In the Section 4.2, “Batch File Ingest” sample we built a Spring Batch application that Spring Cloud Data Flow launched as a task to process a file. This time we will build on that sample to create and deploy a stream that launches that task. The stream will poll an SFTP server and, for each new file that it finds, will download the file and launch the batch job to process it.
The source for the demo project is located in the batch/file-ingest directory at the top-level of this repository.
- A Running Data Flow Shell
The Spring Cloud Data Flow Shell is available for download or you can build it yourself.
![[Note]](images/note.png) | Note |
|---|---|
the Spring Cloud Data Flow Shell and Local server implementation are in the same repository and are both built by running |
To run the Shell open a new terminal session:
$ cd <PATH/TO/SPRING-CLOUD-DATAFLOW-SHELL-JAR> $ java -jar spring-cloud-dataflow-shell-<VERSION>.jar ____ ____ _ __ / ___| _ __ _ __(_)_ __ __ _ / ___| | ___ _ _ __| | \___ \| '_ \| '__| | '_ \ / _` | | | | |/ _ \| | | |/ _` | ___) | |_) | | | | | | | (_| | | |___| | (_) | |_| | (_| | |____/| .__/|_| |_|_| |_|\__, | \____|_|\___/ \__,_|\__,_| ____ |_| _ __|___/ __________ | _ \ __ _| |_ __ _ | ___| | _____ __ \ \ \ \ \ \ | | | |/ _` | __/ _` | | |_ | |/ _ \ \ /\ / / \ \ \ \ \ \ | |_| | (_| | || (_| | | _| | | (_) \ V V / / / / / / / |____/ \__,_|\__\__,_| |_| |_|\___/ \_/\_/ /_/_/_/_/_/ Welcome to the Spring Cloud Data Flow shell. For assistance hit TAB or type "help". dataflow:>
| Note |
|---|---|
The Spring Cloud Data Flow Shell is a Spring Boot application that connects to the Data Flow Server’s REST API and supports a DSL that simplifies the process of defining a stream or task and managing its lifecycle. Most of these samples use the shell. If you prefer, you can use the Data Flow UI localhost:9393/dashboard, (or wherever it the server is hosted) to perform equivalent operations. |
- Spring Cloud Data Flow installed locally
Follow the installation instructions to run Spring Cloud Data Flow on a local host.
| Note |
|---|---|
To simplify the dependencies and configuration in this example, we will use our local machine acting as an SFTP server. |
Build the demo JAR
From the root of this project:
$ cd batch/file-ingest $ mvn clean package
Note For convenience, you can skip this step. The jar is published to the Spring Maven repository
Create the data directories
Now we create a remote directory on the SFTP server and a local directory where the batch job expects to find files.
Note If you are using a remote SFTP server, create the remote directory on the SFTP server. Since we are using the local machine as the SFTP server, we will create both the local and remote directories on the local machine.
$ mkdir -p /tmp/remote-files /tmp/local-files
Register the
sftp-dataflowsource and thetask-launcher-dataflowsinkWith our Spring Cloud Data Flow server running, we register the
sftp-dataflowsource andtask-launcher-dataflowsink. Thesftp-dataflowsource application will do the work of polling the remote directory for new files and downloading them to the local directory. As each file is received, it emits a message for thetask-launcher-dataflowsink to launch the task to process the data from that file.In the Spring Cloud Data Flow shell:
dataflow:>app register --name sftp --type source --uri maven://org.springframework.cloud.stream.app:sftp-dataflow-source-kafka:2.1.0.RELEASE Successfully registered application 'source:sftp' dataflow:>app register --name task-launcher --type sink --uri maven://org.springframework.cloud.stream.app:task-launcher-dataflow-sink-kafka:1.0.1.RELEASE Successfully registered application 'sink:task-launcher'
Register and create the file ingest task. If you’re using the published jar, set
--uri maven://io.spring.cloud.dataflow.ingest:ingest:1.0.0.BUILD-SNAPSHOT:dataflow:>app register --name fileIngest --type task --uri file:///path/to/target/ingest-X.X.X.jar Successfully registered application 'task:fileIngest' dataflow:>task create fileIngestTask --definition fileIngest Created new task 'fileIngestTask'
Create and deploy the stream
Now lets create and deploy the stream. Once deployed, the stream will start polling the SFTP server and, when new files arrive, launch the batch job.
Note Replace
<user>and '<pass>` below. The<username>and<password>values are the credentials for the local (or remote) user. If not using a local SFTP server, specify the host using the--host, and optionally--port, parameters. If not defined,hostdefaults to127.0.0.1andportdefaults to22.dataflow:>stream create --name inboundSftp --definition "sftp --username=<user> --password=<pass> --allow-unknown-keys=true --task.launch.request.taskName=fileIngestTask --remote-dir=/tmp/remote-files/ --local-dir=/tmp/local-files/ | task-launcher" --deploy Created new stream 'inboundSftp' Deployment request has been sent
Verify Stream deployment
We can see the status of the streams to be deployed with
stream list, for example:dataflow:>stream list ╔═══════════╤════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╤════════════════════════════╗ ║Stream Name│ Stream Definition │ Status ║ ╠═══════════╪════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╪════════════════════════════╣ ║inboundSftp│sftp --password='******' --remote-dir=/tmp/remote-files/ --local-dir=/tmp/local-files/ --task.launch.request.taskName=fileIngestTask│The stream has been ║ ║ │--allow-unknown-keys=true --username=<user> | task-launcher │successfully deployed ║ ╚═══════════╧════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╧════════════════════════════╝
Inspect logs
In the event the stream failed to deploy, or you would like to inspect the logs for any reason, you can get the location of the logs to applications created for the
inboundSftpstream using theruntime appscommand:dataflow:>runtime apps ╔═══════════════════════════╤═══════════╤════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╗ ║ App Id / Instance Id │Unit Status│ No. of Instances / Attributes ║ ╠═══════════════════════════╪═══════════╪════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╣ ║inboundSftp.sftp │ deployed │ 1 ║ ╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢ ║ │ │ guid = 23057 ║ ║ │ │ pid = 71927 ║ ║ │ │ port = 23057 ║ ║inboundSftp.sftp-0 │ deployed │ stderr = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540821009913/inboundSftp.sftp/stderr_0.log ║ ║ │ │ stdout = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540821009913/inboundSftp.sftp/stdout_0.log ║ ║ │ │ url = https://192.168.64.1:23057 ║ ║ │ │working.dir = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540821009913/inboundSftp.sftp ║ ╟───────────────────────────┼───────────┼────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╢ ║inboundSftp.task-launcher │ deployed │ 1 ║ ╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢ ║ │ │ guid = 60081 ║ ║ │ │ pid = 71926 ║ ║ │ │ port = 60081 ║ ║inboundSftp.task-launcher-0│ deployed │ stderr = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540820991695/inboundSftp.task-launcher/stderr_0.log║ ║ │ │ stdout = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540820991695/inboundSftp.task-launcher/stdout_0.log║ ║ │ │ url = https://192.168.64.1:60081 ║ ║ │ │working.dir = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540820991695/inboundSftp.task-launcher ║ ╚═══════════════════════════╧═══════════╧════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╝
Add data
Normally data would be uploaded to an SFTP server. We will simulate this by copying a file into the directory specified by
--remote-dir. Sample data can be found in thedata/directory of the Section 4.2, “Batch File Ingest” project.Copy
data/name-list.csvinto the/tmp/remote-filesdirectory which the SFTP source is monitoring. When this file is detected, thesftpsource will download it to the/tmp/local-filesdirectory specified by--local-dir, and emit a Task Launch Request. The Task Launch Request includes the name of the task to launch along with the local file path, given as the command line argumentlocalFilePath. Spring Batch binds each command line argument to a corresponding JobParameter. The FileIngestTask job processes the file given by the JobParameter namedlocalFilePath. Thetask-launchersink polls for messages using an exponential back-off. Since there have not been any recent requests, the task will launch within 30 seconds after the request is published.$ cp data/name-list.csv /tmp/remote-files
When the batch job launches, you will see something like this in the SCDF console log:
2018-10-26 16:47:24.879 INFO 86034 --- [nio-9393-exec-7] o.s.c.d.spi.local.LocalTaskLauncher : Command to be executed: /Library/Java/JavaVirtualMachines/jdk1.8.0_60.jdk/Contents/Home/jre/bin/java -jar <path-to>/batch/file-ingest/target/ingest-1.0.0.jar localFilePath=/tmp/local-files/name-list.csv --spring.cloud.task.executionid=1 2018-10-26 16:47:25.100 INFO 86034 --- [nio-9393-exec-7] o.s.c.d.spi.local.LocalTaskLauncher : launching task fileIngestTask-8852d94d-9dd8-4760-b0e4-90f75ee028de Logs will be in /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/fileIngestTask3100511340216074735/1540586844871/fileIngestTask-8852d94d-9dd8-4760-b0e4-90f75ee028de
Inspect Job Executions
After data is received and the batch job runs, it will be recorded as a Job Execution. We can view job executions by for example issuing the following command in the Spring Cloud Data Flow shell:
dataflow:>job execution list ╔═══╤═══════╤═════════╤════════════════════════════╤═════════════════════╤══════════════════╗ ║ID │Task ID│Job Name │ Start Time │Step Execution Count │Definition Status ║ ╠═══╪═══════╪═════════╪════════════════════════════╪═════════════════════╪══════════════════╣ ║1 │1 │ingestJob│Tue May 01 23:34:05 EDT 2018│1 │Created ║ ╚═══╧═══════╧═════════╧════════════════════════════╧═════════════════════╧══════════════════╝
As well as list more details about that specific job execution:
dataflow:>job execution display --id 1 ╔═══════════════════════════════════════╤══════════════════════════════╗ ║ Key │ Value ║ ╠═══════════════════════════════════════╪══════════════════════════════╣ ║Job Execution Id │1 ║ ║Task Execution Id │1 ║ ║Task Instance Id │1 ║ ║Job Name │ingestJob ║ ║Create Time │Fri Oct 26 16:57:51 EDT 2018 ║ ║Start Time │Fri Oct 26 16:57:51 EDT 2018 ║ ║End Time │Fri Oct 26 16:57:53 EDT 2018 ║ ║Running │false ║ ║Stopping │false ║ ║Step Execution Count │1 ║ ║Execution Status │COMPLETED ║ ║Exit Status │COMPLETED ║ ║Exit Message │ ║ ║Definition Status │Created ║ ║Job Parameters │ ║ ║-spring.cloud.task.executionid(STRING) │1 ║ ║run.id(LONG) │1 ║ ║localFilePath(STRING) │/tmp/local-files/name-list.csv║ ╚═══════════════════════════════════════╧══════════════════════════════╝
Verify data
When the the batch job runs, it processes the file in the local directory
/tmp/local-filesand transforms each item to uppercase names and inserts it into the database.You may use any database tool that supports the H2 database to inspect the data. In this example we use the database tool
DBeaver. Lets inspect the table to ensure our data was processed correctly.Within DBeaver, create a connection to the database using the JDBC URL
jdbc:h2:tcp://localhost:19092/mem:dataflow, and usersawith no password. When connected, expand thePUBLICschema, then expandTablesand then double click on the tablePEOPLE. When the table data loads, click the "Data" tab to view the data.- You’re done!
| Note |
|---|---|
Running this demo in Cloud Foundry requires a shared file system that is accessed by apps running in different containers.
This feature is provided by NFS Volume Services.
To use Volume Services with SCDF, it is required that we provide |
- A Cloud Foundry instance v2.3+ with NFS Volume Services enabled
- An SFTP server accessible from the Cloud Foundry instance
- An
nfsservice instance properly configured
| Note |
|---|---|
For this example, we use an NFS host configured to allow read-write access to the Cloud Foundry instance.
Create the |
$ cf create-service nfs Existing nfs -c '{"share":"<nfs_host_ip>/export","uid":"<uid>","gid":"<gid>", "mount":"/var/scdf"}'- A
mysqlservice instance - A
rabbitservice instance - PivotalMySQLWeb or another database tool to view the data
- Spring Cloud Data Flow installed on Cloud Foundry
Follow the installation instructions to run Spring Cloud Data Flow on Cloud Foundry.
For convenience, we will configure the SCDF server to bind all stream and task apps to the nfs service. Using the Cloud Foundry CLI,
set the following environment variables (or set them in the manifest):
cf set-env <dataflow-server-app-name> SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: mysql,nfs
For the Skipper server:
cf set-env <skipper-server-app-name> SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: rabbit,nfs
| Note |
|---|---|
Normally, for security and operational efficiency, we may want more fine grained control of which apps bind to the nfs service. One way to do this is to set deployment properties when creating and deploying the stream, as shown below. |
The source code for the Section 4.2, “Batch File Ingest” batch job is located in batch/file-ingest.
The resulting executable jar file must be available in a location that is accessible to your Cloud Foundry instance, such as an HTTP server or Maven repository.
For convenience, the jar is published to the Spring Maven repository
Create the remote directory
Create a directory on the SFTP server where the
sftpsource will detect files and download them for processing. This path must exist prior to running the demo and can be any location that is accessible by the configured SFTP user. On the SFTP server create a directory calledremote-files, for example:sftp> mkdir remote-files
Create a shared NFS directory
Create a directory on the NFS server that is accessible to the user, specified by
uidandgid, used to create the nfs service:$ sudo mkdir /export/shared-files $ sudo chown <uid>:<gid> /export/shared-files
Register the
sftp-dataflowsource and thetasklauncher-dataflowsinkWith our Spring Cloud Data Flow server running, we register the
sftp-dataflowsource andtask-launcher-dataflowsink. Thesftp-dataflowsource application will do the work of polling the remote directory for new files and downloading them to the local directory. As each file is received, it emits a message for thetask-launcher-dataflowsink to launch the task to process the data from that file.In the Spring Cloud Data Flow shell:
dataflow:>app register --name sftp --type source --uri maven://org.springframework.cloud.stream.app:sftp-dataflow-source-rabbit:2.1.0.RELEASE Successfully registered application 'source:sftp' dataflow:>app register --name task-launcher --type sink --uri maven://org.springframework.cloud.stream.app:task-launcher-dataflow-sink-rabbit:1.0.1.RELEASE Successfully registered application 'sink:task-launcher'
Register and create the file ingest task:
dataflow:>app register --name fileIngest --type task --uri maven://io.spring.cloud.dataflow.ingest:ingest:1.0.0.BUILD-SNAPSHOT Successfully registered application 'task:fileIngest' dataflow:>task create fileIngestTask --definition fileIngest Created new task 'fileIngestTask'
Create and deploy the stream
Now lets create and deploy the stream. Once deployed, the stream will start polling the SFTP server and, when new files arrive, launch the batch job.
Note Replace
<user>, '<pass>`, and<host>below. The<host>is the SFTP server host,<user>and<password>values are the credentials for the remote user. Additionally, replace--spring.cloud.dataflow.client.server-uri=http://<dataflow-server-route>with the URL of your dataflow server, as shown bycf apps. If you have security enabled for the SCDF server, set the appropriatespring.cloud.dataflow.clientoptions.dataflow:> app info --name task-launcher --type sink ╔══════════════════════════════╤══════════════════════════════╤══════════════════════════════╤══════════════════════════════╗ ║ Option Name │ Description │ Default │ Type ║ ╠══════════════════════════════╪══════════════════════════════╪══════════════════════════════╪══════════════════════════════╣ ║platform-name │The Spring Cloud Data Flow │default │java.lang.String ║ ║ │platform to use for launching │ │ ║ ║ │tasks. | ║ ║spring.cloud.dataflow.client.a│The login username. │<none> │java.lang.String ║ ║uthentication.basic.username │ │ │ ║ ║spring.cloud.dataflow.client.a│The login password. │<none> │java.lang.String ║ ║uthentication.basic.password │ │ │ ║ ║trigger.max-period │The maximum polling period in │30000 │java.lang.Integer ║ ║ │milliseconds. Will be set to │ │ ║ ║ │period if period > maxPeriod. │ │ ║ ║trigger.period │The polling period in │1000 │java.lang.Integer ║ ║ │milliseconds. │ │ ║ ║trigger.initial-delay │The initial delay in │1000 │java.lang.Integer ║ ║ │milliseconds. │ │ ║ ║spring.cloud.dataflow.client.s│Skip Ssl validation. │true │java.lang.Boolean ║ ║kip-ssl-validation │ │ │ ║ ║spring.cloud.dataflow.client.e│Enable Data Flow DSL access. │false │java.lang.Boolean ║ ║nable-dsl │ │ │ ║ ║spring.cloud.dataflow.client.s│The Data Flow server URI. │http://localhost:9393 │java.lang.String ║ ║erver-uri │ │ │ ║ ╚══════════════════════════════╧══════════════════════════════╧══════════════════════════════╧══════════════════════════════╝
Since we configured the SCDF server to bind all stream and task apps to the
nfsservice, no deployment parameters are required.dataflow:>stream create inboundSftp --definition "sftp --username=<user> --password=<pass> --host=<host> --allow-unknown-keys=true --remote-dir=remote-files --local-dir=/var/scdf/shared-files/ --task.launch.request.taskName=fileIngestTask | task-launcher --spring.cloud.dataflow.client.server-uri=http://<dataflow-server-route>" Created new stream 'inboundSftp' dataflow:>stream deploy inboundSftp Deployment request has been sent for stream 'inboundSftp'
Alternatively, we can bind the
nfsservice to thefileIngestTaskby passing deployment properties to the task via the task launch request in the stream definition:--task.launch.request.deployment-properties=deployer.*.cloudfoundry.services=nfsdataflow:>stream deploy inboundSftp --properties "deployer.sftp.cloudfoundry.services=nfs"
Verify Stream deployment
The status of the stream to be deployed can be queried with
stream list, for example:dataflow:>stream list ╔═══════════╤═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╤══════════════════╗ ║Stream Name│ Stream Definition │ Status ║ ╠═══════════╪═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╪══════════════════╣ ║inboundSftp│sftp --task.launch.request.deployment-properties='deployer.*.cloudfoundry.services=nfs' --password='******' --host=<host> │The stream has ║ ║ │--remote-dir=remote-files --local-dir=/var/scdf/shared-files/ --task.launch.request.taskName=fileIngestTask --allow-unknown-keys=true │been successfully ║ ║ │--username=<user> | task-launcher --spring.cloud.dataflow.client.server-uri=http://<dataflow-server-route> │deployed ║ ╚═══════════╧═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╧══════════════════╝
Inspect logs
In the event the stream failed to deploy, or you would like to inspect the logs for any reason, the logs can be obtained from individual applications. First list the deployed apps:
$ cf apps Getting apps in org cf_org / space cf_space as cf_user... OK name requested state instances memory disk urls skipper-server started 1/1 1G 1G skipper-server.cfapps.io data-flow-server started 1/1 2G 2G data-flow-server.cfapps.io fileIngestTask stopped 0/1 1G 1G bxZZ5Yv-inboundSftp-task-launcher-v1 started 1/1 2G 1G bxZZ5Yv-inboundSftp-task-launcher-v1.cfapps.io bxZZ5Yv-inboundSftp-sftp-v1 started 1/1 2G 1G bxZZ5Yv-inboundSftp-sftp-v1.cfapps.io
In this example, the logs for the
sftpapplication can be viewed by:cf logs bxZZ5Yv-inboundSftp-sftp-v1 --recent
The log files of this application would be useful to debug issues such as SFTP connection failures.
Additionally, the logs for the
task-launcherapplication can be viewed by:cf logs bxZZ5Yv-inboundSftp-task-launcher-v1 --recent
Add data
Sample data can be found in the
data/directory of the Section 4.2, “Batch File Ingest” project. Connect to the SFTP server and uploaddata/name-list.csvinto theremote-filesdirectory. Copydata/name-list.csvinto the/remote-filesdirectory which the SFTP source is monitoring. When this file is detected, thesftpsource will download it to the/var/scdf/shared-filesdirectory specified by--local-dir, and emit a Task Launch Request. The Task Launch Request includes the name of the task to launch along with the local file path, given as a command line argument. Spring Batch binds each command line argument to a corresponding JobParameter. The FileIngestTask job processes the file given by the JobParameter namedlocalFilePath. Thetask-launchersink polls for messages using an exponential back-off. Since there have not been any recent requests, the task will launch within 30 seconds after the request is published.Inspect Job Executions
After data is received and the batch job runs, it will be recorded as a Job Execution. We can view job executions by for example issuing the following command in the Spring Cloud Data Flow shell:
dataflow:>job execution list ╔═══╤═══════╤═════════╤════════════════════════════╤═════════════════════╤══════════════════╗ ║ID │Task ID│Job Name │ Start Time │Step Execution Count │Definition Status ║ ╠═══╪═══════╪═════════╪════════════════════════════╪═════════════════════╪══════════════════╣ ║1 │1 │ingestJob│Thu Jun 07 13:46:42 EDT 2018│1 │Created ║ ╚═══╧═══════╧═════════╧════════════════════════════╧═════════════════════╧══════════════════╝
As well as list more details about that specific job execution:
dataflow:>job execution display --id 1 ╔═══════════════════════════════════════════╤════════════════════════════════════╗ ║ Key │ Value ║ ╠═══════════════════════════════════════════╪════════════════════════════════════╣ ║Job Execution Id │1 ║ ║Task Execution Id │1 ║ ║Task Instance Id │1 ║ ║Job Name │ingestJob ║ ║Create Time │Wed Oct 31 03:17:34 EDT 2018 ║ ║Start Time │Wed Oct 31 03:17:34 EDT 2018 ║ ║End Time │Wed Oct 31 03:17:34 EDT 2018 ║ ║Running │false ║ ║Stopping │false ║ ║Step Execution Count │1 ║ ║Execution Status │COMPLETED ║ ║Exit Status │COMPLETED ║ ║Exit Message │ ║ ║Definition Status │Created ║ ║Job Parameters │ ║ ║-spring.cloud.task.executionid(STRING) │1 ║ ║run.id(LONG) │1 ║ ║localFilePath(STRING) │/var/scdf/shared-files/name_list.csv║ ╚═══════════════════════════════════════════╧════════════════════════════════════╝
Verify data
When the the batch job runs, it processes the file in the local directory
/var/scdf/shared-filesand transforms each item to uppercase names and inserts it into the database.Use PivotalMySQLWeb to inspect the data.
- You’re done!
- A Kubernetes cluster
- A database tool such as DBeaver to inspect the database contents
- An SFTP server accessible from the Kubernetes cluster
- An NFS server accessible from the Kubernetes cluster
| Note |
|---|---|
For this example, we use an NFS host configured to allow read-write access. |
Spring Cloud Data Flow installed on Kubernetes
Follow the installation instructions to run Spring Cloud Data Flow on Kubernetes.
Configure a Kubernetes Persistent Volume named
nfsusing the Host IP of the NFS server and the shared directory path:apiVersion: v1 kind: PersistentVolume metadata: name: nfs spec: capacity: storage: 50Gi accessModes: - ReadWriteMany nfs: server: <NFS_SERVER_IP> path: <NFS_SHARED_PATH>Copy and save the above to
pv-nfs.yamland replace<NFS_SERVER_IP>with the IP address of the NFS Server and <NFS_SHARED_PATH> with a shared directory on the server, e.g./export. Create the resource:$kubectl apply -f pv-nfs.yaml persistentvolume/nfs created
Configure a Persistent Volume Claim on the
nfspersistent volume. We will also name the PVCnfs. Later, we will configure our apps to use this to mount the NFS shared directory.apiVersion: v1 kind: PersistentVolumeClaim metadata: name: nfs spec: accessModes: - ReadWriteMany resources: requests: storage: 5GiCopy and save the above to
pvc-nsf.yamland create the PVC resource:$kubectl apply -f pvc-nsf.yaml persistentvolumeclaim/nfs created
The source code for the Section 4.2, “Batch File Ingest” batch job is located in batch/file-ingest.
We will need to build a Docker image for this app and publish it to a Docker registry
accessible to your Kubernetes cluster.
For your convenience, the Docker image is available at
springcloud/ingest.
Build and publish the Docker image
Skip this step if you are using the pre-built image. We are using the
fabric8Maven docker plugin. which will push images to Docker Hub by default. You will need to have a Docker Hub account for this. Note the-Pkubernetesflag adds a dependency to provide the required Maria DB JDBC driver.$cd batch/file-ingest $mvn clean package docker:build docker:push -Ddocker.org=<DOCKER_ORG> -Ddocker.username=<DOCKER_USERNAME> -Ddocker.password=<DOCKER_PASSWORD> -Pkubernetes
Create the remote directory
Create a directory on the SFTP server where the
sftpsource will detect files and download them for processing. This path must exist prior to running the demo and can be any location that is accessible by the configured SFTP user. On the SFTP server create a directory calledremote-files, for example:sftp> mkdir remote-files
Create a shared NFS directory
Create a read/write directory on the NFS server.
$ sudo mkdir /export/shared-files $ sudo chmod 0777 /export/shared-files
Register the
sftp-dataflowsource and thetasklauncher-dataflowsinkWith our Spring Cloud Data Flow server running, we register the
sftp-dataflowsource andtask-launcher-dataflowsink. Thesftp-dataflowsource application will do the work of polling the remote directory for new files and downloading them to the local directory. As each file is received, it emits a message for thetask-launcher-dataflowsink to launch the task to process the data from that file.In the Spring Cloud Data Flow shell:
dataflow:>app register --name sftp --type source --uri docker:springcloud/sftp-dataflow-source-kafka --metadata-uri maven://org.springframework.cloud.stream.app:sftp-dataflow-source-kafka:jar:metadata:2.1.0.RELEASE Successfully registered application 'source:sftp' dataflow:>app register --name task-launcher --type sink --uri docker:springcloud/task-launcher-dataflow-sink-kafka --metadata-uri maven://org.springframework.cloud.stream.app:task-launcher-dataflow-sink-kafka:jar:metadata:1.0.1.RELEASE Successfully registered application 'sink:task-launcher'
Register and create the file ingest task:
dataflow:>app register --name fileIngest --type task --uri docker:springcloud/ingest Successfully registered application 'task:fileIngest' dataflow:>task create fileIngestTask --definition fileIngest Created new task 'fileIngestTask'
Create and deploy the stream
Now lets create the stream. Once deployed, the stream will start polling the SFTP server and, when new files arrive, launch the batch job.
dataflow:>stream create inboundSftp --definition "sftp --host=<host> --username=<user> --password=<password> --allow-unknown-keys=true --remote-dir=/remote-files --local-dir=/staging/shared-files --task.launch.request.taskName=fileIngestTask --task.launch.request.deployment-properties="deployer.*.kubernetes.volumes=[{'name':'staging','persistentVolumeClaim':{'claimName':'nfs'}}],deployer.*.kubernetes.volumeMounts=[{'mountPath':'/staging','name':'staging'}]"| task-launcher --spring.cloud.dataflow.client.server-uri=http://<dataflow-server-ip>"Note Replace
<user>, '<pass>`, and<host>above. The<host>is the SFTP server host,<user>and<password>values are the credentials for the remote user. Additionally, replace--spring.cloud.dataflow.client.server-uri=http://<dataflow-server-ip>with the Cluster IP (External IP should work as well) of your dataflow server, as shown bykubectl get svc/scdf-server. The default Data Flow server credentials areuserandpassword.Note Here we use the Kubernetes Persistent Volume Claim(PVC) resource that we created earlier. In the stream definition, the PVC and the associated Volume Mount are passed to the task via
--task.launch.request.deployment-properties. Thedeployer.*.kubernetes…properties provide native Kubernetes specs as JSON to instruct the Data Flow server’s deployer to add this configuration to the container configuration for the pod that will run the batch job. We mount the NFS shared directory that we configured in thenfsPersistent Volume(PV) as/stagingin the pod’s local file system. ThenfsPVC allows the pod to allocate space on the PV. The corresponding configuration, targeting thesftpsource is used to deploy the stream. This enables thesftpsource to share NFS mounted files with the launched task.Now let’s deploy the stream.
dataflow:>stream deploy inboundSftp --properties "deployer.sftp.kubernetes.volumes=[{'name':'staging','persistentVolumeClaim':{'claimName':'nfs'}}],deployer.sftp.kubernetes.volumeMounts=[{'mountPath':'/staging','name':'staging'}]"Verify Stream deployment
The status of the stream to be deployed can be queried with
stream list, for example:dataflow:>stream list ╔═══════════╤═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╤════════════╗ ║Stream Name│ Stream Definition │ Status ║ ╠═══════════╪═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╪════════════╣ ║inboundSftp│sftp │The stream ║ ║ │--task.launch.request.deployment-properties="deployer.*.kubernetes.volumes=[{'name':'staging','persistentVolumeClaim':{'claimName':'nfs'}}],deployer.*.kubernetes.volumeMounts=[{'mountPath':'/staging','name':'staging'}]"│has been ║ ║ │--password='******' --local-dir=/staging/shared-files --host=<host> --remote-dir=/remote-files --task.launch.request.taskName=fileIngestTask --allow-unknown-keys=true --username=<user> | task-launcher │successfully║ ║ │--spring.cloud.dataflow.client.server-uri=http://<dataflow-server-ip> --spring.cloud.dataflow.client.authentication.basic.username=user --spring.cloud.dataflow.client.authentication.basic.password='******' │deployed ║ ╚═══════════╧═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╧════════════╝Inspect logs
In the event the stream failed to deploy, or you would like to inspect the logs for any reason, the logs can be obtained from individual applications. First list the pods. The following shows all are in a healthy state.:
$ kubectl get pods NAME READY STATUS RESTARTS AGE inboundsftp-sftp-7c44b54cc4-jd65c 1/1 Running 0 1m inboundsftp-task-launcher-768d8f45bd-2s4wc 1/1 Running 0 1m kafka-broker-696786c8f7-4chnn 1/1 Running 0 1d kafka-zk-5f9bff7d5-4tbb7 1/1 Running 0 1d mysql-f878678df-ml5vd 1/1 Running 0 1d redis-748db48b4f-zz2ht 1/1 Running 0 1d scdf-server-64fb996ffb-dmwpj 1/1 Running 0 1d
In this example, the logs for the
sftpapplication can be viewed by:$kubectl logs -f inboundsftp-sftp-7c44b54cc4-jd65c
The log files of this application would be useful to debug issues such as SFTP connection failures.
Additionally, the logs for the
task-launcherapplication can be viewed by:$kubectl logs -f inboundsftp-task-launcher-768d8f45bd-2s4wc
Note Another way to access pods is via metadata labels. The SCDF deployer configures some useful labels, such as
spring-app-id=<stream-name>-<app-name>, converted to lowercase. Sokubectl logs -lspring-app-id=inboundsftp-sftp, for example, will also work.Add data
Sample data can be found in the
data/directory of the Section 4.2, “Batch File Ingest” project. Connect to the SFTP server and uploaddata/name-list.csvinto theremote-filesdirectory. Copydata/name-list.csvinto the/remote-filesdirectory which the SFTP source is monitoring. When this file is detected, thesftpsource will download it to the/staging/shared-filesdirectory specified by--local-dir, and emit a Task Launch Request. The Task Launch Request includes the name of the task to launch along with the local file path, given as a command line argument. Spring Batch binds each command line argument to a corresponding JobParameter. The FileIngestTask job processes the file given by the JobParameter namedlocalFilePath. Thetask-launchersink polls for messages using an exponential back-off. Since there have not been any recent requests, the task will launch within 30 seconds after the request is published.Inspect Job Executions
After data is received and the batch job runs, it will be recorded as a Job Execution. We can view job executions by for example issuing the following command in the Spring Cloud Data Flow shell:
dataflow:>job execution list ╔═══╤═══════╤═════════╤════════════════════════════╤═════════════════════╤══════════════════╗ ║ID │Task ID│Job Name │ Start Time │Step Execution Count │Definition Status ║ ╠═══╪═══════╪═════════╪════════════════════════════╪═════════════════════╪══════════════════╣ ║1 │1 │ingestJob│Fri Nov 30 15:45:29 EST 2018│1 │Created ║ ╚═══╧═══════╧═════════╧════════════════════════════╧═════════════════════╧══════════════════╝
As well as list more details about that specific job execution:
dataflow:>job execution display --id 1 ╔═══════════════════════════════════════════╤══════════════════════════════════════╗ ║ Key │ Value ║ ╠═══════════════════════════════════════════╪══════════════════════════════════════╣ ║Job Execution Id │1 ║ ║Task Execution Id │3 ║ ║Task Instance Id │1 ║ ║Job Name │ingestJob ║ ║Create Time │Fri Nov 30 13:52:38 EST 2018 ║ ║Start Time │Fri Nov 30 13:52:38 EST 2018 ║ ║End Time │Fri Nov 30 13:52:38 EST 2018 ║ ║Running │false ║ ║Stopping │false ║ ║Step Execution Count │1 ║ ║Execution Status │COMPLETED ║ ║Exit Status │COMPLETED ║ ║Exit Message │ ║ ║Definition Status │Created ║ ║Job Parameters │ ║ ║-spring.cloud.task.executionid(STRING) │1 ║ ║run.id(LONG) │1 ║ ║-spring.datasource.username(STRING) │root ║ ║-spring.cloud.task.name(STRING) │fileIngestTask ║ ║-spring.datasource.password(STRING) │****************** ║ ║-spring.datasource.driverClassName(STRING) │org.mariadb.jdbc.Driver ║ ║localFilePath(STRING) │classpath:data.csv ║ ║-spring.datasource.url(STRING) │jdbc:mysql://10.100.200.152:3306/mysql║ ╚═══════════════════════════════════════════╧══════════════════════════════════════╝
Verify data
When the the batch job runs, it processes the file in the local directory
/staging/shared-filesand transforms each item to uppercase names and inserts it into the database. In this case, we are using the same database that SCDF uses to store task execution and job execution status. We can use port forwarding to access the mysql server on a local port.$ kubectl get pods NAME READY STATUS RESTARTS AGE inboundsftp-sftp-7c44b54cc4-jd65c 1/1 Running 0 1m inboundsftp-task-launcher-768d8f45bd-2s4wc 1/1 Running 0 1m kafka-broker-696786c8f7-4chnn 1/1 Running 0 1d kafka-zk-5f9bff7d5-4tbb7 1/1 Running 0 1d mysql-f878678df-ml5vd 1/1 Running 0 1d redis-748db48b4f-zz2ht 1/1 Running 0 1d scdf-server-64fb996ffb-dmwpj 1/1 Running 0 1d
$kubectl port-forward pod/mysql-f878678df-ml5vd 3306:3306 &
You may use any database tool that supports the MySQL database to inspect the data. In this example we use the database tool
DBeaver. Lets inspect the table to ensure our data was processed correctly.Within DBeaver, create a connection to the database using the JDBC URL
jdbc:mysql://localhost:3306/mysql, and userrootwith passwordyourpassword, the default for themysqldeployment. When connected, expand themysqlschema, then expandTablesand then double click on the tablepeople. When the table data loads, click the "Data" tab to view the data.- You’re done!
The Batch File Ingest - SFTP Demo processes a single file with 5000+ items. What if we copy 100 files to the remote directory? The sftp source will process them immediately, generating 100 task launch requests. The Dataflow Server launches tasks asynchronously so this could potentially overwhelm the resources of the runtime platform. For example, when running the Data Flow server on your local machine, each launched task creates a new JVM. In Cloud Foundry, each task creates a new container instance.
Fortunately, Spring Cloud Data Flow provides configuration settings to limit the number of concurrently running tasks. We can use this demo to see how this works.
Set the maximum concurrent tasks to 3.
For running tasks on a local server, restart the server, adding a command line argument spring.cloud.dataflow.task.platform.local.accounts[default].maximum-concurrent-tasks=3.
If running on Cloud Foundry, cf set-env <dataflow-server> SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[DEFAULT]_DEPLOYMENT_MAXIMUMCONCURRENTTASKS 3, and restage.
Follow the main demo instructions but change the Add Data step, as described below.
Monitor the task launcher
Tail the logs on the
task-launcherapp.If there are no requests in the input queue, you will see something like:
07:42:51.760 INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : No task launch request received- increasing polling period to 2 seconds. 07:42:53.768 INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : No task launch request received- increasing polling period to 4 seconds. 07:42:57.780 INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : No task launch request received- increasing polling period to 8 seconds. 07:43:05.791 INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : No task launch request received- increasing polling period to 16 seconds. 07:43:21.801 INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : No task launch request received- increasing polling period to 30 seconds. 07:43:51.811 INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : No task launch request received 07:44:21.824 INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : No task launch request received 07:44:51.834 INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : No task launch request received
The first three messages show the exponential backoff at start up or after processing the final request. The the last three message show the task launcher in a steady state of polling for messages every 30 seconds. Of course, these values are configurable.
The task launcher sink polls the input destination. The polling period adjusts according to the presence of task launch requests and also to the number of currently running tasks reported via the Data Flow server’s
tasks/executions/currentREST endpoint. The sink queries this endpoint and will pause polling the input for new requests if the number of concurrent tasks is at its limit. This introduces a 1-30 second lag between the creation of the task launch request and the execution of the request, sacrificing some performance for resilience. Task launch requests will never be sent to a dead letter queue because the server is busy or unavailable. The exponential backoff also prevents the app from querying the server excessively when there are no task launch requests.You can also monitor the Data Flow server:
$ watch curl <dataflow-server-url>/tasks/executions/current Every 2.0s: curl http://localhost:9393/tasks/executions/current ultrafox.local: Wed Oct 31 08:38:53 2018 % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0100 53 0 53 0 0 53 0 --:--:-- --:--:-- --:--:-- 5888 {"maximumTaskExecutions":3,"runningExecutionCount":0}Add Data
The directory
batch/file-ingest/data/splitcontains the contents ofbatch/file-ingest/data/name-list.csvsplit into 20 files, not 100 but enough to illustrate the concept. Upload these files to the SFTP remote directory, e.g.,
sftp>cd remote-files sftp>lcd batch/file-ingest/data/split sftp>mput *
Or if using the local machine as the SFTP server:
>cp * /tmp/remote-files
In the task-launcher logs, you should now see:
INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling period reset to 1000 ms. INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask WARN o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Data Flow server has reached its concurrent task execution limit: (3) INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 2 seconds. INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling resumed INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling period reset to 1000 ms. WARN o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Data Flow server has reached its concurrent task execution limit: (3) INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 2 seconds. INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling resumed INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling period reset to 1000 ms. INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask WARN o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Data Flow server has reached its concurrent task execution limit: (3) INFO o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 2 seconds. ...
The sftp source will not process files that it has already seen.
It uses a Metadata Store to keep track of files by extracting content from messages at runtime.
Out of the box, it uses an in-memory Metadata Store.
Thus, if we re-deploy the stream, this state is lost and files will be reprocessed.
Thanks to the magic of Spring, we can inject one of the available persistent Metadata Stores.
In this example, we will use the JDBC Metadata Store since we are already using a database.
Configure and Build the SFTP source
For this we add some JDBC dependencies to the
sftp-dataflowsource.Clone the sftp stream app starter. From the sftp directory. Replace <binder> below with
kafkaorrabbitas appropriate for your configuration:$ ./mvnw clean install -DskipTests -PgenerateApps $ cd apps/sftp-dataflow-source-<binder>
Add the following dependencies to
pom.xml:<dependency> <groupId>org.springframework.integration</groupId> <artifactId>spring-integration-jdbc</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> </dependency>If you are running on a local server with the in memory H2 database, set the JDBC url in
src/main/resources/application.propertiesto use the Data Flow server’s database:spring.datasource.url=jdbc:h2:tcp://localhost:19092/mem:dataflow
If you are running in Cloud Foundry, we will bind the source to the
mysqlservice. Add the following property tosrc/main/resources/application.properties:spring.integration.jdbc.initialize-schema=always
Build the app:
$./mvnw clean package
Register the jar
If running in Cloud Foundry, the resulting executable jar file must be available in a location that is accessible to your Cloud Foundry instance, such as an HTTP server or Maven repository. If running on a local server:
dataflow>app register --name sftp --type source --uri file:<project-directory>/sftp/apps/sftp-dataflow-source-kafka/target/sftp-dataflow-source-kafka-X.X.X.jar --force
Run the Demo
Follow the instructions for building and running the main SFTP File Ingest demo, for your preferred platform, up to the
Add Data Step. If you have already completed the main exercise, restore the data to its initial state, and redeploy the stream:- Clean the data directories (e.g.,
tmp/local-filesandtmp/remote-files) - Execute the SQL command
DROP TABLE PEOPLE;in the database Undeploy the stream, and deploy it again to run the updated
sftpsourceIf you are running in Cloud Foundry, set the deployment properties to bind
sftpto themysqlservice. For example:dataflow>stream deploy inboundSftp --properties "deployer.sftp.cloudfoundry.services=nfs,mysql"
- Clean the data directories (e.g.,
Add Data
Let’s use one small file for this. The directory
batch/file-ingest/data/splitcontains the contents ofbatch/file-ingest/data/name-list.csvsplit into 20 files. Upload one of them:sftp>cd remote-files sftp>lcd batch/file-ingest/data/split sftp>put names_aa.csv
Or if using the local machine as the SFTP server:
$cp names_aa.csv truncate INT_METADATA_STORE;
Inspect data
Using a Database browser, as described in the main demo, view the contents of the
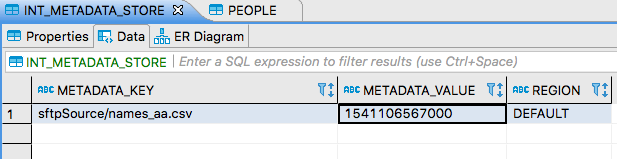
INT_METADATA_STOREtable.Note that there is a single key-value pair, where the key identies the file name (the prefix
sftpSource/provides a namespace for thesftpsource app) and the value is a timestamp indicating when the message was received. The metadata store tracks files that have already been processed. This prevents the same files from being pulled every from the remote directory on every polling cycle. Only new files, or files that have been updated will be processed. Since there are no uniqueness constraints on the data, a file processed multiple times by our batch job will result in duplicate entries.If we view the
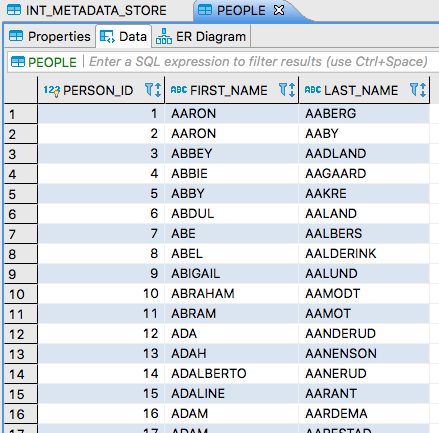
PEOPLEtable, it should look something like this:Now let’s update the remote file, using SFTP
putor if using the local machine as an SFTP server:$touch /tmp/remote-files/names_aa.csv
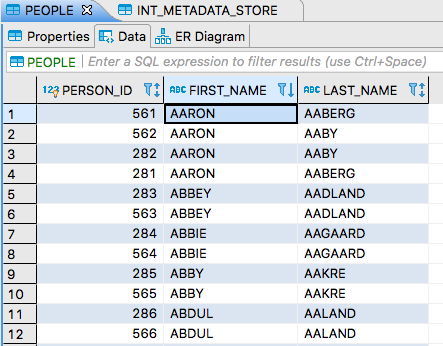
Now the
PEOPLEtable will have duplicate data. If youORDER BY FIRST_NAME, you will see something like this:Of course, if we drop another one of files into the remote directory, that will processed and we will see another entry in the Metadata Store.
In this sample, you have learned:
- How to process SFTP files with a batch job
- How to create a stream to poll files on an SFTP server and launch a batch job
- How to verify job status via logs and shell commands
- How the Data Flow Task Launcher limits concurrent task executions
- How to avoid duplicate processing of files