3.1.3-SNAPSHOT
Preface
A Brief History of Spring’s Data Integration Journey
Spring’s journey on Data Integration started with Spring Integration. With its programming model, it provided a consistent developer experience to build applications that can embrace Enterprise Integration Patterns to connect with external systems such as, databases, message brokers, and among others.
Fast forward to the cloud-era, where microservices have become prominent in the enterprise setting. Spring Boot transformed the way how developers built Applications. With Spring’s programming model and the runtime responsibilities handled by Spring Boot, it became seamless to develop stand-alone, production-grade Spring-based microservices.
To extend this to Data Integration workloads, Spring Integration and Spring Boot were put together into a new project. Spring Cloud Stream was born.
With Spring Cloud Stream, developers can:
-
Build, test and deploy data-centric applications in isolation.
-
Apply modern microservices architecture patterns, including composition through messaging.
-
Decouple application responsibilities with event-centric thinking. An event can represent something that has happened in time, to which the downstream consumer applications can react without knowing where it originated or the producer’s identity.
-
Port the business logic onto message brokers (such as RabbitMQ, Apache Kafka, Amazon Kinesis).
-
Rely on the framework’s automatic content-type support for common use-cases. Extending to different data conversion types is possible.
-
and many more. . .
Quick Start
You can try Spring Cloud Stream in less than 5 min even before you jump into any details by following this three-step guide.
We show you how to create a Spring Cloud Stream application that receives messages coming from the messaging middleware of your choice (more on this later) and logs received messages to the console.
We call it LoggingConsumer.
While not very practical, it provides a good introduction to some of the main concepts
and abstractions, making it easier to digest the rest of this user guide.
The three steps are as follows:
Creating a Sample Application by Using Spring Initializr
To get started, visit the Spring Initializr. From there, you can generate our LoggingConsumer application. To do so:
-
In the Dependencies section, start typing
stream. When the “Cloud Stream” option should appears, select it. -
Start typing either 'kafka' or 'rabbit'.
-
Select “Kafka” or “RabbitMQ”.
Basically, you choose the messaging middleware to which your application binds. We recommend using the one you have already installed or feel more comfortable with installing and running. Also, as you can see from the Initilaizer screen, there are a few other options you can choose. For example, you can choose Gradle as your build tool instead of Maven (the default).
-
In the Artifact field, type 'logging-consumer'.
The value of the Artifact field becomes the application name. If you chose RabbitMQ for the middleware, your Spring Initializr should now be as follows:

-
Click the Generate Project button.
Doing so downloads the zipped version of the generated project to your hard drive.
-
Unzip the file into the folder you want to use as your project directory.
| We encourage you to explore the many possibilities available in the Spring Initializr. It lets you create many different kinds of Spring applications. |
Importing the Project into Your IDE
Now you can import the project into your IDE. Keep in mind that, depending on the IDE, you may need to follow a specific import procedure. For example, depending on how the project was generated (Maven or Gradle), you may need to follow specific import procedure (for example, in Eclipse or STS, you need to use File → Import → Maven → Existing Maven Project).
Once imported, the project must have no errors of any kind. Also, src/main/java should contain com.example.loggingconsumer.LoggingConsumerApplication.
Technically, at this point, you can run the application’s main class. It is already a valid Spring Boot application. However, it does not do anything, so we want to add some code.
Adding a Message Handler, Building, and Running
Modify the com.example.loggingconsumer.LoggingConsumerApplication class to look as follows:
@SpringBootApplication
public class LoggingConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(LoggingConsumerApplication.class, args);
}
@Bean
public Consumer<Person> log() {
return person -> {
System.out.println("Received: " + person);
};
}
public static class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return this.name;
}
}
}As you can see from the preceding listing:
-
We are using functional programming model (see Spring Cloud Function support) to define a single message handler as
Consumer. -
We are relying on framework conventions to bind such handler to the input destination binding exposed by the binder.
Doing so also lets you see one of the core features of the framework: It tries to automatically convert incoming message payloads to type Person.
You now have a fully functional Spring Cloud Stream application that does listens for messages.
From here, for simplicity, we assume you selected RabbitMQ in step one.
Assuming you have RabbitMQ installed and running, you can start the application by running its main method in your IDE.
You should see following output:
--- [ main] c.s.b.r.p.RabbitExchangeQueueProvisioner : declaring queue for inbound: input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg, bound to: input
--- [ main] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: [localhost:5672]
--- [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: rabbitConnectionFactory#2a3a299:0/SimpleConnection@66c83fc8. . .
. . .
--- [ main] o.s.i.a.i.AmqpInboundChannelAdapter : started inbound.input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg
. . .
--- [ main] c.e.l.LoggingConsumerApplication : Started LoggingConsumerApplication in 2.531 seconds (JVM running for 2.897)Go to the RabbitMQ management console or any other RabbitMQ client and send a message to input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg.
The anonymous.CbMIwdkJSBO1ZoPDOtHtCg part represents the group name and is generated, so it is bound to be different in your environment.
For something more predictable, you can use an explicit group name by setting spring.cloud.stream.bindings.input.group=hello (or whatever name you like).
The contents of the message should be a JSON representation of the Person class, as follows:
{"name":"Sam Spade"}
Then, in your console, you should see:
Received: Sam Spade
You can also build and package your application into a boot jar (by using ./mvnw clean install) and run the built JAR by using the java -jar command.
Now you have a working (albeit very basic) Spring Cloud Stream application.
What’s New in 3.x?
New Features and Enhancements
-
Routing Function - see Event Routing for more details.
-
StreamBridge - for dynamic destinations. See Sending arbitrary data to an output (e.g. Foreign event-driven sources) for more details.
-
Multiple bindings with functions (multiple message handlers) - see Multiple functions in a single application for more details.
-
Functions with multiple inputs/outputs (single function that can subscribe or target multiple destinations) - see Functions with multiple input and output arguments for more details.
-
Native support for reactive programming - since v3.0.0 we no longer distribute spring-cloud-stream-reactive modules and instead relying on native reactive support provided by spring cloud function. For backward compatibility you can still bring
spring-cloud-stream-reactivefrom previous versions.
Notable Deprecations
-
Annotation-based programming model. Basically the @EnableBInding, @StreamListener and all related annotations are now deprecated in favor of the functional programming model. See Spring Cloud Function support for more details.
-
Reactive module (
spring-cloud-stream-reactive) is discontinued and no longer distributed in favor of native support via spring-cloud-function. For backward compatibility you can still bringspring-cloud-stream-reactivefrom previous versions. -
Test support binder
spring-cloud-stream-test-supportwith MessageCollector in favor of a new test binder. See Testing for more details. -
@StreamMessageConverter - deprecated as it is no longer required.
-
The
original-content-typeheader references have been removed after it’s been deprecated in v2.0. -
The
BinderAwareChannelResolveris deprecated in favor if providingspring.cloud.stream.sendto.destinationproperty. This is primarily for function-based programming model. For StreamListener it would still be required and thus will stay until we deprecate and eventually discontinue StreamListener and annotation-based programming model.
Introducing Spring Cloud Stream
Spring Cloud Stream is a framework for building message-driven microservice applications. Spring Cloud Stream builds upon Spring Boot to create standalone, production-grade Spring applications and uses Spring Integration to provide connectivity to message brokers. It provides opinionated configuration of middleware from several vendors, introducing the concepts of persistent publish-subscribe semantics, consumer groups, and partitions.
By adding spring-cloud-stream dependencies to the classpath of your application, you get immediate connectivity
to a message broker exposed by the provided spring-cloud-stream binder (more on that later), and you can implement your functional
requirement, which is run (based on the incoming message) by a java.util.function.Function.
The following listing shows a quick example:
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}The following listing shows the corresponding test:
@SpringBootTest(classes = SampleApplication.class)
@Import({TestChannelBinderConfiguration.class})
class BootTestStreamApplicationTests {
@Autowired
private InputDestination input;
@Autowired
private OutputDestination output;
@Test
void contextLoads() {
input.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(output.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
}Main Concepts
Spring Cloud Stream provides a number of abstractions and primitives that simplify the writing of message-driven microservice applications. This section gives an overview of the following:
Application Model
A Spring Cloud Stream application consists of a middleware-neutral core. The application communicates with the outside world by establishing bindings between destinations exposed by the external brokers and input/output arguments in your code. Broker specific details necessary to establish bindings are handled by middleware-specific Binder implementations.
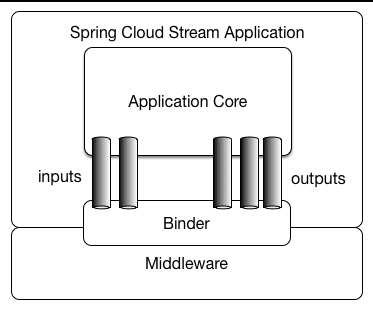
Fat JAR
Spring Cloud Stream applications can be run in stand-alone mode from your IDE for testing. To run a Spring Cloud Stream application in production, you can create an executable (or “fat”) JAR by using the standard Spring Boot tooling provided for Maven or Gradle. See the Spring Boot Reference Guide for more details.
The Binder Abstraction
Spring Cloud Stream provides Binder implementations for Kafka and Rabbit MQ. The framework also includes a test binder for integration testing of your applications as spring-cloud-stream application. See Testing section for more details.
Binder abstraction is also one of the extension points of the framework, which means you can implement your own binder on top of Spring Cloud Stream.
In the How to create a Spring Cloud Stream Binder from scratch post a community member documents
in details, with an example, a set of steps necessary to implement a custom binder.
The steps are also highlighted in the Implementing Custom Binders section.
Spring Cloud Stream uses Spring Boot for configuration, and the Binder abstraction makes it possible for a Spring Cloud Stream application to be flexible in how it connects to middleware.
For example, deployers can dynamically choose, at runtime, the mapping between the external destinations (such as the Kafka topics or RabbitMQ exchanges) and inputs
and outputs of the message handler (such as input parameter of the function and its return argument).
Such configuration can be provided through external configuration properties and in any form supported by Spring Boot (including application arguments, environment variables, and application.yml or application.properties files).
In the sink example from the Introducing Spring Cloud Stream section, setting the spring.cloud.stream.bindings.input.destination application property to raw-sensor-data causes it to read from the raw-sensor-data Kafka topic or from a queue bound to the raw-sensor-data RabbitMQ exchange.
Spring Cloud Stream automatically detects and uses a binder found on the classpath. You can use different types of middleware with the same code. To do so, include a different binder at build time. For more complex use cases, you can also package multiple binders with your application and have it choose the binder( and even whether to use different binders for different bindings) at runtime.
Persistent Publish-Subscribe Support
Communication between applications follows a publish-subscribe model, where data is broadcast through shared topics. This can be seen in the following figure, which shows a typical deployment for a set of interacting Spring Cloud Stream applications.
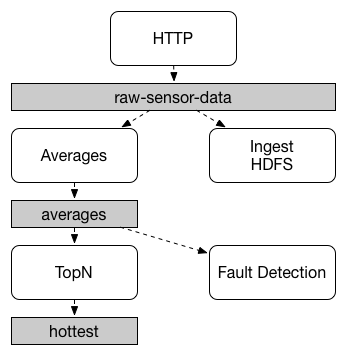
Data reported by sensors to an HTTP endpoint is sent to a common destination named raw-sensor-data.
From the destination, it is independently processed by a microservice application that computes time-windowed averages and by another microservice application that ingests the raw data into HDFS (Hadoop Distributed File System).
In order to process the data, both applications declare the topic as their input at runtime.
The publish-subscribe communication model reduces the complexity of both the producer and the consumer and lets new applications be added to the topology without disruption of the existing flow. For example, downstream from the average-calculating application, you can add an application that calculates the highest temperature values for display and monitoring. You can then add another application that interprets the same flow of averages for fault detection. Doing all communication through shared topics rather than point-to-point queues reduces coupling between microservices.
While the concept of publish-subscribe messaging is not new, Spring Cloud Stream takes the extra step of making it an opinionated choice for its application model. By using native middleware support, Spring Cloud Stream also simplifies use of the publish-subscribe model across different platforms.
Consumer Groups
While the publish-subscribe model makes it easy to connect applications through shared topics, the ability to scale up by creating multiple instances of a given application is equally important. When doing so, different instances of an application are placed in a competing consumer relationship, where only one of the instances is expected to handle a given message.
Spring Cloud Stream models this behavior through the concept of a consumer group.
(Spring Cloud Stream consumer groups are similar to and inspired by Kafka consumer groups.)
Each consumer binding can use the spring.cloud.stream.bindings.<bindingName>.group property to specify a group name.
For the consumers shown in the following figure, this property would be set as spring.cloud.stream.bindings.<bindingName>.group=hdfsWrite or spring.cloud.stream.bindings.<bindingName>.group=average.
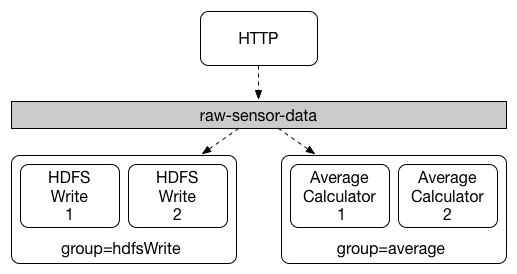
All groups that subscribe to a given destination receive a copy of published data, but only one member of each group receives a given message from that destination. By default, when a group is not specified, Spring Cloud Stream assigns the application to an anonymous and independent single-member consumer group that is in a publish-subscribe relationship with all other consumer groups.
Consumer Types
Two types of consumer are supported:
-
Message-driven (sometimes referred to as Asynchronous)
-
Polled (sometimes referred to as Synchronous)
Prior to version 2.0, only asynchronous consumers were supported. A message is delivered as soon as it is available and a thread is available to process it.
When you wish to control the rate at which messages are processed, you might want to use a synchronous consumer.
Durability
Consistent with the opinionated application model of Spring Cloud Stream, consumer group subscriptions are durable. That is, a binder implementation ensures that group subscriptions are persistent and that, once at least one subscription for a group has been created, the group receives messages, even if they are sent while all applications in the group are stopped.
|
Anonymous subscriptions are non-durable by nature. For some binder implementations (such as RabbitMQ), it is possible to have non-durable group subscriptions. |
In general, it is preferable to always specify a consumer group when binding an application to a given destination. When scaling up a Spring Cloud Stream application, you must specify a consumer group for each of its input bindings. Doing so prevents the application’s instances from receiving duplicate messages (unless that behavior is desired, which is unusual).
Partitioning Support
Spring Cloud Stream provides support for partitioning data between multiple instances of a given application. In a partitioned scenario, the physical communication medium (such as the broker topic) is viewed as being structured into multiple partitions. One or more producer application instances send data to multiple consumer application instances and ensure that data identified by common characteristics are processed by the same consumer instance.
Spring Cloud Stream provides a common abstraction for implementing partitioned processing use cases in a uniform fashion. Partitioning can thus be used whether the broker itself is naturally partitioned (for example, Kafka) or not (for example, RabbitMQ).
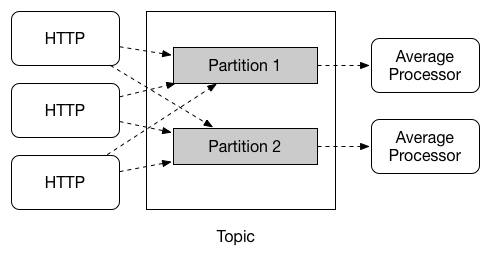
Partitioning is a critical concept in stateful processing, where it is critical (for either performance or consistency reasons) to ensure that all related data is processed together. For example, in the time-windowed average calculation example, it is important that all measurements from any given sensor are processed by the same application instance.
| To set up a partitioned processing scenario, you must configure both the data-producing and the data-consuming ends. |
Programming Model
To understand the programming model, you should be familiar with the following core concepts:
-
Destination Binders: Components responsible to provide integration with the external messaging systems.
-
Bindings: Bridge between the external messaging systems and application provided Producers and Consumers of messages (created by the Destination Binders).
-
Message: The canonical data structure used by producers and consumers to communicate with Destination Binders (and thus other applications via external messaging systems).
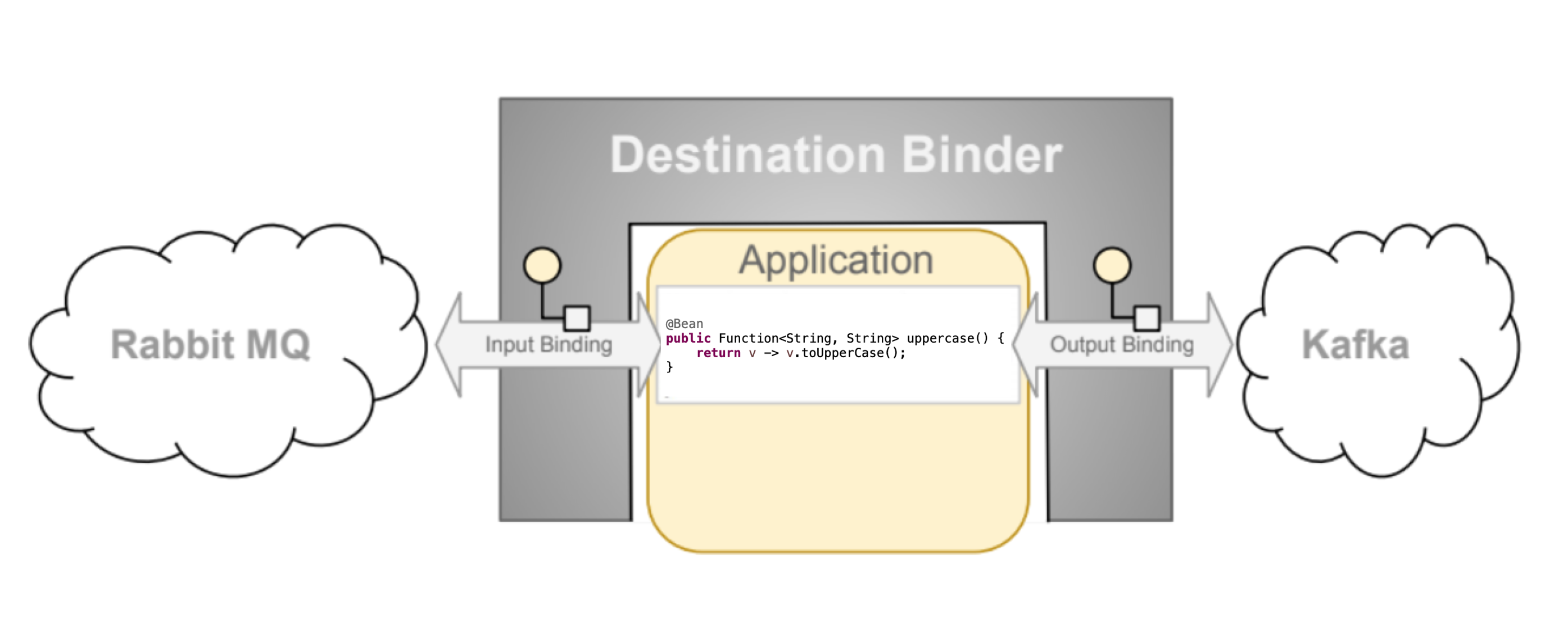
Destination Binders
Destination Binders are extension components of Spring Cloud Stream responsible for providing the necessary configuration and implementation to facilitate integration with external messaging systems. This integration is responsible for connectivity, delegation, and routing of messages to and from producers and consumers, data type conversion, invocation of the user code, and more.
Binders handle a lot of the boiler plate responsibilities that would otherwise fall on your shoulders. However, to accomplish that, the binder still needs some help in the form of minimalistic yet required set of instructions from the user, which typically come in the form of some type of binding configuration.
While it is out of scope of this section to discuss all of the available binder and binding configuration options (the rest of the manual covers them extensively), Binding as a concept, does require special attention. The next section discusses it in detail.
Bindings
As stated earlier, Bindings provide a bridge between the external messaging system (e.g., queue, topic etc.) and application-provided Producers and Consumers.
The following example shows a fully configured and functioning Spring Cloud Stream application that receives the payload of the message
as a String type (see Content Type Negotiation section), logs it to the console and sends it down stream after converting it to upper case.
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> {
System.out.println("Received: " + value);
return value.toUpperCase()
};
}
}The above example looks no different then any vanilla spring-boot application. It defines a single bean of type Function
and that it is. So, how does it became spring-cloud-stream application?
It becomes spring-cloud-stream application simply based on the presence of spring-cloud-stream and binder dependencies
and auto-configuration classes on the classpath effectively setting the context for your boot application as spring-cloud-stream application.
And in this context beans of type Supplier, Function or Consumer are treated as defacto message handlers triggering
binding of to destinations exposed by the provided binder following certain naming conventions and
rules to avoid extra configuration.
Binding and Binding names
Binding is an abstraction that represents a bridge between sources and targets exposed by the binder and user code, This abstraction has a name and while we try to do our best to limit configuration required to run spring-cloud-stream applications, being aware of such name(s) is necessary for cases where additional per-binding configuration is required.
Throughout this manual you will see examples of configuration properties such as spring.cloud.stream.bindings.input.destination=myQueue.
The input segment in this property name is what we refer to as binding name and it could derive via several mechanisms.
The following sub-sections will describe the naming conventions and configuration elements used by spring-cloud-stream to control binding names.
Functional binding names
Unlike the explicit naming required by annotation-based support (legacy) used in the previous versions of spring-cloud-stream, the functional programming model defaults to a simple convention when it comes to binding names, thus greatly simplifying application configuration. Let’s look at the first example:
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}In the preceding example we have an application with a single function which acts as message handler. As a Function it has an
input and output.
The naming convention used to name input and output bindings is as follows:
-
input -
<functionName> + -in- + <index> -
output -
<functionName> + -out- + <index>
The in and out corresponds to the type of binding (such as input or output).
The index is the index of the input or output binding. It is always 0 for typical single input/output function,
so it’s only relevant for Functions with multiple input and output arguments.
So if for example you would want to map the input of this function to a remote destination (e.g., topic, queue etc) called "my-topic" you would do so with the following property:
--spring.cloud.stream.bindings.uppercase-in-0.destination=my-topic
Note how uppercase-in-0 is used as a segment in property name. The same goes for uppercase-out-0.
Descriptive Binding Names
Some times to improve readability you may want to give your binding a more descriptive name (such as 'account', 'orders` etc).
Another way of looking at it is you can map an implicit binding name to an explicit binding name. And you can do it with
spring.cloud.stream.function.bindings.<binding-name> property.
This property also provides a migration path for existing applications that rely on custom interface-based
bindings that require explicit names.
For example,
--spring.cloud.stream.function.bindings.uppercase-in-0=input
In the preceding example you mapped and effectively renamed uppercase-in-0 binding name to input. Now all configuration
properties can refer to input binding name instead (e.g., --spring.cloud.stream.bindings.input.destination=my-topic).
While descriptive binding names may enhance the readability aspect of the configuration, they also create
another level of misdirection by mapping an implicit binding name to an explicit binding name. And since all subsequent
configuration properties will use the explicit binding name you must always refer to this 'bindings' property to
correlate which function it actually corresponds to. We believe that for most cases (with the exception of Functional Composition)
it may be an overkill, so, it is our recommendation to avoid using it altogether, especially
since not using it provides a clear path between binder destination and binding name, such as spring.cloud.stream.bindings.uppercase-in-0.destination=sample-topic,
where you are clearly correlating the input of uppercase function to sample-topic destination.
|
For more on properties and other configuration options please see Configuration Options section.
Producing and Consuming Messages
You can write a Spring Cloud Stream application by simply writing functions and exposing them as `@Bean`s. You can also use Spring Integration annotations based configuration or Spring Cloud Stream annotation based configuration, although starting with spring-cloud-stream 3.x we recommend using functional implementations.
Spring Cloud Function support
Overview
Since Spring Cloud Stream v2.1, another alternative for defining stream handlers and sources is to use build-in
support for Spring Cloud Function where they can be expressed as beans of
type java.util.function.[Supplier/Function/Consumer].
To specify which functional bean to bind to the external destination(s) exposed by the bindings,
you must provide spring.cloud.function.definition property.
In the event you only have single bean of type java.util.function.[Supplier/Function/Consumer], you can
skip the spring.cloud.function.definition property, since such functional bean will be auto-discovered. However,
it is considered best practice to use such property to avoid any confusion.
Some time this auto-discovery can get in the way, since single bean of type java.util.function.[Supplier/Function/Consumer]
could be there for purposes other then handling messages, yet being single it is auto-discovered and auto-bound.
For these rare scenarios you can disable auto-discovery by providing spring.cloud.stream.function.autodetect property with value set to false.
|
Here is the example of the application exposing message handler as java.util.function.Function effectively supporting
pass-thru semantics by acting as consumer and producer of data.
@SpringBootApplication
public class MyFunctionBootApp {
public static void main(String[] args) {
SpringApplication.run(MyFunctionBootApp.class);
}
@Bean
public Function<String, String> toUpperCase() {
return s -> s.toUpperCase();
}
}In the preceding example, we define a bean of type java.util.function.Function called toUpperCase to be acting as message handler
whose 'input' and 'output' must be bound to the external destinations exposed by the provided destination binder.
By default the 'input' and 'output' binding names will be toUpperCase-in-0 and toUpperCase-out-0.
Please see Functional binding names section for details on naming convention used to establish binding names.
Below are the examples of simple functional applications to support other semantics:
Here is the example of a source semantics exposed as java.util.function.Supplier
@SpringBootApplication
public static class SourceFromSupplier {
@Bean
public Supplier<Date> date() {
return () -> new Date(12345L);
}
}Here is the example of a sink semantics exposed as java.util.function.Consumer
@SpringBootApplication
public static class SinkFromConsumer {
@Bean
public Consumer<String> sink() {
return System.out::println;
}
}Suppliers (Sources)
Function and Consumer are pretty straightforward when it comes to how their invocation is triggered. They are triggered based
on data (events) sent to the destination they are bound to. In other words, they are classic event-driven components.
However, Supplier is in its own category when it comes to triggering. Since it is, by definition, the source (the origin) of the data, it does not
subscribe to any in-bound destination and, therefore, has to be triggered by some other mechanism(s).
There is also a question of Supplier implementation, which could be imperative or reactive and which directly relates to the triggering of such suppliers.
Consider the following sample:
@SpringBootApplication
public static class SupplierConfiguration {
@Bean
public Supplier<String> stringSupplier() {
return () -> "Hello from Supplier";
}
}The preceding Supplier bean produces a string whenever its get() method is invoked. However, who invokes this method and how often?
The framework provides a default polling mechanism (answering the question of "Who?") that will trigger the invocation of the supplier and by default it will do so
every second (answering the question of "How often?").
In other words, the above configuration produces a single message every second and each message is sent to an output destination that is exposed by the binder.
To learn how to customize the polling mechanism, see Polling Configuration Properties section.
Consider a different example:
@SpringBootApplication
public static class SupplierConfiguration {
@Bean
public Supplier<Flux<String>> stringSupplier() {
return () -> Flux.fromStream(Stream.generate(new Supplier<String>() {
@Override
public String get() {
try {
Thread.sleep(1000);
return "Hello from Supplier";
} catch (Exception e) {
// ignore
}
}
})).subscribeOn(Schedulers.elastic()).share();
}
}The preceding Supplier bean adopts the reactive programming style. Typically, and unlike the imperative supplier,
it should be triggered only once, given that the invocation of its get() method produces (supplies) the continuous stream of messages and not an
individual message.
The framework recognizes the difference in the programming style and guarantees that such a supplier is triggered only once.
However, imagine the use case where you want to poll some data source and return a finite stream of data representing the result set. The reactive programming style is a perfect mechanism for such a Supplier. However, given the finite nature of the produced stream, such Supplier still needs to be invoked periodically.
Consider the following sample, which emulates such use case by producing a finite stream of data:
@SpringBootApplication
public static class SupplierConfiguration {
@PollableBean
public Supplier<Flux<String>> stringSupplier() {
return () -> Flux.just("hello", "bye");
}
}The bean itself is annotated with PollableBean annotation (sub-set of @Bean), thus signaling to the framework that although the implementation
of such a supplier is reactive, it still needs to be polled.
There is a splittable attribute defined in PollableBean which signals to the post processors of this annotation
that the result produced by the annotated component has to be split and is set to true by default. It means that
the framework will split the returning sending out each item as an individual message. If this is not
he desired behavior you can set it to false at which point such supplier will simply return
the produced Flux without splitting it.
|
Supplier & threading
As you have learned by now, unlike Function and Consumer, which are triggered by an event (they have input data), Supplier does not have
any input and thus triggered by a different mechanism - poller, which may have an unpredictable threading mechanism. And while the details of the
threading mechanism most of the time are not relevant to the downstream execution of the function it may present an issue in certain cases
especially with integrated frameworks that may have certain expectations to thread affinity. For example, Spring Cloud Sleuth which relies
on tracing data stored in thread local.
For those cases we have another mechanism via StreamBridge, where user has more control over threading mechanism. You can get more details
in Sending arbitrary data to an output (e.g. Foreign event-driven sources) section.
|
Consumer (Reactive)
Reactive Consumer is a little bit special because it has a void return type, leaving framework with no reference to subscribe to.
Most likely you will not need to write Consumer<Flux<?>>, and instead write it as a Function<Flux<?>, Mono<Void>> invoking then
operator as the last operator on your stream.
For example:
public Function<Flux<?>, Mono<Void>>consumer() {
return flux -> flux.map(..).filter(..).then();
}But if you do need to write an explicit Consumer<Flux<?>>, remember to subscribe to the incoming Flux.
Polling Configuration Properties
The following properties are exposed by org.springframework.cloud.stream.config.DefaultPollerProperties and are prefixed with
spring.cloud.stream.poller:
- fixedDelay
-
Fixed delay for default poller in milliseconds.
Default: 1000L.
- maxMessagesPerPoll
-
Maximum messages for each polling event of the default poller.
Default: 1L.
- cron
-
Cron expression value for the Cron Trigger.
Default: none.
- initialDelay
-
Initial delay for periodic triggers.
Default: 0.
- timeUnit
-
The TimeUnit to apply to delay values.
Default: MILLISECONDS.
For example --spring.cloud.stream.poller.fixed-delay=2000 sets the poller interval to poll every two seconds.
Sending arbitrary data to an output (e.g. Foreign event-driven sources)
There are cases where the actual source of data may be coming from the external (foreign) system that is not a binder. For example, the source of the data may be a classic REST endpoint. How do we bridge such source with the functional mechanism used by spring-cloud-stream?
Spring Cloud Stream provides two mechanisms, so let’s look at them in more details
Here, for both samples we’ll use a standard MVC endpoint method called delegateToSupplier bound to the root web context,
delegating incoming requests to stream via StreamBridge mechanism.
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class, "--spring.cloud.stream.source=toStream");
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("toStream-out-0", body);
}
}Here we autowire a StreamBridge bean which allows us to send data to an output binding effectively
bridging non-stream application with spring-cloud-stream. Note that preceding example does not have any
source functions defined (e.g., Supplier bean) leaving the framework with no trigger to create source bindings, which would be typical for cases where
configuration contains function beans.
So to trigger the creation of source binding we use spring.cloud.stream.source property where you can declare the name of your sources.
The provided name will be used as a trigger to create a source binding.
So in the preceding example the name of the output binding will be toStream-out-0 which is consistent with the binding naming
convention used by functions (see Binding and Binding names). You can use ; to signify multiple sources
(e.g., --spring.cloud.stream.source=foo;bar)
Also, note that streamBridge.send(..) method takes an Object for data. This means you can send POJO or Message to it and it
will go through the same routine when sending output as if it was from any Function or Supplier providing the same level
of consistency as with functions. This means the output type conversion, partitioning etc are honored as if it was from the output produced by functions.
StreamBridge and Dynamic Destinations
StreamBridge can also be used for cases when output destination(s) are not known ahead of time similar to the use cases
described in Routing FROM Consumer section.
Let’s look at the example
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class, args);
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
System.out.println("Sending " + body);
streamBridge.send("myDestination", body);
}
}As you can see the preceding example is very similar to the previous one with the exception of explicit binding instruction provided via
spring.cloud.stream.source property (which is not provided).
Here we’re sending data to myDestination name which does not exist as a binding. Therefore such name will be treated as dynamic destination
as described in Routing FROM Consumer section.
In the preceding example, we are using ApplicationRunner as a foreign source to feed the stream.
A more practical example, where the foreign source is REST endpoint.
@SpringBootApplication
@Controller
public class WebSourceApplication {
public static void main(String[] args) {
SpringApplication.run(WebSourceApplication.class);
}
@Autowired
private StreamBridge streamBridge;
@RequestMapping
@ResponseStatus(HttpStatus.ACCEPTED)
public void delegateToSupplier(@RequestBody String body) {
streamBridge.send("myBinidng", body);
}
}As you can see inside of delegateToSupplier method we’re using StreamBridge to send data to myBinidng binding. And here you’re also benefiting from
the dynamic features of StreamBridge where if myBinidng doesn’t exist it will be created automatically, otherwise existing binding will be used.
curl -H "Content-Type: text/plain" -X POST -d "hello from the other side" http://localhost:8080/
By showing two example we want to emphasize the approach will work with any type of foreign sources.
Output Content Type with StreamBridge
You can also provide specific content type if necessary with the following method signature public boolean send(String bindingName, Object data, MimeType outputContentType).
Or if you send data as a Message, its content type will be honored.
Using specific binder type with StreamBridge
Spring Cloud Stream supports multiple binder scenarios. For example you may be receiving data from Kafka and sending it to RabbitMQ.
For more information on multiple binders scenarios, please see Binders section and specifically Multiple Binders on the Classpath
In the event you are planning to use StreamBridge and have more then one binder configured in your application you must also tell StreamBridge
which binder to use. And for that there are two more variations of send method:
public boolean send(String bindingName, @Nullable String binderType, Object data)
public boolean send(String bindingName, @Nullable String binderType, Object data, MimeType outputContentType)As you can see there is one additional argument that you can provide - binderType, telling BindingService which binder to use when creating dynamic binding.
For cases where spring.cloud.stream.source property is used or the binding was already created under different binder, the binderType
argument will have no effect.
|
Reactive Functions support
Since Spring Cloud Function is build on top of Project Reactor there isn’t much you need to do
to benefit from reactive programming model while implementing Supplier, Function or Consumer.
For example:
@SpringBootApplication
public static class SinkFromConsumer {
@Bean
public Function<Flux<String>, Flux<String>> reactiveUpperCase() {
return flux -> flux.map(val -> val.toUpperCase());
}
}Functional Composition
Using functional programming model you can also benefit from functional composition where you can dynamically compose complex handlers from a set of simple functions. As an example let’s add the following function bean to the application defined above
@Bean
public Function<String, String> wrapInQuotes() {
return s -> "\"" + s + "\"";
}and modify the spring.cloud.function.definition property to reflect your intention to compose a new function from both ‘toUpperCase’ and ‘wrapInQuotes’.
To do so Spring Cloud Function relies on | (pipe) symbol. So, to finish our example our property will now look like this:
--spring.cloud.function.definition=toUpperCase|wrapInQuotes| One of the great benefits of functional composition support provided by Spring Cloud Function is the fact that you can compose reactive and imperative functions. |
The result of a composition is a single function which, as you may guess, could have a very long and rather cryptic name (e.g., foo|bar|baz|xyz. . .)
presenting a great deal of inconvenience when it comes to other configuration properties. This is where descriptive binding names
feature described in Functional binding names section can help.
For example, if we want to give our toUpperCase|wrapInQuotes a more descriptive name we can do so
with the following property spring.cloud.stream.function.bindings.toUpperCase|wrapInQuotes-in-0=quotedUpperCaseInput allowing
other configuration properties to refer to that binding name (e.g., spring.cloud.stream.bindings.quotedUpperCaseInput.destination=myDestination).
Functional Composition and Cross-cutting Concerns
Function composition effectively allows you to address complexity by breaking it down to a set of simple and individually manageable/testable components that could still be represented as one at runtime. But that is not the only benefit.
You can also use composition to address certain cross-cutting non-functional concerns, such as content enrichment. For example, assume you have an incoming message that may be lacking certain headers, or some headers are not in the exact state your business function would expect. You can now implement a separate function that addresses those concerns and then compose it with the main business function.
Let’s look at the example
@SpringBootApplication
public class DemoStreamApplication {
public static void main(String[] args) {
SpringApplication.run(DemoStreamApplication.class,
"--spring.cloud.function.definition=enrich|echo",
"--spring.cloud.stream.function.bindings.enrich|echo-in-0=input",
"--spring.cloud.stream.bindings.input.destination=myDestination",
"--spring.cloud.stream.bindings.input.group=myGroup");
}
@Bean
public Function<Message<String>, Message<String>> enrich() {
return message -> {
Assert.isTrue(!message.getHeaders().containsKey("foo"), "Should NOT contain 'foo' header");
return MessageBuilder.fromMessage(message).setHeader("foo", "bar").build();
};
}
@Bean
public Function<Message<String>, Message<String>> echo() {
return message -> {
Assert.isTrue(message.getHeaders().containsKey("foo"), "Should contain 'foo' header");
System.out.println("Incoming message " + message);
return message;
};
}
}While trivial, this example demonstrates how one function enriches the incoming Message with the additional header(s) (non-functional concern),
so the other function - echo - can benefit form it. The echo function stays clean and focused on business logic only.
You can also see the usage of spring.cloud.stream.function.bindings property to simplify composed binding name.
Functions with multiple input and output arguments
Starting with version 3.0 spring-cloud-stream provides support for functions that have multiple inputs and/or multiple outputs (return values). What does this actually mean and what type of use cases it is targeting?
-
Big Data: Imagine the source of data you’re dealing with is highly un-organized and contains various types of data elements (e.g., orders, transactions etc) and you effectively need to sort it out.
-
Data aggregation: Another use case may require you to merge data elements from 2+ incoming _streams.
The above describes just a few use cases where you may need to use a single function to accept and/or produce multiple streams of data. And that is the type of use cases we are targeting here.
Also, note a slightly different emphasis on the concept of streams here. The assumption is that such functions are only valuable
if they are given access to the actual streams of data (not the individual elements). So for that we are relying on
abstractions provided by Project Reactor (i.e., Flux and Mono) which is already available on the
classpath as part of the dependencies brought in by spring-cloud-functions.
Another important aspect is representation of multiple input and outputs. While java provides
variety of different abstractions to represent multiple of something those abstractions
are a) unbounded, b) lack arity and c) lack type information which are all important in this context.
As an example, let’s look at Collection or an array which only allows us to
describe multiple of a single type or up-cast everything to an Object, affecting the transparent type conversion feature of
spring-cloud-stream and so on.
So to accommodate all these requirements the initial support is relying on the signature which utilizes another abstraction provided by Project Reactor - Tuples. However, we are working on allowing a more flexible signatures.
| Please refer to Binding and Binding names section to understand the naming convention used to establish binding names used by such application. |
Let’s look at the few samples:
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<Tuple2<Flux<String>, Flux<Integer>>, Flux<String>> gather() {
return tuple -> {
Flux<String> stringStream = tuple.getT1();
Flux<String> intStream = tuple.getT2().map(i -> String.valueOf(i));
return Flux.merge(stringStream, intStream);
};
}
}The above example demonstrates function which takes two inputs (first of type String and second of type Integer)
and produces a single output of type String.
So, for the above example the two input bindings will be gather-in-0 and gather-in-1 and for consistency the
output binding also follows the same convention and is named gather-out-0.
Knowing that will allow you to set binding specific properties.
For example, the following will override content-type for gather-in-0 binding:
--spring.cloud.stream.bindings.gather-in-0.content-type=text/plain
@SpringBootApplication
public class SampleApplication {
@Bean
public static Function<Flux<Integer>, Tuple2<Flux<String>, Flux<String>>> scatter() {
return flux -> {
Flux<Integer> connectedFlux = flux.publish().autoConnect(2);
UnicastProcessor even = UnicastProcessor.create();
UnicastProcessor odd = UnicastProcessor.create();
Flux<Integer> evenFlux = connectedFlux.filter(number -> number % 2 == 0).doOnNext(number -> even.onNext("EVEN: " + number));
Flux<Integer> oddFlux = connectedFlux.filter(number -> number % 2 != 0).doOnNext(number -> odd.onNext("ODD: " + number));
return Tuples.of(Flux.from(even).doOnSubscribe(x -> evenFlux.subscribe()), Flux.from(odd).doOnSubscribe(x -> oddFlux.subscribe()));
};
}
}The above example is somewhat of a the opposite from the previous sample and demonstrates function which
takes single input of type Integer and produces two outputs (both of type String).
So, for the above example the input binding is scatter-in-0 and the
output bindings are scatter-out-0 and scatter-out-1.
And you test it with the following code:
@Test
public void testSingleInputMultiOutput() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleApplication.class))
.run("--spring.cloud.function.definition=scatter")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
for (int i = 0; i < 10; i++) {
inputDestination.send(MessageBuilder.withPayload(String.valueOf(i).getBytes()).build());
}
int counter = 0;
for (int i = 0; i < 5; i++) {
Message<byte[]> even = outputDestination.receive(0, 0);
assertThat(even.getPayload()).isEqualTo(("EVEN: " + String.valueOf(counter++)).getBytes());
Message<byte[]> odd = outputDestination.receive(0, 1);
assertThat(odd.getPayload()).isEqualTo(("ODD: " + String.valueOf(counter++)).getBytes());
}
}
}Multiple functions in a single application
There may also be a need for grouping several message handlers in a single application. You would do so by defining several functions.
@SpringBootApplication
public class SampleApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
@Bean
public Function<String, String> reverse() {
return value -> new StringBuilder(value).reverse().toString();
}
}In the above example we have configuration which defines two functions uppercase and reverse.
So first, as mentioned before, we need to notice that there is a a conflict (more then one function) and therefore
we need to resolve it by providing spring.cloud.function.definition property pointing to the actual function
we want to bind. Except here we will use ; delimiter to point to both functions (see test case below).
| As with functions with multiple inputs/outputs, please refer to Binding and Binding names section to understand the naming convention used to establish binding names used by such application. |
And you test it with the following code:
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
ReactiveFunctionConfiguration.class))
.run("--spring.cloud.function.definition=uppercase;reverse")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "uppercase-in-0");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "uppercase-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-1");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}Batch Consumers
When using a MessageChannelBinder that supports batch listeners, and the feature is enabled for the consumer binding, you can set spring.cloud.stream.bindings.<binding-name>.consumer.batch-mode to true to enable the
entire batch of messages to be passed to the function in a List.
@Bean
public Function<List<Person>, Person> findFirstPerson() {
return persons -> persons.get(0);
}Batch Producers
You can also use the concept of batching on the producer side by returning a collection of Messages which effectively provides an inverse effect where each message in the collection will be sent individually by the binder.
Consider the following function:
@Bean
public Function<String, List<Message<String>>> batch() {
return p -> {
List<Message<String>> list = new ArrayList<>();
list.add(MessageBuilder.withPayload(p + ":1").build());
list.add(MessageBuilder.withPayload(p + ":2").build());
list.add(MessageBuilder.withPayload(p + ":3").build());
list.add(MessageBuilder.withPayload(p + ":4").build());
return list;
};
}Each message in the returned list will be sent individually resulting in four messages sent to output destination.
Spring Integration flow as functions
When you implement a function, you may have complex requirements that fit the category of Enterprise Integration Patterns (EIP). These are best handled by using a framework such as Spring Integration (SI), which is a reference implementation of EIP.
Thankfully SI already provides support for exposing integration flows as functions via Integration flow as gateway Consider the following sample:
@SpringBootApplication
public class FunctionSampleSpringIntegrationApplication {
public static void main(String[] args) {
SpringApplication.run(FunctionSampleSpringIntegrationApplication.class, args);
}
@Bean
public IntegrationFlow uppercaseFlow() {
return IntegrationFlows.from(MessageFunction.class, "uppercase")
.<String, String>transform(String::toUpperCase)
.logAndReply(LoggingHandler.Level.WARN);
}
public interface MessageFunction extends Function<Message<String>, Message<String>> {
}
}For those who are familiar with SI you can see we define a bean of type IntegrationFlow where we
declare an integration flow that we want to expose as a Function<String, String> (using SI DSL) called uppercase.
The MessageFunction interface lets us explicitly declare the type of the inputs and outputs for proper type conversion.
See Content Type Negotiation section for more on type conversion.
To receive raw input you can use from(Function.class, …).
The resulting function is bound to the input and output destinations exposed by the target binder.
| Please refer to Binding and Binding names section to understand the naming convention used to establish binding names used by such application. |
For more details on interoperability of Spring Integration and Spring Cloud Stream specifically around functional programming model you may find this post very interesting, as it dives a bit deeper into various patterns you can apply by merging the best of Spring Integration and Spring Cloud Stream/Functions.
Using Polled Consumers
Overview
When using polled consumers, you poll the PollableMessageSource on demand.
To define binding for polled consumer you need to provide spring.cloud.stream.pollable-source property.
Consider the following example of a polled consumer binding:
--spring.cloud.stream.pollable-source=myDestinationThe pollable-source name myDestination in the preceding example will result in myDestination-in-0 binding name to stay
consistent with functional programming model.
Given the polled consumer in the preceding example, you might use it as follows:
@Bean
public ApplicationRunner poller(PollableMessageSource destIn, MessageChannel destOut) {
return args -> {
while (someCondition()) {
try {
if (!destIn.poll(m -> {
String newPayload = ((String) m.getPayload()).toUpperCase();
destOut.send(new GenericMessage<>(newPayload));
})) {
Thread.sleep(1000);
}
}
catch (Exception e) {
// handle failure
}
}
};
}A less manual and more Spring-like alternative would be to configure a scheduled task bean. For example,
@Scheduled(fixedDelay = 5_000)
public void poll() {
System.out.println("Polling...");
this.source.poll(m -> {
System.out.println(m.getPayload());
}, new ParameterizedTypeReference<Foo>() { });
}The PollableMessageSource.poll() method takes a MessageHandler argument (often a lambda expression, as shown here).
It returns true if the message was received and successfully processed.
As with message-driven consumers, if the MessageHandler throws an exception, messages are published to error channels,
as discussed in Error Handling.
Normally, the poll() method acknowledges the message when the MessageHandler exits.
If the method exits abnormally, the message is rejected (not re-queued), but see Handling Errors.
You can override that behavior by taking responsibility for the acknowledgment, as shown in the following example:
@Bean
public ApplicationRunner poller(PollableMessageSource dest1In, MessageChannel dest2Out) {
return args -> {
while (someCondition()) {
if (!dest1In.poll(m -> {
StaticMessageHeaderAccessor.getAcknowledgmentCallback(m).noAutoAck();
// e.g. hand off to another thread which can perform the ack
// or acknowledge(Status.REQUEUE)
})) {
Thread.sleep(1000);
}
}
};
}
You must ack (or nack) the message at some point, to avoid resource leaks.
|
Some messaging systems (such as Apache Kafka) maintain a simple offset in a log. If a delivery fails and is re-queued with StaticMessageHeaderAccessor.getAcknowledgmentCallback(m).acknowledge(Status.REQUEUE);, any later successfully ack’d messages are redelivered.
|
There is also an overloaded poll method, for which the definition is as follows:
poll(MessageHandler handler, ParameterizedTypeReference<?> type)The type is a conversion hint that allows the incoming message payload to be converted, as shown in the following example:
boolean result = pollableSource.poll(received -> {
Map<String, Foo> payload = (Map<String, Foo>) received.getPayload();
...
}, new ParameterizedTypeReference<Map<String, Foo>>() {});Handling Errors
By default, an error channel is configured for the pollable source; if the callback throws an exception, an ErrorMessage is sent to the error channel (<destination>.<group>.errors); this error channel is also bridged to the global Spring Integration errorChannel.
You can subscribe to either error channel with a @ServiceActivator to handle errors; without a subscription, the error will simply be logged and the message will be acknowledged as successful.
If the error channel service activator throws an exception, the message will be rejected (by default) and won’t be redelivered.
If the service activator throws a RequeueCurrentMessageException, the message will be requeued at the broker and will be again retrieved on a subsequent poll.
If the listener throws a RequeueCurrentMessageException directly, the message will be requeued, as discussed above, and will not be sent to the error channels.
Event Routing
Event Routing, in the context of Spring Cloud Stream, is the ability to either a) route events to a particular event subscriber or b) route events produced by an event subscriber to a particular destination. Here we’ll refer to it as route ‘TO’ and route ‘FROM’.
Routing TO Consumer
Routing can be achieved by relying on RoutingFunction available in Spring Cloud Function 3.0. All you need to do is enable it via
--spring.cloud.stream.function.routing.enabled=true application property or provide spring.cloud.function.routing-expression property.
Once enabled RoutingFunction will be bound to input destination
receiving all the messages and route them to other functions based on the provided instruction.
For the purposes of binding the name of the routing destination is functionRouter-in-0
(see RoutingFunction.FUNCTION_NAME and binding naming convention Functional binding names).
|
Instruction could be provided with individual messages as well as application properties.
Here are couple of samples:
Using message headers
@SpringBootApplication
public class SampleApplication {
public static void main(String[] args) {
SpringApplication.run(SampleApplication.class,
"--spring.cloud.stream.function.routing.enabled=true");
}
@Bean
public Consumer<String> even() {
return value -> {
System.out.println("EVEN: " + value);
};
}
@Bean
public Consumer<String> odd() {
return value -> {
System.out.println("ODD: " + value);
};
}
}By sending a message to the functionRouter-in-0 destination exposed by the binder (i.e., rabbit, kafka),
such message will be routed to the appropriate (‘even’ or ‘odd’) Consumer.
By default RoutingFunction will look for a spring.cloud.function.definition or spring.cloud.function.routing-expression (for more dynamic scenarios with SpEL)
header and if it is found, its value will be treated as the routing instruction.
For example,
setting spring.cloud.function.routing-expression header to value T(java.lang.System).currentTimeMillis() % 2 == 0 ? 'even' : 'odd' will end up semi-randomly routing request to either odd or even functions.
Also, for SpEL, the root object of the evaluation context is Message so you can do evaluation on individual headers (or message) as well ….routing-expression=headers['type']
Using application properties
The spring.cloud.function.routing-expression and/or spring.cloud.function.definition
can be passed as application properties (e.g., spring.cloud.function.routing-expression=headers['type'].
@SpringBootApplication
public class RoutingStreamApplication {
public static void main(String[] args) {
SpringApplication.run(RoutingStreamApplication.class,
"--spring.cloud.function.routing-expression="
+ "T(java.lang.System).nanoTime() % 2 == 0 ? 'even' : 'odd'");
}
@Bean
public Consumer<Integer> even() {
return value -> System.out.println("EVEN: " + value);
}
@Bean
public Consumer<Integer> odd() {
return value -> System.out.println("ODD: " + value);
}
}| Passing instructions via application properties is especially important for reactive functions given that a reactive function is only invoked once to pass the Publisher, so access to the individual items is limited. |
Routing Function and output binding
RoutingFunction is a Function and as such treated no differently than any other function. Well. . . almost.
When RoutingFunction routes to another Function, its output is sent to the output binding of the RoutingFunction which
is functionRouter-in-0 as expected. But what if RoutingFunction routes to a Consumer? In other words the result of invocation
of the RoutingFunction may not produce anything to be sent to the output binding, thus making it necessary to even have one.
So, we do treat RoutingFunction a little bit differently when we create bindings. And even though it is transparent to you as a user
(there is really nothing for you to do), being aware of some of the mechanics would help you understand its inner workings.
So, the rule is;
We never create output binding for the RoutingFunction, only input. So when you routing to Consumer, the RoutingFunction effectively
becomes as a Consumer by not having any output bindings. However, if RoutingFunction happen to route to another Function which produces
the output, the output binding for the RoutingFunction will be create dynamically at which point RoutingFunction will act as a regular Function
with regards to bindings (having both input and output bindings).
Routing FROM Consumer
Aside from static destinations, Spring Cloud Stream lets applications send messages to dynamically bound destinations. This is useful, for example, when the target destination needs to be determined at runtime. Applications can do so in one of two ways.
BinderAwareChannelResolver
The BinderAwareChannelResolver is a special bean registered automatically by the framework.
You can autowire this bean into your application and use it to resolve output destination at runtime
The 'spring.cloud.stream.dynamicDestinations' property can be used for restricting the dynamic destination names to a known set (that is, intentionally allowed values). If this property is not set, any destination can be bound dynamically.
The following example demonstrates one of the common scenarios where REST controller uses a path variable to determine target destination:
@SpringBootApplication
@Controller
public class SourceWithDynamicDestination {
@Autowired
private BinderAwareChannelResolver resolver;
@RequestMapping(value="/{target}")
@ResponseStatus(HttpStatus.ACCEPTED)
public void send(@RequestBody String body, @PathVariable("target") String target){
resolver.resolveDestination(target).send(new GenericMessage<String>(body));
}
}Now consider what happens when we start the application on the default port (8080) and make the following requests with CURL:
curl -H "Content-Type: application/json" -X POST -d "customer-1" http://localhost:8080/customers curl -H "Content-Type: application/json" -X POST -d "order-1" http://localhost:8080/orders
The destinations, 'customers' and 'orders', are created in the broker (in the exchange for Rabbit or in the topic for Kafka) with names of 'customers' and 'orders', and the data is published to the appropriate destinations.
spring.cloud.stream.sendto.destination
You can also delegate to the framework to dynamically resolve the output destination by specifying spring.cloud.stream.sendto.destination header
set to the name of the destination to be resolved.
Consider the following example:
@SpringBootApplication
@Controller
public class SourceWithDynamicDestination {
@Bean
public Function<String, Message<String>> destinationAsPayload() {
return value -> {
return MessageBuilder.withPayload(value)
.setHeader("spring.cloud.stream.sendto.destination", value).build();};
}
}Albeit trivial you can clearly see in this example, our output is a Message with spring.cloud.stream.sendto.destination header
set to the value of he input argument. The framework will consult this header and will attempt to create or discover
a destination with that name and send output to it.
If destination names are known in advance, you can configure the producer properties as with any other destination.
Alternatively, if you register a NewDestinationBindingCallback<> bean, it is invoked just before the binding is created.
The callback takes the generic type of the extended producer properties used by the binder.
It has one method:
void configure(String destinationName, MessageChannel channel, ProducerProperties producerProperties,
T extendedProducerProperties);The following example shows how to use the RabbitMQ binder:
@Bean
public NewDestinationBindingCallback<RabbitProducerProperties> dynamicConfigurer() {
return (name, channel, props, extended) -> {
props.setRequiredGroups("bindThisQueue");
extended.setQueueNameGroupOnly(true);
extended.setAutoBindDlq(true);
extended.setDeadLetterQueueName("myDLQ");
};
}
If you need to support dynamic destinations with multiple binder types, use Object for the generic type and cast the extended argument as needed.
|
Also, please see [Using StreamBridge] section to see how yet another option (StreamBridge) can be utilized for similar cases.
Error Handling
In this section we’ll explain the general idea behind error handling mechanisms provided by the framework. We’ll be using Rabbit binder as an example, since individual binders define different set of properties for certain supported mechanisms specific to underlying broker capabilities (such as Kafka binder).
Errors happen, and Spring Cloud Stream provides several flexible mechanisms to deal with them. Note, the techniques are dependent on binder implementation and the capability of the underlying messaging middleware as well as programming model (more on this later).
Whenever Message handler (function) throws an exception, it is propagated back to the binder, and the binder subsequently propagates
the error back to the messaging system. The framework then will make several attempts at re-trying
the same message (3 by default) using RetryTemplate provided by the Spring Retry library.
After that, depending on the capabilities of the messaging system such system may drop the message, re-queue the message for re-processing or send the failed message to DLQ. Both Rabbit and Kafka support these concepts. However, other binders may not, so refer to your individual binder’s documentation for details on supported error-handling options.
Keep in mind however, the reactive function does NOT qualify as a Message handler, since it does not handle individual messages and instead provides a way to connect stream (i.e., Flux) provided by the framework with the one provided by the user. In other way of looking at it is - Message handler (i.e., imperative function) is invoked for each Message, while the reactive function is invoked only once during the initialization to connect two stream definitions at which point framework effectively hands off any and all control to the reactive API.
Why is this important? That is because anything you read later in this section with regard to Retry Template, dropping failed messages, retrying, DLQ and configuration properties that assist with all of it only applies to Message handlers (i.e., imperative functions).
Reactive API provides a very rich library of its own operators and mechanisms to assist you with error handling specific to
variety of reactive uses cases which are far more complex then simple Message handler cases, So use them, such
as public final Flux<T> retryWhen(Retry retrySpec); that you can find in reactor.core.publisher.Flux.
@Bean
public Function<Flux<String>, Flux<String>> uppercase() {
return flux -> flux
.retryWhen(Retry.backoff(3, Duration.ofMillis(1000)))
.map(v -> v.toUpperCase());
}Drop Failed Messages
By default, if no additional system-level configuration is provided, the messaging system drops the failed message. While acceptable in some cases, for most cases, it is not, and we need some recovery mechanism to avoid message loss.
DLQ - Dead Letter Queue
Perhaps the most common mechanism, DLQ allows failed messages to be sent to a special destination: the Dead Letter Queue.
When configured, failed messages are sent to this destination for subsequent re-processing or auditing and reconciliation.
Consider the following example:
@SpringBootApplication
public class SimpleStreamApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(SimpleStreamApplication.class,
"--spring.cloud.function.definition=uppercase",
"--spring.cloud.stream.bindings.uppercase-in-0.destination=uppercase",
"--spring.cloud.stream.bindings.uppercase-in-0.group=myGroup",
"--spring.cloud.stream.rabbit.bindings.uppercase-in-0.consumer.auto-bind-dlq=true"
);
}
@Bean
public Function<Person, Person> uppercase() {
return personIn -> {
throw new RuntimeException("intentional");
});
};
}
}As a reminder, in this example uppercase-in-0 segment of the property corresponds to the name of the input destination binding.
The consumer segment indicates that it is a consumer property.
When using DLQ, at least the group property must be provided for proper naming of the DLQ destination. However group is often used together
with destination property, as in our example.
|
Aside from some standard properties we also set the auto-bind-dlq to instruct the binder to create and configure DLQ destination for
uppercase-in-0 binding which corresponds to uppercase destination (see corresponding property), which results in an additional Rabbit queue named uppercase.myGroup.dlq (see Kafka documentation for Kafka specific DLQ properties).
Once configured, all failed messages are routed to this destination preserving the original message for further actions.
And you can see that the error message contains more information relevant to the original error, as follows:
. . . .
x-exception-stacktrace: org.springframework.messaging.MessageHandlingException: nested exception is
org.springframework.messaging.MessagingException: has an error, failedMessage=GenericMessage [payload=byte[15],
headers={amqp_receivedDeliveryMode=NON_PERSISTENT, amqp_receivedRoutingKey=input.hello, amqp_deliveryTag=1,
deliveryAttempt=3, amqp_consumerQueue=input.hello, amqp_redelivered=false, id=a15231e6-3f80-677b-5ad7-d4b1e61e486e,
amqp_consumerTag=amq.ctag-skBFapilvtZhDsn0k3ZmQg, contentType=application/json, timestamp=1522327846136}]
at org.spring...integ...han...MethodInvokingMessageProcessor.processMessage(MethodInvokingMessageProcessor.java:107)
at. . . . .
Payload: blahYou can also facilitate immediate dispatch to DLQ (without re-tries) by setting max-attempts to '1'. For example,
--spring.cloud.stream.bindings.uppercase-in-0.consumer.max-attempts=1Retry Template
In this section we cover configuration properties relevant to configuration of retry capabilities.
The RetryTemplate is part of the Spring Retry library.
While it is out of scope of this document to cover all of the capabilities of the RetryTemplate, we
will mention the following consumer properties that are specifically related to
the RetryTemplate:
- maxAttempts
-
The number of attempts to process the message.
Default: 3.
- backOffInitialInterval
-
The backoff initial interval on retry.
Default 1000 milliseconds.
- backOffMaxInterval
-
The maximum backoff interval.
Default 10000 milliseconds.
- backOffMultiplier
-
The backoff multiplier.
Default 2.0.
- defaultRetryable
-
Whether exceptions thrown by the listener that are not listed in the
retryableExceptionsare retryable.Default:
true. - retryableExceptions
-
A map of Throwable class names in the key and a boolean in the value. Specify those exceptions (and subclasses) that will or won’t be retried. Also see
defaultRetriable. Example:spring.cloud.stream.bindings.input.consumer.retryable-exceptions.java.lang.IllegalStateException=false.Default: empty.
While the preceding settings are sufficient for the majority of the customization requirements, they may not satisfy certain complex requirements, at which
point you may want to provide your own instance of the RetryTemplate. To do so configure it as a bean in your application configuration. The application provided
instance will override the one provided by the framework. Also, to avoid conflicts you must qualify the instance of the RetryTemplate you want to be used by the binder
as @StreamRetryTemplate. For example,
@StreamRetryTemplate
public RetryTemplate myRetryTemplate() {
return new RetryTemplate();
}As you can see from the above example you don’t need to annotate it with @Bean since @StreamRetryTemplate is a qualified @Bean.
If you need to be more precise with your RetryTemplate, you can specify the bean by name in your ConsumerProperties to associate
the specific retry bean per binding.
spring.cloud.stream.bindings.<foo>.consumer.retry-template-name=<your-retry-template-bean-name>Binders
Spring Cloud Stream provides a Binder abstraction for use in connecting to physical destinations at the external middleware. This section provides information about the main concepts behind the Binder SPI, its main components, and implementation-specific details.
Producers and Consumers
The following image shows the general relationship of producers and consumers:
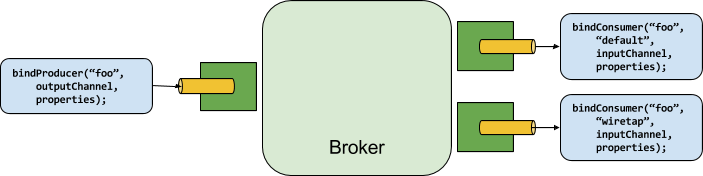
A producer is any component that sends messages to a binding destination.
The binding destination can be bound to an external message broker with a Binder implementation for that broker.
When invoking the bindProducer() method, the first parameter is the name of the destination within the broker, the second parameter is the instance if local destination to which the producer sends messages, and the third parameter contains properties (such as a partition key expression) to be used within the adapter that is created for that binding destination.
A consumer is any component that receives messages from the binding destination.
As with a producer, the consumer can be bound to an external message broker.
When invoking the bindConsumer() method, the first parameter is the destination name, and a second parameter provides the name of a logical group of consumers.
Each group that is represented by consumer bindings for a given destination receives a copy of each message that a producer sends to that destination (that is, it follows normal publish-subscribe semantics).
If there are multiple consumer instances bound with the same group name, then messages are load-balanced across those consumer instances so that each message sent by a producer is consumed by only a single consumer instance within each group (that is, it follows normal queueing semantics).
Binder SPI
The Binder SPI consists of a number of interfaces, out-of-the box utility classes, and discovery strategies that provide a pluggable mechanism for connecting to external middleware.
The key point of the SPI is the Binder interface, which is a strategy for connecting inputs and outputs to external middleware. The following listing shows the definition of the Binder interface:
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
Binding<T> bindConsumer(String bindingName, String group, T inboundBindTarget, C consumerProperties);
Binding<T> bindProducer(String bindingName, T outboundBindTarget, P producerProperties);
}The interface is parameterized, offering a number of extension points:
-
Input and output bind targets.
-
Extended consumer and producer properties, allowing specific Binder implementations to add supplemental properties that can be supported in a type-safe manner.
A typical binder implementation consists of the following:
-
A class that implements the
Binderinterface; -
A Spring
@Configurationclass that creates a bean of typeBinderalong with the middleware connection infrastructure. -
A
META-INF/spring.bindersfile found on the classpath containing one or more binder definitions, as shown in the following example:kafka:\ org.springframework.cloud.stream.binder.kafka.config.KafkaBinderConfiguration
As it was mentioned earlier Binder abstraction is also one of the extension points of the framework. So if you can’t find a suitable binder in the preceding list you can implement your own binder on top of Spring Cloud Stream.
In the How to create a Spring Cloud Stream Binder from scratch post a community member documents
in details, with an example, a set of steps necessary to implement a custom binder.
The steps are also highlighted in the Implementing Custom Binders section.
|
Binder Detection
Spring Cloud Stream relies on implementations of the Binder SPI to perform the task of connecting (binding) user code to message brokers. Each Binder implementation typically connects to one type of messaging system.
Classpath Detection
By default, Spring Cloud Stream relies on Spring Boot’s auto-configuration to configure the binding process. If a single Binder implementation is found on the classpath, Spring Cloud Stream automatically uses it. For example, a Spring Cloud Stream project that aims to bind only to RabbitMQ can add the following dependency:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>For the specific Maven coordinates of other binder dependencies, see the documentation of that binder implementation.
Multiple Binders on the Classpath
When multiple binders are present on the classpath, the application must indicate which binder is to be used for each destination binding.
Each binder configuration contains a META-INF/spring.binders file, which is a simple properties file, as shown in the following example:
rabbit:\
org.springframework.cloud.stream.binder.rabbit.config.RabbitServiceAutoConfigurationSimilar files exist for the other provided binder implementations (such as Kafka), and custom binder implementations are expected to provide them as well.
The key represents an identifying name for the binder implementation, whereas the value is a comma-separated list of configuration classes that each contain one and only one bean definition of type org.springframework.cloud.stream.binder.Binder.
Binder selection can either be performed globally, using the spring.cloud.stream.defaultBinder property (for example, spring.cloud.stream.defaultBinder=rabbit) or individually, by configuring the binder on each binding.
For instance, a processor application (that has bindings named input and output for read and write respectively) that reads from Kafka and writes to RabbitMQ can specify the following configuration:
spring.cloud.stream.bindings.input.binder=kafka
spring.cloud.stream.bindings.output.binder=rabbitConnecting to Multiple Systems
By default, binders share the application’s Spring Boot auto-configuration, so that one instance of each binder found on the classpath is created. If your application should connect to more than one broker of the same type, you can specify multiple binder configurations, each with different environment settings.
Turning on explicit binder configuration disables the default binder configuration process altogether.
If you do so, all binders in use must be included in the configuration.
Frameworks that intend to use Spring Cloud Stream transparently may create binder configurations that can be referenced by name, but they do not affect the default binder configuration.
In order to do so, a binder configuration may have its defaultCandidate flag set to false (for example, spring.cloud.stream.binders.<configurationName>.defaultCandidate=false).
This denotes a configuration that exists independently of the default binder configuration process.
|
The following example shows a typical configuration for a processor application that connects to two RabbitMQ broker instances:
spring:
cloud:
stream:
bindings:
input:
destination: thing1
binder: rabbit1
output:
destination: thing2
binder: rabbit2
binders:
rabbit1:
type: rabbit
environment:
spring:
rabbitmq:
host: <host1>
rabbit2:
type: rabbit
environment:
spring:
rabbitmq:
host: <host2>
The environment property of the particular binder can also be used for any Spring Boot property,
including this spring.main.sources which can be useful for adding additional configurations for the
particular binders, e.g. overriding auto-configured beans.
|
For example;
environment:
spring:
main:
sources: com.acme.config.MyCustomBinderConfigurationTo activate a specific profile for the particular binder environment, you should use a spring.profiles.active property:
environment:
spring:
profiles:
active: myBinderProfileCustomizing binders in multi binder applications
When an application has multiple binders in it and wants to customize the binders, then that can be achieved by providing a BinderCustomizer implementation.
In the case of applications with a single binder, this special customizer is not necessary since the binder context can access the customization beans directly.
However, this is not the case in a multi-binder scenario, since various binders live in different application contexts.
By providing an implementation of BinderCustomizer interface, the binders, although reside in different application contexts, will receive the customization.
Spring Cloud Stream ensures that the customizations take place before the applications start using the binders.
The user must check for the binder type and then apply the necessary customizations.
Here is an example of providing a BinderCustomizer bean.
@Bean
public BinderCustomizer binderCustomizer() {
return (binder, binderName) -> {
if (binder instanceof KafkaMessageChannelBinder) {
((KafkaMessageChannelBinder) binder).setRebalanceListener(...);
}
else if (binder instanceof KStreamBinder) {
...
}
else if (binder instanceof RabbitMessageChannelBinder) {
...
}
};
}Note that, when there are more than one instance of the same type of the binder, the binder name can be used to filter customization.
Binding visualization and control
Spring Cloud Stream supports visualization and control of the Bindings through Actuator endpoints as well as programmatic way.
Programmatic way
Since version 3.1 we expose org.springframework.cloud.stream.binding.BindingsLifecycleController which is registered as bean and once
injected could be used to control the lifecycle of individual bindings
For example, looks at the fragment from one of the test cases. As you can see we retrieve BindingsLifecycleController
from spring application context and execute individual methods to control the lifecycle of echo-in-0 binding..
BindingsLifecycleController bindingsController = context.getBean(BindingsLifecycleController.class);
Binding binding = bindingsController.queryState("echo-in-0");
assertThat(binding.isRunning()).isTrue();
bindingsController.changeState("echo-in-0", State.STOPPED);
//Alternative way of changing state. For convenience we expose start/stop and pause/resume operations.
//bindingsController.stop("echo-in-0")
assertThat(binding.isRunning()).isFalse();Actuator
Since actuator and web are optional, you must first add one of the web dependencies as well as add the actuator dependency manually. The following example shows how to add the dependency for the Web framework:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>The following example shows how to add the dependency for the WebFlux framework:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>You can add the Actuator dependency as follows:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
To run Spring Cloud Stream 2.0 apps in Cloud Foundry, you must add spring-boot-starter-web and spring-boot-starter-actuator to the classpath. Otherwise, the
application will not start due to health check failures.
|
You must also enable the bindings actuator endpoints by setting the following property: --management.endpoints.web.exposure.include=bindings.
Once those prerequisites are satisfied. you should see the following in the logs when application start:
: Mapped "{[/actuator/bindings/{name}],methods=[POST]. . .
: Mapped "{[/actuator/bindings],methods=[GET]. . .
: Mapped "{[/actuator/bindings/{name}],methods=[GET]. . .
To visualize the current bindings, access the following URL:
http://<host>:<port>/actuator/bindings
Alternative, to see a single binding, access one of the URLs similar to the following:
http://<host>:<port>/actuator/bindings/<bindingName>;
You can also stop, start, pause, and resume individual bindings by posting to the same URL while providing a state argument as JSON, as shown in the following examples:
curl -d '{"state":"STOPPED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"STARTED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"PAUSED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
curl -d '{"state":"RESUMED"}' -H "Content-Type: application/json" -X POST http://<host>:<port>/actuator/bindings/myBindingName
PAUSED and RESUMED work only when the corresponding binder and its underlying technology supports it. Otherwise, you see the warning message in the logs.
Currently, only Kafka binder supports the PAUSED and RESUMED states.
|
Binder Configuration Properties
The following properties are available when customizing binder configurations. These properties exposed via org.springframework.cloud.stream.config.BinderProperties
They must be prefixed with spring.cloud.stream.binders.<configurationName>.
- type
-
The binder type. It typically references one of the binders found on the classpath — in particular, a key in a
META-INF/spring.bindersfile.By default, it has the same value as the configuration name.
- inheritEnvironment
-
Whether the configuration inherits the environment of the application itself.
Default:
true. - environment
-
Root for a set of properties that can be used to customize the environment of the binder. When this property is set, the context in which the binder is being created is not a child of the application context. This setting allows for complete separation between the binder components and the application components.
Default:
empty. - defaultCandidate
-
Whether the binder configuration is a candidate for being considered a default binder or can be used only when explicitly referenced. This setting allows adding binder configurations without interfering with the default processing.
Default:
true.
Implementing Custom Binders
In order to implement a custom Binder, all you need is to:
-
Add the required dependencies
-
Provide a ProvisioningProvider implementation
-
Provide a MessageProducer implementation
-
Provide a MessageHandler implementation
-
Provide a Binder implementation
-
Create a Binder Configuration
-
Define your binder in META-INF/spring.binders
Add the required dependencies
Add the spring-cloud-stream dependency to your project (eg. for Maven):
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
<version>${spring.cloud.stream.version}</version>
</dependency>Provide a ProvisioningProvider implementation
The ProvisioningProvider is responsible for the provisioning of consumer and producer destinations, and is required to convert the logical destinations included in the application.yml or application.properties file in physical destination references.
Below an example of ProvisioningProvider implementation that simply trims the destinations provided via input/output bindings configuration:
public class FileMessageBinderProvisioner implements ProvisioningProvider<ConsumerProperties, ProducerProperties> {
@Override
public ProducerDestination provisionProducerDestination(
final String name,
final ProducerProperties properties) {
return new FileMessageDestination(name);
}
@Override
public ConsumerDestination provisionConsumerDestination(
final String name,
final String group,
final ConsumerProperties properties) {
return new FileMessageDestination(name);
}
private class FileMessageDestination implements ProducerDestination, ConsumerDestination {
private final String destination;
private FileMessageDestination(final String destination) {
this.destination = destination;
}
@Override
public String getName() {
return destination.trim();
}
@Override
public String getNameForPartition(int partition) {
throw new UnsupportedOperationException("Partitioning is not implemented for file messaging.");
}
}
}Provide a MessageProducer implementation
The MessageProducer is responsible for consuming events and handling them as messages to the client application that is configured to consume such events.
Here is an example of MessageProducer implementation that extends the MessageProducerSupport abstraction in order to poll on a file that matches the trimmed destination name and is located in the project path, while also archiving read messages and discarding consequent identical messages:
public class FileMessageProducer extends MessageProducerSupport {
public static final String ARCHIVE = "archive.txt";
private final ConsumerDestination destination;
private String previousPayload;
public FileMessageProducer(ConsumerDestination destination) {
this.destination = destination;
}
@Override
public void doStart() {
receive();
}
private void receive() {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
executorService.scheduleWithFixedDelay(() -> {
String payload = getPayload();
if(payload != null) {
Message<String> receivedMessage = MessageBuilder.withPayload(payload).build();
archiveMessage(payload);
sendMessage(receivedMessage);
}
}, 0, 50, MILLISECONDS);
}
private String getPayload() {
try {
List<String> allLines = Files.readAllLines(Paths.get(destination.getName()));
String currentPayload = allLines.get(allLines.size() - 1);
if(!currentPayload.equals(previousPayload)) {
previousPayload = currentPayload;
return currentPayload;
}
} catch (IOException e) {
throw new RuntimeException(e);
}
return null;
}
private void archiveMessage(String payload) {
try {
Files.write(Paths.get(ARCHIVE), (payload + "\n").getBytes(), CREATE, APPEND);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}| When implementing a custom binder, this step is not strictly mandatory as you could always resort to using an already existing MessageProducer implementation! |
Provide a MessageHandler implementation
The MessageHandler provides the logic required to produce an event.
Here is an example of MessageHandler implementation:
public class FileMessageHandler implements MessageHandler{
@Override
public void handleMessage(Message<?> message) throws MessagingException {
//write message to file
}
}| When implementing a custom binder, this step is not strictly mandatory as you could always resort to using an already existing MessageHandler implementation! |
Provide a Binder implementation
You are now able to provide your own implementation of the Binder abstraction. This can be easily done by:
-
extending the
AbstractMessageChannelBinderclass -
specifying your ProvisioningProvider as a generic argument of the AbstractMessageChannelBinder
-
overriding the
createProducerMessageHandlerandcreateConsumerEndpointmethods
eg.:
public class FileMessageBinder extends AbstractMessageChannelBinder<ConsumerProperties, ProducerProperties, FileMessageBinderProvisioner> {
public FileMessageBinder(
String[] headersToEmbed,
FileMessageBinderProvisioner provisioningProvider) {
super(headersToEmbed, provisioningProvider);
}
@Override
protected MessageHandler createProducerMessageHandler(
final ProducerDestination destination,
final ProducerProperties producerProperties,
final MessageChannel errorChannel) throws Exception {
return message -> {
String fileName = destination.getName();
String payload = new String((byte[])message.getPayload()) + "\n";
try {
Files.write(Paths.get(fileName), payload.getBytes(), CREATE, APPEND);
} catch (IOException e) {
throw new RuntimeException(e);
}
};
}
@Override
protected MessageProducer createConsumerEndpoint(
final ConsumerDestination destination,
final String group,
final ConsumerProperties properties) throws Exception {
return new FileMessageProducer(destination);
}
}Create a Binder Configuration
It is strictly required that you create a Spring Configuration to initialize the bean for your binder implementation (and all other beans that you might need):
@Configuration
public class FileMessageBinderConfiguration {
@Bean
@ConditionalOnMissingBean
public FileMessageBinderProvisioner fileMessageBinderProvisioner() {
return new FileMessageBinderProvisioner();
}
@Bean
@ConditionalOnMissingBean
public FileMessageBinder fileMessageBinder(FileMessageBinderProvisioner fileMessageBinderProvisioner) {
return new FileMessageBinder(null, fileMessageBinderProvisioner);
}
}Define your binder in META-INF/spring.binders
Finally, you must define your binder in a META-INF/spring.binders file on the classpath, specifying both the name of the binder and the full qualified name of your Binder Configuration class:
myFileBinder:\
com.example.springcloudstreamcustombinder.config.FileMessageBinderConfigurationConfiguration Options
Spring Cloud Stream supports general configuration options as well as configuration for bindings and binders. Some binders let additional binding properties support middleware-specific features.
Configuration options can be provided to Spring Cloud Stream applications through any mechanism supported by Spring Boot. This includes application arguments, environment variables, and YAML or .properties files.
Binding Service Properties
These properties are exposed via org.springframework.cloud.stream.config.BindingServiceProperties
- spring.cloud.stream.instanceCount
-
The number of deployed instances of an application. Must be set for partitioning on the producer side. Must be set on the consumer side when using RabbitMQ and with Kafka if
autoRebalanceEnabled=false.Default:
1. - spring.cloud.stream.instanceIndex
-
The instance index of the application: A number from
0toinstanceCount - 1. Used for partitioning with RabbitMQ and with Kafka ifautoRebalanceEnabled=false. Automatically set in Cloud Foundry to match the application’s instance index. - spring.cloud.stream.dynamicDestinations
-
A list of destinations that can be bound dynamically (for example, in a dynamic routing scenario). If set, only listed destinations can be bound.
Default: empty (letting any destination be bound).
- spring.cloud.stream.defaultBinder
-
The default binder to use, if multiple binders are configured. See Multiple Binders on the Classpath.
Default: empty.
- spring.cloud.stream.overrideCloudConnectors
-
This property is only applicable when the
cloudprofile is active and Spring Cloud Connectors are provided with the application. If the property isfalse(the default), the binder detects a suitable bound service (for example, a RabbitMQ service bound in Cloud Foundry for the RabbitMQ binder) and uses it for creating connections (usually through Spring Cloud Connectors). When set totrue, this property instructs binders to completely ignore the bound services and rely on Spring Boot properties (for example, relying on thespring.rabbitmq.*properties provided in the environment for the RabbitMQ binder). The typical usage of this property is to be nested in a customized environment when connecting to multiple systems.Default:
false. - spring.cloud.stream.bindingRetryInterval
-
The interval (in seconds) between retrying binding creation when, for example, the binder does not support late binding and the broker (for example, Apache Kafka) is down. Set it to zero to treat such conditions as fatal, preventing the application from starting.
Default:
30
Binding Properties
Binding properties are supplied by using the format of spring.cloud.stream.bindings.<bindingName>.<property>=<value>.
The <bindingName> represents the name of the binding being configured.
For example, for the following function
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}there are two bindings named uppercase-in-0 for input and uppercase-out-0 for output. See Binding and Binding names for more details.
To avoid repetition, Spring Cloud Stream supports setting values for all bindings, in the format of spring.cloud.stream.default.<property>=<value>
and spring.cloud.stream.default.<producer|consumer>.<property>=<value> for common binding properties.
When it comes to avoiding repetitions for extended binding properties, this format should be used - spring.cloud.stream.<binder-type>.default.<producer|consumer>.<property>=<value>.
Common Binding Properties
These properties are exposed via org.springframework.cloud.stream.config.BindingProperties
The following binding properties are available for both input and output bindings and must be prefixed with spring.cloud.stream.bindings.<bindingName>.
(for example, spring.cloud.stream.bindings.uppercase-in-0.destination=ticktock).
Default values can be set by using the spring.cloud.stream.default prefix (for example`spring.cloud.stream.default.contentType=application/json`).
- destination
-
The target destination of a binding on the bound middleware (for example, the RabbitMQ exchange or Kafka topic). If binding represents a consumer binding (input), it could be bound to multiple destinations, and the destination names can be specified as comma-separated
Stringvalues. If not, the actual binding name is used instead. The default value of this property cannot be overridden. - group
-
The consumer group of the binding. Applies only to inbound bindings. See Consumer Groups.
Default:
null(indicating an anonymous consumer). - contentType
-
The content type of this binding. See
Content Type Negotiation.Default:
application/json. - binder
-
The binder used by this binding. See
Multiple Binders on the Classpathfor details.Default:
null(the default binder is used, if it exists).
Consumer Properties
These properties are exposed via org.springframework.cloud.stream.binder.ConsumerProperties
The following binding properties are available for input bindings only and must be prefixed with spring.cloud.stream.bindings.<bindingName>.consumer. (for example, spring.cloud.stream.bindings.input.consumer.concurrency=3).
Default values can be set by using the spring.cloud.stream.default.consumer prefix (for example, spring.cloud.stream.default.consumer.headerMode=none).
- autoStartup
-
Signals if this consumer needs to be started automatically
Default:
true. - concurrency
-
The concurrency of the inbound consumer.
Default:
1. - partitioned
-
Whether the consumer receives data from a partitioned producer.
Default:
false. - headerMode
-
When set to
none, disables header parsing on input. Effective only for messaging middleware that does not support message headers natively and requires header embedding. This option is useful when consuming data from non-Spring Cloud Stream applications when native headers are not supported. When set toheaders, it uses the middleware’s native header mechanism. When set toembeddedHeaders, it embeds headers into the message payload.Default: depends on the binder implementation.
- maxAttempts
-
If processing fails, the number of attempts to process the message (including the first). Set to
1to disable retry.Default:
3. - backOffInitialInterval
-
The backoff initial interval on retry.
Default:
1000. - backOffMaxInterval
-
The maximum backoff interval.
Default:
10000. - backOffMultiplier
-
The backoff multiplier.
Default:
2.0. - defaultRetryable
-
Whether exceptions thrown by the listener that are not listed in the
retryableExceptionsare retryable.Default:
true. - instanceCount
-
When set to a value greater than equal to zero, it allows customizing the instance count of this consumer (if different from
spring.cloud.stream.instanceCount). When set to a negative value, it defaults tospring.cloud.stream.instanceCount. SeeInstance Index and Instance Countfor more information.Default:
-1. - instanceIndex
-
When set to a value greater than equal to zero, it allows customizing the instance index of this consumer (if different from
spring.cloud.stream.instanceIndex). When set to a negative value, it defaults tospring.cloud.stream.instanceIndex. Ignored ifinstanceIndexListis provided. SeeInstance Index and Instance Countfor more information.Default:
-1. - instanceIndexList
-
Used with binders that do not support native partitioning (such as RabbitMQ); allows an application instance to consume from more than one partition.
Default: empty.
- retryableExceptions
-
A map of Throwable class names in the key and a boolean in the value. Specify those exceptions (and subclasses) that will or won’t be retried. Also see
defaultRetriable. Example:spring.cloud.stream.bindings.input.consumer.retryable-exceptions.java.lang.IllegalStateException=false.Default: empty.
- useNativeDecoding
-
When set to
true, the inbound message is deserialized directly by the client library, which must be configured correspondingly (for example, setting an appropriate Kafka producer value deserializer). When this configuration is being used, the inbound message unmarshalling is not based on thecontentTypeof the binding. When native decoding is used, it is the responsibility of the producer to use an appropriate encoder (for example, the Kafka producer value serializer) to serialize the outbound message. Also, when native encoding and decoding is used, theheaderMode=embeddedHeadersproperty is ignored and headers are not embedded in the message. See the producer propertyuseNativeEncoding.Default:
false. - multiplex
-
When set to true, the underlying binder will natively multiplex destinations on the same input binding.
Default:
false.
Advanced Consumer Configuration
For advanced configuration of the underlying message listener container for message-driven consumers, add a single ListenerContainerCustomizer bean to the application context.
It will be invoked after the above properties have been applied and can be used to set additional properties.
Similarly, for polled consumers, add a MessageSourceCustomizer bean.
The following is an example for the RabbitMQ binder:
@Bean
public ListenerContainerCustomizer<AbstractMessageListenerContainer> containerCustomizer() {
return (container, dest, group) -> container.setAdviceChain(advice1, advice2);
}
@Bean
public MessageSourceCustomizer<AmqpMessageSource> sourceCustomizer() {
return (source, dest, group) -> source.setPropertiesConverter(customPropertiesConverter);
}Producer Properties
These properties are exposed via org.springframework.cloud.stream.binder.ProducerProperties
The following binding properties are available for output bindings only and must be prefixed with spring.cloud.stream.bindings.<bindingName>.producer.
(for example, spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=payload.id).
Default values can be set by using the prefix spring.cloud.stream.default.producer (for example, spring.cloud.stream.default.producer.partitionKeyExpression=payload.id).
- autoStartup
-
Signals if this consumer needs to be started automatically
Default:
true. - partitionKeyExpression
-
A SpEL expression that determines how to partition outbound data. If set, outbound data on this binding is partitioned.
partitionCountmust be set to a value greater than 1 to be effective. SeePartitioning Support.Default: null.
- partitionKeyExtractorName
-
The name of the bean that implements
PartitionKeyExtractorStrategy. Used to extract a key used to compute the partition id (see 'partitionSelector*'). Mutually exclusive with 'partitionKeyExpression'.Default: null.
- partitionSelectorName
-
The name of the bean that implements
PartitionSelectorStrategy. Used to determine partition id based on partition key (see 'partitionKeyExtractor*'). Mutually exclusive with 'partitionSelectorExpression'.Default: null.
- partitionSelectorExpression
-
A SpEL expression for customizing partition selection. If neither is set, the partition is selected as the
hashCode(key) % partitionCount, wherekeyis computed through eitherpartitionKeyExpression.Default:
null. - partitionCount
-
The number of target partitions for the data, if partitioning is enabled. Must be set to a value greater than 1 if the producer is partitioned. On Kafka, it is interpreted as a hint. The larger of this and the partition count of the target topic is used instead.
Default:
1. - requiredGroups
-
A comma-separated list of groups to which the producer must ensure message delivery even if they start after it has been created (for example, by pre-creating durable queues in RabbitMQ).
- headerMode
-
When set to
none, it disables header embedding on output. It is effective only for messaging middleware that does not support message headers natively and requires header embedding. This option is useful when producing data for non-Spring Cloud Stream applications when native headers are not supported. When set toheaders, it uses the middleware’s native header mechanism. When set toembeddedHeaders, it embeds headers into the message payload.Default: Depends on the binder implementation.
- useNativeEncoding
-
When set to
true, the outbound message is serialized directly by the client library, which must be configured correspondingly (for example, setting an appropriate Kafka producer value serializer). When this configuration is being used, the outbound message marshalling is not based on thecontentTypeof the binding. When native encoding is used, it is the responsibility of the consumer to use an appropriate decoder (for example, the Kafka consumer value de-serializer) to deserialize the inbound message. Also, when native encoding and decoding is used, theheaderMode=embeddedHeadersproperty is ignored and headers are not embedded in the message. See the consumer propertyuseNativeDecoding.Default:
false. - errorChannelEnabled
-
When set to true, if the binder supports asynchroous send results, send failures are sent to an error channel for the destination. See Error Handling for more information.
Default: false.
Content Type Negotiation
Data transformation is one of the core features of any message-driven microservice architecture. Given that, in Spring Cloud Stream, such data
is represented as a Spring Message, a message may have to be transformed to a desired shape or size before reaching its destination. This is required for two reasons:
-
To convert the contents of the incoming message to match the signature of the application-provided handler.
-
To convert the contents of the outgoing message to the wire format.
The wire format is typically byte[] (that is true for the Kafka and Rabbit binders), but it is governed by the binder implementation.
In Spring Cloud Stream, message transformation is accomplished with an org.springframework.messaging.converter.MessageConverter.
| As a supplement to the details to follow, you may also want to read the following blog post. |
Mechanics
To better understand the mechanics and the necessity behind content-type negotiation, we take a look at a very simple use case by using the following message handler as an example:
public Function<Person, Person> personFunction {..}| For simplicity, we assume that this is the only handler function in the application (we assume there is no internal pipeline). |
The handler shown in the preceding example expects a Person object as an argument and produces a String type as an output.
In order for the framework to succeed in passing the incoming Message as an argument to this handler, it has to somehow transform the payload of the Message type from the wire format to a Person type.
In other words, the framework must locate and apply the appropriate MessageConverter.
To accomplish that, the framework needs some instructions from the user.
One of these instructions is already provided by the signature of the handler method itself (Person type).
Consequently, in theory, that should be (and, in some cases, is) enough.
However, for the majority of use cases, in order to select the appropriate MessageConverter, the framework needs an additional piece of information.
That missing piece is contentType.
Spring Cloud Stream provides three mechanisms to define contentType (in order of precedence):
-
HEADER: The
contentTypecan be communicated through the Message itself. By providing acontentTypeheader, you declare the content type to use to locate and apply the appropriateMessageConverter. -
BINDING: The
contentTypecan be set per destination binding by setting thespring.cloud.stream.bindings.input.content-typeproperty.The inputsegment in the property name corresponds to the actual name of the destination (which is “input” in our case). This approach lets you declare, on a per-binding basis, the content type to use to locate and apply the appropriateMessageConverter. -
DEFAULT: If
contentTypeis not present in theMessageheader or the binding, the defaultapplication/jsoncontent type is used to locate and apply the appropriateMessageConverter.
As mentioned earlier, the preceding list also demonstrates the order of precedence in case of a tie. For example, a header-provided content type takes precedence over any other content type. The same applies for a content type set on a per-binding basis, which essentially lets you override the default content type. However, it also provides a sensible default (which was determined from community feedback).
Another reason for making application/json the default stems from the interoperability requirements driven by distributed microservices architectures, where producer and consumer not only run in different JVMs but can also run on different non-JVM platforms.
When the non-void handler method returns, if the return value is already a Message, that Message becomes the payload. However, when the return value is not a Message, the new Message is constructed with the return value as the payload while inheriting
headers from the input Message minus the headers defined or filtered by SpringIntegrationProperties.messageHandlerNotPropagatedHeaders.
By default, there is only one header set there: contentType. This means that the new Message does not have contentType header set, thus ensuring that the contentType can evolve.
You can always opt out of returning a Message from the handler method where you can inject any header you wish.
If there is an internal pipeline, the Message is sent to the next handler by going through the same process of conversion. However, if there is no internal pipeline or you have reached the end of it, the Message is sent back to the output destination.
Content Type versus Argument Type
As mentioned earlier, for the framework to select the appropriate MessageConverter, it requires argument type and, optionally, content type information.
The logic for selecting the appropriate MessageConverter resides with the argument resolvers (HandlerMethodArgumentResolvers), which trigger right before the invocation of the user-defined handler method (which is when the actual argument type is known to the framework).
If the argument type does not match the type of the current payload, the framework delegates to the stack of the
pre-configured MessageConverters to see if any one of them can convert the payload.
As you can see, the Object fromMessage(Message<?> message, Class<?> targetClass);
operation of the MessageConverter takes targetClass as one of its arguments.
The framework also ensures that the provided Message always contains a contentType header.
When no contentType header was already present, it injects either the per-binding contentType header or the default contentType header.
The combination of contentType argument type is the mechanism by which framework determines if message can be converted to a target type.
If no appropriate MessageConverter is found, an exception is thrown, which you can handle by adding a custom MessageConverter (see User-defined Message Converters).
But what if the payload type matches the target type declared by the handler method? In this case, there is nothing to convert, and the
payload is passed unmodified. While this sounds pretty straightforward and logical, keep in mind handler methods that take a Message<?> or Object as an argument.
By declaring the target type to be Object (which is an instanceof everything in Java), you essentially forfeit the conversion process.
Do not expect Message to be converted into some other type based only on the contentType.
Remember that the contentType is complementary to the target type.
If you wish, you can provide a hint, which MessageConverter may or may not take into consideration.
|
Message Converters
MessageConverters define two methods:
Object fromMessage(Message<?> message, Class<?> targetClass);
Message<?> toMessage(Object payload, @Nullable MessageHeaders headers);It is important to understand the contract of these methods and their usage, specifically in the context of Spring Cloud Stream.
The fromMessage method converts an incoming Message to an argument type.
The payload of the Message could be any type, and it is
up to the actual implementation of the MessageConverter to support multiple types.
For example, some JSON converter may support the payload type as byte[], String, and others.
This is important when the application contains an internal pipeline (that is, input → handler1 → handler2 →. . . → output) and the output of the upstream handler results in a Message which may not be in the initial wire format.
However, the toMessage method has a more strict contract and must always convert Message to the wire format: byte[].
So, for all intents and purposes (and especially when implementing your own converter) you regard the two methods as having the following signatures:
Object fromMessage(Message<?> message, Class<?> targetClass);
Message<byte[]> toMessage(Object payload, @Nullable MessageHeaders headers);Provided MessageConverters
As mentioned earlier, the framework already provides a stack of MessageConverters to handle most common use cases.
The following list describes the provided MessageConverters, in order of precedence (the first MessageConverter that works is used):
-
ApplicationJsonMessageMarshallingConverter: Variation of theorg.springframework.messaging.converter.MappingJackson2MessageConverter. Supports conversion of the payload of theMessageto/from POJO for cases whencontentTypeisapplication/json(DEFAULT). -
ByteArrayMessageConverter: Supports conversion of the payload of theMessagefrombyte[]tobyte[]for cases whencontentTypeisapplication/octet-stream. It is essentially a pass through and exists primarily for backward compatibility. -
ObjectStringMessageConverter: Supports conversion of any type to aStringwhencontentTypeistext/plain. It invokes Object’stoString()method or, if the payload isbyte[], a newString(byte[]). -
JsonUnmarshallingConverter: Similar to theApplicationJsonMessageMarshallingConverter. It supports conversion of any type whencontentTypeisapplication/x-java-object. It expects the actual type information to be embedded in thecontentTypeas an attribute (for example,application/x-java-object;type=foo.bar.Cat).
When no appropriate converter is found, the framework throws an exception. When that happens, you should check your code and configuration and ensure you did not miss anything (that is, ensure that you provided a contentType by using a binding or a header).
However, most likely, you found some uncommon case (such as a custom contentType perhaps) and the current stack of provided MessageConverters
does not know how to convert. If that is the case, you can add custom MessageConverter. See User-defined Message Converters.
User-defined Message Converters
Spring Cloud Stream exposes a mechanism to define and register additional MessageConverters.
To use it, implement org.springframework.messaging.converter.MessageConverter, configure it as a @Bean.
It is then appended to the existing stack of `MessageConverter`s.
It is important to understand that custom MessageConverter implementations are added to the head of the existing stack.
Consequently, custom MessageConverter implementations take precedence over the existing ones, which lets you override as well as add to the existing converters.
|
The following example shows how to create a message converter bean to support a new content type called application/bar:
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter customMessageConverter() {
return new MyCustomMessageConverter();
}
}
public class MyCustomMessageConverter extends AbstractMessageConverter {
public MyCustomMessageConverter() {
super(new MimeType("application", "bar"));
}
@Override
protected boolean supports(Class<?> clazz) {
return (Bar.class.equals(clazz));
}
@Override
protected Object convertFromInternal(Message<?> message, Class<?> targetClass, Object conversionHint) {
Object payload = message.getPayload();
return (payload instanceof Bar ? payload : new Bar((byte[]) payload));
}
}Spring Cloud Stream also provides support for Avro-based converters and schema evolution.
See [schema-evolution] for details.
[ == Inter-Application Communication
Spring Cloud Stream enables communication between applications. Inter-application communication is a complex issue spanning several concerns, as described in the following topics:
Connecting Multiple Application Instances
While Spring Cloud Stream makes it easy for individual Spring Boot applications to connect to messaging systems, the typical scenario for Spring Cloud Stream is the creation of multi-application pipelines, where microservice applications send data to each other. You can achieve this scenario by correlating the input and output destinations of “adjacent” applications.
Suppose a design calls for the Time Source application to send data to the Log Sink application. You could use a common destination named ticktock for bindings within both applications.
Time Source (that has the binding named output) would set the following property:
spring.cloud.stream.bindings.output.destination=ticktock
Log Sink (that has the binding named input) would set the following property:
spring.cloud.stream.bindings.input.destination=ticktock
Instance Index and Instance Count
When scaling up Spring Cloud Stream applications, each instance can receive information about how many other instances of the same application exist and what its own instance index is.
Spring Cloud Stream does this through the spring.cloud.stream.instanceCount and spring.cloud.stream.instanceIndex properties.
For example, if there are three instances of a HDFS sink application, all three instances have spring.cloud.stream.instanceCount set to 3, and the individual applications have spring.cloud.stream.instanceIndex set to 0, 1, and 2, respectively.
When Spring Cloud Stream applications are deployed through Spring Cloud Data Flow, these properties are configured automatically; when Spring Cloud Stream applications are launched independently, these properties must be set correctly.
By default, spring.cloud.stream.instanceCount is 1, and spring.cloud.stream.instanceIndex is 0.
In a scaled-up scenario, correct configuration of these two properties is important for addressing partitioning behavior (see below) in general, and the two properties are always required by certain binders (for example, the Kafka binder) in order to ensure that data are split correctly across multiple consumer instances.
Partitioning
Partitioning in Spring Cloud Stream consists of two tasks:
Configuring Output Bindings for Partitioning
You can configure an output binding to send partitioned data by setting one and only one of its partitionKeyExpression or partitionKeyExtractorName properties, as well as its partitionCount property.
For example, the following is a valid and typical configuration:
spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=payload.id spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
Based on that example configuration, data is sent to the target partition by using the following logic.
A partition key’s value is calculated for each message sent to a partitioned output binding based on the partitionKeyExpression.
The partitionKeyExpression is a SpEL expression that is evaluated against the outbound message for extracting the partitioning key.
If a SpEL expression is not sufficient for your needs, you can instead calculate the partition key value by providing an implementation of org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy and configuring it as a bean (by using the @Bean annotation).
If you have more then one bean of type org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy available in the Application Context, you can further filter it by specifying its name with the partitionKeyExtractorName property, as shown in the following example:
--spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExtractorName=customPartitionKeyExtractor
--spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
. . .
@Bean
public CustomPartitionKeyExtractorClass customPartitionKeyExtractor() {
return new CustomPartitionKeyExtractorClass();
}
In previous versions of Spring Cloud Stream, you could specify the implementation of org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy by setting the spring.cloud.stream.bindings.output.producer.partitionKeyExtractorClass property.
Since version 3.0, this property is removed.
|
Once the message key is calculated, the partition selection process determines the target partition as a value between 0 and partitionCount - 1.
The default calculation, applicable in most scenarios, is based on the following formula: key.hashCode() % partitionCount.
This can be customized on the binding, either by setting a SpEL expression to be evaluated against the 'key' (through the partitionSelectorExpression property) or by configuring an implementation of org.springframework.cloud.stream.binder.PartitionSelectorStrategy as a bean (by using the @Bean annotation).
Similar to the PartitionKeyExtractorStrategy, you can further filter it by using the spring.cloud.stream.bindings.output.producer.partitionSelectorName property when more than one bean of this type is available in the Application Context, as shown in the following example:
--spring.cloud.stream.bindings.func-out-0.producer.partitionSelectorName=customPartitionSelector
. . .
@Bean
public CustomPartitionSelectorClass customPartitionSelector() {
return new CustomPartitionSelectorClass();
}
In previous versions of Spring Cloud Stream you could specify the implementation of org.springframework.cloud.stream.binder.PartitionSelectorStrategy by setting the spring.cloud.stream.bindings.output.producer.partitionSelectorClass property.
Since version 3.0, this property is removed.
|
Configuring Input Bindings for Partitioning
An input binding (with the binding name uppercase-in-0) is configured to receive partitioned data by setting its partitioned
property, as well as the instanceIndex and instanceCount properties on the application itself, as shown in the following example:
spring.cloud.stream.bindings.uppercase-in-0.consumer.partitioned=true spring.cloud.stream.instanceIndex=3 spring.cloud.stream.instanceCount=5
The instanceCount value represents the total number of application instances between which the data should be partitioned.
The instanceIndex must be a unique value across the multiple instances, with a value between 0 and instanceCount - 1.
The instance index helps each application instance to identify the unique partition(s) from which it receives data.
It is required by binders using technology that does not support partitioning natively.
For example, with RabbitMQ, there is a queue for each partition, with the queue name containing the instance index.
With Kafka, if autoRebalanceEnabled is true (default), Kafka takes care of distributing partitions across instances, and these properties are not required.
If autoRebalanceEnabled is set to false, the instanceCount and instanceIndex are used by the binder to determine which partition(s) the instance subscribes to (you must have at least as many partitions as there are instances).
The binder allocates the partitions instead of Kafka.
This might be useful if you want messages for a particular partition to always go to the same instance.
When a binder configuration requires them, it is important to set both values correctly in order to ensure that all of the data is consumed and that the application instances receive mutually exclusive datasets.
While a scenario in which using multiple instances for partitioned data processing may be complex to set up in a standalone case, Spring Cloud Dataflow can simplify the process significantly by populating both the input and output values correctly and by letting you rely on the runtime infrastructure to provide information about the instance index and instance count.
Testing
Spring Cloud Stream provides support for testing your microservice applications without connecting to a messaging system.
Spring Integration Test Binder
The old test binder defined in spring-cloud-stream-test-support module was specifically designed to facilitate unit testing of the actual messaging components and thus bypasses some of the core functionality of the binder API.
While such light-weight approach is sufficient for a lot of cases, it usually requires additional integration testing with real binders (e.g., Rabbit, Kafka etc). So we are effectively deprecating it.
To begin bridging the gap between unit and integration testing we’ve developed a new test binder which uses Spring Integration framework as an in-JVM Message Broker essentially giving you the best of both worlds - a real binder without the networking.
Test Binder configuration
To enable Spring Integration Test Binder all you need is:
-
Add required dependencies
-
Remove the dependency for
spring-cloud-stream-test-support
Add required dependencies
Below is the example of the required Maven POM entries.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
<version>${spring.cloud.stream.version}</version>
<type>test-jar</type>
<scope>test</scope>
<classifier>test-binder</classifier>
</dependency>Or for build.gradle.kts
testImplementation("org.springframework.cloud:spring-cloud-stream") {
artifact {
name = "spring-cloud-stream"
extension = "jar"
type ="test-jar"
classifier = "test-binder"
}
}Test Binder usage
Now you can test your microservice as a simple unit test
@SpringBootTest
@RunWith(SpringRunner.class)
public class SampleStreamTests {
@Autowired
private InputDestination input;
@Autowired
private OutputDestination output;
@Test
public void testEmptyConfiguration() {
this.input.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(output.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
@SpringBootApplication
@Import(TestChannelBinderConfiguration.class)
public static class SampleConfiguration {
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
}
}And if you need more control or want to test several configurations in the same test suite you can also do the following:
@EnableAutoConfiguration
public static class MyTestConfiguration {
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
}
. . .
@Test
public void sampleTest() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
MyTestConfiguration.class))
.run("--spring.cloud.function.definition=uppercase")) {
InputDestination source = context.getBean(InputDestination.class);
OutputDestination target = context.getBean(OutputDestination.class);
source.send(new GenericMessage<byte[]>("hello".getBytes()));
assertThat(target.receive().getPayload()).isEqualTo("HELLO".getBytes());
}
}For cases where you have multiple bindings and/or multiple inputs and outputs, or simply want to be explicit about names of
the destination you are sending to or receiving from, the send() and receive()
methods of InputDestination and OutputDestination are overridden to allow you to provide the name of the input and output destination.
Consider the following sample:
@EnableAutoConfiguration
public static class SampleFunctionConfiguration {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
@Bean
public Function<String, String> reverse() {
return value -> new StringBuilder(value).reverse().toString();
}
}and the actual test
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleFunctionConfiguration.class))
.run("--spring.cloud.function.definition=uppercase;reverse")) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "uppercase-in-0");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "uppercase-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}For cases where you have additional mapping properties such as destination you should use those names. For example, consider a different version of the
preceding test where we explicitly map inputs and outputs of the uppercase function to myInput and myOutput binding names:
@Test
public void testMultipleFunctions() {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
TestChannelBinderConfiguration.getCompleteConfiguration(
SampleFunctionConfiguration.class))
.run(
"--spring.cloud.function.definition=uppercase;reverse",
"--spring.cloud.stream.bindings.uppercase-in-0.destination=myInput",
"--spring.cloud.stream.bindings.uppercase-out-0.destination=myOutput"
)) {
InputDestination inputDestination = context.getBean(InputDestination.class);
OutputDestination outputDestination = context.getBean(OutputDestination.class);
Message<byte[]> inputMessage = MessageBuilder.withPayload("Hello".getBytes()).build();
inputDestination.send(inputMessage, "myInput");
inputDestination.send(inputMessage, "reverse-in-0");
Message<byte[]> outputMessage = outputDestination.receive(0, "myOutput");
assertThat(outputMessage.getPayload()).isEqualTo("HELLO".getBytes());
outputMessage = outputDestination.receive(0, "reverse-out-0");
assertThat(outputMessage.getPayload()).isEqualTo("olleH".getBytes());
}
}Test Binder and PollableMessageSource
Spring Integration Test Binder also allows you to write tests when working with PollableMessageSource (see Using Polled Consumers for more details).
The important thing that needs to be understood though is that polling is not event-driven, and that PollableMessageSource is a strategy which exposes operation to produce (poll for) a Message (singular).
How often you poll or how many threads you use or where you’re polling from (message queue or file system) is entirely up to you;
In other words it is your responsibility to configure Poller or Threads or the actual source of Message. Luckily Spring has plenty of abstractions to configure exactly that.
Let’s look at the example:
@Test
public void samplePollingTest() {
ApplicationContext context = new SpringApplicationBuilder(SamplePolledConfiguration.class)
.web(WebApplicationType.NONE)
.run("--spring.jmx.enabled=false", "--spring.cloud.stream.pollable-source=myDestination");
OutputDestination destination = context.getBean(OutputDestination.class);
System.out.println("Message 1: " + new String(destination.receive().getPayload()));
System.out.println("Message 2: " + new String(destination.receive().getPayload()));
System.out.println("Message 3: " + new String(destination.receive().getPayload()));
}
@Import(TestChannelBinderConfiguration.class)
@EnableAutoConfiguration
public static class SamplePolledConfiguration {
@Bean
public ApplicationRunner poller(PollableMessageSource polledMessageSource, StreamBridge output, TaskExecutor taskScheduler) {
return args -> {
taskScheduler.execute(() -> {
for (int i = 0; i < 3; i++) {
try {
if (!polledMessageSource.poll(m -> {
String newPayload = ((String) m.getPayload()).toUpperCase();
output.send("myOutput", newPayload);
})) {
Thread.sleep(2000);
}
}
catch (Exception e) {
// handle failure
}
}
});
};
}
}The above (very rudimentary) example will produce 3 messages in 2 second intervals sending them to the output destination of Source
which this binder sends to OutputDestination where we retrieve them (for any assertions).
Currently, it prints the following:
Message 1: POLLED DATA
Message 2: POLLED DATA
Message 3: POLLED DATAAs you can see the data is the same. That is because this binder defines a default implementation of the actual MessageSource - the source
from which the Messages are polled using poll() operation. While sufficient for most testing scenarios, there are cases where you may want
to define your own MessageSource. To do so simply configure a bean of type MessageSource in your test configuration providing your own
implementation of Message sourcing.
Here is the example:
@Bean
public MessageSource<?> source() {
return () -> new GenericMessage<>("My Own Data " + UUID.randomUUID());
}rendering the following output;
Message 1: MY OWN DATA 1C180A91-E79F-494F-ABF4-BA3F993710DA
Message 2: MY OWN DATA D8F3A477-5547-41B4-9434-E69DA7616FEE
Message 3: MY OWN DATA 20BF2E64-7FF4-4CB6-A823-4053D30B5C74
DO NOT name this bean messageSource as it is going to be in conflict with the bean of the same name (different type)
provided by Spring Boot for unrelated reasons.
|
Health Indicator
Spring Cloud Stream provides a health indicator for binders.
It is registered under the name binders and can be enabled or disabled by setting the management.health.binders.enabled property.
To enable health check you first need to enable both "web" and "actuator" by including its dependencies (see Binding visualization and control)
If management.health.binders.enabled is not set explicitly by the application, then management.health.defaults.enabled is matched as true and the binder health indicators are enabled.
If you want to disable health indicator completely, then you have to set management.health.binders.enabled to false.
You can use Spring Boot actuator health endpoint to access the health indicator - /actuator/health.
By default, you will only receive the top level application status when you hit the above endpoint.
In order to receive the full details from the binder specific health indicators, you need to include the property management.endpoint.health.show-details with the value ALWAYS in your application.
Health indicators are binder-specific and certain binder implementations may not necessarily provide a health indicator.
If you want to completely disable all health indicators available out of the box and instead provide your own health indicators,
you can do so by setting property management.health.binders.enabled to false and then provide your own HealthIndicator beans in your application.
In this case, the health indicator infrastructure from Spring Boot will still pick up these custom beans.
Even if you are not disabling the binder health indicators, you can still enhance the health checks by providing your own HealthIndicator beans in addition to the out of the box health checks.
When you have multiple binders in the same application, health indicators are enabled by default unless the application turns them off by setting management.health.binders.enabled to false.
In this case, if the user wants to disable health check for a subset of the binders, then that should be done by setting management.health.binders.enabled to false in the multi binder configurations’s environment.
See Connecting to Multiple Systems for details on how environment specific properties can be provided.
If there are multiple binders present in the classpath but not all of them are used in the application, this may cause some issues in the context of health indicators.
There may be implementation specific details as to how the health checks are performed. For example, a Kafka binder may decide the status as DOWN if there are no destinations registered by the binder.
Lets take a concrete situation. Imagine you have both Kafka and Kafka Streams binders present in the classpath, but only use the Kafka Streams binder in the application code, i.e. only provide bindings using the Kafka Streams binder.
Since Kafka binder is not used and it has specific checks to see if any destinations are registered, the binder health check will fail.
The top level application health check status will be reported as DOWN.
In this situation, you can simply remove the dependency for kafka binder from your application since you are not using it.
Samples
For Spring Cloud Stream samples, see the spring-cloud-stream-samples repository on GitHub.
Deploying Stream Applications on CloudFoundry
On CloudFoundry, services are usually exposed through a special environment variable called VCAP_SERVICES.
When configuring your binder connections, you can use the values from an environment variable as explained on the dataflow Cloud Foundry Server docs.
Binder Implementations
The following is the list of available binder implementations
As it was mentioned earlier Binder abstraction is also one of the extension points of the framework. So if you can’t find a suitable binder in the preceding list you can implement your own binder on top of Spring Cloud Stream.
In the How to create a Spring Cloud Stream Binder from scratch post a community member documents
in details, with an example, a set of steps necessary to implement a custom binder.
The steps are also highlighted in the Implementing Custom Binders section.