3.1.3-SNAPSHOT
Reference Guide
This guide describes the RabbitMQ implementation of the Spring Cloud Stream Binder. It contains information about its design, usage and configuration options, as well as information on how the Stream Cloud Stream concepts map into RabbitMQ specific constructs.
1. Usage
To use the RabbitMQ binder, you can add it to your Spring Cloud Stream application, by using the following Maven coordinates:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>Alternatively, you can use the Spring Cloud Stream RabbitMQ Starter, as follows:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>2. RabbitMQ Binder Overview
The following simplified diagram shows how the RabbitMQ binder operates:

By default, the RabbitMQ Binder implementation maps each destination to a TopicExchange.
For each consumer group, a Queue is bound to that TopicExchange.
Each consumer instance has a corresponding RabbitMQ Consumer instance for its group’s Queue.
For partitioned producers and consumers, the queues are suffixed with the partition index and use the partition index as the routing key.
For anonymous consumers (those with no group property), an auto-delete queue (with a randomized unique name) is used.
By using the optional autoBindDlq option, you can configure the binder to create and configure dead-letter queues (DLQs) (and a dead-letter exchange DLX, as well as routing infrastructure).
By default, the dead letter queue has the name of the destination, appended with .dlq.
If retry is enabled (maxAttempts > 1), failed messages are delivered to the DLQ after retries are exhausted.
If retry is disabled (maxAttempts = 1), you should set requeueRejected to false (the default) so that failed messages are routed to the DLQ, instead of being re-queued.
In addition, republishToDlq causes the binder to publish a failed message to the DLQ (instead of rejecting it).
This feature lets additional information (such as the stack trace in the x-exception-stacktrace header) be added to the message in headers.
See the frameMaxHeadroom property for information about truncated stack traces.
This option does not need retry enabled.
You can republish a failed message after just one attempt.
Starting with version 1.2, you can configure the delivery mode of republished messages.
See the republishDeliveryMode property.
If the stream listener throws an ImmediateAcknowledgeAmqpException, the DLQ is bypassed and the message simply discarded.
Starting with version 2.1, this is true regardless of the setting of republishToDlq; previously it was only the case when republishToDlq was false.
Setting requeueRejected to true (with republishToDlq=false ) causes the message to be re-queued and redelivered continually, which is likely not what you want unless the reason for the failure is transient.
In general, you should enable retry within the binder by setting maxAttempts to greater than one or by setting republishToDlq to true.
|
Starting with version 3.1.2, if the consumer is marked as transacted, publishing to the DLQ will participate in the transaction.
This allows the transaction to roll back if the publishing fails for some reason (for example, if the user is not authorized to publish to the dead letter exchange).
In addition, if the connection factory is configured for publisher confirms or returns, the publication to the DLQ will wait for the confirmation and check for a returned message.
If a negative acknowledgment or returned message is received, the binder will throw an AmqpRejectAndDontRequeueException, allowing the broker to take care of publishing to the DLQ as if the republishToDlq property is false.
See RabbitMQ Binder Properties for more information about these properties.
The framework does not provide any standard mechanism to consume dead-letter messages (or to re-route them back to the primary queue). Some options are described in Dead-Letter Queue Processing.
When multiple RabbitMQ binders are used in a Spring Cloud Stream application, it is important to disable 'RabbitAutoConfiguration' to avoid the same configuration from RabbitAutoConfiguration being applied to the two binders.
You can exclude the class by using the @SpringBootApplication annotation.
|
Starting with version 2.0, the RabbitMessageChannelBinder sets the RabbitTemplate.userPublisherConnection property to true so that the non-transactional producers avoid deadlocks on consumers, which can happen if cached connections are blocked because of a memory alarm on the broker.
Currently, a multiplex consumer (a single consumer listening to multiple queues) is only supported for message-driven consumers; polled consumers can only retrieve messages from a single queue.
|
3. Configuration Options
This section contains settings specific to the RabbitMQ Binder and bound channels.
For general binding configuration options and properties, see the Spring Cloud Stream core documentation.
3.1. RabbitMQ Binder Properties
By default, the RabbitMQ binder uses Spring Boot’s ConnectionFactory.
Conseuqently, it supports all Spring Boot configuration options for RabbitMQ.
(For reference, see the Spring Boot documentation).
RabbitMQ configuration options use the spring.rabbitmq prefix.
In addition to Spring Boot options, the RabbitMQ binder supports the following properties:
- spring.cloud.stream.rabbit.binder.adminAddresses
-
A comma-separated list of RabbitMQ management plugin URLs. Only used when
nodescontains more than one entry. Each entry in this list must have a corresponding entry inspring.rabbitmq.addresses. Only needed if you use a RabbitMQ cluster and wish to consume from the node that hosts the queue. See Queue Affinity and the LocalizedQueueConnectionFactory for more information.Default: empty.
- spring.cloud.stream.rabbit.binder.nodes
-
A comma-separated list of RabbitMQ node names. When more than one entry, used to locate the server address where a queue is located. Each entry in this list must have a corresponding entry in
spring.rabbitmq.addresses. Only needed if you use a RabbitMQ cluster and wish to consume from the node that hosts the queue. See Queue Affinity and the LocalizedQueueConnectionFactory for more information.Default: empty.
- spring.cloud.stream.rabbit.binder.compressionLevel
-
The compression level for compressed bindings. See
java.util.zip.Deflater.Default:
1(BEST_LEVEL). - spring.cloud.stream.binder.connection-name-prefix
-
A connection name prefix used to name the connection(s) created by this binder. The name is this prefix followed by
#n, wherenincrements each time a new connection is opened.Default: none (Spring AMQP default).
3.2. RabbitMQ Consumer Properties
The following properties are available for Rabbit consumers only and must be prefixed with spring.cloud.stream.rabbit.bindings.<channelName>.consumer..
However if the same set of properties needs to be applied to most bindings, to
avoid repetition, Spring Cloud Stream supports setting values for all channels,
in the format of spring.cloud.stream.rabbit.default.<property>=<value>.
Also, keep in mind that binding specific property will override its equivalent in the default.
- acknowledgeMode
-
The acknowledge mode.
Default:
AUTO. - anonymousGroupPrefix
-
When the binding has no
groupproperty, an anonymous, auto-delete queue is bound to the destination exchange. The default naming stragegy for such queues results in a queue namedanonymous.<base64 representation of a UUID>. Set this property to change the prefix to something other than the default.Default:
anonymous.. - autoBindDlq
-
Whether to automatically declare the DLQ and bind it to the binder DLX.
Default:
false. - bindingRoutingKey
-
The routing key with which to bind the queue to the exchange (if
bindQueueistrue). Can be multiple keys - seebindingRoutingKeyDelimiter. For partitioned destinations,-<instanceIndex>is appended to each key.Default:
#. - bindingRoutingKeyDelimiter
-
When this is not null, 'bindingRoutingKey' is considered to be a list of keys delimited by this value; often a comma is used.
Default:
null. - bindQueue
-
Whether to declare the queue and bind it to the destination exchange. Set it to
falseif you have set up your own infrastructure and have previously created and bound the queue.Default:
true. - consumerTagPrefix
-
Used to create the consumer tag(s); will be appended by
#nwherenincrements for each consumer created. Example:${spring.application.name}-${spring.cloud.stream.bindings.input.group}-${spring.cloud.stream.instance-index}.Default: none - the broker will generate random consumer tags.
- containerType
-
Select the type of listener container to be used. See Choosing a Container in the Spring AMQP documentation for more information.
Default:
simple - deadLetterQueueName
-
The name of the DLQ
Default:
prefix+destination.dlq - deadLetterExchange
-
A DLX to assign to the queue. Relevant only if
autoBindDlqistrue.Default: 'prefix+DLX'
- deadLetterExchangeType
-
The type of the DLX to assign to the queue. Relevant only if
autoBindDlqistrue.Default: 'direct'
- deadLetterRoutingKey
-
A dead letter routing key to assign to the queue. Relevant only if
autoBindDlqistrue.Default:
destination - declareDlx
-
Whether to declare the dead letter exchange for the destination. Relevant only if
autoBindDlqistrue. Set tofalseif you have a pre-configured DLX.Default:
true. - declareExchange
-
Whether to declare the exchange for the destination.
Default:
true. - delayedExchange
-
Whether to declare the exchange as a
Delayed Message Exchange. Requires the delayed message exchange plugin on the broker. Thex-delayed-typeargument is set to theexchangeType.Default:
false. - dlqBindingArguments
-
Arguments applied when binding the dlq to the dead letter exchange; used with
headersdeadLetterExchangeTypeto specify headers to match on. For example…dlqBindingArguments.x-match=any,…dlqBindingArguments.someHeader=someValue.Default: empty
- dlqDeadLetterExchange
-
If a DLQ is declared, a DLX to assign to that queue.
Default:
none - dlqDeadLetterRoutingKey
-
If a DLQ is declared, a dead letter routing key to assign to that queue.
Default:
none - dlqExpires
-
How long before an unused dead letter queue is deleted (in milliseconds).
Default:
no expiration - dlqLazy
-
Declare the dead letter queue with the
x-queue-mode=lazyargument. See “Lazy Queues”. Consider using a policy instead of this setting, because using a policy allows changing the setting without deleting the queue.Default:
false. - dlqMaxLength
-
Maximum number of messages in the dead letter queue.
Default:
no limit - dlqMaxLengthBytes
-
Maximum number of total bytes in the dead letter queue from all messages.
Default:
no limit - dlqMaxPriority
-
Maximum priority of messages in the dead letter queue (0-255).
Default:
none - dlqOverflowBehavior
-
Action to take when
dlqMaxLengthordlqMaxLengthBytesis exceeded; currentlydrop-headorreject-publishbut refer to the RabbitMQ documentation.Default:
none - dlqQuorum.deliveryLimit
-
When
quorum.enabled=true, set a delivery limit after which the message is dropped or dead-lettered.Default: none - broker default will apply.
- dlqQuorum.enabled
-
When true, create a quorum dead letter queue instead of a classic queue.
Default: false
- dlqQuorum.initialQuorumSize
-
When
quorum.enabled=true, set the initial quorum size.Default: none - broker default will apply.
- dlqSingleActiveConsumer
-
Set to true to set the
x-single-active-consumerqueue property to true.Default:
false - dlqTtl
-
Default time to live to apply to the dead letter queue when declared (in milliseconds).
Default:
no limit - durableSubscription
-
Whether the subscription should be durable. Only effective if
groupis also set.Default:
true. - exchangeAutoDelete
-
If
declareExchangeis true, whether the exchange should be auto-deleted (that is, removed after the last queue is removed).Default:
true. - exchangeDurable
-
If
declareExchangeis true, whether the exchange should be durable (that is, it survives broker restart).Default:
true. - exchangeType
-
The exchange type:
direct,fanout,headersortopicfor non-partitioned destinations anddirect, headers ortopicfor partitioned destinations.Default:
topic. - exclusive
-
Whether to create an exclusive consumer. Concurrency should be 1 when this is
true. Often used when strict ordering is required but enabling a hot standby instance to take over after a failure. SeerecoveryInterval, which controls how often a standby instance attempts to consume. Consider usingsingleActiveConsumerinstead when using RabbitMQ 3.8 or later.Default:
false. - expires
-
How long before an unused queue is deleted (in milliseconds).
Default:
no expiration - failedDeclarationRetryInterval
-
The interval (in milliseconds) between attempts to consume from a queue if it is missing.
Default: 5000
- frameMaxHeadroom
-
The number of bytes to reserve for other headers when adding the stack trace to a DLQ message header. All headers must fit within the
frame_maxsize configured on the broker. Stack traces can be large; if the size plus this property exceedsframe_maxthen the stack trace will be truncated. A WARN log will be written; consider increasing theframe_maxor reducing the stack trace by catching the exception and throwing one with a smaller stack trace.Default: 20000
- headerPatterns
-
Patterns for headers to be mapped from inbound messages.
Default:
['*'](all headers). - lazy
-
Declare the queue with the
x-queue-mode=lazyargument. See “Lazy Queues”. Consider using a policy instead of this setting, because using a policy allows changing the setting without deleting the queue.Default:
false. - maxConcurrency
-
The maximum number of consumers. Not supported when the
containerTypeisdirect.Default:
1. - maxLength
-
The maximum number of messages in the queue.
Default:
no limit - maxLengthBytes
-
The maximum number of total bytes in the queue from all messages.
Default:
no limit - maxPriority
-
The maximum priority of messages in the queue (0-255).
Default:
none - missingQueuesFatal
-
When the queue cannot be found, whether to treat the condition as fatal and stop the listener container. Defaults to
falseso that the container keeps trying to consume from the queue — for example, when using a cluster and the node hosting a non-HA queue is down.Default:
false - overflowBehavior
-
Action to take when
maxLengthormaxLengthBytesis exceeded; currentlydrop-headorreject-publishbut refer to the RabbitMQ documentation.Default:
none - prefetch
-
Prefetch count.
Default:
1. - prefix
-
A prefix to be added to the name of the
destinationand queues.Default: "".
- queueBindingArguments
-
Arguments applied when binding the queue to the exchange; used with
headersexchangeTypeto specify headers to match on. For example…queueBindingArguments.x-match=any,…queueBindingArguments.someHeader=someValue.Default: empty
- queueDeclarationRetries
-
The number of times to retry consuming from a queue if it is missing. Relevant only when
missingQueuesFatalistrue. Otherwise, the container keeps retrying indefinitely. Not supported when thecontainerTypeisdirect.Default:
3 - queueNameGroupOnly
-
When true, consume from a queue with a name equal to the
group. Otherwise the queue name isdestination.group. This is useful, for example, when using Spring Cloud Stream to consume from an existing RabbitMQ queue.Default: false.
- quorum.deliveryLimit
-
When
quorum.enabled=true, set a delivery limit after which the message is dropped or dead-lettered.Default: none - broker default will apply.
- quorum.enabled
-
When true, create a quorum queue instead of a classic queue.
Default: false
- quorum.initialQuorumSize
-
When
quorum.enabled=true, set the initial quorum size.Default: none - broker default will apply.
- recoveryInterval
-
The interval between connection recovery attempts, in milliseconds.
Default:
5000. - requeueRejected
-
Whether delivery failures should be re-queued when retry is disabled or
republishToDlqisfalse.Default:
false.
- republishDeliveryMode
-
When
republishToDlqistrue, specifies the delivery mode of the republished message.Default:
DeliveryMode.PERSISTENT - republishToDlq
-
By default, messages that fail after retries are exhausted are rejected. If a dead-letter queue (DLQ) is configured, RabbitMQ routes the failed message (unchanged) to the DLQ. If set to
true, the binder republishs failed messages to the DLQ with additional headers, including the exception message and stack trace from the cause of the final failure. Also see the frameMaxHeadroom property.Default:
true - singleActiveConsumer
-
Set to true to set the
x-single-active-consumerqueue property to true.Default:
false - transacted
-
Whether to use transacted channels.
Default:
false. - ttl
-
Default time to live to apply to the queue when declared (in milliseconds).
Default:
no limit - txSize
-
The number of deliveries between acks. Not supported when the
containerTypeisdirect.Default:
1.
3.3. Advanced Listener Container Configuration
To set listener container properties that are not exposed as binder or binding properties, add a single bean of type ListenerContainerCustomizer to the application context.
The binder and binding properties will be set and then the customizer will be called.
The customizer (configure() method) is provided with the queue name as well as the consumer group as arguments.
3.4. Advanced Queue/Exchange/Binding Configuration
From time to time, the RabbitMQ team add new features that are enabled by setting some argument when declaring, for example, a queue.
Generally, such features are enabled in the binder by adding appropriate properties, but this may not be immediately available in a current version.
Starting with version 3.0.1, you can now add DeclarableCustomizer bean(s) to the application context to modify a Declarable (Queue, Exchange or Binding) just before the declaration is performed.
This allows you to add arguments that are not currently directly supported by the binder.
3.5. Receiving Batched Messages
With the RabbitMQ binder, there are two types of batches handled by consumer bindings:
3.5.1. Batches Created by Producers
Normally, if a producer binding has batch-enabled=true (see Rabbit Producer Properties), or a message is created by a BatchingRabbitTemplate, elements of the batch are returned as individual calls to the listener method.
Starting with version 3.0, any such batch can be presented as a List<?> to the listener method if spring.cloud.stream.bindings.<name>.consumer.batch-mode is set to true.
3.5.2. Consumer-side Batching
Starting with version 3.1, the consumer can be configured to assemble multiple inbound messages into a batch which is presented to the application as a List<?> of converted payloads.
The following simple application demonstrates how to use this technique:
spring.cloud.stream.bindings.input-in-0.group=someGroup
spring.cloud.stream.bindings.input-in-0.consumer.batch-mode=true
spring.cloud.stream.rabbit.bindings.input-in-0.consumer.enable-batching=true
spring.cloud.stream.rabbit.bindings.input-in-0.consumer.batch-size=10
spring.cloud.stream.rabbit.bindings.input-in-0.consumer.receive-timeout=200@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
Consumer<List<Thing>> input() {
return list -> {
System.out.println("Received " + list.size());
list.forEach(thing -> {
System.out.println(thing);
// ...
});
};
}
@Bean
public ApplicationRunner runner(RabbitTemplate template) {
return args -> {
template.convertAndSend("input-in-0.someGroup", "{\"field\":\"value1\"}");
template.convertAndSend("input-in-0.someGroup", "{\"field\":\"value2\"}");
};
}
public static class Thing {
private String field;
public Thing() {
}
public Thing(String field) {
this.field = field;
}
public String getField() {
return this.field;
}
public void setField(String field) {
this.field = field;
}
@Override
public String toString() {
return "Thing [field=" + this.field + "]";
}
}
}Received 2
Thing [field=value1]
Thing [field=value2]The number of messages in a batch is specified by the batch-size and receive-timeout properties; if the receive-timeout elapses with no new messages, a "short" batch is delivered.
Consumer-side batching is only supported with container-type=simple (the default).
|
If you wish to examine headers of consumer-side batched messages, you should consume Message<List<?>>; the headers are a List<Map<String, Object>> in a header AmqpInboundChannelAdapter.CONSOLIDATED_HEADERS, with the headers for each payload element in the corresponding index.
Again, here is a simple example:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
Consumer<Message<List<Thing>>> input() {
return msg -> {
List<Thing> things = msg.getPayload();
System.out.println("Received " + things.size());
@SuppressWarnings("unchecked")
List<Map<String, Object>> headers =
(List<Map<String, Object>>) msg.getHeaders().get(AmqpInboundChannelAdapter.CONSOLIDATED_HEADERS);
for (int i = 0; i < things.size(); i++) {
System.out.println(things.get(i) + " myHeader=" + headers.get(i).get("myHeader"));
// ...
}
};
}
@Bean
public ApplicationRunner runner(RabbitTemplate template) {
return args -> {
template.convertAndSend("input-in-0.someGroup", "{\"field\":\"value1\"}", msg -> {
msg.getMessageProperties().setHeader("myHeader", "headerValue1");
return msg;
});
template.convertAndSend("input-in-0.someGroup", "{\"field\":\"value2\"}", msg -> {
msg.getMessageProperties().setHeader("myHeader", "headerValue2");
return msg;
});
};
}
public static class Thing {
private String field;
public Thing() {
}
public Thing(String field) {
this.field = field;
}
public String getfield() {
return this.field;
}
public void setfield(String field) {
this.field = field;
}
@Override
public String toString() {
return "Thing [field=" + this.field + "]";
}
}
}Received 2
Thing [field=value1] myHeader=headerValue1
Thing [field=value2] myHeader=headerValue23.6. Rabbit Producer Properties
The following properties are available for Rabbit producers only and must be prefixed with spring.cloud.stream.rabbit.bindings.<channelName>.producer..
However if the same set of properties needs to be applied to most bindings, to
avoid repetition, Spring Cloud Stream supports setting values for all channels,
in the format of spring.cloud.stream.rabbit.default.<property>=<value>.
Also, keep in mind that binding specific property will override its equivalent in the default.
- autoBindDlq
-
Whether to automatically declare the DLQ and bind it to the binder DLX.
Default:
false. - batchingEnabled
-
Whether to enable message batching by producers. Messages are batched into one message according to the following properties (described in the next three entries in this list): 'batchSize',
batchBufferLimit, andbatchTimeout. See Batching for more information. Also see Receiving Batched Messages.Default:
false. - batchSize
-
The number of messages to buffer when batching is enabled.
Default:
100. - batchBufferLimit
-
The maximum buffer size when batching is enabled.
Default:
10000. - batchTimeout
-
The batch timeout when batching is enabled.
Default:
5000. - bindingRoutingKey
-
The routing key with which to bind the queue to the exchange (if
bindQueueistrue). Can be multiple keys - seebindingRoutingKeyDelimiter. For partitioned destinations,-nis appended to each key. Only applies ifrequiredGroupsare provided and then only to those groups.Default:
#. - bindingRoutingKeyDelimiter
-
When this is not null, 'bindingRoutingKey' is considered to be a list of keys delimited by this value; often a comma is used. Only applies if
requiredGroupsare provided and then only to those groups.Default:
null. - bindQueue
-
Whether to declare the queue and bind it to the destination exchange. Set it to
falseif you have set up your own infrastructure and have previously created and bound the queue. Only applies ifrequiredGroupsare provided and then only to those groups.Default:
true. - compress
-
Whether data should be compressed when sent.
Default:
false. - confirmAckChannel
-
When
errorChannelEnabledis true, a channel to which to send positive delivery acknowledgments (aka publisher confirms). If the channel does not exist, aDirectChannelis registered with this name. The connection factory must be configured to enable publisher confirms. Mutually exclusive withuseConfirmHeader.Default:
nullChannel(acks are discarded). - deadLetterQueueName
-
The name of the DLQ Only applies if
requiredGroupsare provided and then only to those groups.Default:
prefix+destination.dlq - deadLetterExchange
-
A DLX to assign to the queue. Relevant only when
autoBindDlqistrue. Applies only whenrequiredGroupsare provided and then only to those groups.Default: 'prefix+DLX'
- deadLetterExchangeType
-
The type of the DLX to assign to the queue. Relevant only if
autoBindDlqistrue. Applies only whenrequiredGroupsare provided and then only to those groups.Default: 'direct'
- deadLetterRoutingKey
-
A dead letter routing key to assign to the queue. Relevant only when
autoBindDlqistrue. Applies only whenrequiredGroupsare provided and then only to those groups.Default:
destination - declareDlx
-
Whether to declare the dead letter exchange for the destination. Relevant only if
autoBindDlqistrue. Set tofalseif you have a pre-configured DLX. Applies only whenrequiredGroupsare provided and then only to those groups.Default:
true. - declareExchange
-
Whether to declare the exchange for the destination.
Default:
true. - delayExpression
-
A SpEL expression to evaluate the delay to apply to the message (
x-delayheader). It has no effect if the exchange is not a delayed message exchange.Default: No
x-delayheader is set. - delayedExchange
-
Whether to declare the exchange as a
Delayed Message Exchange. Requires the delayed message exchange plugin on the broker. Thex-delayed-typeargument is set to theexchangeType.Default:
false. - deliveryMode
-
The delivery mode.
Default:
PERSISTENT. - dlqBindingArguments
-
Arguments applied when binding the dlq to the dead letter exchange; used with
headersdeadLetterExchangeTypeto specify headers to match on. For example…dlqBindingArguments.x-match=any,…dlqBindingArguments.someHeader=someValue. Applies only whenrequiredGroupsare provided and then only to those groups.Default: empty
- dlqDeadLetterExchange
-
When a DLQ is declared, a DLX to assign to that queue. Applies only if
requiredGroupsare provided and then only to those groups.Default:
none - dlqDeadLetterRoutingKey
-
When a DLQ is declared, a dead letter routing key to assign to that queue. Applies only when
requiredGroupsare provided and then only to those groups.Default:
none - dlqExpires
-
How long (in milliseconds) before an unused dead letter queue is deleted. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no expiration - dlqLazy
-
Declare the dead letter queue with the
x-queue-mode=lazyargument. See “Lazy Queues”. Consider using a policy instead of this setting, because using a policy allows changing the setting without deleting the queue. Applies only whenrequiredGroupsare provided and then only to those groups. - dlqMaxLength
-
Maximum number of messages in the dead letter queue. Applies only if
requiredGroupsare provided and then only to those groups.Default:
no limit - dlqMaxLengthBytes
-
Maximum number of total bytes in the dead letter queue from all messages. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no limit - dlqMaxPriority
-
Maximum priority of messages in the dead letter queue (0-255) Applies only when
requiredGroupsare provided and then only to those groups.Default:
none - dlqQuorum.deliveryLimit
-
When
quorum.enabled=true, set a delivery limit after which the message is dropped or dead-lettered. Applies only whenrequiredGroupsare provided and then only to those groups.Default: none - broker default will apply.
- dlqQuorum.enabled
-
When true, create a quorum dead letter queue instead of a classic queue. Applies only when
requiredGroupsare provided and then only to those groups.Default: false
- dlqQuorum.initialQuorumSize
-
When
quorum.enabled=true, set the initial quorum size. Applies only whenrequiredGroupsare provided and then only to those groups.Default: none - broker default will apply.
- dlqSingleActiveConsumer
-
Set to true to set the
x-single-active-consumerqueue property to true. Applies only whenrequiredGroupsare provided and then only to those groups.Default:
false - dlqTtl
-
Default time (in milliseconds) to live to apply to the dead letter queue when declared. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no limit - exchangeAutoDelete
-
If
declareExchangeistrue, whether the exchange should be auto-delete (it is removed after the last queue is removed).Default:
true. - exchangeDurable
-
If
declareExchangeistrue, whether the exchange should be durable (survives broker restart).Default:
true. - exchangeType
-
The exchange type:
direct,fanout,headersortopicfor non-partitioned destinations anddirect,headersortopicfor partitioned destinations.Default:
topic. - expires
-
How long (in milliseconds) before an unused queue is deleted. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no expiration - headerPatterns
-
Patterns for headers to be mapped to outbound messages.
Default:
['*'](all headers). - lazy
-
Declare the queue with the
x-queue-mode=lazyargument. See “Lazy Queues”. Consider using a policy instead of this setting, because using a policy allows changing the setting without deleting the queue. Applies only whenrequiredGroupsare provided and then only to those groups.Default:
false. - maxLength
-
Maximum number of messages in the queue. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no limit - maxLengthBytes
-
Maximum number of total bytes in the queue from all messages. Only applies if
requiredGroupsare provided and then only to those groups.Default:
no limit - maxPriority
-
Maximum priority of messages in the queue (0-255). Only applies if
requiredGroupsare provided and then only to those groups.Default:
none - prefix
-
A prefix to be added to the name of the
destinationexchange.Default: "".
- queueBindingArguments
-
Arguments applied when binding the queue to the exchange; used with
headersexchangeTypeto specify headers to match on. For example…queueBindingArguments.x-match=any,…queueBindingArguments.someHeader=someValue. Applies only whenrequiredGroupsare provided and then only to those groups.Default: empty
- queueNameGroupOnly
-
When
true, consume from a queue with a name equal to thegroup. Otherwise the queue name isdestination.group. This is useful, for example, when using Spring Cloud Stream to consume from an existing RabbitMQ queue. Applies only whenrequiredGroupsare provided and then only to those groups.Default: false.
- quorum.deliveryLimit
-
When
quorum.enabled=true, set a delivery limit after which the message is dropped or dead-lettered. Applies only whenrequiredGroupsare provided and then only to those groups.Default: none - broker default will apply.
- quorum.enabled
-
When true, create a quorum queue instead of a classic queue. Applies only when
requiredGroupsare provided and then only to those groups.Default: false
- quorum.initialQuorumSize
-
When
quorum.enabled=true, set the initial quorum size. Applies only whenrequiredGroupsare provided and then only to those groups.Default: none - broker default will apply.
- routingKeyExpression
-
A SpEL expression to determine the routing key to use when publishing messages. For a fixed routing key, use a literal expression, such as
routingKeyExpression='my.routingKey'in a properties file orroutingKeyExpression: '''my.routingKey'''in a YAML file.Default:
destinationordestination-<partition>for partitioned destinations. - singleActiveConsumer
-
Set to true to set the
x-single-active-consumerqueue property to true. Applies only whenrequiredGroupsare provided and then only to those groups.Default:
false - transacted
-
Whether to use transacted channels.
Default:
false. - ttl
-
Default time (in milliseconds) to live to apply to the queue when declared. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no limit - useConfirmHeader
-
See Publisher Confirms. Mutually exclusive with
confirmAckChannel.In the case of RabbitMQ, content type headers can be set by external applications. Spring Cloud Stream supports them as part of an extended internal protocol used for any type of transport — including transports, such as Kafka (prior to 0.11), that do not natively support headers.
3.7. Publisher Confirms
There are two mechanisms to get the result of publishing a message; in each case, the connection factory must have publisherConfirmType set ConfirmType.CORRELATED.
The "legacy" mechanism is to set the confirmAckChannel to the bean name of a message channel from which you can retrieve the confirmations asynchronously; negative acks are sent to the error channel (if enabled) - see Error Channels.
The preferred mechanism, added in version 3.1 is to use a correlation data header and wait for the result via its Future<Confirm> property.
This is particularly useful with a batch listener because you can send multiple messages before waiting for the result.
To use this technique, set the useConfirmHeader property to true
The following simple application is an example of using this technique:
spring.cloud.stream.bindings.input-in-0.group=someGroup
spring.cloud.stream.bindings.input-in-0.consumer.batch-mode=true
spring.cloud.stream.source=output
spring.cloud.stream.bindings.output-out-0.producer.error-channel-enabled=true
spring.cloud.stream.rabbit.bindings.output-out-0.producer.useConfirmHeader=true
spring.cloud.stream.rabbit.bindings.input-in-0.consumer.auto-bind-dlq=true
spring.cloud.stream.rabbit.bindings.input-in-0.consumer.batch-size=10
spring.rabbitmq.publisher-confirm-type=correlated
spring.rabbitmq.publisher-returns=true@SpringBootApplication
public class Application {
private static final Logger log = LoggerFactory.getLogger(Application.class);
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Autowired
private StreamBridge bridge;
@Bean
Consumer<List<String>> input() {
return list -> {
List<MyCorrelationData> results = new ArrayList<>();
list.forEach(str -> {
log.info("Received: " + str);
MyCorrelationData corr = new MyCorrelationData(UUID.randomUUID().toString(), str);
results.add(corr);
this.bridge.send("output-out-0", MessageBuilder.withPayload(str.toUpperCase())
.setHeader(AmqpHeaders.PUBLISH_CONFIRM_CORRELATION, corr)
.build());
});
results.forEach(correlation -> {
try {
Confirm confirm = correlation.getFuture().get(10, TimeUnit.SECONDS);
log.info(confirm + " for " + correlation.getPayload());
if (correlation.getReturnedMessage() != null) {
log.error("Message for " + correlation.getPayload() + " was returned ");
// throw some exception to invoke binder retry/error handling
}
}
catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new IllegalStateException(e);
}
catch (ExecutionException | TimeoutException e) {
throw new IllegalStateException(e);
}
};
}
@Bean
public ApplicationRunner runner(BatchingRabbitTemplate template) {
return args -> IntStream.range(0, 10).forEach(i ->
template.convertAndSend("input-in-0", "input-in-0.rbgh303", "foo" + i));
}
@Bean
public BatchingRabbitTemplate template(CachingConnectionFactory cf, TaskScheduler taskScheduler) {
BatchingStrategy batchingStrategy = new SimpleBatchingStrategy(10, 1000000, 1000);
return new BatchingRabbitTemplate(cf, batchingStrategy, taskScheduler);
}
}
class MyCorrelationData extends CorrelationData {
private final String payload;
MyCorrelationData(String id, String payload) {
super(id);
this.payload = payload;
}
public String getPayload() {
return this.payload;
}
}As you can see, we send each message and then await for the publication results. If the messages can’t be routed, then correlation data is populated with the returned message before the future is completed.
The correlation data must be provided with a unique id so that the framework can perform the correlation.
|
You cannot set both useConfirmHeader and confirmAckChannel but you can still receive returned messages in the error channel when useConfirmHeader is true, but using the correlation header is more convenient.
4. Using Existing Queues/Exchanges
By default, the binder will automatically provision a topic exchange with the name being derived from the value of the destination binding property <prefix><destination>.
The destination defaults to the binding name, if not provided.
When binding a consumer, a queue will automatically be provisioned with the name <prefix><destination>.<group> (if a group binding property is specified), or an anonymous, auto-delete queue when there is no group.
The queue will be bound to the exchange with the "match-all" wildcard routing key (#) for a non-partitioned binding or <destination>-<instanceIndex> for a partitioned binding.
The prefix is an empty String by default.
If an output binding is specified with requiredGroups, a queue/binding will be provisioned for each group.
There are a number of rabbit-specific binding properties that allow you to modify this default behavior.
If you have an existing exchange/queue that you wish to use, you can completely disable automatic provisioning as follows, assuming the exchange is named myExchange and the queue is named myQueue:
-
spring.cloud.stream.bindings.<binding name>.destination=myExchange -
spring.cloud.stream.bindings.<binding name>.group=myQueue -
spring.cloud.stream.rabbit.bindings.<binding name>.consumer.bindQueue=false -
spring.cloud.stream.rabbit.bindings.<binding name>.consumer.declareExchange=false -
spring.cloud.stream.rabbit.bindings.<binding name>.consumer.queueNameGroupOnly=true
If you want the binder to provision the queue/exchange, but you want to do it using something other than the defaults discussed here, use the following properties. Refer to the property documentation above for more information.
-
spring.cloud.stream.rabbit.bindings.<binding name>.consumer.bindingRoutingKey=myRoutingKey -
spring.cloud.stream.rabbit.bindings.<binding name>.consumer.exchangeType=<type> -
spring.cloud.stream.rabbit.bindings.<binding name>.producer.routingKeyExpression='myRoutingKey'
There are similar properties used when declaring a dead-letter exchange/queue, when autoBindDlq is true.
5. Retry With the RabbitMQ Binder
When retry is enabled within the binder, the listener container thread is suspended for any back off periods that are configured. This might be important when strict ordering is required with a single consumer. However, for other use cases, it prevents other messages from being processed on that thread. An alternative to using binder retry is to set up dead lettering with time to live on the dead-letter queue (DLQ) as well as dead-letter configuration on the DLQ itself. See “RabbitMQ Binder Properties” for more information about the properties discussed here. You can use the following example configuration to enable this feature:
-
Set
autoBindDlqtotrue. The binder create a DLQ. Optionally, you can specify a name indeadLetterQueueName. -
Set
dlqTtlto the back off time you want to wait between redeliveries. -
Set the
dlqDeadLetterExchangeto the default exchange. Expired messages from the DLQ are routed to the original queue, because the defaultdeadLetterRoutingKeyis the queue name (destination.group). Setting to the default exchange is achieved by setting the property with no value, as shown in the next example.
To force a message to be dead-lettered, either throw an AmqpRejectAndDontRequeueException or set requeueRejected to false (the default) and throw any exception.
The loop continue without end, which is fine for transient problems, but you may want to give up after some number of attempts.
Fortunately, RabbitMQ provides the x-death header, which lets you determine how many cycles have occurred.
To acknowledge a message after giving up, throw an ImmediateAcknowledgeAmqpException.
5.1. Putting it All Together
The following configuration creates an exchange myDestination with queue myDestination.consumerGroup bound to a topic exchange with a wildcard routing key #:
---
spring.cloud.stream.bindings.input.destination=myDestination
spring.cloud.stream.bindings.input.group=consumerGroup
#disable binder retries
spring.cloud.stream.bindings.input.consumer.max-attempts=1
#dlx/dlq setup
spring.cloud.stream.rabbit.bindings.input.consumer.auto-bind-dlq=true
spring.cloud.stream.rabbit.bindings.input.consumer.dlq-ttl=5000
spring.cloud.stream.rabbit.bindings.input.consumer.dlq-dead-letter-exchange=
---This configuration creates a DLQ bound to a direct exchange (DLX) with a routing key of myDestination.consumerGroup.
When messages are rejected, they are routed to the DLQ.
After 5 seconds, the message expires and is routed to the original queue by using the queue name as the routing key, as shown in the following example:
@SpringBootApplication
@EnableBinding(Sink.class)
public class XDeathApplication {
public static void main(String[] args) {
SpringApplication.run(XDeathApplication.class, args);
}
@StreamListener(Sink.INPUT)
public void listen(String in, @Header(name = "x-death", required = false) Map<?,?> death) {
if (death != null && death.get("count").equals(3L)) {
// giving up - don't send to DLX
throw new ImmediateAcknowledgeAmqpException("Failed after 4 attempts");
}
throw new AmqpRejectAndDontRequeueException("failed");
}
}Notice that the count property in the x-death header is a Long.
6. Error Channels
Starting with version 1.3, the binder unconditionally sends exceptions to an error channel for each consumer destination and can also be configured to send async producer send failures to an error channel. See “[spring-cloud-stream-overview-error-handling]” for more information.
RabbitMQ has two types of send failures:
-
Returned messages,
-
Negatively acknowledged Publisher Confirms.
The latter is rare.
According to the RabbitMQ documentation "[A nack] will only be delivered if an internal error occurs in the Erlang process responsible for a queue.".
You can also get a negative acknowledgment if you publish to a bounded queue with reject-publish queue overflow behavior.
As well as enabling producer error channels (as described in “[spring-cloud-stream-overview-error-handling]”), the RabbitMQ binder only sends messages to the channels if the connection factory is appropriately configured, as follows:
-
ccf.setPublisherConfirms(true); -
ccf.setPublisherReturns(true);
When using Spring Boot configuration for the connection factory, set the following properties:
-
spring.rabbitmq.publisher-confirms -
spring.rabbitmq.publisher-returns
The payload of the ErrorMessage for a returned message is a ReturnedAmqpMessageException with the following properties:
-
failedMessage: The spring-messagingMessage<?>that failed to be sent. -
amqpMessage: The raw spring-amqpMessage. -
replyCode: An integer value indicating the reason for the failure (for example, 312 - No route). -
replyText: A text value indicating the reason for the failure (for example,NO_ROUTE). -
exchange: The exchange to which the message was published. -
routingKey: The routing key used when the message was published.
Also see Publisher Confirms for an alternative mechanism to receive returned messages.
For negatively acknowledged confirmations, the payload is a NackedAmqpMessageException with the following properties:
-
failedMessage: The spring-messagingMessage<?>that failed to be sent. -
nackReason: A reason (if available — you may need to examine the broker logs for more information).
There is no automatic handling of these exceptions (such as sending to a dead-letter queue). You can consume these exceptions with your own Spring Integration flow.
7. Dead-Letter Queue Processing
Because you cannot anticipate how users would want to dispose of dead-lettered messages, the framework does not provide any standard mechanism to handle them.
If the reason for the dead-lettering is transient, you may wish to route the messages back to the original queue.
However, if the problem is a permanent issue, that could cause an infinite loop.
The following Spring Boot application shows an example of how to route those messages back to the original queue but moves them to a third “parking lot” queue after three attempts.
The second example uses the RabbitMQ Delayed Message Exchange to introduce a delay to the re-queued message.
In this example, the delay increases for each attempt.
These examples use a @RabbitListener to receive messages from the DLQ.
You could also use RabbitTemplate.receive() in a batch process.
The examples assume the original destination is so8400in and the consumer group is so8400.
7.1. Non-Partitioned Destinations
The first two examples are for when the destination is not partitioned:
@SpringBootApplication
public class ReRouteDlqApplication {
private static final String ORIGINAL_QUEUE = "so8400in.so8400";
private static final String DLQ = ORIGINAL_QUEUE + ".dlq";
private static final String PARKING_LOT = ORIGINAL_QUEUE + ".parkingLot";
private static final String X_RETRIES_HEADER = "x-retries";
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext context = SpringApplication.run(ReRouteDlqApplication.class, args);
System.out.println("Press enter to exit");
System.in.read();
context.close();
}
@Autowired
private RabbitTemplate rabbitTemplate;
@RabbitListener(queues = DLQ)
public void rePublish(Message failedMessage) {
Integer retriesHeader = (Integer) failedMessage.getMessageProperties().getHeaders().get(X_RETRIES_HEADER);
if (retriesHeader == null) {
retriesHeader = Integer.valueOf(0);
}
if (retriesHeader < 3) {
failedMessage.getMessageProperties().getHeaders().put(X_RETRIES_HEADER, retriesHeader + 1);
this.rabbitTemplate.send(ORIGINAL_QUEUE, failedMessage);
}
else {
this.rabbitTemplate.send(PARKING_LOT, failedMessage);
}
}
@Bean
public Queue parkingLot() {
return new Queue(PARKING_LOT);
}
}@SpringBootApplication
public class ReRouteDlqApplication {
private static final String ORIGINAL_QUEUE = "so8400in.so8400";
private static final String DLQ = ORIGINAL_QUEUE + ".dlq";
private static final String PARKING_LOT = ORIGINAL_QUEUE + ".parkingLot";
private static final String X_RETRIES_HEADER = "x-retries";
private static final String DELAY_EXCHANGE = "dlqReRouter";
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext context = SpringApplication.run(ReRouteDlqApplication.class, args);
System.out.println("Press enter to exit");
System.in.read();
context.close();
}
@Autowired
private RabbitTemplate rabbitTemplate;
@RabbitListener(queues = DLQ)
public void rePublish(Message failedMessage) {
Map<String, Object> headers = failedMessage.getMessageProperties().getHeaders();
Integer retriesHeader = (Integer) headers.get(X_RETRIES_HEADER);
if (retriesHeader == null) {
retriesHeader = Integer.valueOf(0);
}
if (retriesHeader < 3) {
headers.put(X_RETRIES_HEADER, retriesHeader + 1);
headers.put("x-delay", 5000 * retriesHeader);
this.rabbitTemplate.send(DELAY_EXCHANGE, ORIGINAL_QUEUE, failedMessage);
}
else {
this.rabbitTemplate.send(PARKING_LOT, failedMessage);
}
}
@Bean
public DirectExchange delayExchange() {
DirectExchange exchange = new DirectExchange(DELAY_EXCHANGE);
exchange.setDelayed(true);
return exchange;
}
@Bean
public Binding bindOriginalToDelay() {
return BindingBuilder.bind(new Queue(ORIGINAL_QUEUE)).to(delayExchange()).with(ORIGINAL_QUEUE);
}
@Bean
public Queue parkingLot() {
return new Queue(PARKING_LOT);
}
}7.2. Partitioned Destinations
With partitioned destinations, there is one DLQ for all partitions. We determine the original queue from the headers.
7.2.1. republishToDlq=false
When republishToDlq is false, RabbitMQ publishes the message to the DLX/DLQ with an x-death header containing information about the original destination, as shown in the following example:
@SpringBootApplication
public class ReRouteDlqApplication {
private static final String ORIGINAL_QUEUE = "so8400in.so8400";
private static final String DLQ = ORIGINAL_QUEUE + ".dlq";
private static final String PARKING_LOT = ORIGINAL_QUEUE + ".parkingLot";
private static final String X_DEATH_HEADER = "x-death";
private static final String X_RETRIES_HEADER = "x-retries";
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext context = SpringApplication.run(ReRouteDlqApplication.class, args);
System.out.println("Press enter to exit");
System.in.read();
context.close();
}
@Autowired
private RabbitTemplate rabbitTemplate;
@SuppressWarnings("unchecked")
@RabbitListener(queues = DLQ)
public void rePublish(Message failedMessage) {
Map<String, Object> headers = failedMessage.getMessageProperties().getHeaders();
Integer retriesHeader = (Integer) headers.get(X_RETRIES_HEADER);
if (retriesHeader == null) {
retriesHeader = Integer.valueOf(0);
}
if (retriesHeader < 3) {
headers.put(X_RETRIES_HEADER, retriesHeader + 1);
List<Map<String, ?>> xDeath = (List<Map<String, ?>>) headers.get(X_DEATH_HEADER);
String exchange = (String) xDeath.get(0).get("exchange");
List<String> routingKeys = (List<String>) xDeath.get(0).get("routing-keys");
this.rabbitTemplate.send(exchange, routingKeys.get(0), failedMessage);
}
else {
this.rabbitTemplate.send(PARKING_LOT, failedMessage);
}
}
@Bean
public Queue parkingLot() {
return new Queue(PARKING_LOT);
}
}7.2.2. republishToDlq=true
When republishToDlq is true, the republishing recoverer adds the original exchange and routing key to headers, as shown in the following example:
@SpringBootApplication
public class ReRouteDlqApplication {
private static final String ORIGINAL_QUEUE = "so8400in.so8400";
private static final String DLQ = ORIGINAL_QUEUE + ".dlq";
private static final String PARKING_LOT = ORIGINAL_QUEUE + ".parkingLot";
private static final String X_RETRIES_HEADER = "x-retries";
private static final String X_ORIGINAL_EXCHANGE_HEADER = RepublishMessageRecoverer.X_ORIGINAL_EXCHANGE;
private static final String X_ORIGINAL_ROUTING_KEY_HEADER = RepublishMessageRecoverer.X_ORIGINAL_ROUTING_KEY;
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext context = SpringApplication.run(ReRouteDlqApplication.class, args);
System.out.println("Press enter to exit");
System.in.read();
context.close();
}
@Autowired
private RabbitTemplate rabbitTemplate;
@RabbitListener(queues = DLQ)
public void rePublish(Message failedMessage) {
Map<String, Object> headers = failedMessage.getMessageProperties().getHeaders();
Integer retriesHeader = (Integer) headers.get(X_RETRIES_HEADER);
if (retriesHeader == null) {
retriesHeader = Integer.valueOf(0);
}
if (retriesHeader < 3) {
headers.put(X_RETRIES_HEADER, retriesHeader + 1);
String exchange = (String) headers.get(X_ORIGINAL_EXCHANGE_HEADER);
String originalRoutingKey = (String) headers.get(X_ORIGINAL_ROUTING_KEY_HEADER);
this.rabbitTemplate.send(exchange, originalRoutingKey, failedMessage);
}
else {
this.rabbitTemplate.send(PARKING_LOT, failedMessage);
}
}
@Bean
public Queue parkingLot() {
return new Queue(PARKING_LOT);
}
}8. Partitioning with the RabbitMQ Binder
RabbitMQ does not support partitioning natively.
Sometimes, it is advantageous to send data to specific partitions — for example, when you want to strictly order message processing, all messages for a particular customer should go to the same partition.
The RabbitMessageChannelBinder provides partitioning by binding a queue for each partition to the destination exchange.
The following Java and YAML examples show how to configure the producer:
@SpringBootApplication
@EnableBinding(Source.class)
public class RabbitPartitionProducerApplication {
private static final Random RANDOM = new Random(System.currentTimeMillis());
private static final String[] data = new String[] {
"abc1", "def1", "qux1",
"abc2", "def2", "qux2",
"abc3", "def3", "qux3",
"abc4", "def4", "qux4",
};
public static void main(String[] args) {
new SpringApplicationBuilder(RabbitPartitionProducerApplication.class)
.web(false)
.run(args);
}
@InboundChannelAdapter(channel = Source.OUTPUT, poller = @Poller(fixedRate = "5000"))
public Message<?> generate() {
String value = data[RANDOM.nextInt(data.length)];
System.out.println("Sending: " + value);
return MessageBuilder.withPayload(value)
.setHeader("partitionKey", value)
.build();
}
} spring:
cloud:
stream:
bindings:
output:
destination: partitioned.destination
producer:
partitioned: true
partition-key-expression: headers['partitionKey']
partition-count: 2
required-groups:
- myGroup|
The configuration in the prececing example uses the default partitioning ( The |
The following configuration provisions a topic exchange:

The following queues are bound to that exchange:

The following bindings associate the queues to the exchange:
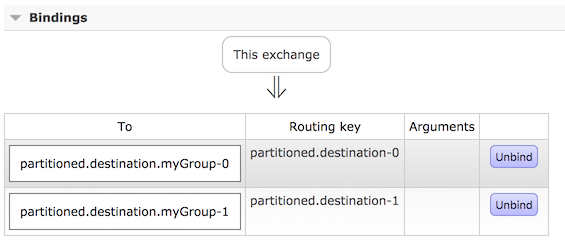
The following Java and YAML examples continue the previous examples and show how to configure the consumer:
@SpringBootApplication
@EnableBinding(Sink.class)
public class RabbitPartitionConsumerApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(RabbitPartitionConsumerApplication.class)
.web(false)
.run(args);
}
@StreamListener(Sink.INPUT)
public void listen(@Payload String in, @Header(AmqpHeaders.CONSUMER_QUEUE) String queue) {
System.out.println(in + " received from queue " + queue);
}
} spring:
cloud:
stream:
bindings:
input:
destination: partitioned.destination
group: myGroup
consumer:
partitioned: true
instance-index: 0
The RabbitMessageChannelBinder does not support dynamic scaling.
There must be at least one consumer per partition.
The consumer’s instanceIndex is used to indicate which partition is consumed.
Platforms such as Cloud Foundry can have only one instance with an instanceIndex.
|
Appendices
Appendix A: Building
A.1. Basic Compile and Test
To build the source you will need to install JDK 1.8.
The build uses the Maven wrapper so you don’t have to install a specific version of Maven. To enable the tests, you should have RabbitMQ server running on localhost and the default port (5672) before building.
The main build command is
$ ./mvnw clean install
You can also add '-DskipTests' if you like, to avoid running the tests.
You can also install Maven (>=3.3.3) yourself and run the mvn command
in place of ./mvnw in the examples below. If you do that you also
might need to add -P spring if your local Maven settings do not
contain repository declarations for spring pre-release artifacts.
|
Be aware that you might need to increase the amount of memory
available to Maven by setting a MAVEN_OPTS environment variable with
a value like -Xmx512m -XX:MaxPermSize=128m. We try to cover this in
the .mvn configuration, so if you find you have to do it to make a
build succeed, please raise a ticket to get the settings added to
source control.
|
The projects that require middleware generally include a
docker-compose.yml, so consider using
Docker Compose to run the middeware servers
in Docker containers.
A.2. Documentation
There is a "docs" profile that will generate documentation.
./mvnw clean package -Pdocs -DskipTests
The reference documentation can then be found in docs/target/contents/reference.
A.3. Working with the code
If you don’t have an IDE preference we would recommend that you use Spring Tools Suite or Eclipse when working with the code. We use the m2eclipe eclipse plugin for maven support. Other IDEs and tools should also work without issue.
A.3.1. Importing into eclipse with m2eclipse
We recommend the m2eclipe eclipse plugin when working with eclipse. If you don’t already have m2eclipse installed it is available from the "eclipse marketplace".
Unfortunately m2e does not yet support Maven 3.3, so once the projects
are imported into Eclipse you will also need to tell m2eclipse to use
the .settings.xml file for the projects. If you do not do this you
may see many different errors related to the POMs in the
projects. Open your Eclipse preferences, expand the Maven
preferences, and select User Settings. In the User Settings field
click Browse and navigate to the Spring Cloud project you imported
selecting the .settings.xml file in that project. Click Apply and
then OK to save the preference changes.
Alternatively you can copy the repository settings from .settings.xml into your own ~/.m2/settings.xml.
|
A.3.2. Importing into eclipse without m2eclipse
If you prefer not to use m2eclipse you can generate eclipse project metadata using the following command:
$ ./mvnw eclipse:eclipse
The generated eclipse projects can be imported by selecting import existing projects
from the file menu.
Appendix B: Contributing
Spring Cloud is released under the non-restrictive Apache 2.0 license, and follows a very standard Github development process, using Github tracker for issues and merging pull requests into master. If you want to contribute even something trivial please do not hesitate, but follow the guidelines below.
B.1. Sign the Contributor License Agreement
Before we accept a non-trivial patch or pull request we will need you to sign the contributor’s agreement. Signing the contributor’s agreement does not grant anyone commit rights to the main repository, but it does mean that we can accept your contributions, and you will get an author credit if we do. Active contributors might be asked to join the core team, and given the ability to merge pull requests.
B.2. Code Conventions and Housekeeping
None of these is essential for a pull request, but they will all help. They can also be added after the original pull request but before a merge.
-
Use the Spring Framework code format conventions. If you use Eclipse you can import formatter settings using the
eclipse-code-formatter.xmlfile from the Spring Cloud Build project. If using IntelliJ, you can use the Eclipse Code Formatter Plugin to import the same file. -
Make sure all new
.javafiles to have a simple Javadoc class comment with at least an@authortag identifying you, and preferably at least a paragraph on what the class is for. -
Add the ASF license header comment to all new
.javafiles (copy from existing files in the project) -
Add yourself as an
@authorto the .java files that you modify substantially (more than cosmetic changes). -
Add some Javadocs and, if you change the namespace, some XSD doc elements.
-
A few unit tests would help a lot as well — someone has to do it.
-
If no-one else is using your branch, please rebase it against the current master (or other target branch in the main project).
-
When writing a commit message please follow these conventions, if you are fixing an existing issue please add
Fixes gh-XXXXat the end of the commit message (where XXXX is the issue number).