Please read the sample prerequistes before following these instructions.
This sample demonstrates how to execute the wordcount example in the
context of a Spring Batch application. It serves as a starting point that
will be expanded upon in other samples. The sample code is located in the
distribution directory
<spring-hadoop-install-dir>/samples/batch-wordcount
The sample uses the Spring for Apache Hadoop namespace to define a Spring Batch Tasklet that runs a Hadoop job. A Spring Batch Job (not to be confused with a Hadoop job) combines multiple steps together to create a flow of execution, a small workflow. Each step in the flow does some processing which can be as complex or as simple as your require. The configuration of the flow from one step to another can very simple, a linear sequence of steps, or complex using conditional and programmatic branching as well as sequential and parallel step execution. A Spring Batch Tasklet is the abstraction that represents the processing for a Step and is an extensible part of Spring Batch. You can write your own implementation of a Tasklet to perform arbitrary processing, but often you configure existing Tasklets provided by Spring Batch and Spring Hadoop.
Spring Batch provides Tasklets for reading, writing, and processing data from flat files, databases, messaging systems and executing system (shell) commands. Spring for Apache Hadoop provides Tasklets for running Hadoop MapReduce, Streaming, Hive, and Pig jobs as well as executing script files that have build in support for ease of use interaction with HDFS.
The part of the configuration file that defines the Spring Batch Job
flow is shown below and can be found in the file
wordcount-context.xml. The elements
<batch:job/>, <batch:step/>,
<batch:tasklet> come from the XML Schema for Spring
Batch
<batch:job id="job1"> <batch:step id="import" next="wordcount"> <batch:tasklet ref="script-tasklet"/> </batch:step> <batch:step id="wordcount"> <batch:tasklet ref="wordcount-tasklet" /> </batch:step> </batch:job>
This configuration defines a Spring Batch Job named "job1" that contains two steps executed sequentially. The first one prepares HDFS with sample data and the second runs the Hadoop wordcount mapreduce job. The tasklet's reference to "script-tasklet" and "wordcount-tasklet" definitions that will be shown a little later.
The Spring Source Toolsuite is a free Eclipse-powered development environment which provides a nice visualization and authoring help for Spring Batch workflows as shown below.
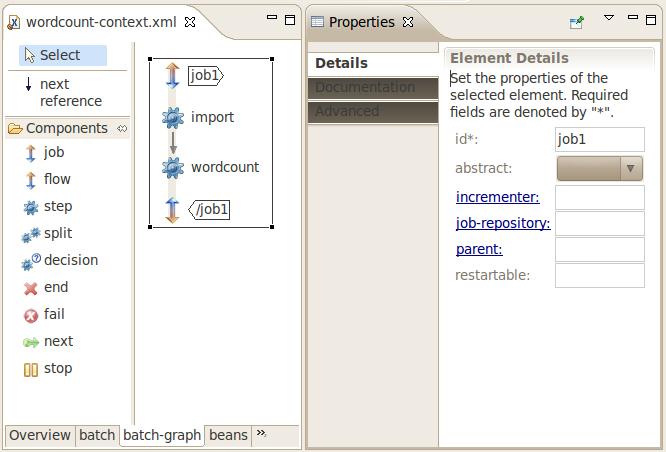
The script tasklet shown below uses Groovy to remove any data that is in the input or output directories and puts the file "nietzsche-chapter-1.txt" into HDFS.
<script-tasklet id="script-tasklet"> <script language="groovy"> inputPath = "${wordcount.input.path:/user/gutenberg/input/word/}" outputPath = "${wordcount.output.path:/user/gutenberg/output/word/}" if (fsh.test(inputPath)) { fsh.rmr(inputPath) } if (fsh.test(outputPath)) { fsh.rmr(outputPath) } inputFile = "src/main/resources/data/nietzsche-chapter-1.txt" fsh.put(inputFile, inputPath) </script> </script-tasklet>
The script makes use of the predefined variable fsh, which is the
embedded Filesystem Shell that
Spring for Apache Hadoop provides. It also uses Spring's Property
Placeholder functionality so that the input and out paths can be
configured external to the application, for example using property files.
The syntax for variables recognized by Spring's Property Placeholder is
${key:defaultValue}, so in this case
/user/gutenberg/input/word and
/user/gutenberg/output/word are the default input and
output paths. Note you can also use Spring's
Expression Language to configure values in the script or in other
XML definitions.
The configuration of the tasklet to execute the Hadoop MapReduce jobs is shown below.
<hdp:tasklet id="hadoop-tasklet" job-ref="mr-job"/> <job id="wordcount-job" input-path="${wordcount.input.path:/user/gutenberg/input/word/}" output-path="${wordcount.output.path:/user/gutenberg/output/word/}" mapper="org.apache.hadoop.examples.WordCount.TokenizerMapper" reducer="org.apache.hadoop.examples.WordCount.IntSumReducer" />
The <hdp:tasklet> and
<hdp:job/> elements are from Spring Haddop XML
Schema. The hadoop tasklet is the bridge between the Spring Batch world
and the Hadoop world. The hadoop tasklet in turn refers to your map reduce
job. Various common properties of a map reduce job can be set, such as the
mapper and reducer. The section Creating a
Hadoop Job describes the additional elements you can configure in
the XML.
![[Note]](images/note.png) | Note |
|---|---|
|
If you look at the JavaDocs for the org.apache.hadoop.examples package (here), you can see the Mapper and Reducer class names for many examples you may have previously used from the hadoop command line runner. |
The configuration-ref element in the job
definition refers to common Hadoop configuration information that can be
shared across many jobs. It is defined in the file
hadoop-context.xml and is shown below
<!-- default id is 'hadoopConfiguration' --> <hdp:configuration register-url-handler="false"> fs.default.name=${hd.fs} </hdp:configuration>
As mentioned before, as this is a configuration file processed by
the Spring container, it supports variable substitution through the use of
${var} style variables. In this case the location for
HDFS is parameterized and no default value is provided. The property file
hadoop.properties contains the definition of the hd.fs
variable, change the value if you want to refer to a different name node
location.
hd.fs=hdfs://localhost:9000
The entire application is put together in the configuration file
launch-context.xml, shown below.
<!-- where to read externalized configuration values --> <context:property-placeholder location="classpath:batch.properties,classpath:hadoop.properties" ignore-resource-not-found="true" ignore-unresolvable="true" /> <!-- simple base configuration for batch components, e.g. JobRepository --> <import resource="classpath:/META-INF/spring/batch-common.xml" /> <!-- shared hadoop configuration --> <import resource="classpath:/META-INF/spring/hadoop-context.xml" /> <!-- word count workflow --> <import resource="classpath:/META-INF/spring/wordcount-context.xml" />
In the directory
<spring-hadoop-install-dir>/samples/batch-wordcount
build and run the sample
$ ../../gradlew
If this is the first time you are using gradlew, it will download the Gradle build tool and all necessary dependencies to run the sample.
| Note |
|---|---|
|
If you run into some issues, drop us a line in the Spring Forums. |
You can use Gradle to export all required dependencies into a directory and create a shell script to run the application. To do this execute the command
$ ../../gradlew installApp
This places the shell scripts and dependencies under the
build/install/batch-wordcount directory. You can zip up that
directory and share the application with others.
The main Java class used is part of Spring Batch. The class is
org.springframework.batch.core.launch.support.CommandLineJobRunner.
This main app requires you to specify at least a Spring configuration file
and a job instance name. You can read the CommandLineJobRunner JavaDocs
for more information as well as this
section in the reference docs for Spring Batch to find out more of
what command line options it supports.
$ ./build/install/wordcount/bin/wordcount classpath:/launch-context.xml job1
You can then verify the output from work count is present and cat it to the screen
$ hadoop dfs -ls /user/gutenberg/output/word Warning: $HADOOP_HOME is deprecated. Found 2 items -rw-r--r-- 3 mpollack supergroup 0 2012-01-31 19:29 /user/gutenberg/output/word/_SUCCESS -rw-r--r-- 3 mpollack supergroup 918472 2012-01-31 19:29 /user/gutenberg/output/word/part-r-00000 $ hadoop dfs -cat /user/gutenberg/output/word/part-r-00000 | more Warning: $HADOOP_HOME is deprecated. "'Spells 1 "'army' 1 "(1) 1 "(Lo)cra"1 "13 4 "1490 1 "1498," 1 "35" 1 "40," 1 "A 9 "AS-IS". 1 "AWAY 1 "A_ 1 "Abide 1 "About 1