This guide walks you through building and running a simple Spring Boot, Apache Geode ClientCache application
using the Spring Boot for Apache Geode (SBDG) framework. Later in this guide, we switch the application from
Apache Geode to Pivotal Cloud Cache and deploy (i.e push)
the application up to Pivotal Platform.
Specifically, you will:
-
Create a new "Spring for Apache Geode" project using Spring Initializer at start.spring.io. Goto the Spring Initializer topic.
-
Then, we build a simple Spring Boot, Apache Geode
ClientCacheapplication that can persist data locally in Apache Geode. Goto the Build App topic. -
Next, we switch the application from running locally to using a client/server topology. Goto the Client/Server topic.
-
And finally, we deploy the application to Pivotal Platform and bind our application to a provisioned Pivotal Cloud Cache (PCC) service instance. Goto the Cloud Platform topic.
Our goal is to accomplish each step with little to no code or configuration changes. It should just work!
| It is also possible to migrate from a Commercial, Managed environment (running in Pivotal Platform using Pivotal Cloud Cache (PCC)) back to an Open Source, Non-Managed environment (i.e. running with an externally managed Apache Geode cluster). |
By the end of this guide, you should feel comfortable and ready to begin building Spring Boot applications using either Apache Geode standalone or by deploying and running in Pivotal Platform using Pivotal Cloud Cache (PCC).
| Pivotal Cloud Cache (PCC) has replaced Pivotal GemFire as the new brand name. |
Let’s begin!
1. Begin with Spring Initializer at start.spring.io
First, open your Web browser to https://start.spring.io.
When creating the example app for this guide, we selected:
-
Project: Maven Project (alternatively, you can create a "Gradle Project")
-
Language: Java (alternatively, you can use "Kotlin", or "Groovy")
-
Spring Boot: 2.2.0 RC1
-
Project Metadata:
-
Group: example.app
-
Artifact: crm
-
Options:
-
Package Name: example.app.crm
-
-
-
Dependencies: Add "Spring for Apache Geode" by typing "Geode" into the "Search dependencies to add" text field.
-
(Optional) Dependencies: Add "Spring Web" to pull in
org.springframework.boot:spring-boot-starter-webif you want this Spring Boot application to be a Web application.
You can use this link to get you started. You will most likely need to set the "Spring Boot" version as well as the "Package Name".
As of this writing, Spring Boot 2.2.0.RC1 was the latest version. However, that may not be the case after you
read this, so please select the latest, non-SNAPSHOT version of Spring Boot greater than 2.2.0.RC1. The instructions
reflect the screenshots of Spring Initializer at start.spring.io below when this guide was written, therefore you will
see that 2.2.0.RC1 was selected when the project was generated. For more on versions see the
sidebar at the end of this section.
|
Your selections should look similar to:
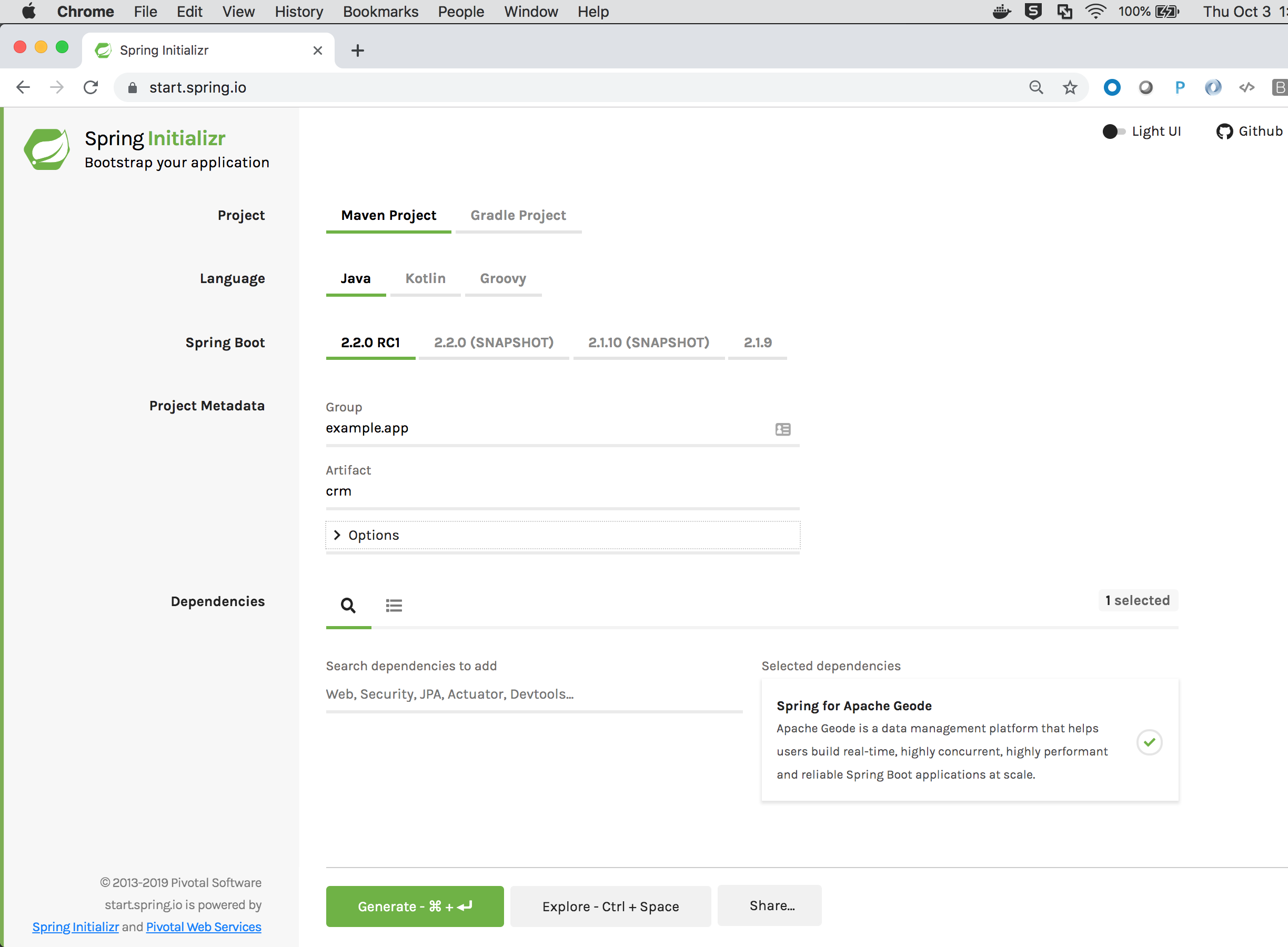
Be sure to click the "+" button next to the "Spring for Apache Geode" dependency to select and add it to the generated project Maven POM file.
You can explore the contents of the generated project by pressing the CTRL+SPACE keys:
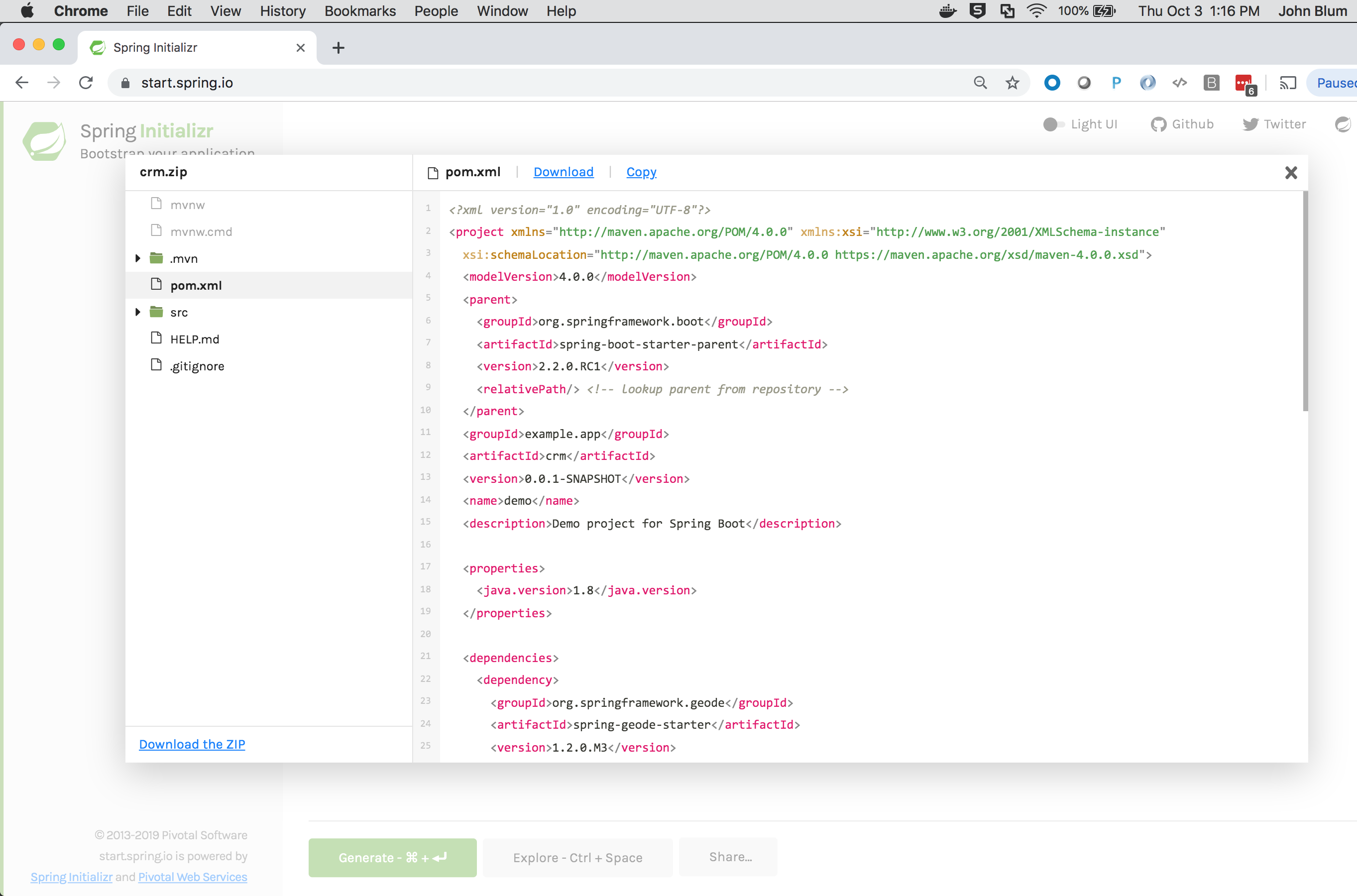
Click the "Generate the project" button. This generates a Java 8 project with JAR packaging.
Download the ZIP file and unpack it to your desired working directory.
You can then use your favorite IDE (e.g. IntelliJ IDEA or Spring Tool Suite (STS)) to open the generated project.
You are ready to begin developing your Spring Boot, Apache Geode ClientCache application.
1.1. Exploring the Source Code and Running the CrmApplication
The generated project contains a example.app.crm.CrmApplication Java class that is annotated with the
@SpringBootApplication annotation.
CrmApplication classpackage example.app.crm;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class CrmApplication {
public static void main(String[] args) {
SpringApplication.run(CrmApplication.class, args);
}
}Additionally, in the project Maven POM file, we see the "Spring Boot for Apache Geode" (SBDG) dependency
(org.springframework.geode:spring-geode-starter):
<dependency>
<groupId>org.springframework.geode</groupId>
<artifactId>spring-geode-starter</artifactId>
</dependency>With the Spring Boot for Apache Geode dependency (i.e. org.springframework.geode:spring-geode-starter)
on the application classpath along with the main Java class being a proper Spring Boot application, this application
will startup and run as an Apache Geode ClientCache application:
/Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/bin/java "-javaagent:/Applications
/IntelliJ IDEA 19 CE.app/Contents/lib/idea_rt.jar=57178:/Applications/IntelliJ IDEA 19 CE.app/Contents/bin" ...
example.app.crm.CrmApplication
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.2.0.BUILD-SNAPSHOT)
... : Starting CrmApplication on jblum-mbpro-2.local with PID 7156
(.../spring-boot-data-geode/spring-geode-samples/intro/getting-started/out/production/classes
started by jblum in /Users/jblum/pivdev/spring-boot-data-geode)
... : No active profile set, falling back to default profiles: default
... : Failed to connect to localhost[40404]
... : Failed to connect to localhost[10334]
... : Bootstrapping Spring Data repositories in DEFAULT mode.
... : Finished Spring Data repository scanning in 7ms. Found 0 repository interfaces.
... : @Bean method PdxConfiguration.pdxDiskStoreAwareBeanFactoryPostProcessor is non-static
and returns an object assignable to Spring's BeanFactoryPostProcessor interface. This
will result in a failure to process annotations such as @Autowired, @Resource and
@PostConstruct within the method's declaring @Configuration class. Add the 'static'
modifier to this method to avoid these container lifecycle issues; see @Bean javadoc
for complete details.
... : Bean 'o.s.geode.boot.autoconfigure.RegionTemplateAutoConfiguration' of type
[o.s.geode.boot.autoconfigure.RegionTemplateAutoConfiguration$$EnhancerBySpringCGLIB$$7fa0e8c9]
is not eligible for getting processed by all BeanPostProcessors (for example:
not eligible for auto-proxying)
...
---------------------------------------------------------------------------
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with this
work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with the
License. You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
License for the specific language governing permissions and limitations
under the License.
---------------------------------------------------------------------------
Build-Date: 2019-04-19 11:49:13 -0700
Build-Id: onichols 0
Build-Java-Version: 1.8.0_192
Build-Platform: Mac OS X 10.14.4 x86_64
Product-Name: Apache Geode
Product-Version: 1.9.0
Source-Date: 2019-04-19 11:11:31 -0700
Source-Repository: release/1.9.0
Source-Revision: c0a73d1cb84986d432003bd12e70175520e63597
Native version: native code unavailable
Running on: /10.99.199.24, 8 cpu(s), x86_64 Mac OS X 10.13.6
Communications version: 100
Process ID: 7156
User: jblum
Current dir: /Users/jblum/pivdev/spring-boot-data-geode
Home dir: /Users/jblum
Command Line Parameters:
-javaagent:/Applications/IntelliJ IDEA 19 CE.app/Contents/lib/idea_rt.jar=57178:/Applications
/IntelliJ IDEA 19 CE.app/Contents/bin
-Dfile.encoding=UTF-8
Class Path:
...
// NOTE: JRE JAR files ommitted
...
.../spring-boot-starter-test-2.2.0.BUILD-SNAPSHOT.jar
.../spring-data-geode-test-0.0.9.BUILD-SNAPSHOT.jar
.../assertj-core-3.13.2.jar
.../7b533399d6f88039537bb757f25a2c90d46fcdc7/spring-boot-starter-2.2.0.BUILD-SNAPSHOT.jar
.../spring-data-geode-2.2.0.RC3.jar
.../geode-cq-1.9.0.jar
.../geode-lucene-1.9.0.jar
.../geode-wan-1.9.0.jar
.../geode-core-1.9.0.jar
.../spring-shell-1.2.0.RELEASE.jar
.../2e5515925b591e23e23faf6e15defdaf542fe5a4/spring-boot-test-autoconfigure-2.2.0.BUILD-SNAPSHOT.jar
.../spring-boot-autoconfigure-2.2.0.BUILD-SNAPSHOT.jar
.../spring-boot-test-2.2.0.BUILD-SNAPSHOT.jar
.../spring-boot-2.2.0.BUILD-SNAPSHOT.jar
.../spring-boot-starter-logging-2.2.0.BUILD-SNAPSHOT.jar
.../jakarta.annotation-api-1.3.5.jar
.../spring-context-support-5.2.0.BUILD-SNAPSHOT.jar
.../spring-test-5.2.0.BUILD-SNAPSHOT.jar
.../spring-context-5.2.0.BUILD-SNAPSHOT.jar
.../spring-tx-5.2.0.BUILD-SNAPSHOT.jar
.../geode-management-1.9.0.jar
.../spring-web-5.2.0.BUILD-SNAPSHOT.jar
.../spring-data-commons-2.2.0.RC3.jar
.../spring-aop-5.2.0.BUILD-SNAPSHOT.jar
.../spring-beans-5.2.0.BUILD-SNAPSHOT.jar
.../spring-expression-5.2.0.BUILD-SNAPSHOT.jar
.../spring-core-5.2.0.BUILD-SNAPSHOT.jar
.../spring-jcl-5.2.0.BUILD-SNAPSHOT.jar
.../guava-17.0.jar
.../jline-2.12.jar
.../commons-io-2.6.jar
.../json-path-2.4.0.jar
.../jakarta.xml.bind-api-2.3.2.jar
.../junit-jupiter-5.5.2.jar
.../junit-vintage-engine-5.5.2.jar
.../mockito-junit-jupiter-3.0.0.jar
.../junit-4.12.jar
.../hamcrest-core-2.1.jar
.../hamcrest-2.1.jar
.../mockito-core-3.0.0.jar
.../jsonassert-1.5.0.jar
.../xmlunit-core-2.6.3.jar
.../multithreadedtc-1.01.jar
.../logback-classic-1.2.3.jar
.../log4j-to-slf4j-2.12.1.jar
.../jul-to-slf4j-1.7.28.jar
.../shiro-spring-1.4.1.jar
.../aspectjweaver-1.9.4.jar
.../jackson-databind-2.9.9.3.jar
.../jackson-annotations-2.9.0.jar
.../shiro-web-1.4.1.jar
.../shiro-core-1.4.1.jar
.../shiro-cache-1.4.1.jar
.../shiro-crypto-hash-1.4.1.jar
.../shiro-crypto-cipher-1.4.1.jar
.../shiro-config-ogdl-1.4.1.jar
.../shiro-config-core-1.4.1.jar
.../shiro-event-1.4.1.jar
.../shiro-crypto-core-1.4.1.jar
.../shiro-lang-1.4.1.jar
.../slf4j-api-1.7.28.jar
.../json-smart-2.3.jar
.../jakarta.activation-api-1.2.1.jar
.../junit-jupiter-params-5.5.2.jar
.../junit-jupiter-api-5.5.2.jar
.../junit-platform-engine-1.5.2.jar
.../junit-platform-commons-1.5.2.jar
.../apiguardian-api-1.1.0.jar
.../byte-buddy-1.9.10.jar
.../byte-buddy-agent-1.9.10.jar
.../objenesis-2.6.jar
.../android-json-0.0.20131108.vaadin1.jar
.../logback-core-1.2.3.jar
.../log4j-api-2.12.1.jar
.../findbugs-annotations-1.3.9-1.jar
.../jgroups-3.6.14.Final.jar
.../antlr-2.7.7.jar
.../commons-validator-1.6.jar
.../commons-digester-2.1.jar
.../javax.activation-1.2.0.jar
.../jaxb-api-2.3.1.jar
.../jaxb-impl-2.3.1.jar
.../istack-commons-runtime-2.2.jar
.../commons-lang3-3.9.jar
.../micrometer-core-1.2.1.jar
.../fastutil-8.2.2.jar
.../javax.resource-api-1.7.1.jar
.../jna-4.5.2.jar
.../jopt-simple-5.0.4.jar
.../jetty-server-9.4.20.v20190813.jar
.../classgraph-4.0.6.jar
.../rmiio-2.1.2.jar
.../geode-common-1.9.0.jar
.../lucene-analyzers-common-6.6.2.jar
.../lucene-queryparser-6.6.2.jar
.../lucene-core-6.6.2.jar
.../mx4j-3.0.2.jar
.../jackson-core-2.9.9.jar
.../accessors-smart-1.2.jar
.../opentest4j-1.2.0.jar
.../commons-beanutils-1.9.3.jar
.../httpclient-4.5.9.jar
.../commons-logging-1.2.jar
.../commons-collections-3.2.2.jar
.../javax.activation-api-1.2.0.jar
.../HdrHistogram-2.1.11.jar
.../LatencyUtils-2.0.3.jar
.../javax.transaction-api-1.3.jar
.../jetty-http-9.4.20.v20190813.jar
.../jetty-io-9.4.20.v20190813.jar
.../lucene-queries-6.6.2.jar
.../asm-5.0.4.jar
.../jetty-util-9.4.20.v20190813.jar
.../httpcore-4.4.12.jar
.../commons-codec-1.13.jar
.../lombok-1.18.8.jar
.../snakeyaml-1.25.jar
.../junit-jupiter-engine-5.5.2.jar
.../lucene-analyzers-phonetic-6.6.2.jar
/Applications/IntelliJ IDEA 19 CE.app/Contents/lib/idea_rt.jar
Library Path:
/Users/jblum/Library/Java/Extensions
/Library/Java/Extensions
/Network/Library/Java/Extensions
/System/Library/Java/Extensions
/usr/lib/java
.
System Properties:
PID = 7156
awt.toolkit = sun.lwawt.macosx.LWCToolkit
file.encoding = UTF-8
file.encoding.pkg = sun.io
file.separator = /
ftp.nonProxyHosts = local|*.local|169.254/16|*.169.254/16
gopherProxySet = false
http.nonProxyHosts = local|*.local|169.254/16|*.169.254/16
java.awt.graphicsenv = sun.awt.CGraphicsEnvironment
java.awt.headless = true
java.awt.printerjob = sun.lwawt.macosx.CPrinterJob
java.class.version = 52.0
java.endorsed.dirs = /Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home
/jre/lib/endorsed
java.ext.dirs = /Users/jblum/Library/Java/Extensions:/Library/Java/JavaVirtualMachines
/jdk1.8.0_192.jdk/Contents/Home/jre/lib/ext
:/Library/Java/Extensions
:/Network/Library/Java/Extensions:/System/Library/Java/Extensions
:/usr/lib/java
java.home = /Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/jre
java.io.tmpdir = /var/folders/ly/d_6wcpgx7qv146hbwnp7zvfr0000gn/T/
java.runtime.name = Java(TM) SE Runtime Environment
java.runtime.version = 1.8.0_192-b12
java.specification.name = Java Platform API Specification
java.specification.vendor = Oracle Corporation
java.specification.version = 1.8
java.vendor = Oracle Corporation
java.vendor.url = https://java.oracle.com/
java.vendor.url.bug = https://bugreport.sun.com/bugreport/
java.version = 1.8.0_192
java.vm.info = mixed mode
java.vm.name = Java HotSpot(TM) 64-Bit Server VM
java.vm.specification.name = Java Virtual Machine Specification
java.vm.specification.vendor = Oracle Corporation
java.vm.specification.version = 1.8
java.vm.vendor = Oracle Corporation
java.vm.version = 25.192-b12
line.separator =
os.version = 10.13.6
path.separator = :
socksNonProxyHosts = local|*.local|169.254/16|*.169.254/16
spring.beaninfo.ignore = true
spring.data.gemfire.cache.client.region.shortcut = LOCAL
sun.arch.data.model = 64
sun.boot.class.path = /Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/jre/lib/resources.jar
:/Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/jre/lib/rt.jar
:/Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/jre/lib/sunrsasign.jar
:/Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/jre/lib/jsse.jar
:/Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/jre/lib/jce.jar
:/Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/jre/lib/charsets.jar
:/Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/jre/lib/jfr.jar
:/Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/jre/classes
sun.boot.library.path = /Library/Java/JavaVirtualMachines/jdk1.8.0_192.jdk/Contents/Home/jre/lib
sun.cpu.endian = little
sun.cpu.isalist =
sun.io.unicode.encoding = UnicodeBig
sun.java.command = example.app.crm.CrmApplication
sun.java.launcher = SUN_STANDARD
sun.jnu.encoding = UTF-8
sun.management.compiler = HotSpot 64-Bit Tiered Compilers
sun.nio.ch.bugLevel =
sun.os.patch.level = unknown
user.country = US
user.language = en
user.timezone = America/Los_Angeles
Log4J 2 Configuration:
org.apache.geode.internal.logging.NullProviderAgent
---------------------------------------------------------------------------
2019-09-15 23:16:17.617 INFO 7156 --- [main] o.a.g.internal.logging.LoggingSession
: Startup Configuration: ### GemFire Properties defined with api ###
locators=
log-level=config
mcast-port=0
name=SpringBasedCacheClientApplication
### GemFire Properties using default values ###
ack-severe-alert-threshold=0
ack-wait-threshold=15
archive-disk-space-limit=0
archive-file-size-limit=0
async-distribution-timeout=0
async-max-queue-size=8
async-queue-timeout=60000
bind-address=
cache-xml-file=cache.xml
cluster-configuration-dir=
cluster-ssl-ciphers=any
cluster-ssl-enabled=false
cluster-ssl-keystore=
cluster-ssl-keystore-password=
cluster-ssl-keystore-type=
cluster-ssl-protocols=any
cluster-ssl-require-authentication=true
cluster-ssl-truststore=
cluster-ssl-truststore-password=
conflate-events=server
conserve-sockets=true
delta-propagation=true
deploy-working-dir=/Users/jblum/pivdev/spring-boot-data-geode
disable-auto-reconnect=false
disable-jmx=false
disable-tcp=false
distributed-system-id=-1
distributed-transactions=false
durable-client-id=
durable-client-timeout=300
enable-cluster-configuration=true
enable-network-partition-detection=true
enable-time-statistics=false
enforce-unique-host=false
gateway-ssl-ciphers=any
gateway-ssl-enabled=false
gateway-ssl-keystore=
gateway-ssl-keystore-password=
gateway-ssl-keystore-type=
gateway-ssl-protocols=any
gateway-ssl-require-authentication=true
gateway-ssl-truststore=
gateway-ssl-truststore-password=
groups=
http-service-bind-address=
http-service-port=7070
http-service-ssl-ciphers=any
http-service-ssl-enabled=false
http-service-ssl-keystore=
http-service-ssl-keystore-password=
http-service-ssl-keystore-type=
http-service-ssl-protocols=any
http-service-ssl-require-authentication=false
http-service-ssl-truststore=
http-service-ssl-truststore-password=
jmx-manager=false
jmx-manager-access-file=
jmx-manager-bind-address=
jmx-manager-hostname-for-clients=
jmx-manager-http-port=7070
jmx-manager-password-file=
jmx-manager-port=1099
jmx-manager-ssl-ciphers=any
jmx-manager-ssl-enabled=false
jmx-manager-ssl-keystore=
jmx-manager-ssl-keystore-password=
jmx-manager-ssl-keystore-type=
jmx-manager-ssl-protocols=any
jmx-manager-ssl-require-authentication=true
jmx-manager-ssl-truststore=
jmx-manager-ssl-truststore-password=
jmx-manager-start=false
jmx-manager-update-rate=2000
load-cluster-configuration-from-dir=false
locator-wait-time=0
lock-memory=false
log-disk-space-limit=0
log-file=
log-file-size-limit=0
max-num-reconnect-tries=3
max-wait-time-reconnect=60000
mcast-address=239.192.81.1
mcast-flow-control=1048576, 0.25, 5000
mcast-recv-buffer-size=1048576
mcast-send-buffer-size=65535
mcast-ttl=32
member-timeout=5000
membership-port-range=41000-61000
memcached-bind-address=
memcached-port=0
memcached-protocol=ASCII
off-heap-memory-size=
redis-bind-address=
redis-password=
redis-port=0
redundancy-zone=
remote-locators=
remove-unresponsive-client=false
roles=
security-client-accessor=
security-client-accessor-pp=
security-client-auth-init=
security-client-authenticator=
security-client-dhalgo=
security-log-file=
security-log-level=config
security-manager=
security-peer-auth-init=
security-peer-authenticator=
security-peer-verifymember-timeout=1000
security-post-processor=
security-udp-dhalgo=
serializable-object-filter=!*
server-bind-address=
server-ssl-ciphers=any
server-ssl-enabled=false
server-ssl-keystore=
server-ssl-keystore-password=
server-ssl-keystore-type=
server-ssl-protocols=any
server-ssl-require-authentication=true
server-ssl-truststore=
server-ssl-truststore-password=
socket-buffer-size=32768
socket-lease-time=60000
ssl-ciphers=any
ssl-cluster-alias=
ssl-default-alias=
ssl-enabled-components=
ssl-endpoint-identification-enabled=false
ssl-gateway-alias=
ssl-jmx-alias=
ssl-keystore=
ssl-keystore-password=
ssl-keystore-type=
ssl-locator-alias=
ssl-protocols=any
ssl-require-authentication=true
ssl-server-alias=
ssl-truststore=
ssl-truststore-password=
ssl-truststore-type=
ssl-use-default-context=false
ssl-web-alias=
ssl-web-require-authentication=false
start-dev-rest-api=false
start-locator=
statistic-archive-file=
statistic-sample-rate=1000
statistic-sampling-enabled=true
tcp-port=0
thread-monitor-enabled=true
thread-monitor-interval-ms=60000
thread-monitor-time-limit-ms=30000
udp-fragment-size=60000
udp-recv-buffer-size=1048576
udp-send-buffer-size=65535
use-cluster-configuration=true
user-command-packages=
validate-serializable-objects=false
... : initializing InternalDataSerializer with 3 services
... : [ThreadsMonitor] New Monitor object and process were created.
... : Disabling statistic archival.
... : Running in client mode
... : Initialized cache service org.apache.geode.cache.lucene.internal.LuceneServiceImpl
... : Connected to Distributed System [SpringBasedCacheClientApplication]
as Member [*****(SpringBasedCacheClientApplication:7156:loner):0:e5f5b638:SpringBasedCacheClientApplication]
in Group(s) [[]]
with Role(s) [[]]
on Host [10.99.199.24]
having PID [7156]
... : Created new Apache Geode version [1.9.0] Cache [SpringBasedCacheClientApplication]
... : Started CrmApplication in 3.95474938 seconds (JVM running for 4.876)
... : VM is exiting - shutting down distributed system
... : GemFireCache[id = 1985175273; isClosing = true; isShutDownAll = false;
created = Sun Sep 15 23:16:17 PDT 2019; server = false; copyOnRead = false; lockLease = 120;
lockTimeout = 60]: Now closing.
Process finished with exit code 0First, you see the JVM bootstrap Spring Boot, which in turn runs our CrmApplication and also auto-configures
and bootstraps an Apache Geode ClientCache instance. Most of the output comes from Apache Geode.
The application falls straight through because it is not doing anything interesting, and technically, because there are no non-daemon Threads (e.g. Socket Thread listening on HTTP port 8080 in the case of Web applications running an embedded Servlet Container like Apache Tomcat) that prevents the "main" Java Thread from exiting immediately.
2. Build a Spring Boot, Apache Geode ClientCache application
Our Spring Boot application is a simple Customer Relationship Management (CRM) application that allows users
to persist Customer data in Apache Geode and lookup Customers by name.
2.1. Customer class
First, we define a Customer class:
Customer class@Region("Customers")
@Data
@ToString(of = "name")
@NoArgsConstructor
@AllArgsConstructor(staticName = "newCustomer")
public class Customer {
@Id
private Long id;
private String name;
}The CRM application defines a Customer in terms of an identifier (i.e. Long id) and a name (i.e. String name).
Both fields are required.
Additionally, we map Customer objects to the "/Customers" Region using Spring Data for Apache Geode’s (SDG)
@Region annotation.
The @Region annotation tells Spring Data where to persist and access Customer objects in Apache Geode. It is
basically equivalent to JPA’s @javax.persistence.Table annotation.
Additionally, we annotate the Long id field with Spring Data’s @org.springframework.data.annotation.Id annotation.
This designates the id field as the identifier, or in Apache Geode’s case, the "key" since a Region is a key/value
store. In fact, Apache Geode’s Region interface
implements the java.uti.Map interface making it a Map data structure.
We use Project Lombok to simply the implementation of the Customer class.
If you want to use Project Lombok, you will need org.projectlombok:lombok on your application classpath
as a compile-time dependency.
|
| While Project Lombok is useful and convenient for prototyping and testing purposes, it has become a rather subjective topic on whether to use Lombok in production code. We have no opinion here. |
2.2. CustomerRepository interface
Now that we have defined a basic model for managing customer data, we can create a Spring Data CrudRepository used by
our application to persist Customer objects to Apache Geode. This same Repository can be used to lookup, or query
Customers by name.
CustomerRepository interfacepublic interface CustomerRepository extends CrudRepository<Customer, Long> {
Customer findByNameLike(String name);
}A Spring Data CrudRepository is a Data Access Object (DAO)
that enables an application to perform basic CRUD (i.e. CREATE, READ, UPDATE, DELETE) as well as simple Query
data access operations on a persistent entity (e.g. Customer).
| Review the Spring Data Commons Reference Guide for more details on Working with Spring Data Repositories and Spring Data for Apache Geode’s (SDG) extension and implementation of Spring Data Commons Repository Abstraction. |
2.3. CustomerController interface
OPTIONAL: And, dependent on org.springframework.boot:spring-boot-starter-web, the "Spring Web" dependency.
If you selected the "Spring Web" dependency from the beginning when you generated the project using the
Spring Initializer, then you can create a Spring Web MVC @RestController to access the CRM application
from your Web browser.
CustomerController class@RestController
public class CustomerController {
private static final String HTML = "<H1>%s</H1>";
@Autowired
private CustomerRepository customerRepository;
@GetMapping("/customers")
public Iterable<Customer> findAll() {
return this.customerRepository.findAll();
}
@PostMapping("/customers")
public Customer save(Customer customer) {
return this.customerRepository.save(customer);
}
@GetMapping("/customers/{name}")
public Customer findByName(@PathVariable("name") String name) {
return this.customerRepository.findByNameLike(name);
}
@GetMapping("/")
public String home() {
return format("Customer Relationship Management");
}
@GetMapping("/ping")
public String ping() {
return format("PONG");
}
private String format(String value) {
return String.format(HTML, value);
}
}The CustomerController class is a Spring Web MVC @RestController containing several REST-ful Web service endpoints
for accessing the CRM application via a Web client (e.g. Web browser).
| URL | Description |
|---|---|
GET |
Returns description of the application. |
GET |
Heartbeat request to test that the application is alive and running. |
GET |
Returns a list of all Customers. |
GET |
Returns the named Customer. |
POST |
Accepts JSON and creates a new Customer. |
If you did not enable the Web components by adding the Spring Web dependency to your application classpath, then
no worries, we will still be inspecting the application’s effects on Apache Geode using Gfsh (Apache Geode & Pivotal
GemFire’s shell tool). Of course, you can just add the org.springframework.boot:spring-boot-starter-web dependency
to your Maven POM file as well.
|
2.4. CustomerConfiguration class
The final bit of code required by the CRM application is to take care of some boilerplate configuration.
This will no doubt cause you to pause and think, why do I need any configuration at all if we are using Spring Boot? Doesn’t Spring Boot, and specifically SBDG, Auto-configuration take care of all our non-custom "configuration" needs?
For the most part, YES, and we’ll be reviewing further below what is actually being handled by SBDG, and Spring Boot in general.
But, there are certain cases that not even SBDG will take for granted and assume, which becomes part of your responsibility as the application developer. One example is Region configuration.
2.4.1. Configure the "/Customers" Region
There are many ways to configure a Region and it varies significantly from application Use Case to application Use Case.
First, there are different data management policies (e.g. PARTITION or REPLICATE) that might be applicable depending
on the type of data you store in Apache Geode (e.g. Transactional vs. Reference data). You might need different
Eviction and Expiration policies depending on your user base or workloads. Some data is suited for Off-Heap memory.
Depending on the data management policy of the Region (e.g. PARTITION) you can configure additional per node and total
Region memory usage restrictions, collocate the Region with another Region for use in JOIN Queries, etc.
Still, we want the getting started experience to be as simple and as easy as possible, and to do so in a reliable way, especially during development. So, while SBDG may not provide implicit auto-configuration support for every concern, this does not mean you are left to figure it all out by yourself (e.g. Region configuration).
During development, if you don’t care specifically "how" your data is stored and you just want to simply and rapidly iterate, putting and getting data into and out of Apache Geode, then SBDG can help.
The first thing we will do is annotate our application configuration with SDG’s @EnableEntityDefinedRegions annotation
and set the basePackageClasses attribute to our Customer class:
EnableEntityDefinedRegions.@Configuration
@EnableEntityDefinedRegions(basePackageClasses = Customer.class)
public class CustomerConfiguration { ... }Using the @EnableEntityDefinedRegions annotation is basically equivalent to the JPA entity scan and Hibernate’s
auto-schema creation (DDL generation) based on your JPA annotated entity classes.
The basePackageClasses attribute is a type-safe way to specify the base package or packages for where the entity scan
will begin. It scans for all classes annotated with the @Region mapping annotation in the current package as well as
all sub-packages. If the class is not annotated with @Region then it is not an entity. The entity scan searches down
from the package declared by the class (or classes) specified in the basePackageClasses attribute. Sub-packages are
scanned, nested entity classes are not. The class or classes specified in the basePackageClasses attribute may be
an entity class, but is not required to be an entity class. It is also not necessary to list all classes in the package
and sub-packages. One class per unique top-level package is sufficient.
@EnableEntityDefinedRegions creates Regions local to your application. By default, your SBDG based application is
a ClientCache and therefore will create client Regions for your entities.
The alternative to using @EnableEntityDefinedRegions (or the like) is to define Regions explicitly using Spring
JavaConfig, like so:
@Bean("Customers")
public ClientRegionFactoryBean<Long, Customer> customersRegion(GemFireCache gemfireCache) {
ClientRegionFactoryBean<Long, Customer> clientRegion = new ClientRegionFactoryBean<>();
clientRegion.setCache(gemfireCache);
clientRegion.setShortcut(ClientRegionShortcut.PROXY);
return clientRegion;
}You can also use Spring XML:
<gfe:client-region id="Customers" shortcut="PROXY">2.4.2. Configure the Application to be Cluster-Aware
The final bit of configuration helps determine whether the client application is by itself or whether a cluster of Apache Geode servers are available to manage the application’s data.
During development, you might be iteratively and rapidly developing inside your IDE, debugging and testing new functions locally and then switch to a client/server environment for further integration testing.
Apache Geode requires 1) all client Regions that send data to/from the cluster be *PROXY Regions and 2) that a
server-side Region by the same name exists in the cluster.
Switching the data management policy for all client Regions' from *PROXY to LOCAL when pulling your application code
back inside your IDE locally, where a cluster might not be available, and then having to remember to switch the data
management policy back to *PROXY in addition to creating any new Regions when you add new entity classes before
pushing back up to the client/server environment is a tedious and error-prone task. So, SBDG has introduced the new
@EnableClusterAware annotation for this very purpose.
@EnableClusterAware@Configuration
@EnableClusterAware
public class CustomerConfiguration { ... }The nearly equivalent alternative to @EnableClusterAware is:
@Configuration
@EnableEntityDefinedRegions(clientRegionShortcut = ClientRegionShortcut.LOCAL)
public class CustomerConfiguration { ... }If you switch to a client/server topology, then you would need to remember to change the clientRegionShortcut to
ClientRegionShortcut.PROXY (the default). Of course, you could use Spring Profiles with a profile customized for
each environment where the application will be run. Or, you can just simply use the @EnableClusterAware annotation.
We say "nearly" equivalent because the @EnableClusterAware annotation does much more than control the data management
policy used by your client Regions, particularly when a cluster of servers is available, as we’ll see further below.
The clientRegionShortcut attribute is available for all application-defined Region annotations:
[@EnableEntityDefinedRegions, @EnableCachingDefinedRegions, @EnableClusterDefinedRegions].
|
3. Run the Application Locally
To make it apparent that the CRM application does something, we add the following Spring Boot ApplicationRunner bean
to our main @SpringBootApplication class:
ApplicationRunner in the main @SpringBootApplication class @Bean
ApplicationRunner runner(CustomerRepository customerRepository) {
return args -> {
assertThat(customerRepository.count()).isEqualTo(0);
Customer jonDoe = Customer.newCustomer(1L, "JonDoe");
System.err.printf("Saving Customer [%s]...%n", jonDoe);
jonDoe = customerRepository.save(jonDoe);
assertThat(jonDoe).isNotNull();
assertThat(jonDoe.getId()).isEqualTo(1L);
assertThat(jonDoe.getName()).isEqualTo("JonDoe");
assertThat(customerRepository.count()).isEqualTo(1);
System.err.println("Querying for Customer [SELECT * FROM /Customers WHERE name LIKE '%Doe']...");
Customer queriedJonDoe = customerRepository.findByNameLike("%Doe");
assertThat(queriedJonDoe).isEqualTo(jonDoe);
System.err.printf("Customer was [%s]%n", queriedJonDoe);
};
}
}The runner creates a new Customer "JonDoe", persists "JonDoe" to Apache Geode in the "/Customers" client LOCAL
Region, runs an OQL query to lookup "JonDoe" by name using a wildcard query with the LIKE operator and argument
"%Doe", then asserts that the result is correct.
The example code uses AssertJ to perform assertions inside the ApplicationRunner bean, which means you would
need org.assertj:assertj-core on your application classpath as a compile-time dependency.
|
After running the application again, you should see:
...
... : Started CrmApplication in 5.506010062 seconds (JVM running for 6.114)
Saving Customer [Customer(name=JonDoe)]...
Querying for Customer [SELECT * FROM /Customers WHERE name LIKE '%Doe']...
Customer was [Customer(name=JonDoe)]SBDG, with the help of @EnableEntityDefinedRegions and @EnableClusterAware, along with Spring Data, has already done
quite a bit of work for us:
-
SBDG auto-configured a
ClientCacheinstance required to use Apache Geode in the application. -
The
@EnableEntityDefinedRegionannotation created the required "/Customers" client Region from ourCustomerentity class. -
SBDG auto-configured the Spring Data Repository infrastructure and supplied an implementation for the
CustomerRepositoryinterface. -
The
CustomerRepository.findByName(:String)derived query method applies OO to a framework generated OQL query thereby enabling the application to lookup aCustomergiven a name by simply invoking a POJO method. -
The
@EnableClusterAwareannotation determined the runtime context of the application (e.g. local or client/server).
To show one aspect of SBDG’s auto-configuration at play, what would happen if you did not annotate the application
configuration with @EnableClusterAware?
Then, you would hit the following Exception:
Error starting ApplicationContext. To display the conditions report re-run your application
with 'debug' enabled.
2019-09-16 13:57:46.401 ERROR 10127 --- [ main] o.s.boot.SpringApplication
: Application run failed
java.lang.IllegalStateException: Failed to execute ApplicationRunner
at o.s.b.SpringApplication.callRunner(SpringApplication.java:778)
at o.s.b.SpringApplication.callRunners(SpringApplication.java:765)
at o.s.b.SpringApplication.run(SpringApplication.java:322)
at o.s.b.SpringApplication.run(SpringApplication.java:1226)
at o.s.b.SpringApplication.run(SpringApplication.java:1215)
at example.app.crm.CrmApplication.main(CrmApplication.java:41)
Caused by: o.s.dao.DataAccessResourceFailureException:
nested exception is o.a.g.c.c.NoAvailableServersException
at o.s.d.g.GemfireCacheUtils.convertGemfireAccessException(GemfireCacheUtils.java:235)
at o.s.d.g.GemfireAccessor.convertGemFireAccessException(GemfireAccessor.java:93)
at o.s.d.g.GemfireTemplate.find(GemfireTemplate.java:330)
at o.s.d.g.r.s.SimpleGemfireRepository.count(SimpleGemfireRepository.java:129)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at o.s.d.r.c.s.RepositoryComposition$RepositoryFragments
.invoke(RepositoryComposition.java:371)
at o.s.d.r.c.s.RepositoryComposition.invoke(RepositoryComposition.java:204)
at o.s.d.r.c.s.RepositoryFactorySupport$ImplementationMethodExecutionInterceptor
.invoke(RepositoryFactorySupport.java:657)
at o.s.a.f.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
at o.s.d.r.c.s.RepositoryFactorySupport$QueryExecutorMethodInterceptor
.doInvoke(RepositoryFactorySupport.java:621)
at o.s.d.r.c.s.RepositoryFactorySupport$QueryExecutorMethodInterceptor
.invoke(RepositoryFactorySupport.java:605)
at o.s.a.f.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
at o.s.a.i.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:93)
at o.s.a.f.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186)
at o.s.a.f.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:212)
at com.sun.proxy.$Proxy86.count(Unknown Source)
at example.app.crm.CrmApplication.lambda$runner$0(CrmApplication.java:50)
at o.s.b.SpringApplication.callRunner(SpringApplication.java:775)
... 5 common frames omitted
Caused by: o.a.g.cache.client.NoAvailableServersException: null
at o.a.g.c.c.i.p.ConnectionManagerImpl.borrowConnection(ConnectionManagerImpl.java:265)
at o.a.g.c.c.i.OpExecutorImpl.execute(OpExecutorImpl.java:150)
at o.a.g.c.c.i.OpExecutorImpl.execute(OpExecutorImpl.java:130)
at o.a.g.c.c.i.PoolImpl.execute(PoolImpl.java:792)
at o.a.g.c.c.i.QueryOp.execute(QueryOp.java:59)
at o.a.g.c.c.i.ServerProxy.query(ServerProxy.java:69)
at o.a.g.c.q.i.DefaultQuery.executeOnServer(DefaultQuery.java:328)
at o.a.g.c.q.i.DefaultQuery.execute(DefaultQuery.java:216)
at o.s.d.g.GemfireTemplate.find(GemfireTemplate.java:312)
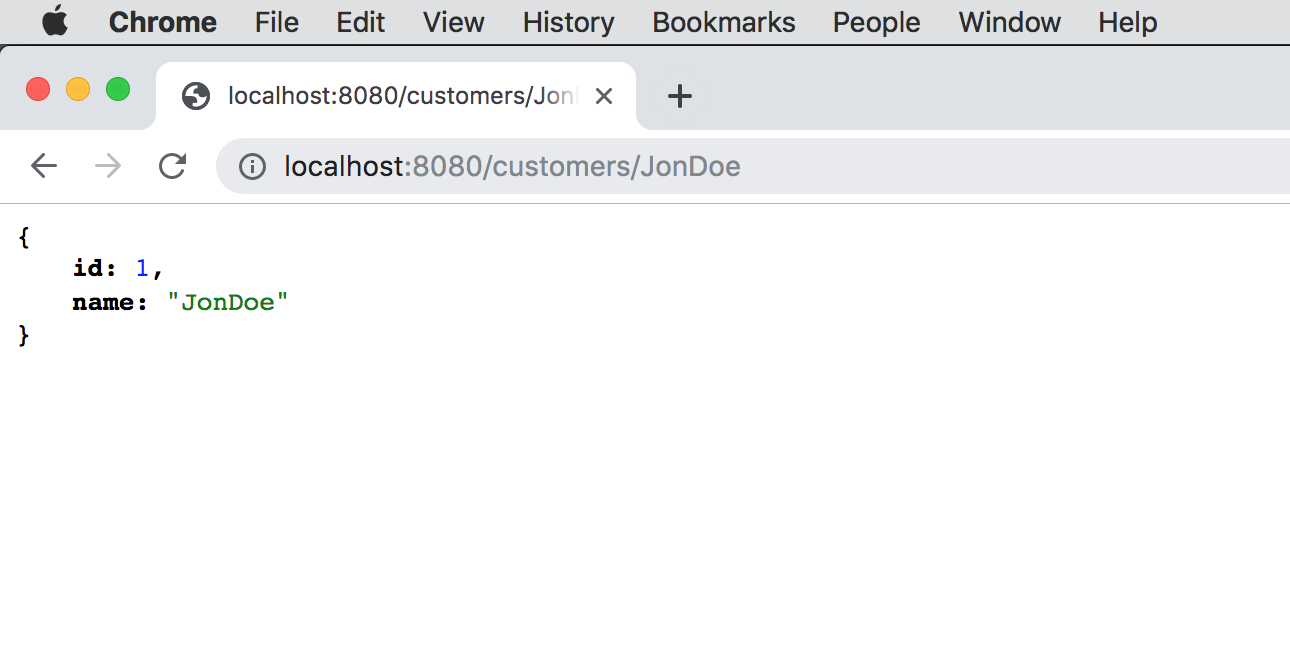
... 23 common frames omittedThe application will continue to run if you included the Spring Web dependencies in your application classpath, in which case, you can then inspect the application using a Web client (e.g. Web browser):
4. Run the Application in a Client/Server Topology
Now that we have a simple Spring Boot, Apache Geode ClientCache application running locally inside our IDE, we want to
expand on this bit and switch to a client/server topology.
Although we are not quite ready to move to a managed cloud platform environment, like Pivotal Platform (formerly known as Pivotal CloudFoundry) using Pivotal Cloud Cache (PCC), we no longer want to maintain the data locally.
Without persistence, we would lose all our data if the client application were shutdown since the data is maintained in-memory. Additionally, by maintaining the data locally, other client applications, or even other instances of our existing application (e.g. in a Microservices landscape) would not be able to use this data, which is useless!
To switch to a client/server topology, we need to first configure and bootstrap an Apache Geode cluster.
The Example Code for this Guide already provides the necessary Geode shell script (Gfsh) to start a cluster:
# Gfsh shell script to start an Apache Geode cluster with 1 Locator and 2 Servers.
start locator --name=LocatorOne --log-level=config
start server --name=ServerOne --log-level=config
start server --name=ServerTwo --log-level=config --server-port=50505The cluster can be conveniently started with the following Gfsh command:
gfsh> run --file=@SBDG_HOME@/spring-geode-samples/intro/getting-started/src/main/resources/geode/bin/start-cluster.gfsh
Be sure to change the @SBDG_HOME@ placeholder variable with the location of your cloned copy of SBDG.
|
The Gfsh shell script starts an Apache Geode cluster with 1 Locator and 2 Servers.
The output from the shell script will look similar to:
gfsh>run --file=.../spring-boot-data-geode/spring-geode-samples/intro/getting-started/src/main/resources/geode/bin/start-cluster.gfsh
1. Executing - start locator --name=LocatorOne --log-level=config
Starting a Geode Locator in /Users/jblum/pivdev/lab/LocatorOne...
.......
Locator in /Users/jblum/pivdev/lab/LocatorOne on 10.99.199.24[10334] as LocatorOne is currently online.
Process ID: 10429
Uptime: 5 seconds
Geode Version: 1.9.0
Java Version: 1.8.0_192
Log File: /Users/jblum/pivdev/lab/LocatorOne/LocatorOne.log
JVM Arguments: -Dgemfire.enable-cluster-configuration=true
-Dgemfire.load-cluster-configuration-from-dir=false
-Dgemfire.log-level=config
-Dgemfire.launcher.registerSignalHandlers=true
-Djava.awt.headless=true
-Dsun.rmi.dgc.server.gcInterval=9223372036854775806
Class-Path: .../apache-geode-1.9.0/lib/geode-core-1.9.0.jar:.../apache-geode-1.9.0/lib/geode-dependencies.jar
Successfully connected to: JMX Manager [host=10.99.199.24, port=1099]
Cluster configuration service is up and running.
2. Executing - start server --name=ServerOne --log-level=config
Starting a Geode Server in /Users/jblum/pivdev/lab/ServerOne...
....
Server in /Users/jblum/pivdev/lab/ServerOne on 10.99.199.24[40404] as ServerOne is currently online.
Process ID: 10439
Uptime: 3 seconds
Geode Version: 1.9.0
Java Version: 1.8.0_192
Log File: /Users/jblum/pivdev/lab/ServerOne/ServerOne.log
JVM Arguments: -Dgemfire.default.locators=10.99.199.24[10334]
-Dgemfire.start-dev-rest-api=false
-Dgemfire.use-cluster-configuration=true
-Dgemfire.log-level=config
-XX:OnOutOfMemoryError=kill -KILL %p
-Dgemfire.launcher.registerSignalHandlers=true
-Djava.awt.headless=true
-Dsun.rmi.dgc.server.gcInterval=9223372036854775806
Class-Path: .../apache-geode-1.9.0/lib/geode-core-1.9.0.jar
:.../apache-geode-1.9.0/lib/geode-dependencies.jar
3. Executing - start server --name=ServerTwo --log-level=config --server-port=50505
Starting a Geode Server in /Users/jblum/pivdev/lab/ServerTwo...
...
Server in /Users/jblum/pivdev/lab/ServerTwo on 10.99.199.24[50505] as ServerTwo is currently online.
Process ID: 10443
Uptime: 2 seconds
Geode Version: 1.9.0
Java Version: 1.8.0_192
Log File: /Users/jblum/pivdev/lab/ServerTwo/ServerTwo.log
JVM Arguments: -Dgemfire.default.locators=10.99.199.24[10334]
-Dgemfire.start-dev-rest-api=false
-Dgemfire.use-cluster-configuration=true
-Dgemfire.log-level=config
-XX:OnOutOfMemoryError=kill -KILL %p
-Dgemfire.launcher.registerSignalHandlers=true
-Djava.awt.headless=true
-Dsun.rmi.dgc.server.gcInterval=9223372036854775806
Class-Path: .../apache-geode-1.9.0/lib/geode-core-1.9.0.jar
:.../apache-geode-1.9.0/lib/geode-dependencies.jar
************************* Execution Summary ***********************
Script file: .../spring-boot-data-geode/spring-geode-samples/intro/getting-started/src/main/resources/geode/bin/start-cluster.gfsh
Command-1 : start locator --name=LocatorOne --log-level=config
Status : PASSED
Command-2 : start server --name=ServerOne --log-level=config
Status : PASSED
Command-3 : start server --name=ServerTwo --log-level=config --server-port=50505
Status : PASSEDAfter the cluster is started, Gfsh will connect to the Locator/Manager where you can then inspect the cluster:
gfsh>list members
Name | Id
---------- | ------------------------------------------------------------------
LocatorOne | 10.99.199.24(LocatorOne:10429:locator)<ec><v0>:41000 [Coordinator]
ServerOne | 10.99.199.24(ServerOne:10439)<v1>:41001
ServerTwo | 10.99.199.24(ServerTwo:10443)<v2>:41002
gfsh>describe member --name=ServerOne
Name : ServerOne
Id : 10.99.199.24(ServerOne:10439)<v1>:41001
Host : 10.99.199.24
Regions :
PID : 10439
Groups :
Used Heap : 97M
Max Heap : 3641M
Working Dir : /Users/jblum/pivdev/lab/ServerOne
Log file : /Users/jblum/pivdev/lab/ServerOne/ServerOne.log
Locators : 10.99.199.24[10334]
Cache Server Information
Server Bind :
Server Port : 40404
Running : true
Client Connections : 0
gfsh>describe member --name=ServerTwo
Name : ServerTwo
Id : 10.99.199.24(ServerTwo:10443)<v2>:41002
Host : 10.99.199.24
Regions :
PID : 10443
Groups :
Used Heap : 96M
Max Heap : 3641M
Working Dir : /Users/jblum/pivdev/lab/ServerTwo
Log file : /Users/jblum/pivdev/lab/ServerTwo/ServerTwo.log
Locators : 10.99.199.24[10334]
Cache Server Information
Server Bind :
Server Port : 50505
Running : true
Client Connections : 0Note that we do not currently have any server-side Regions (e.g. "/Customers") defined. This is deliberate!
gfsh>list regions
No Regions FoundNow, without any code or configuration changes, simply run the CRM application again!
...
... : Started CrmApplication in 6.418627159 seconds (JVM running for 6.978)
Saving Customer [Customer(name=JonDoe)]...
... : Caching PdxType[dsid=0, typenum=3302226
name=example.app.crm.model.Customer
fields=[
id:Object:identity:0:idx0(relativeOffset)=0:idx1(vlfOffsetIndex)=-1
name:String:1:1:idx0(relativeOffset)=0:idx1(vlfOffsetIndex)=1]]
Querying for Customer [SELECT * FROM /Customers WHERE name LIKE '%Doe']...
Customer was [Customer(name=JonDoe)]The output is nearly identical except for the PDX Type metadata registration. We will explain this more below.
Now, list Regions in the cluster again, using Gfsh:
gfsh>list regions
List of regions
---------------
CustomersThe "/Customers" Region has been magically created!
When we describe the "/Customers" Region, we can see that it has 1 entry:
gfsh>describe region --name=/Customers
Name : Customers
Data Policy : partition
Hosting Members : ServerTwo
ServerOne
Non-Default Attributes Shared By Hosting Members
Type | Name | Value
------ | ----------- | ---------
Region | size | 1
| data-policy | PARTITIONThe "/Customers" Region entry is from the Spring Boot ApplicationRunner bean, which added Customer "JonDoe"
at runtime during startup of the application.
You will also notice that the server-side "/Customers" Region is created as a PARTITION Region, which provides
the best data management policy and organization for transactional data. The "/Customers" Region is being hosted
on our 2 Servers, "ServerOne" and "ServerTwo".
| You must have redundancy (and optionally, persistence) configured in your cluster to prevent (complete) data loss, which forms the basis for high-availability (HA) in Apache Geode and Pivotal Cloud Cache (PCC). |
We can query "JonDoe" from Gfsh:
gfsh>query --query="SELECT customer.id, customer.name FROM /Customers customer"
Result : true
Limit : 100
Rows : 1
id | name
-- | ------
1 | JonDoeThanks to the @EnableClusterAware annotation, the application seamlessly switched from local to a client/server
topology without so much as a single line of code, or any configuration changes!
Technically, SBDG identified the configuration of the client application and pushed configuration metadata for the required server-side, "/Customers" Region up to the cluster. Not only that, but the configuration metadata was sent in such a way that the cluster will remember the configuration on restarts and when new nodes are added, they will get the same configuration.
For instance, if we start another server, it too will have the "/Customers" Region, which is important when you are "scaling-out".
gfsh>start server --name=ServerThree --log-level=config --server-port=12345
Starting a Geode Server in /Users/jblum/pivdev/lab/ServerThree...
...
Server in /Users/jblum/pivdev/lab/ServerThree on 10.99.199.24[12345] as ServerThree is currently online.
Process ID: 10616
Uptime: 3 seconds
Geode Version: 1.9.0
Java Version: 1.8.0_192
Log File: /Users/jblum/pivdev/lab/ServerThree/ServerThree.log
JVM Arguments: -Dgemfire.default.locators=10.99.199.24[10334]
-Dgemfire.start-dev-rest-api=false
-Dgemfire.use-cluster-configuration=true
-Dgemfire.log-level=config
-XX:OnOutOfMemoryError=kill -KILL %p
-Dgemfire.launcher.registerSignalHandlers=true
-Djava.awt.headless=true
-Dsun.rmi.dgc.server.gcInterval=9223372036854775806
Class-Path: .../apache-geode-1.9.0/lib/geode-core-1.9.0.jar
:.../apache-geode-1.9.0/lib/geode-dependencies.jar
gfsh>list members
Name | Id
----------- | ------------------------------------------------------------------
LocatorOne | 10.99.199.24(LocatorOne:10429:locator)<ec><v0>:41000 [Coordinator]
ServerOne | 10.99.199.24(ServerOne:10439)<v1>:41001
ServerTwo | 10.99.199.24(ServerTwo:10443)<v2>:41002
ServerThree | 10.99.199.24(ServerThree:10616)<v3>:41003
gfsh>describe member --name=ServerThree
Name : ServerThree
Id : 10.99.199.24(ServerThree:10616)<v3>:41003
Host : 10.99.199.24
Regions : Customers
PID : 10616
Groups :
Used Heap : 98M
Max Heap : 3641M
Working Dir : /Users/jblum/pivdev/lab/ServerThree
Log file : /Users/jblum/pivdev/lab/ServerThree/ServerThree.log
Locators : 10.99.199.24[10334]
Cache Server Information
Server Bind :
Server Port : 12345
Running : true
Client Connections : 0You can see that "ServerThree" is hosting the "/Customers" Region.
| You can still access this application from your Web client (e.g. Web browser) and view the data. |
Once again, SBDG is providing you with tremendous power and convenience that you may not be aware of.
While there are very apparent things happening, there are also a few non-apparent things happening as well. In addition to the aforementioned things in the last section, we are now benefiting from:
-
SBDG appropriately configured and relied on Apache Geode internal features to connect the client to the cluster.
-
Configuration metadata for our application’s required client Regions (e.g. "/Customers") was sent to the cluster and created on the servers to leverage the client/server topology.
-
SBDG auto-configured PDX, Apache Geode’s highly powerful Serialization framework and alternative to Java Serialization.
Once we migrate to a managed cloud platform environment, we’ll see the full effects of SBDG’s auto-configuration at play.
5. Run the Application in a Cloud Platform Environment
Now that we have built and ran our application locally as well as in a client/server topology, we are ready to push the application to a managed cloud platform environment, like Pivotal Platform using Pivotal Cloud Cache (PCC).
This is the final step in our journey to the cloud and SBDG makes this a non-event!
While SBDG handles most application development concerns, Pivotal Cloud Cache (PCC), in conjunction with Pivotal Platform, handles most operational concerns.
Once you have acquired a Pivotal Platform environment and installed the required tools (e.g. CF CLI), then you can package the application and deploy (i.e. "push") it to Pivotal Platform.
Before we package the application, we must switch the "Spring (Boot) for Apache Geode" dependency in our application Maven POM file from:
<dependency>
<groupId>org.springframework.geode</groupId>
<artifactId>spring-geode-starter</artifactId>
<version>1.2.13.RELEASE</version>
</dependency>To:
<dependency>
<groupId>org.springframework.geode</groupId>
<artifactId>spring-gemfire-starter</artifactId>
<version>1.2.13.RELEASE</version>
</dependency>| See the Appendix for more details on making the switch. |
Additionally, and specifically when deploying to Pivotal Platform, we will create a manifest.yml file
containing details about the services our application requires at runtime to function properly up in the cloud:
---
applications:
- name: crm-app
memory: 768M
instances: 1
path: ./build/libs/spring-geode-samples-getting-started-1.2.0.BUILD-SNAPSHOT.jar
services:
- pccServiceOne
buildpacks:
- https://github.com/cloudfoundry/java-buildpack.gitThe manifest.yml file is a type of deployment descriptor for our application to inform the cloud platform about
the runtime environment required to run our application.
In order to properly package the application for deployment to a managed cloud platform environment, such as Pivotal Platform, you use the Spring Boot Maven Plugin, which was added to the generated project by Spring Initializer:
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>Then, you only need to run the mvn command from the command-line to package the CRM application:
$ mvn clean packageThis will produce artifacts similar to:
$ ls -la target/
total 135232
drwxr-xr-x 11 jblum staff 352 Sep 16 18:21 .
drwxr-xr-x@ 10 jblum staff 320 Sep 16 18:21 ..
drwxr-xr-x 4 jblum staff 128 Sep 16 18:21 classes
-rw-r--r-- 1 jblum staff 69230815 Sep 16 18:21 crm-0.0.1-SNAPSHOT.jar
-rw-r--r-- 1 jblum staff 2715 Sep 16 18:21 crm-0.0.1-SNAPSHOT.jar.original
drwxr-xr-x 3 jblum staff 96 Sep 16 18:21 generated-sources
drwxr-xr-x 3 jblum staff 96 Sep 16 18:21 generated-test-sources
drwxr-xr-x 3 jblum staff 96 Sep 16 18:21 maven-archiver
drwxr-xr-x 3 jblum staff 96 Sep 16 18:21 maven-status
drwxr-xr-x 4 jblum staff 128 Sep 16 18:21 surefire-reports
drwxr-xr-x 3 jblum staff 96 Sep 16 18:21 test-classesThe crm-0.0.1-SNAPSHOT.jar file contains the entire application: classes, configuration files and all the dependencies
needed to run this application in the cloud.
Now, we are ready to deploy, or "push" our CRM application up to the cloud.
The first thing you will need to do is login to your Pivotal Platform environment from the command-line
using the CF CLI tool (i.e. cf):
| The following CF CLI commands show what we did in our Pivotal Platform environment. You will follow a similar procedure for your Pivotal Platform environment. Sensitive information has be stared (*) out. |
$ cf login -a <your API endpoint here> --sso
API endpoint: *****
Temporary Authentication Code ( Get one at https://login.run.****/passcode )>
Authenticating...
OK
Select an org (or press enter to skip):
1. pivot-jblum
Org>
API endpoint: https://api.run.***** (API version: 2.139.0)
User: *****
No org or space targeted, use 'cf target -o ORG -s SPACE'The "Temporary Authentication Code" (i.e. "passcode") is obtained by following the provided HTTPS URL in your Web browser.
After you successfully authenticate you can set your target Org and Space to which your Spring Boot applications will be deployed:
$ cf target -o pivot-jblum -s playground
api endpoint: https://api.run.*****
api version: 2.139.0
user: *****
org: pivot-jblum
space: playgroundNow you can push your CRM, Spring Boot application up to your cloud environment:
$ cf push crm-app -u none --no-start -p build/libs/spring-geode-samples-getting-started-1.2.0.BUILD-SNAPSHOT.jar
Pushing from manifest to org pivot-jblum / space playground as *****...
Using manifest file .../spring-boot-data-geode/spring-geode-samples/intro/getting-started/manifest.yml
Getting app info...
Creating app with these attributes...
+ name: crm-app
path: .../spring-boot-data-geode/spring-geode-samples/intro/getting-started/build/libs
/spring-geode-samples-getting-started-1.2.13.RELEASE.jar
buildpacks:
+ https://github.com/cloudfoundry/java-buildpack.git
+ health check type: none
+ instances: 1
+ memory: 768M
services:
+ pccServiceOne
routes:
+ crm-app.apps.*****
Creating app crm-app...
Mapping routes...
Binding services...
Comparing local files to remote cache...
Packaging files to upload...
Uploading files...
14.23 MiB / 14.23 MiB [===============================================================================================
==========================================================================================================] 100.00% 22s
Waiting for API to complete processing files...
name: crm-app
requested state: stopped
routes: crm-app.apps.*****
last uploaded:
stack:
buildpacks:
type: web
instances: 0/1
memory usage: 768M
state since cpu memory disk details
#0 down 2019-09-27T06:12:32Z 0.0% 0 of 0 0 of 0The CRM, Spring Boot application is now deployed to the cloud.
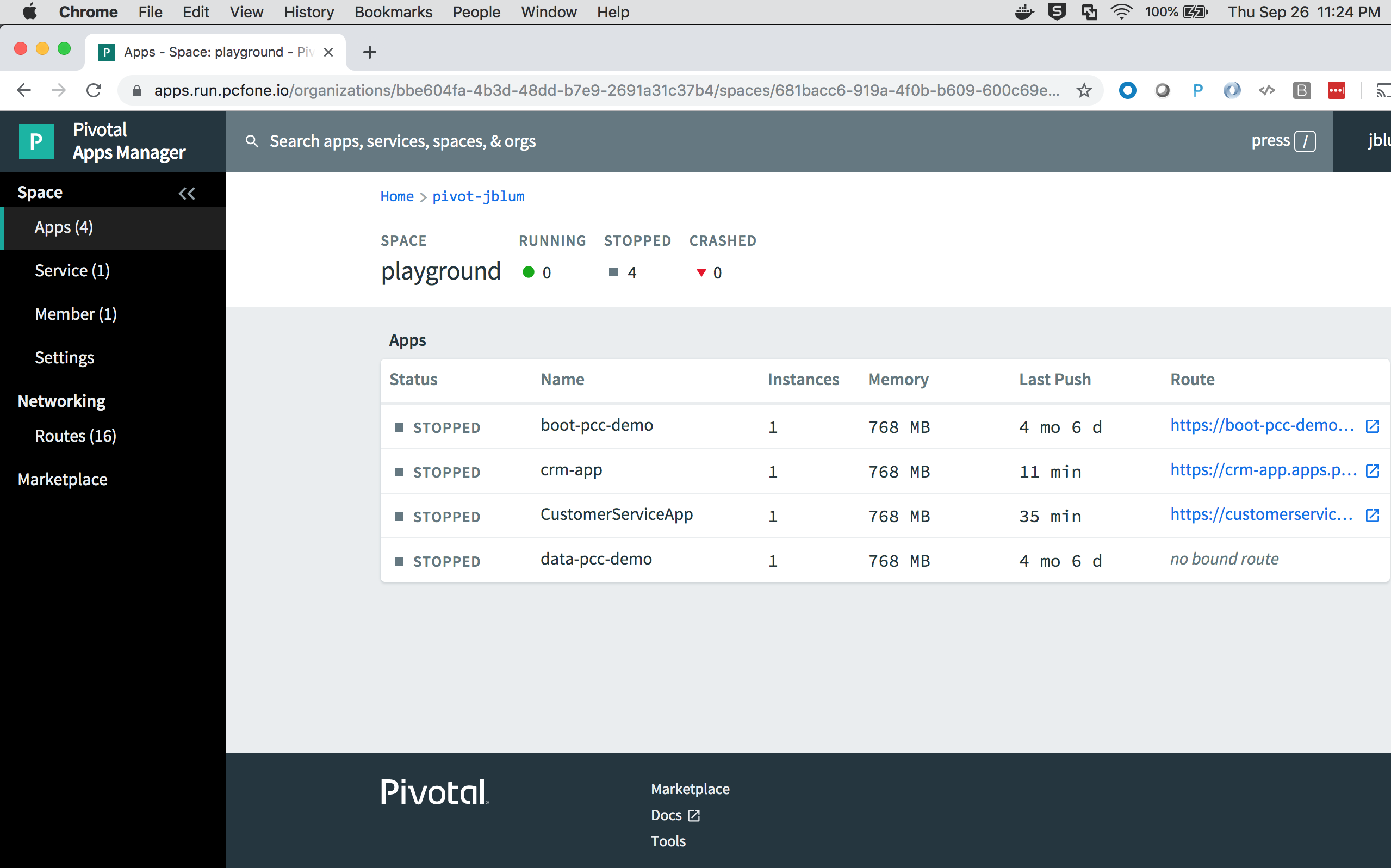
We can list the deployed apps and their current state:
$ cf apps
Getting apps in org pivot-jblum / space playground as *****...
OK
name requested state instances memory disk urls
boot-pcc-demo stopped 0/1 768M 1G boot-pcc-demo-fantastic-kudu.apps.*****
crm-app stopped 0/1 768M 1G crm-app.apps.*****
CustomerServiceApp stopped 0/1 768M 1G customerserviceapp.apps.*****
data-pcc-demo stopped 0/1 768M 1GWe see the "crm-app" in the table of apps, which is currently stopped.
We can either start and stop the app, restage the app, bind services, and so on, all from the command-line using cf,
or we can perform these actions from within Pivotal AppsManager, which is what we will do:
Again, we see the "crm-app". You can click on the app name and drill in to get more details:
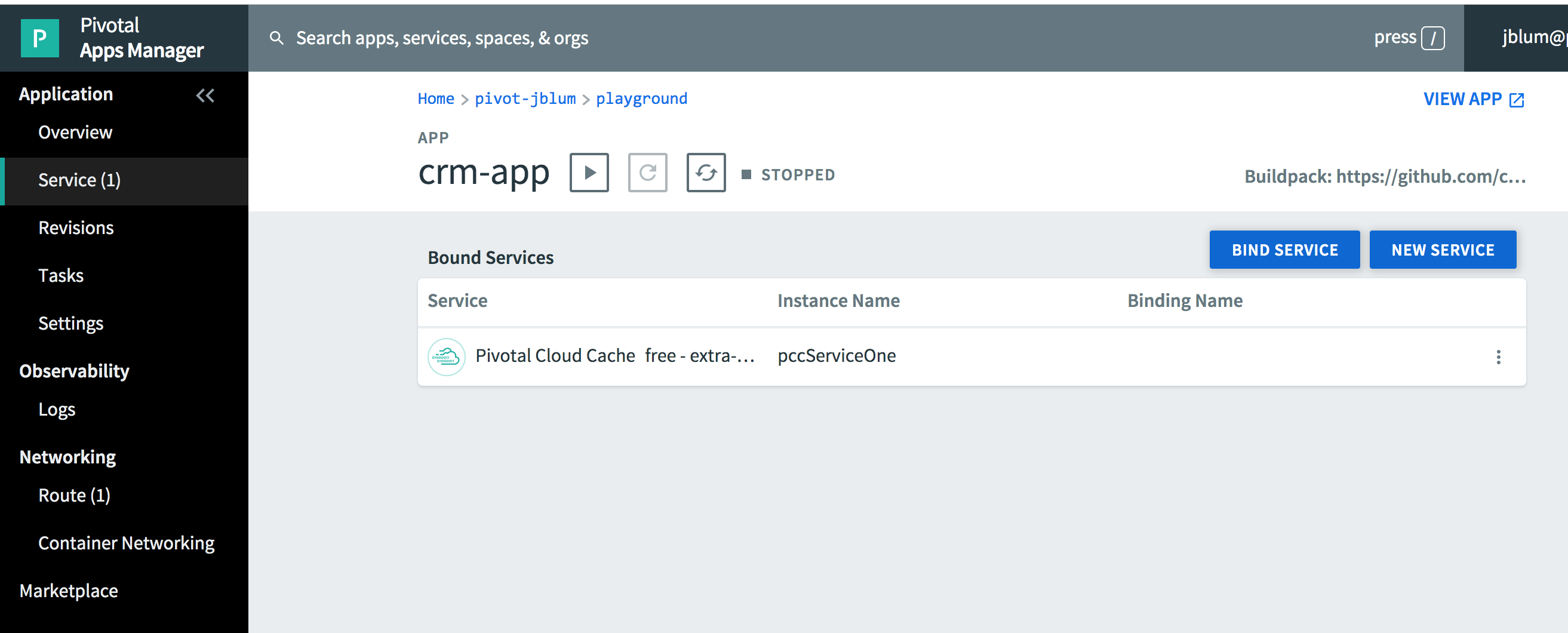
If you click on "Service (1)" in the left navigation bar, you will see that the "crm-app" is bound to the "pccServiceOne" Pivotal Cloud Cache service instance:
If you click on "Settings" in the left navigation bar and "REVEAL ENV VARS" you will find the "Gfsh login string" that you can use to connect to the Pivotal Cloud Cache cluster using Gfsh from your local development environment:
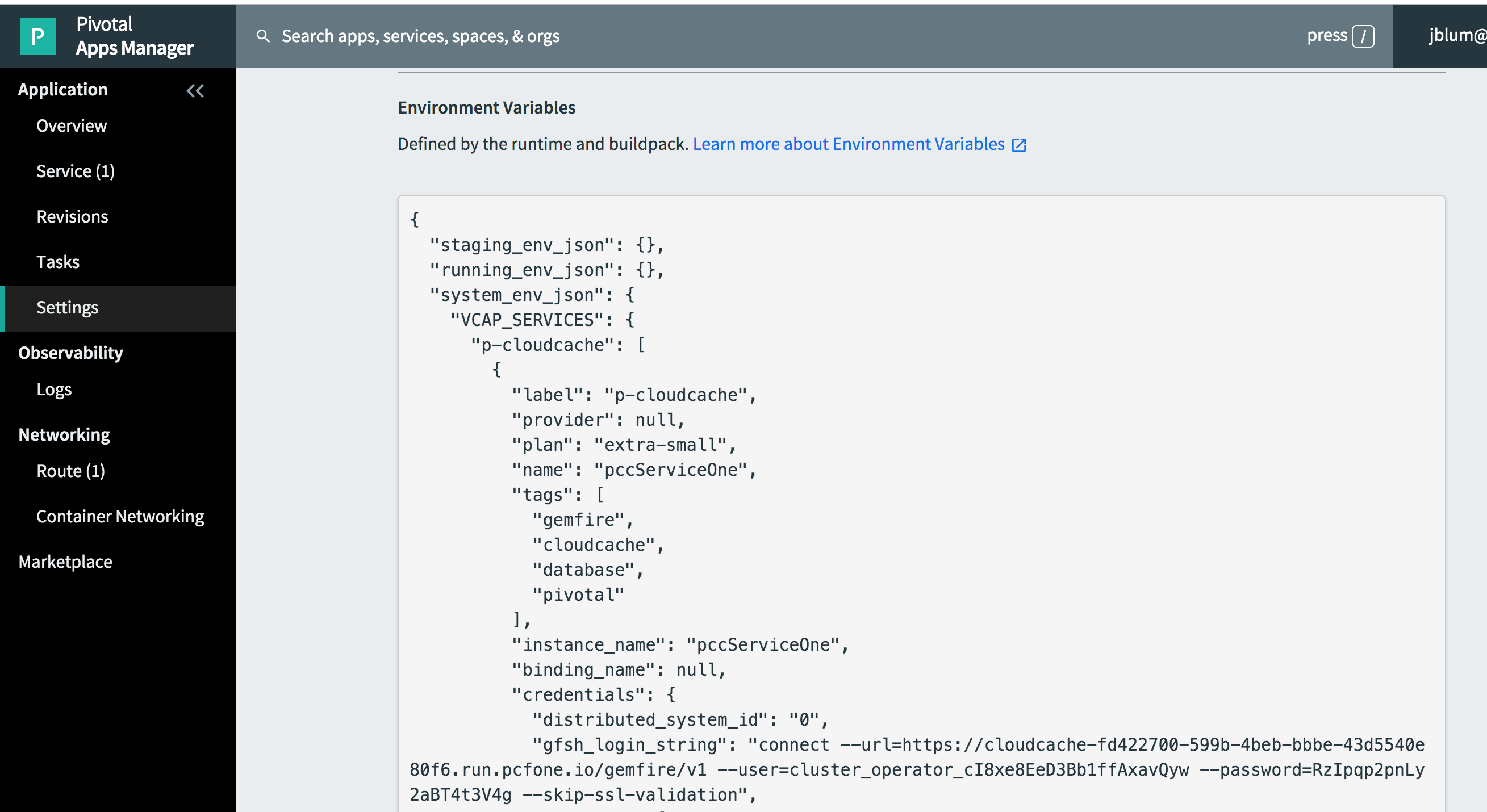
Let’s do that now. Copy the "Gfsh login string" and enter it in Gfsh:
$ echo $GEMFIRE
/Users/jblum/pivdev/pivotal-gemfire-9.8.4
$ gfsh
_________________________ __
/ _____/ ______/ ______/ /____/ /
/ / __/ /___ /_____ / _____ /
/ /__/ / ____/ _____/ / / / /
/______/_/ /______/_/ /_/ 9.8.4
Monitor and Manage Pivotal GemFire
gfsh>connect --url=https://cloudcache-fd422700-599b-4beb-bbbe-43d5540e80f6.run.*****/gemfire/v1
--user=cluster_operator_cI8xe8EeD3Bb1ffAxavQyw --password=RzIpqp2pnLy2aBT4t3V4g
--skip-ssl-validation
key-store:
key-store-password:
key-store-type(default: JKS):
trust-store:
trust-store-password:
trust-store-type(default: JKS):
ssl-ciphers(default: any):
ssl-protocols(default: any):
ssl-enabled-components(default: all):
Successfully connected to: GemFire Manager HTTP service @ https://cloudcache-fd422700-599b-4beb-bbbe-43d5540e80f6.run.*****/gemfire/v1
Cluster-0 gfsh>list members
Name | Id
------------------------------------------------ | -------------------------------------------------------------------------------------
locator-1cabab56-b2d2-4ed9-8931-a1ea64cd8ce2 | 192.168.12.32(locator-1cabab56-b2d2-4ed9-8931-a1ea64cd8ce2:6:locator)<ec><v163>:56152
locator-0dd76536-7bb0-43d7-ae98-f2d0389b66ae | 192.168.14.38(locator-0dd76536-7bb0-43d7-ae98-f2d0389b66ae:6:locator)<ec><v173>:56152
locator-38e07e17-18cb-45ab-bdf1-69201c1c8db9 | 192.168.14.39(locator-38e07e17-18cb-45ab-bdf1-69201c1c8db9:6:locator)<ec><v181>:56152
cacheserver-b7a9665a-e672-42c9-b8f6-e2ada2cbf003 | 192.168.14.40(cacheserver-b7a9665a-e672-42c9-b8f6-e2ada2cbf003:7)<v183>:56152
cacheserver-5a9305cf-7bd9-47c4-b624-3ef37c8ab92e | 192.168.14.79(cacheserver-5a9305cf-7bd9-47c4-b624-3ef37c8ab92e:6)<v185>:56152
cacheserver-7c8e247d-c6ae-42a6-88b0-ce5d61062463 | 192.168.14.80(cacheserver-7c8e247d-c6ae-42a6-88b0-ce5d61062463:7)<v187>:56152
cacheserver-a2234d3d-bc38-4acf-bf37-487bdc3e7842 | 192.168.14.81(cacheserver-a2234d3d-bc38-4acf-bf37-487bdc3e7842:7)<v189>:56152
Cluster-0 gfsh>list regions
No Regions FoundNow, we can start the CRM, Spring Boot application using Pivotal AppsManager from the "crm-app Overview" page.
The "crm-app" will be staged and then started:
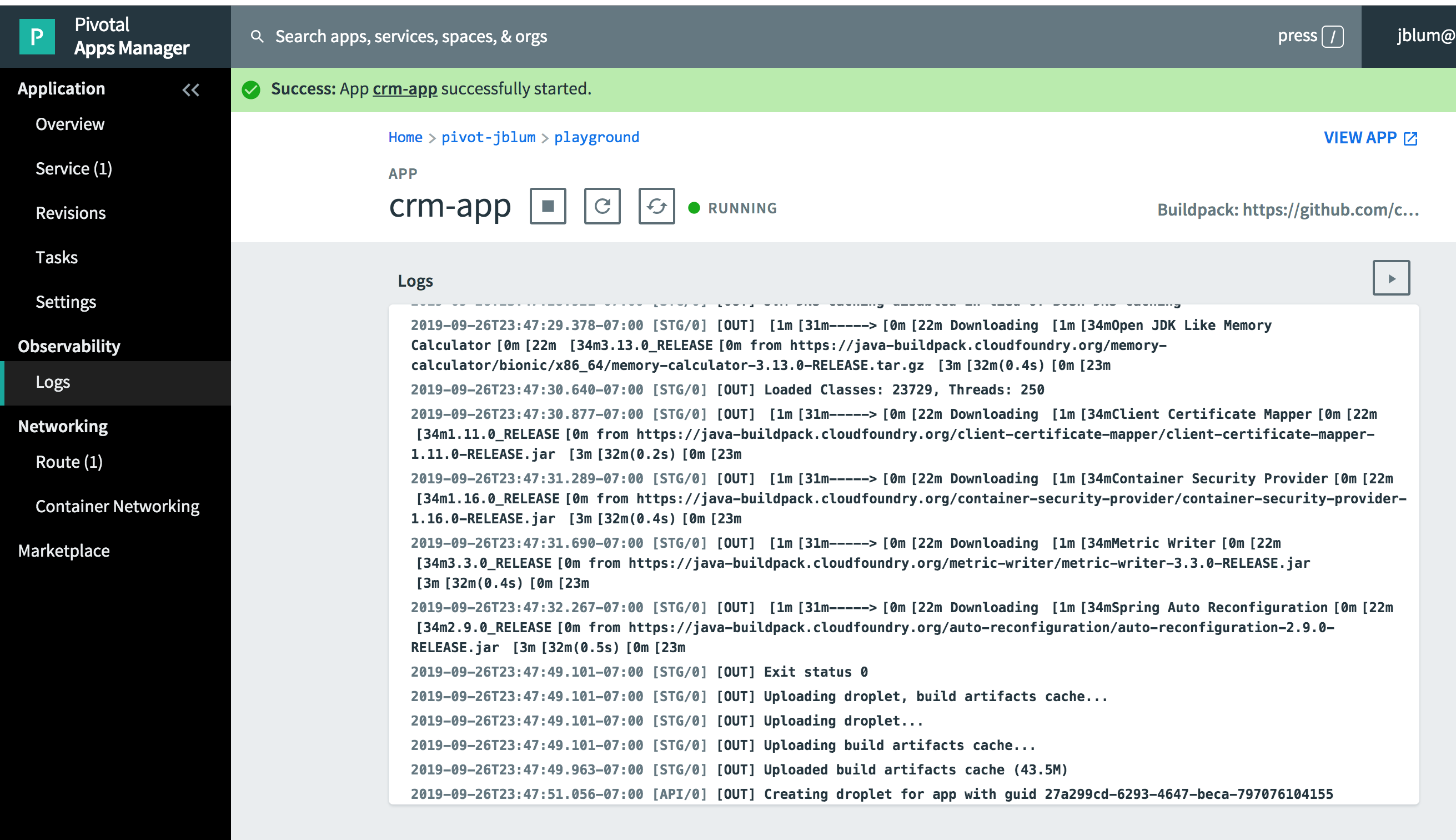
Click the "play" button in the upper right corner above the log output frame to tail the log file of the CRM, Spring Boot application. Eventually, you should see the application log the interaction with "JonDoe".
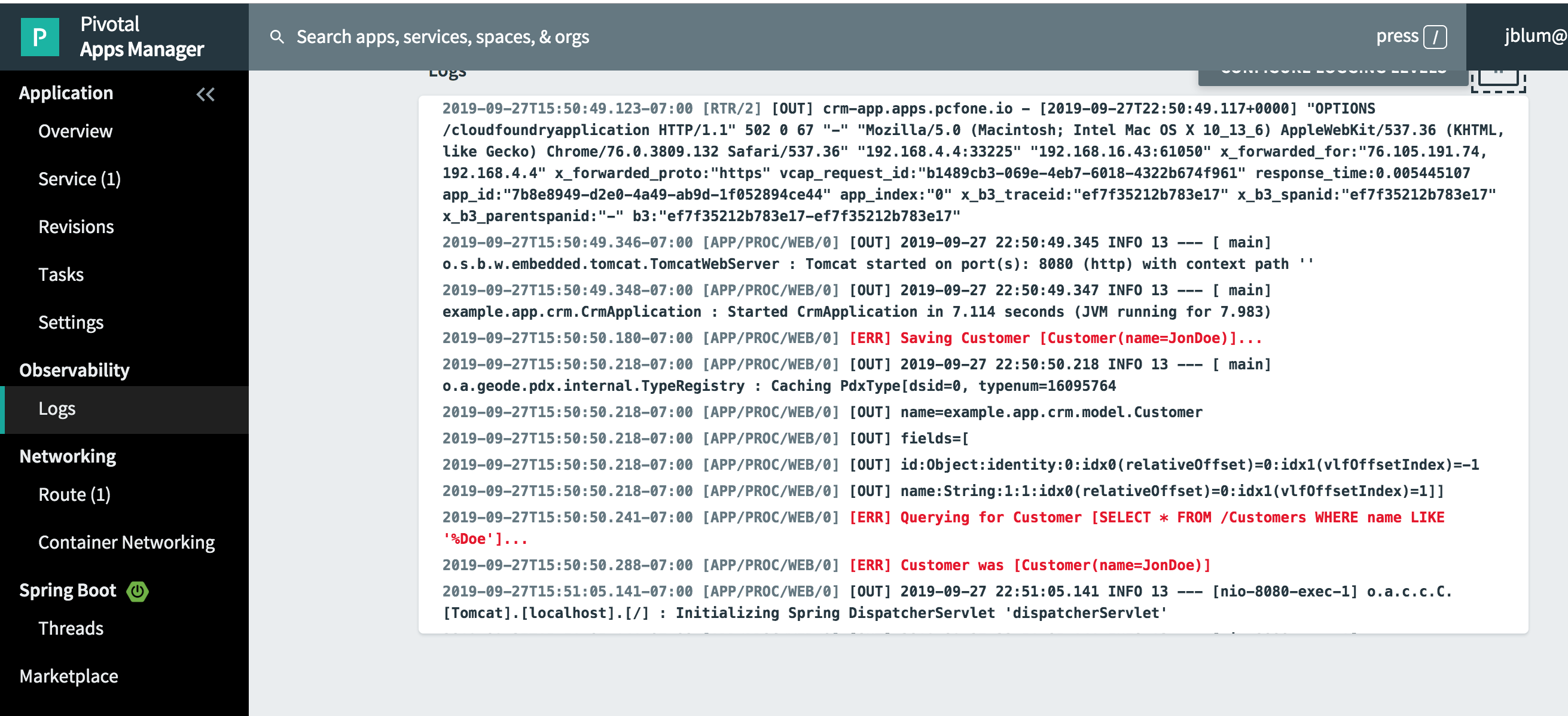
As you can see in the image above, the application successfully logged the interactions with "JonDoe". This only
appears in red "[ERR]" since the interactions with logged with System.err.printf statements.
If you now click on "VIEW APP" link in the upper right-hand corner, it will open a new tab to the CRM Web app’s home page:
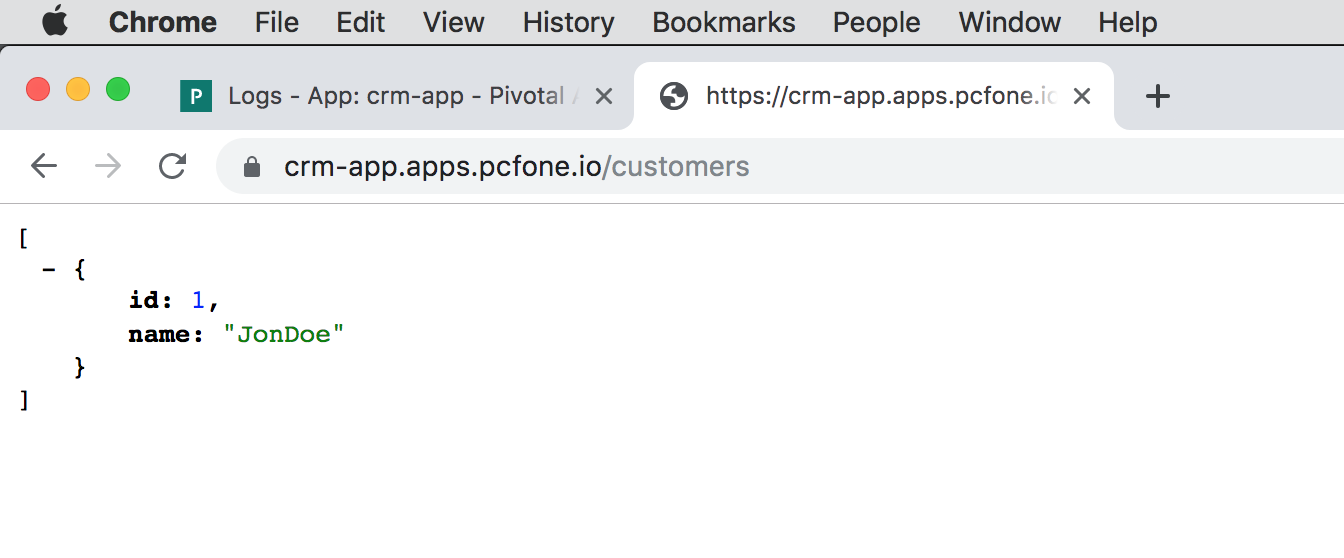
Then, you get all customers in JSON by using HTTP GET http://host:port/customers REST API Web service endpoint:
Now, back in Gfsh, you can see that the 1) "/Customers" Region was added to the cluster of PCC servers and that 2) "JonDoe" was persisted to the cluster and you are able to query for "JonDoe".
Cluster-0 gfsh>list regions
List of regions
---------------
Customers
Cluster-0 gfsh>describe region --name=/Customers
Name : Customers
Data Policy : partition
Hosting Members : cacheserver-a2234d3d-bc38-4acf-bf37-487bdc3e7842
cacheserver-5a9305cf-7bd9-47c4-b624-3ef37c8ab92e
cacheserver-7c8e247d-c6ae-42a6-88b0-ce5d61062463
cacheserver-b7a9665a-e672-42c9-b8f6-e2ada2cbf003
Non-Default Attributes Shared By Hosting Members
Type | Name | Value
------ | ----------- | ---------
Region | size | 1
| data-policy | PARTITION
Cluster-0 gfsh>query --query="SELECT customer.id, customer.name FROM /Customers customer"
Result : true
Limit : 100
Rows : 1
id | name
-- | ------
1 | JonDoeYou successfully deployed the CRM, Spring Boot Apache Geode/Pivotal Cloud Cache ClientCache application to the cloud!
In this final incarnation of our CRM, Spring Boot application, SBDG yet again handled many different concerns for us so we did not need to. This is in addition to all the things mentioned above when running the application locally as well as running the application using a client/server topology. Now, we also benefit from:
-
SBDG figures out the connection criteria needed to connect your client to the servers in the Pivotal Cloud Cache (PCC) cluster, which is technically extracted from the VCAP environment. SBDG will connect the Spring Boot app to the PCC Locators.
-
SBDG automatically authenticates your Spring Boot app with the PCC cluster providing your app was correctly bound to the PCC service instance so the app can access the servers in the cluster.
-
If Transport Layer Security (TLS) were required and SSL enabled, you could simply set the
spring.data.gemfire.security.ssl.use-default-contextproperty in Spring Boot’sapplication.propertiesand SBDG would connect your client to the Locator(s) and Servers in the PCC cluster using SSL. -
SBDG still sends configuration metadata to the PCC cluster to ensure the correct Region and Index configuration on the server-side to match your client app.
This is very powerful, and it greatly simplifies development, especially are you traversing environments.
6. Running the Application in a Hybrid Environment
While it is possible to run the CRM, Spring Boot ClientCache application in a Hybrid Cloud Environment, we will not
specifically cover the details of doing so in this guide.
Running in a Hybrid Cloud Environment specifically means deploying your CRM, Spring Boot ClientCache application to
a managed cloud platform environment, such as Pivotal Platform, but connect the app to an externally managed
Apache Geode or Pivotal GemFire cluster, i.e. the GemFire/Geode cluster is running and managed off platform.
| As of this writing, the inverse is also being explored, running your Spring Boot applications off platform, but connecting those apps to managed data services (e.g. Pivotal Cloud Cache (PCC)) on platform. |
There may be cases where you are unable to move your data management architecture for your applications entirely to the cloud. In those cases, SBDG supports a Hybrid Cloud Architecture, that is both an on-prem and off-prem arrangement. Indeed, this is perhaps a crucial step in moving to the cloud, being able to migrate application services when it is applicable or possible to do so.
You can find more information on running in a Hybrid Cloud Environment, here.
7. Summary
In this guide, we saw first-hand the power of Spring Boot for Apache Geode (SBDG) when building Apache Geode powered Spring Boot applications.
Apache Geode can truly make your Spring Boot applications highly resilient to failures, highly available, performant (i.e. high throughput and low latency), without sacrificing consistency, which is paramount to any data intensive application.
SBDG handles a lot of low-level application concerns so you do not have to. Your focus, as an application developer, can remain on building the application to meet your customers' needs, collect feedback, iterate rapidly, and realize the value proposition sooner.
Indeed, our intended goal is to make developing Apache Geode applications with Spring, and Spring Boot in particular, a highly productive and enjoyable experience.
We hope you enjoy!