Spring Cloud Stream provides support for schema-based message converters through its spring-cloud-stream-schema module.
Currently, the only serialization format supported out of the box for schema-based message converters is Apache Avro, with more formats to be added in future versions.
The spring-cloud-stream-schema module contains two types of message converters that can be used for Apache Avro serialization:
- converters using the class information of the serialized/deserialized objects, or a schema with a location known at startup;
- converters using a schema registry - they locate the schemas at runtime, as well as dynamically registering new schemas as domain objects evolve.
The AvroSchemaMessageConverter supports serializing and deserializing messages either using a predefined schema or by using the schema information available in the class (either reflectively, or contained in the SpecificRecord).
If the target type of the conversion is a GenericRecord, then a schema must be set.
For using it, you can simply add it to the application context, optionally specifying one ore more MimeTypes to associate it with.
The default MimeType is application/avro.
Here is an example of configuring it in a sink application registering the Apache Avro MessageConverter, without a predefined schema:
@EnableBinding(Sink.class) @SpringBootApplication public static class SinkApplication { ... @Bean public MessageConverter userMessageConverter() { return new AvroSchemaMessageConverter(MimeType.valueOf("avro/bytes")); } }
Conversely, here is an application that registers a converter with a predefined schema, to be found on the classpath:
@EnableBinding(Sink.class) @SpringBootApplication public static class SinkApplication { ... @Bean public MessageConverter userMessageConverter() { AvroSchemaMessageConverter converter = new AvroSchemaMessageConverter(MimeType.valueOf("avro/bytes")); converter.setSchemaLocation(new ClassPathResource("schemas/User.avro")); return converter; } }
In order to understand the schema registry client converter, we will describe the schema registry support first.
Most serialization models, especially the ones that aim for portability across different platforms and languages, rely on a schema that describes how the data is serialized in the binary payload. In order to serialize the data and then to interpret it, both the sending and receiving sides must have access to a schema that describes the binary format. In certain cases, the schema can be inferred from the payload type on serialization, or from the target type on deserialization, but in a lot of cases applications benefit from having access to an explicit schema that describes the binary data format. A schema registry allows you to store schema information in a textual format (typically JSON) and makes that information accessible to various applications that need it to receive and send data in binary format. A schema is referenceable as a tuple consisting of:
- a subject that is the logical name of the schema;
- the schema version;
- the schema format which describes the binary format of the data.
Spring Cloud Stream provides a schema registry server implementation.
In order to use it, you can simply add the spring-cloud-stream-schema-server artifact to your project and use the @EnableSchemaRegistryServer annotation, adding the schema registry server REST controller to your application.
This annotation is intended to be used with Spring Boot web applications, and the listening port of the server is controlled by the server.port setting.
The spring.cloud.stream.schema.server.path setting can be used to control the root path of the schema server (especially when it is embedded in other applications).
The spring.cloud.stream.schema.server.allowSchemaDeletion boolean setting enables the deletion of schema. By default this is disabled.
The schema registry server uses a relational database to store the schemas. By default, it uses an embedded database. You can customize the schema storage using the Spring Boot SQL database and JDBC configuration options.
A Spring Boot application enabling the schema registry looks as follows:
@SpringBootApplication @EnableSchemaRegistryServer public class SchemaRegistryServerApplication { public static void main(String[] args) { SpringApplication.run(SchemaRegistryServerApplication.class, args); } }
The Schema Registry Server API consists of the following operations:
Register a new schema.
Accepts JSON payload with the following fields:
subjectthe schema subject;formatthe schema format;definitionthe schema definition.
Response is a schema object in JSON format, with the following fields:
idthe schema id;subjectthe schema subject;formatthe schema format;versionthe schema version;definitionthe schema definition.
Retrieve an existing schema by its subject, format and version.
Response is a schema object in JSON format, with the following fields:
idthe schema id;subjectthe schema subject;formatthe schema format;versionthe schema version;definitionthe schema definition.
Retrieve a list of existing schema by its subject and format.
Response is a list of schemas with each schema object in JSON format, with the following fields:
idthe schema id;subjectthe schema subject;formatthe schema format;versionthe schema version;definitionthe schema definition.
Retrieve an existing schema by its id.
Response is a schema object in JSON format, with the following fields:
idthe schema id;subjectthe schema subject;formatthe schema format;versionthe schema version;definitionthe schema definition.
Delete existing schemas by their subject.
![[Note]](images/note.png) | Note |
|---|---|
This note applies to users of Spring Cloud Stream 1.1.0.RELEASE only.
Spring Cloud Stream 1.1.0.RELEASE used the table name |
The client-side abstraction for interacting with schema registry servers is the SchemaRegistryClient interface, with the following structure:
public interface SchemaRegistryClient { SchemaRegistrationResponse register(String subject, String format, String schema); String fetch(SchemaReference schemaReference); String fetch(Integer id); }
Spring Cloud Stream provides out of the box implementations for interacting with its own schema server, as well as for interacting with the Confluent Schema Registry.
A client for the Spring Cloud Stream schema registry can be configured using the @EnableSchemaRegistryClient as follows:
@EnableBinding(Sink.class) @SpringBootApplication @EnableSchemaRegistryClient public static class AvroSinkApplication { ... }
| Note |
|---|---|
The default converter is optimized to cache not only the schemas from the remote server but also the |
The Schema Registry Client supports the following properties:
- spring.cloud.stream.schemaRegistryClient.endpoint
- The location of the schema-server.
Use a full URL when setting this, including protocol (
httporhttps) , port and context path. - Default
localhost:8990/- spring.cloud.stream.schemaRegistryClient.cached
- Whether the client should cache schema server responses.
Normally set to
false, as the caching happens iin the message converter. Clients using the schema registry client should set this totrue. - Default
true
For Spring Boot applications that have a SchemaRegistryClient bean registered with the application context, Spring Cloud Stream will auto-configure an Apache Avro message converter that uses the schema registry client for schema management.
This eases schema evolution, as applications that receive messages can get easy access to a writer schema that can be reconciled with their own reader schema.
For outbound messages, the MessageConverter will be activated if the content type of the channel is set to application/*+avro, e.g.:
spring.cloud.stream.bindings.output.contentType=application/*+avroDuring the outbound conversion, the message converter will try to infer the schemas of the outbound messages based on their type and register them to a subject based on the payload type using the SchemaRegistryClient.
If an identical schema is already found, then a reference to it will be retrieved.
If not, the schema will be registered and a new version number will be provided.
The message will be sent with a contentType header using the scheme application/[prefix].[subject].v[version]+avro, where prefix is configurable and subject is deduced from the payload type.
For example, a message of the type User may be sent as a binary payload with a content type of application/vnd.user.v2+avro, where user is the subject and 2 is the version number.
When receiving messages, the converter will infer the schema reference from the header of the incoming message and will try to retrieve it. The schema will be used as the writer schema in the deserialization process.
If you have enabled Avro based schema registry client by setting spring.cloud.stream.bindings.output.contentType=application/*+avro you can customize the behavior of the registration with the following properties.
- spring.cloud.stream.schema.avro.dynamicSchemaGenerationEnabled
- Enable if you want the converter to use reflection to infer a Schema from a POJO.
- Default
false- spring.cloud.stream.schema.avro.readerSchema
- Avro compares schema versions by looking at a writer schema (origin payload) and a reader schema (your application payload), check Avro documentation for more information. If set, this overrides any lookups at the schema server and uses the local schema as the reader schema.
- Default
null- spring.cloud.stream.schema.avro.schemaLocations
- Register any
.avscfiles listed in this property with the Schema Server. - Default
empty- spring.cloud.stream.schema.avro.prefix
- The prefix to be used on the Content-Type header.
- Default
vnd
To better understand how Spring Cloud Stream registers and resolves new schemas, as well as its use of Avro schema comparison features, we will provide two separate subsections below: one for the registration, and one for the resolution of schemas.
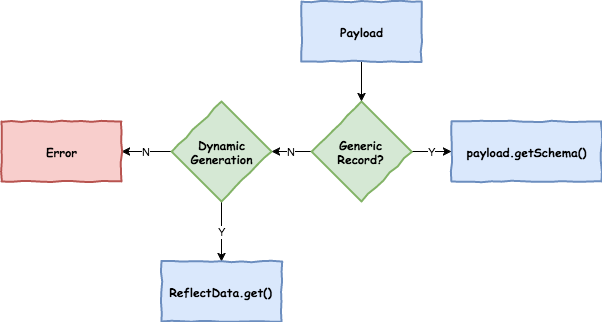
The first part of the registration process is extracting a schema from the payload that is being sent over a channel.
Avro types such as SpecificRecord or GenericRecord already contain a schema, which can be retrieved immediately from the instance.
In the case of POJOs a schema will be inferred if the property spring.cloud.stream.schema.avro.dynamicSchemaGenerationEnabled is set to true (the default).
Once a schema is obtained, the converter will then load its metadata (version) from the remote server. First it queries a local cache, and if not found it then submits the data to the server that will reply with versioning information. The converter will always cache the results to avoid the overhead of querying the Schema Server for every new message that needs to be serialized.
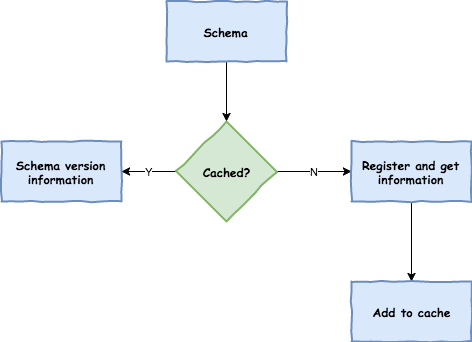
With the schema version information, the converter sets the contentType header of the message to carry the version information such as application/vnd.user.v1+avro
When reading messages that contain version information (i.e. a contentType header with a scheme like above), the converter will query the Schema server to fetch the writer schema of the message.
Once it has found the correct schema of the incoming message, it then retrieves the reader schema and using Avro’s schema resolution support reads it into the reader definition (setting defaults and missing properties).
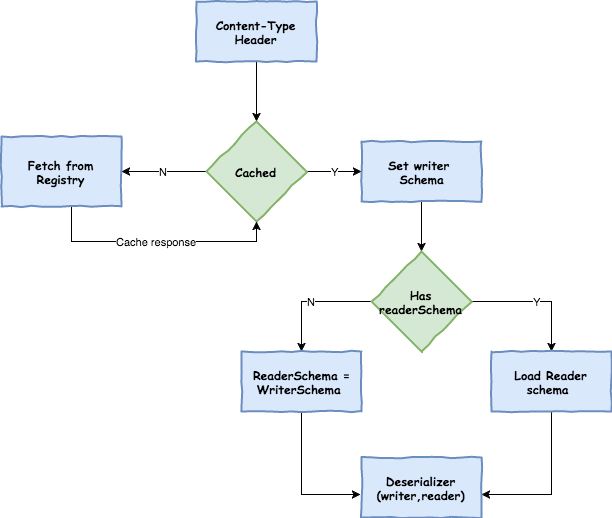
| Note |
|---|---|
It’s important to understand the difference between a writer schema (the application that wrote the message) and a reader schema (the receiving application). Please take a moment to read the Avro terminology and understand the process. Spring Cloud Stream will always fetch the writer schema to determine how to read a message. If you want to get Avro’s schema evolution support working you need to make sure that a readerSchema was properly set for your application. |