Span newSpan = this.tracer.nextSpan().name("calculateTax");
try (Tracer.SpanInScope ws = this.tracer.withSpanInScope(newSpan.start())) {
// ...
// You can tag a span
newSpan.tag("taxValue", taxValue);
// ...
// You can log an event on a span
newSpan.annotate("taxCalculated");
}
finally {
// Once done remember to finish the span. This will allow collecting
// the span to send it to Zipkin
newSpan.finish();
}In the preceding example, we could see how to create a new instance of the span. If there is already a span in this thread, it becomes the parent of the new span.
| Always clean after you create a span. Also, always finish any span that you want to send to Zipkin. |
| If your span contains a name greater than 50 chars, that name is truncated to 50 chars. Your names have to be explicit and concrete. Big names lead to latency issues and sometimes even exceptions. |
9.2. Continuing Spans
Sometimes, you do not want to create a new span but you want to continue one. An example of such a situation might be as follows:
-
AOP: If there was already a span created before an aspect was reached, you might not want to create a new span.
-
Hystrix: Executing a Hystrix command is most likely a logical part of the current processing. It is in fact merely a technical implementation detail that you would not necessarily want to reflect in tracing as a separate being.
To continue a span, you can use brave.Tracer, as shown in the following example:
// let's assume that we're in a thread Y and we've received
// the `initialSpan` from thread X
Span continuedSpan = this.tracer.toSpan(newSpan.context());
try {
// ...
// You can tag a span
continuedSpan.tag("taxValue", taxValue);
// ...
// You can log an event on a span
continuedSpan.annotate("taxCalculated");
}
finally {
// Once done remember to flush the span. That means that
// it will get reported but the span itself is not yet finished
continuedSpan.flush();
}9.3. Creating a Span with an explicit Parent
You might want to start a new span and provide an explicit parent of that span.
Assume that the parent of a span is in one thread and you want to start a new span in another thread.
In Brave, whenever you call nextSpan(), it creates a span in reference to the span that is currently in scope.
You can put the span in scope and then call nextSpan(), as shown in the following example:
// let's assume that we're in a thread Y and we've received
// the `initialSpan` from thread X. `initialSpan` will be the parent
// of the `newSpan`
Span newSpan = null;
try (Tracer.SpanInScope ws = this.tracer.withSpanInScope(initialSpan)) {
newSpan = this.tracer.nextSpan().name("calculateCommission");
// ...
// You can tag a span
newSpan.tag("commissionValue", commissionValue);
// ...
// You can log an event on a span
newSpan.annotate("commissionCalculated");
}
finally {
// Once done remember to finish the span. This will allow collecting
// the span to send it to Zipkin. The tags and events set on the
// newSpan will not be present on the parent
if (newSpan != null) {
newSpan.finish();
}
}| After creating such a span, you must finish it. Otherwise it is not reported (for example, to Zipkin). |
10. Naming spans
Picking a span name is not a trivial task. A span name should depict an operation name. The name should be low cardinality, so it should not include identifiers.
Since there is a lot of instrumentation going on, some span names are artificial:
-
controller-method-namewhen received by a Controller with a method name ofcontrollerMethodName -
asyncfor asynchronous operations done with wrappedCallableandRunnableinterfaces. -
Methods annotated with
@Scheduledreturn the simple name of the class.
Fortunately, for asynchronous processing, you can provide explicit naming.
10.1. @SpanName Annotation
You can name the span explicitly by using the @SpanName annotation, as shown in the following example:
@SpanName("calculateTax")
class TaxCountingRunnable implements Runnable {
@Override
public void run() {
// perform logic
}
}In this case, when processed in the following manner, the span is named calculateTax:
Runnable runnable = new TraceRunnable(this.tracing, spanNamer,
new TaxCountingRunnable());
Future<?> future = executorService.submit(runnable);
// ... some additional logic ...
future.get();10.2. toString() method
It is pretty rare to create separate classes for Runnable or Callable.
Typically, one creates an anonymous instance of those classes.
You cannot annotate such classes.
To overcome that limitation, if there is no @SpanName annotation present, we check whether the class has a custom implementation of the toString() method.
Running such code leads to creating a span named calculateTax, as shown in the following example:
Runnable runnable = new TraceRunnable(this.tracing, spanNamer, new Runnable() {
@Override
public void run() {
// perform logic
}
@Override
public String toString() {
return "calculateTax";
}
});
Future<?> future = executorService.submit(runnable);
// ... some additional logic ...
future.get();11. Managing Spans with Annotations
You can manage spans with a variety of annotations.
11.1. Rationale
There are a number of good reasons to manage spans with annotations, including:
-
API-agnostic means to collaborate with a span. Use of annotations lets users add to a span with no library dependency on a span api. Doing so lets Sleuth change its core API to create less impact to user code.
-
Reduced surface area for basic span operations. Without this feature, you must use the span api, which has lifecycle commands that could be used incorrectly. By only exposing scope, tag, and log functionality, you can collaborate without accidentally breaking span lifecycle.
-
Collaboration with runtime generated code. With libraries such as Spring Data and Feign, the implementations of interfaces are generated at runtime. Consequently, span wrapping of objects was tedious. Now you can provide annotations over interfaces and the arguments of those interfaces.
11.2. Creating New Spans
If you do not want to create local spans manually, you can use the @NewSpan annotation.
Also, we provide the @SpanTag annotation to add tags in an automated fashion.
Now we can consider some examples of usage.
@NewSpan
void testMethod();Annotating the method without any parameter leads to creating a new span whose name equals the annotated method name.
@NewSpan("customNameOnTestMethod4")
void testMethod4();If you provide the value in the annotation (either directly or by setting the name parameter), the created span has the provided value as the name.
// method declaration
@NewSpan(name = "customNameOnTestMethod5")
void testMethod5(@SpanTag("testTag") String param);
// and method execution
this.testBean.testMethod5("test");You can combine both the name and a tag. Let’s focus on the latter.
In this case, the value of the annotated method’s parameter runtime value becomes the value of the tag.
In our sample, the tag key is testTag, and the tag value is test.
@NewSpan(name = "customNameOnTestMethod3")
@Override
public void testMethod3() {
}You can place the @NewSpan annotation on both the class and an interface.
If you override the interface’s method and provide a different value for the @NewSpan annotation, the most
concrete one wins (in this case customNameOnTestMethod3 is set).
11.3. Continuing Spans
If you want to add tags and annotations to an existing span, you can use the @ContinueSpan annotation, as shown in the following example:
// method declaration
@ContinueSpan(log = "testMethod11")
void testMethod11(@SpanTag("testTag11") String param);
// method execution
this.testBean.testMethod11("test");
this.testBean.testMethod13();(Note that, in contrast with the @NewSpan annotation ,you can also add logs with the log parameter.)
That way, the span gets continued and:
-
Log entries named
testMethod11.beforeandtestMethod11.afterare created. -
If an exception is thrown, a log entry named
testMethod11.afterFailureis also created. -
A tag with a key of
testTag11and a value oftestis created.
11.4. Advanced Tag Setting
There are 3 different ways to add tags to a span. All of them are controlled by the SpanTag annotation.
The precedence is as follows:
-
Try with a bean of
TagValueResolvertype and a provided name. -
If the bean name has not been provided, try to evaluate an expression. We search for a
TagValueExpressionResolverbean. The default implementation uses SPEL expression resolution. IMPORTANT You can only reference properties from the SPEL expression. Method execution is not allowed due to security constraints. -
If we do not find any expression to evaluate, return the
toString()value of the parameter.
11.4.1. Custom extractor
The value of the tag for the following method is computed by an implementation of TagValueResolver interface.
Its class name has to be passed as the value of the resolver attribute.
Consider the following annotated method:
@NewSpan
public void getAnnotationForTagValueResolver(
@SpanTag(key = "test", resolver = TagValueResolver.class) String test) {
}Now further consider the following TagValueResolver bean implementation:
@Bean(name = "myCustomTagValueResolver")
public TagValueResolver tagValueResolver() {
return parameter -> "Value from myCustomTagValueResolver";
}The two preceding examples lead to setting a tag value equal to Value from myCustomTagValueResolver.
11.4.2. Resolving Expressions for a Value
Consider the following annotated method:
@NewSpan
public void getAnnotationForTagValueExpression(@SpanTag(key = "test",
expression = "'hello' + ' characters'") String test) {
}No custom implementation of a TagValueExpressionResolver leads to evaluation of the SPEL expression, and a tag with a value of 4 characters is set on the span.
If you want to use some other expression resolution mechanism, you can create your own implementation of the bean.
11.4.3. Using the toString() method
Consider the following annotated method:
@NewSpan
public void getAnnotationForArgumentToString(@SpanTag("test") Long param) {
}Running the preceding method with a value of 15 leads to setting a tag with a String value of "15".
12. Customizations
12.1. Customizers
With Brave 5.7 you have various options of providing customizers for your project. Brave ships with
-
TracingCustomizer- allows configuration plugins to collaborate on building an instance ofTracing. -
CurrentTraceContextCustomizer- allows configuration plugins to collaborate on building an instance ofCurrentTraceContext. -
ExtraFieldCustomizer- allows configuration plugins to collaborate on building an instance ofExtraFieldPropagation.Factory.
Sleuth will search for beans of those types and automatically apply customizations.
12.2. HTTP
12.2.1. Data Policy
The default span data policy for HTTP requests is described in Brave: github.com/openzipkin/brave/tree/master/instrumentation/http#span-data-policy
To add different data to the span, you need to register a bean of type
brave.http.HttpRequestParser or brave.http.HttpResponseParser based on when
the data is collected.
The bean names correspond to the request or response side, and whether it is
a client or server. For example, sleuthHttpClientRequestParser changes what
is collected before a client request is sent to the server.
For your convenience @HttpClientRequestParser, @HttpClientResponseParser
and corresponding server annotations can be used to inject the proper beans
or to reference the bean names via their static String NAME fields.
Here’s an example adding the HTTP url in addition to defaults:
@Configuration
class Config {
@Bean(name = { HttpClientRequestParser.NAME, HttpServerRequestParser.NAME })
HttpRequestParser sleuthHttpServerRequestParser() {
return (req, context, span) -> {
HttpRequestParser.DEFAULT.parse(req, context, span);
String url = req.url();
if (url != null) {
span.tag("http.url", url);
}
};
}
}12.2.2. Sampling
If client /server sampling is required, just register a bean of type
brave.sampler.SamplerFunction<HttpRequest> and name the bean
sleuthHttpClientSampler for client sampler and sleuthHttpServerSampler
for server sampler.
For your convenience the @HttpClientSampler and @HttpServerSampler
annotations can be used to inject the proper beans or to reference the bean
names via their static String NAME fields.
Check out Brave’s code to see an example of how to make a path-based sampler github.com/openzipkin/brave/tree/master/instrumentation/http#sampling-policy
If you want to completely rewrite the HttpTracing bean you can use the SkipPatternProvider
interface to retrieve the URL Pattern for spans that should be not sampled. Below you can see
an example of usage of SkipPatternProvider inside a server side, Sampler<HttpRequest>.
@Configuration
class Config {
@Bean(name = HttpServerSampler.NAME)
SamplerFunction<HttpRequest> myHttpSampler(SkipPatternProvider provider) {
Pattern pattern = provider.skipPattern();
return request -> {
String url = request.path();
boolean shouldSkip = pattern.matcher(url).matches();
if (shouldSkip) {
return false;
}
return null;
};
}
}12.3. TracingFilter
You can also modify the behavior of the TracingFilter, which is the component that is responsible for processing the input HTTP request and adding tags basing on the HTTP response.
You can customize the tags or modify the response headers by registering your own instance of the TracingFilter bean.
In the following example, we register the TracingFilter bean, add the ZIPKIN-TRACE-ID response header containing the current Span’s trace id, and add a tag with key custom and a value tag to the span.
@Component
@Order(TraceWebServletAutoConfiguration.TRACING_FILTER_ORDER + 1)
class MyFilter extends GenericFilterBean {
private final Tracer tracer;
MyFilter(Tracer tracer) {
this.tracer = tracer;
}
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
Span currentSpan = this.tracer.currentSpan();
if (currentSpan == null) {
chain.doFilter(request, response);
return;
}
// for readability we're returning trace id in a hex form
((HttpServletResponse) response).addHeader("ZIPKIN-TRACE-ID",
currentSpan.context().traceIdString());
// we can also add some custom tags
currentSpan.tag("custom", "tag");
chain.doFilter(request, response);
}
}12.4. Messaging
Sleuth automatically configures the MessagingTracing bean which serves as a
foundation for Messaging instrumentation such as Kafka or JMS.
If a customization of producer / consumer sampling of messaging traces is required,
just register a bean of type brave.sampler.SamplerFunction<MessagingRequest> and
name the bean sleuthProducerSampler for producer sampler and sleuthConsumerSampler
for consumer sampler.
For your convenience the @ProducerSampler and @ConsumerSampler
annotations can be used to inject the proper beans or to reference the bean
names via their static String NAME fields.
Ex. Here’s a sampler that traces 100 consumer requests per second, except for
the "alerts" channel. Other requests will use a global rate provided by the
Tracing component.
@Configuration
class Config {
}12.5. RPC
Sleuth automatically configures the RpcTracing bean which serves as a
foundation for RPC instrumentation such as gRPC or Dubbo.
If a customization of client / server sampling of the RPC traces is required,
just register a bean of type brave.sampler.SamplerFunction<RpcRequest> and
name the bean sleuthRpcClientSampler for client sampler and
sleuthRpcServerSampler for server sampler.
For your convenience the @RpcClientSampler and @RpcServerSampler
annotations can be used to inject the proper beans or to reference the bean
names via their static String NAME fields.
Ex. Here’s a sampler that traces 100 "GetUserToken" server requests per second. This doesn’t start new traces for requests to the health check service. Other requests will use the global sampling configuration.
@Configuration
class Config {
@Bean(name = RpcServerSampler.NAME)
SamplerFunction<RpcRequest> myRpcSampler() {
Matcher<RpcRequest> userAuth = and(serviceEquals("users.UserService"),
methodEquals("GetUserToken"));
return RpcRuleSampler.newBuilder()
.putRule(serviceEquals("grpc.health.v1.Health"), Sampler.NEVER_SAMPLE)
.putRule(userAuth, RateLimitingSampler.create(100)).build();
}
}12.6. Custom service name
By default, Sleuth assumes that, when you send a span to Zipkin, you want the span’s service name to be equal to the value of the spring.application.name property.
That is not always the case, though.
There are situations in which you want to explicitly provide a different service name for all spans coming from your application.
To achieve that, you can pass the following property to your application to override that value (the example is for a service named myService):
spring.zipkin.service.name: myService12.7. Customization of Reported Spans
Before reporting spans (for example, to Zipkin) you may want to modify that span in some way.
You can do so by implementing a SpanHandler.
In Sleuth, we generate spans with a fixed name.
Some users want to modify the name depending on values of tags.
You can implement the SpanHandler interface to alter that name.
The following example shows how to register two beans that implement SpanHandler:
@Bean
SpanHandler handlerOne() {
return new SpanHandler() {
@Override
public boolean end(TraceContext traceContext, MutableSpan span,
Cause cause) {
span.name("foo");
return true; // keep this span
}
};
}
@Bean
SpanHandler handlerTwo() {
return new SpanHandler() {
@Override
public boolean end(TraceContext traceContext, MutableSpan span,
Cause cause) {
span.name(span.name() + " bar");
return true; // keep this span
}
};
}The preceding example results in changing the name of the reported span to foo bar, just before it gets reported (for example, to Zipkin).
12.8. Host Locator
| This section is about defining host from service discovery. It is NOT about finding Zipkin through service discovery. |
To define the host that corresponds to a particular span, we need to resolve the host name and port. The default approach is to take these values from server properties. If those are not set, we try to retrieve the host name from the network interfaces.
If you have the discovery client enabled and prefer to retrieve the host address from the registered instance in a service registry, you have to set the spring.zipkin.locator.discovery.enabled property (it is applicable for both HTTP-based and Stream-based span reporting), as follows:
spring.zipkin.locator.discovery.enabled: true13. Sending Spans to Zipkin
By default, if you add spring-cloud-starter-zipkin as a dependency to your project, when the span is closed, it is sent to Zipkin over HTTP.
The communication is asynchronous.
You can configure the URL by setting the spring.zipkin.baseUrl property, as follows:
spring.zipkin.baseUrl: https://192.168.99.100:9411/If you want to find Zipkin through service discovery, you can pass the Zipkin’s service ID inside the URL, as shown in the following example for zipkinserver service ID:
spring.zipkin.baseUrl: https://zipkinserver/To disable this feature just set spring.zipkin.discoveryClientEnabled to `false.
When the Discovery Client feature is enabled, Sleuth uses
LoadBalancerClient to find the URL of the Zipkin Server. It means
that you can set up the load balancing configuration e.g. via Ribbon.
zipkinserver:
ribbon:
ListOfServers: host1,host2If you have web, rabbit, activemq or kafka together on the classpath, you might need to pick the means by which you would like to send spans to zipkin.
To do so, set web, rabbit, activemq or kafka to the spring.zipkin.sender.type property.
The following example shows setting the sender type for web:
spring.zipkin.sender.type: webTo customize the RestTemplate that sends spans to Zipkin via HTTP, you can register
the ZipkinRestTemplateCustomizer bean.
@Configuration
class MyConfig {
@Bean ZipkinRestTemplateCustomizer myCustomizer() {
return new ZipkinRestTemplateCustomizer() {
@Override
void customize(RestTemplate restTemplate) {
// customize the RestTemplate
}
};
}
}If, however, you would like to control the full process of creating the RestTemplate
object, you will have to create a bean of zipkin2.reporter.Sender type.
@Bean Sender myRestTemplateSender(ZipkinProperties zipkin,
ZipkinRestTemplateCustomizer zipkinRestTemplateCustomizer) {
RestTemplate restTemplate = mySuperCustomRestTemplate();
zipkinRestTemplateCustomizer.customize(restTemplate);
return myCustomSender(zipkin, restTemplate);
}14. Zipkin Stream Span Consumer
| We recommend using Zipkin’s native support for message-based span sending. Starting from the Edgware release, the Zipkin Stream server is deprecated. In the Finchley release, it got removed. |
If for some reason you need to create the deprecated Stream Zipkin server, see the Dalston Documentation.
15. Integrations
15.1. OpenTracing
Spring Cloud Sleuth is compatible with OpenTracing.
If you have OpenTracing on the classpath, we automatically register the OpenTracing Tracer bean.
If you wish to disable this, set spring.sleuth.opentracing.enabled to false
15.2. Runnable and Callable
If you wrap your logic in Runnable or Callable, you can wrap those classes in their Sleuth representative, as shown in the following example for Runnable:
Runnable runnable = new Runnable() {
@Override
public void run() {
// do some work
}
@Override
public String toString() {
return "spanNameFromToStringMethod";
}
};
// Manual `TraceRunnable` creation with explicit "calculateTax" Span name
Runnable traceRunnable = new TraceRunnable(this.tracing, spanNamer, runnable,
"calculateTax");
// Wrapping `Runnable` with `Tracing`. That way the current span will be available
// in the thread of `Runnable`
Runnable traceRunnableFromTracer = this.tracing.currentTraceContext()
.wrap(runnable);The following example shows how to do so for Callable:
Callable<String> callable = new Callable<String>() {
@Override
public String call() throws Exception {
return someLogic();
}
@Override
public String toString() {
return "spanNameFromToStringMethod";
}
};
// Manual `TraceCallable` creation with explicit "calculateTax" Span name
Callable<String> traceCallable = new TraceCallable<>(this.tracing, spanNamer,
callable, "calculateTax");
// Wrapping `Callable` with `Tracing`. That way the current span will be available
// in the thread of `Callable`
Callable<String> traceCallableFromTracer = this.tracing.currentTraceContext()
.wrap(callable);That way, you ensure that a new span is created and closed for each execution.
15.3. Spring Cloud CircuitBreaker
If you have Spring Cloud CircuitBreaker on the classpath, we will wrap the passed command Supplier and the fallback Function in its trace representations. In order to disable this instrumentation set spring.sleuth.circuitbreaker.enabled to false.
15.4. Hystrix
15.4.1. Custom Concurrency Strategy
We register a custom HystrixConcurrencyStrategy called TraceCallable that wraps all Callable instances in their Sleuth representative.
The strategy either starts or continues a span, depending on whether tracing was already going on before the Hystrix command was called.
Optionally, you can set spring.sleuth.hystrix.strategy.passthrough to true to just propagate the trace context to the Hystrix execution thread if you don’t wish to start a new span.
To disable the custom Hystrix Concurrency Strategy, set the spring.sleuth.hystrix.strategy.enabled to false.
15.4.2. Manual Command setting
Assume that you have the following HystrixCommand:
HystrixCommand<String> hystrixCommand = new HystrixCommand<String>(setter) {
@Override
protected String run() throws Exception {
return someLogic();
}
};To pass the tracing information, you have to wrap the same logic in the Sleuth version of the HystrixCommand, which is called
TraceCommand, as shown in the following example:
TraceCommand<String> traceCommand = new TraceCommand<String>(tracer, setter) {
@Override
public String doRun() throws Exception {
return someLogic();
}
};15.5. RxJava
We registering a custom RxJavaSchedulersHook that wraps all Action0 instances in their Sleuth representative, which is called TraceAction.
The hook either starts or continues a span, depending on whether tracing was already going on before the Action was scheduled.
To disable the custom RxJavaSchedulersHook, set the spring.sleuth.rxjava.schedulers.hook.enabled to false.
You can define a list of regular expressions for thread names for which you do not want spans to be created.
To do so, provide a comma-separated list of regular expressions in the spring.sleuth.rxjava.schedulers.ignoredthreads property.
| The suggest approach to reactive programming and Sleuth is to use the Reactor support. |
15.6. HTTP integration
Features from this section can be disabled by setting the spring.sleuth.web.enabled property with value equal to false.
15.6.1. HTTP Filter
Through the TracingFilter, all sampled incoming requests result in creation of a Span.
That Span’s name is http: + the path to which the request was sent.
For example, if the request was sent to /this/that then the name will be http:/this/that.
You can configure which URIs you would like to skip by setting the spring.sleuth.web.skipPattern property.
If you have ManagementServerProperties on classpath, its value of contextPath gets appended to the provided skip pattern.
If you want to reuse the Sleuth’s default skip patterns and just append your own, pass those patterns by using the spring.sleuth.web.additionalSkipPattern.
By default, all the spring boot actuator endpoints are automatically added to the skip pattern.
If you want to disable this behaviour set spring.sleuth.web.ignore-auto-configured-skip-patterns
to true.
To change the order of tracing filter registration, please set the
spring.sleuth.web.filter-order property.
To disable the filter that logs uncaught exceptions you can disable the
spring.sleuth.web.exception-throwing-filter-enabled property.
15.6.2. HandlerInterceptor
Since we want the span names to be precise, we use a TraceHandlerInterceptor that either wraps an existing HandlerInterceptor or is added directly to the list of existing HandlerInterceptors.
The TraceHandlerInterceptor adds a special request attribute to the given HttpServletRequest.
If the the TracingFilter does not see this attribute, it creates a "fallback" span, which is an additional span created on the server side so that the trace is presented properly in the UI.
If that happens, there is probably missing instrumentation.
In that case, please file an issue in Spring Cloud Sleuth.
15.6.3. Async Servlet support
If your controller returns a Callable or a WebAsyncTask, Spring Cloud Sleuth continues the existing span instead of creating a new one.
15.6.4. WebFlux support
Through TraceWebFilter, all sampled incoming requests result in creation of a Span.
That Span’s name is http: + the path to which the request was sent.
For example, if the request was sent to /this/that, the name is http:/this/that.
You can configure which URIs you would like to skip by using the spring.sleuth.web.skipPattern property.
If you have ManagementServerProperties on the classpath, its value of contextPath gets appended to the provided skip pattern.
If you want to reuse Sleuth’s default skip patterns and append your own, pass those patterns by using the spring.sleuth.web.additionalSkipPattern.
To change the order of tracing filter registration, please set the
spring.sleuth.web.filter-order property.
15.6.5. Dubbo RPC support
Via the integration with Brave, Spring Cloud Sleuth supports Dubbo.
It’s enough to add the brave-instrumentation-dubbo dependency:
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-dubbo</artifactId>
</dependency>You need to also set a dubbo.properties file with the following contents:
dubbo.provider.filter=tracing
dubbo.consumer.filter=tracing15.7. HTTP Client Integration
15.7.1. Synchronous Rest Template
We inject a RestTemplate interceptor to ensure that all the tracing information is passed to the requests.
Each time a call is made, a new Span is created.
It gets closed upon receiving the response.
To block the synchronous RestTemplate features, set spring.sleuth.web.client.enabled to false.
You have to register RestTemplate as a bean so that the interceptors get injected.
If you create a RestTemplate instance with a new keyword, the instrumentation does NOT work.
|
15.7.2. Asynchronous Rest Template
Starting with Sleuth 2.0.0, we no longer register a bean of AsyncRestTemplate type.
It is up to you to create such a bean.
Then we instrument it.
|
To block the AsyncRestTemplate features, set spring.sleuth.web.async.client.enabled to false.
To disable creation of the default TraceAsyncClientHttpRequestFactoryWrapper, set spring.sleuth.web.async.client.factory.enabled
to false.
If you do not want to create AsyncRestClient at all, set spring.sleuth.web.async.client.template.enabled to false.
Multiple Asynchronous Rest Templates
Sometimes you need to use multiple implementations of the Asynchronous Rest Template.
In the following snippet, you can see an example of how to set up such a custom AsyncRestTemplate:
@Configuration
@EnableAutoConfiguration
static class Config {
@Bean(name = "customAsyncRestTemplate")
public AsyncRestTemplate traceAsyncRestTemplate() {
return new AsyncRestTemplate(asyncClientFactory(),
clientHttpRequestFactory());
}
private ClientHttpRequestFactory clientHttpRequestFactory() {
ClientHttpRequestFactory clientHttpRequestFactory = new CustomClientHttpRequestFactory();
// CUSTOMIZE HERE
return clientHttpRequestFactory;
}
private AsyncClientHttpRequestFactory asyncClientFactory() {
AsyncClientHttpRequestFactory factory = new CustomAsyncClientHttpRequestFactory();
// CUSTOMIZE HERE
return factory;
}
}15.7.3. WebClient
We inject a ExchangeFilterFunction implementation that creates a span and, through on-success and on-error callbacks, takes care of closing client-side spans.
To block this feature, set spring.sleuth.web.client.enabled to false.
You have to register either a WebClient or WebClient.Builder as a bean so that the tracing instrumentation gets applied.
If you manually create a WebClient or WebClient.Builder, the instrumentation does NOT work.
|
15.7.4. Traverson
If you use the Traverson library, you can inject a RestTemplate as a bean into your Traverson object.
Since RestTemplate is already intercepted, you get full support for tracing in your client. The following pseudo code
shows how to do that:
@Autowired RestTemplate restTemplate;
Traverson traverson = new Traverson(URI.create("https://some/address"),
MediaType.APPLICATION_JSON, MediaType.APPLICATION_JSON_UTF8).setRestOperations(restTemplate);
// use Traverson15.7.5. Apache HttpClientBuilder and HttpAsyncClientBuilder
We instrument the HttpClientBuilder and HttpAsyncClientBuilder so that
tracing context gets injected to the sent requests.
To block these features, set spring.sleuth.web.client.enabled to false.
15.7.6. Netty HttpClient
We instrument the Netty’s HttpClient.
To block this feature, set spring.sleuth.web.client.enabled to false.
You have to register HttpClient as a bean so that the instrumentation happens.
If you create a HttpClient instance with a new keyword, the instrumentation does NOT work.
|
15.7.7. UserInfoRestTemplateCustomizer
We instrument the Spring Security’s UserInfoRestTemplateCustomizer.
To block this feature, set spring.sleuth.web.client.enabled to false.
15.8. Feign
By default, Spring Cloud Sleuth provides integration with Feign through TraceFeignClientAutoConfiguration.
You can disable it entirely by setting spring.sleuth.feign.enabled to false.
If you do so, no Feign-related instrumentation take place.
Part of Feign instrumentation is done through a FeignBeanPostProcessor.
You can disable it by setting spring.sleuth.feign.processor.enabled to false.
If you set it to false, Spring Cloud Sleuth does not instrument any of your custom Feign components.
However, all the default instrumentation is still there.
15.9. gRPC
Spring Cloud Sleuth provides instrumentation for gRPC through TraceGrpcAutoConfiguration. You can disable it entirely by setting spring.sleuth.grpc.enabled to false.
15.9.1. Variant 1
Dependencies
| The gRPC integration relies on two external libraries to instrument clients and servers and both of those libraries must be on the class path to enable the instrumentation. |
Maven:
<dependency>
<groupId>io.github.lognet</groupId>
<artifactId>grpc-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-grpc</artifactId>
</dependency>Gradle:
compile("io.github.lognet:grpc-spring-boot-starter")
compile("io.zipkin.brave:brave-instrumentation-grpc")Server Instrumentation
Spring Cloud Sleuth leverages grpc-spring-boot-starter to register Brave’s gRPC server interceptor with all services annotated with @GRpcService.
Client Instrumentation
gRPC clients leverage a ManagedChannelBuilder to construct a ManagedChannel used to communicate to the gRPC server. The native ManagedChannelBuilder provides static methods as entry points for construction of ManagedChannel instances, however, this mechanism is outside the influence of the Spring application context.
Spring Cloud Sleuth provides a SpringAwareManagedChannelBuilder that can be customized through the Spring application context and injected by gRPC clients. This builder must be used when creating ManagedChannel instances.
|
Sleuth creates a TracingManagedChannelBuilderCustomizer which inject Brave’s client interceptor into the SpringAwareManagedChannelBuilder.
15.9.2. Variant 2
Grpc Spring Boot Starter automatically detects the presence of Spring Cloud Sleuth and brave’s instrumentation for gRPC and registers the necessary client and/or server tooling.
15.10. Asynchronous Communication
15.10.1. @Async Annotated methods
In Spring Cloud Sleuth, we instrument async-related components so that the tracing information is passed between threads.
You can disable this behavior by setting the value of spring.sleuth.async.enabled to false.
If you annotate your method with @Async, we automatically create a new Span with the following characteristics:
-
If the method is annotated with
@SpanName, the value of the annotation is the Span’s name. -
If the method is not annotated with
@SpanName, the Span name is the annotated method name. -
The span is tagged with the method’s class name and method name.
15.10.2. @Scheduled Annotated Methods
In Spring Cloud Sleuth, we instrument scheduled method execution so that the tracing information is passed between threads.
You can disable this behavior by setting the value of spring.sleuth.scheduled.enabled to false.
If you annotate your method with @Scheduled, we automatically create a new span with the following characteristics:
-
The span name is the annotated method name.
-
The span is tagged with the method’s class name and method name.
If you want to skip span creation for some @Scheduled annotated classes, you can set the spring.sleuth.scheduled.skipPattern with a regular expression that matches the fully qualified name of the @Scheduled annotated class.
If you use spring-cloud-sleuth-stream and spring-cloud-netflix-hystrix-stream together, a span is created for each Hystrix metrics and sent to Zipkin.
This behavior may be annoying. That’s why, by default, spring.sleuth.scheduled.skipPattern=org.springframework.cloud.netflix.hystrix.stream.HystrixStreamTask.
15.10.3. Executor, ExecutorService, and ScheduledExecutorService
We provide LazyTraceExecutor, TraceableExecutorService, and TraceableScheduledExecutorService. Those implementations create spans each time a new task is submitted, invoked, or scheduled.
The following example shows how to pass tracing information with TraceableExecutorService when working with CompletableFuture:
CompletableFuture<Long> completableFuture = CompletableFuture.supplyAsync(() -> {
// perform some logic
return 1_000_000L;
}, new TraceableExecutorService(beanFactory, executorService,
// 'calculateTax' explicitly names the span - this param is optional
"calculateTax"));
Sleuth does not work with parallelStream() out of the box.
If you want to have the tracing information propagated through the stream, you have to use the approach with supplyAsync(...), as shown earlier.
|
If there are beans that implement the Executor interface that you would like
to exclude from span creation, you can use the spring.sleuth.async.ignored-beans
property where you can provide a list of bean names.
Customization of Executors
Sometimes, you need to set up a custom instance of the AsyncExecutor.
The following example shows how to set up such a custom Executor:
@Configuration
@EnableAutoConfiguration
@EnableAsync
// add the infrastructure role to ensure that the bean gets auto-proxied
@Role(BeanDefinition.ROLE_INFRASTRUCTURE)
static class CustomExecutorConfig extends AsyncConfigurerSupport {
@Autowired
BeanFactory beanFactory;
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// CUSTOMIZE HERE
executor.setCorePoolSize(7);
executor.setMaxPoolSize(42);
executor.setQueueCapacity(11);
executor.setThreadNamePrefix("MyExecutor-");
// DON'T FORGET TO INITIALIZE
executor.initialize();
return new LazyTraceExecutor(this.beanFactory, executor);
}
}
To ensure that your configuration gets post processed, remember
to add the @Role(BeanDefinition.ROLE_INFRASTRUCTURE) on your
@Configuration class
|
15.11. Messaging
Features from this section can be disabled by setting the spring.sleuth.messaging.enabled property with value equal to false.
15.11.1. Spring Integration and Spring Cloud Stream
Spring Cloud Sleuth integrates with Spring Integration.
It creates spans for publish and subscribe events.
To disable Spring Integration instrumentation, set spring.sleuth.integration.enabled to false.
You can provide the spring.sleuth.integration.patterns pattern to explicitly provide the names of channels that you want to include for tracing.
By default, all channels but hystrixStreamOutput channel are included.
When using the Executor to build a Spring Integration IntegrationFlow, you must use the untraced version of the Executor.
Decorating the Spring Integration Executor Channel with TraceableExecutorService causes the spans to be improperly closed.
|
If you want to customize the way tracing context is read from and written to message headers, it’s enough for you to register beans of types:
-
Propagation.Setter<MessageHeaderAccessor, String>- for writing headers to the message -
Propagation.Getter<MessageHeaderAccessor, String>- for reading headers from the message
15.11.2. Spring RabbitMq
We instrument the RabbitTemplate so that tracing headers get injected
into the message.
To block this feature, set spring.sleuth.messaging.rabbit.enabled to false.
15.11.3. Spring Kafka
We instrument the Spring Kafka’s ProducerFactory and ConsumerFactory
so that tracing headers get injected into the created Spring Kafka’s
Producer and Consumer.
To block this feature, set spring.sleuth.messaging.kafka.enabled to false.
15.11.4. Spring Kafka Streams
We instrument the KafkaStreams KafkaClientSupplier so that tracing headers
get injected into the Producer and Consumer`s. A `KafkaStreamsTracing bean
allows for further instrumentation through additional TransformerSupplier and
ProcessorSupplier methods.
To block this feature, set spring.sleuth.messaging.kafka.streams.enabled to false.
15.11.5. Spring JMS
We instrument the JmsTemplate so that tracing headers get injected
into the message. We also support @JmsListener annotated methods on the consumer side.
To block this feature, set spring.sleuth.messaging.jms.enabled to false.
| We don’t support baggage propagation for JMS |
15.11.6. Spring Cloud AWS Messaging SQS
We instrument @SqsListener which is provided by org.springframework.cloud:spring-cloud-aws-messaging
so that tracing headers get extracted from the message and a trace gets put into the context.
To block this feature, set spring.sleuth.messaging.sqs.enabled to false.
15.12. Zuul
We instrument the Zuul Ribbon integration by enriching the Ribbon requests with tracing information.
To disable Zuul support, set the spring.sleuth.zuul.enabled property to false.
15.13. Redis
We set tracing property to Lettcue ClientResources instance to enable Brave tracing built in Lettuce .
To disable Redis support, set the spring.sleuth.redis.enabled property to false.
15.14. Quartz
We instrument quartz jobs by adding Job/Trigger listeners to the Quartz Scheduler.
To turn off this feature, set the spring.sleuth.quartz.enabled property to false.
15.15. Project Reactor
For projects depending on Project Reactor such as Spring Cloud Gateway, we suggest turning the spring.sleuth.reactor.decorate-on-each option to false. That way an increased performance gain should be observed in comparison to the standard instrumentation mechanism. What this option does is it will wrap decorate onLast operator instead of onEach which will result in creation of far fewer objects. The downside of this is that when Project Reactor will change threads, the trace propagation will continue without issues, however anything relying on the ThreadLocal such as e.g. MDC entries can be buggy.
16. Configuration properties
To see the list of all Sleuth related configuration properties please check the Appendix page.
17. Running examples
You can see the running examples deployed in the Pivotal Web Services. Check them out at the following links:
-
Zipkin for apps presented in the samples to the top. First make a request to Service 1 and then check out the trace in Zipkin.
-
Zipkin for Brewery on PWS, its Github Code. Ensure that you’ve picked the lookback period of 7 days. If there are no traces, go to Presenting application and order some beers. Then check Zipkin for traces.