There is considerable variability in the types of input and output formats in batch jobs. There are also a number of options to consider in terms of how the types of strategies that will be used to handle skips, recovery, and statistics. However, when approaching a new batch job there are a few standard questions to answer to help determine how the job will be written and how to use the services offered by the spring batch framework. Consider the following:
Here is a list of samples with checks to indicate which features each one demonstrates:
| Job / Feature | skip | retry | restart | automatic mapping | asynch launch | validation | delegation | write behind | non- sequential | asynch process | filtering |
| adhocLoop | x | ||||||||||
| beanWrapperMapperSample | x | ||||||||||
| compositeItemWriterSample | x | ||||||||||
| customerFilter | x | ||||||||||
| delegating | x | ||||||||||
| football | |||||||||||
| headerFooter | |||||||||||
| hibernate | x | x | |||||||||
| ioSample | x | x | |||||||||
| infiniteLoop | x | ||||||||||
| loopflow | x | ||||||||||
| multiline | x | ||||||||||
| multilineOrder | x | ||||||||||
| parallel | x | ||||||||||
| partition | x | ||||||||||
| quartz | x | ||||||||||
| restart | x | ||||||||||
| retry | x | ||||||||||
| skip | x | ||||||||||
| trade | x |
The ioSampleJob (ioSample) has a number of special instances that show different IO features using the same job configuration but with different readers and writers:
| Job / Feature | delimited input | fixed-length input | xml input | db paging input | db cursor input | delimited output | fixed-length output | xml output | db output | multiple files | multi-line | multi-record |
| delimited | x | x | ||||||||||
| fixedLength | x | x | ||||||||||
| ibatis | x | x | ||||||||||
| iohibernate | x | x | ||||||||||
| jdbcCursor | x | x | ||||||||||
| jpa | x | x | ||||||||||
| multiLine | x | x | ||||||||||
| multiRecordtype | x | x | ||||||||||
| multiResource | x | x | x | |||||||||
| xml | x | x |
The easiest way to launch a sample job in Spring Batch is to open up a unit test in your IDE and run it directly. Each sample has a separate test case in the org.springframework.batch.samples package. The name of the test case is [JobName]FunctionalTests.
You can also use the same Spring configuration as the unit test to launch the job via a main method in CommmandLineJobRunner. The samples source code has an Eclipse launch configuration to do this, taking the hassle out of setting up a classpath to run the job.
This job is simply an infinite loop. It runs forever so it is useful for testing features to do with stopping and starting jobs. It is used, for instance, as one of the jobs that can be run from JMX using the Eclipse launch configuration "jmxLauncher".
The JMX launcher uses an additional XML configuration file (adhoc-job-launcher-context.xml) to set up a JobOperator for running jobs asynchronously (i.e. in a background thread). This follows the same pattern as the Quartz sample, so see that section for more details of the JobLauncher configuration.
The rest of the configuration for this demo consists of exposing some components from the application context as JMX managed beans. The JobOperator is exposed so that it can be controlled from a remote client (such as JConsole from the JDK) which does not have Spring Batch on the classpath. See the Spring Core Reference Guide for more details on how to customise the JMX configuration.
The purpose of this sample is to show to usage of the JdbcCursorItemReader and the JdbcBatchItemWriter to make efficient updates to a database table.
The JdbcBatchItemWriter accepts a special form of PreparedStatementSetter as a (mandatory) dependency. This is responsible for copying fields from the item to be written to a PreparedStatement matching the SQL query that has been injected. The implementation of the CustomerCreditUpdatePreparedStatementSetter shows best practice of keeping all the information needed for the execution in one place, since it contains a static constant value (QUERY) which is used to configure the query for the writer.
This sample shows the use of automatic mapping from fields in a file to a domain object. The Trade and Person objects needed by the job are created from the Spring configuration using prototype beans, and then their properties are set using the BeanWrapperFieldSetMapper, which sets properties of the prototype according to the field names in the file.
Nested property paths are resolved in the same way as normal Spring binding occurs, but with a little extra leeway in terms of spelling and capitalisation. Thus for instance, the Trade object has a property called customer (lower case), but the file has been configured to have a column name CUSTOMER (upper case), and the mapper will accept the values happily. Underscores instead of camel-casing (e.g. CREDIT_CARD instead of creditCard) also work.
This shows a common use case using a composite pattern, composing instances of other framework readers or writers. It is also quite common for business-specific readers or writers to wrap off-the-shelf components in a similar way.
In this job the composite pattern is used just to make duplicate copies of the output data. The delegates for the CompositeItemWriter have to be separately registered as streams in the Step where they are used, in order for the step to be restartable. This is a common feature of all delegate patterns.
This shows the use of the ItemProcessor to filter out items by returning null. When an item is filtered it leads to an increment in the filterCount in the step execution.
This sample shows the delegate pattern again, and also the ItemReaderAdapter which is used to adapt a POJO to the ItemReader interface.
The goal is to demonstrate a typical scenario of importing data from a fixed-length file to database
This job shows a typical scenario, when reading input data and processing the data is cleanly separated. The data provider is responsible for reading input and mapping each record to a domain object, which is then passed to the module processor. The module processor handles the processing of the domain objects, in this case it only writes them to database.
In this example we are using a simple fixed length record structure that can be found in the project at data/iosample/input. A considerable amount of thought can go into designing the folder structures for batch file management. The fixed length records look like this:
UK21341EAH4597898.34customer1 UK21341EAH4611218.12customer2 UK21341EAH4724512.78customer2 UK21341EAH48108109.25customer3 UK21341EAH49854123.39customer4
Looking back to the configuration file you will see where this is documented in the property of the FixedLengthTokenizer. You can infer the following properties:
| FieldName ISIN Quantity Price Customer |
Length 12 3 5 9 |
Output target: database - writes the data to database using a DAO object
This is a (American) Football statistics loading job. We gave it the id of footballJob in our configuration file. Before diving into the batch job, we'll examine the two input files that need to be loaded. First is player.csv, which can be found in the samples project under src/main/resources/data/footballjob/input/. Each line within this file represents a player, with a unique id, the playerâs name, position, etc:
AbduKa00,Abdul-Jabbar,Karim,rb,1974,1996 AbduRa00,Abdullah,Rabih,rb,1975,1999 AberWa00,Abercrombie,Walter,rb,1959,1982 AbraDa00,Abramowicz,Danny,wr,1945,1967 AdamBo00,Adams,Bob,te,1946,1969 AdamCh00,Adams,Charlie,wr,1979,2003 ...
One of the first noticeable characteristics of the file is that each data element is separated by a comma, a format most are familiar with known as 'CSV'. Other separators such as pipes or semicolons could just as easily be used to delineate between unique elements. In general, it falls into one of two types of flat file formats: delimited or fixed length. (The fixed length case was covered in the fixedLengthImportJob.
The second file, 'games.csv' is formatted the same as the previous example, and resides in the same directory:
AbduKa00,1996,mia,10,nwe,0,0,0,0,0,29,104,,16,2 AbduKa00,1996,mia,11,clt,0,0,0,0,0,18,70,,11,2 AbduKa00,1996,mia,12,oti,0,0,0,0,0,18,59,,0,0 AbduKa00,1996,mia,13,pit,0,0,0,0,0,16,57,,0,0 AbduKa00,1996,mia,14,rai,0,0,0,0,0,18,39,,7,0 AbduKa00,1996,mia,15,nyg,0,0,0,0,0,17,96,,14,0 ...
Each line in the file represents an individual player's performance in a particular game, containing such statistics as passing yards, receptions, rushes, and total touchdowns.
Our example batch job is going to load both files into a database, and then combine each to summarise how each player performed for a particular year. Although this example is fairly trivial, it shows multiple types of input, and the general style is a common batch scenario. That is, summarising a very large dataset so that it can be more easily manipulated or viewed by an online web-based application. In an enterprise solution the third step, the reporting step, could be implemented through the use of Eclipse BIRT or one of the many Java Reporting Engines. Given this description, we can then easily divide our batch job up into 3 'steps': one to load the player data, one to load the game data, and one to produce a summary report:
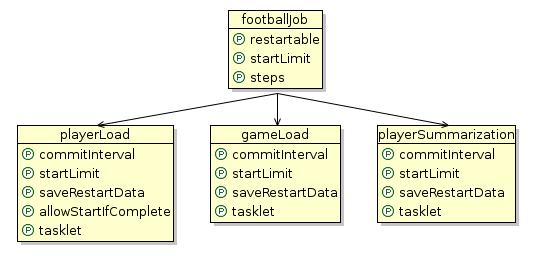
This corresponds exactly with the footballJob.xml job configuration file which can be found in the jobs folder under src/main/resources. When you drill down into the football job you will see that the configuration has a list of steps:
<property name="steps">
<list>
<bean id="playerload" parent="simpleStep" .../>
<bean id="gameLoad" parent="simpleStep" .../>
<bean id="playerSummarization" parent="simpleStep" .../>
</list>
</property>
A step is run until there is no more input to process, which in this case would mean that each file has been completely processed. To describe it in a more narrative form: the first step, playerLoad, begins executing by grabbing one line of input from the file, and parsing it into a domain object. That domain object is then passed to a dao, which writes it out to the PLAYERS table. This action is repeated until there are no more lines in the file, causing the playerLoad step to finish. Next, the gameLoad step does the same for the games input file, inserting into the GAMES table. Once finished, the playerSummarization step can begin. Unlike the first two steps, playerSummarization input comes from the database, using a Sql statement to combine the GAMES and PLAYERS table. Each returned row is packaged into a domain object and written out to the PLAYER_SUMMARY table.
Now that we've discussed the entire flow of the batch job, we can dive deeper into the first step: playerLoad:
<bean id="playerload" parent="simpleStep">
<property name="commitInterval" value="${job.commit.interval}" />
<property name="startLimit" value="100" />
<property name="itemReader"
ref="playerFileItemReader" />
<property name="itemWriter">
<bean
class="org.springframework.batch.sample.domain.football.internal.internal.PlayerItemWriter">
<property name="playerDao">
<bean
class="org.springframework.batch.sample.domain.football.internal.internal.JdbcPlayerDao">
<property name="dataSource"
ref="dataSource" />
</bean>
</property>
</bean>
</property>
</bean>
The root bean in this case is a SimpleStepFactoryBean, which can be considered a 'blueprint' of sorts that tells the execution environment basic details about how the batch job should be executed. It contains four properties: (others have been removed for greater clarity) commitInterval, startLimit, itemReader and itemWriter . After performing all necessary startup, the framework will periodically delegate to the reader and writer. In this way, the developer can remain solely concerned with their business logic.
The application developer simply provides a job configuration with a configured number of steps, an ItemReader associated to some type of input source, and ItemWriter associated to some type of output source and a little mapping of data from flat records to objects and the pipe is ready wired for processing.
Another property in the step configuration, the commitInterval, gives the framework vital information about how to control transactions during the batch run. Due to the large amount of data involved in batch processing, it is often advantageous to 'batch' together multiple logical units of work into one transaction, since starting and committing a transaction is extremely expensive. For example, in the playerLoad step, the framework calls read() on the item reader. The item reader reads one record from the file, and returns a domain object representation which is passed to the processor. The writer then writes the one record to the database. It can then be said that one iteration = one call to ItemReader.read() = one line of the file. Therefore, setting your commitInterval to 5 would result in the framework committing a transaction after 5 lines have been read from the file, with 5 resultant entries in the PLAYERS table.
Following the general flow of the batch job, the next step is to describe how each line of the file will be parsed from its string representation into a domain object. The first thing the provider will need is an ItemReader, which is provided as part of the Spring Batch infrastructure. Because the input is flat-file based, a FlatFileItemReader is used:
<bean id="playerFileItemReader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource"
value="classpath:data/footballjob/input/${player.file.name}" />
<property name="lineTokenizer">
<bean
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="names"
value="ID,lastName,firstName,position,birthYear,debutYear" />
</bean>
</property>
<property name="fieldSetMapper">
<bean
class="org.springframework.batch.sample.domain.football.internal.internal.PlayerFieldSetMapper" />
</property>
</bean>
There are three required dependencies of the item reader; the first is a resource to read in, which is the file to process. The second dependency is a LineTokenizer. The interface for a LineTokenizer is very simple, given a string; it will return a FieldSet that wraps the results from splitting the provided string. A FieldSet is Spring Batch's abstraction for flat file data. It allows developers to work with file input in much the same way as they would work with database input. All the developers need to provide is a FieldSetMapper (similar to a Spring RowMapper) that will map the provided FieldSet into an Object. Simply by providing the names of each token to the LineTokenizer, the ItemReader can pass the FieldSet into our PlayerMapper, which implements the FieldSetMapper interface. There is a single method, mapLine(), which maps FieldSets the same way that developers are comfortable mapping ResultSets into Java Objects, either by index or field name. This behaviour is by intention and design similar to the RowMapper passed into a JdbcTemplate. You can see this below:
public class
PlayerMapper implements FieldSetMapper {
public Object mapLine(FieldSet fs) {
if(fs == null){
return null;
}
Player player = new Player();
player.setID(fs.readString("ID"));
player.setLastName(fs.readString("lastName"));
player.setFirstName(fs.readString("firstName"));
player.setPosition(fs.readString("position"));
player.setDebutYear(fs.readInt("debutYear"));
player.setBirthYear(fs.readInt("birthYear"));
return player;
}
}
The flow of the ItemReader, in this case, starts with a call to read the next line from the file. This is passed into the provided LineTokenizer. The LineTokenizer splits the line at every comma, and creates a FieldSet using the created String array and the array of names passed in.
Once the domain representation of the data has been returned by the provider, (i.e. a Player object in this case) it is passed to the ItemWriter, which is essentially a Dao that uses a Spring JdbcTemplate to insert a new row in the PLAYERS table.
The next step, gameLoad, works almost exactly the same as the playerLoad step, except the games file is used.
The final step, playerSummarization, is much like the previous two steps, in that it reads from a reader and returns a domain object to a writer. However, in this case, the input source is the database, not a file:
<bean id="playerSummarizationSource"
class="org.springframework.batch.item.database.JdbcCursorItemReader">
<property name="dataSource" ref="dataSource" />
<property name="mapper">
<bean
class="org.springframework.batch.sample.domain.football.internal.internal.PlayerSummaryMapper" />
</property>
<property name="sql">
<value>
SELECT games.player_id, games.year_no, SUM(COMPLETES),
SUM(ATTEMPTS), SUM(PASSING_YARDS), SUM(PASSING_TD),
SUM(INTERCEPTIONS), SUM(RUSHES), SUM(RUSH_YARDS),
SUM(RECEPTIONS), SUM(RECEPTIONS_YARDS), SUM(TOTAL_TD)
from games, players where players.player_id =
games.player_id group by games.player_id, games.year_no
</value>
</property>
</bean>
The JdbcCursorItemReader has three dependences:
When the step is first started, a query will be run against the database to open a cursor, and each call to itemReader.read() will move the cursor to the next row, using the provided RowMapper to return the correct object. As with the previous two steps, each record returned by the provider will be written out to the database in the PLAYER_SUMMARY table. Finally to run this sample application you can execute the JUnit test FootballJobFunctionalTests, and you'll see an output showing each of the records as they are processed. Please keep in mind that AoP is used to wrap the ItemWriter and output each record as it is processed to the logger, which may impact performance.
This sample shows the use of callbacks and listeners to deal with headers and footers in flat files. It uses two custom callbacks:
The purpose of this sample is to show a typical usage of Hibernate as an ORM tool in the input and output of a job.
The job uses a HibernateCursorItemReader for the input, where a simple HQL query is used to supply items. It also uses a non-framework ItemWriter wrapping a DAO, which perhaps was written as part of an online system.
The output reliability and robustness are improved by the use of Session.flush() inside ItemWriter.write(). This "write-behind" behaviour is provided by Hibernate implicitly, but we need to take control of it so that the skip and retry features provided by Spring Batch can work effectively.
The goal of this sample is to show the use of Ibatis as a query mapping tool. Its features are similar to the Hibernate sample, but it uses Ibatis to drive its input and output.
This sample has a single step that is an infinite loop, reading and writing fake data. It is used to demonstrate stop signals and restart capabilities.
Shows how to implement a job that repeats one of its steps up to a limit set by a JobExecutionDecider.
The goal of this sample is to show some common tricks with multiline records in file input jobs.
The input file in this case consists of two groups of trades delimited by special lines in a file (BEGIN and END):
BEGIN UK21341EAH4597898.34customer1 UK21341EAH4611218.12customer2 END BEGIN UK21341EAH4724512.78customer2 UK21341EAH4810809.25customer3 UK21341EAH4985423.39customer4 END
The goal of the job is to operate on the two groups, so the item type is naturally List<Trade>. To get these items delivered from an item reader we employ two components from Spring Batch: the AggregateItemReader and the PrefixMatchingCompositeLineTokenizer. The latter is responsible for recognising the difference between the trade data and the delimiter records. The former is responsible for aggregating the trades from each group into a List and handing out the list from its read() method. To help these components perform their responsibilities we also provide some business knowledge about the data in the form of a FieldSetMapper (TradeFieldSetMapper). The TradeFieldSetMapper checks its input for the delimiter fields (BEGIN, END) and if it detects them, returns the special tokens that AggregateItemReader needs. Otherwise it maps the input into a Trade object.
The goal is to demonstrate how to handle a more complex file input format, where a record meant for processing includes nested records and spans multiple lines
The input source is file with multiline records. OrderItemReader is an example of a non-default programmatic item reader. It reads input until it detects that the multiline record has finished and encapsulates the record in a single domain object.
The output target is a file with multiline records. The concrete ItemWriter passes the object to a an injected 'delegate writer' which in this case writes the output to a file. The writer in this case demonstrates how to write multiline output using a custom aggregator transformer.
The purpose of this sample is to show multi-threaded step execution using the Process Indicator pattern.
The job reads data from the same file as the Fixed Length Import sample, but instead of writing it out directly it goes through a staging table, and the staging table is read in a multi-threaded step. Note that for such a simple example where the item processing was not expensive, there is unlikely to be much if any benefit in using a multi-threaded step.
Multi-threaded step execution is easy to configure using Spring Batch, but there are some limitations. Most of the out-of-the-box ItemReader and ItemWriter implementations are not designed to work in this scenario because they need to be restartable and they are also stateful. There should be no surprise about this, and reading a file (for instance) is usually fast enough that multi-threading that part of the process is not likely to provide much benefit, compared to the cost of managing the state.
The best strategy to cope with restart state from multiple concurrent threads depends on the kind of input source involved:
This last strategy is implemented in the StagingItemReader. Its companion, the StagingItemWriter is responsible for setting up the data in a staging table which contains the process indicator. The reader is then driven by a simple SQL query that includes a where clause for the processed flag, i.e.
SELECT ID FROM BATCH_STAGING WHERE JOB_ID=? AND PROCESSED=? ORDER BY ID
It is then responsible for updating the processed flag (which happens inside the main step transaction).
The purpose of this sample is to show multi-threaded step execution using the PartitionHandler SPI. The example uses a TaskExecutorPartitionHandler to spread the work of reading some files acrosss multiple threads, with one Step execution per thread. The key components are the PartitionStep and the MultiResourcePartitioner which is responsible for dividing up the work. Notice that the readers and writers in the Step that is being partitioned are step-scoped, so that their state does not get shared across threads of execution.
The goal is to demonstrate how to schedule job execution using Quartz scheduler. In this case there is no unit test to launch the sample because it just re-uses the football job. There is a main method in JobRegistryBackgroundJobRunner and an Eclipse launch configuration which runs it with arguments to pick up the football job.
The additional XML configuration for this job is in quartz-job-launcher.xml, and it also re-uses footballJob.xml
The configuration declares a JobLauncher bean. The launcher bean is different from the other samples only in that it uses an asynchronous task executor, so that the jobs are launched in a separate thread to the main method:
<bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
<property name="taskExecutor">
<bean class="org.springframework.core.task.SimpleAsyncTaskExecutor" />
</property>
</bean>
Also, a Quartz JobDetail is defined using a Spring JobDetailBean as a convenience.
<bean id="jobDetail" class="org.springframework.scheduling.quartz.JobDetailBean">
<property name="jobClass" value="org.springframework.batch.sample.quartz.JobLauncherDetails" />
<property name="group" value="quartz-batch" />
<property name="jobDataAsMap">
<map>
<entry key="jobName" value="footballJob"/>
<entry key="jobLocator" value-ref="jobRegistry"/>
<entry key="jobLauncher" value-ref="jobLauncher"/>
</map>
</property>
</bean>
Finally, a trigger with a scheduler is defined that will launch the job detail every 10 seconds:
<bean class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<bean id="cronTrigger" class="org.springframework.scheduling.quartz.CronTriggerBean">
<property name="jobDetail" ref="jobDetail" />
<property name="cronExpression" value="0/10 * * * * ?" />
</bean>
</property>
</bean>
The job is thus scheduled to run every 10 seconds. In fact it should be successful on the first attempt, so the second and subsequent attempts should through a JobInstanceAlreadyCompleteException. In a production system, the job detail would probably be modified to account for this exception (e.g. catch it and re-submit with a new set of job parameters). The point here is that Spring Batch guarantees that the job execution is idempotent - you can never inadvertently process the same data twice.
The goal of this sample is to show how a job can be restarted after a failure and continue processing where it left off.
To simulate a failure we "fake" a failure on the fourth record though the use of a sample component ExceptionThrowingItemReaderProxy. This is a stateful reader that counts how many records it has processed and throws a planned exception in a specified place. Since we re-use the same instance when we restart the job it will not fail the second time.
The purpose of this sample is to show how to use the automatic retry capabilities of Spring Batch.
The retry is configured in the step through the SkipLimitStepFactoryBean:
<bean id="step1" parent="simpleStep"
class="org.springframework.batch.core.step.item.FaultTolerantStepFactoryBean">
...
<property name="retryLimit" value="3" />
<property name="retryableExceptionClasses" value="java.lang.Exception" />
</bean>
Failed items will cause a rollback for all Exception types, up to a limit of 3 attempts. On the 4th attempt, the failed item would be skipped, and there would be a callback to a ItemSkipListener if one was provided (via the "listeners" property of the step factory bean).
An ItemReader is provided that will generate unique Trade data by just incrementing a counter. Note that it uses the counter in its mark() and reset() methods so that the same content is returned after a rollback. The same content is returned, but the instance of Trade is different, which means that the implementation of equals() in the Trade object is important. This is because to identify a failed item on retry (so that the number of attempts can be counted) the framework by default uses Object.equals() to compare the recently failed item with a cache of previously failed items. Without implementing a field-based equals() method for the domain object, our job will spin round the retry for potentially quite a long time before failing because the default implementation of equals() is based on object reference, not on field content.
The purpose of this sample is to show how to use the skip features of Spring Batch. Since skip is really just a special case of retry (with limit 0), the details are quite similar to the Retry Sample, but the use case is less artificial, since it is based on the Trade Sample.
The failure condition is still artificial, since it is triggered by a special ItemWriter wrapper (ItemTrackingItemWriter). The plan is that a certain item (the third) will fail business validation in the writer, and the system can then respond by skipping it. We also configure the step so that it will not roll back on the validation exception, since we know that it didn't invalidate the transaction, only the item. This is done through the transaction attribute:
<bean id="step2" parent="skipLimitStep">
<property name="skipLimit" value="1" />
<!-- No rollback for exceptions that are marked with "+" in the tx attributes -->
<property name="transactionAttribute"
value="+org.springframework.batch.item.validator.ValidationException" />
....
</bean>
The format for the transaction attribute specification is given in the Spring Core documentation (e.g. see the Javadocs for TransactionAttributeEditor).
The goal is to show the simplest use of the batch framework with a single job with a single step, which cleans up a directory and runs a system command.
Description: The Job itself is defined by the bean definition with id="taskletJob". In this example we have two steps.
You can visualise the Spring configuration of a job through Spring-IDE. See Spring IDE. The source view of the configuration is as follows:
<bean id="taskletJob" parent="simpleJob">
<property name="steps">
<list>
<bean id="deleteFilesInDir" parent="taskletStep">
<property name="tasklet">
<bean
class="org.springframework.batch.sample.tasklet.FileDeletingTasklet">
<property name="directoryResource"
ref="directory" />
</bean>
</property>
</bean>
<bean id="executeSystemCommand" parent="taskletStep">
<property name="tasklet">
<bean
class="org.springframework.batch.sample.common.SystemCommandTasklet">
<property name="command" value="echo hello" />
<!-- 5 second timeout for the command to complete -->
<property name="timeout" value="5000" />
</bean>
</property>
</bean>
</list>
</property>
</bean>
<bean id="directory"
class="org.springframework.core.io.FileSystemResource">
<constructor-arg value="target/test-outputs/test-dir" />
</bean>
For simplicity we are only displaying the job configuration itself and leaving out the details of the supporting batch execution environment configuration.
The goal is to show a reasonably complex scenario, that would resemble the real-life usage of the framework.
This job has 3 steps. First, data about trades are imported from a file to database. Second, the trades are read from the database and credit on customer accounts is decreased appropriately. Last, a report about customers is exported to a file.
The goal here is to show the use of XML input and output through streaming and Spring OXM marshallers and unmarshallers.
The job has a single step that copies Trade data from one XML file to another. It uses XStream for the object XML conversion, because this is simple to configure for basic use cases like this one. See Spring OXM documentation for details of other options.