Preface
1. About the documentation
Copies of this document may be made for your own use and for distribution to others, provided that you do not charge any fee for such copies and further provided that each copy contains this Copyright Notice, whether distributed in print or electronically.
2. Getting help
Having trouble with Spring Cloud Data Flow? We would like to help!
-
Ask a question. We monitor stackoverflow.com for questions tagged with
spring-cloud-dataflow. -
Report bugs with Spring Cloud Data Flow at github.com/spring-cloud/spring-cloud-dataflow/issues.
-
Review the latest release notes at github.com/spring-cloud/spring-cloud-dataflow/releases.
| All of Spring Cloud Data Flow is open source, including the documentation! If you find problems with the docs or if you just want to improve them, please get involved. |
Overview
Microservice based Streaming and Batch data processing for Cloud Foundry and Kubernetes.
Spring Cloud Data Flow provides tools to create complex topologies for streaming and batch data pipelines. The data pipelines consist of Spring Boot apps, built using the Spring Cloud Stream or Spring Cloud Task microservice frameworks.
Spring Cloud Data Flow supports a range of data processing use cases, from ETL to import/export, event streaming, and predictive analytics.
Getting Started
| This version of Spring Cloud Data Flow provides: Spring Boot 3.x Support |
3. Getting Started - Local
This section covers how to get started with Spring Cloud Data Flow running locally on Docker Compose. See the Local Machine section of the microsite for more information on installing Spring Cloud Data Flow on Docker Compose.
4. Getting Started - Cloud Foundry
This section covers how to get started with Spring Cloud Data Flow on Cloud Foundry. See the Cloud Foundry section of the microsite for more information on installing Spring Cloud Data Flow on Cloud Foundry.
Once you have the Data Flow server installed on Cloud Foundry, you probably want to get started with orchestrating the deployment of readily available pre-built applications into coherent streaming or batch data pipelines. We have guides to help you get started with both Stream and Batch processing.
5. Getting Started - Kubernetes
This section covers how to get started with Spring Cloud Data Flow running locally on Kubernetes. See Deployment using Carvel and Configuration - Kubernetes for more information on installing Spring Cloud Data Flow on Kubernetes.
Once you have the Data Flow server installed on Kubernetes, you probably want to get started with orchestrating the deployment of readily available pre-built applications into a coherent streaming or batch data pipelines. We have guides to help you get started with both Stream and Batch processing.
We have prepared scripts to simplify the process of creating a local Minikube or Kind cluster, or to use a remote cluster like GKE or TKG, more at Configure Kubernetes for Local Development
Applications
A selection of pre-built applications for various data integration and processing scenarios to facilitate learning and experimentation can be found here.
Architecture
6. Introduction
Spring Cloud Data Flow simplifies the development and deployment of applications that are focused on data-processing use cases.
The Architecture section of the microsite describes Data Flow’s architecture.
Configuration
7. Maven Resources
Spring Cloud Dataflow supports referencing artifacts via Maven (maven:).
If you want to override specific Maven configuration properties (remote repositories, proxies, and others) or run the Data Flow Server behind a proxy,
you need to specify those properties as command-line arguments when you start the Data Flow Server, as shown in the following example:
$ java -jar spring-cloud-dataflow-server-2.11.5.jar --spring.config.additional-location=/home/joe/maven.ymlThe preceding command assumes a maven.yaml similar to the following:
maven:
localRepository: mylocal
remote-repositories:
repo1:
url: https://repo1
auth:
username: user1
password: pass1
snapshot-policy:
update-policy: daily
checksum-policy: warn
release-policy:
update-policy: never
checksum-policy: fail
repo2:
url: https://repo2
policy:
update-policy: always
checksum-policy: fail
proxy:
host: proxy1
port: "9010"
auth:
username: proxyuser1
password: proxypass1By default, the protocol is set to http. You can omit the auth properties if the proxy does not need a username and password. Also, by default, the maven localRepository is set to ${user.home}/.m2/repository/.
As shown in the preceding example, you can specify the remote repositories along with their authentication (if needed). If the remote repositories are behind a proxy, you can specify the proxy properties, as shown in the preceding example.
You can specify the repository policies for each remote repository configuration, as shown in the preceding example.
The key policy is applicable to both the snapshot and the release repository policies.
See the Repository Policies topic for the list of supported repository policies.
As these are Spring Boot @ConfigurationProperties you need to specify by adding them to the SPRING_APPLICATION_JSON environment variable. The following example shows how the JSON is structured:
$ SPRING_APPLICATION_JSON='
{
"maven": {
"local-repository": null,
"remote-repositories": {
"repo1": {
"url": "https://repo1",
"auth": {
"username": "repo1user",
"password": "repo1pass"
}
},
"repo2": {
"url": "https://repo2"
}
},
"proxy": {
"host": "proxyhost",
"port": 9018,
"auth": {
"username": "proxyuser",
"password": "proxypass"
}
}
}
}
'7.1. Wagon
There is a limited support for using Wagon transport with Maven. Currently, this
exists to support preemptive authentication with http-based repositories
and needs to be enabled manually.
Wagon-based http transport is enabled by setting the maven.use-wagon property
to true. Then you can enable preemptive authentication for each remote
repository. Configuration loosely follows the similar patterns found in
HttpClient HTTP Wagon.
At the time of this writing, documentation in Maven’s own site is slightly misleading
and missing most of the possible configuration options.
The maven.remote-repositories.<repo>.wagon.http namespace contains all Wagon
http related settings, and the keys directly under it map to supported http methods — namely, all, put, get and head, as in Maven’s own configuration.
Under these method configurations, you can then set various options, such as
use-preemptive. A simpl preemptive configuration to send an auth
header with all requests to a specified remote repository would look like the following example:
maven:
use-wagon: true
remote-repositories:
springRepo:
url: https://repo.example.org
wagon:
http:
all:
use-preemptive: true
auth:
username: user
password: passwordInstead of configuring all methods, you can tune settings for get
and head requests only, as follows:
maven:
use-wagon: true
remote-repositories:
springRepo:
url: https://repo.example.org
wagon:
http:
get:
use-preemptive: true
head:
use-preemptive: true
use-default-headers: true
connection-timeout: 1000
read-timeout: 1000
headers:
sample1: sample2
params:
http.socket.timeout: 1000
http.connection.stalecheck: true
auth:
username: user
password: passwordThere are settings for use-default-headers, connection-timeout,
read-timeout, request headers, and HttpClient params. For more about parameters,
see Wagon ConfigurationUtils.
8. Security
By default, the Data Flow server is unsecured and runs on an unencrypted HTTP connection. You can secure your REST endpoints as well as the Data Flow Dashboard by enabling HTTPS and requiring clients to authenticate with OAuth 2.0.
|
Appendix Azure contains more information how to setup Azure Active Directory integration. |
|
By default, the REST endpoints (administration, management, and health) as well as the Dashboard UI do not require authenticated access. |
While you can theoretically choose any OAuth provider in conjunction with Spring Cloud Data Flow, we recommend using the CloudFoundry User Account and Authentication (UAA) Server.
Not only is the UAA OpenID certified and is used by Cloud Foundry, but you can also use it in local stand-alone deployment scenarios. Furthermore, the UAA not only provides its own user store, but it also provides comprehensive LDAP integration.
8.1. Enabling HTTPS
By default, the dashboard, management, and health endpoints use HTTP as a transport.
You can switch to HTTPS by adding a certificate to your configuration in
application.yml, as shown in the following example:
server:
port: 8443 (1)
ssl:
key-alias: yourKeyAlias (2)
key-store: path/to/keystore (3)
key-store-password: yourKeyStorePassword (4)
key-password: yourKeyPassword (5)
trust-store: path/to/trust-store (6)
trust-store-password: yourTrustStorePassword (7)| 1 | As the default port is 9393, you may choose to change the port to a more common HTTPs-typical port. |
| 2 | The alias (or name) under which the key is stored in the keystore. |
| 3 | The path to the keystore file. You can also specify classpath resources, by using the classpath prefix - for example: classpath:path/to/keystore. |
| 4 | The password of the keystore. |
| 5 | The password of the key. |
| 6 | The path to the truststore file. You can also specify classpath resources, by using the classpath prefix - for example: classpath:path/to/trust-store |
| 7 | The password of the trust store. |
| If HTTPS is enabled, it completely replaces HTTP as the protocol over which the REST endpoints and the Data Flow Dashboard interact. Plain HTTP requests fail. Therefore, make sure that you configure your Shell accordingly. |
Using Self-Signed Certificates
For testing purposes or during development, it might be convenient to create self-signed certificates. To get started, execute the following command to create a certificate:
$ keytool -genkey -alias dataflow -keyalg RSA -keystore dataflow.keystore \
-validity 3650 -storetype JKS \
-dname "CN=localhost, OU=Spring, O=Pivotal, L=Kailua-Kona, ST=HI, C=US" (1)
-keypass dataflow -storepass dataflow| 1 | CN is the important parameter here. It should match the domain you are trying to access - for example, localhost. |
Then add the following lines to your application.yml file:
server:
port: 8443
ssl:
enabled: true
key-alias: dataflow
key-store: "/your/path/to/dataflow.keystore"
key-store-type: jks
key-store-password: dataflow
key-password: dataflowThis is all you need to do for the Data Flow Server. Once you start the server,
you should be able to access it at localhost:8443/.
As this is a self-signed certificate, you should hit a warning in your browser, which
you need to ignore.
| Never use self-signed certificates in production. |
Self-Signed Certificates and the Shell
By default, self-signed certificates are an issue for the shell, and additional steps are necessary to make the shell work with self-signed certificates. Two options are available:
-
Add the self-signed certificate to the JVM truststore.
-
Skip certificate validation.
Adding the Self-signed Certificate to the JVM Truststore
In order to use the JVM truststore option, you need to export the previously created certificate from the keystore, as follows:
$ keytool -export -alias dataflow -keystore dataflow.keystore -file dataflow_cert -storepass dataflowNext, you need to create a truststore that the shell can use, as follows:
$ keytool -importcert -keystore dataflow.truststore -alias dataflow -storepass dataflow -file dataflow_cert -nopromptNow you are ready to launch the Data Flow Shell with the following JVM arguments:
$ java -Djavax.net.ssl.trustStorePassword=dataflow \
-Djavax.net.ssl.trustStore=/path/to/dataflow.truststore \
-Djavax.net.ssl.trustStoreType=jks \
-jar spring-cloud-dataflow-shell-2.11.5.jar|
If you run into trouble establishing a connection over SSL, you can enable additional
logging by using and setting the |
Do not forget to target the Data Flow Server with the following command:
dataflow:> dataflow config server --uri https://localhost:8443/Skipping Certificate Validation
Alternatively, you can also bypass the certification validation by providing the
optional --dataflow.skip-ssl-validation=true command-line parameter.
If you set this command-line parameter, the shell accepts any (self-signed) SSL certificate.
|
If possible, you should avoid using this option. Disabling the trust manager defeats the purpose of SSL and makes your application vulnerable to man-in-the-middle attacks. |
8.2. Authentication by using OAuth 2.0
To support authentication and authorization, Spring Cloud Data Flow uses OAuth 2.0. It lets you integrate Spring Cloud Data Flow into Single Sign On (SSO) environments.
| As of Spring Cloud Data Flow 2.0, OAuth2 is the only mechanism for providing authentication and authorization. |
The following OAuth2 Grant Types are used:
-
Authorization Code: Used for the GUI (browser) integration. Visitors are redirected to your OAuth Service for authentication
-
Password: Used by the shell (and the REST integration), so visitors can log in with username and password
-
Client Credentials: Retrieves an access token directly from your OAuth provider and passes it to the Data Flow server by using the Authorization HTTP header
| Currently, Spring Cloud Data Flow uses opaque tokens and not transparent tokens (JWT). |
You can access the REST endpoints in two ways:
-
Basic authentication, which uses the Password Grant Type to authenticate with your OAuth2 service
-
Access token, which uses the Client Credentials Grant Type
| When you set up authentication, you really should enable HTTPS as well, especially in production environments. |
You can turn on OAuth2 authentication by adding the following to application.yml or by setting
environment variables. The following example shows the minimal setup needed for
CloudFoundry User Account and Authentication (UAA) Server:
spring:
security:
oauth2: (1)
client:
registration:
uaa: (2)
client-id: myclient
client-secret: mysecret
redirect-uri: '{baseUrl}/login/oauth2/code/{registrationId}'
authorization-grant-type: authorization_code
scope:
- openid (3)
provider:
uaa:
jwk-set-uri: http://uaa.local:8080/uaa/token_keys
token-uri: http://uaa.local:8080/uaa/oauth/token
user-info-uri: http://uaa.local:8080/uaa/userinfo (4)
user-name-attribute: user_name (5)
authorization-uri: http://uaa.local:8080/uaa/oauth/authorize
resourceserver:
opaquetoken:
introspection-uri: http://uaa.local:8080/uaa/introspect (6)
client-id: dataflow
client-secret: dataflow| 1 | Providing this property activates OAuth2 security. |
| 2 | The provider ID. You can specify more than one provider. |
| 3 | As the UAA is an OpenID provider, you must at least specify the openid scope.
If your provider also provides additional scopes to control the role assignments,
you must specify those scopes here as well. |
| 4 | OpenID endpoint. Used to retrieve user information such as the username. Mandatory. |
| 5 | The JSON property of the response that contains the username. |
| 6 | Used to introspect and validate a directly passed-in token. Mandatory. |
You can verify that basic authentication is working properly by using curl, as follows:
curl -u myusername:mypassword http://localhost:9393/ -H 'Accept: application/json'As a result, you should see a list of available REST endpoints.
When you access the Root URL with a web browser and
security enabled, you are redirected to the Dashboard UI. To see the
list of REST endpoints, specify the application/json Accept header. Also be sure
to add the Accept header by using tools such as
Postman (Chrome)
or RESTClient (Firefox).
|
Besides Basic Authentication, you can also provide an access token, to access the REST API. To do so, retrieve an OAuth2 Access Token from your OAuth2 provider and pass that access token to the REST Api by using the Authorization HTTP header, as follows:
$ curl -H "Authorization: Bearer <ACCESS_TOKEN>" http://localhost:9393/ -H 'Accept: application/json'8.3. Customizing Authorization
The preceding content mostly deals with authentication — that is, how to assess the identity of the user. In this section, we discuss the available authorization options — that is, who can do what.
The authorization rules are defined in dataflow-server-defaults.yml (part of
the Spring Cloud Data Flow Core module).
Because the determination of security roles is environment-specific,
Spring Cloud Data Flow, by default, assigns all roles to authenticated OAuth2
users. The DefaultDataflowAuthoritiesExtractor class is used for that purpose.
Alternatively, you can have Spring Cloud Data Flow map OAuth2 scopes to Data Flow roles by
setting the boolean property map-oauth-scopes for your provider to true (the default is false).
For example, if your provider’s ID is uaa, the property would be
spring.cloud.dataflow.security.authorization.provider-role-mappings.uaa.map-oauth-scopes.
Role Mappings
By default all roles are assigned to users that login to Spring Cloud Data Flow. However, you can set the property:
spring.cloud.dataflow.security.authorization.provider-role-mappings.uaa.map-oauth-scopes: true
This will instruct the underlying DefaultAuthoritiesExtractor to map
OAuth scopes to the respective authorities. The following scopes are supported:
-
Scope
dataflow.createmaps to theCREATErole -
Scope
dataflow.deploymaps to theDEPLOYrole -
Scope
dataflow.destroymaps to theDESTROYrole -
Scope
dataflow.managemaps to theMANAGErole -
Scope
dataflow.modifymaps to theMODIFYrole -
Scope
dataflow.schedulemaps to theSCHEDULErole -
Scope
dataflow.viewmaps to theVIEWrole
Additionally you can also map arbitrary scopes to each of the Data Flow roles:
spring:
cloud:
dataflow:
security:
authorization:
provider-role-mappings:
uaa:
map-oauth-scopes: true (1)
role-mappings:
ROLE_CREATE: dataflow.create (2)
ROLE_DEPLOY: dataflow.deploy
ROLE_DESTROY: dataflow.destoy
ROLE_MANAGE: dataflow.manage
ROLE_MODIFY: dataflow.modify
ROLE_SCHEDULE: dataflow.schedule
ROLE_VIEW: dataflow.view| 1 | Enables explicit mapping support from OAuth scopes to Data Flow roles |
| 2 | When role mapping support is enabled, you must provide a mapping for all 7 Spring Cloud Data Flow roles ROLE_CREATE, ROLE_DEPLOY, ROLE_DESTROY, ROLE_MANAGE, ROLE_MODIFY, ROLE_SCHEDULE, ROLE_VIEW. |
|
You can assign an OAuth scope to multiple Spring Cloud Data Flow roles, giving you flexible regarding the granularity of your authorization configuration. |
Group Mappings
Mapping roles from scopes has its own problems as it may not be always possible to change those in a given identity provider. If it’s possible to define group claims in a token returned from an identity provider, these can be used as well to map into server roles.
spring:
cloud:
dataflow:
security:
authorization:
provider-role-mappings:
uaa:
map-oauth-scopes: false
map-group-claims: true
group-claim: roles
group-mappings:
ROLE_CREATE: my-group-id
ROLE_DEPLOY: my-group-id
ROLE_DESTROY: my-group-id
ROLE_MANAGE: my-group-id
ROLE_MODIFY: my-group-id
ROLE_SCHEDULE: my-group-id
ROLE_VIEW: my-group-idYou can also customize the role-mapping behavior by providing your own Spring bean definition that
extends Spring Cloud Data Flow’s AuthorityMapper interface. In that case,
the custom bean definition takes precedence over the default one provided by
Spring Cloud Data Flow.
The default scheme uses seven roles to protect the REST endpoints that Spring Cloud Data Flow exposes:
-
ROLE_CREATE: For anything that involves creating, such as creating streams or tasks
-
ROLE_DEPLOY: For deploying streams or launching tasks
-
ROLE_DESTROY: For anything that involves deleting streams, tasks, and so on.
-
ROLE_MANAGE: For Boot management endpoints
-
ROLE_MODIFY: For anything that involves mutating the state of the system
-
ROLE_SCHEDULE: For scheduling related operation (such as scheduling a task)
-
ROLE_VIEW: For anything that relates to retrieving state
As mentioned earlier in this section, all authorization-related default settings are specified
in dataflow-server-defaults.yml, which is part of the Spring Cloud Data Flow Core
Module. Nonetheless, you can override those settings, if desired — for example,
in application.yml. The configuration takes the form of a YAML list (as some
rules may have precedence over others). Consequently, you need to copy and paste
the whole list and tailor it to your needs (as there is no way to merge lists).
Always refer to your version of the application.yml file, as the following snippet may be outdated.
|
The default rules are as follows:
spring:
cloud:
dataflow:
security:
authorization:
enabled: true
loginUrl: "/"
permit-all-paths: "/authenticate,/security/info,/assets/**,/dashboard/logout-success-oauth.html,/favicon.ico"
rules:
# About
- GET /about => hasRole('ROLE_VIEW')
# Audit
- GET /audit-records => hasRole('ROLE_VIEW')
- GET /audit-records/** => hasRole('ROLE_VIEW')
# Boot Endpoints
- GET /management/** => hasRole('ROLE_MANAGE')
# Apps
- GET /apps => hasRole('ROLE_VIEW')
- GET /apps/** => hasRole('ROLE_VIEW')
- DELETE /apps/** => hasRole('ROLE_DESTROY')
- POST /apps => hasRole('ROLE_CREATE')
- POST /apps/** => hasRole('ROLE_CREATE')
- PUT /apps/** => hasRole('ROLE_MODIFY')
# Completions
- GET /completions/** => hasRole('ROLE_VIEW')
# Job Executions & Batch Job Execution Steps && Job Step Execution Progress
- GET /jobs/executions => hasRole('ROLE_VIEW')
- PUT /jobs/executions/** => hasRole('ROLE_MODIFY')
- GET /jobs/executions/** => hasRole('ROLE_VIEW')
- GET /jobs/thinexecutions => hasRole('ROLE_VIEW')
# Batch Job Instances
- GET /jobs/instances => hasRole('ROLE_VIEW')
- GET /jobs/instances/* => hasRole('ROLE_VIEW')
# Running Applications
- GET /runtime/streams => hasRole('ROLE_VIEW')
- GET /runtime/streams/** => hasRole('ROLE_VIEW')
- GET /runtime/apps => hasRole('ROLE_VIEW')
- GET /runtime/apps/** => hasRole('ROLE_VIEW')
# Stream Definitions
- GET /streams/definitions => hasRole('ROLE_VIEW')
- GET /streams/definitions/* => hasRole('ROLE_VIEW')
- GET /streams/definitions/*/related => hasRole('ROLE_VIEW')
- POST /streams/definitions => hasRole('ROLE_CREATE')
- DELETE /streams/definitions/* => hasRole('ROLE_DESTROY')
- DELETE /streams/definitions => hasRole('ROLE_DESTROY')
# Stream Deployments
- DELETE /streams/deployments/* => hasRole('ROLE_DEPLOY')
- DELETE /streams/deployments => hasRole('ROLE_DEPLOY')
- POST /streams/deployments/** => hasRole('ROLE_MODIFY')
- GET /streams/deployments/** => hasRole('ROLE_VIEW')
# Stream Validations
- GET /streams/validation/ => hasRole('ROLE_VIEW')
- GET /streams/validation/* => hasRole('ROLE_VIEW')
# Stream Logs
- GET /streams/logs/* => hasRole('ROLE_VIEW')
# Task Definitions
- POST /tasks/definitions => hasRole('ROLE_CREATE')
- DELETE /tasks/definitions/* => hasRole('ROLE_DESTROY')
- GET /tasks/definitions => hasRole('ROLE_VIEW')
- GET /tasks/definitions/* => hasRole('ROLE_VIEW')
# Task Executions
- GET /tasks/executions => hasRole('ROLE_VIEW')
- GET /tasks/executions/* => hasRole('ROLE_VIEW')
- POST /tasks/executions => hasRole('ROLE_DEPLOY')
- POST /tasks/executions/* => hasRole('ROLE_DEPLOY')
- DELETE /tasks/executions/* => hasRole('ROLE_DESTROY')
- GET /tasks/thinexecutions => hasRole('ROLE_VIEW')
# Task Schedules
- GET /tasks/schedules => hasRole('ROLE_VIEW')
- GET /tasks/schedules/* => hasRole('ROLE_VIEW')
- GET /tasks/schedules/instances => hasRole('ROLE_VIEW')
- GET /tasks/schedules/instances/* => hasRole('ROLE_VIEW')
- POST /tasks/schedules => hasRole('ROLE_SCHEDULE')
- DELETE /tasks/schedules/* => hasRole('ROLE_SCHEDULE')
# Task Platform Account List */
- GET /tasks/platforms => hasRole('ROLE_VIEW')
# Task Validations
- GET /tasks/validation/ => hasRole('ROLE_VIEW')
- GET /tasks/validation/* => hasRole('ROLE_VIEW')
# Task Logs
- GET /tasks/logs/* => hasRole('ROLE_VIEW')
# Tools
- POST /tools/** => hasRole('ROLE_VIEW')The format of each line is the following:
HTTP_METHOD URL_PATTERN '=>' SECURITY_ATTRIBUTE
where:
-
HTTP_METHOD is one HTTP method (such as PUT or GET), capital case.
-
URL_PATTERN is an Ant-style URL pattern.
-
SECURITY_ATTRIBUTE is a SpEL expression. See Expression-Based Access Control.
-
Each of those is separated by one or whitespace characters (spaces, tabs, and so on).
Be mindful that the above is a YAML list, not a map (thus the use of '-' dashes
at the start of each line) that lives under the spring.cloud.dataflow.security.authorization.rules key.
Authorization — Shell and Dashboard Behavior
When security is enabled, the dashboard and the shell are role-aware, meaning that, depending on the assigned roles, not all functionality may be visible.
For instance, shell commands for which the user does not have the necessary roles are marked as unavailable.
|
Currently, the shell’s |
Conversely, for the Dashboard, the UI does not show pages or page elements for which the user is not authorized.
Securing the Spring Boot Management Endpoints
When security is enabled, the
Spring Boot HTTP Management Endpoints
are secured in the same way as the other REST endpoints. The management REST endpoints
are available under /management and require the MANAGEMENT role.
The default configuration in dataflow-server-defaults.yml is as follows:
management:
endpoints:
web:
base-path: /management
security:
roles: MANAGE| Currently, you should not customize the default management path. |
8.4. Setting up UAA Authentication
For local deployment scenarios, we recommend using the CloudFoundry User Account and Authentication (UAA) Server, which is OpenID certified. While the UAA is used by Cloud Foundry, it is also a fully featured stand alone OAuth2 server with enterprise features, such as LDAP integration.
Requirements
You need to check out, build and run UAA. To do so, make sure that you:
-
Use Java 8.
-
Have Git installed.
-
Have the CloudFoundry UAA Command Line Client installed.
-
Use a different host name for UAA when running on the same machine — for example,
uaa/.
If you run into issues installing uaac, you may have to set the GEM_HOME environment
variable:
export GEM_HOME="$HOME/.gem"You should also ensure that ~/.gem/gems/cf-uaac-4.2.0/bin has been added to your path.
Prepare UAA for JWT
As the UAA is an OpenID provider and uses JSON Web Tokens (JWT), it needs to have a private key for signing those JWTs:
openssl genrsa -out signingkey.pem 2048
openssl rsa -in signingkey.pem -pubout -out verificationkey.pem
export JWT_TOKEN_SIGNING_KEY=$(cat signingkey.pem)
export JWT_TOKEN_VERIFICATION_KEY=$(cat verificationkey.pem)Later, once the UAA is started, you can see the keys when you access uaa:8080/uaa/token_keys.
Here, the uaa in the URL uaa:8080/uaa/token_keys is the hostname.
|
Download and Start UAA
To download and install UAA, run the following commands:
git clone https://github.com/pivotal/uaa-bundled.git
cd uaa-bundled
./mvnw clean install
java -jar target/uaa-bundled-1.0.0.BUILD-SNAPSHOT.jarThe configuration of the UAA is driven by a YAML file uaa.yml, or you can script the configuration
using the UAA Command Line Client:
uaac target http://uaa:8080/uaa
uaac token client get admin -s adminsecret
uaac client add dataflow \
--name dataflow \
--secret dataflow \
--scope cloud_controller.read,cloud_controller.write,openid,password.write,scim.userids,sample.create,sample.view,dataflow.create,dataflow.deploy,dataflow.destroy,dataflow.manage,dataflow.modify,dataflow.schedule,dataflow.view \
--authorized_grant_types password,authorization_code,client_credentials,refresh_token \
--authorities uaa.resource,dataflow.create,dataflow.deploy,dataflow.destroy,dataflow.manage,dataflow.modify,dataflow.schedule,dataflow.view,sample.view,sample.create\
--redirect_uri http://localhost:9393/login \
--autoapprove openid
uaac group add "sample.view"
uaac group add "sample.create"
uaac group add "dataflow.view"
uaac group add "dataflow.create"
uaac user add springrocks -p mysecret --emails [email protected]
uaac user add vieweronly -p mysecret --emails [email protected]
uaac member add "sample.view" springrocks
uaac member add "sample.create" springrocks
uaac member add "dataflow.view" springrocks
uaac member add "dataflow.create" springrocks
uaac member add "sample.view" vieweronlyThe preceding script sets up the dataflow client as well as two users:
-
User springrocks has have both scopes:
sample.viewandsample.create. -
User vieweronly has only one scope:
sample.view.
Once added, you can quickly double-check that the UAA has the users created:
curl -v -d"username=springrocks&password=mysecret&client_id=dataflow&grant_type=password" -u "dataflow:dataflow" http://uaa:8080/uaa/oauth/token -d 'token_format=opaque'The preceding command should produce output similar to the following:
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to uaa (127.0.0.1) port 8080 (#0)
* Server auth using Basic with user 'dataflow'
> POST /uaa/oauth/token HTTP/1.1
> Host: uaa:8080
> Authorization: Basic ZGF0YWZsb3c6ZGF0YWZsb3c=
> User-Agent: curl/7.54.0
> Accept: */*
> Content-Length: 97
> Content-Type: application/x-www-form-urlencoded
>
* upload completely sent off: 97 out of 97 bytes
< HTTP/1.1 200
< Cache-Control: no-store
< Pragma: no-cache
< X-XSS-Protection: 1; mode=block
< X-Frame-Options: DENY
< X-Content-Type-Options: nosniff
< Content-Type: application/json;charset=UTF-8
< Transfer-Encoding: chunked
< Date: Thu, 31 Oct 2019 21:22:59 GMT
<
* Connection #0 to host uaa left intact
{"access_token":"0329c8ecdf594ee78c271e022138be9d","token_type":"bearer","id_token":"eyJhbGciOiJSUzI1NiIsImprdSI6Imh0dHBzOi8vbG9jYWxob3N0OjgwODAvdWFhL3Rva2VuX2tleXMiLCJraWQiOiJsZWdhY3ktdG9rZW4ta2V5IiwidHlwIjoiSldUIn0.eyJzdWIiOiJlZTg4MDg4Ny00MWM2LTRkMWQtYjcyZC1hOTQ4MmFmNGViYTQiLCJhdWQiOlsiZGF0YWZsb3ciXSwiaXNzIjoiaHR0cDovL2xvY2FsaG9zdDo4MDkwL3VhYS9vYXV0aC90b2tlbiIsImV4cCI6MTU3MjYwMDE3OSwiaWF0IjoxNTcyNTU2OTc5LCJhbXIiOlsicHdkIl0sImF6cCI6ImRhdGFmbG93Iiwic2NvcGUiOlsib3BlbmlkIl0sImVtYWlsIjoic3ByaW5ncm9ja3NAc29tZXBsYWNlLmNvbSIsInppZCI6InVhYSIsIm9yaWdpbiI6InVhYSIsImp0aSI6IjAzMjljOGVjZGY1OTRlZTc4YzI3MWUwMjIxMzhiZTlkIiwiZW1haWxfdmVyaWZpZWQiOnRydWUsImNsaWVudF9pZCI6ImRhdGFmbG93IiwiY2lkIjoiZGF0YWZsb3ciLCJncmFudF90eXBlIjoicGFzc3dvcmQiLCJ1c2VyX25hbWUiOiJzcHJpbmdyb2NrcyIsInJldl9zaWciOiJlOTkyMDQxNSIsInVzZXJfaWQiOiJlZTg4MDg4Ny00MWM2LTRkMWQtYjcyZC1hOTQ4MmFmNGViYTQiLCJhdXRoX3RpbWUiOjE1NzI1NTY5Nzl9.bqYvicyCPB5cIIu_2HEe5_c7nSGXKw7B8-reTvyYjOQ2qXSMq7gzS4LCCQ-CMcb4IirlDaFlQtZJSDE-_UsM33-ThmtFdx--TujvTR1u2nzot4Pq5A_ThmhhcCB21x6-RNNAJl9X9uUcT3gKfKVs3gjE0tm2K1vZfOkiGhjseIbwht2vBx0MnHteJpVW6U0pyCWG_tpBjrNBSj9yLoQZcqrtxYrWvPHaa9ljxfvaIsOnCZBGT7I552O1VRHWMj1lwNmRNZy5koJFPF7SbhiTM8eLkZVNdR3GEiofpzLCfoQXrr52YbiqjkYT94t3wz5C6u1JtBtgc2vq60HmR45bvg","refresh_token":"6ee95d017ada408697f2d19b04f7aa6c-r","expires_in":43199,"scope":"scim.userids openid sample.create cloud_controller.read password.write cloud_controller.write sample.view","jti":"0329c8ecdf594ee78c271e022138be9d"}By using the token_format parameter, you can request the token to be either:
-
opaque
-
jwt
9. Configuration - Local
9.1. Feature Toggles
Spring Cloud Data Flow Server offers specific set of features that can be enabled/disabled when launching. These features include all the lifecycle operations and REST endpoints (server and client implementations, including the shell and the UI) for:
-
Streams (requires Skipper)
-
Tasks
-
Task Scheduler
One can enable and disable these features by setting the following boolean properties when launching the Data Flow server:
-
spring.cloud.dataflow.features.streams-enabled -
spring.cloud.dataflow.features.tasks-enabled -
spring.cloud.dataflow.features.schedules-enabled
By default, stream (requires Skipper), and tasks are enabled and Task Scheduler is disabled by default.
The REST /about endpoint provides information on the features that have been enabled and disabled.
9.2. Java Home
When launching Spring Cloud Data Flow or Skipper Server they may need to know where Java 17 home is in order to successfully launch Spring Boot 3 applications.
By passing the following property you can provide the path.
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-{project-version}.jar \
--spring.cloud.dataflow.defaults.boot3.local.javaHomePath=/usr/lib/jvm/java-17 \
--spring.cloud.dataflow.defaults.boot2.local.javaHomePath=/usr/lib/jvm/java-1.89.3. Database
A relational database is used to store stream and task definitions as well as the state of executed tasks. Spring Cloud Data Flow provides schemas for MariaDB, MySQL, Oracle, PostgreSQL, Db2, SQL Server, and H2. The schema is automatically created when the server starts.
| The JDBC drivers for MariaDB, MySQL (via the MariaDB driver), PostgreSQL, SQL Server are available without additional configuration. To use any other database you need to put the corresponding JDBC driver jar on the classpath of the server as described here. |
To configure a database the following properties must be set:
-
spring.datasource.url -
spring.datasource.username -
spring.datasource.password -
spring.datasource.driver-class-name -
spring.jpa.database-platform
The username and password are the same regardless of the database. However, the url and driver-class-name vary per database as follows.
| Database | spring.datasource.url | spring.datasource.driver-class-name | spring.jpa.database-platform | Driver included |
|---|---|---|---|---|
MariaDB 10.0 - 10.1 |
jdbc:mariadb://${db-hostname}:${db-port}/${db-name} |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MariaDB10Dialect |
Yes |
MariaDB 10.2 |
jdbc:mariadb://${db-hostname}:${db-port}/${db-name} |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MariaDB102Dialect |
Yes |
MariaDB 10.3 - 10.5 |
jdbc:mariadb://${db-hostname}:${db-port}/${db-name} |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MariaDB103Dialect |
Yes |
MariaDB 10.6+ |
jdbc:mariadb://${db-hostname}:${db-port}/${db-name} |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MariaDB106Dialect[1] |
Yes |
MySQL 5.7 |
jdbc:mysql://${db-hostname}:${db-port}/${db-name}?permitMysqlScheme |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MySQL57Dialect |
Yes |
MySQL 8.0+ |
jdbc:mysql://${db-hostname}:${db-port}/${db-name}?allowPublicKeyRetrieval=true&useSSL=false&autoReconnect=true&permitMysqlScheme[2] |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MySQL8Dialect |
Yes |
PostgresSQL |
jdbc:postgres://${db-hostname}:${db-port}/${db-name} |
org.postgresql.Driver |
Remove for Hibernate default |
Yes |
SQL Server |
jdbc:sqlserver://${db-hostname}:${db-port};databasename=${db-name}&encrypt=false |
com.microsoft.sqlserver.jdbc.SQLServerDriver |
Remove for Hibernate default |
Yes |
DB2 |
jdbc:db2://${db-hostname}:${db-port}/{db-name} |
com.ibm.db2.jcc.DB2Driver |
Remove for Hibernate default |
No |
Oracle |
jdbc:oracle:thin:@${db-hostname}:${db-port}/{db-name} |
oracle.jdbc.OracleDriver |
Remove for Hibernate default |
No |
9.3.1. H2
When no other database is configured then Spring Cloud Data Flow uses an embedded instance of the H2 database as the default.
| H2 is good for development purposes but is not recommended for production use nor is it supported as an external mode. |
9.3.2. Database configuration
When running locally, the database properties can be passed as environment variables or command-line arguments to the Data Flow Server. For example, to start the server with MariaDB using command line arguments execute the following command:
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.11.5.jar \
--spring.datasource.url=jdbc:mariadb://localhost:3306/mydb \
--spring.datasource.username=user \
--spring.datasource.password=pass \
--spring.datasource.driver-class-name=org.mariadb.jdbc.DriverLikewise, to start the server with MariaDB using environment variables execute the following command:
SPRING_DATASOURCE_URL=jdbc:mariadb://localhost:3306/mydb
SPRING_DATASOURCE_USERNAME=user
SPRING_DATASOURCE_PASSWORD=pass
SPRING_DATASOURCE_DRIVER_CLASS_NAME=org.mariadb.jdbc.Driver
SPRING_JPA_DATABASE_PLATFORM=org.hibernate.dialect.MariaDB106Dialect
java -jar spring-cloud-dataflow-server/target/spring-cloud-dataflow-server-2.11.5.jar9.3.3. Schema Handling
On default database schema is managed with Flyway which is convenient if it’s possible to give enough permissions to a database user.
Here’s a description what happens when Skipper server is started:
-
Flyway checks if
flyway_schema_historytable exists. -
Does a baseline(to version 1) if schema is not empty as Dataflow tables may be in place if a shared DB is used.
-
If schema is empty, flyway assumes to start from a scratch.
-
Goes through all needed schema migrations.
Here’s a description what happens when Dataflow server is started:
-
Flyway checks if
flyway_schema_history_dataflowtable exists. -
Does a baseline(to version 1) if schema is not empty as Skipper tables may be in place if a shared DB is used.
-
If schema is empty, flyway assumes to start from a scratch.
-
Goes through all needed schema migrations.
|
We have schema ddl’s in our source code
schemas
which can be used manually if Flyway is disabled by using configuration
|
9.4. Deployer Properties
You can use the following configuration properties of the Local deployer to customize how Streams and Tasks are deployed.
When deploying using the Data Flow shell, you can use the syntax deployer.<appName>.local.<deployerPropertyName>. See below for an example shell usage.
These properties are also used when configuring Local Task Platforms in the Data Flow server and local platforms in Skipper for deploying Streams.
| Deployer Property Name | Description | Default Value |
|---|---|---|
workingDirectoriesRoot |
Directory in which all created processes will run and create log files. |
java.io.tmpdir |
envVarsToInherit |
Array of regular expression patterns for environment variables that are passed to launched applications. |
<"TMP", "LANG", "LANGUAGE", "LC_.*", "PATH", "SPRING_APPLICATION_JSON"> on windows and <"TMP", "LANG", "LANGUAGE", "LC_.*", "PATH"> on Unix |
deleteFilesOnExit |
Whether to delete created files and directories on JVM exit. |
true |
javaCmd |
Command to run java |
java |
javaHomePath.<bootVersion> |
Path to JDK installation for launching applications depending on their registered Boot version. |
System property |
shutdownTimeout |
Max number of seconds to wait for app shutdown. |
30 |
javaOpts |
The Java Options to pass to the JVM, e.g -Dtest=foo |
<none> |
inheritLogging |
allow logging to be redirected to the output stream of the process that triggered child process. |
false |
debugPort |
Port for remote debugging |
<none> |
As an example, to set Java options for the time application in the ticktock stream, use the following stream deployment properties.
dataflow:> stream create --name ticktock --definition "time --server.port=9000 | log"
dataflow:> stream deploy --name ticktock --properties "deployer.time.local.javaOpts=-Xmx2048m -Dtest=foo"As a convenience, you can set the deployer.memory property to set the Java option -Xmx, as shown in the following example:
dataflow:> stream deploy --name ticktock --properties "deployer.time.memory=2048m"At deployment time, if you specify an -Xmx option in the deployer.<app>.local.javaOpts property in addition to a value of the deployer.<app>.local.memory option, the value in the javaOpts property has precedence. Also, the javaOpts property set when deploying the application has precedence over the Data Flow Server’s spring.cloud.deployer.local.javaOpts property.
9.5. Logging
Spring Cloud Data Flow local server is automatically configured to use RollingFileAppender for logging.
The logging configuration is located on the classpath contained in a file named logback-spring.xml.
By default, the log file is configured to use:
<property name="LOG_FILE" value="${LOG_FILE:-${LOG_PATH:-${LOG_TEMP:-${java.io.tmpdir:-/tmp}}}/spring-cloud-dataflow-server-local.log}"/>with the logback configuration for the RollingPolicy:
<appender name="FILE"
class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- daily rolling -->
<fileNamePattern>${LOG_FILE}.${LOG_FILE_ROLLING_FILE_NAME_PATTERN:-%d{yyyy-MM-dd}}.%i.gz</fileNamePattern>
<maxFileSize>${LOG_FILE_MAX_SIZE:-100MB}</maxFileSize>
<maxHistory>${LOG_FILE_MAX_HISTORY:-30}</maxHistory>
<totalSizeCap>${LOG_FILE_TOTAL_SIZE_CAP:-500MB}</totalSizeCap>
</rollingPolicy>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
</appender>To check the java.io.tmpdir for the current Spring Cloud Data Flow Server local server,
jinfo <pid> | grep "java.io.tmpdir"If you want to change or override any of the properties LOG_FILE, LOG_PATH, LOG_TEMP, LOG_FILE_MAX_SIZE, LOG_FILE_MAX_HISTORY and LOG_FILE_TOTAL_SIZE_CAP, please set them as system properties.
9.6. Streams
Data Flow Server delegates to the Skipper server the management of the Stream’s lifecycle. Set the configuration property spring.cloud.skipper.client.serverUri to the location of Skipper, e.g.
$ java -jar spring-cloud-dataflow-server-2.11.5.jar --spring.cloud.skipper.client.serverUri=https://192.51.100.1:7577/apiThe configuration of how streams are deployed and to which platforms, is done by configuration of platform accounts on the Skipper server.
See the documentation on platforms for more information.
9.7. Tasks
The Data Flow server is responsible for deploying Tasks.
Tasks that are launched by Data Flow write their state to the same database that is used by the Data Flow server.
For Tasks which are Spring Batch Jobs, the job and step execution data is also stored in this database.
As with streams launched by Skipper, Tasks can be launched to multiple platforms.
If no platform is defined, a platform named default is created using the default values of the class LocalDeployerProperties, which is summarized in the table Local Deployer Properties
To configure new platform accounts for the local platform, provide an entry under the spring.cloud.dataflow.task.platform.local section in your application.yaml file or via another Spring Boot supported mechanism.
In the following example, two local platform accounts named localDev and localDevDebug are created.
The keys such as shutdownTimeout and javaOpts are local deployer properties.
spring:
cloud:
dataflow:
task:
platform:
local:
accounts:
localDev:
shutdownTimeout: 60
javaOpts: "-Dtest=foo -Xmx1024m"
localDevDebug:
javaOpts: "-Xdebug -Xmx2048m"
By defining one platform as default allows you to skip using platformName where its use would otherwise be required.
|
When launching a task, pass the value of the platform account name using the task launch option --platformName If you do not pass a value for platformName, the value default will be used.
| When deploying a task to multiple platforms, the configuration of the task needs to connect to the same database as the Data Flow Server. |
You can configure the Data Flow server that is running locally to deploy tasks to Cloud Foundry or Kubernetes. See the sections on Cloud Foundry Task Platform Configuration and Kubernetes Task Platform Configuration for more information.
Detailed examples for launching and scheduling tasks across multiple platforms, are available in this section Multiple Platform Support for Tasks on dataflow.spring.io.
9.8. Security Configuration
9.8.1. CloudFoundry User Account and Authentication (UAA) Server
See the CloudFoundry User Account and Authentication (UAA) Server configuration section for details how to configure for local testing and development.
9.8.2. LDAP Authentication
LDAP Authentication (Lightweight Directory Access Protocol) is indirectly provided by Spring Cloud Data Flow using the UAA. The UAA itself provides comprehensive LDAP support.
|
While you may use your own OAuth2 authentication server, the LDAP support documented here requires using the UAA as authentication server. For any other provider, please consult the documentation for that particular provider. |
The UAA supports authentication against an LDAP (Lightweight Directory Access Protocol) server using the following modes:
|
When integrating with an external identity provider such as LDAP, authentication within the UAA becomes chained. UAA first attempts to authenticate with a user’s credentials against the UAA user store before the external provider, LDAP. For more information, see Chained Authentication in the User Account and Authentication LDAP Integration GitHub documentation. |
LDAP Role Mapping
The OAuth2 authentication server (UAA), provides comprehensive support for mapping LDAP groups to OAuth scopes.
The following options exist:
-
ldap/ldap-groups-null.xmlNo groups will be mapped -
ldap/ldap-groups-as-scopes.xmlGroup names will be retrieved from an LDAP attribute. E.g.CN -
ldap/ldap-groups-map-to-scopes.xmlGroups will be mapped to UAA groups using the external_group_mapping table
These values are specified via the configuration property ldap.groups.file controls. Under the covers
these values reference a Spring XML configuration file.
|
During test and development it might be necessary to make frequent changes to LDAP groups and users and see those reflected in the UAA. However, user information is cached for the duration of the login. The following script helps to retrieve the updated information quickly: |
9.8.3. Spring Security OAuth2 Resource/Authorization Server Sample
For local testing and development, you may also use the Resource and Authorization Server support provided by Spring Security. It allows you to easily create your own OAuth2 Server by configuring the SecurityFilterChain.
Samples can be found at: Spring Security Samples
9.8.4. Data Flow Shell Authentication
When using the Shell, the credentials can either be provided via username and password or by specifying a credentials-provider command. If your OAuth2 provider supports the Password Grant Type you can start the Data Flow Shell with:
$ java -jar spring-cloud-dataflow-shell-2.11.5.jar \
--dataflow.uri=http://localhost:9393 \ (1)
--dataflow.username=my_username \ (2)
--dataflow.password=my_password \ (3)
--skip-ssl-validation \ (4)| 1 | Optional, defaults to localhost:9393. |
| 2 | Mandatory. |
| 3 | If the password is not provided, the user is prompted for it. |
| 4 | Optional, defaults to false, ignores certificate errors (when using self-signed certificates). Use cautiously! |
| Keep in mind that when authentication for Spring Cloud Data Flow is enabled, the underlying OAuth2 provider must support the Password OAuth2 Grant Type if you want to use the Shell via username/password authentication. |
From within the Data Flow Shell you can also provide credentials by using the following command:
server-unknown:>dataflow config server \
--uri http://localhost:9393 \ (1)
--username myuser \ (2)
--password mysecret \ (3)
--skip-ssl-validation \ (4)| 1 | Optional, defaults to localhost:9393. |
| 2 | Mandatory.. |
| 3 | If security is enabled, and the password is not provided, the user is prompted for it. |
| 4 | Optional, ignores certificate errors (when using self-signed certificates). Use cautiously! |
The following image shows a typical shell command to connect to and authenticate a Data Flow Server:

Once successfully targeted, you should see the following output:
dataflow:>dataflow config info
dataflow config info
╔═══════════╤═══════════════════════════════════════╗
║Credentials│[username='my_username, password=****']║
╠═══════════╪═══════════════════════════════════════╣
║Result │ ║
║Target │http://localhost:9393 ║
╚═══════════╧═══════════════════════════════════════╝Alternatively, you can specify the credentials-provider command in order to
pass-in a bearer token directly, instead of providing a username and password.
This works from within the shell or by providing the
--dataflow.credentials-provider-command command-line argument when starting the Shell.
|
When using the credentials-provider command, please be aware that your specified command must return a Bearer token (Access Token prefixed with Bearer). For instance, in Unix environments the following simplistic command can be used: |
9.9. About API Configuration
The Spring Cloud Data Flow About Restful API result contains a display name, version, and, if specified, a URL for each of the major dependencies that comprise Spring Cloud Data Flow. The result (if enabled) also contains the sha1 and or sha256 checksum values for the shell dependency. The information that is returned for each of the dependencies is configurable by setting the following properties:
| Property Name | Description |
|---|---|
spring.cloud.dataflow.version-info.spring-cloud-dataflow-core.name |
Name to be used for the core |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-core.version |
Version to be used for the core |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-dashboard.name |
Name to be used for the dashboard |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-dashboard.version |
Version to be used for the dashboard |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-implementation.name |
Name to be used for the implementation |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-implementation.version |
Version to be used for the implementation |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.name |
Name to be used for the shell |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.version |
Version to be used for the shell |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.url |
URL to be used for downloading the shell dependency |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha1 |
Sha1 checksum value that is returned with the shell dependency info |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha256 |
Sha256 checksum value that is returned with the shell dependency info |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha1-url |
if |
spring.cloud.dataflow.version-info.spring-cloud-dataflow-shell.checksum-sha256-url |
if the |
9.9.1. Enabling Shell Checksum values
By default, checksum values are not displayed for the shell dependency. If
you need this feature enabled, set the
spring.cloud.dataflow.version-info.dependency-fetch.enabled property to true.
9.9.2. Reserved Values for URLs
There are reserved values (surrounded by curly braces) that you can insert into the URL that will make sure that the links are up to date:
-
repository: if using a build-snapshot, milestone, or release candidate of Data Flow, the repository refers to the repo-spring-io repository. Otherwise, it refers to Maven Central. -
version: Inserts the version of the jar/pom.
For example,
https://myrepository/org/springframework/cloud/spring-cloud-dataflow-shell/{version}/spring-cloud-dataflow-shell-\{version}.jarproduces
https://myrepository/org/springframework/cloud/spring-cloud-dataflow-shell/2.1.4/spring-cloud-dataflow-shell-2.11.0.jarif you were using the 2.11.0 version of the Spring Cloud Data Flow Shell.
10. Configuration - Cloud Foundry
This section describes how to configure Spring Cloud Data Flow server’s features, such as security and which relational database to use. It also describes how to configure Spring Cloud Data Flow shell’s features.
10.1. Feature Toggles
Data Flow server offers a specific set of features that you can enable or disable when launching. These features include all the lifecycle operations and REST endpoints (server, client implementations including Shell and the UI) for:
-
Streams
-
Tasks
You can enable or disable these features by setting the following boolean properties when you launch the Data Flow server:
-
spring.cloud.dataflow.features.streams-enabled -
spring.cloud.dataflow.features.tasks-enabled
By default, all features are enabled.
The REST endpoint (/features) provides information on the enabled and disabled features.
10.2. Deployer Properties
You can use the following configuration properties of the Data Flow server’s Cloud Foundry deployer to customize how applications are deployed.
When deploying with the Data Flow shell, you can use the syntax deployer.<appName>.cloudfoundry.<deployerPropertyName>. See below for an example shell usage.
These properties are also used when configuring the Cloud Foundry Task platforms in the Data Flow server and and Kubernetes platforms in Skipper for deploying Streams.
| Deployer Property Name | Description | Default Value |
|---|---|---|
services |
The names of services to bind to the deployed application. |
<none> |
host |
The host name to use as part of the route. |
hostname derived by Cloud Foundry |
domain |
The domain to use when mapping routes for the application. |
<none> |
routes |
The list of routes that the application should be bound to. Mutually exclusive with host and domain. |
<none> |
buildpack |
The buildpack to use for deploying the application. Deprecated use buildpacks. |
|
buildpacks |
The list of buildpacks to use for deploying the application. |
|
memory |
The amount of memory to allocate. Default unit is mebibytes, 'M' and 'G" suffixes supported |
1024m |
disk |
The amount of disk space to allocate. Default unit is mebibytes, 'M' and 'G" suffixes supported. |
1024m |
healthCheck |
The type of health check to perform on deployed application. Values can be HTTP, NONE, PROCESS, and PORT |
PORT |
healthCheckHttpEndpoint |
The path that the http health check will use, |
/health |
healthCheckTimeout |
The timeout value for health checks in seconds. |
120 |
instances |
The number of instances to run. |
1 |
enableRandomAppNamePrefix |
Flag to enable prefixing the app name with a random prefix. |
true |
apiTimeout |
Timeout for blocking API calls, in seconds. |
360 |
statusTimeout |
Timeout for status API operations in milliseconds |
5000 |
useSpringApplicationJson |
Flag to indicate whether application properties are fed into |
true |
stagingTimeout |
Timeout allocated for staging the application. |
15 minutes |
startupTimeout |
Timeout allocated for starting the application. |
5 minutes |
appNamePrefix |
String to use as prefix for name of deployed application |
The Spring Boot property |
deleteRoutes |
Whether to also delete routes when un-deploying an application. |
true |
javaOpts |
The Java Options to pass to the JVM, e.g -Dtest=foo |
<none> |
pushTasksEnabled |
Whether to push task applications or assume that the application already exists when launched. |
true |
autoDeleteMavenArtifacts |
Whether to automatically delete Maven artifacts from the local repository when deployed. |
true |
env.<key> |
Defines a top level environment variable. This is useful for customizing Java build pack configuration which must be included as top level environment variables in the application manifest, as the Java build pack does not recognize |
The deployer determines if the app has Java CfEnv in its classpath. If so, it applies the required configuration. |
Here are some examples using the Cloud Foundry deployment properties:
-
You can set the buildpack that is used to deploy each application. For example, to use the Java offline buildback, set the following environment variable:
cf set-env dataflow-server SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_BUILDPACKS java_buildpack_offline-
Setting
buildpackis now deprecated in favour ofbuildpackswhich allows you to pass on more than one if needed. More about this can be found from How Buildpacks Work. -
You can customize the health check mechanism used by Cloud Foundry to assert whether apps are running by using the
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_HEALTH_CHECKenvironment variable. The current supported options arehttp(the default),port, andnone.
You can also set environment variables that specify the HTTP-based health check endpoint and timeout: SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_HEALTH_CHECK_ENDPOINT and SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_HEALTH_CHECK_TIMEOUT, respectively. These default to /health (the Spring Boot default location) and 120 seconds.
-
You can also specify deployment properties by using the DSL. For instance, if you want to set the allocated memory for the
httpapplication to 512m and also bind a postgres service to thejdbcapplication, you can run the following commands:
dataflow:> stream create --name postgresstream --definition "http | jdbc --tableName=names --columns=name"
dataflow:> stream deploy --name postgresstream --properties "deployer.http.memory=512, deployer.jdbc.cloudfoundry.services=postgres"|
You can configure these settings separately for stream and task apps. To alter settings for tasks,
substitute |
10.3. Tasks
The Data Flow server is responsible for deploying Tasks.
Tasks that are launched by Data Flow write their state to the same database that is used by the Data Flow server.
For Tasks which are Spring Batch Jobs, the job and step execution data is also stored in this database.
As with Skipper, Tasks can be launched to multiple platforms.
When Data Flow is running on Cloud Foundry, a Task platfom must be defined.
To configure new platform accounts that target Cloud Foundry, provide an entry under the spring.cloud.dataflow.task.platform.cloudfoundry section in your application.yaml file for via another Spring Boot supported mechanism.
In the following example, two Cloud Foundry platform accounts named dev and qa are created.
The keys such as memory and disk are Cloud Foundry Deployer Properties.
spring:
cloud:
dataflow:
task:
platform:
cloudfoundry:
accounts:
dev:
connection:
url: https://api.run.pivotal.io
org: myOrg
space: mySpace
domain: cfapps.io
username: [email protected]
password: drowssap
skipSslValidation: false
deployment:
memory: 512m
disk: 2048m
instances: 4
services: rabbit,postgres
appNamePrefix: dev1
qa:
connection:
url: https://api.run.pivotal.io
org: myOrgQA
space: mySpaceQA
domain: cfapps.io
username: [email protected]
password: drowssap
skipSslValidation: true
deployment:
memory: 756m
disk: 724m
instances: 2
services: rabbitQA,postgresQA
appNamePrefix: qa1
By defining one platform as default allows you to skip using platformName where its use would otherwise be required.
|
When launching a task, pass the value of the platform account name using the task launch option --platformName If you do not pass a value for platformName, the value default will be used.
| When deploying a task to multiple platforms, the configuration of the task needs to connect to the same database as the Data Flow Server. |
You can configure the Data Flow server that is on Cloud Foundry to deploy tasks to Cloud Foundry or Kubernetes. See the section on Kubernetes Task Platform Configuration for more information.
Detailed examples for launching and scheduling tasks across multiple platforms, are available in this section Multiple Platform Support for Tasks on dataflow.spring.io.
10.4. Application Names and Prefixes
To help avoid clashes with routes across spaces in Cloud Foundry, a naming strategy that provides a random prefix to a
deployed application is available and is enabled by default. You can override the default configurations
and set the respective properties by using cf set-env commands.
For instance, if you want to disable the randomization, you can override it by using the following command:
cf set-env dataflow-server SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_ENABLE_RANDOM_APP_NAME_PREFIX false10.5. Custom Routes
As an alternative to a random name or to get even more control over the hostname used by the deployed apps, you can use custom deployment properties, as the following example shows:
dataflow:>stream create foo --definition "http | log"
sdataflow:>stream deploy foo --properties "deployer.http.cloudfoundry.domain=mydomain.com,
deployer.http.cloudfoundry.host=myhost,
deployer.http.cloudfoundry.route-path=my-path"The preceding example binds the http app to the myhost.mydomain.com/my-path URL. Note that this
example shows all of the available customization options. In practice, you can use only one or two out of the three.
10.6. Docker Applications
Starting with version 1.2, it is possible to register and deploy Docker based apps as part of streams and tasks by using Data Flow for Cloud Foundry.
If you use Spring Boot and RabbitMQ-based Docker images, you can provide a common deployment property
to facilitate binding the apps to the RabbitMQ service. Assuming your RabbitMQ service is named rabbit, you can provide the following:
cf set-env dataflow-server SPRING_APPLICATION_JSON '{"spring.cloud.dataflow.applicationProperties.stream.spring.rabbitmq.addresses": "${vcap.services.rabbit.credentials.protocols.amqp.uris}"}'For Spring Cloud Task apps, you can use something similar to the following, if you use a database service instance named postgres:
cf set-env SPRING_DATASOURCE_URL '${vcap.services.postgres.credentials.jdbcUrl}'
cf set-env SPRING_DATASOURCE_USERNAME '${vcap.services.postgres.credentials.username}'
cf set-env SPRING_DATASOURCE_PASSWORD '${vcap.services.postgres.credentials.password}'
cf set-env SPRING_DATASOURCE_DRIVER_CLASS_NAME 'org.mariadb.jdbc.Driver'
cf set-env SPRING_JPA_DATABASE_PLATFORM 'org.hibernate.dialect.MariaDB106Dialect'For non-Java or non-Boot applications, your Docker app must parse the VCAP_SERVICES variable in order to bind to any available services.
|
Passing application properties
When using non-Boot applications, chances are that you want to pass the application properties by using traditional
environment variables, as opposed to using the special |
10.7. Application-level Service Bindings
When deploying streams in Cloud Foundry, you can take advantage of application-specific service bindings, so not all services are globally configured for all the apps orchestrated by Spring Cloud Data Flow.
For instance, if you want to provide a postgres service binding only for the jdbc application in the following stream
definition, you can pass the service binding as a deployment property:
dataflow:>stream create --name httptojdbc --definition "http | jdbc"
dataflow:>stream deploy --name httptojdbc --properties "deployer.jdbc.cloudfoundry.services=postgresService"where postgresService is the name of the service specifically bound only to the jdbc application and the http
application does not get the binding by this method.
If you have more than one service to bind, they can be passed as comma-separated items
(for example: deployer.jdbc.cloudfoundry.services=postgresService,someService).
10.8. Configuring Service binding parameters
The CloudFoundry API supports providing configuration parameters when binding a service instance. Some service brokers require or recommend binding configuration. For example, binding the Google Cloud Platform service using the CF CLI looks something like:
cf bind-service my-app my-google-bigquery-example -c '{"role":"bigquery.user"}'Likewise the NFS Volume Service supports binding configuration such as:
cf bind-service my-app nfs_service_instance -c '{"uid":"1000","gid":"1000","mount":"/var/volume1","readonly":true}'Starting with version 2.0, Data Flow for Cloud Foundry allows you to provide binding configuration parameters may be provided in the app level or server level cloudfoundry.services deployment property. For example, to bind to the nfs service, as above :
dataflow:> stream deploy --name mystream --properties "deployer.<app>.cloudfoundry.services='nfs_service_instance uid:1000,gid:1000,mount:/var/volume1,readonly:true'"The format is intended to be compatible with the Data Flow DSL parser.
Generally, the cloudfoundry.services deployment property accepts a comma delimited value.
Since a comma is also used to separate configuration parameters, and to avoid white space issues, any item including configuration parameters must be enclosed in singe quotes. Valid values incude things like:
rabbitmq,'nfs_service_instance uid:1000,gid:1000,mount:/var/volume1,readonly:true',postgres,'my-google-bigquery-example role:bigquery.user'
Spaces are permitted within single quotes and = may be used instead of : to delimit key-value pairs.
|
10.9. User-provided Services
In addition to marketplace services, Cloud Foundry supports User-provided Services (UPS). Throughout this reference manual, regular services have been mentioned, but there is nothing precluding the use of User-provided Services as well, whether for use as the messaging middleware (for example, if you want to use an external Apache Kafka installation) or for use by some of the stream applications (for example, an Oracle Database).
Now we review an example of extracting and supplying the connection credentials from a UPS.
The following example shows a sample UPS setup for Apache Kafka:
cf create-user-provided-service kafkacups -p '{”brokers":"HOST:PORT","zkNodes":"HOST:PORT"}'The UPS credentials are wrapped within VCAP_SERVICES, and they can be supplied directly in the stream definition, as
the following example shows.
stream create fooz --definition "time | log"
stream deploy fooz --properties "app.time.spring.cloud.stream.kafka.binder.brokers=${vcap.services.kafkacups.credentials.brokers},app.time.spring.cloud.stream.kafka.binder.zkNodes=${vcap.services.kafkacups.credentials.zkNodes},app.log.spring.cloud.stream.kafka.binder.brokers=${vcap.services.kafkacups.credentials.brokers},app.log.spring.cloud.stream.kafka.binder.zkNodes=${vcap.services.kafkacups.credentials.zkNodes}"10.10. Database Connection Pool
As of Data Flow 2.0, the Spring Cloud Connector library is no longer used to create the DataSource. The library java-cfenv is now used which allows you to set Spring Boot properties to configure the connection pool.
10.11. Maximum Disk Quota
By default, every application in Cloud Foundry starts with 1G disk quota and this can be adjusted to a default maximum of 2G. The default maximum can also be overridden up to 10G by using Pivotal Cloud Foundry’s (PCF) Ops Manager GUI.
This configuration is relevant for Spring Cloud Data Flow because every task deployment is composed of applications (typically Spring Boot uber-jar’s), and those applications are resolved from a remote maven repository. After resolution, the application artifacts are downloaded to the local Maven Repository for caching and reuse. With this happening in the background, the default disk quota (1G) can fill up rapidly, especially when we experiment with streams that are made up of unique applications. In order to overcome this disk limitation and depending on your scaling requirements, you may want to change the default maximum from 2G to 10G. Let’s review the steps to change the default maximum disk quota allocation.
10.11.1. PCF’s Operations Manager
From PCF’s Ops Manager, select the “Pivotal Elastic Runtime” tile and navigate to the “Application Developer Controls” tab. Change the “Maximum Disk Quota per App (MB)” setting from 2048 (2G) to 10240 (10G). Save the disk quota update and click “Apply Changes” to complete the configuration override.
10.12. Scale Application
Once the disk quota change has been successfully applied and assuming you have a running application,
you can scale the application with a new disk_limit through the CF CLI, as the following example shows:
→ cf scale dataflow-server -k 10GB
Scaling app dataflow-server in org ORG / space SPACE as user...
OK
....
....
....
....
state since cpu memory disk details
#0 running 2016-10-31 03:07:23 PM 1.8% 497.9M of 1.1G 193.9M of 10GYou can then list the applications and see the new maximum disk space, as the following example shows:
→ cf apps
Getting apps in org ORG / space SPACE as user...
OK
name requested state instances memory disk urls
dataflow-server started 1/1 1.1G 10G dataflow-server.apps.io10.13. Managing Disk Use
Even when configuring the Data Flow server to use 10G of space, there is the possibility of exhausting
the available space on the local disk. To prevent this, jar artifacts downloaded from external sources, i.e., apps registered as http or maven resources, are automatically deleted whenever the application is deployed, whether or not the deployment request succeeds.
This behavior is optimal for production environments in which container runtime stability is more critical than I/O latency incurred during deployment.
In development environments deployment happens more frequently. Additionally, the jar artifact (or a lighter metadata jar) contains metadata describing application configuration properties
which is used by various operations related to application configuration, more frequently performed during pre-production activities (see Application Metadata for details).
To provide a more responsive interactive developer experience at the expense of more disk usage in pre-production environments, you can set the CloudFoundry deployer property autoDeleteMavenArtifacts to false.
If you deploy the Data Flow server by using the default port health check type, you must explicitly monitor the disk space on the server in order to avoid running out space.
If you deploy the server by using the http health check type (see the next example), the Data Flow server is restarted if there is low disk space.
This is due to Spring Boot’s Disk Space Health Indicator.
You can configure the settings of the Disk Space Health Indicator by using the properties that have the management.health.diskspace prefix.
For version 1.7, we are investigating the use of Volume Services for the Data Flow server to store .jar artifacts before pushing them to Cloud Foundry.
The following example shows how to deploy the http health check type to an endpoint called /management/health:
---
...
health-check-type: http
health-check-http-endpoint: /management/health10.14. Application Resolution Alternatives
Though we recommend using a Maven Artifactory for application Register a Stream Application, there might be situations where one of the following alternative approaches would make sense.
-
With the help of Spring Boot, we can serve static content in Cloud Foundry. A simple Spring Boot application can bundle all the required stream and task applications. By having it run on Cloud Foundry, the static application can then serve the über-jar’s. From the shell, you can, for example, register the application with the name
http-source.jarby using--uri=http://<Route-To-StaticApp>/http-source.jar. -
The über-jar’s can be hosted on any external server that’s reachable over HTTP. They can be resolved from raw GitHub URIs as well. From the shell, you can, for example, register the app with the name
http-source.jarby using--uri=http://<Raw_GitHub_URI>/http-source.jar. -
Static Buildpack support in Cloud Foundry is another option. A similar HTTP resolution works on this model, too.
-
Volume Services is another great option. The required über-jars can be hosted in an external file system. With the help of volume-services, you can, for example, register the application with the name
http-source.jarby using--uri=file://<Path-To-FileSystem>/http-source.jar.
10.15. Security
By default, the Data Flow server is unsecured and runs on an unencrypted HTTP connection. You can secure your REST endpoints
(as well as the Data Flow Dashboard) by enabling HTTPS and requiring clients to authenticate.
For more details about securing the
REST endpoints and configuring to authenticate against an OAUTH backend (UAA and SSO running on Cloud Foundry),
see the security section from the core Security Configuration. You can configure the security details in dataflow-server.yml or pass them as environment variables through cf set-env commands.
10.15.1. Authentication
Spring Cloud Data Flow can either integrate with Pivotal Single Sign-On Service (for example, on PWS) or Cloud Foundry User Account and Authentication (UAA) Server.
Pivotal Single Sign-On Service
When deploying Spring Cloud Data Flow to Cloud Foundry, you can bind the application to the Pivotal Single Sign-On Service. By doing so, Spring Cloud Data Flow takes advantage of the Java CFEnv, which provides Cloud Foundry-specific auto-configuration support for OAuth 2.0.
To do so, bind the Pivotal Single Sign-On Service to your Data Flow Server application and provide the following properties:
SPRING_CLOUD_DATAFLOW_SECURITY_CFUSEUAA: false (1)
SECURITY_OAUTH2_CLIENT_CLIENTID: "${security.oauth2.client.clientId}"
SECURITY_OAUTH2_CLIENT_CLIENTSECRET: "${security.oauth2.client.clientSecret}"
SECURITY_OAUTH2_CLIENT_ACCESSTOKENURI: "${security.oauth2.client.accessTokenUri}"
SECURITY_OAUTH2_CLIENT_USERAUTHORIZATIONURI: "${security.oauth2.client.userAuthorizationUri}"
SECURITY_OAUTH2_RESOURCE_USERINFOURI: "${security.oauth2.resource.userInfoUri}"| 1 | It is important that the property spring.cloud.dataflow.security.cf-use-uaa is set to false |
Authorization is similarly supported for non-Cloud Foundry security scenarios. See the security section from the core Data Flow Security Configuration.
As the provisioning of roles can vary widely across environments, we by default assign all Spring Cloud Data Flow roles to users.
You can customize this behavior by providing your own AuthoritiesExtractor.
The following example shows one possible approach to set the custom AuthoritiesExtractor on the UserInfoTokenServices:
public class MyUserInfoTokenServicesPostProcessor
implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) {
if (bean instanceof UserInfoTokenServices) {
final UserInfoTokenServices userInfoTokenServices == (UserInfoTokenServices) bean;
userInfoTokenServices.setAuthoritiesExtractor(ctx.getBean(AuthoritiesExtractor.class));
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
return bean;
}
}
Then you can declare it in your configuration class as follows:
@Bean
public BeanPostProcessor myUserInfoTokenServicesPostProcessor() {
BeanPostProcessor postProcessor == new MyUserInfoTokenServicesPostProcessor();
return postProcessor;
}
Cloud Foundry UAA
The availability of Cloud Foundry User Account and Authentication (UAA) depends on the Cloud Foundry environment.
In order to provide UAA integration, you have to provide the necessary
OAuth2 configuration properties (for example, by setting the SPRING_APPLICATION_JSON
property).
The following JSON example shows how to create a security configuration:
{
"security.oauth2.client.client-id": "scdf",
"security.oauth2.client.client-secret": "scdf-secret",
"security.oauth2.client.access-token-uri": "https://login.cf.myhost.com/oauth/token",
"security.oauth2.client.user-authorization-uri": "https://login.cf.myhost.com/oauth/authorize",
"security.oauth2.resource.user-info-uri": "https://login.cf.myhost.com/userinfo"
}By default, the spring.cloud.dataflow.security.cf-use-uaa property is set to true. This property activates a special
AuthoritiesExtractor called CloudFoundryDataflowAuthoritiesExtractor.
If you do not use CloudFoundry UAA, you should set spring.cloud.dataflow.security.cf-use-uaa to false.
Under the covers, this AuthoritiesExtractor calls out to the
Cloud Foundry
Apps API and ensure that users are in fact Space Developers.
If the authenticated user is verified as a Space Developer, all roles are assigned.
10.16. Configuration Reference
You must provide several pieces of configuration. These are Spring Boot @ConfigurationProperties, so you can set
them as environment variables or by any other means that Spring Boot supports. The following listing is in environment
variable format, as that is an easy way to get started configuring Boot applications in Cloud Foundry.
Note that in the future, you will be able to deploy tasks to multiple platforms, but for 2.0.0.M1 you can deploy only to a single platform and the name must be default.
# Default values appear after the equal signs.
# Example values, typical for Pivotal Web Services, are included as comments.
# URL of the CF API (used when using cf login -a for example) - for example, https://api.run.pivotal.io
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL=
# The name of the organization that owns the space above - for example, youruser-org
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG=
# The name of the space into which modules will be deployed - for example, development
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE=
# The root domain to use when mapping routes - for example, cfapps.io
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_DOMAIN=
# The user name and password of the user to use to create applications
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME=
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD
# The identity provider to be used when accessing the Cloud Foundry API (optional).
# The passed string has to be a URL-Encoded JSON Object, containing the field origin with value as origin_key of an identity provider - for example, {"origin":"uaa"}
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_LOGIN_HINT=
# Whether to allow self-signed certificates during SSL validation (you should NOT do so in production)
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SKIP_SSL_VALIDATION
# A comma-separated set of service instance names to bind to every deployed task application.
# Among other things, this should include an RDBMS service that is used
# for Spring Cloud Task execution reporting, such as my_postgres
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES
spring.cloud.deployer.cloudfoundry.task.services=
# Timeout, in seconds, to use when doing blocking API calls to Cloud Foundry
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_API_TIMEOUT=
# Timeout, in milliseconds, to use when querying the Cloud Foundry API to compute app status
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_STATUS_TIMEOUTNote that you can set spring.cloud.deployer.cloudfoundry.services,
spring.cloud.deployer.cloudfoundry.buildpacks, or the Spring Cloud Deployer-standard
spring.cloud.deployer.memory and spring.cloud.deployer.disk
as part of an individual deployment request by using the deployer.<app-name> shortcut, as the following example shows:
stream create --name ticktock --definition "time | log"
stream deploy --name ticktock --properties "deployer.time.memory=2g"The commands in the preceding example deploy the time source with 2048MB of memory, while the log sink uses the default 1024MB.
When you deploy a stream, you can also pass JAVA_OPTS as a deployment property, as the following example shows:
stream deploy --name ticktock --properties "deployer.time.cloudfoundry.javaOpts=-Duser.timezone=America/New_York"10.17. Debugging
If you want to get better insights into what is happening when your streams and tasks are being deployed, you may want to turn on the following features:
-
Reactor “stacktraces”, showing which operators were involved before an error occurred. This feature is helpful, as the deployer relies on project reactor and regular stacktraces may not always allow understanding the flow before an error happened. Note that this comes with a performance penalty, so it is disabled by default.
spring.cloud.dataflow.server.cloudfoundry.debugReactor == true-
Deployer and Cloud Foundry client library request and response logs. This feature allows seeing a detailed conversation between the Data Flow server and the Cloud Foundry Cloud Controller.
logging.level.cloudfoundry-client == DEBUG10.18. Spring Cloud Config Server
You can use Spring Cloud Config Server to centralize configuration properties for Spring Boot applications. Likewise, both Spring Cloud Data Flow and the applications orchestrated by Spring Cloud Data Flow can be integrated with a configuration server to use the same capabilities.
10.18.1. Stream, Task, and Spring Cloud Config Server
Similar to Spring Cloud Data Flow server, you can configure both the stream and task applications to resolve the centralized properties from the configuration server.
Setting the spring.cloud.config.uri property for the deployed applications is a common way to bind to the configuration server.
See the Spring Cloud Config Client reference guide for more information.
Since this property is likely to be used across all deployed applications, the Data Flow server’s spring.cloud.dataflow.applicationProperties.stream property for stream applications and spring.cloud.dataflow.applicationProperties.task property for task applications can be used to pass the uri of the Config Server to each deployed stream or task application. See the section on Common Application Properties for more information.
Note that, if you use the out-of-the-box Stream Applications, these applications already embed the spring-cloud-services-starter-config-client dependency.
If you build your application from scratch and want to add the client side support for config server, you can add a dependency reference to the config server client library. The following snippet shows a Maven example:
...
<dependency>
<groupId>io.pivotal.spring.cloud</groupId>
<artifactId>spring-cloud-services-starter-config-client</artifactId>
<version>CONFIG_CLIENT_VERSION</version>
</dependency>
...where CONFIG_CLIENT_VERSION can be the latest release of the Spring Cloud Config Server
client for Pivotal Cloud Foundry.
You may see a WARN logging message if the application that uses this library cannot connect to the configuration
server when the application starts and whenever the /health endpoint is accessed.
If you know that you are not using config server functionality, you can disable the client library by setting the
SPRING_CLOUD_CONFIG_ENABLED environment variable to false.
|
10.18.2. Sample Manifest Template
The following SCDF and Skipper manifest.yml templates includes the required environment variables for the Skipper and Spring Cloud Data Flow server and deployed applications and tasks to successfully run on Cloud Foundry and automatically resolve centralized properties from my-config-server at runtime:
applications:
- name: data-flow-server
host: data-flow-server
memory: 2G
disk_quota: 2G
instances: 1
path: {PATH TO SERVER UBER-JAR}
env:
SPRING_APPLICATION_NAME: data-flow-server
MAVEN_REMOTEREPOSITORIES_REPO1_URL: https://my.custom.repo/prod-repo
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL: https://api.sys.huron.cf-app.com
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG: sabby20
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE: sabby20
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_DOMAIN: apps.huron.cf-app.com
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME: admin
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD: ***
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SKIP_SSL_VALIDATION: true
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: postgres
SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI: https://<skipper-host-name>/api
services:
- postgres
- my-config-serverapplications:
- name: skipper-server
host: skipper-server
memory: 1G
disk_quota: 1G
instances: 1
timeout: 180
buildpack: java_buildpack
path: <PATH TO THE DOWNLOADED SKIPPER SERVER UBER-JAR>
env:
SPRING_APPLICATION_NAME: skipper-server
SPRING_CLOUD_SKIPPER_SERVER_ENABLE_LOCAL_PLATFORM: false
SPRING_CLOUD_SKIPPER_SERVER_STRATEGIES_HEALTHCHECK_TIMEOUTINMILLIS: 300000
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL: https://api.local.pcfdev.io
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG: pcfdev-org
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE: pcfdev-space
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_DOMAIN: cfapps.io
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME: admin
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD: admin
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SKIP_SSL_VALIDATION: false
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_DELETE_ROUTES: false
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: rabbit,my-config-server
services:
- postgres
my-config-serverwhere my-config-server is the name of the Spring Cloud Config Service instance running on Cloud Foundry.
By binding the service to Spring Cloud Data Flow server, Spring Cloud Task and via Skipper to all the Spring Cloud Stream applications respectively, we can now resolve centralized properties backed by this service.
10.18.3. Self-signed SSL Certificate and Spring Cloud Config Server
Often, in a development environment, we may not have a valid certificate to enable SSL communication between clients and the backend services. However, the configuration server for Pivotal Cloud Foundry uses HTTPS for all client-to-service communication, so we need to add a self-signed SSL certificate in environments with no valid certificates.
By using the same manifest.yml templates listed in the previous section for the server, we can provide the self-signed SSL certificate by setting TRUST_CERTS: <API_ENDPOINT>.
However, the deployed applications also require TRUST_CERTS as a flat environment variable (as opposed to being wrapped inside SPRING_APPLICATION_JSON), so we must instruct the server with yet another set of tokens (SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_USE_SPRING_APPLICATION_JSON: false) for tasks.
With this setup, the applications receive their application properties as regular environment variables.
The following listing shows the updated manifest.yml with the required changes. Both the Data Flow server and deployed applications
get their configuration from the my-config-server Cloud Config server (deployed as a Cloud Foundry service).
applications:
- name: test-server
host: test-server
memory: 1G
disk_quota: 1G
instances: 1
path: spring-cloud-dataflow-server-VERSION.jar
env:
SPRING_APPLICATION_NAME: test-server
MAVEN_REMOTEREPOSITORIES_REPO1_URL: https://my.custom.repo/prod-repo
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL: https://api.sys.huron.cf-app.com
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG: sabby20
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE: sabby20
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_DOMAIN: apps.huron.cf-app.com
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME: admin
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD: ***
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SKIP_SSL_VALIDATION: true
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: postgres, config-server
SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI: https://<skipper-host-name>/api
TRUST_CERTS: <API_ENDPOINT> #this is for the server
SPRING_CLOUD_DATAFLOW_APPLICATION_PROPERTIES_TASK_TRUST_CERTS: <API_ENDPOINT> #this propagates to all tasks
services:
- postgres
- my-config-server #this is for the serverAlso add the my-config-server service to the Skipper’s manifest environment
applications:
- name: skipper-server
host: skipper-server
memory: 1G
disk_quota: 1G
instances: 1
timeout: 180
buildpack: java_buildpack
path: <PATH TO THE DOWNLOADED SKIPPER SERVER UBER-JAR>
env:
SPRING_APPLICATION_NAME: skipper-server
SPRING_CLOUD_SKIPPER_SERVER_ENABLE_LOCAL_PLATFORM: false
SPRING_CLOUD_SKIPPER_SERVER_STRATEGIES_HEALTHCHECK_TIMEOUTINMILLIS: 300000
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL: <URL>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG: <ORG>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE: <SPACE>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_DOMAIN: <DOMAIN>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME: <USER>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD: <PASSWORD>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: rabbit, my-config-server #this is so all stream applications bind to my-config-server
services:
- postgres
my-config-server10.19. Configure Scheduling
This section discusses how to configure Spring Cloud Data Flow to connect to the PCF-Scheduler as its agent to execute tasks.
|
Before following these instructions, be sure to have an instance of the PCF-Scheduler service running in your Cloud Foundry space.
To create a PCF-Scheduler in your space (assuming it is in your Market Place) execute the following from the CF CLI: |
For scheduling, you must add (or update) the following environment variables in your environment:
-
Enable scheduling for Spring Cloud Data Flow by setting
spring.cloud.dataflow.features.schedules-enabledtotrue. -
Bind the task deployer to your instance of PCF-Scheduler by adding the PCF-Scheduler service name to the
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICESenvironment variable. -
Establish the URL to the PCF-Scheduler by setting the
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_SCHEDULER_SCHEDULER_URLenvironment variable.
|
After creating the preceding configurations, you must create any task definitions that need to be scheduled. |
The following sample manifest shows both environment properties configured (assuming you have a PCF-Scheduler service available with the name myscheduler):
applications:
- name: data-flow-server
host: data-flow-server
memory: 2G
disk_quota: 2G
instances: 1
path: {PATH TO SERVER UBER-JAR}
env:
SPRING_APPLICATION_NAME: data-flow-server
SPRING_CLOUD_SKIPPER_SERVER_ENABLE_LOCAL_PLATFORM: false
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_URL: <URL>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_ORG: <ORG>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_SPACE: <SPACE>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_DOMAIN: <DOMAIN>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_USERNAME: <USER>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_CONNECTION_PASSWORD: <PASSWORD>
SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_DEPLOYMENT_SERVICES: rabbit, myscheduler
SPRING_CLOUD_DATAFLOW_FEATURES_SCHEDULES_ENABLED: true
SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI: https://<skipper-host-name>/api
SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]_SCHEDULER_SCHEDULER_URL: https://scheduler.local.pcfdev.io
services:
- postgresWhere the SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[default]SCHEDULER_SCHEDULER_URL has the following format: scheduler.<Domain-Name> (for
example, scheduler.local.pcfdev.io). Check the actual address from your _PCF environment.
| Detailed examples for launching and scheduling tasks across multiple platforms, are available in this section Multiple Platform Support for Tasks on dataflow.spring.io. |
11. Configuration - Kubernetes
This section describes how to configure Spring Cloud Data Flow features, such as deployer properties, tasks, and which relational database to use.
11.1. Feature Toggles
Data Flow server offers specific set of features that can be enabled or disabled when launching. These features include all the lifecycle operations, REST endpoints (server and client implementations including Shell and the UI) for:
-
Streams
-
Tasks
-
Schedules
You can enable or disable these features by setting the following boolean environment variables when launching the Data Flow server:
-
SPRING_CLOUD_DATAFLOW_FEATURES_STREAMS_ENABLED -
SPRING_CLOUD_DATAFLOW_FEATURES_TASKS_ENABLED -
SPRING_CLOUD_DATAFLOW_FEATURES_SCHEDULES_ENABLED
By default, all the features are enabled.
The /features REST endpoint provides information on the features that have been enabled and disabled.
11.2. Application and Server Properties
This section covers how you can customize the deployment of your applications. You can use a number of properties to influence settings for the applications that are deployed. Properties can be applied on a per-application basis or in the appropriate server configuration for all deployed applications.
| Properties set on a per-application basis always take precedence over properties set as the server configuration. This arrangement lets you override global server level properties on a per-application basis. |
Properties to be applied for all deployed Tasks are defined in the src/kubernetes/server/server-config-[binder].yaml file and for Streams in src/kubernetes/skipper/skipper-config-[binder].yaml. Replace [binder] with the messaging middleware you are using — for example, rabbit or kafka.
11.2.1. Memory and CPU Settings
Applications are deployed with default memory and CPU settings. If you need to, you can adjust these values. The following example shows how to set Limits to 1000m for CPU and 1024Mi for memory and Requests to 800m for CPU and 640Mi for memory:
deployer.<application>.kubernetes.limits.cpu=1000m
deployer.<application>.kubernetes.limits.memory=1024Mi
deployer.<application>.kubernetes.requests.cpu=800m
deployer.<application>.kubernetes.requests.memory=640MiThose values results in the following container settings being used:
Limits:
cpu: 1
memory: 1Gi
Requests:
cpu: 800m
memory: 640MiYou can also control the default values to which to set the cpu and memory globally.
The following example shows how to set the CPU and memory for streams:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
limits:
memory: 640mi
cpu: 500mThe following example shows how to set the CPU and memory for tasks:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
limits:
memory: 640mi
cpu: 500mThe settings we have used so far affect only the settings for the container. They do not affect the memory setting for the JVM process in the container. If you would like to set JVM memory settings, you can set an environment variable to do so. See the next section for details.
11.2.2. Environment Variables
To influence the environment settings for a given application, you can use the spring.cloud.deployer.kubernetes.environmentVariables deployer property.
For example, a common requirement in production settings is to influence the JVM memory arguments.
You can do so by using the JAVA_TOOL_OPTIONS environment variable, as the following example shows:
deployer.<application>.kubernetes.environmentVariables=JAVA_TOOL_OPTIONS=-Xmx1024m
The environmentVariables property accepts a comma-delimited string. If an environment variable contains a value
that is also a comma-delimited string, it must be enclosed in single quotation marks — for example,
spring.cloud.deployer.kubernetes.environmentVariables=spring.cloud.stream.kafka.binder.brokers='somehost:9092,
anotherhost:9093'
|
This overrides the JVM memory setting for the desired <application> (replace <application> with the name of your application).
11.2.3. Liveness, Readiness and Startup Probes
The liveness and readiness probes use paths called /health/liveness and /health/readiness, respectively. They use a delay of 1 for both and a period of 60 and 10 respectively. You can change these defaults when you deploy the stream by using deployer properties. The liveness and readiness probes are applied only to streams.
The startup probe will use the /health path and a delay of 30 and period for 3 with a failure threshold of 20 times before the container restarts the application.
The following example changes the liveness and startup probes (replace <application> with the name of your application) by setting deployer properties:
deployer.<application>.kubernetes.livenessProbePath=/health/livesness
deployer.<application>.kubernetes.livenessProbeDelay=1
deployer.<application>.kubernetes.livenessProbePeriod=60
deployer.<application>.kubernetes.livenessProbeSuccess=1
deployer.<application>.kubernetes.livenessProbeFailure=3
deployer.<application>.kubernetes.readinessProbePath=/health/readiness
deployer.<application>.kubernetes.readinessProbeDelay=1
deployer.<application>.kubernetes.readinessProbePeriod=60
deployer.<application>.kubernetes.readinessProbeSuccess=1
deployer.<application>.kubernetes.readinessProbeFailure=3
deployer.<application>.kubernetes.startupHttpProbePath=/health
deployer.<application>.kubernetes.startupProbeDelay=20
deployer.<application>.kubernetes.startupProbeSuccess=1
deployer.<application>.kubernetes.startupProbeFailure=30
deployer.<application>.kubernetes.startupProbePeriod=5
deployer.<application>.kubernetes.startupProbeTimeout=3You can declare the same as part of the server global configuration for streams, as the following example shows:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
livenessHttpProbePath: /health/liveness
livenessProbeDelay: 1
livenessProbePeriod: 60
livenessProbeSuccess: 1
livenessProbeFailure: 3
startupHttpProbePath: /health
startupProbeDelay: 20
startupProbeSuccess: 1
startupProbeFailure: 30
startupProbePeriod: 5
startupProbeTimeout: 3Similarly, you can swap liveness for readiness to override the default readiness settings.
By default, port 8080 is used as the probe port. You can change the defaults for both liveness and readiness probe ports by using deployer properties, as the following example shows:
deployer.<application>.kubernetes.readinessProbePort=7000
deployer.<application>.kubernetes.livenessProbePort=7000
deployer.<application>.kubernetes.startupProbePort=7000You can declare the same as part of the global configuration for streams, as the following example shows:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
readinessProbePort: 7000
livenessProbePort: 7000
startupProbePort: 7000|
By default, the The To automatically set both |
You can access secured probe endpoints by using credentials stored in a Kubernetes secret. You can use an existing secret, provided the credentials are contained under the credentials key name of the secret’s data block. You can configure probe authentication on a per-application basis. When enabled, it is applied to both the liveness and readiness probe endpoints by using the same credentials and authentication type. Currently, only Basic authentication is supported.
To create a new secret:
-
Generate the base64 string with the credentials used to access the secured probe endpoints.
Basic authentication encodes a username and a password as a base64 string in the format of
username:password.The following example (which includes output and in which you should replace
userandpasswith your values) shows how to generate a base64 string:$ echo -n "user:pass" | base64 dXNlcjpwYXNz -
With the encoded credentials, create a file (for example,
myprobesecret.yml) with the following contents:apiVersion: v1 kind: Secret metadata: name: myprobesecret type: Opaque data: credentials: GENERATED_BASE64_STRING -
Replace
GENERATED_BASE64_STRINGwith the base64-encoded value generated earlier. -
Create the secret by using
kubectl, as the following example shows:$ kubectl create -f ./myprobesecret.yml secret "myprobesecret" created -
Set the following deployer properties to use authentication when accessing probe endpoints, as the following example shows:
deployer.<application>.kubernetes.probeCredentialsSecret=myprobesecretReplace
<application>with the name of the application to which to apply authentication.
11.2.4. Using SPRING_APPLICATION_JSON
You can use a SPRING_APPLICATION_JSON environment variable to set Data Flow server properties (including the configuration of Maven repository settings) that are common across all of the Data Flow server implementations. These settings go at the server level in the container env section of a deployment YAML. The following example shows how to do so:
env:
- name: SPRING_APPLICATION_JSON
value: "{ \"maven\": { \"local-repository\": null, \"remote-repositories\": { \"repo1\": { \"url\": \"https://my.custom.repo/prod-repo\"} } } }"11.2.5. Private Docker Registry
You can pull Docker images from a private registry on a per-application basis. First, you must create a secret in the cluster. Follow the Pull an Image from a Private Registry guide to create the secret.
Once you have created the secret, you can use the imagePullSecret property to set the secret to use, as the following example shows:
deployer.<application>.kubernetes.imagePullSecret=mysecretReplace <application> with the name of your application and mysecret with the name of the secret you created earlier.
You can also configure the image pull secret at the global server level.
The following example shows how to do so for streams:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
imagePullSecret: mysecretThe following example shows how to do so for tasks:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
imagePullSecret: mysecretReplace mysecret with the name of the secret you created earlier.
11.2.6. Annotations
You can add annotations to Kubernetes objects on a per-application basis. The supported object types are pod Deployment, Service, and Job. Annotations are defined in a key:value format, allowing for multiple annotations separated by a comma. For more information and use cases on annotations, see Annotations.
The following example shows how you can configure applications to use annotations:
deployer.<application>.kubernetes.podAnnotations=annotationName:annotationValue
deployer.<application>.kubernetes.serviceAnnotations=annotationName:annotationValue,annotationName2:annotationValue2
deployer.<application>.kubernetes.jobAnnotations=annotationName:annotationValueReplace <application> with the name of your application and the value of your annotations.
11.2.7. Entry Point Style
An entry point style affects how application properties are passed to the container to be deployed. Currently, three styles are supported:
-
exec(default): Passes all application properties and command line arguments in the deployment request as container arguments. Application properties are transformed into the format of--key=value. -
shell: Passes all application properties and command line arguments as environment variables. Each of the applicationor command-line argument properties is transformed into an uppercase string and.characters are replaced with_. -
boot: Creates an environment variable calledSPRING_APPLICATION_JSONthat contains a JSON representation of all application properties. Command line arguments from the deployment request are set as container args.
| In all cases, environment variables defined at the server-level configuration and on a per-application basis are sent on to the container as is. |
You can configure an application as follows:
deployer.<application>.kubernetes.entryPointStyle=<Entry Point Style>Replace <application> with the name of your application and <Entry Point Style> with your desired entry point style.
You can also configure the entry point style at the global server level.
The following example shows how to do so for streams:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
entryPointStyle: entryPointStyleThe following example shows how to do so for tasks:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
entryPointStyle: entryPointStyleReplace entryPointStyle with the desired entry point style.
You should choose an Entry Point Style of either exec or shell, to correspond to how the ENTRYPOINT syntax is defined in the container’s Dockerfile. For more information and uses cases on exec versus shell, see the ENTRYPOINT section of the Docker documentation.
Using the boot entry point style corresponds to using the exec style ENTRYPOINT. Command line arguments from the deployment request are passed to the container, with the addition of application properties being mapped into the SPRING_APPLICATION_JSON environment variable rather than command line arguments.
When you use the boot Entry Point Style, the deployer.<application>.kubernetes.environmentVariables property must not contain SPRING_APPLICATION_JSON.
|
11.2.8. Deployment Service Account
You can configure a custom service account for application deployments through properties. You can use an existing service account or create a new one. One way to create a service account is by using kubectl, as the following example shows:
$ kubectl create serviceaccount myserviceaccountname
serviceaccount "myserviceaccountname" createdThen you can configure individual applications as follows:
deployer.<application>.kubernetes.deploymentServiceAccountName=myserviceaccountnameReplace <application> with the name of your application and myserviceaccountname with your service account name.
You can also configure the service account name at the global server level.
The following example shows how to do so for streams:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
deploymentServiceAccountName: myserviceaccountnameThe following example shows how to do so for tasks:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
deploymentServiceAccountName: myserviceaccountnameReplace myserviceaccountname with the service account name to be applied to all deployments.
11.2.9. Image Pull Policy
An image pull policy defines when a Docker image should be pulled to the local registry. Currently, three policies are supported:
-
IfNotPresent(default): Do not pull an image if it already exists. -
Always: Always pull the image regardless of whether it already exists. -
Never: Never pull an image. Use only an image that already exists.
The following example shows how you can individually configure applications:
deployer.<application>.kubernetes.imagePullPolicy=IfNotPresentReplace <application> with the name of your application and Always with your desired image pull policy.
You can configure an image pull policy at the global server level.
The following example shows how to do so for streams:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
imagePullPolicy: IfNotPresentThe following example shows how to do so for tasks:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
imagePullPolicy: AlwaysReplace Always with your desired image pull policy.
11.2.10. Deployment Labels
You can set custom labels on objects related to Deployment. See Labels for more information on labels. Labels are specified in key:value format.
The following example shows how you can individually configure applications:
deployer.<application>.kubernetes.deploymentLabels=myLabelName:myLabelValueReplace <application> with the name of your application, myLabelName with your label name, and myLabelValue with the value of your label.
Additionally, you can apply multiple labels, as the following example shows:
deployer.<application>.kubernetes.deploymentLabels=myLabelName:myLabelValue,myLabelName2:myLabelValue211.2.11. Tolerations
Tolerations work with taints to ensure pods are not scheduled onto particular nodes. Tolerations are set into the pod configuration while taints are set onto nodes. See the Taints and Tolerations section of the Kubernetes reference for more information.
The following example shows how you can individually configure applications:
deployer.<application>.kubernetes.tolerations=[{key: 'mykey', operator: 'Equal', value: 'myvalue', effect: 'NoSchedule'}]Replace <application> with the name of your application and the key-value pairs according to your desired toleration configuration.
You can configure tolerations at the global server level as well.
The following example shows how to do so for streams:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
tolerations:
- key: mykey
operator: Equal
value: myvalue
effect: NoScheduleThe following example shows how to do so for tasks:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
tolerations:
- key: mykey
operator: Equal
value: myvalue
effect: NoScheduleReplace the tolerations key-value pairs according to your desired toleration configuration.
11.2.12. Secret References
Secrets can be referenced and their entire data contents can be decoded and inserted into the pod environment as individual variables. See the Configure all key-value pairs in a Secret as container environment variables section of the Kubernetes reference for more information.
The following example shows how you can individually configure applications:
deployer.<application>.kubernetes.secretRefs=testsecretYou can also specify multiple secrets, as follows:
deployer.<application>.kubernetes.secretRefs=[testsecret,anothersecret]Replace <application> with the name of your application and the secretRefs attribute with the appropriate values for your application environment and secret.
You can configure secret references at the global server level as well.
The following example shows how to do so for streams:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
secretRefs:
- testsecret
- anothersecretThe following example shows how to do so for tasks:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
secretRefs:
- testsecret
- anothersecretReplace the items of secretRefs with one or more secret names.
11.2.13. Secret Key References
Secrets can be referenced and their decoded value can be inserted into the pod environment. See the Using Secrets as Environment Variables section of the Kubernetes reference for more information.
The following example shows how you can individually configure applications:
deployer.<application>.kubernetes.secretKeyRefs=[{envVarName: 'MY_SECRET', secretName: 'testsecret', dataKey: 'password'}]Replace <application> with the name of your application and the envVarName, secretName, and dataKey attributes with the appropriate values for your application environment and secret.
You can configure secret key references at the global server level as well.
The following example shows how to do so for streams:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
secretKeyRefs:
- envVarName: MY_SECRET
secretName: testsecret
dataKey: passwordThe following example shows how to do so for tasks:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
secretKeyRefs:
- envVarName: MY_SECRET
secretName: testsecret
dataKey: passwordReplace the envVarName, secretName, and dataKey attributes with the appropriate values for your secret.
11.2.14. ConfigMap References
A ConfigMap can be referenced and its entire data contents can be decoded and inserted into the pod environment as individual variables. See the Configure all key-value pairs in a ConfigMap as container environment variables section of the Kubernetes reference for more information.
The following example shows how you can individually configure applications:
deployer.<application>.kubernetes.configMapRefs=testcmYou can also specify multiple ConfigMap instances, as follows:
deployer.<application>.kubernetes.configMapRefs=[testcm,anothercm]Replace <application> with the name of your application and the configMapRefs attribute with the appropriate values for your application environment and ConfigMap.
You can configure ConfigMap references at the global server level as well.
The following example shows how to do so for streams. Edit the appropriate skipper-config-(binder).yaml, replacing (binder) with the corresponding binder in use:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
configMapRefs:
- testcm
- anothercmThe following example shows how to do so for tasks by editing the server-config.yaml file:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
configMapRefs:
- testcm
- anothercmReplace the items of configMapRefs with one or more secret names.
11.2.15. ConfigMap Key References
A ConfigMap can be referenced and its associated key value inserted into the pod environment. See the Define container environment variables using ConfigMap data section of the Kubernetes reference for more information.
The following example shows how you can individually configure applications:
deployer.<application>.kubernetes.configMapKeyRefs=[{envVarName: 'MY_CM', configMapName: 'testcm', dataKey: 'platform'}]Replace <application> with the name of your application and the envVarName, configMapName, and dataKey attributes with the appropriate values for your application environment and ConfigMap.
You can configure ConfigMap references at the global server level as well.
The following example shows how to do so for streams. Edit the appropriate skipper-config-(binder).yaml, replacing (binder) with the corresponding binder in use:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
configMapKeyRefs:
- envVarName: MY_CM
configMapName: testcm
dataKey: platformThe following example shows how to do so for tasks by editing the server-config.yaml file:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
configMapKeyRefs:
- envVarName: MY_CM
configMapName: testcm
dataKey: platformReplace the envVarName, configMapName, and dataKey attributes with the appropriate values for your ConfigMap.
11.2.16. Pod Security Context
The pod security context specifies security settings for a pod and its containers.
The configurable options are listed HERE (more details for each option can be found in the Pod Security Context section of the Kubernetes API reference).
The following example shows how you can configure the security context for an individual application pod:
deployer.<application>.kubernetes.podSecurityContext={runAsUser: 65534, fsGroup: 65534, supplementalGroups: [65534, 65535], seccompProfile: { type: 'RuntimeDefault' }}Replace <application> with the name of your application and any attributes with the appropriate values for your container environment.
You can configure the pod security context at the global server level as well.
The following example shows how to do so for streams. Edit the appropriate skipper-config-(binder).yaml, replacing (binder) with the corresponding binder in use:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
podSecurityContext:
runAsUser: 65534
fsGroup: 65534
supplementalGroups: [65534,65535]
seccompProfile:
type: Localhost
localhostProfile: my-profiles/profile-allow.jsonThe following example shows how to do so for tasks by editing the server-config.yaml file:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
podSecurityContext:
runAsUser: 65534
fsGroup: 65534
supplementalGroups: [65534,65535]
seccompProfile:
type: Localhost
localhostProfile: my-profiles/profile-allow.jsonAdjust the podSecurityContext attributes with the appropriate values for your container environment.
11.2.17. Container Security Context
The container security context specifies security settings for an individual container.
The configurable options are listed HERE (more details for each option can be found in the Container Security Context section of the Kubernetes API reference).
| The container security context is applied to all containers in your deployment unless they have their own security already explicitly defined, including regular init containers, stateful set init containers, and additional containers. |
The following example shows how you can configure the security context for containers in an individual application pod:
deployer.<application>.kubernetes.containerSecurityContext={allowPrivilegeEscalation: true, runAsUser: 65534}Replace <application> with the name of your application and any attributes with the appropriate values for your container environment.
You can configure the container security context at the global server level as well.
The following example shows how to do so for streams. Edit the appropriate skipper-config-(binder).yaml, replacing (binder) with the corresponding binder in use:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
containerSecurityContext:
allowPrivilegeEscalation: true
runAsUser: 65534The following example shows how to do so for tasks by editing the server-config.yaml file:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
containerSecurityContext:
allowPrivilegeEscalation: true
runAsUser: 65534Adjust the containerSecurityContext attributes with the appropriate values for your container environment.
11.2.18. Service Ports
When you deploy applications, a kubernetes Service object is created with a default port of 8080. If the server.port property is set, it overrides the default port value. You can add additional ports to the Service object on a per-application basis. You can add multiple ports with a comma delimiter.
The following example shows how you can configure additional ports on a Service object for an application:
deployer.<application>.kubernetes.servicePorts=5000
deployer.<application>.kubernetes.servicePorts=5000,9000Replace <application> with the name of your application and the value of your ports.
11.2.19. StatefulSet Init Container
When deploying an application by using a StatefulSet, an Init Container is used to set the instance index in the pod.
By default, the image used is busybox, which you can be customize.
The following example shows how you can individually configure application pods:
deployer.<application>.kubernetes.statefulSetInitContainerImageName=myimage:mylabelReplace <application> with the name of your application and the statefulSetInitContainerImageName attribute with the appropriate value for your environment.
You can configure the StatefulSet Init Container at the global server level as well.
The following example shows how to do so for streams. Edit the appropriate skipper-config-(binder).yaml, replacing (binder) with the corresponding binder in use:
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
statefulSetInitContainerImageName: myimage:mylabelThe following example shows how to do so for tasks by editing the server-config.yaml file:
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
statefulSetInitContainerImageName: myimage:mylabelReplace the statefulSetInitContainerImageName attribute with the appropriate value for your environment.
11.2.20. Init Containers
When you deploy applications, you can set a custom Init Container on a per-application basis. Refer to the Init Containers section of the Kubernetes reference for more information.
The following example shows how you can configure an Init Container or multiple Init Containers for an application:
deployer.<application>.kubernetes.initContainer={containerName: 'test', imageName: 'busybox:latest', commands: ['sh', '-c', 'echo hello']}
# alternative for multiple init containers
deployer.<application>.kubernetes.initContainers=[{containerName:'test', imageName: 'busybox:latest', commands: ['sh', '-c', 'echo hello']}, {containerName:'test2', imageName:'busybox:latest', commands:['sh', '-c', 'echo world']}]
# multiple containers can be created inidividually
deployer.<application>.kubernetes.initContainers[0]={containerName:'test', imageName:'busybox:latest', commands:['sh', '-c', 'echo hello']}
deployer.<application>.kubernetes.initContainers[1]={containerName:'test2', imageName:'busybox:latest', commands:['sh', '-c', 'echo world']}Replace <application> with the name of your application and set the values of the initContainer attributes appropriate for your Init Container.
11.2.21. Lifecycle Support
When you deploy applications, you may attach postStart and preStop Lifecycle handlers to execute commands.
The Kubernetes API supports other types of handlers besides exec. This feature may be extended to support additional actions in a future release.
To configure the Lifecycle handlers as shown in the linked page above,specify each command as a comma-delimited list, using the following property keys:
deployer.<application>.kubernetes.lifecycle.postStart.exec.command=/bin/sh,-c,'echo Hello from the postStart handler > /usr/share/message'
deployer.<application>.kubernetes.lifecycle.preStop.exec.command=/bin/sh,-c,'nginx -s quit; while killall -0 nginx; do sleep 1; done'11.2.22. Additional Containers
When you deploy applications, you may need one or more containers to be deployed along with the main container. This would allow you to adapt some deployment patterns such as sidecar, adapter in case of multi container pod setup.
The following example shows how you can configure additional containers for an application:
deployer.<application>.kubernetes.additionalContainers=[{name: 'c1', image: 'busybox:1', command: ['sh', '-c', 'echo hello1'], volumeMounts: [{name: 'test-volume', mountPath: '/tmp', readOnly: true}]},{name: 'c2', image: 'busybox:1.26.1', command: ['sh', '-c', 'echo hello2']}]11.3. Deployer Properties
You can use the following configuration properties the Kubernetes deployer to customize how Streams and Tasks are deployed.
When deploying with the Data Flow shell, you can use the syntax deployer.<appName>.kubernetes.<deployerPropertyName>.
These properties are also used when configuring the Kubernetes task platforms in the Data Flow server and Kubernetes platforms in Skipper for deploying Streams.
| Deployer Property Name | Description | Default Value |
|---|---|---|
namespace |
Namespace to use |
environment variable |
deployment.nodeSelector |
The node selectors to apply to the deployment in |
<none> |
imagePullSecret |
Secrets for a access a private registry to pull images. |
<none> |
imagePullPolicy |
The Image Pull Policy to apply when pulling images. Valid options are |
IfNotPresent |
livenessProbeDelay |
Delay in seconds when the Kubernetes liveness check of the app container should start checking its health status. |
10 |
livenessProbePeriod |
Period in seconds for performing the Kubernetes liveness check of the app container. |
60 |
livenessProbeTimeout |
Timeout in seconds for the Kubernetes liveness check of the app container. If the health check takes longer than this value to return it is assumed as 'unavailable'. |
2 |
livenessProbePath |
Path that app container has to respond to for liveness check. |
<none> |
livenessProbePort |
Port that app container has to respond on for liveness check. |
<none> |
startupProbeDelay |
Delay in seconds when the Kubernetes startup check of the app container should start checking its health status. |
30 |
startupProbePeriod |
Period in seconds for performing the Kubernetes startup check of the app container. |
3 |
startupProbeFailure |
Number of probe failures allowed for the startup probe before the pod is restarted. |
20 |
startupHttpProbePath |
Path that app container has to respond to for startup check. |
<none> |
startupProbePort |
Port that app container has to respond on for startup check. |
<none> |
readinessProbeDelay |
Delay in seconds when the readiness check of the app container should start checking if the module is fully up and running. |
10 |
readinessProbePeriod |
Period in seconds to perform the readiness check of the app container. |
10 |
readinessProbeTimeout |
Timeout in seconds that the app container has to respond to its health status during the readiness check. |
2 |
readinessProbePath |
Path that app container has to respond to for readiness check. |
<none> |
readinessProbePort |
Port that app container has to respond on for readiness check. |
<none> |
probeCredentialsSecret |
The secret name containing the credentials to use when accessing secured probe endpoints. |
<none> |
limits.memory |
The memory limit, maximum needed value to allocate a pod, Default unit is mebibytes, 'M' and 'G" suffixes supported |
<none> |
limits.cpu |
The CPU limit, maximum needed value to allocate a pod |
<none> |
limits.ephemeral-storage |
The ephemeral-storage limit, maximum needed value to allocate a pod. |
<none> |
limits.hugepages-2Mi |
The hugepages-2Mi limit, maximum needed value to allocate a pod. |
<none> |
limits.hugepages-1Gi |
The hugepages-1Gi limit, maximum needed value to allocate a pod. |
<none> |
requests.memory |
The memory request, guaranteed needed value to allocate a pod. |
<none> |
requests.cpu |
The CPU request, guaranteed needed value to allocate a pod. |
<none> |
requests.ephemeral-storage |
The ephemeral-storage request, guaranteed needed value to allocate a pod. |
<none> |
requests.hugepages-2Mi |
The hugepages-2Mi request, guaranteed needed value to allocate a pod. |
<none> |
requests.hugepages-1Gi |
The hugepages-1Gi request, guaranteed needed value to allocate a pod. |
<none> |
affinity.nodeAffinity |
The node affinity expressed in YAML format. e.g. |
<none> |
affinity.podAffinity |
The pod affinity expressed in YAML format. e.g. |
<none> |
affinity.podAntiAffinity |
The pod anti-affinity expressed in YAML format. e.g. |
<none> |
statefulSet.volumeClaimTemplate.storageClassName |
Name of the storage class for a stateful set |
<none> |
statefulSet.volumeClaimTemplate.storage |
The storage amount. Default unit is mebibytes, 'M' and 'G" suffixes supported |
<none> |
environmentVariables |
List of environment variables to set for any deployed app container |
<none> |
entryPointStyle |
Entry point style used for the Docker image. Used to determine how to pass in properties. Can be |
|
createLoadBalancer |
Create a "LoadBalancer" for the service created for each app. This facilitates assignment of external IP to app. |
false |
serviceAnnotations |
Service annotations to set for the service created for each application. String of the format |
<none> |
podAnnotations |
Pod annotations to set for the pod created for each deployment. String of the format |
<none> |
jobAnnotations |
Job annotations to set for the pod or job created for a job. String of the format |
<none> |
priorityClassName |
Pod Spec priorityClassName. Create a PriorityClass in Kubernetes before using this property. See Pod Priority and Preemption |
<none> |
shareProcessNamespace |
Will assign value to Pod.spec.shareProcessNamespace. See Share Process Namespace between Containers in a Pod |
<none> |
minutesToWaitForLoadBalancer |
Time to wait for load balancer to be available before attempting delete of service (in minutes). |
5 |
maxTerminatedErrorRestarts |
Maximum allowed restarts for app that fails due to an error or excessive resource use. |
2 |
maxCrashLoopBackOffRestarts |
Maximum allowed restarts for app that is in a CrashLoopBackOff. Values are |
|
volumeMounts |
volume mounts expressed in YAML format. e.g. |
<none> |
volumes |
The volumes that a Kubernetes instance supports specifed in YAML format. e.g. |
<none> |
hostNetwork |
The hostNetwork setting for the deployments, see kubernetes.io/docs/api-reference/v1/definitions/#_v1_podspec |
false |
createDeployment |
Create a "Deployment" with a "Replica Set" instead of a "Replication Controller". |
true |
createJob |
Create a "Job" instead of just a "Pod" when launching tasks. |
false |
containerCommand |
Overrides the default entry point command with the provided command and arguments. |
<none> |
containerPorts |
Adds additional ports to expose on the container. |
<none> |
createNodePort |
The explicit port to use when |
<none> |
deploymentServiceAccountName |
Service account name used in app deployments. Note: The service account name used for app deployments is derived from the Data Flow servers deployment. |
<none> |
deploymentLabels |
Additional labels to add to the deployment in |
<none> |
bootMajorVersion |
The Spring Boot major version to use. Currently only used to configure Spring Boot version specific probe paths automatically. Valid options are |
2 |
tolerations.key |
The key to use for the toleration. |
<none> |
tolerations.effect |
The toleration effect. See kubernetes.io/docs/concepts/configuration/taint-and-toleration for valid options. |
<none> |
tolerations.operator |
The toleration operator. See kubernetes.io/docs/concepts/configuration/taint-and-toleration/ for valid options. |
<none> |
tolerations.tolerationSeconds |
The number of seconds defining how long the pod will stay bound to the node after a taint is added. |
<none> |
tolerations.value |
The toleration value to apply, used in conjunction with |
<none> |
secretRefs |
The name of the secret(s) to load the entire data contents into individual environment variables. Multiple secrets may be comma separated. |
<none> |
secretKeyRefs.envVarName |
The environment variable name to hold the secret data |
<none> |
secretKeyRefs.secretName |
The secret name to access |
<none> |
secretKeyRefs.dataKey |
The key name to obtain secret data from |
<none> |
configMapRefs |
The name of the ConfigMap(s) to load the entire data contents into individual environment variables. Multiple ConfigMaps be comma separated. |
<none> |
configMapKeyRefs.envVarName |
The environment variable name to hold the ConfigMap data |
<none> |
configMapKeyRefs.configMapName |
The ConfigMap name to access |
<none> |
configMapKeyRefs.dataKey |
The key name to obtain ConfigMap data from |
<none> |
maximumConcurrentTasks |
The maximum concurrent tasks allowed for this platform instance |
20 |
podSecurityContext |
The security context applied to the pod expressed in YAML format. e.g. |
<none> |
podSecurityContext.runAsUser |
The numeric user ID to run pod container processes under |
<none> |
podSecurityContext.runAsGroup |
The numeric group id to run the entrypoint of the container process |
<none> |
podSecurityContext.runAsNonRoot |
Indicates that the container must run as a non-root user |
<none> |
podSecurityContext.fsGroup |
The numeric group ID for the volumes of the pod |
<none> |
podSecurityContext.fsGroupChangePolicy |
Defines behavior of changing ownership and permission of the volume before being exposed inside pod (only applies to volume types which support fsGroup based ownership and permissions) - possible values are "OnRootMismatch", "Always" |
<none> |
podSecurityContext.supplementalGroups |
The numeric group IDs applied to the pod container processes, in addition to the container’s primary group ID |
<none> |
podSecurityContext.seccompProfile |
The seccomp options to use for the pod containers expressed in YAML format. e.g. |
<none> |
podSecurityContext.seLinuxOptions |
The SELinux context to be applied to the pod containers expressed in YAML format. e.g. |
<none> |
podSecurityContext.sysctls |
List of namespaced sysctls used for the pod expressed in YAML format. e.g. |
<none> |
podSecurityContext.windowsOptions |
The Windows specific settings applied to all containers expressed in YAML format. e.g. |
<none> |
containerSecurityContext |
The security context applied to the containers expressed in YAML format. e.g. |
<none> |
containerSecurityContext.allowPrivilegeEscalation |
Whether a process can gain more privileges than its parent process |
<none> |
containerSecurityContext.capabilities |
The capabilities to add/drop when running the container expressed in YAML format. e.g. |
<none> |
containerSecurityContext.privileged |
Run container in privileged mode. |
<none> |
containerSecurityContext.procMount |
The type of proc mount to use for the container (only used when spec.os.name is not windows) |
<none> |
containerSecurityContext.readOnlyRootFilesystem |
Mounts the container’s root filesystem as read-only |
<none> |
containerSecurityContext.runAsUser |
The numeric user ID to run pod container processes under |
<none> |
containerSecurityContext.runAsGroup |
The numeric group id to run the entrypoint of the container process |
<none> |
containerSecurityContext.runAsNonRoot |
Indicates that the container must run as a non-root user |
<none> |
containerSecurityContext.seccompProfile |
The seccomp options to use for the pod containers expressed in YAML format. e.g. |
<none> |
containerSecurityContext.seLinuxOptions |
The SELinux context to be applied to the pod containers expressed in YAML format. e.g. |
<none> |
containerSecurityContext.sysctls |
List of namespaced sysctls used for the pod expressed in YAML format. e.g. |
<none> |
containerSecurityContext.windowsOptions |
The Windows specific settings applied to all containers expressed in YAML format. e.g. |
<none> |
statefulSetInitContainerImageName |
A custom image name to use for the StatefulSet Init Container |
<none> |
initContainer |
An Init Container expressed in YAML format to be applied to a pod. e.g. |
<none> |
additionalContainers |
Additional containers expressed in YAML format to be applied to a pod. e.g. |
<none> |
11.4. Tasks
The Data Flow server is responsible for deploying Tasks.
Tasks that are launched by Data Flow write their state to the same database that is used by the Data Flow server.
For Tasks which are Spring Batch Jobs, the job and step execution data is also stored in this database.
As with Skipper, Tasks can be launched to multiple platforms.
When Data Flow is running on Kubernetes, a Task platfom must be defined.
To configure new platform accounts that target Kubernetes, provide an entry under the spring.cloud.dataflow.task.platform.kubernetes section in your application.yaml file for via another Spring Boot supported mechanism.
In the following example, two Kubernetes platform accounts named dev and qa are created.
The keys such as memory and disk are Cloud Foundry Deployer Properties.
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
dev:
namespace: devNamespace
imagePullPolicy: IfNotPresent
entryPointStyle: exec
limits:
cpu: 4
qa:
namespace: qaNamespace
imagePullPolicy: IfNotPresent
entryPointStyle: boot
limits:
memory: 2048m
By defining one platform as default allows you to skip using platformName where its use would otherwise be required.
|
When launching a task, pass the value of the platform account name using the task launch option --platformName If you do not pass a value for platformName, the value default will be used.
| When deploying a task to multiple platforms, the configuration of the task needs to connect to the same database as the Data Flow Server. |
You can configure the Data Flow server that is on Kubernetes to deploy tasks to Cloud Foundry and Kubernetes. See the section on Cloud Foundry Task Platform Configuration for more information.
Detailed examples for launching and scheduling tasks across multiple platforms, are available in this section Multiple Platform Support for Tasks on dataflow.spring.io.
11.5. General Configuration
The Spring Cloud Data Flow server for Kubernetes uses the spring-cloud-kubernetes module to process secrets that are mounted under /etc/secrets. ConfigMaps must be mounted as application.yaml in the /config directory that is processed by Spring Boot. To avoid access to the Kubernetes API server the SPRING_CLOUD_KUBERNETES_CONFIG_ENABLE_API and SPRING_CLOUD_KUBERNETES_SECRETS_ENABLE_API are set to false.
11.5.1. Using ConfigMap and Secrets
You can pass configuration properties to the Data Flow Server by using Kubernetes ConfigMap and secrets.
The following example shows one possible configuration, which enables MariaDB and sets a memory limit:
apiVersion: v1
kind: ConfigMap
metadata:
name: scdf-server
labels:
app: scdf-server
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
limits:
memory: 1024Mi
datasource:
url: jdbc:mariadb://${MARIADB_SERVICE_HOST}:${MARIADB_SERVICE_PORT}/database
username: root
password: ${database-password}
driverClassName: org.mariadb.jdbc.Driver
testOnBorrow: true
validationQuery: "SELECT 1"The preceding example assumes that MariaDB is deployed with mariadb as the service name. Kubernetes publishes the host and port values of these services as environment variables that we can use when configuring the apps we deploy.
We prefer to provide the MariaDB connection password in a Secrets file, as the following example shows:
apiVersion: v1
kind: Secret
metadata:
name: mariadb
labels:
app: mariadb
data:
database-password: eW91cnBhc3N3b3JkThe password is a base64-encoded value.
11.6. Database
A relational database is used to store stream and task definitions as well as the state of executed tasks. Spring Cloud Data Flow provides schemas for MariaDB, MySQL, Oracle, PostgreSQL, Db2, SQL Server, and H2. The schema is automatically created when the server starts.
| The JDBC drivers for MariaDB, MySQL (via the MariaDB driver), PostgreSQL, SQL Server are available without additional configuration. To use any other database you need to put the corresponding JDBC driver jar on the classpath of the server as described here. |
To configure a database the following properties must be set:
-
spring.datasource.url -
spring.datasource.username -
spring.datasource.password -
spring.datasource.driver-class-name -
spring.jpa.database-platform
The username and password are the same regardless of the database. However, the url and driver-class-name vary per database as follows.
| Database | spring.datasource.url | spring.datasource.driver-class-name | spring.jpa.database-platform | Driver included |
|---|---|---|---|---|
MariaDB 10.0 - 10.1 |
jdbc:mariadb://${db-hostname}:${db-port}/${db-name} |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MariaDB10Dialect |
Yes |
MariaDB 10.2 |
jdbc:mariadb://${db-hostname}:${db-port}/${db-name} |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MariaDB102Dialect |
Yes |
MariaDB 10.3 - 10.5 |
jdbc:mariadb://${db-hostname}:${db-port}/${db-name} |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MariaDB103Dialect |
Yes |
MariaDB 10.6+ |
jdbc:mariadb://${db-hostname}:${db-port}/${db-name} |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MariaDB106Dialect[3] |
Yes |
MySQL 5.7 |
jdbc:mysql://${db-hostname}:${db-port}/${db-name}?permitMysqlScheme |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MySQL57Dialect |
Yes |
MySQL 8.0+ |
jdbc:mysql://${db-hostname}:${db-port}/${db-name}?allowPublicKeyRetrieval=true&useSSL=false&autoReconnect=true&permitMysqlScheme[4] |
org.mariadb.jdbc.Driver |
org.hibernate.dialect.MySQL8Dialect |
Yes |
PostgresSQL |
jdbc:postgres://${db-hostname}:${db-port}/${db-name} |
org.postgresql.Driver |
Remove for Hibernate default |
Yes |
SQL Server |
jdbc:sqlserver://${db-hostname}:${db-port};databasename=${db-name}&encrypt=false |
com.microsoft.sqlserver.jdbc.SQLServerDriver |
Remove for Hibernate default |
Yes |
DB2 |
jdbc:db2://${db-hostname}:${db-port}/{db-name} |
com.ibm.db2.jcc.DB2Driver |
Remove for Hibernate default |
No |
Oracle |
jdbc:oracle:thin:@${db-hostname}:${db-port}/{db-name} |
oracle.jdbc.OracleDriver |
Remove for Hibernate default |
No |
11.6.1. H2
When no other database is configured then Spring Cloud Data Flow uses an embedded instance of the H2 database as the default.
| H2 is good for development purposes but is not recommended for production use nor is it supported as an external mode. |
11.6.2. Database configuration
When running in Kubernetes, the database properties are typically set in the ConfigMap. For instance, if you use MariaDB in addition to a password in the secrets file, you could provide the following properties in the ConfigMap:
data:
application.yaml: |-
spring:
datasource:
url: jdbc:mariadb://${MARIADB_SERVICE_HOST}:${MARIADB_SERVICE_PORT}/database
username: root
password: ${database-password}
driverClassName: org.mariadb.jdbc.DriverSimilarly, for PostgreSQL you could use the following configuration:
data:
application.yaml: |-
spring:
datasource:
url: jdbc:postgresql://${PGSQL_SERVICE_HOST}:${PGSQL_SERVICE_PORT}/database
username: root
password: ${postgres-password}
driverClassName: org.postgresql.DriverThe following YAML snippet from a Deployment is an example of mounting a ConfigMap as application.yaml under /config where Spring Boot will process it plus a Secret mounted under /etc/secrets where it will get picked up by the spring-cloud-kubernetes library due to the environment variable SPRING_CLOUD_KUBERNETES_SECRETS_PATHS being set to /etc/secrets.
...
containers:
- name: scdf-server
image: springcloud/spring-cloud-dataflow-server:2.11.3-SNAPSHOT
imagePullPolicy: IfNotPresent
volumeMounts:
- name: config
mountPath: /config
readOnly: true
- name: database
mountPath: /etc/secrets/database
readOnly: true
ports:
...
volumes:
- name: config
configMap:
name: scdf-server
items:
- key: application.yaml
path: application.yaml
- name: database
secret:
secretName: mariadbYou can find migration scripts for specific database types in the spring-cloud-task repo.
11.7. Monitoring and Management
We recommend using the kubectl command for troubleshooting streams and tasks.
You can list all artifacts and resources used by using the following command:
kubectl get all,cm,secrets,pvcYou can list all resources used by a specific application or service by using a label to select resources. The following command lists all resources used by the mariadb service:
kubectl get all -l app=mariadbYou can get the logs for a specific pod by issuing the following command:
kubectl logs pod <pod-name>If the pod is continuously getting restarted, you can add -p as an option to see the previous log, as follows:
kubectl logs -p <pod-name>You can also tail or follow a log by adding an -f option, as follows:
kubectl logs -f <pod-name>A useful command to help in troubleshooting issues, such as a container that has a fatal error when starting up, is to use the describe command, as the following example shows:
kubectl describe pod ticktock-log-0-qnk7211.7.1. Inspecting Server Logs
You can access the server logs by using the following command:
kubectl get pod -l app=scdf=server
kubectl logs <scdf-server-pod-name>11.7.2. Streams
Stream applications are deployed with the stream name followed by the name of the application. For processors and sinks, an instance index is also appended.
To see all the pods that are deployed by the Spring Cloud Data Flow server, you can specify the role=spring-app label, as follows:
kubectl get pod -l role=spring-appTo see details for a specific application deployment you can use the following command:
kubectl describe pod <app-pod-name>To view the application logs, you can use the following command:
kubectl logs <app-pod-name>If you would like to tail a log you can use the following command:
kubectl logs -f <app-pod-name>11.7.3. Tasks
Tasks are launched as bare pods without a replication controller. The pods remain after the tasks complete, which gives you an opportunity to review the logs.
To see all pods for a specific task, use the following command:
kubectl get pod -l task-name=<task-name>To review the task logs, use the following command:
kubectl logs <task-pod-name>You have two options to delete completed pods. You can delete them manually once they are no longer needed or you can use the Data Flow shell task execution cleanup command to remove the completed pod for a task execution.
To delete the task pod manually, use the following command:
kubectl delete pod <task-pod-name>To use the task execution cleanup command, you must first determine the ID for the task execution. To do so, use the task execution list command, as the following example (with output) shows:
dataflow:>task execution list
╔═════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗
║Task Name│ID│ Start Time │ End Time │Exit Code║
╠═════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣
║task1 │1 │Fri May 05 18:12:05 EDT 2017│Fri May 05 18:12:05 EDT 2017│0 ║
╚═════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝Once you have the ID, you can issue the command to cleanup the execution artifacts (the completed pod), as the following example shows:
dataflow:>task execution cleanup --id 1
Request to clean up resources for task execution 1 has been submittedDatabase Credentials for Tasks
By default Spring Cloud Data Flow passes database credentials as properties to the pod at task launch time.
If using the exec or shell entry point styles the DB credentials will be viewable if the user does a kubectl describe on the task’s pod.
To configure Spring Cloud Data Flow to use Kubernetes Secrets: Set spring.cloud.dataflow.task.use.kubernetes.secrets.for.db.credentials property to true. If using the yaml files provided by Spring Cloud Data Flow update the `src/kubernetes/server/server-deployment.yaml to add the following environment variable:
- name: SPRING_CLOUD_DATAFLOW_TASK_USE_KUBERNETES_SECRETS_FOR_DB_CREDENTIALS
value: 'true'If upgrading from a previous version of SCDF be sure to verify that spring.datasource.username and spring.datasource.password environment variables are present in the secretKeyRefs in the server-config.yaml. If not, add it as shown in the example below:
...
task:
platform:
kubernetes:
accounts:
default:
secretKeyRefs:
- envVarName: "spring.datasource.password"
secretName: mariadb
dataKey: database-password
- envVarName: "spring.datasource.username"
secretName: mariadb
dataKey: database-username
...Also verify that the associated secret(dataKey) is also available in secrets. SCDF provides an example of this for MariaDB here: src/kubernetes/mariadb/mariadb-svc.yaml.
| Passing of DB credentials via properties by default is to preserve to backwards compatibility. This will be feature will be removed in future release. |
11.8. Scheduling
This section covers customization of how scheduled tasks are configured. Scheduling of tasks is enabled by default in the Spring Cloud Data Flow Kubernetes Server. Properties are used to influence settings for scheduled tasks and can be configured on a global or per-schedule basis.
| Unless noted, properties set on a per-schedule basis always take precedence over properties set as the server configuration. This arrangement allows for the ability to override global server level properties for a specific schedule. |
11.8.1. Entry Point Style
An Entry Point Style affects how application properties are passed to the task container to be deployed. Currently, three styles are supported:
-
exec: (default) Passes all application properties as command line arguments. -
shell: Passes all application properties as environment variables. -
boot: Creates an environment variable calledSPRING_APPLICATION_JSONthat contains a JSON representation of all application properties.
You can configure the entry point style as follows:
deployer.kubernetes.entryPointStyle=<Entry Point Style>Replace <Entry Point Style> with your desired Entry Point Style.
You can also configure the Entry Point Style at the server level in the container env section of a deployment YAML, as the following example shows:
env:
- name: SPRING_CLOUD_DEPLOYER_KUBERNETES_ENTRY_POINT_STYLE
value: entryPointStyleReplace entryPointStyle with the desired Entry Point Style.
You should choose an Entry Point Style of either exec or shell, to correspond to how the ENTRYPOINT syntax is defined in the container’s Dockerfile. For more information and uses cases on exec vs shell, see the ENTRYPOINT section of the Docker documentation.
Using the boot Entry Point Style corresponds to using the exec style ENTRYPOINT. Command line arguments from the deployment request are passed to the container, with the addition of application properties mapped into the SPRING_APPLICATION_JSON environment variable rather than command line arguments.
ttlSecondsAfterFinished
When scheduling an application, You can clean up finished Jobs (either Complete or Failed) automatically by specifying ttlSecondsAfterFinished value.
The following example shows how you can configure for scheduled application jobs:
deployer.<application>.kubernetes.cron.ttlSecondsAfterFinished=86400The following example shows how you can individually configure application jobs:
deployer.<application>.kubernetes.ttlSecondsAfterFinished=86400Replace <application> with the name of your application and the ttlSecondsAfterFinished attribute with the appropriate value for clean up finished Jobs.
You can configure the ttlSecondsAfterFinished at the global server level as well.
The following example shows how to do so for tasks:
You can configure an image pull policy at the server level in the container env section of a deployment YAML, as the following example shows:
env:
- name: SPRING_CLOUD_DEPLOYER_KUBERNETES_TTL_SECONDS_AFTER_FINISHED
value: 8640011.8.2. Environment Variables
To influence the environment settings for a given application, you can take advantage of the spring.cloud.deployer.kubernetes.environmentVariables property.
For example, a common requirement in production settings is to influence the JVM memory arguments.
You can achieve this by using the JAVA_TOOL_OPTIONS environment variable, as the following example shows:
deployer.kubernetes.environmentVariables=JAVA_TOOL_OPTIONS=-Xmx1024m
When deploying stream applications or launching task applications where some of the properties may contain sensitive information, use the shell or boot as the entryPointStyle. This is because the exec (default) converts all properties to command line arguments and thus may not be secure in some environments.
|
Additionally you can configure environment variables at the server level in the container env section of a deployment YAML, as the following example shows:
| When specifying environment variables in the server configuration and on a per-schedule basis, environment variables will be merged. This allows for the ability to set common environment variables in the server configuration and more specific at the specific schedule level. |
env:
- name: SPRING_CLOUD_DEPLOYER_KUBERNETES_ENVIRONMENT_VARIABLES
value: myVar=myValReplace myVar=myVal with your desired environment variables.
11.8.3. Image Pull Policy
An image pull policy defines when a Docker image should be pulled to the local registry. Currently, three policies are supported:
-
IfNotPresent: (default) Do not pull an image if it already exists. -
Always: Always pull the image regardless of whether it already exists. -
Never: Never pull an image. Use only an image that already exists.
The following example shows how you can individually configure containers:
deployer.kubernetes.imagePullPolicy=IfNotPresentReplace Always with your desired image pull policy.
You can configure an image pull policy at the server level in the container env section of a deployment YAML, as the following example shows:
env:
- name: SPRING_CLOUD_DEPLOYER_KUBERNETES_IMAGE_PULL_POLICY
value: AlwaysReplace Always with your desired image pull policy.
11.8.4. Private Docker Registry
Docker images that are private and require authentication can be pulled by configuring a Secret. First, you must create a Secret in the cluster. Follow the Pull an Image from a Private Registry guide to create the Secret.
Once you have created the secret, use the imagePullSecret property to set the secret to use, as the following example shows:
deployer.kubernetes.imagePullSecret=mysecretReplace mysecret with the name of the secret you created earlier.
You can also configure the image pull secret at the server level in the container env section of a deployment YAML, as the following example shows:
env:
- name: SPRING_CLOUD_DEPLOYER_KUBERNETES_IMAGE_PULL_SECRET
value: mysecretReplace mysecret with the name of the secret you created earlier.
11.8.5. Namespace
By default the namespace used for scheduled tasks is default. This value can be set at the server level configuration in the container env section of a deployment YAML, as the following example shows:
env:
- name: SPRING_CLOUD_DEPLOYER_KUBERNETES_NAMESPACE
value: mynamespace11.8.6. Service Account
You can configure a custom service account for scheduled tasks through properties. An existing service account can be used or a new one created. One way to create a service account is by using kubectl, as the following example shows:
$ kubectl create serviceaccount myserviceaccountname
serviceaccount "myserviceaccountname" createdThen you can configure the service account to use on a per-schedule basis as follows:
deployer.kubernetes.taskServiceAccountName=myserviceaccountnameReplace myserviceaccountname with your service account name.
You can also configure the service account name at the server level in the container env section of a deployment YAML, as the following example shows:
env:
- name: SPRING_CLOUD_DEPLOYER_KUBERNETES_TASK_SERVICE_ACCOUNT_NAME
value: myserviceaccountnameReplace myserviceaccountname with the service account name to be applied to all deployments.
For more information on scheduling tasks see Scheduling Tasks.
11.9. Debug Support
Debugging the Spring Cloud Data Flow Kubernetes Server and included components (such as the Spring Cloud Kubernetes Deployer) is supported through the Java Debug Wire Protocol (JDWP). This section outlines an approach to manually enable debugging and another approach that uses configuration files provided with Spring Cloud Data Flow Server Kubernetes to “patch” a running deployment.
| JDWP itself does not use any authentication. This section assumes debugging is being done on a local development environment (such as Minikube), so guidance on securing the debug port is not provided. |
11.9.1. Enabling Debugging Manually
To manually enable JDWP, first edit src/kubernetes/server/server-deployment.yaml and add an additional containerPort entry under spec.template.spec.containers.ports with a value of 5005. Additionally, add the JAVA_TOOL_OPTIONS environment variable under spec.template.spec.containers.env as the following example shows:
spec:
...
template:
...
spec:
containers:
- name: scdf-server
...
ports:
...
- containerPort: 5005
env:
- name: JAVA_TOOL_OPTIONS
value: '-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005'
The preceding example uses port 5005, but it can be any number that does not conflict with another port. The chosen port number must also be the same for the added containerPort value and the address parameter of the JAVA_TOOL_OPTIONS -agentlib flag, as shown in the preceding example.
|
You can now start the Spring Cloud Data Flow Kubernetes Server. Once the server is up, you can verify the configuration changes on the scdf-server deployment, as the following example (with output) shows:
kubectl describe deployment/scdf-server
...
...
Pod Template:
...
Containers:
scdf-server:
...
Ports: 80/TCP, 5005/TCP
...
Environment:
JAVA_TOOL_OPTIONS: -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
...With the server started and JDWP enabled, you need to configure access to the port. In this example, we use the port-forward subcommand of kubectl. The following example (with output) shows how to expose a local port to your debug target by using port-forward:
$ kubectl get pod -l app=scdf-server
NAME READY STATUS RESTARTS AGE
scdf-server-5b7cfd86f7-d8mj4 1/1 Running 0 10m
$ kubectl port-forward scdf-server-5b7cfd86f7-d8mj4 5005:5005
Forwarding from 127.0.0.1:5005 -> 5005
Forwarding from [::1]:5005 -> 5005You can now attach a debugger by pointing it to 127.0.0.1 as the host and 5005 as the port. The port-forward subcommand runs until stopped (by pressing CTRL+c, for example).
You can remove debugging support by reverting the changes to src/kubernetes/server/server-deployment.yaml. The reverted changes are picked up on the next deployment of the Spring Cloud Data Flow Kubernetes Server. Manually adding debug support to the configuration is useful when debugging should be enabled by default each time the server is deployed.
11.9.2. Enabling Debugging with Patching
Rather than manually changing the server-deployment.yaml, Kubernetes objects can be “patched” in place. For convenience, patch files that provide the same configuration as the manual approach are included. To enable debugging by patching, use the following command:
kubectl patch deployment scdf-server -p "$(cat src/kubernetes/server/server-deployment-debug.yaml)"Running the preceding command automatically adds the containerPort attribute and the JAVA_TOOL_OPTIONS environment variable. The following example (with output) shows how toverify changes to the scdf-server deployment:
$ kubectl describe deployment/scdf-server
...
...
Pod Template:
...
Containers:
scdf-server:
...
Ports: 5005/TCP, 80/TCP
...
Environment:
JAVA_TOOL_OPTIONS: -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
...To enable access to the debug port, rather than using the port-forward subcommand of kubectl, you can patch the scdf-server Kubernetes service object. You must first ensure that the scdf-server Kubernetes service object has the proper configuration. The following example (with output) shows how to do so:
kubectl describe service/scdf-server
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 30784/TCPIf the output contains <unset>, you must patch the service to add a name for this port. The following example shows how to do so:
$ kubectl patch service scdf-server -p "$(cat src/kubernetes/server/server-svc.yaml)"
A port name should only be missing if the target cluster had been created prior to debug functionality being added. Since multiple ports are being added to the scdf-server Kubernetes Service Object, each needs to have its own name.
|
Now you can add the debug port, as the following example shows:
kubectl patch service scdf-server -p "$(cat src/kubernetes/server/server-svc-debug.yaml)"The following example (with output) shows how to verify the mapping:
$ kubectl describe service scdf-server
Name: scdf-server
...
...
Port: scdf-server-jdwp 5005/TCP
TargetPort: 5005/TCP
NodePort: scdf-server-jdwp 31339/TCP
...
...
Port: scdf-server 80/TCP
TargetPort: 80/TCP
NodePort: scdf-server 30883/TCP
...
...The output shows that container port 5005 has been mapped to the NodePort of 31339. The following example (with output) shows how to get the IP address of the Minikube node:
$ minikube ip
192.168.99.100With this information, you can create a debug connection by using a host of 192.168.99.100 and a port of 31339.
The following example shows how to disable JDWP:
$ kubectl rollout undo deployment/scdf-server
$ kubectl patch service scdf-server --type json -p='[{"op": "remove", "path": "/spec/ports/0"}]'The Kubernetes deployment object is rolled back to its state before being patched. The Kubernetes service object is then patched with a remove operation to remove port 5005 from the containerPorts list.
kubectl rollout undo forces the pod to restart. Patching the Kubernetes Service Object does not re-create the service, and the port mapping to the scdf-server deployment remains the same.
|
See Rolling Back a Deployment for more information on deployment rollbacks, including managing history and Updating API Objects in Place Using kubectl Patch.
12. Deployment using Carvel
Deployment of a carvel package requires the installation of tools and specific Kubernetes controllers. Then you will add the package repository to the cluster and install the application.
For local minikube or kind cluster you can use: Configure Kubernetes for local development or testing, and follow the instructions until the section Deploy Spring Cloud Data Flow
12.1. Required Tools
-
kubectl- Kubernetes CLI (Install withbrew install kubectl) -
carvel- Packaging and Deployment tools
Carvel CLI can be installed using:
wget -O- https://carvel.dev/install.sh | bash
# or with curl...
curl -L https://carvel.dev/install.sh | bashAlternative following the instructions at the bottom of the home page at carvel.dev
The following tools are use by the scripts.
-
jq- lightweight JSON parser -
yq- lightweight YAML parser -
wget- Invoke http requests. -
dirnameprovides the directory part of a filename. -
readlinkprovides absolute path of a relative link.
| Some of these utilities are not installed in macOS or *nix by default but will be available from MacPorts or HomeBrew. |
12.2. Scripts
These scripts assume you are connected to a Kubernetes cluster and kubectl is available.
| Name | Arguments | Descriptions |
|---|---|---|
|
<broker> [scdf-type] [namespace] [release|snapshot] |
Configures environmental variables needs for the rest of the scripts. |
|
N/A |
Installs cert-manager, secretgen-controller and kapp-controller |
|
[scdf-type] (oss, pro) |
Creates |
|
<secret-name> <namespace> [secret-namespace] [--import|--placeholder] |
Creates an import secret, placeholder or import using secretgen-controller. |
|
[scdf-type] (oss, pro) |
Creates the namespace and installs the relevant Carvel package and credentials. If the optional scdf-type is not provided the environmental variable |
|
<host> <port> [step] |
Configures Spring Boot Actuator properties for Data Flow, Skipper, Streams and Tasks. Default |
|
<app> <database> <url> <username/secret-name> [password/secret-username-key] [secret-password-key] |
If only secret-name is provided then secret-username-key defaults to The following 3 combinations are allowed after the url:
|
|
[app-name] |
Deploys the application using the package and |
|
[app-name] |
Updated the deployed application using a modified values file.
The default app-name is |
|
N/A |
Will print the URL to access dataflow. If you use |
|
<broker> [stream-application-version] |
broker must be one of rabbit or kafka. stream-application-version is optional and will install the latest version. The latest version is 2021.1.2 |
| Take note that the registration of application in the pro version can take a few minutes since it retrieves all version information and metadata upfront. |
12.3. Preparation
You will need to prepare a values file named scdf-values.yml The following steps will provide help.
12.3.1. Prepare Configuration parameters
Executing the following script will configure the environmental variables needed.
source ./carvel/start-deploy.sh <broker> <namespace> [scdf-type] [release|snapshot]Where:
-
brokeris one of rabbitmq or kafka -
namespaceA valid Kubernetes namespace other thandefault -
scdf-typeOne of oss or pro. oss is the default. -
release|snapshotandscdf-typewill determine the value ofPACKAGE_VERSION.
*The best option to ensure using the type and version of package intended is to modify deploy/versions.yaml*
The environmental variables can also be configured manually to override the values.
| Name | Description | Default |
|---|---|---|
|
Version of Carvel package. |
Release version |
|
Version of Spring Cloud Data Flow |
2.11.2 |
|
Version of Spring Cloud Data Flow Pro |
1.6.1 |
|
Version of Spring Cloud Skipper |
2.11.2 |
|
Url and repository of package registry. Format |
|
|
One of |
|
|
One of |
|
|
A Kubernetes namespace other than |
|
|
One of |
|
The above environmental variables should only be provided if different from the default in deploy/versions.yaml
|
12.4. Prepare cluster and add repository
Login to docker and optionally registry.tanzu.vmware.com for Spring Cloud Data Flow Pro.
# When deploying SCDF Pro.
export TANZU_DOCKER_USERNAME="<tanzu-net-username>"
export TANZU_DOCKER_PASSWORD="<tanzu-net-password>"
docker login --username $TANZU_DOCKER_USERNAME --password $TANZU_DOCKER_PASSWORD registry.packages.broadcom.com
# Always required to ensure you don't experience rate limiting with Docker HUB
export DOCKER_HUB_USERNAME="<docker-hub-username>"
export DOCKER_HUB_PASSWORD="<docker-hub-password>"
docker login --username $DOCKER_HUB_USERNAME --password $DOCKER_HUB_PASSWORD index.docker.ioInstall carvel kapp-controller, secretgen-controller and certmanager
./carvel/prepare-cluster.shLoad scdf repo package for the scdf-type
./carvel/setup-scdf-repo.sh12.5. Install supporting services
In a production environment you should be using supported database and broker services or operators along with shared observability tools.
For local development or demonstration the following can be used to install database, broker and prometheus.
12.6. Configure Prometheus proxy
In the case where and existing prometheus and prometheus proxy is deployed the proxy can be configured using:
./carvel/configure-prometheus-proxy.sh <host> <port> [step]12.7. Deploy Spring Cloud Data Flow
You can configure the before register-apps.sh:
-
STREAM_APPS_RT_VERSIONStream Apps Release Train Version. Default is 2022.0.0. -
STREAM_APPS_VERSIONStream Apps Version. Default is 4.0.0.
./carvel/deploy-scdf.sh
source ./carvel/export-dataflow-ip.sh
# expected output: Dataflow URL: <url-to-access-dataflow>
./carvel/register-apps.shShell
This section covers the options for starting the shell and more advanced functionality relating to how the shell handles whitespace, quotes, and interpretation of SpEL expressions. The introductory chapters to the Stream DSL and Composed Task DSL are good places to start for the most common usage of shell commands.
13. Shell Options
The shell is built upon the Spring Shell project. Some command-line options come from Spring Shell, and some are specific to Data Flow. The shell takes the following command line options:
unix:>java -jar spring-cloud-dataflow-shell-2.11.5.jar --help
Data Flow Options:
--dataflow.uri= Address of the Data Flow Server [default: http://localhost:9393].
--dataflow.username= Username of the Data Flow Server [no default].
--dataflow.password= Password of the Data Flow Server [no default].
--dataflow.credentials-provider-command= Executes an external command which must return an
OAuth Bearer Token (Access Token prefixed with 'Bearer '),
e.g. 'Bearer 12345'), [no default].
--dataflow.skip-ssl-validation= Accept any SSL certificate (even self-signed) [default: no].
--dataflow.proxy.uri= Address of an optional proxy server to use [no default].
--dataflow.proxy.username= Username of the proxy server (if required by proxy server) [no default].
--dataflow.proxy.password= Password of the proxy server (if required by proxy server) [no default].
--spring.shell.historySize= Default size of the shell log file [default: 3000].
--spring.shell.commandFile= Data Flow Shell executes commands read from the file(s) and then exits.
--help This message. You can use the spring.shell.commandFile option to point to an existing file that contains
all the shell commands to deploy one or many related streams and tasks.
Running multiple files is also supported. They should be passed as a comma-delimited string:
--spring.shell.commandFile=file1.txt,file2.txt
This option is useful when creating some scripts to help automate deployment.
Also, the following shell command helps to modularize a complex script into multiple independent files:
dataflow:>script --file <YOUR_AWESOME_SCRIPT>
14. Listing Available Commands
Typing help at the command prompt gives a listing of all available commands.
Most of the commands are for Data Flow functionality, but a few are general purpose.
The following listing shows the output of the help command:
Built-In Commands
help: Display help about available commands
stacktrace: Display the full stacktrace of the last error.
clear: Clear the shell screen.
quit, exit: Exit the shell.
history: Display or save the history of previously run commands
version: Show version info
script: Read and execute commands from a file.Adding the name of the command to help shows additional information on how to invoke the command:
dataflow:>help stream create
NAME
stream create - Create a new stream definition
SYNOPSIS
stream create [--name String] [--definition String] --description String --deploy boolean
OPTIONS
--name String
the name to give to the stream
[Mandatory]
--definition String
a stream definition, using the DSL (e.g. "http --port=9000 | hdfs")
[Mandatory]
--description String
a short description about the stream
[Optional]
--deploy boolean
whether to deploy the stream immediately
[Optional, default = false]15. Tab Completion
You can complete the shell command options in the shell by pressing the TAB key after the leading --. For example, pressing TAB after stream create -- results in the following pair of suggestions:
dataflow:>stream create --
--definition --deploy --description --nameIf you type --de and then press tab, --definition expands.
Tab completion is also available inside the stream or composed task DSL expression for application or task properties. You can also use TAB to get hints in a stream DSL expression for the available sources, processors, or sinks that you can use.
16. Whitespace and Quoting Rules
You need to quote parameter values only if they contain spaces or the | character. The following example passes a SpEL expression (which is applied to any data it encounters) to a transform processor:
transform --expression='new StringBuilder(payload).reverse()'If the parameter value needs to embed a single quote, use two single quotes, as follows:
// Query is: Select * from /Customers where name='Smith'
scan --query='Select * from /Customers where name=''Smith'''16.1. Quotes and Escaping
There is a Spring Shell-based client that talks to the Data Flow Server and is responsible for parsing the DSL. In turn, applications may have application properties that rely on embedded languages, such as the Spring Expression Language.
The Shell, Data Flow DSL parser, and SpEL have rules about how they handle quotes and how syntax escaping works. When combined together, confusion may arise. This section explains the rules that apply and provides examples of the most complicated situations you may encounter when all three components are involved.
|
It is not always that complicated
If you do not use the Data Flow Shell (for example, if you use the REST API directly) or if application properties are not SpEL expressions, the escaping rules are simpler. |
16.1.1. Shell Rules
Arguably, the most complex component when it comes to quotes is the Shell. The rules can be laid out quite simply, though:
-
A shell command is made of keys (
--something) and corresponding values. There is a special, keyless mapping, though, which is described later. -
A value cannot normally contain spaces, as space is the default delimiter for commands.
-
Spaces can be added though, by surrounding the value with quotes (either single (
') or double (") quotes). -
Values passed inside deployment properties (for example,
deployment <stream-name> --properties " …") should not be quoted again. -
If surrounded with quotes, a value can embed a literal quote of the same kind by prefixing it with a backslash (
\). -
Other escapes are available, such as
\t,\n,\r,\fand unicode escapes of the form\uxxxx. -
The keyless mapping is handled in a special way such that it does not need quoting to contain spaces.
For example, the shell supports the ! command to execute native shell commands. The ! accepts a single keyless argument. This is why the following example works:
dataflow:>! rm somethingThe argument here is the whole rm something string, which is passed as is to the underlying shell.
As another example, the following commands are strictly equivalent, and the argument value is something (without the quotes):
dataflow:>stream destroy something
dataflow:>stream destroy --name something
dataflow:>stream destroy "something"
dataflow:>stream destroy --name "something"16.1.2. Property Files Rules
The rules are relaxed when loading the properties from files.
-
The special characters used in property files (both Java and YAML) need to be escaped. For example
\should be replaced by\\,\tby\\tand so forth. -
For Java property files (
--propertiesFile <FILE_PATH>.properties), the property values should not be surrounded by quotes. It is not needed even if they contain spaces.filter.expression=payload > 5 -
For YAML property files (
--propertiesFile <FILE_PATH>.yaml), though, the values need to be surrounded by double quotes.app: filter: filter: expression: "payload > 5"
16.1.3. DSL Parsing Rules
At the parser level (that is, inside the body of a stream or task definition), the rules are as follows:
-
Option values are normally parsed until the first space character.
-
They can be made of literal strings, though, surrounded by single or double quotes.
-
To embed such a quote, use two consecutive quotes of the desired kind.
As such, the values of the --expression option to the filter application are semantically equivalent in the following examples:
filter --expression=payload>5
filter --expression="payload>5"
filter --expression='payload>5'
filter --expression='payload > 5'Arguably, the last one is more readable. It is made possible thanks to the surrounding quotes. The actual expression is payload > 5.
Now, imagine that we want to test against string messages. If we want to compare the payload to the SpEL literal string, "something", we could use the following:
filter --expression=payload=='something' (1)
filter --expression='payload == ''something''' (2)
filter --expression='payload == "something"' (3)| 1 | This works because there are no spaces. It is not very legible, though. |
| 2 | This uses single quotes to protect the whole argument. Hence, the actual single quotes need to be doubled. |
| 3 | SpEL recognizes String literals with either single or double quotes, so this last method is arguably the most readable. |
Note that the preceding examples are to be considered outside of the shell (for example, when calling the REST API directly). When entered inside the shell, chances are that the whole stream definition is itself inside double quotes, which would need to be escaped. The whole example then becomes the following:
dataflow:>stream create something --definition "http | filter --expression=payload='something' | log"
dataflow:>stream create something --definition "http | filter --expression='payload == ''something''' | log"
dataflow:>stream create something --definition "http | filter --expression='payload == \"something\"' | log"16.1.4. SpEL Syntax and SpEL Literals
The last piece of the puzzle is about SpEL expressions. Many applications accept options that are to be interpreted as SpEL expressions, and, as seen earlier, String literals are handled in a special way there, too. The rules are as follows:
-
Literals can be enclosed in either single or double quotes.
-
Quotes need to be doubled to embed a literal quote. Single quotes inside double quotes need no special treatment, and the reverse is also true.
As a last example, assume you want to use the transform processor.
This processor accepts an expression option which is a SpEL expression. It is to be evaluated against the incoming message, with a default of payload (which forwards the message payload untouched).
It is important to understand that the following statements are equivalent:
transform --expression=payload
transform --expression='payload'However, they are different from the following (and variations upon them):
transform --expression="'payload'"
transform --expression='''payload'''The first series evaluates to the message payload, while the latter examples evaluate to the literal string, payload.
16.1.5. Putting It All Together
As a last, complete example, consider how you could force the transformation of all messages to the string literal, hello world, by creating a stream in the context of the Data Flow shell:
dataflow:>stream create something --definition "http | transform --expression='''hello world''' | log" (1) dataflow:>stream create something --definition "http | transform --expression='\"hello world\"' | log" (2) dataflow:>stream create something --definition "http | transform --expression=\"'hello world'\" | log" (2)
| 1 | In the first line, single quotes surround the string (at the Data Flow parser level), but they need to be doubled because they are inside a string literal (started by the first single quote after the equals sign). |
| 2 | The second and third lines use single and double quotes, respectively, to encompass the whole string at the Data Flow parser level. Consequently, the other kind of quote can be used inside the string. The whole thing is inside the --definition argument to the shell, though, which uses double quotes. Consequently, double quotes are escaped (at the shell level). |
Streams
This section goes into more detail about how you can create Streams, which are collections of Spring Cloud Stream applications. It covers topics such as creating and deploying Streams.
If you are just starting out with Spring Cloud Data Flow, you should probably read the Getting Started guide before diving into this section.
17. Introduction
A Stream is a collection of long-lived Spring Cloud Stream applications that communicate with each other over messaging middleware. A text-based DSL defines the configuration and data flow between the applications. While many applications are provided for you to implement common use-cases, you typically create a custom Spring Cloud Stream application to implement custom business logic.
The general lifecycle of a Stream is:
-
Register applications.
-
Create a Stream Definition.
-
Deploy the Stream.
-
Undeploy or destroy the Stream.
-
Upgrade or roll back applications in the Stream.
For deploying Streams, the Data Flow Server has to be configured to delegate the deployment to a new server in the Spring Cloud ecosystem named Skipper.
Furthermore, you can configure Skipper to deploy applications to one or more Cloud Foundry orgs and spaces, one or more namespaces on a Kubernetes cluster, or to the local machine. When deploying a stream in Data Flow, you can specify which platform to use at deployment time. Skipper also provides Data Flow with the ability to perform updates to deployed streams. There are many ways the applications in a stream can be updated, but one of the most common examples is to upgrade a processor application with new custom business logic while leaving the existing source and sink applications alone.
17.1. Stream Pipeline DSL
A stream is defined by using a Unix-inspired Pipeline syntax.
The syntax uses vertical bars, known as “pipes”, to connect multiple commands.
The command ls -l | grep key | less in Unix takes the output of the ls -l process and pipes it to the input of the grep key process.
The output of grep is, in turn, sent to the input of the less process.
Each | symbol connects the standard output of the command on the left to the standard input of the command on the right.
Data flows through the pipeline from left to right.
In Data Flow, the Unix command is replaced by a Spring Cloud Stream application and each pipe symbol represents connecting the input and output of applications over messaging middleware, such as RabbitMQ or Apache Kafka.
Each Spring Cloud Stream application is registered under a simple name. The registration process specifies where the application can be obtained (for example, in a Maven Repository or a Docker registry). In Data Flow, we classify the Spring Cloud Stream applications as Sources, Processors, or Sinks.
As a simple example, consider the collection of data from an HTTP Source and writing to a File Sink. Using the DSL, the stream description is:
http | file
A stream that involves some processing would be expressed as:
http | filter | transform | file
Stream definitions can be created by using the shell’s stream create command, as shown in the following example:
dataflow:> stream create --name httpIngest --definition "http | file"
The Stream DSL is passed in to the --definition command option.
The deployment of stream definitions is done through the Shell’s stream deploy command, as follows:
dataflow:> stream deploy --name ticktock
The Getting Started section shows you how to start the server and how to start and use the Spring Cloud Data Flow shell.
Note that the shell calls the Data Flow Server’s REST API. For more information on making HTTP requests directly to the server, see the REST API Guide.
When naming a stream definition, keep in mind that each application in the stream will be created on the platform with the name in the format of <stream name>-<app name>. Thus, the total length of the generated application name can’t exceed 58 characters.
|
17.2. Stream Application DSL
You can use the Stream Application DSL to define custom binding properties for each of the Spring Cloud Stream applications. See the Stream Application DSL section of the microsite for more information.
17.3. Application Properties
Each application takes properties to customize its behavior. As an example, the http source module exposes a port setting that lets the data ingestion port be changed from the default value:
dataflow:> stream create --definition "http --port=8090 | log" --name myhttpstreamThis port property is actually the same as the standard Spring Boot server.port property.
Data Flow adds the ability to use the shorthand form port instead of server.port.
You can also specify the longhand version:
dataflow:> stream create --definition "http --server.port=8000 | log" --name myhttpstreamThis shorthand behavior is discussed more in the section on Stream Application Properties.
If you have registered application property metadata, you can use tab completion in the shell after typing -- to get a list of candidate property names.
The shell provides tab completion for application properties. The app info --name <appName> --type <appType> shell command provides additional documentation for all the supported properties.
Supported Stream <appType> possibilities are: source, processor, and sink.
|
18. Stream Lifecycle
The lifecycle of a stream goes through the following stages:
-
Register stream definition
-
Create stream using definition
-
Deploy stream
-
Destroy or undeploy stream
-
Upgrade or rollback apps in the stream
Skipper is a server that lets you discover Spring Boot applications and manage their lifecycle on multiple cloud platforms.
Applications in Skipper are bundled as packages that contain the application’s resource location, application properties, and deployment properties.
You can think of Skipper packages as being analogous to packages found in tools such as apt-get or brew.
When Data Flow deploys a Stream, it generates and upload a package to Skipper that represents the applications in the Stream. Subsequent commands to upgrade or roll back the applications within the Stream are passed through to Skipper. In addition, the Stream definition is reverse-engineered from the package, and the status of the Stream is also delegated to Skipper.
18.1. Register a Stream Application
You can register a versioned stream application by using the app register command. You must provide a unique name, an application type, and a URI that can be resolved to the application artifact.
For the type, specify source, processor, or sink. The version is resolved from the URI. Here are a few examples:
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.1
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.2
dataflow:>app register --name mysource --type source --uri maven://com.example:mysource:0.0.3
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │> mysource-0.0.1 <│ │ │ ║
║ │mysource-0.0.2 │ │ │ ║
║ │mysource-0.0.3 │ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝
dataflow:>app register --name myprocessor --type processor --uri file:///Users/example/myprocessor-1.2.3.jar
dataflow:>app register --name mysink --type sink --uri https://example.com/mysink-2.0.1.jarThe application URI should conform to one the following schema formats:
-
Maven schema:
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version> -
HTTP schema:
http://<web-path>/<artifactName>-<version>.jar -
File schema:
file:///<local-path>/<artifactName>-<version>.jar -
Docker schema:
docker:<docker-image-path>/<imageName>:<version>
The URI <version> part is compulsory for versioned stream applications.
Skipper uses the multi-versioned stream applications to allow upgrading or rolling back those applications at runtime by using the deployment properties.
|
If you would like to register the snapshot versions of the http and log
applications built with the RabbitMQ binder, you could do the following:
dataflow:>app register --name http --type source --uri maven://org.springframework.cloud.stream.app:http-source-rabbit:3.2.1
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:3.2.1If you would like to register multiple applications at one time, you can store them in a properties file, where the keys are formatted as <type>.<name> and the values are the URIs.
For example, to register the snapshot versions of the http and log applications built with the RabbitMQ binder, you could have the following in a properties file (for example, stream-apps.properties):
source.http=maven://org.springframework.cloud.stream.app:http-source-rabbit:3.2.1
sink.log=maven://org.springframework.cloud.stream.app:log-sink-rabbit:3.2.1Then, to import the applications in bulk, use the app import command and provide the location of the properties file with the --uri switch, as follows:
dataflow:>app import --uri file:///<YOUR_FILE_LOCATION>/stream-apps.propertiesRegistering an application by using --type app is the same as registering a source, processor or sink.
Applications of the type app can be used only in the Stream Application DSL (which uses double pipes || instead of single pipes | in the DSL) and instructs Data Flow not to configure the Spring Cloud Stream binding properties of the application.
The application that is registered using --type app does not have to be a Spring Cloud Stream application. It can be any Spring Boot application.
See the Stream Application DSL introduction for more about using this application type.
You can register multiple versions of the same applications (for example, the same name and type), but you can set only one as the default. The default version is used for deploying Streams.
The first time an application is registered, it is marked as default. The default application version can be altered with the app default command:
dataflow:>app default --id source:mysource --version 0.0.2
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │mysource-0.0.1 │ │ │ ║
║ │> mysource-0.0.2 <│ │ │ ║
║ │mysource-0.0.3 │ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝The app list --id <type:name> command lists all versions for a given stream application.
The app unregister command has an optional --version parameter to specify the application version to unregister:
dataflow:>app unregister --name mysource --type source --version 0.0.1
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │> mysource-0.0.2 <│ │ │ ║
║ │mysource-0.0.3 │ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝If --version is not specified, the default version is unregistered.
|
All applications in a stream should have a default version set for the stream to be deployed.
Otherwise, they are treated as unregistered application during the deployment.
Use the |
app default --id source:mysource --version 0.0.3
dataflow:>app list --id source:mysource
╔═══╤══════════════════╤═════════╤════╤════╗
║app│ source │processor│sink│task║
╠═══╪══════════════════╪═════════╪════╪════╣
║ │mysource-0.0.2 │ │ │ ║
║ │> mysource-0.0.3 <│ │ │ ║
╚═══╧══════════════════╧═════════╧════╧════╝The stream deploy necessitates default application versions being set.
The stream update and stream rollback commands, though, can use all (default and non-default) registered application versions.
The following command creates a stream that uses the default mysource version (0.0.3):
dataflow:>stream create foo --definition "mysource | log"Then we can update the version to 0.0.2:
dataflow:>stream update foo --properties version.mysource=0.0.2
Only pre-registered applications can be used to deploy, update, or rollback a Stream.
|
An attempt to update the mysource to version 0.0.1 (not registered) fails.
18.1.1. Register Out-of-the-Box Applications and Tasks
For convenience, we have the static files with application-URIs (for both Maven and Docker) available for all the out-of-the-box stream and task applications. You can point to this file and import all the application-URIs in bulk. Otherwise, as explained previously, you can register them individually or have your own custom property file with only the required application-URIs in it. We recommend, however, having a “focused” list of desired application-URIs in a custom property file.
Out-of-the-Box Stream Applications
The following table includes the dataflow.spring.io links to the stream applications based on Spring Cloud Stream 3.2.x and Spring Boot 2.7.x.
| Artifact Type | Stable Release | SNAPSHOT Release |
|---|---|---|
RabbitMQ + Maven |
||
RabbitMQ + Docker |
||
Apache Kafka + Maven |
||
Apache Kafka + Docker |
By default, the out-of-the-box app’s actuator endpoints are secured. You can disable security by deploying streams by setting the following property: app.*.spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.security.servlet.SecurityAutoConfiguration
|
On Kubernetes, see the Liveness and readiness probes section for how to configure security for actuator endpoints.
Out-of-the-Box Task Applications
The following table includes the dataflow.spring.io links to the task applications based on Spring Cloud Task 2.4.x and Spring Boot 2.7.x.
| Artifact Type | Stable Release | SNAPSHOT Release |
|---|---|---|
Maven |
||
Docker |
For more information about the available out-of-the-box stream applications see the Spring Cloud Stream Applications project page.
For more information about the available out-of-the-box task applications see timestamp-task and timestamp-batch docs.
As an example, if you would like to register all out-of-the-box stream applications built with the Kafka binder in bulk, you can use the following command:
$ dataflow:>app import --uri https://dataflow.spring.io/kafka-maven-latestAlternatively, you can register all the stream applications with the Rabbit binder, as follows:
$ dataflow:>app import --uri https://dataflow.spring.io/rabbitmq-maven-latestYou can also pass the --local option (which is true by default) to indicate whether the
properties file location should be resolved within the shell process itself. If the location should
be resolved from the Data Flow Server process, specify --local false.
|
When you use either Note, however, that, once downloaded, applications may be cached locally on the Data Flow server, based on the resource
location. If the resource location does not change (even though the actual resource bytes may be different), it
is not re-downloaded. When using Moreover, if a stream is already deployed and uses some version of a registered app, then (forcibly) re-registering a different application has no effect until the stream is deployed again. |
| In some cases, the resource is resolved on the server side. In others, the URI is passed to a runtime container instance, where it is resolved. See the specific documentation of each Data Flow Server for more detail. |
18.1.2. Register Custom Applications
While Data Flow includes source, processor, sink applications, you can extend these applications or write a custom Spring Cloud Stream application. You can follow the Stream Development guide on the Microsite to create your own custom application. Once you have created a custom application, you can register it, as described in Register a Stream Application.
18.2. Creating a Stream
The Spring Cloud Data Flow Server exposes a full RESTful API for managing the lifecycle of stream definitions, but the easiest way to use is it is through the Spring Cloud Data Flow shell. The Getting Started section describes how to start the shell.
New streams are created with the help of stream definitions. The definitions are built from a simple DSL. For example, consider what happens if we run the following shell command:
dataflow:> stream create --definition "time | log" --name ticktockThis defines a stream named ticktock that is based off of the DSL expression time | log. The DSL uses the “pipe” symbol (|), to connect a source to a sink.
The stream info command shows useful information about the stream, as shown (with its output) in the following example:
dataflow:>stream info ticktock
╔═══════════╤═════════════════╤═══════════╤══════════╗
║Stream Name│Stream Definition│Description│ Status ║
╠═══════════╪═════════════════╪═══════════╪══════════╣
║ticktock │time | log │ │undeployed║
╚═══════════╧═════════════════╧═══════════╧══════════╝18.2.1. Stream Application Properties
Application properties are the properties associated with each application in the stream. When the application is deployed, the application properties are applied to the application through command-line arguments or environment variables, depending on the underlying deployment implementation.
The following stream can have application properties defined at the time of stream creation:
dataflow:> stream create --definition "time | log" --name ticktockThe app info --name <appName> --type <appType> shell command displays the exposed application properties for the application.
For more about exposed properties, see Application Metadata.
The following listing shows the exposed properties for the time application:
dataflow:> app info --name time --type source
Information about source application 'time':
Version: '3.2.1':
Default application version: 'true':
Resource URI: maven://org.springframework.cloud.stream.app:time-source-rabbit:3.2.1
╔══════════════════════════════╤══════════════════════════════╤══════════════════════════════╤══════════════════════════════╗
║ Option Name │ Description │ Default │ Type ║
╠══════════════════════════════╪══════════════════════════════╪══════════════════════════════╪══════════════════════════════╣
║spring.integration.poller.max-│Maximum number of messages to │<none> │java.lang.Integer ║
║messages-per-poll │poll per polling cycle. │ │ ║
║spring.integration.poller.fixe│Polling rate period. Mutually │<none> │java.time.Duration ║
║d-rate │exclusive with 'fixedDelay' │ │ ║
║ │and 'cron'. │ │ ║
║spring.integration.poller.fixe│Polling delay period. Mutually│<none> │java.time.Duration ║
║d-delay │exclusive with 'cron' and │ │ ║
║ │'fixedRate'. │ │ ║
║spring.integration.poller.rece│How long to wait for messages │1s │java.time.Duration ║
║ive-timeout │on poll. │ │ ║
║spring.integration.poller.cron│Cron expression for polling. │<none> │java.lang.String ║
║ │Mutually exclusive with │ │ ║
║ │'fixedDelay' and 'fixedRate'. │ │ ║
║spring.integration.poller.init│Polling initial delay. Applied│<none> │java.time.Duration ║
║ial-delay │for 'fixedDelay' and │ │ ║
║ │'fixedRate'; ignored for │ │ ║
║ │'cron'. │ │ ║
║time.date-format │Format for the date value. │MM/dd/yy HH:mm:ss │java.lang.String ║
╚══════════════════════════════╧══════════════════════════════╧══════════════════════════════╧══════════════════════════════╝The following listing shows the exposed properties for the log application:
dataflow:> app info --name log --type sink
Information about sink application 'log':
Version: '3.2.1':
Default application version: 'true':
Resource URI: maven://org.springframework.cloud.stream.app:log-sink-rabbit:3.2.1
╔══════════════════════════════╤══════════════════════════════╤══════════════════════════════╤══════════════════════════════╗
║ Option Name │ Description │ Default │ Type ║
╠══════════════════════════════╪══════════════════════════════╪══════════════════════════════╪══════════════════════════════╣
║log.name │The name of the logger to use.│<none> │java.lang.String ║
║log.level │The level at which to log │<none> │org.springframework.integratio║
║ │messages. │ │n.handler.LoggingHandler$Level║
║log.expression │A SpEL expression (against the│payload │java.lang.String ║
║ │incoming message) to evaluate │ │ ║
║ │as the logged message. │ │ ║
╚══════════════════════════════╧══════════════════════════════╧══════════════════════════════╧══════════════════════════════╝You can specify the application properties for the time and log apps at the time of stream creation, as follows:
dataflow:> stream create --definition "time --fixed-delay=5 | log --level=WARN" --name ticktockNote that, in the preceding example, the fixed-delay and level properties defined for the time and log applications are the “short-form” property names provided by the shell completion.
These “short-form” property names are applicable only for the exposed properties. In all other cases, you should use only fully qualified property names.
18.2.2. Common Application Properties
In addition to configuration through DSL, Spring Cloud Data Flow provides a mechanism for setting common properties to all
the streaming applications that are launched by it.
This can be done by adding properties prefixed with spring.cloud.dataflow.applicationProperties.stream when starting
the server.
When doing so, the server passes all the properties, without the prefix, to the instances it launches.
For example, all the launched applications can be configured to use a specific Kafka broker by launching the Data Flow server with the following options:
--spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.brokers=192.168.1.100:9092
--spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.zkNodes=192.168.1.100:2181Doing so causes the spring.cloud.stream.kafka.binder.brokers and spring.cloud.stream.kafka.binder.zkNodes properties
to be passed to all the launched applications.
Properties configured with this mechanism have lower precedence than stream deployment properties.
They are overridden if a property with the same key is specified at stream deployment time (for example,
app.http.spring.cloud.stream.kafka.binder.brokers overrides the common property).
|
18.3. Deploying a Stream
This section describes how to deploy a Stream when the Spring Cloud Data Flow server is responsible for deploying the stream. It covers the deployment and upgrade of Streams by using the Skipper service. The description of how to set deployment properties applies to both approaches of Stream deployment.
Consider the ticktock stream definition:
dataflow:> stream create --definition "time | log" --name ticktockTo deploy the stream, use the following shell command:
dataflow:> stream deploy --name ticktockThe Data Flow Server delegates to Skipper the resolution and deployment of the time and log applications.
The stream info command shows useful information about the stream, including the deployment properties:
dataflow:>stream info --name ticktock
╔═══════════╤═════════════════╤═════════╗
║Stream Name│Stream Definition│ Status ║
╠═══════════╪═════════════════╪═════════╣
║ticktock │time | log │deploying║
╚═══════════╧═════════════════╧═════════╝
Stream Deployment properties: {
"log" : {
"resource" : "maven://org.springframework.cloud.stream.app:log-sink-rabbit",
"spring.cloud.deployer.group" : "ticktock",
"version" : "2.0.1.RELEASE"
},
"time" : {
"resource" : "maven://org.springframework.cloud.stream.app:time-source-rabbit",
"spring.cloud.deployer.group" : "ticktock",
"version" : "2.0.1.RELEASE"
}
}There is an important optional command argument (called --platformName) to the stream deploy command.
Skipper can be configured to deploy to multiple platforms.
Skipper is pre-configured with a platform named default, which deploys applications to the local machine where Skipper is running.
The default value of the --platformName command line argument is default.
If you commonly deploy to one platform, when installing Skipper, you can override the configuration of the default platform.
Otherwise, specify the platformName to be one of the values returned by the stream platform-list command.
In the preceding example, the time source sends the current time as a message each second, and the log sink outputs it by using the logging framework.
You can tail the stdout log (which has an <instance> suffix). The log files are located within the directory displayed in the Data Flow Server’s log output, as shown in the following listing:
$ tail -f /var/folders/wn/8jxm_tbd1vj28c8vj37n900m0000gn/T/spring-cloud-dataflow-912434582726479179/ticktock-1464788481708/ticktock.log/stdout_0.log
2016-06-01 09:45:11.250 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:11
2016-06-01 09:45:12.250 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:12
2016-06-01 09:45:13.251 INFO 79194 --- [ kafka-binder-] log.sink : 06/01/16 09:45:13You can also create and deploy the stream in one step by passing the --deploy flag when creating the stream, as follows:
dataflow:> stream create --definition "time | log" --name ticktock --deployHowever, it is not common in real-world use cases to create and deploy the stream in one step.
The reason is that when you use the stream deploy command, you can pass in properties that define how to map the applications onto the platform (for example, what is the memory size of the container to use, the number of each application to run, and whether to enable data partitioning features).
Properties can also override application properties that were set when creating the stream.
The next sections cover this feature in detail.
18.3.1. Deployment Properties
When deploying a stream, you can specify properties that can control how applications are deployed and configured. See the Deployment Properties section of the microsite for more information.
18.4. Destroying a Stream
You can delete a stream by issuing the stream destroy command from the shell, as follows:
dataflow:> stream destroy --name ticktockIf the stream was deployed, it is undeployed before the stream definition is deleted.
18.5. Undeploying a Stream
Often, you want to stop a stream but retain the name and definition for future use. In that case, you can undeploy the stream by name:
dataflow:> stream undeploy --name ticktock
dataflow:> stream deploy --name ticktockYou can issue the deploy command at a later time to restart it:
dataflow:> stream deploy --name ticktock18.6. Validating a Stream
Sometimes, an application contained within a stream definition contains an invalid URI in its registration.
This can caused by an invalid URI being entered at application registration time or by the application being removed from the repository from which it was to be drawn.
To verify that all the applications contained in a stream are resolve-able, a user can use the validate command:
dataflow:>stream validate ticktock
╔═══════════╤═════════════════╗
║Stream Name│Stream Definition║
╠═══════════╪═════════════════╣
║ticktock │time | log ║
╚═══════════╧═════════════════╝
ticktock is a valid stream.
╔═══════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════╪═════════════════╣
║source:time│valid ║
║sink:log │valid ║
╚═══════════╧═════════════════╝In the preceding example, the user validated their ticktock stream. Both the source:time and sink:log are valid.
Now we can see what happens if we have a stream definition with a registered application with an invalid URI:
dataflow:>stream validate bad-ticktock
╔════════════╤═════════════════╗
║Stream Name │Stream Definition║
╠════════════╪═════════════════╣
║bad-ticktock│bad-time | log ║
╚════════════╧═════════════════╝
bad-ticktock is an invalid stream.
╔═══════════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════════╪═════════════════╣
║source:bad-time│invalid ║
║sink:log │valid ║
╚═══════════════╧═════════════════╝In this case, Spring Cloud Data Flow states that the stream is invalid because source:bad-time has an invalid URI.
18.7. Updating a Stream
To update the stream, use the stream update command, which takes either --properties or --propertiesFile as a command argument.
Skipper has an important new top-level prefix: version.
The following commands deploy http | log stream (and the version of log which registered at the time of deployment was 3.2.0):
dataflow:> stream create --name httptest --definition "http --server.port=9000 | log"
dataflow:> stream deploy --name httptest
dataflow:>stream info httptest
╔══════════════════════════════╤══════════════════════════════╤════════════════════════════╗
║ Name │ DSL │ Status ║
╠══════════════════════════════╪══════════════════════════════╪════════════════════════════╣
║httptest │http --server.port=9000 | log │deploying ║
╚══════════════════════════════╧══════════════════════════════╧════════════════════════════╝
Stream Deployment properties: {
"log" : {
"spring.cloud.deployer.indexed" : "true",
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:log-sink-rabbit" : "3.2.0"
},
"http" : {
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:http-source-rabbit" : "3.2.0"
}
}Then the following command updates the stream to use the 3.2.1 version of the log application.
Before updating the stream with the specific version of the application, we need to make sure that the application is registered with that version:
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:3.2.1
Successfully registered application 'sink:log'Then we can update the application:
dataflow:>stream update --name httptest --properties version.log=3.2.1
You can use only pre-registered application versions to deploy, update, or rollback a stream.
|
To verify the deployment properties and the updated version, we can use stream info, as shown (with its output) in the following example:
dataflow:>stream info httptest
╔══════════════════════════════╤══════════════════════════════╤════════════════════════════╗
║ Name │ DSL │ Status ║
╠══════════════════════════════╪══════════════════════════════╪════════════════════════════╣
║httptest │http --server.port=9000 | log │deploying ║
╚══════════════════════════════╧══════════════════════════════╧════════════════════════════╝
Stream Deployment properties: {
"log" : {
"spring.cloud.deployer.indexed" : "true",
"spring.cloud.deployer.count" : "1",
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:log-sink-rabbit" : "3.2.1"
},
"http" : {
"spring.cloud.deployer.group" : "httptest",
"maven://org.springframework.cloud.stream.app:http-source-rabbit" : "3.2.1"
}
}18.8. Forcing an Update of a Stream
When upgrading a stream, you can use the --force option to deploy new instances of currently deployed applications even if no application or deployment properties have changed.
This behavior is needed for when configuration information is obtained by the application itself at startup time — for example, from Spring Cloud Config Server.
You can specify the applications for which to force an upgrade by using the --app-names option.
If you do not specify any application names, all the applications are forced to upgrade.
You can specify the --force and --app-names options together with the --properties or --propertiesFile options.
18.9. Stream Versions
Skipper keeps a history of the streams that were deployed.
After updating a Stream, there is a second version of the stream.
You can query for the history of the versions by using the stream history --name <name-of-stream> command:
dataflow:>stream history --name httptest
╔═══════╤════════════════════════════╤════════╤════════════╤═══════════════╤════════════════╗
║Version│ Last updated │ Status │Package Name│Package Version│ Description ║
╠═══════╪════════════════════════════╪════════╪════════════╪═══════════════╪════════════════╣
║2 │Mon Nov 27 22:41:16 EST 2017│DEPLOYED│httptest │1.0.0 │Upgrade complete║
║1 │Mon Nov 27 22:40:41 EST 2017│DELETED │httptest │1.0.0 │Delete complete ║
╚═══════╧════════════════════════════╧════════╧════════════╧═══════════════╧════════════════╝18.10. Stream Manifests
Skipper keeps a “manifest” of the all of the applications, their application properties, and their deployment properties after all values have been substituted. This represents the final state of what was deployed to the platform. You can view the manifest for any of the versions of a Stream by using the following command:
stream manifest --name <name-of-stream> --releaseVersion <optional-version>If the --releaseVersion is not specified, the manifest for the last version is returned.
The following example shows the use of the manifest:
dataflow:>stream manifest --name httptestUsing the command results in the following output:
# Source: log.yml
apiVersion: skipper.spring.io/v1
kind: SpringCloudDeployerApplication
metadata:
name: log
spec:
resource: maven://org.springframework.cloud.stream.app:log-sink-rabbit
version: 3.2.0
applicationProperties:
spring.cloud.dataflow.stream.app.label: log
spring.cloud.stream.bindings.input.group: httptest
spring.cloud.dataflow.stream.name: httptest
spring.cloud.dataflow.stream.app.type: sink
spring.cloud.stream.bindings.input.destination: httptest.http
deploymentProperties:
spring.cloud.deployer.indexed: true
spring.cloud.deployer.group: httptest
spring.cloud.deployer.count: 1
---
# Source: http.yml
apiVersion: skipper.spring.io/v1
kind: SpringCloudDeployerApplication
metadata:
name: http
spec:
resource: maven://org.springframework.cloud.stream.app:http-source-rabbit
version: 3.2.0
applicationProperties:
spring.cloud.dataflow.stream.app.label: http
spring.cloud.stream.bindings.output.producer.requiredGroups: httptest
server.port: 9000
spring.cloud.stream.bindings.output.destination: httptest.http
spring.cloud.dataflow.stream.name: httptest
spring.cloud.dataflow.stream.app.type: source
deploymentProperties:
spring.cloud.deployer.group: httptestThe majority of the deployment and application properties were set by Data Flow to enable the applications to talk to each other and to send application metrics with identifying labels.
18.11. Rollback a Stream
You can roll back to a previous version of the stream by using the stream rollback command:
dataflow:>stream rollback --name httptestThe optional --releaseVersion command argument adds the version of the stream.
If not specified, the rollback operation goes to the previous stream version.
18.12. Application Count
The application count is a dynamic property of the system used to specify the number of instances of applications. See the Application Count section of the microsite for more information.
18.13. Skipper’s Upgrade Strategy
Skipper has a simple “red/black” upgrade strategy. It deploys the new version of the applications, using as many instances as the currently running version, and checks the /health endpoint of the application.
If the health of the new application is good, the previous application is undeployed.
If the health of the new application is bad, all new applications are undeployed, and the upgrade is considered to be not successful.
The upgrade strategy is not a rolling upgrade, so, if five instances of the application are running, then, in a sunny-day scenario, five of the new applications are also running before the older version is undeployed.
19. Stream DSL
This section covers additional features of the Stream DSL not covered in the Stream DSL introduction.
19.1. Tap a Stream
Taps can be created at various producer endpoints in a stream. See the Tapping a Stream section of the microsite for more information.
19.2. Using Labels in a Stream
When a stream is made up of multiple applications with the same name, they must be qualified with labels. See the Labeling Applications section of the microsite for more information.
19.3. Named Destinations
Instead of referencing a source or sink application, you can use a named destination. See the Named Destinations section of the microsite for more information.
19.4. Fan-in and Fan-out
By using named destinations, you can support fan-in and fan-out use cases. See the Fan-in and Fan-out section of the microsite for more information.
20. Stream Java DSL
Instead of using the shell to create and deploy streams, you can use the Java-based DSL provided by the spring-cloud-dataflow-rest-client module.
See the Java DSL section of the microsite for more information.
21. Stream Applications with Multiple Binder Configurations
In some cases, a stream can have its applications bound to multiple spring cloud stream binders when they are required to connect to different messaging middleware configurations. In those cases, you should make sure the applications are configured appropriately with their binder configurations. For example, a multi-binder transformer that supports both Kafka and Rabbit binders is the processor in the following stream:
http | multibindertransform --expression=payload.toUpperCase() | log
In the preceding example, you would write your own multibindertransform application.
|
In this stream, each application connects to messaging middleware in the following way:
-
The HTTP source sends events to RabbitMQ (
rabbit1). -
The Multi-Binder Transform processor receives events from RabbitMQ (
rabbit1) and sends the processed events into Kafka (kafka1). -
The log sink receives events from Kafka (
kafka1).
Here, rabbit1 and kafka1 are the binder names given in the Spring Cloud Stream application properties.
Based on this setup, the applications have the following binders in their classpaths with the appropriate configuration:
-
HTTP: Rabbit binder
-
Transform: Both Kafka and Rabbit binders
-
Log: Kafka binder
The spring-cloud-stream binder configuration properties can be set within the applications themselves.
If not, they can be passed through deployment properties when the stream is deployed:
dataflow:>stream create --definition "http | multibindertransform --expression=payload.toUpperCase() | log" --name mystream
dataflow:>stream deploy mystream --properties "app.http.spring.cloud.stream.bindings.output.binder=rabbit1,app.multibindertransform.spring.cloud.stream.bindings.input.binder=rabbit1,
app.multibindertransform.spring.cloud.stream.bindings.output.binder=kafka1,app.log.spring.cloud.stream.bindings.input.binder=kafka1"You can override any of the binder configuration properties by specifying them through deployment properties.
22. Function Composition
Function composition lets you attach a functional logic dynamically to an existing event streaming application. See the Function Composition section of the microsite for more details.
23. Functional Applications
With Spring Cloud Stream 3.x adding functional support, you can build Source, Sink and Processor applications merely by implementing the Java Util’s Supplier, Consumer, and Function interfaces respectively.
See the Functional Application Recipe of the SCDF site for more about this feature.
24. Examples
This chapter includes the following examples:
24.1. Simple Stream Processing
As an example of a simple processing step, we can transform the payload of the HTTP-posted data to upper case by using the following stream definition:
http | transform --expression=payload.toUpperCase() | logTo create this stream, enter the following command in the shell:
dataflow:> stream create --definition "http --server.port=9000 | transform --expression=payload.toUpperCase() | log" --name mystream --deployThe following example uses a shell command to post some data:
dataflow:> http post --target http://localhost:9000 --data "hello"The preceding example results in an upper-case HELLO in the log, as follows:
2016-06-01 09:54:37.749 INFO 80083 --- [ kafka-binder-] log.sink : HELLO24.2. Stateful Stream Processing
To demonstrate the data partitioning functionality, the following listing deploys a stream with Kafka as the binder:
dataflow:>stream create --name words --definition "http --server.port=9900 | splitter --expression=payload.split(' ') | log"
Created new stream 'words'
dataflow:>stream deploy words --properties "app.splitter.producer.partitionKeyExpression=payload,deployer.log.count=2"
Deployed stream 'words'
dataflow:>http post --target http://localhost:9900 --data "How much wood would a woodchuck chuck if a woodchuck could chuck wood"
> POST (text/plain;Charset=UTF-8) http://localhost:9900 How much wood would a woodchuck chuck if a woodchuck could chuck wood
> 202 ACCEPTED
dataflow:>runtime apps
╔════════════════════╤═══════════╤═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╗
║App Id / Instance Id│Unit Status│ No. of Instances / Attributes ║
╠════════════════════╪═══════════╪═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╣
║words.log-v1 │ deployed │ 2 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 24166 ║
║ │ │ pid = 33097 ║
║ │ │ port = 24166 ║
║words.log-v1-0 │ deployed │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1/stderr_0.log ║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1/stdout_0.log ║
║ │ │ url = https://192.168.0.102:24166 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 41269 ║
║ │ │ pid = 33098 ║
║ │ │ port = 41269 ║
║words.log-v1-1 │ deployed │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1/stderr_1.log ║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1/stdout_1.log ║
║ │ │ url = https://192.168.0.102:41269 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461063/words.log-v1 ║
╟────────────────────┼───────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╢
║words.http-v1 │ deployed │ 1 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 9900 ║
║ │ │ pid = 33094 ║
║ │ │ port = 9900 ║
║words.http-v1-0 │ deployed │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461054/words.http-v1/stderr_0.log ║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461054/words.http-v1/stdout_0.log ║
║ │ │ url = https://192.168.0.102:9900 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803461054/words.http-v1 ║
╟────────────────────┼───────────┼───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╢
║words.splitter-v1 │ deployed │ 1 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 33963 ║
║ │ │ pid = 33093 ║
║ │ │ port = 33963 ║
║words.splitter-v1-0 │ deployed │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803437542/words.splitter-v1/stderr_0.log║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803437542/words.splitter-v1/stdout_0.log║
║ │ │ url = https://192.168.0.102:33963 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/words-1542803437542/words.splitter-v1 ║
╚════════════════════╧═══════════╧═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╝When you review the words.log-v1-0 logs, you should see the following:
2016-06-05 18:35:47.047 INFO 58638 --- [ kafka-binder-] log.sink : How
2016-06-05 18:35:47.066 INFO 58638 --- [ kafka-binder-] log.sink : chuck
2016-06-05 18:35:47.066 INFO 58638 --- [ kafka-binder-] log.sink : chuckWhen you review the words.log-v1-1 logs, you should see the following:
2016-06-05 18:35:47.047 INFO 58639 --- [ kafka-binder-] log.sink : much
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : wood
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : would
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : a
2016-06-05 18:35:47.066 INFO 58639 --- [ kafka-binder-] log.sink : woodchuck
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : if
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : a
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : woodchuck
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : could
2016-06-05 18:35:47.067 INFO 58639 --- [ kafka-binder-] log.sink : woodThis example has shown that payload splits that contain the same word are routed to the same application instance.
24.3. Other Source and Sink Application Types
This example shows something a bit more complicated: swapping out the time source for something else. Another supported source type is http, which accepts data for ingestion over HTTP POST requests. Note that the http source accepts data on a different port from the Data Flow Server (default 8080). By default, the port is randomly assigned.
To create a stream that uses an http source but still uses the same log sink, we would change the original command in the Simple Stream Processing example to the following:
dataflow:> stream create --definition "http | log" --name myhttpstream --deployNote that, this time, we do not see any other output until we actually post some data (by using a shell command). To see the randomly assigned port on which the http source is listening, run the following command:
dataflow:>runtime apps
╔══════════════════════╤═══════════╤═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╗
║ App Id / Instance Id │Unit Status│ No. of Instances / Attributes ║
╠══════════════════════╪═══════════╪═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╣
║myhttpstream.log-v1 │ deploying │ 1 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 39628 ║
║ │ │ pid = 34403 ║
║ │ │ port = 39628 ║
║myhttpstream.log-v1-0 │ deploying │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803867070/myhttpstream.log-v1/stderr_0.log ║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803867070/myhttpstream.log-v1/stdout_0.log ║
║ │ │ url = https://192.168.0.102:39628 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803867070/myhttpstream.log-v1 ║
╟──────────────────────┼───────────┼─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╢
║myhttpstream.http-v1 │ deploying │ 1 ║
╟┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┼┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈┈╢
║ │ │ guid = 52143 ║
║ │ │ pid = 34401 ║
║ │ │ port = 52143 ║
║myhttpstream.http-v1-0│ deploying │ stderr = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803866800/myhttpstream.http-v1/stderr_0.log║
║ │ │ stdout = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803866800/myhttpstream.http-v1/stdout_0.log║
║ │ │ url = https://192.168.0.102:52143 ║
║ │ │working.dir = /var/folders/js/7b_pn0t575l790x7j61slyxc0000gn/T/spring-cloud-deployer-6467595568759190742/myhttpstream-1542803866800/myhttpstream.http-v1 ║
╚══════════════════════╧═══════════╧═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╝You should see that the corresponding http source has a url property that contains the host and port information on which it is listening. You are now ready to post to that url, as shown in the following example:
dataflow:> http post --target http://localhost:1234 --data "hello"
dataflow:> http post --target http://localhost:1234 --data "goodbye"The stream then funnels the data from the http source to the output log implemented by the log sink, yielding output similar to the following:
2016-06-01 09:50:22.121 INFO 79654 --- [ kafka-binder-] log.sink : hello
2016-06-01 09:50:26.810 INFO 79654 --- [ kafka-binder-] log.sink : goodbyeWe could also change the sink implementation. You could pipe the output to a file (file), to hadoop (hdfs), or to any of the other sink applications that are available. You can also define your own applications.
Stream Developer Guide
Stream Monitoring
Tasks
This section goes into more detail about how you can orchestrate Spring Cloud Task applications on Spring Cloud Data Flow.
If you are just starting out with Spring Cloud Data Flow, you should probably read the Getting Started guide for “Local” , “Cloud Foundry”, or “Kubernetes” before diving into this section.
25. Introduction
A task application is short-lived, meaning that it stops running on purpose and can be run on demand or scheduled for later. One use case might be to scrape a web page and write to the database.
The Spring Cloud Task framework is based on Spring Boot and adds the ability for Boot applications to record the lifecycle events of a short-lived application, such as when it starts, when it ends, and the exit status.
The TaskExecution documentation shows which information is stored in the database.
The entry point for code execution in a Spring Cloud Task application is most often an implementation of Boot’s CommandLineRunner interface, as shown in this example.
The Spring Batch project is probably what comes to mind for Spring developers writing short-lived applications.
Spring Batch provides a much richer set of functionality than Spring Cloud Task and is recommended when processing large volumes of data.
One use case might be to read many CSV files, transform each row of data, and write each transformed row to a database.
Spring Batch provides its own database schema with a much more rich set of information about the execution of a Spring Batch job.
Spring Cloud Task is integrated with Spring Batch so that, if a Spring Cloud Task application defines a Spring Batch Job, a link between the Spring Cloud Task and Spring Cloud Batch execution tables is created.
When running Data Flow on your local machine, Tasks are launched in a separate JVM.
When running on Cloud Foundry, tasks are launched by using Cloud Foundry’s Task functionality. When running on Kubernetes, tasks are launched by using either a Pod or a Job resource.
26. The Lifecycle of a Task
Before you dive deeper into the details of creating Tasks, you should understand the typical lifecycle for tasks in the context of Spring Cloud Data Flow:
26.1. Creating a Task Application
Spring Cloud Dataflow provides a couple of out-of-the-box task applications (timestamp-task and timestamp-batch) but most task applications require custom development.
To create a custom task application:
-
Use the Spring Initializer to create a new project, making sure to select the following starters:
-
Cloud Task: This dependency is thespring-cloud-starter-task. -
JDBC: This dependency is thespring-jdbcstarter. -
Select your database dependency: Enter the database dependency that Data Flow is currently using. For example:
H2.
-
-
Within your new project, create a new class to serve as your main class, as follows:
@EnableTask @SpringBootApplication public class MyTask { public static void main(String[] args) { SpringApplication.run(MyTask.class, args); } } -
With this class, you need one or more
CommandLineRunnerorApplicationRunnerimplementations within your application. You can either implement your own or use the ones provided by Spring Boot (there is one for running batch jobs, for example). -
Packaging your application with Spring Boot into an über jar is done through the standard Spring Boot conventions. The packaged application can be registered and deployed as noted below.
26.1.1. Task Database Configuration
| When launching a task application, be sure that the database driver that is being used by Spring Cloud Data Flow is also a dependency on the task application. For example, if your Spring Cloud Data Flow is set to use Postgresql, be sure that the task application also has Postgresql as a dependency. |
| When you run tasks externally (that is, from the command line) and you want Spring Cloud Data Flow to show the TaskExecutions in its UI, be sure that common datasource settings are shared among them both. By default, Spring Cloud Task uses a local H2 instance, and the execution is recorded to the database used by Spring Cloud Data Flow. |
26.2. Registering a Task Application
You can register a Task application with the App Registry by using the Spring Cloud Data Flow Shell app register command.
You must provide a unique name and a URI that can be resolved to the application artifact. For the type, specify task.
The following listing shows three examples:
dataflow:>app register --name task1 --type task --uri maven://com.example:mytask:1.0.2
dataflow:>app register --name task2 --type task --uri file:///Users/example/mytask-1.0.2.jar
dataflow:>app register --name task3 --type task --uri https://example.com/mytask-1.0.2.jarWhen providing a URI with the maven scheme, the format should conform to the following:
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>If you would like to register multiple applications at one time, you can store them in a properties file where the keys are formatted as <type>.<name> and the values are the URIs.
For example, the following listing would be a valid properties file:
task.cat=file:///tmp/cat-1.2.1.BUILD-SNAPSHOT.jar
task.hat=file:///tmp/hat-1.2.1.BUILD-SNAPSHOT.jarThen you can use the app import command and provide the location of the properties file by using the --uri option, as follows:
app import --uri file:///tmp/task-apps.propertiesFor example, if you would like to register all the task applications that ship with Data Flow in a single operation, you can do so with the following command:
dataflow:>app import --uri https://dataflow.spring.io/task-maven-latestYou can also pass the --local option (which is TRUE by default) to indicate whether the properties file location should be resolved within the shell process itself.
If the location should be resolved from the Data Flow Server process, specify --local false.
When using either app register or app import, if a task application is already registered with
the provided name and version, it is not overridden by default. If you would like to override the
pre-existing task application with a different uri or uri-metadata location, include the --force option.
| In some cases, the resource is resolved on the server side. In other cases, the URI is passed to a runtime container instance, where it is resolved. Consult the specific documentation of each Data Flow Server for more detail. |
26.3. Creating a Task Definition
You can create a task definition from a task application by providing a definition name as well as
properties that apply to the task execution. You can create a task definition through
the RESTful API or the shell. To create a task definition by using the shell, use the
task create command to create the task definition, as shown in the following example:
dataflow:>task create mytask --definition "timestamp --format=\"yyyy\""
Created new task 'mytask'You can obtain a listing of the current task definitions through the RESTful API or the shell.
To get the task definition list by using the shell, use the task list command.
26.3.1. Maximum Task Definition Name Length
The maximum character length of a task definition name is dependent on the platform.
| Consult the platform documents for specifics on resource naming. The Local platform stores the task definition name in a database column with a maximum size of 255. |
| Kubernetes Bare Pods | Kubernetes Jobs | Cloud Foundry | Local |
|---|---|---|---|
63 |
52 |
63 |
255 |
26.3.2. Automating the Creation of Task Definitions
As of version 2.3.0, you can configure the Data Flow server to automatically create task definitions by setting spring.cloud.dataflow.task.autocreate-task-definitions to true.
This is not the default behavior but is provided as a convenience.
When this property is enabled, a task launch request can specify the registered task application name as the task name.
If the task application is registered, the server creates a basic task definition that specifies only the application name, as required. This eliminates a manual step similar to:
dataflow:>task create mytask --definition "mytask"You can still specify command-line arguments and deployment properties for each task launch request.
26.4. Launching a Task
An ad hoc task can be launched through the RESTful API or the shell.
To launch an ad hoc task through the shell, use the task launch command, as shown in the following example:
dataflow:>task launch mytask
Launched task 'mytask'When a task is launched, you can set any properties that need to be passed as command-line arguments to the task application when you launch the task, as follows:
dataflow:>task launch mytask --arguments "--server.port=8080 --custom=value"| The arguments need to be passed as space-delimited values. |
You can pass in additional properties meant for a TaskLauncher itself by using the --properties option.
The format of this option is a comma-separated string of properties prefixed with app.<task definition name>.<property>.
Properties are passed to TaskLauncher as application properties.
It is up to an implementation to choose how those are passed into an actual task application.
If the property is prefixed with deployer instead of app, it is passed to TaskLauncher as a deployment property, and its meaning may be TaskLauncher implementation specific.
dataflow:>task launch mytask --properties "deployer.timestamp.custom1=value1,app.timestamp.custom2=value2"26.4.1. Application properties
Each application takes properties to customize its behavior. For example, the timestamp task format setting establishes an output format that is different from the default value.
dataflow:> task create --definition "timestamp --format=\"yyyy\"" --name printTimeStampThis timestamp property is actually the same as the timestamp.format property specified by the timestamp application.
Data Flow adds the ability to use the shorthand form format instead of timestamp.format.
You can also specify the longhand version as well, as shown in the following example:
dataflow:> task create --definition "timestamp --timestamp.format=\"yyyy\"" --name printTimeStampThis shorthand behavior is discussed more in the section on Stream Application Properties.
If you have registered application property metadata, you can use tab completion in the shell after typing -- to get a list of candidate property names.
The shell provides tab completion for application properties. The app info --name <appName> --type <appType> shell command provides additional documentation for all the supported properties. The supported task <appType> is task.
When restarting Spring Batch Jobs on Kubernetes, you must use the entry point of shell or boot.
|
Application Properties With Sensitive Information on Kubernetes
When launching task applications where some of the properties may contain sensitive information, use the shell or boot as the entryPointStyle. This is because the exec (default) converts all properties to command-line arguments and, as a result, may not be secure in some environments.
26.4.2. Common application properties
In addition to configuration through DSL, Spring Cloud Data Flow provides a mechanism for setting properties that are common to all the task applications that are launched by it.
You can do so by adding properties prefixed with spring.cloud.dataflow.applicationProperties.task when starting the server.
The server then passes all the properties, without the prefix, to the instances it launches.
For example, you can configure all the launched applications to use the prop1 and prop2 properties by launching the Data Flow server with the following options:
--spring.cloud.dataflow.applicationProperties.task.prop1=value1
--spring.cloud.dataflow.applicationProperties.task.prop2=value2This causes the prop1=value1 and prop2=value2 properties to be passed to all the launched applications.
Properties configured by using this mechanism have lower precedence than task deployment properties.
They are overridden if a property with the same key is specified at task launch time (for example, app.trigger.prop2
overrides the common property).
|
26.4.3. Launching tasks with a specific application version
When launching a task you can specify the specific version of the application.
If no version is specified Spring Cloud Data Flow will use the default version of the application.
To specify a version of the application to be used at launch time use the deployer property version.<app-name>.
For example:
task launch my-task --properties 'version.timestamp=3.0.0'Similarly, when scheduling a task you will use the same format of version.<app-name>. For example:
task schedule create --name my-schedule --definitionName my-task --expression '*/1 * * * *' --properties 'version.timestamp=3.0.0'26.5. Limit the number concurrent task launches
Spring Cloud Data Flow lets a user limit the maximum number of concurrently running tasks for each configured platform to prevent the saturation of IaaS or hardware resources.
By default, the limit is set to 20 for all supported platforms. If the number of concurrently running tasks on a platform instance is greater than or equal to the limit, the next task launch request fails, and an error message is returned through the RESTful API, the Shell, or the UI.
You can configure this limit for a platform instance by setting the corresponding deployer property, spring.cloud.dataflow.task.platform.<platform-type>.accounts[<account-name>].maximumConcurrentTasks, where <account-name> is the name of a configured platform account (default if no accounts are explicitly configured).
The <platform-type> refers to one of the currently supported deployers: local or kubernetes. For cloudfoundry, the property is spring.cloud.dataflow.task.platform.<platform-type>.accounts[<account-name>].deployment.maximumConcurrentTasks. (The difference is that deployment has been added to the path).
The TaskLauncher implementation for each supported platform determines the number of currently running tasks by querying the underlying platform’s runtime state, if possible. The method for identifying a task varies by platform.
For example, launching a task on the local host uses the LocalTaskLauncher. LocalTaskLauncher runs a process for each launch request and keeps track of these processes in memory. In this case, we do not query the underlying OS, as it is impractical to identify tasks this way.
For Cloud Foundry, tasks are a core concept supported by its deployment model. The state of all tasks ) is available directly through the API.
This means that every running task container in the account’s organization and space is included in the running execution count, whether or not it was launched by using Spring Cloud Data Flow or by invoking the CloudFoundryTaskLauncher directly.
For Kubernetes, launching a task through the KubernetesTaskLauncher, if successful, results in a running pod, which we expect to eventually complete or fail.
In this environment, there is generally no easy way to identify pods that correspond to a task.
For this reason, we count only pods that were launched by the KubernetesTaskLauncher.
Since the task launcher provides task-name label in the pod’s metadata, we filter all running pods by the presence of this label.
26.6. Reviewing Task Executions
Once the task is launched, the state of the task is stored in a relational database. The state includes:
-
Task Name
-
Start Time
-
End Time
-
Exit Code
-
Exit Message
-
Last Updated Time
-
Parameters
You can check the status of your task executions through the RESTful API or the shell.
To display the latest task executions through the shell, use the task execution list command.
To get a list of task executions for just one task definition, add --name and
the task definition name — for example, task execution list --name foo. To retrieve full
details for a task execution, use the task execution status command with the ID of the task execution,
for example task execution status --id 549.
26.7. Destroying a Task Definition
Destroying a task definition removes the definition from the definition repository.
This can be done through the RESTful API or the shell.
To destroy a task through the shell, use the task destroy command, as shown in the following example:
dataflow:>task destroy mytask
Destroyed task 'mytask'The task destroy command also has an option to cleanup the task executions of the task being destroyed, as shown in the following example:
dataflow:>task destroy mytask --cleanup
Destroyed task 'mytask'By default, the cleanup option is set to false (that is, by default, the task executions are not cleaned up when the task is destroyed).
To destroy all tasks through the shell, use the task all destroy command as shown in the following example:
dataflow:>task all destroy
Really destroy all tasks? [y, n]: y
All tasks destroyedIf need be, you can use the force switch:
dataflow:>task all destroy --force
All tasks destroyedThe task execution information for previously launched tasks for the definition remains in the task repository.
| This does not stop any currently running tasks for this definition. Instead, it removes the task definition from the database. |
|
+
. Obtain a list of the apps by using the |
26.8. Validating a Task
Sometimes, an application contained within a task definition has an invalid URI in its registration.
This can be caused by an invalid URI being entered at application-registration time or the by the application being removed from the repository from which it was to be drawn.
To verify that all the applications contained in a task are resolve-able, use the validate command, as follows:
dataflow:>task validate time-stamp
╔══════════╤═══════════════╗
║Task Name │Task Definition║
╠══════════╪═══════════════╣
║time-stamp│timestamp ║
╚══════════╧═══════════════╝
time-stamp is a valid task.
╔═══════════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════════╪═════════════════╣
║task:timestamp │valid ║
╚═══════════════╧═════════════════╝In the preceding example, the user validated their time-stamp task. The task:timestamp application is valid.
Now we can see what happens if we have a stream definition with a registered application that has an invalid URI:
dataflow:>task validate bad-timestamp
╔═════════════╤═══════════════╗
║ Task Name │Task Definition║
╠═════════════╪═══════════════╣
║bad-timestamp│badtimestamp ║
╚═════════════╧═══════════════╝
bad-timestamp is an invalid task.
╔══════════════════╤═════════════════╗
║ App Name │Validation Status║
╠══════════════════╪═════════════════╣
║task:badtimestamp │invalid ║
╚══════════════════╧═════════════════╝In this case, Spring Cloud Data Flow states that the task is invalid because task:badtimestamp has an invalid URI.
26.9. Stopping a Task Execution
In some cases, a task that is running on a platform may not stop because of a problem on the platform or the application business logic itself.
For such cases, Spring Cloud Data Flow offers the ability to send a request to the platform to end the task.
To do this, submit a task execution stop for a given set of task executions, as follows:
task execution stop --ids 5
Request to stop the task execution with id(s): 5 has been submittedWith the preceding command, the trigger to stop the execution of id=5 is submitted to the underlying deployer implementation. As a result, the operation stops that task. When we view the result for the task execution, we see that the task execution completed with a 0 exit code:
dataflow:>task execution list
╔══════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗
║Task Name │ID│ Start Time │ End Time │Exit Code║
╠══════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣
║batch-demo│5 │Mon Jul 15 13:58:41 EDT 2019│Mon Jul 15 13:58:55 EDT 2019│0 ║
║timestamp │1 │Mon Jul 15 09:26:41 EDT 2019│Mon Jul 15 09:26:41 EDT 2019│0 ║
╚══════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝If you submit a stop for a task execution that has child task executions associated with it, such as a composed task, a stop request is sent for each of the child task executions.
When stopping a task execution that has a running Spring Batch job, the job is left with a batch status of STARTED.
Each of the supported platforms sends a SIG-INT to the task application when a stop is requested. That allows Spring Cloud Task to capture the state of the app. However, Spring Batch does not handle a SIG-INT and, as a result, the job stops but remains in the STARTED status.
|
| When launching Remote Partitioned Spring Batch Task applications, Spring Cloud Data Flow supports stopping a worker partition task directly for both Cloud Foundry and Kubernetes platforms. Stopping worker partition task is not supported for the local platform. |
26.9.1. Stopping a Task Execution that was Started Outside of Spring Cloud Data Flow
You may wish to stop a task that has been launched outside of Spring Cloud Data Flow. An example of this is the worker applications launched by a remote batch partitioned application.
In such cases, the remote batch partitioned application stores the external-execution-id for each of the worker applications. However, no platform information is stored.
So when Spring Cloud Data Flow has to stop a remote batch partitioned application and its worker applications, you need to specify the platform name, as follows:
dataflow:>task execution stop --ids 1 --platform myplatform
Request to stop the task execution with id(s): 1 for platform myplatform has been submitted27. Subscribing to Task and Batch Events
You can also tap into various task and batch events when the task is launched.
If the task is enabled to generate task or batch events (with the additional dependencies of spring-cloud-task-stream and, in the case of Kafka as the binder, spring-cloud-stream-binder-kafka), those events are published during the task lifecycle.
By default, the destination names for those published events on the broker (Rabbit, Kafka, and others) are the event names themselves (for instance: task-events, job-execution-events, and so on).
dataflow:>task create myTask --definition "myBatchJob"
dataflow:>stream create task-event-subscriber1 --definition ":task-events > log" --deploy
dataflow:>task launch myTaskYou can control the destination name for those events by specifying explicit names when launching the task, as follows:
dataflow:>stream create task-event-subscriber2 --definition ":myTaskEvents > log" --deploy
dataflow:>task launch myTask --properties "app.myBatchJob.spring.cloud.stream.bindings.task-events.destination=myTaskEvents"The following table lists the default task and batch event and destination names on the broker:
Event |
Destination |
Task events |
|
Job Execution events |
|
Step Execution events |
|
Item Read events |
|
Item Process events |
|
Item Write events |
|
Skip events |
|
28. Composed Tasks
Spring Cloud Data Flow lets you create a directed graph, where each node of the graph is a task application. This is done by using the DSL for composed tasks. You can create a composed task through the RESTful API, the Spring Cloud Data Flow Shell, or the Spring Cloud Data Flow UI.
28.1. The Composed Task Runner
Composed tasks are run through a task application called the Composed Task Runner. The Spring Cloud Data Flow server automatically deploys the Composed Task Runner when launching a composed task.
28.1.1. Configuring the Composed Task Runner
The composed task runner application has a dataflow-server-uri property that is used for validation and for launching child tasks.
This defaults to localhost:9393. If you run a distributed Spring Cloud Data Flow server, as you would if you deploy the server on Cloud Foundry or Kubernetes, you need to provide the URI that can be used to access the server.
You can either provide this by setting the dataflow-server-uri property for the composed task runner application when launching a composed task or by setting the spring.cloud.dataflow.server.uri property for the Spring Cloud Data Flow server when it is started.
For the latter case, the dataflow-server-uri composed task runner application property is automatically set when a composed task is launched.
Configuration Options
The ComposedTaskRunner task has the following options:
-
composed-task-argumentsThe command line arguments to be used for each of the tasks. (String, default: <none>). -
increment-instance-enabledAllows a singleComposedTaskRunnerinstance to be run again without changing the parameters by adding a incremented number job parameter based onrun.idfrom the previous execution. (Boolean, default:true). ComposedTaskRunner is built by using Spring Batch. As a result, upon a successful execution, the batch job is considered to be complete. To launch the sameComposedTaskRunnerdefinition multiple times, you must set eitherincrement-instance-enabledoruuid-instance-enabledproperty totrueor change the parameters for the definition for each launch. When using this option, it must be applied for all task launches for the desired application, including the first launch. -
uuid-instance-enabledAllows a singleComposedTaskRunnerinstance to be run again without changing the parameters by adding a UUID to thectr.idjob parameter. (Boolean, default:false). ComposedTaskRunner is built by using Spring Batch. As a result, upon a successful execution, the batch job is considered to be complete. To launch the sameComposedTaskRunnerdefinition multiple times, you must set eitherincrement-instance-enabledoruuid-instance-enabledproperty totrueor change the parameters for the definition for each launch. When using this option, it must be applied for all task launches for the desired application, including the first launch. This option when set to true will override the value ofincrement-instance-id. Set this option totruewhen running multiple instances of the same composed task definition at the same time. -
interval-time-between-checksThe amount of time, in milliseconds, that theComposedTaskRunnerwaits between checks of the database to see if a task has completed. (Integer, default:10000).ComposedTaskRunneruses the datastore to determine the status of each child tasks. This interval indicates toComposedTaskRunnerhow often it should check the status its child tasks. -
transaction-isolation-levelEstablish the transaction isolation level for the Composed Task Runner. A list of available transaction isolation levels can be found here. Default isISOLATION_REPEATABLE_READ. -
max-start-wait-timeThe maximum amount of time, in milliseconds, that the Composed Task Runner will wait for thestart_timeof a stepstaskExecutionto be set before the execution of the Composed task is failed (Integer, default: 0). Determines the maximum time each child task is allowed for application startup. The default of0indicates no timeout. -
max-wait-timeThe maximum amount of time, in milliseconds, that an individual step can run before the execution of the Composed task is failed (Integer, default: 0). Determines the maximum time each child task is allowed to run before the CTR ends with a failure. The default of0indicates no timeout. -
split-thread-allow-core-thread-timeoutSpecifies whether to allow split core threads to timeout. (Boolean, default:false) Sets the policy governing whether core threads may timeout and terminate if no tasks arrive within the keep-alive time, being replaced if needed when new tasks arrive. -
split-thread-core-pool-sizeSplit’s core pool size. (Integer, default:1) Each child task contained in a split requires a thread in order to execute. So, for example, a definition such as<AAA || BBB || CCC> && <DDD || EEE>would require asplit-thread-core-pool-sizeof3. This is because the largest split contains three child tasks. A count of2would mean thatAAAandBBBwould run in parallel, but CCC would wait until eitherAAAorBBBfinish in order to run. ThenDDDandEEEwould run in parallel. -
split-thread-keep-alive-secondsSplit’s thread keep alive seconds. (Integer, default:60) If the pool currently has more thancorePoolSizethreads, excess threads are stopped if they have been idle for more than thekeepAliveTime. -
split-thread-max-pool-sizeSplit’s maximum pool size. (Integer, default:Integer.MAX_VALUE). Establish the maximum number of threads allowed for the thread pool. -
split-thread-queue-capacity Capacity for Split’s
BlockingQueue. (Integer, default:Integer.MAX_VALUE)-
If fewer than
corePoolSizethreads are running, theExecutoralways prefers adding a new thread rather than queuing. -
If
corePoolSizeor more threads are running, theExecutoralways prefers queuing a request rather than adding a new thread. -
If a request cannot be queued, a new thread is created unless this would exceed
maximumPoolSize. In that case, the task is rejected.
-
-
split-thread-wait-for-tasks-to-complete-on-shutdownWhether to wait for scheduled tasks to complete on shutdown, not interrupting running tasks and running all tasks in the queue. (Boolean, default:false) -
dataflow-server-uriThe URI for the Data Flow server that receives task launch requests. (String, default:localhost:9393) -
dataflow-server-usernameThe optional username for the Data Flow server that receives task launch requests. Used to access the the Data Flow server by using Basic Authentication. Not used ifdataflow-server-access-tokenis set. -
dataflow-server-passwordThe optional password for the Data Flow server that receives task launch requests. Used to access the the Data Flow server by using Basic Authentication. Not used ifdataflow-server-access-tokenis set. -
dataflow-server-access-tokenThis property sets an optional OAuth2 Access Token. Typically, the value is automatically set by using the token from the currently logged-in user, if available. However, for special use-cases, this value can also be set explicitly.
A special boolean property, dataflow-server-use-user-access-token, exists for when you want to use the access token of the currently logged-in user and propagate it to the Composed Task Runner. This property is used
by Spring Cloud Data Flow and, if set to true, auto-populates the dataflow-server-access-token property. When using dataflow-server-use-user-access-token, it must be passed for each task execution.
In some cases, it may be preferred that the user’s dataflow-server-access-token must be passed for each composed task launch by default.
In this case, set the Spring Cloud Data Flow spring.cloud.dataflow.task.useUserAccessToken property to true.
To set a property for Composed Task Runner you will need to prefix the property with app.composed-task-runner..
For example to set the dataflow-server-uri property the property will look like app.composed-task-runner.dataflow-server-uri.
28.2. The Lifecycle of a Composed Task
The lifecycle of a composed task has three parts:
28.2.1. Creating a Composed Task
The DSL for the composed tasks is used when creating a task definition through the task create command, as shown in the following example:
dataflow:> app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:
dataflow:> app register --name mytaskapp --type task --uri file:///home/tasks/mytask.jar
dataflow:> task create my-composed-task --definition "mytaskapp && timestamp"
dataflow:> task launch my-composed-task In the preceding example, we assume that the applications to be used by our composed task have not yet been registered.
Consequently, in the first two steps, we register two task applications.
We then create our composed task definition by using the task create command.
The composed task DSL in the preceding example, when launched, runs mytaskapp and then runs the timestamp application.
But before we launch the my-composed-task definition, we can view what Spring Cloud Data Flow generated for us.
This can be done by using the task list command, as shown (including its output) in the following example:
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│unknown ║
║my-composed-task-mytaskapp│mytaskapp │unknown ║
║my-composed-task-timestamp│timestamp │unknown ║
╚══════════════════════════╧══════════════════════╧═══════════╝In the example, Spring Cloud Data Flow created three task definitions, one for each of the applications that makes up our composed task (my-composed-task-mytaskapp and my-composed-task-timestamp) as well as the composed task (my-composed-task) definition.
We also see that each of the generated names for the child tasks is made up of the name of the composed task and the name of the application, separated by a hyphen - (as in my-composed-task - mytaskapp).
28.2.2. Launching a Composed Task
Launching a composed task is done in the same way as launching a stand-alone task, as follows:
task launch my-composed-taskOnce the task is launched, and assuming all the tasks complete successfully, you can see three task executions when you run a task execution list, as shown in the following example:
dataflow:>task execution list
╔══════════════════════════╤═══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID │ Start Time │ End Time │Exit Code║
╠══════════════════════════╪═══╪════════════════════════════╪════════════════════════════╪═════════╣
║my-composed-task-timestamp│713│Wed Apr 12 16:43:07 EDT 2017│Wed Apr 12 16:43:07 EDT 2017│0 ║
║my-composed-task-mytaskapp│712│Wed Apr 12 16:42:57 EDT 2017│Wed Apr 12 16:42:57 EDT 2017│0 ║
║my-composed-task │711│Wed Apr 12 16:42:55 EDT 2017│Wed Apr 12 16:43:15 EDT 2017│0 ║
╚══════════════════════════╧═══╧════════════════════════════╧════════════════════════════╧═════════╝In the preceding example, we see that my-compose-task launched and that the other tasks were also launched in sequential order.
Each of them ran successfully with an Exit Code as 0.
Passing Properties to the Child Tasks
To set the properties for child tasks in a composed task graph at task launch time,
use the following format: app.<child task app name>.<property>.
The following listing shows a composed task definition as an example:
dataflow:> task create my-composed-task --definition "mytaskapp && mytimestamp"To have mytaskapp display 'HELLO' and set the mytimestamp timestamp format to YYYY for the composed task definition, use the following task launch format:
task launch my-composed-task --properties "app.mytaskapp.displayMessage=HELLO,app.mytimestamp.timestamp.format=YYYY"Similar to application properties, you can also set the deployer properties for child tasks by using the following format: deployer.<child task app name>.<deployer-property>:
task launch my-composed-task --properties "deployer.mytaskapp.memory=2048m,app.mytimestamp.timestamp.format=HH:mm:ss"
Launched task 'a1'Passing Arguments to the Composed Task Runner
You can pass command-line arguments for the composed task runner by using the --arguments option:
dataflow:>task create my-composed-task --definition "<aaa: timestamp || bbb: timestamp>"
Created new task 'my-composed-task'
dataflow:>task launch my-composed-task --arguments "--increment-instance-enabled=true --max-wait-time=50000 --split-thread-core-pool-size=4" --properties "app.bbb.timestamp.format=dd/MM/yyyy HH:mm:ss"
Launched task 'my-composed-task'Exit Statuses
The following list shows how the exit status is set for each step (task) contained in the composed task following each step execution:
-
If the
TaskExecutionhas anExitMessage, that is used as theExitStatus. -
If no
ExitMessageis present and theExitCodeis set to zero, theExitStatusfor the step isCOMPLETED. -
If no
ExitMessageis present and theExitCodeis set to any non-zero number, theExitStatusfor the step isFAILED.
28.2.3. Destroying a Composed Task
The command used to destroy a stand-alone task is the same as the command used to destroy a composed task.
The only difference is that destroying a composed task also destroys the child tasks associated with it.
The following example shows the task list before and after using the destroy command:
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│COMPLETED ║
║my-composed-task-mytaskapp│mytaskapp │COMPLETED ║
║my-composed-task-timestamp│timestamp │COMPLETED ║
╚══════════════════════════╧══════════════════════╧═══════════╝
...
dataflow:>task destroy my-composed-task
dataflow:>task list
╔═════════╤═══════════════╤═══════════╗
║Task Name│Task Definition│Task Status║
╚═════════╧═══════════════╧═══════════╝28.2.4. Stopping a Composed Task
In cases where a composed task execution needs to be stopped, you can do so through the:
-
RESTful API
-
Spring Cloud Data Flow Dashboard
To stop a composed task through the dashboard, select the Jobs tab and click the *Stop() button next to the job execution that you want to stop.
The composed task run is stopped when the currently running child task completes.
The step associated with the child task that was running at the time that the composed task was stopped is marked as STOPPED as well as the composed task job execution.
28.2.5. Restarting a Composed Task
In cases where a composed task fails during execution and the status of the composed task is FAILED, the task can be restarted.
You can do so through the:
-
RESTful API
-
The shell
-
Spring Cloud Data Flow Dashboard
To restart a composed task through the shell, launch the task with the same parameters. To restart a composed task through the dashboard, select the Jobs tab and click the Restart button next to the job execution that you want to restart.
Restarting a composed task job that has been stopped (through the Spring Cloud Data Flow Dashboard or RESTful API) relaunches the STOPPED child task and then launches the remaining (unlaunched) child tasks in the specified order.
|
29. Composed Tasks DSL
Composed tasks can be run in three ways:
29.1. Conditional Execution
Conditional execution is expressed by using a double ampersand symbol (&&).
This lets each task in the sequence be launched only if the previous task
successfully completed, as shown in the following example:
task create my-composed-task --definition "task1 && task2"When the composed task called my-composed-task is launched, it launches the task called task1 and, if task1 completes successfully, the task called task2 is launched.
If task1 fails, task2 does not launch.
You can also use the Spring Cloud Data Flow Dashboard to create your conditional execution, by using the designer to drag and drop applications that are required and connecting them together to create your directed graph, as shown in the following image:
The preceding diagram is a screen capture of the directed graph as it being created by using the Spring Cloud Data Flow Dashboard. You can see that four components in the diagram comprise a conditional execution:
-
Start icon: All directed graphs start from this symbol. There is only one.
-
Task icon: Represents each task in the directed graph.
-
End icon: Represents the end of a directed graph.
-
Solid line arrow: Represents the flow conditional execution flow between:
-
Two applications.
-
The start control node and an application.
-
An application and the end control node.
-
-
End icon: All directed graphs end at this symbol.
| You can view a diagram of your directed graph by clicking the Detail button next to the composed task definition on the Definitions tab. |
29.2. Transitional Execution
The DSL supports fine-grained control over the transitions taken during the execution of the directed graph.
Transitions are specified by providing a condition for equality that is based on the exit status of the previous task.
A task transition is represented by the following symbol ->.
29.2.1. Basic Transition
A basic transition would look like the following:
task create my-transition-composed-task --definition "foo 'FAILED' -> bar 'COMPLETED' -> baz"In the preceding example, foo would launch, and, if it had an exit status of FAILED, the bar task would launch.
If the exit status of foo was COMPLETED, baz would launch.
All other statuses returned by cat have no effect, and the task would end normally.
Using the Spring Cloud Data Flow Dashboard to create the same “basic transition” would resemble the following image:
The preceding diagram is a screen capture of the directed graph as it being created in the Spring Cloud Data Flow Dashboard. Notice that there are two different types of connectors:
-
Dashed line: Represents transitions from the application to one of the possible destination applications.
-
Solid line: Connects applications in a conditional execution or a connection between the application and a control node (start or end).
To create a transitional connector:
-
When creating a transition, link the application to each possible destination by using the connector.
-
Once complete, go to each connection and select it by clicking it.
-
A bolt icon appears.
-
Click that icon.
-
Enter the exit status required for that connector.
-
The solid line for that connector turns to a dashed line.
29.2.2. Transition With a Wildcard
Wildcards are supported for transitions by the DSL, as shown in the following example:
task create my-transition-composed-task --definition "foo 'FAILED' -> bar '*' -> baz"In the preceding example, foo would launch, and, if it had an exit status of FAILED, bar task would launch.
For any exit status of cat other than FAILED, baz would launch.
Using the Spring Cloud Data Flow Dashboard to create the same “transition with wildcard” would resemble the following image:
29.2.3. Transition With a Following Conditional Execution
A transition can be followed by a conditional execution, so long as the wildcard is not used, as shown in the following example:
task create my-transition-conditional-execution-task --definition "foo 'FAILED' -> bar 'UNKNOWN' -> baz && qux && quux"In the preceding example, foo would launch, and, if it had an exit status of FAILED, the bar task would launch.
If foo had an exit status of UNKNOWN, baz would launch.
For any exit status of foo other than FAILED or UNKNOWN, qux would launch and, upon successful completion, quux would launch.
Using the Spring Cloud Data Flow Dashboard to create the same “transition with conditional execution” would resemble the following image:
In this diagram, the dashed line (transition) connects the foo application to the target applications, but a solid line connects the conditional executions between foo, qux, and quux.
|
29.2.4. Ignoring Exit Message
If any child task within a split returns an ExitMessage other than COMPLETED the split
will have an ExitStatus of FAILED. To ignore the ExitMessage of a child task,
add the ignoreExitMessage=true for each app that will return an ExitMessage
within the split. When using this flag, the ExitStatus of the task will be
COMPLETED if the ExitCode of the child task is zero. The split will have an
ExitStatus of FAILED if the ExitCode`s is non zero. There are 2 ways to
set the `ignoreExitMessage flag:
-
Setting the property for each of the apps that need to have their exitMessage ignored within the split. For example a split like
<AAA || BBB>whereBBBwill return anexitMessage, you would set theignoreExitMessageproperty likeapp.BBB.ignoreExitMessage=true -
You can also set it for all apps using the composed-task-arguments property, for example:
--composed-task-arguments=--ignoreExitMessage=true.
29.3. Split Execution
Splits let multiple tasks within a composed task be run in parallel.
It is denoted by using angle brackets (<>) to group tasks and flows that are to be run in parallel.
These tasks and flows are separated by the double pipe || symbol, as shown in the following example:
task create my-split-task --definition "<foo || bar || baz>"The preceding example launches tasks foo, bar and baz in parallel.
Using the Spring Cloud Data Flow Dashboard to create the same “split execution” would resemble the following image:
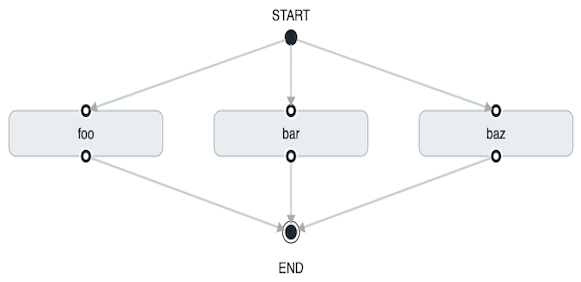
With the task DSL, you can also run multiple split groups in succession, as shown in the following example:
task create my-split-task --definition "<foo || bar || baz> && <qux || quux>"In the preceding example, the foo, bar, and baz tasks are launched in parallel.
Once they all complete, then the qux and quux tasks are launched in parallel.
Once they complete, the composed task ends.
However, if foo, bar, or baz fails, the split containing qux and quux does not launch.
Using the Spring Cloud Data Flow Dashboard to create the same “split with multiple groups” would resemble the following image:
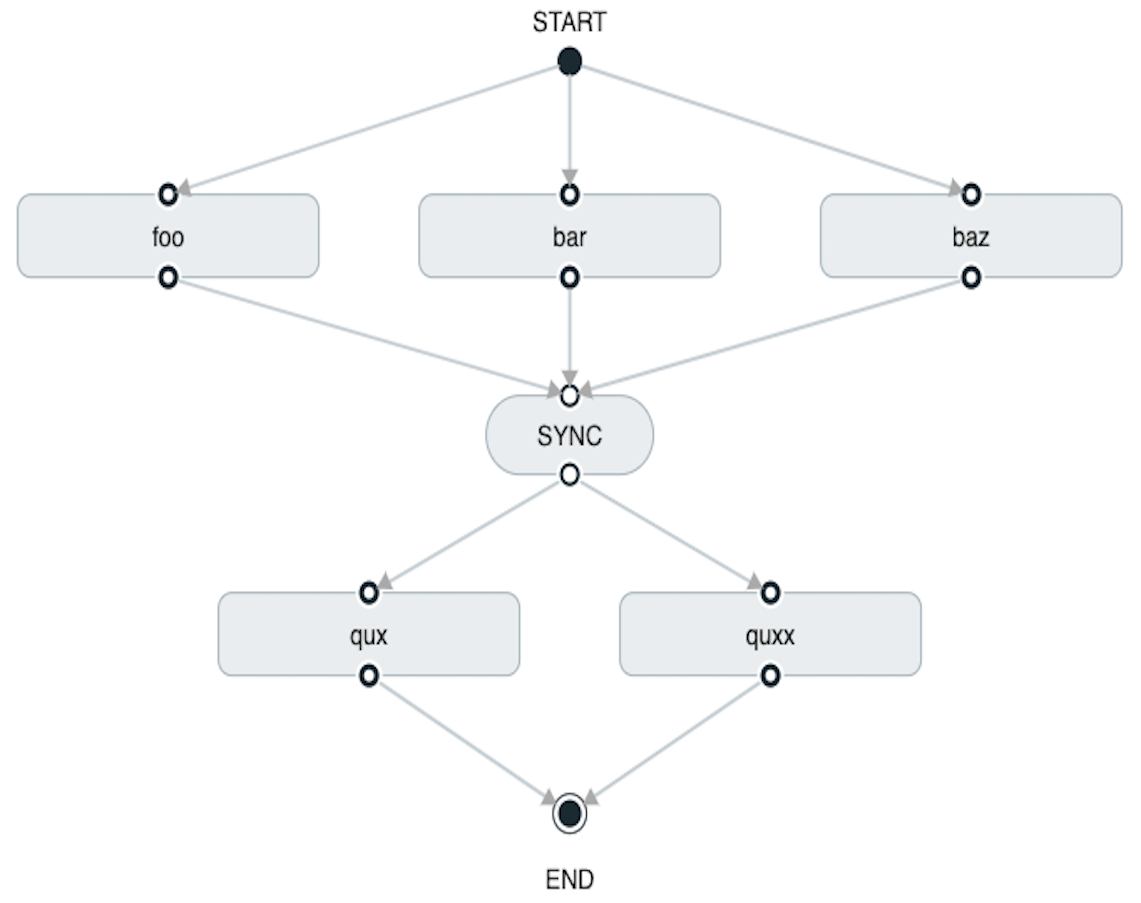
Notice that there is a SYNC control node that is inserted by the designer when
connecting two consecutive splits.
Tasks that are used in a split should not set the their ExitMessage. Setting the ExitMessage is only to be used
with transitions.
|
29.3.1. Split Containing Conditional Execution
A split can also have a conditional execution within the angle brackets, as shown in the following example:
task create my-split-task --definition "<foo && bar || baz>"In the preceding example, we see that foo and baz are launched in parallel.
However, bar does not launch until foo completes successfully.
Using the Spring Cloud Data Flow Dashboard to create the same " split containing conditional execution " resembles the following image:
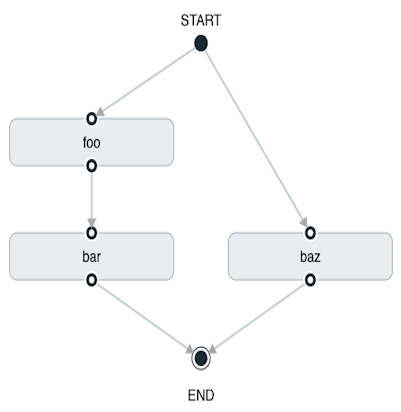
29.3.2. Establishing the Proper Thread Count for Splits
Each child task contained in a split requires a thread in order to run. To set this properly, you want to look at your graph and find the split that has the largest number of child tasks. The number of child tasks in that split is the number of threads you need.
To set the thread count, use the split-thread-core-pool-size property (defaults to 1). So, for example, a definition such as <AAA || BBB || CCC> && <DDD || EEE> requires a split-thread-core-pool-size of 3.
This is because the largest split contains three child tasks. A count of two would mean that AAA and BBB would run in parallel but CCC would wait for either AAA or BBB to finish in order to run.
Then DDD and EEE would run in parallel.
30. Launching Tasks from a Stream
You can launch a task from a stream by using the task-launcher-dataflow sink which is provided as a part of the Spring Cloud Data Flow project.
The sink connects to a Data Flow server and uses its REST API to launch any defined task.
The sink accepts a JSON payload representing a task launch request, which provides the name of the task to launch and may include command line arguments and deployment properties.
The task-launch-request-function component, in conjunction with Spring Cloud Stream functional composition, can transform the output of any source or processor to a task launch request.
Adding a dependency to task-launch-request-function auto-configures a java.util.function.Function implementation, registered through Spring Cloud Function as a taskLaunchRequest.
For example, you can start with the time source, add the following dependency, build it, and register it as a custom source.
<dependency>
<groupId>org.springframework.cloud.stream.app</groupId>
<artifactId>app-starters-task-launch-request-common</artifactId>
</dependency>To build the application follow the instructions here.
This will create an apps directory that contains time-source-rabbit and time-source-kafka directories in the <stream app project>/applications/source/time-source directory. In each of these you will see a target directory that contains a time-source-<binder>-<version>.jar. Now register the time-source jar (use the appropriate binder jar) with SCDF as a time source named timestamp-tlr.
Next, register the task-launcher-dataflow sink with SCDF and create a task definition timestamp-task. Once this is complete create the stream definition as shown below:
stream create --name task-every-minute --definition 'timestamp-tlr --fixed-delay=60000 --task.launch.request.task-name=timestamp-task --spring.cloud.function.definition=\"timeSupplier|taskLaunchRequestFunction\"| tasklauncher-sink' --deployThe preceding stream produces a task launch request every minute. The request provides the name of the task to launch: {"name":"timestamp-task"}.
The following stream definition illustrates the use of command line arguments. It produces messages such as {"args":["foo=bar","time=12/03/18 17:44:12"],"deploymentProps":{},"name":"timestamp-task"} to provide command-line arguments to the task:
stream create --name task-every-second --definition 'timestamp-tlr --task.launch.request.task-name=timestamp-task --spring.cloud.function.definition=\"timeSupplier|taskLaunchRequestFunction\" --task.launch.request.args=foo=bar --task.launch.request.arg-expressions=time=payload | tasklauncher-sink' --deployNote the use of SpEL expressions to map each message payload to the time command-line argument, along with a static argument (foo=bar).
You can then see the list of task executions by using the shell command task execution list, as shown (with its output) in the following example:
dataflow:>task execution list
╔══════════════╤═══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID │ Start Time │ End Time │Exit Code║
╠══════════════╪═══╪════════════════════════════╪════════════════════════════╪═════════╣
║timestamp-task│581│Thu Sep 08 11:38:33 EDT 2022│Thu Sep 08 11:38:33 EDT 2022│0 ║
║timestamp-task│580│Thu Sep 08 11:38:31 EDT 2022│Thu Sep 08 11:38:31 EDT 2022│0 ║
║timestamp-task│579│Thu Sep 08 11:38:29 EDT 2022│Thu Sep 08 11:38:29 EDT 2022│0 ║
║timestamp-task│578│Thu Sep 08 11:38:26 EDT 2022│Thu Sep 08 11:38:26 EDT 2022│0 ║
╚══════════════╧═══╧════════════════════════════╧════════════════════════════╧═════════╝In this example, we have shown how to use the time source to launch a task at a fixed rate.
This pattern may be applied to any source to launch a task in response to any event.
30.1. Launching a Composed Task From a Stream
A composed task can be launched with the task-launcher-dataflow sink, as discussed here.
Since we use the ComposedTaskRunner directly, we need to set up the task definitions for the composed task runner itself, along with the composed tasks, prior to the creation of the composed task launching stream.
Suppose we wanted to create the following composed task definition: AAA && BBB.
The first step would be to create the task definition, as shown in the following example:
task create --name composed-task-sample --definition "AAA: timestamp && BBB: timestamp"Now that the task definition we need for composed task definition is ready, we need to create a stream that launches composed-task-sample.
We create a stream with:
-
The
timestamp-tlrsource customized to emit task launch requests, as shown earlier. -
The
task-launchersink that launches thecomposed-task-sample
The stream should resemble the following:
stream create --name ctr-stream --definition "timestamp-tlr --fixed-delay=30000 --spring.cloud.function.definition=\"timeSupplier|taskLaunchRequestFunction\" --task.launch.request.task-name=composed-task-sample | tasklauncher-sink" --deploy31. Sharing Spring Cloud Data Flow’s Datastore with Tasks
As discussed in the Tasks documentation, Spring Cloud Data Flow lets you view Spring Cloud Task application executions. So, in this section, we discuss what is required for a task application and Spring Cloud Data Flow to share the task execution information.
31.1. A Common DataStore Dependency
Spring Cloud Data Flow supports many databases out-of-the-box,
so all you typically need to do is declare the spring_datasource_* environment variables
to establish what data store Spring Cloud Data Flow needs.
Regardless of which database you decide to use for Spring Cloud Data Flow, make sure that your task also
includes that database dependency in its pom.xml or gradle.build file. If the database dependency
that is used by Spring Cloud Data Flow is not present in the Task Application, the task fails
and the task execution is not recorded.
31.2. A Common Data Store
Spring Cloud Data Flow and your task application must access the same datastore instance. This is so that the task executions recorded by the task application can be read by Spring Cloud Data Flow to list them in the Shell and Dashboard views. Also, the task application must have read and write privileges to the task data tables that are used by Spring Cloud Data Flow.
Given this understanding of the datasource dependency between Task applications and Spring Cloud Data Flow, you can now review how to apply them in various Task orchestration scenarios.
31.2.1. Simple Task Launch
When launching a task from Spring Cloud Data Flow, Data Flow adds its datasource
properties (spring.datasource.url, spring.datasource.driverClassName, spring.datasource.username, spring.datasource.password)
to the application properties of the task being launched. Thus, a task application
records its task execution information to the Spring Cloud Data Flow repository.
31.2.2. Composed Task Runner
Spring Cloud Data Flow lets you create a directed graph where each node
of the graph is a task application. This is done through the
composed task runner.
In this case, the rules that applied to a simple task launch
or task launcher sink apply to the composed task runner as well.
All child applications must also have access to the datastore that is being used by the composed task runner.
Also, all child applications must have the same database dependency as the composed task runner enumerated in their pom.xml or gradle.build file.
31.2.3. Launching a Task Externally from Spring Cloud Data Flow
You can launch Spring Cloud Task applications by using another method (scheduler, for example) but still track the task execution in Spring Cloud Data Flow. You can do so, provided the task applications observe the rules specified here and here.
If you want to use Spring Cloud Data Flow to view your
Spring Batch jobs, make sure that
your batch application uses the @EnableTask annotation and follow the rules enumerated here and here.
More information is available here.
|
32. Scheduling Tasks
Spring Cloud Data Flow lets you schedule the execution of tasks with a cron expression.
You can create a schedule through the RESTful API or the Spring Cloud Data Flow UI.
32.1. The Scheduler
Spring Cloud Data Flow schedules the execution of its tasks through a scheduling agent that is available on the cloud platform. When using the Cloud Foundry platform, Spring Cloud Data Flow uses the PCF Scheduler. When using Kubernetes, a CronJob will be used.
| Scheduled tasks do not implement the continuous deployment feature. Any changes to application version or properties for a task definition in Spring Cloud Data Flow will not affect scheduled tasks. |

32.2. Enabling Scheduling
By default, Spring Cloud Data Flow leaves the scheduling feature disabled. To enable the scheduling feature, set the following feature properties to true:
-
spring.cloud.dataflow.features.schedules-enabled -
spring.cloud.dataflow.features.tasks-enabled
32.3. The Lifecycle of a Schedule
The lifecycle of a schedule has three parts:
32.3.1. Scheduling a Task Execution
You can schedule a task execution via the:
-
Spring Cloud Data Flow Shell
-
Spring Cloud Data Flow Dashboard
-
Spring Cloud Data Flow RESTful API
32.3.2. Scheduling a Task
To schedule a task using the shell, use the task schedule create command to create the schedule, as shown in the following example:
dataflow:>task schedule create --definitionName mytask --name mytaskschedule --expression '*/1 * * * *'
Created schedule 'mytaskschedule'In the earlier example, we created a schedule called mytaskschedule for the task definition called mytask. This schedule launches mytask once a minute.
If using Cloud Foundry, the cron expression above would be: */1 * ? * *. This is because Cloud Foundry uses the Quartz cron expression format.
|
32.3.3. Deleting a Schedule
You can delete a schedule by using the:
-
Spring Cloud Data Flow Shell
-
Spring Cloud Data Flow Dashboard
-
Spring Cloud Data Flow RESTful API
To delete a task schedule by using the shell, use the task schedule destroy command, as shown in the following example:
dataflow:>task schedule destroy --name mytaskschedule
Deleted task schedule 'mytaskschedule'32.3.4. Listing Schedules
You can view the available schedules by using the:
-
Spring Cloud Data Flow Shell
-
Spring Cloud Data Flow Dashboard
-
Spring Cloud Data Flow RESTful API
To view your schedules from the shell, use the task schedule list command, as shown in the following example:
dataflow:>task schedule list
╔══════════════════════════╤════════════════════╤════════════════════════════════════════════════════╗
║ Schedule Name │Task Definition Name│ Properties ║
╠══════════════════════════╪════════════════════╪════════════════════════════════════════════════════╣
║mytaskschedule │mytask │spring.cloud.scheduler.cron.expression = */1 * * * *║
╚══════════════════════════╧════════════════════╧════════════════════════════════════════════════════╝| Instructions to create, delete, and list schedules by using the Spring Cloud Data Flow UI can be found here. |
33. Continuous Deployment
As task applications evolve, you want to get your updates to production. This section walks through the capabilities that Spring Cloud Data Flow provides around being able to update task applications.
When a task application is registered (see Registering a Task Application), a version is associated with it. A task application can have multiple versions associated with it, with one selected as the default. The following image illustrates an application with multiple versions associated with it (see the timestamp entry).
Versions of an application are managed by registering multiple applications with the same name and coordinates, except the version. For example, if you were to register an application with the following values, you would get one application registered with two versions (2.1.0.RELEASE and 2.1.1.RELEASE):
-
Application 1
-
Name:
timestamp -
Type:
task -
URI:
maven://org.springframework.cloud.task.app:timestamp-task:2.1.0.RELEASE
-
-
Application 2
-
Name:
timestamp -
Type:
task -
URI:
maven://org.springframework.cloud.task.app:timestamp-task:2.1.1.RELEASE
-
Besides having multiple versions, Spring Cloud Data Flow needs to know which version to run on the next launch. This is indicated by setting a version to be the default version. Whatever version of a task application is configured as the default version is the one to be run on the next launch request. You can see which version is the default in the UI, as this image shows:
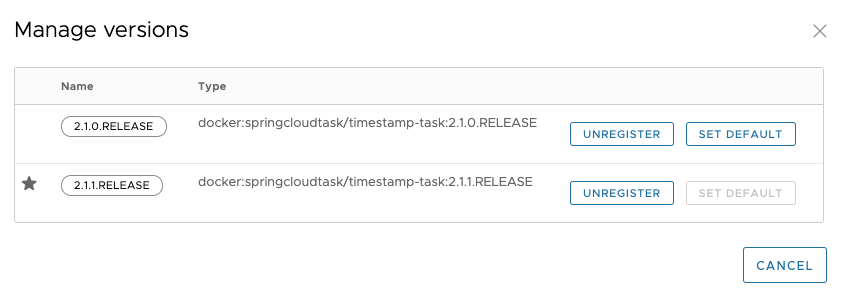
33.1. Task Launch Lifecycle
In previous versions of Spring Cloud Data Flow, when the request to launch a task was received, Spring Cloud Data Flow would deploy the application (if needed) and run it. If the application was being run on a platform that did not need to have the application deployed every time (CloudFoundry, for example), the previously deployed application was used. This flow has changed in 2.3. The following image shows what happens when a task launch request comes in now:
There are three main flows to consider in the preceding diagram. Launching the first time or launching with no changes is one. The other two are launching when there are changes but the appliction is not currently and launching when there are changes and the application is running. We look at the flow with no changes first.
33.1.1. Launching a Task With No Changes
-
A launch request comes into Data Flow. Data Flow determines that an upgrade is not required, since nothing has changed (no properties, deployment properties, or versions have changed since the last execution).
-
On platforms that cache a deployed artifact (CloudFoundry, at this writing), Data Flow checks whether the application was previously deployed.
-
If the application needs to be deployed, Data Flow deploys the task application.
-
Data Flow launches the application.
This flow is the default behavior and, if nothing has changed, occurs every time a request comes in. Note that this is the same flow that Data Flow has always use for launching tasks.
33.1.2. Launching a Task With Changes That Is Not Currently Running
The second flow to consider when launching a task is when a task is not running but there is a change in any of the task application version, application properties, or deployment properties. In this case, the following flow is executed:
-
A launch request comes into Data Flow. Data Flow determines that an upgrade is required, since there was a change in the task application version, the application properties, or the deployment properties.
-
Data Flow checks to see whether another instance of the task definition is currently running.
-
If there is no other instance of the task definition currently running, the old deployment is deleted.
-
On platforms that cache a deployed artifact (CloudFoundry, at this writing), Data Flow checks whether the application was previously deployed (this check evaluates to
falsein this flow, since the old deployment was deleted). -
Data Flow does the deployment of the task application with the updated values (new application version, new merged properties, and new merged deployment properties).
-
Data Flow launches the application.
This flow is what fundamentally enables continuous deployment for Spring Cloud Data Flow.
33.1.3. Launch a Task With Changes While Another Instance Is Running
The last main flow is when a launch request comes to Spring Cloud Data Flow to do an upgrade but the task definition is currently running. In this case, the launch is blocked due to the requirement to delete the current application. On some platforms (CloudFoundry, at this writing), deleting the application causes all currently running applications to be shut down. This feature prevents that from happening. The following process describes what happens when a task changes while another instance is running:
-
A launch request comes into Data Flow. Data Flow determines that an upgrade is required, since there was a change in the task application version, the application properties, or the deployment properties.
-
Data Flow checks to see whether another instance of the task definition is currently running.
-
Data Flow prevents the launch from happening, because other instances of the task definition are running.
| Any launch that requires an upgrade of a task definition that is running at the time of the request is blocked from running due to the need to delete any currently running tasks. |
Task Developer Guide
Task Monitoring
Dashboard
This section describes how to use the dashboard of Spring Cloud Data Flow.
34. Introduction
Spring Cloud Data Flow provides a browser-based GUI called the Dashboard to manage the following information:
-
Apps: The Apps tab lists all available applications and provides the controls to register and unregister them.
-
Runtime: The Runtime tab provides the list of all running applications.
-
Streams: The Streams tab lets you list, design, create, deploy, and destroy Stream Definitions.
-
Tasks: The Tasks tab lets you list, create, launch, schedule, and destroy Task Definitions.
-
Jobs: The Jobs tab lets you perform batch job related functions.
Upon starting Spring Cloud Data Flow, the dashboard is available at:
For example, if Spring Cloud Data Flow is running locally, the dashboard is available at localhost:9393/dashboard.
If you have enabled HTTPS, the dashboard is available at localhost:9393/dashboard.
If you have enabled security, a login form is available at localhost:9393/dashboard/#/login.
The default Dashboard server port is 9393.
|
The following image shows the opening page of the Spring Cloud Data Flow dashboard:

35. Apps
The Applications tab of the dashboard lists all the available applications and provides the controls to register and unregister them (if applicable). You can import a number of applications at once by using the Bulk Import Applications action.
The following image shows a typical list of available applications within the dashboard:
35.1. Bulk Import of Applications
Applications can be imported in numerous ways which are available on the "Applications" page. For bulk import, the application definitions are expected to be expressed in a properties style, as follows:
<type>.<name> = <coordinates>The following examples show typical application definitions:
task.timestamp=maven://org.springframework.cloud.task.app:timestamp-task:1.2.0.RELEASE
processor.transform=maven://org.springframework.cloud.stream.app:transform-processor-rabbit:1.2.0.RELEASEIn the "Import application coordinates from an HTTP URI location" section, you can specify a URI that points to a properties file stored elsewhere, it should contain properties formatted as shown in the previous example. Alternatively, by using the Apps as Properties textbox in the "Import application coordinates from a properties file" section , you can directly list each property string. Finally, if the properties are stored in a local file, the Import a File option opens a local file browser to select the file. After setting your definitions through one of these routes, click Import Application(s).
The following image shows an example page of one way to bulk import applications:
36. Runtime
The Runtime tab of the Dashboard application shows the list of all running applications. For each runtime applicaiton, the state of the deployment and the number of deployed instances is shown. A list of the used deployment properties is available by clicking on the application ID.
The following image shows an example of the Runtime tab in use:
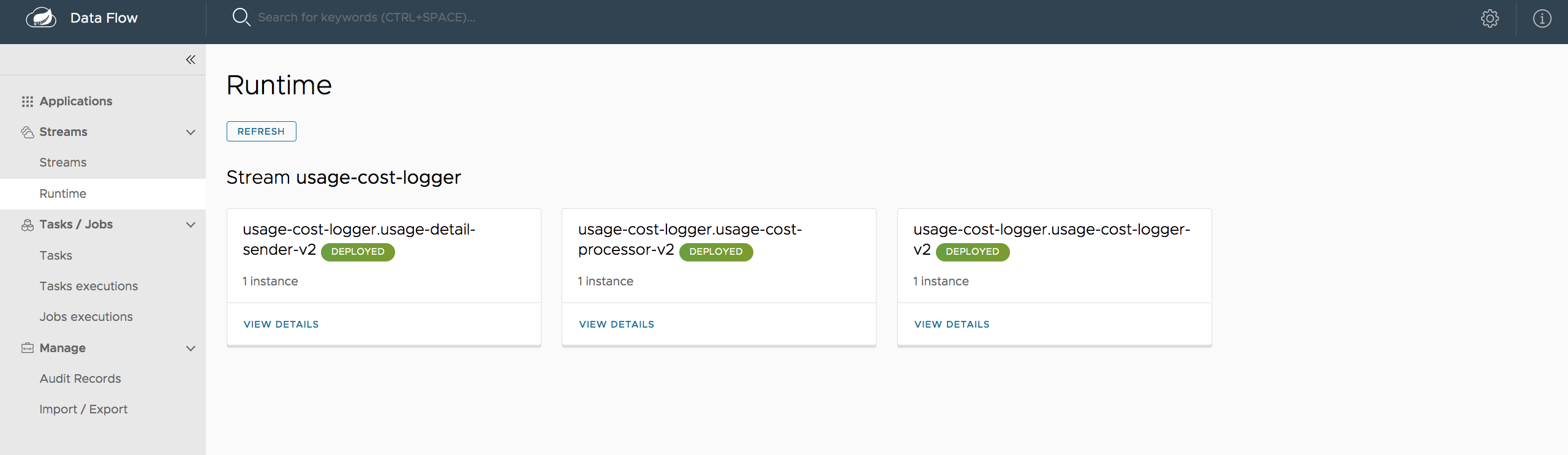
37. Streams
The Streams tab has two child tabs: Definitions and Create Stream. The following topics describe how to work with each one:
37.1. Working with Stream Definitions
The Streams section of the Dashboard includes the Definitions tab that provides a listing of stream definitions. There you have the option to deploy or undeploy those stream definitions. Additionally, you can remove the definition by clicking on Destroy. Each row includes an arrow on the left, which you can click to see a visual representation of the definition. Hovering over the boxes in the visual representation shows more details about the applications, including any options passed to them.
In the following screenshot, the timer stream has been expanded to show the visual representation:
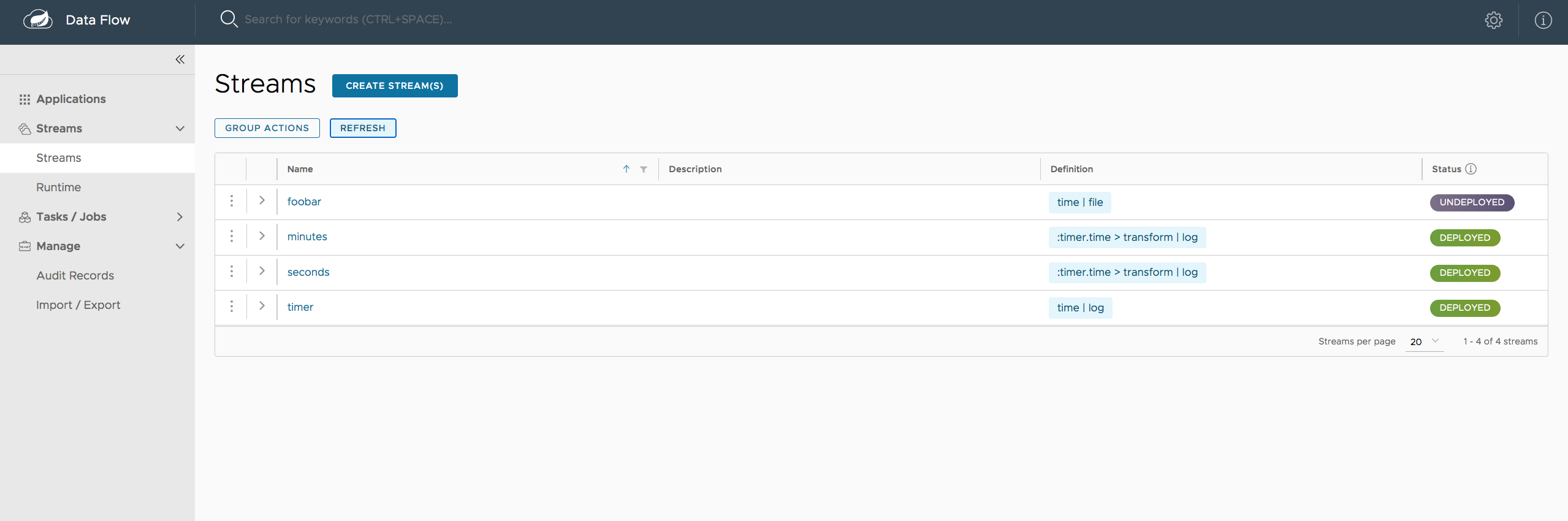
If you click the details button, the view changes to show a visual representation of that stream and any related streams.
In the preceding example, if you click details for the timer stream, the view changes to the following view, which clearly shows the relationship between the three streams (two of them are tapping into the timer stream):
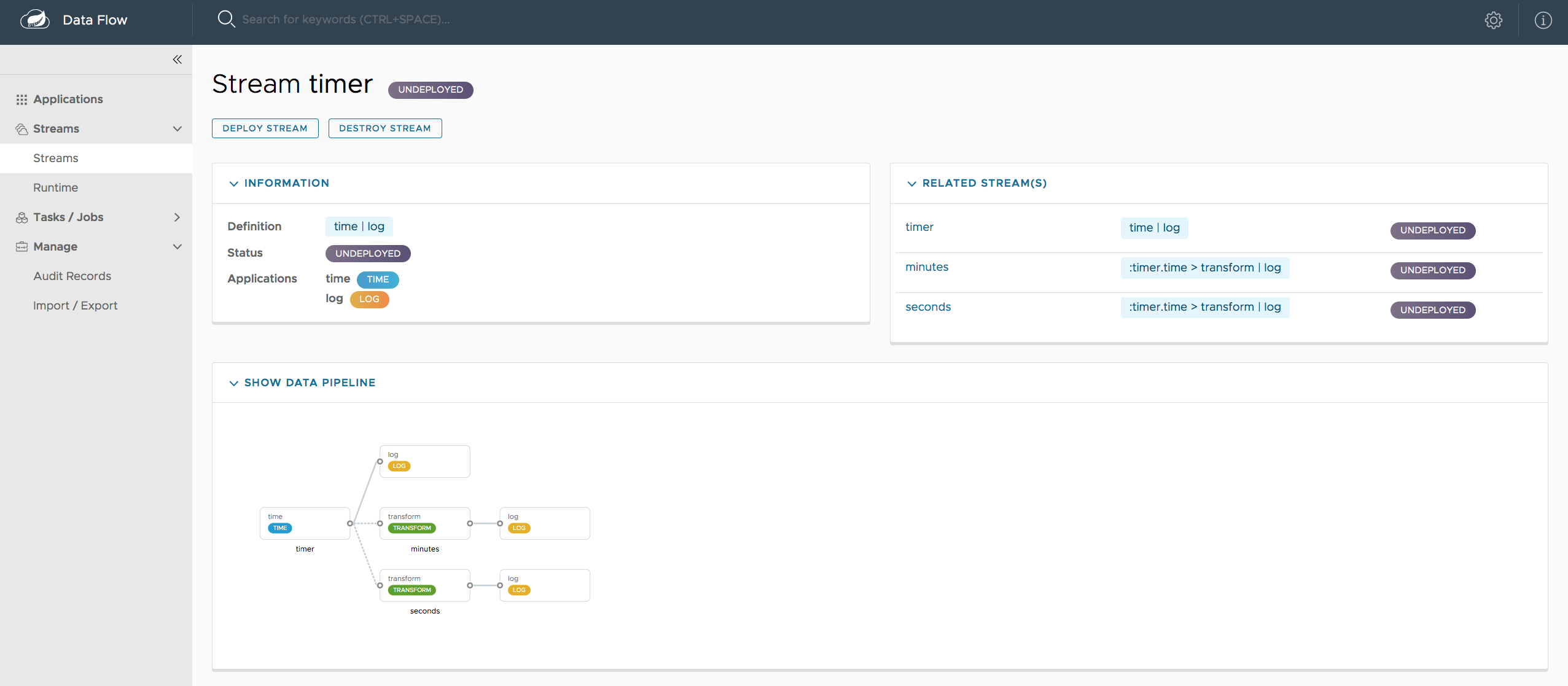
37.2. Creating a Stream
The Streams section of the Dashboard includes the Create Stream tab, which makes the Spring Flo designer available. The designer is a canvas application that offers an interactive graphical interface for creating data pipelines.
In this tab, you can:
-
Create, manage, and visualize stream pipelines by using DSL, a graphical canvas, or both
-
Write pipelines by using DSL with content-assist and auto-complete
-
Use auto-adjustment and grid-layout capabilities in the GUI for simpler and interactive organization of pipelines
You should watch this screencast that highlights some of the "Flo for Spring Cloud Data Flow" capabilities. The Spring Flo wiki includes more detailed content on core Flo capabilities.
The following image shows the Flo designer in use:
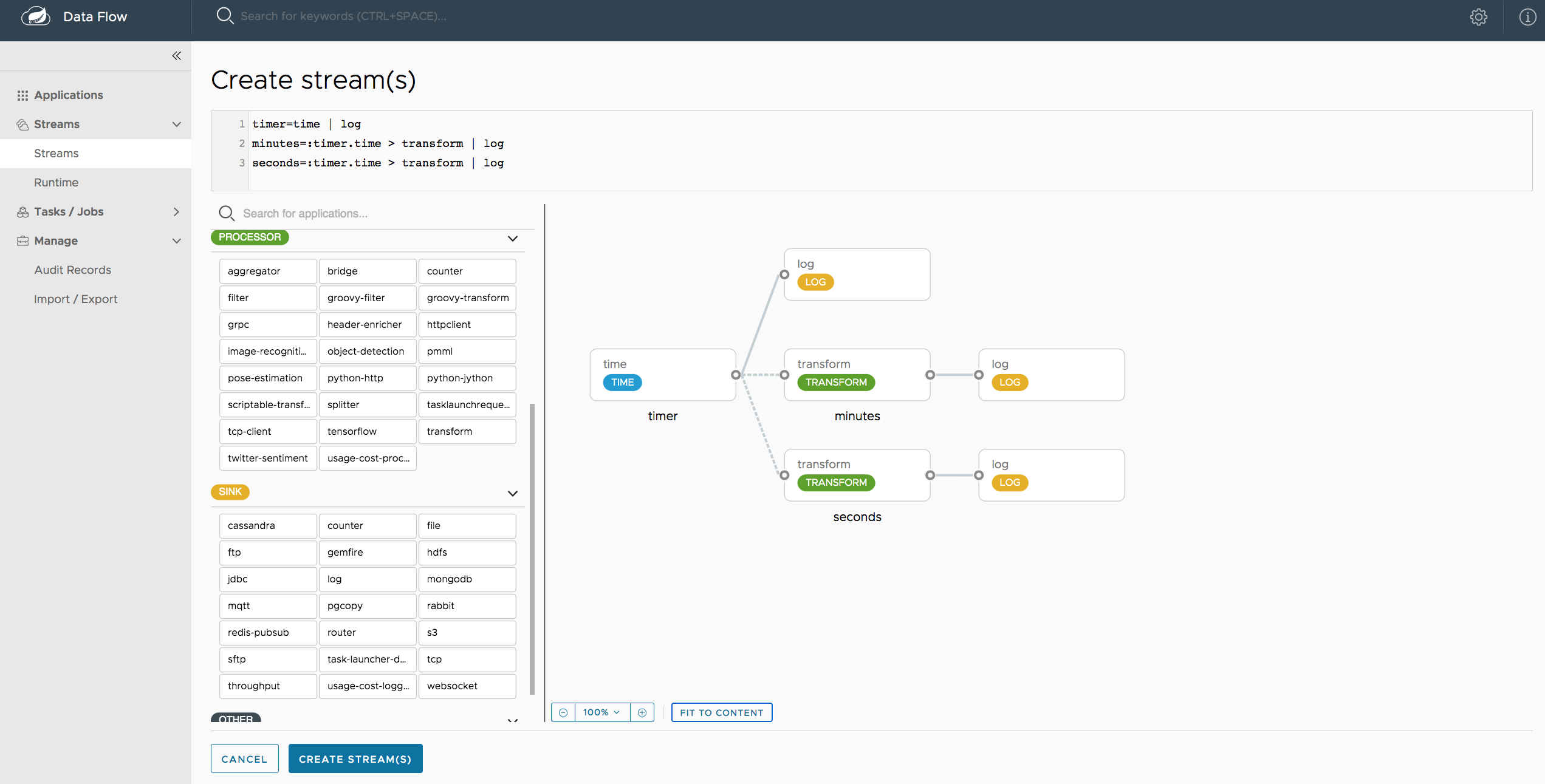
37.3. Deploying a Stream
The stream deploy page includes tabs that provide different ways to set up the deployment properties and deploy the stream.
The following screenshots show the stream deploy page for foobar (time | log).
You can define deployments properties by using:
-
Form builder tab: a builder that helps you to define deployment properties (deployer, application properties, and so on)
-
Free text tab: a free text area (for key-value pairs)
You can switch between both views.
| The form builder offers stronger validation of the inputs. |
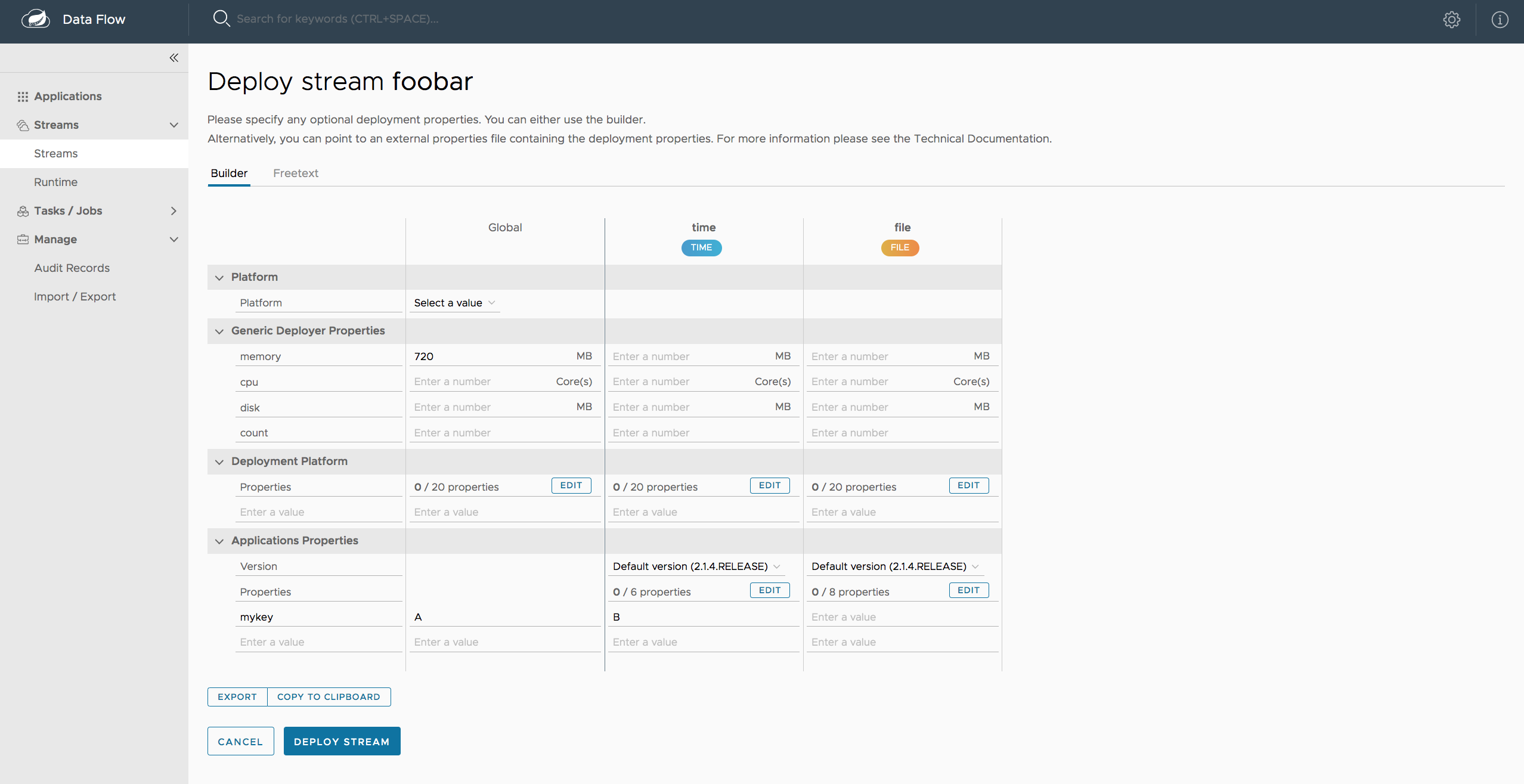
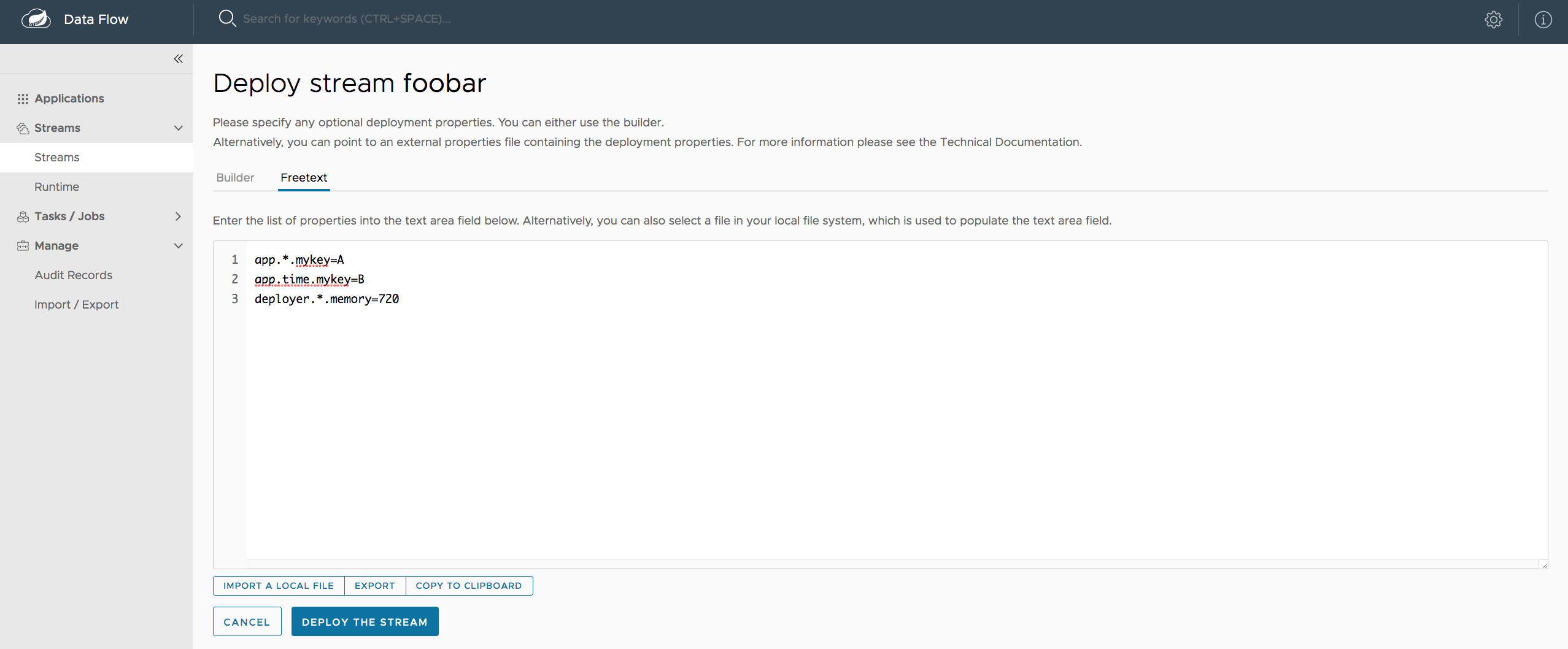
37.4. Accessing Stream Logs
Once the stream applications are deployed, their logs can be accessed from the Stream summary page, as the following image shows:
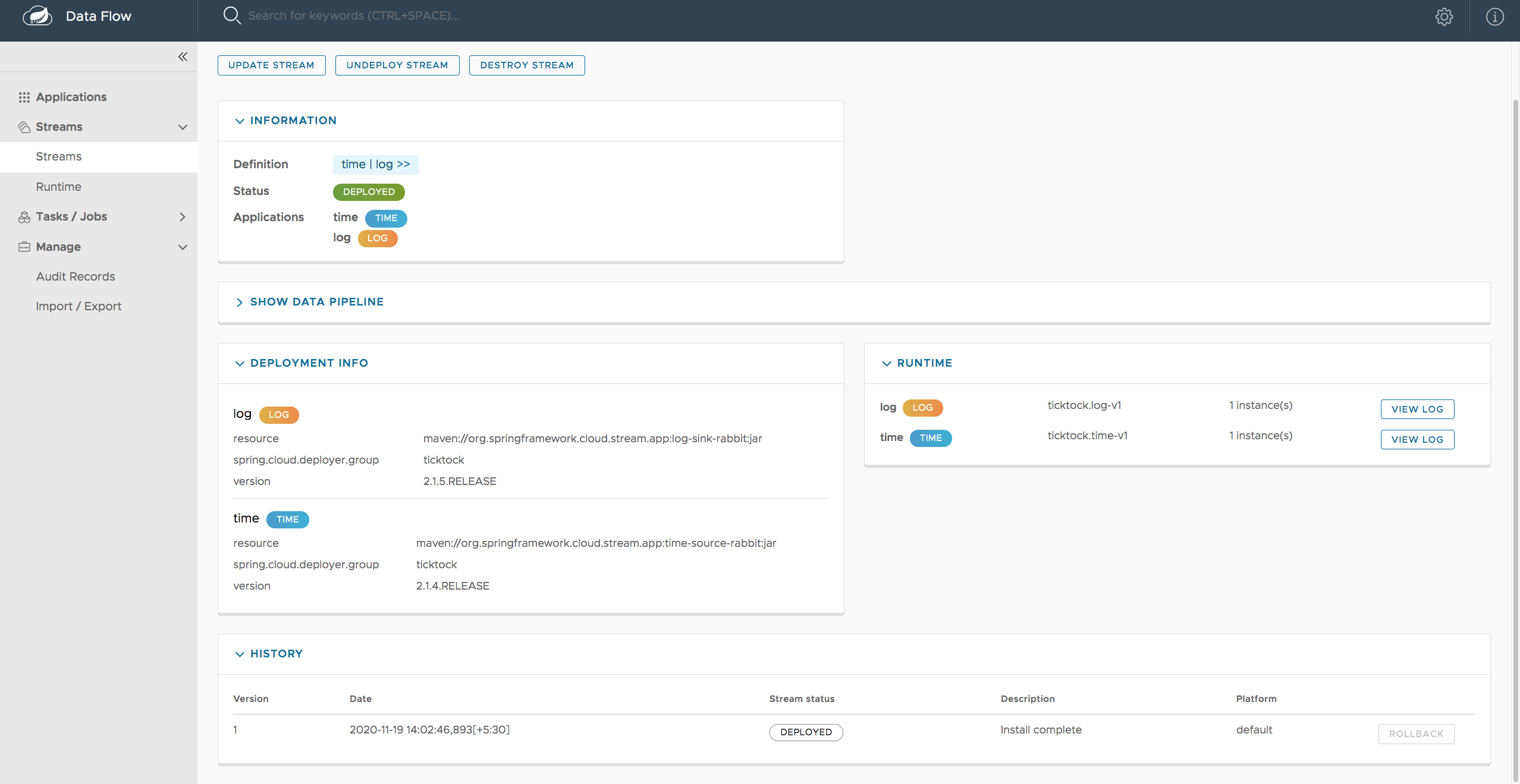
37.5. Creating Fan-In and Fan-Out Streams
In the Fan-in and Fan-out chapter, you can learn how to support fan-in and fan-out use cases by using named destinations. The UI provides dedicated support for named destinations as well:
In this example, we have data from an HTTP Source and a JDBC Source that is being sent to the sharedData channel, which represents a fan-in use case. On the other end we have a Cassandra Sink and a File Sink subscribed to the sharedData channel, which represents a fan-out use case.
37.6. Creating a Tap Stream
Creating taps by using the Dashboard is straightforward. Suppose you have a stream consisting of an HTTP Source and a File Sink and you would like to tap into the stream to also send data to a JDBC Sink. To create the tap stream, connect the output connector of the HTTP Source to the JDBC Sink. The connection is displayed as a dotted line, indicating that you created a tap stream.
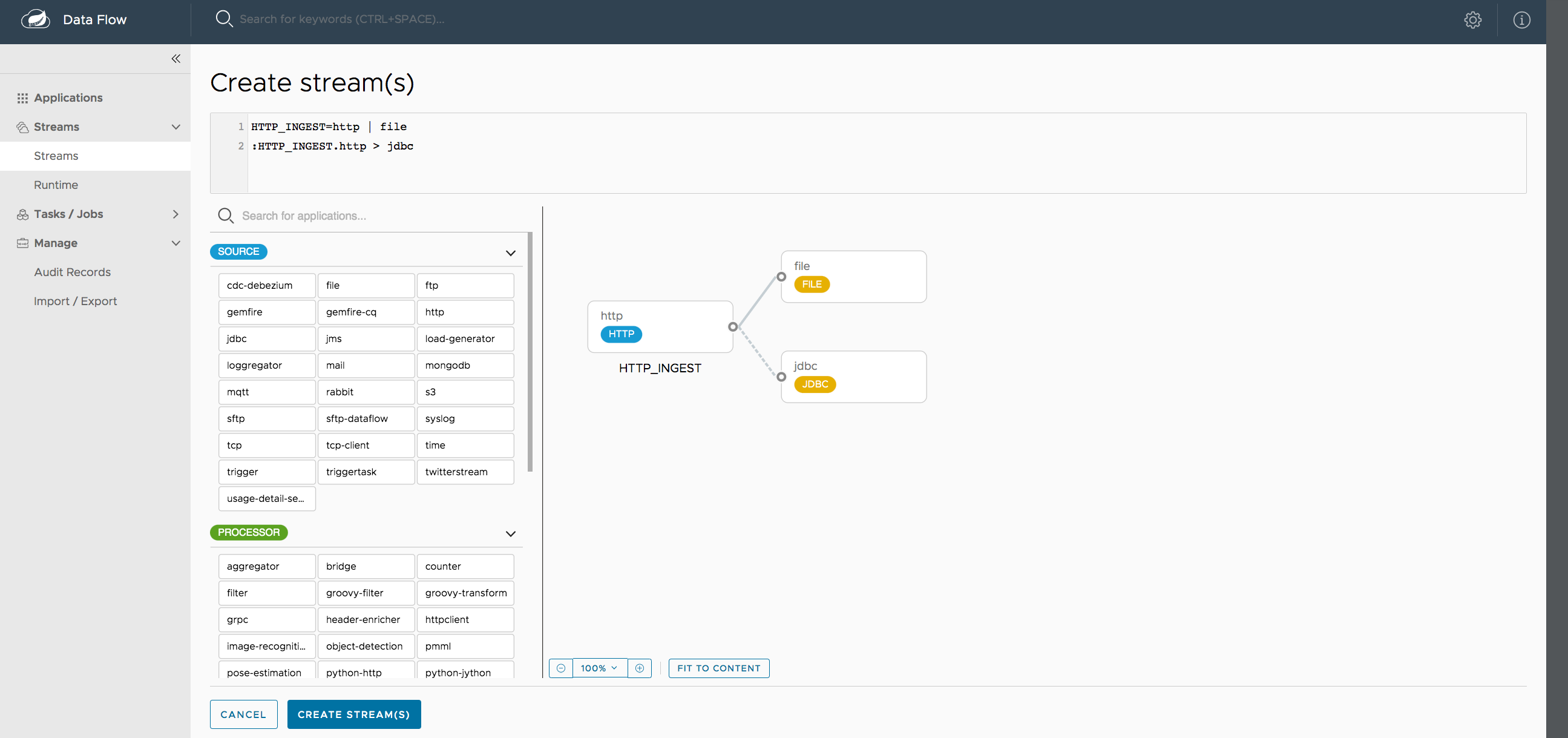
The primary stream (HTTP Source to File Sink) will be automatically named, in case you did not provide a name for the stream, yet. When creating tap streams, the primary stream must always be explicitly named. In the preceding image, the primary stream was named HTTP_INGEST.
By using the Dashboard, you can also switch the primary stream so that it becomes the secondary tap stream.
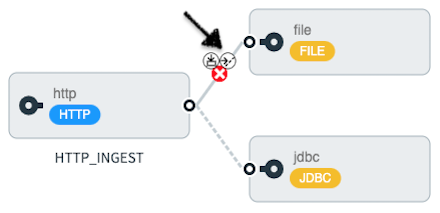
Hover over the existing primary stream, the line between HTTP Source and File Sink. Several control icons appear, and, by clicking on the icon labeled Switch to/from tap, you change the primary stream into a tap stream. Do the same for the tap stream and switch it to a primary stream.
| When interacting directly with named destinations, there can be "n" combinations (Inputs/Outputs). This allows you to create complex topologies involving a wide variety of data sources and destinations. |
37.7. Import and Export Streams
The Import/Export tab of the Dashboard includes a page that provides the option to import and export streams.
The following image shows the streams export page:
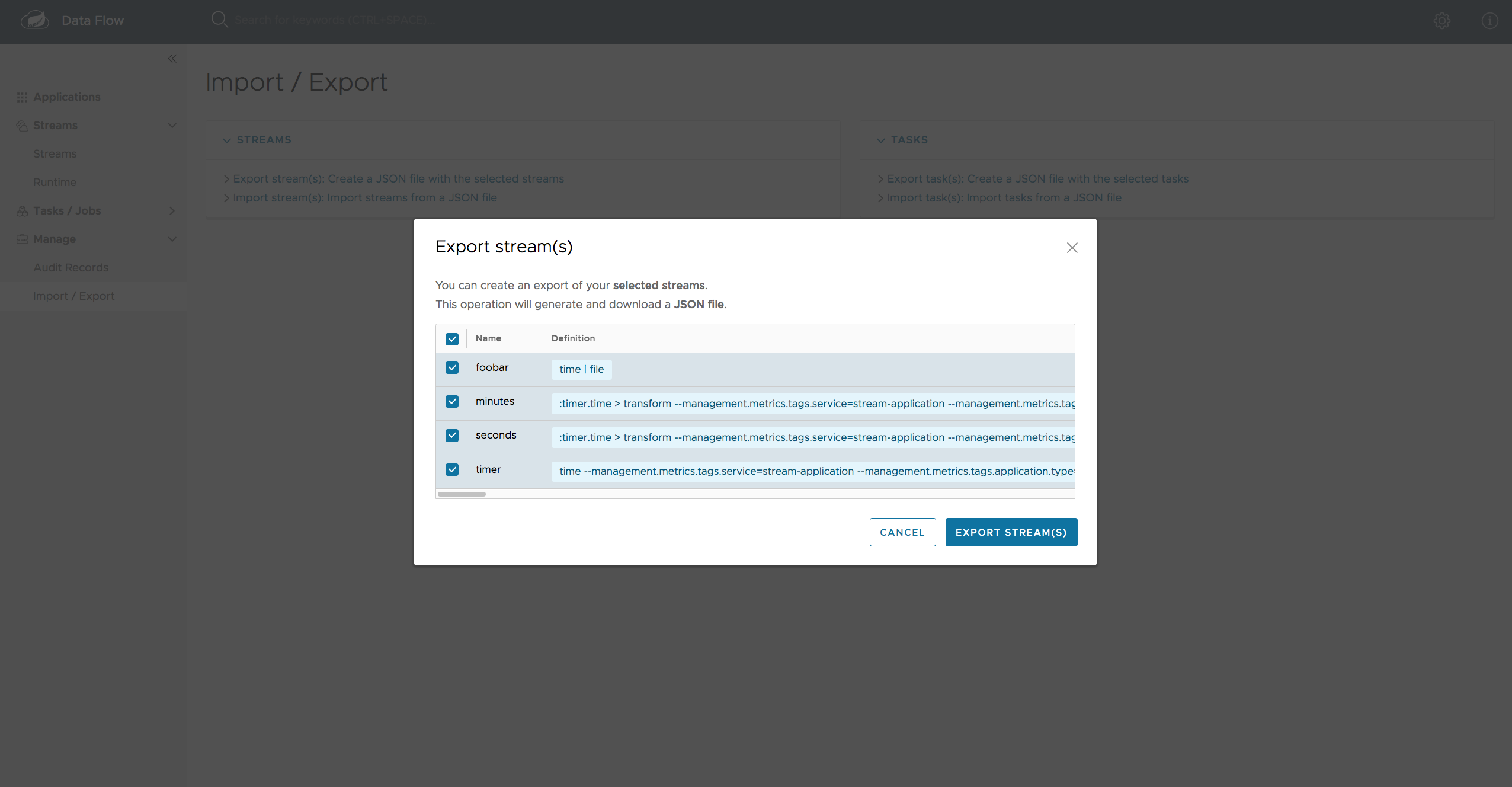
When importing the streams, you have to import from a valid JSON file. You can either manually draft the file or export the file from the streams export page.
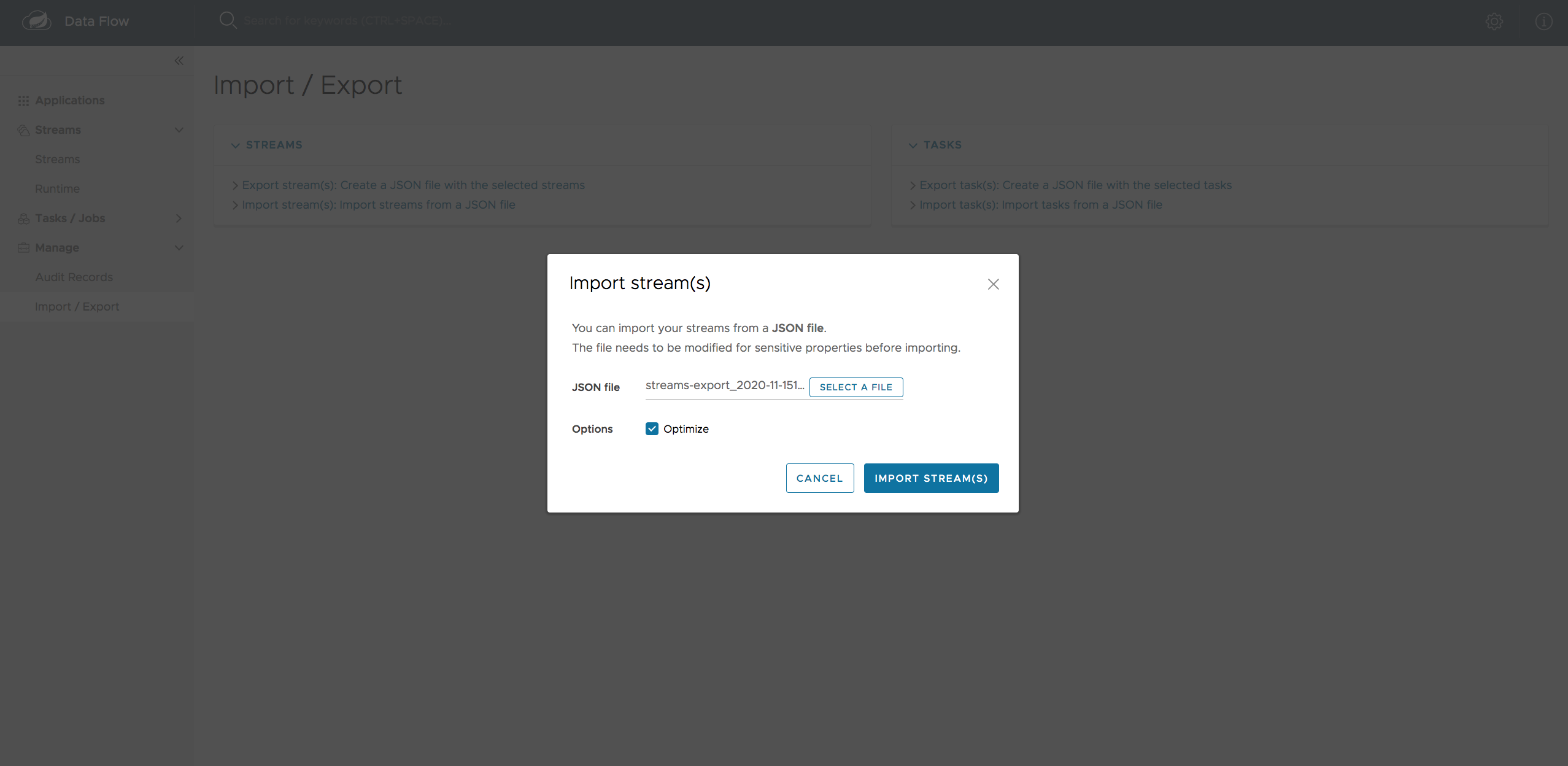
After importing the file, you get confirmation of whether the operation completed successfully.
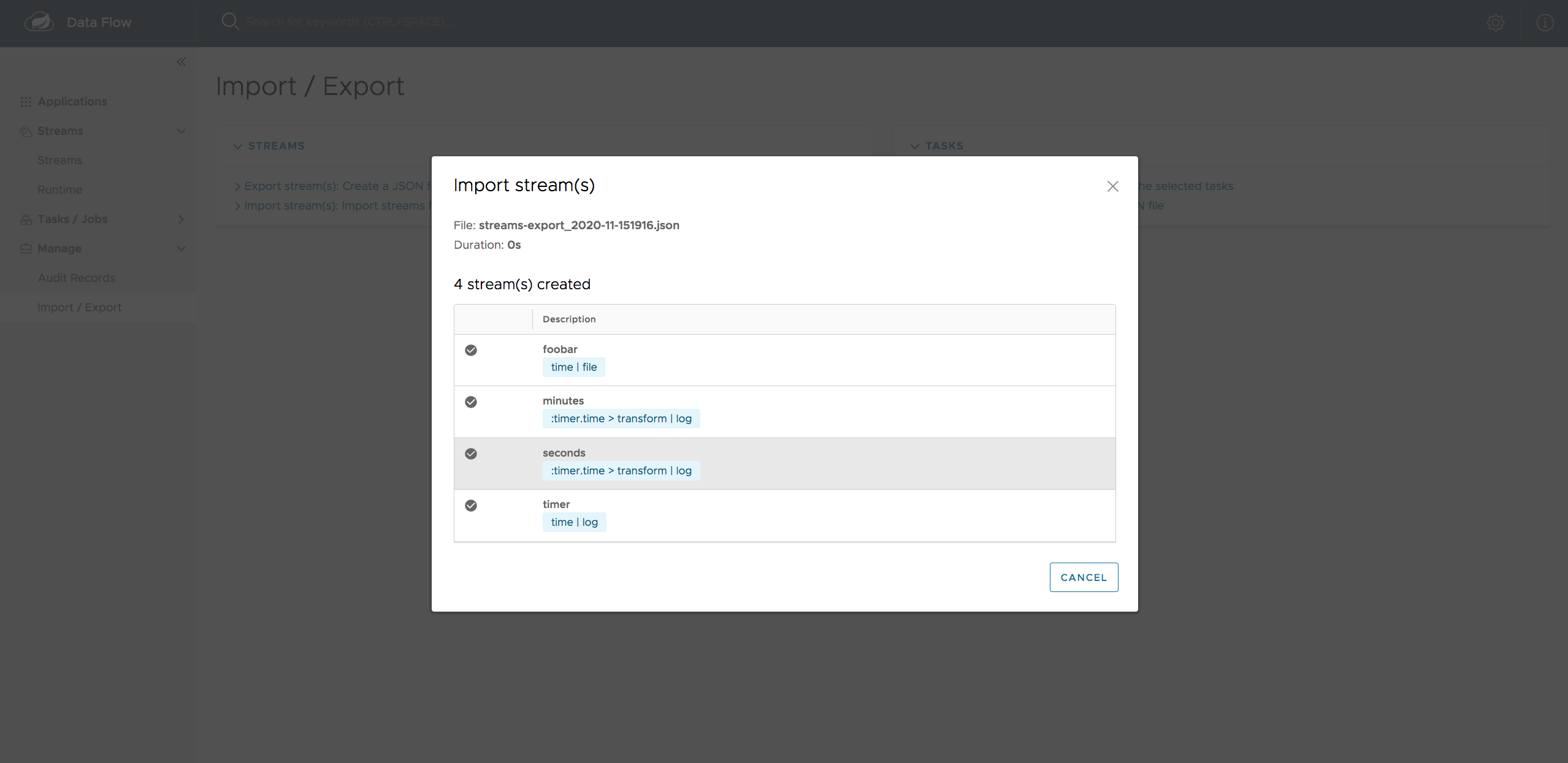
38. Tasks
The Tasks tab of the Dashboard currently has three tabs:
38.1. Apps
Each application encapsulates a unit of work into a reusable component. Within the Data Flow runtime environment, applications let you create definitions for streams as well as tasks. Consequently, the Apps tab within the Tasks tab lets you create task definitions.
| You can also use this tab to create Batch Jobs. |
The following image shows a typical list of task applications:
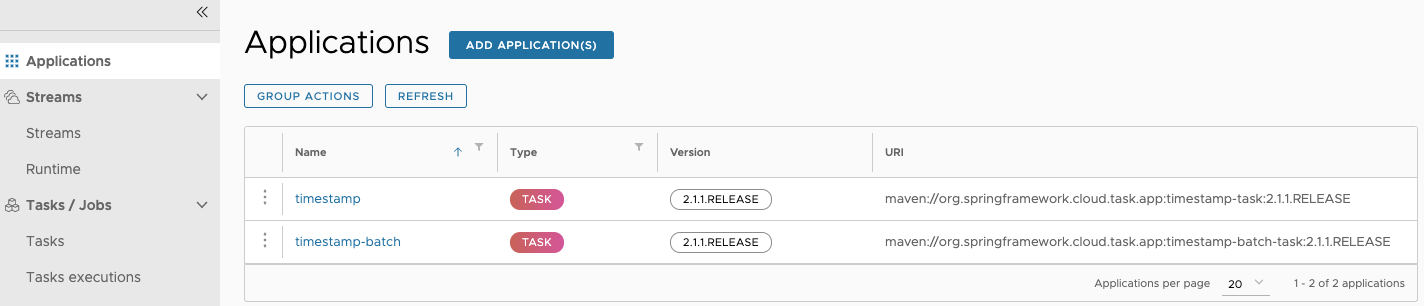
On this screen, you can perform the following actions:
-
View details, such as the task application options.
-
Create a task definition from the respective application.
38.2. Definitions
This page lists the Data Flow task definitions and provides actions to launch or destroy those tasks.
The following image shows the Definitions page:
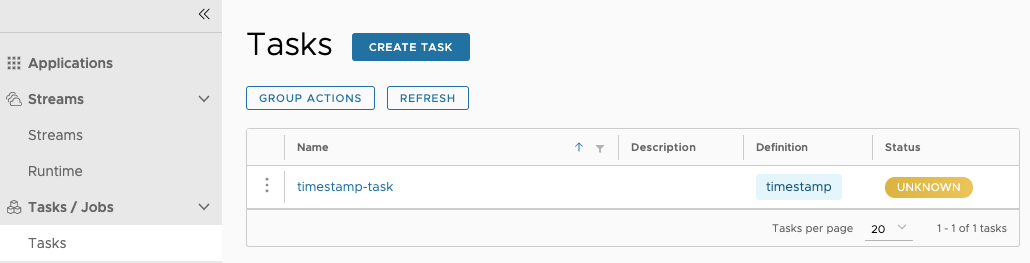
38.2.1. Create a Task Definition
The following image shows a task definition composed of the timestamp application as well as the list of task applications that can be used to create a task definiton:
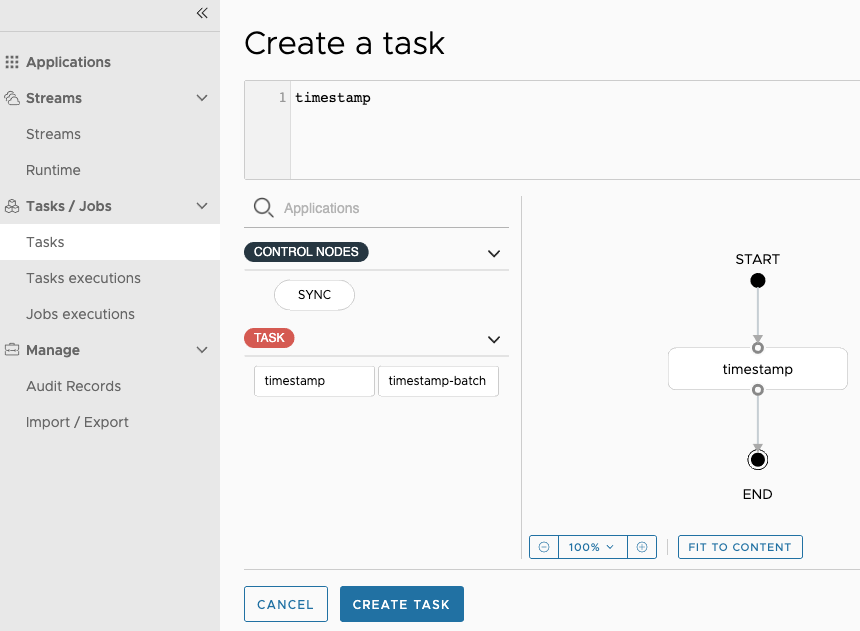
On this page, you can also specify various properties that are used during the deployment of the application. Once you are satisfied with the task definition, you can click the CREATE TASK button. A dialog box then asks for a task definition name and description. At a minimum, you must provide a name for the new definition.
38.2.2. Creating Composed Task Definitions
The dashboard includes the Create Composed Task tab, which provides an interactive graphical interface for creating composed tasks.
In this tab, you can:
-
Create and visualize composed tasks by using DSL, a graphical canvas, or both.
-
Use auto-adjustment and grid-layout capabilities in the GUI for simpler and interactive organization of the composed task.
On the Create Composed Task screen, you can define one or more task parameters by entering both the parameter key and the parameter value.
| Task parameters are not typed. |
The following image shows the composed task designer:
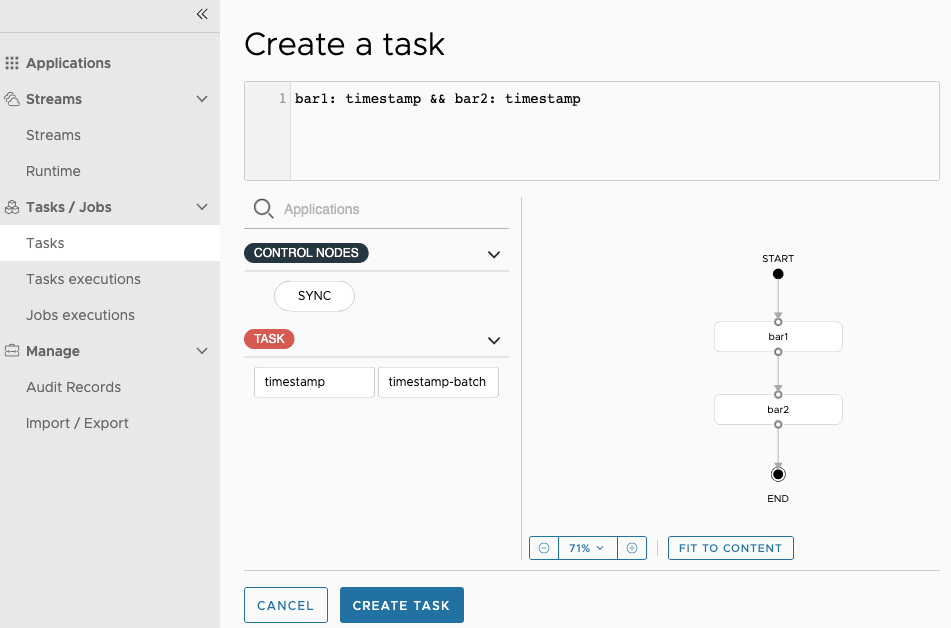
38.2.3. Launching Tasks
Once the task definition has been created, you can launch the tasks through the dashboard.
To do so, click the Tasks tab and select the task you want to launch by pressing Launch.
The following image shows the Task Launch page:
38.2.4. Import/Export Tasks
The Import/Export page provides the option to import and export tasks. This is done by clicking the Import/Export option on the left side of page. From here, click the Export task(s): Create a JSON file with the selected tasks option. The Export Tasks(s) page appears.
The following image shows the tasks export page:
Similarly, you can import task definitions. To do so, click the Import/Export option on the left side of page. From here, click the Import task(s): Import tasks from a JSON file option to show the Import Tasks page. On the Import Tasks page, you have to import from a valid JSON file. You can either manually draft the file or export the file from the Tasks Export page.
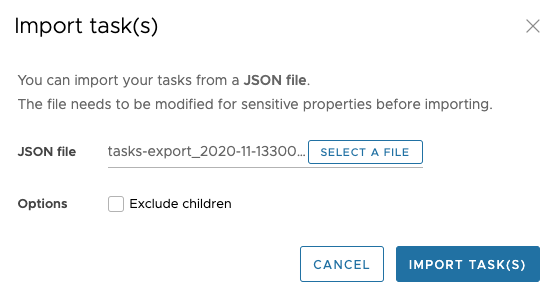
After importing the file, you get confirmation on whether the operation completed successfully.
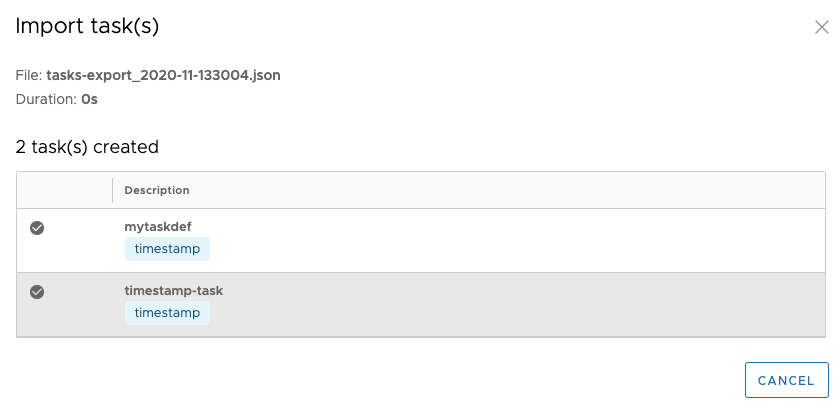
38.3. Executions
The Task Executions tab shows the current running and completed task executions. From this page, you can drill down into the Task Execution details page. Furthermore, you can relaunch a Task Execution or stop a running execution.
Finally, you can clean up one or more task executions. This operation removes any associated task or batch job from the underlying persistence store. This operation can only be triggered for parent task executions and cascades down to the child task executions (if there are any).
The following image shows the Executions tab:

38.4. Execution Detail
For each task execution on the Task Executions tab, you can retrieve detailed information about a specific execution by clicking the Execution ID of the task execution.
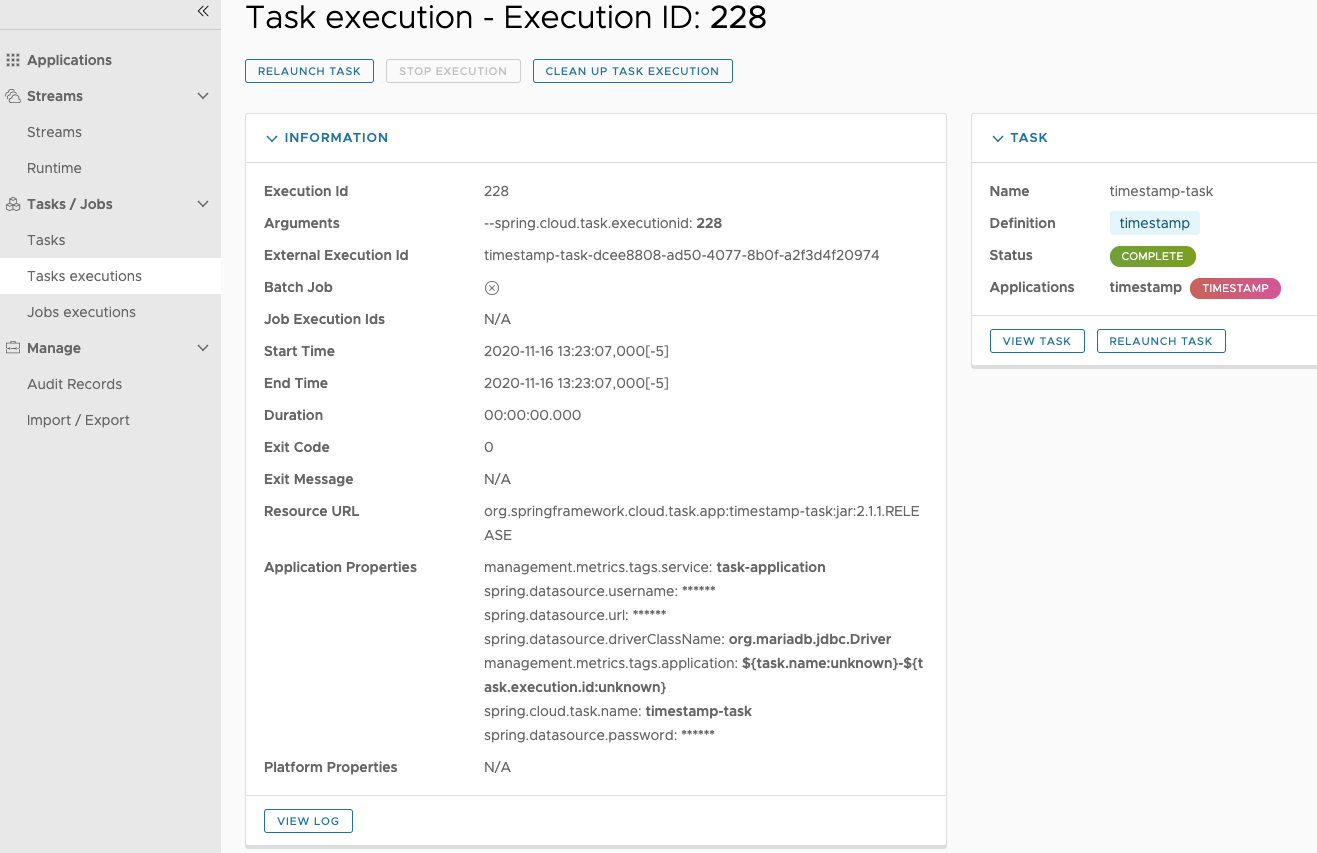
On this screen, you can view not only the information from the task executions page but also:
-
Task Arguments
-
External Execution ID
-
Batch Job Indicator (indicates if the task execution contained Spring Batch jobs.)
-
Job Execution IDs links (Clicking the Job Execution Id will take you to the Job Execution Details for that Job Execution ID.)
-
Task Execution Duration
-
Task Execution Exit Message
-
Logging output from the Task Execution
Additionally, you can trigger the following operations:
-
Relaunch a task
-
Stop a running task
-
Task execution cleanup (for parent task executions only)
38.4.1. Stop Executing Tasks
To submit a stop task execution request to the platform, click the drop down button next to the task execution that needs to be stopped.
Now click the Stop task option. The dashboard presents a dialog box asking if you are sure that you want to stop the task execution. If so, click Stop Task Execution(s).
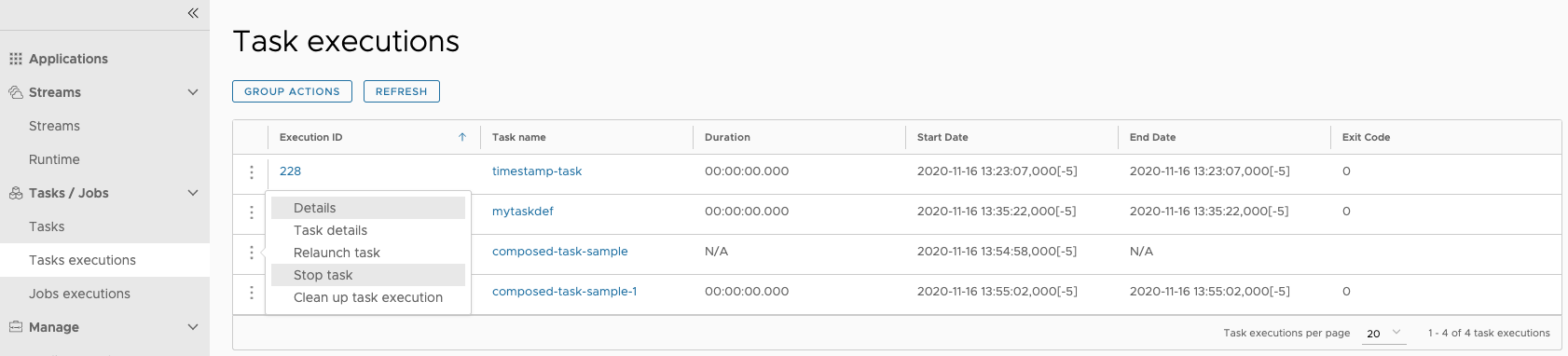
| Child Spring Cloud Task applications launched via Spring Batch applications that use remote partitioning are not stopped. |
39. Jobs
The Job Executions tab of the Dashboard lets you inspect batch jobs. The main section of the screen provides a list of job executions. Batch jobs are tasks that each execute one or more batch jobs. Each job execution has a reference to the task execution ID (in the Task ID column).
The list of job executions also shows the state of the underlying Job Definition. Thus, if the underlying definition has been deleted, “No definition found” appears in the Status column.
You can take the following actions for each job:
-
Restart (for failed jobs).
-
Stop (for running jobs).
-
View execution details.
| Clicking the stop button actually sends a stop request to the running job, which may not immediately stop. |
The following image shows the Jobs tab:

39.1. Job Execution Details
After you have launched a batch job, the Job Execution Details page shows information about the job.
The following image shows the Job Execution Details page:
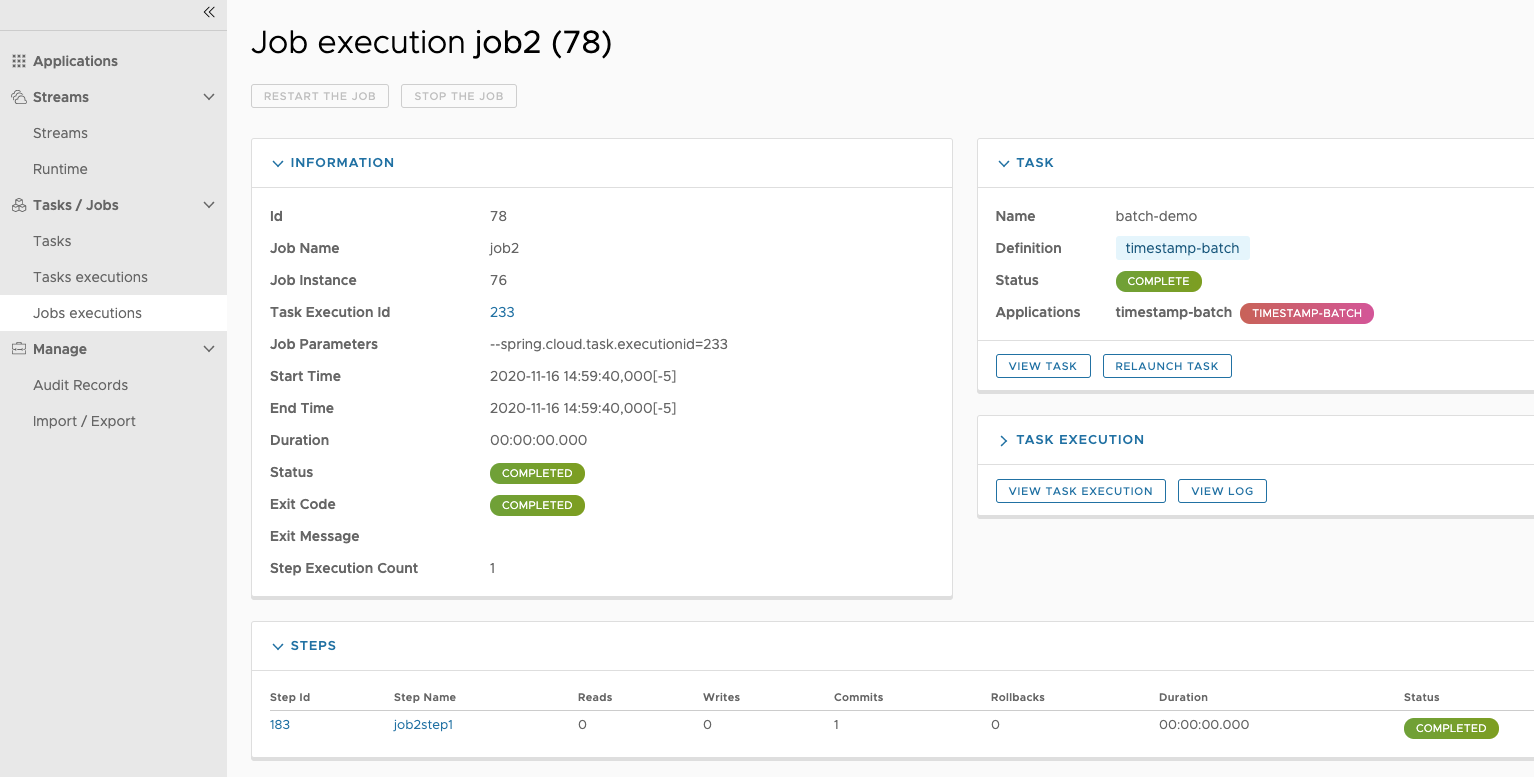
The Job Execution Details page contains a list of the executed steps. You can further drill into the details of each step’s execution by clicking the magnifying glass icon.
39.2. Step Execution Details
The Step Execution Details page provides information about an individual step within a job.
The following image shows the Step Execution Details page:
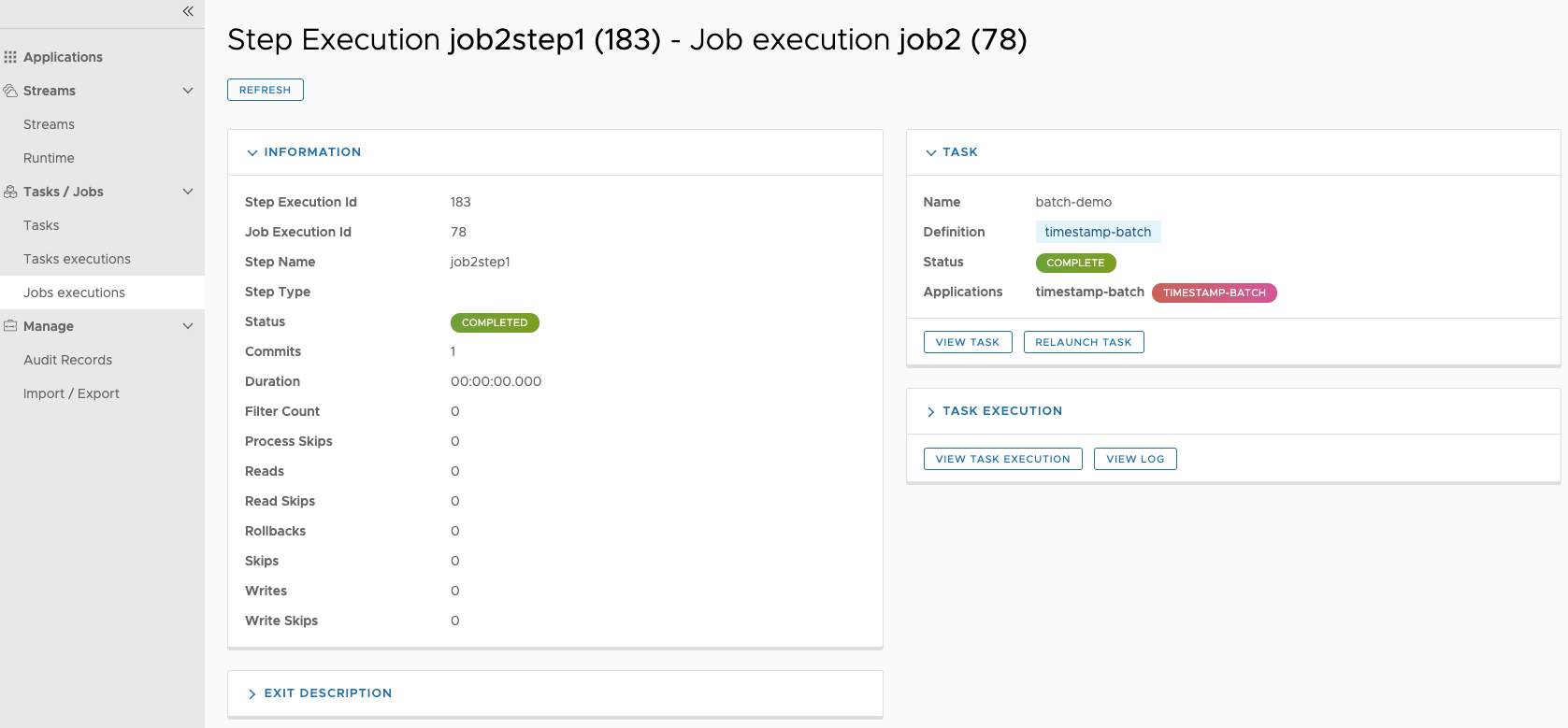
The Step Execution Details screen provides a complete list of all Step Execution Context key-value pairs.
| For exceptions, the Exit Description field contains additional error information. However, this field can have a maximum of 2500 characters. Therefore, in the case of long exception stack traces, trimming of error messages may occur. When that happens, check the server log files for further details. |
39.3. Step Execution History
Under Step Execution History, you can also view various metrics associated with the selected step, such as duration, read counts, write counts, and others across all of its executions. For each metric there are 5 attributes:
-
Count - The number of step executions that the metric could have participated. It is not a count for the number of times the event occurred during each step execution.
-
Min - The minimum value for the metric across all the executions for this step.
-
Max - The maximum value for the metric across all the executions for this step.
-
Mean - The mean value for the metric across all the executions for this step.
-
Standard Deviation - The standard deviation for the metric across all the executions for this step.
The Step Execution contains the following metrics:
-
Commit Count - The max, min, mean, and standard deviation for the number of commits of all the executions for the given step.
-
Duration - The max, min, mean, and standard deviation for the duration of all the executions for the given step.
-
Duration Per Read - The max, min, mean, and standard deviation for the duration per read of all the executions for the given step.
-
FilterCount - The max, min, mean, and standard deviation for the number of filters of all the executions for the given step.
-
Process Skip Count - The max, min, mean, and standard deviation for the process skips of all the executions for the given step.
-
Read Count - The max, min, mean, and standard deviation for the number of reads of all the executions for the given step.
-
Read Skip Count - The max, min, mean, and standard deviation for the number of read skips of all the executions for the given step.
-
Rollback Count - The max, min, mean, and standard deviation for the number of rollbacks of all the executions for the given step.
-
Write Count - The max, min, mean, and standard deviation for the number of writes of all the executions for the given step.
-
Write Skip Count - The max, min, mean, and standard deviation for the number of skips of all the executions for the given step.
40. Scheduling
You can create schedules from the SCDF Dashboard for the Task Definitions. See the Scheduling Batch Jobs section of the microsite for more information.
41. Auditing
The Auditing page of the Dashboard gives you access to recorded audit events. Audit events are recorded for:
-
Streams
-
Create
-
Delete
-
Deploy
-
Undeploy
-
-
Tasks
-
Create
-
Delete
-
Launch
-
-
Scheduling of Tasks
-
Create Schedule
-
Delete Schedule
-
The following image shows the Audit Records page:
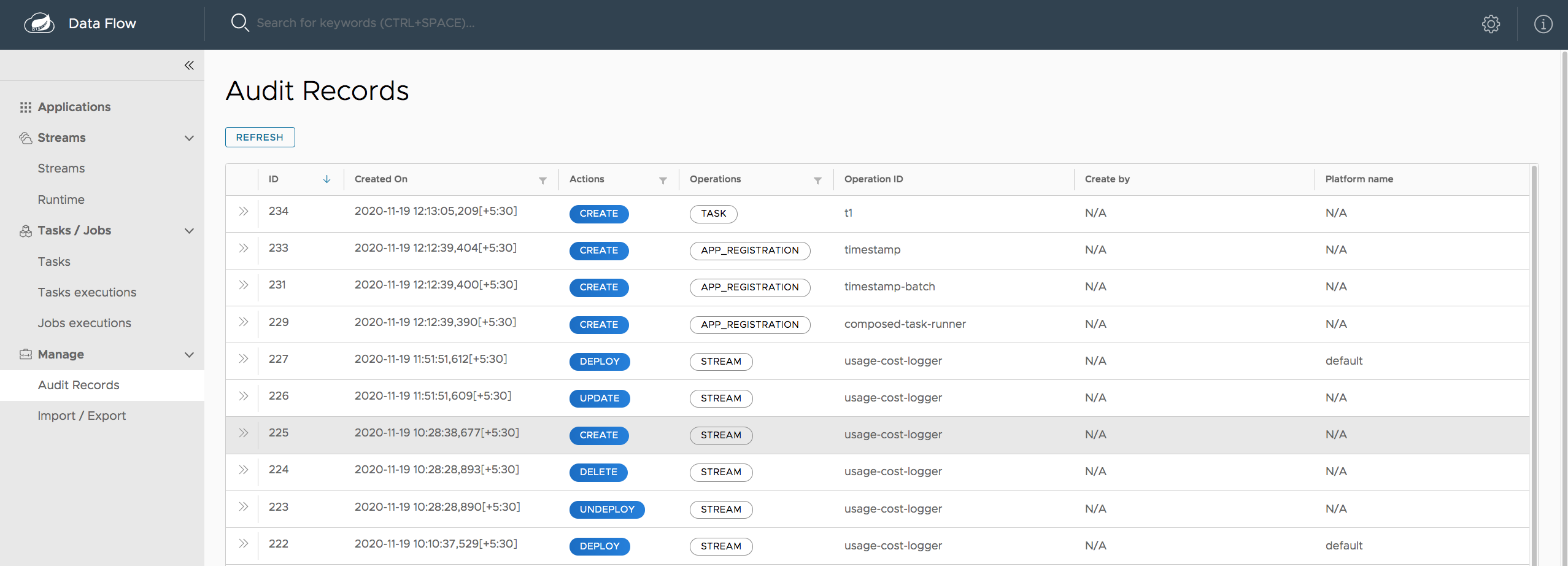
By clicking the show details icon (the “i” in a circle on the right), you can obtain further details regarding the auditing details:
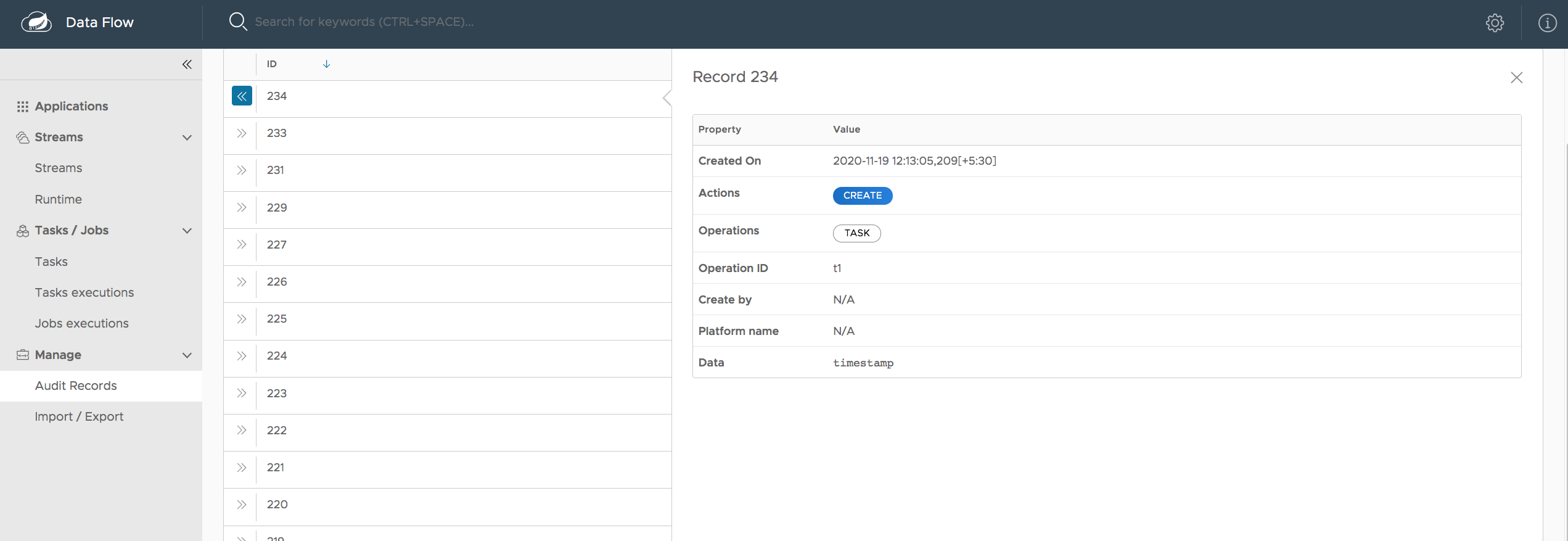
Generally, auditing provides the following information:
-
When was the record created?
-
The name of the user who triggered the audit event (if security is enabled)
-
Audit operation (Schedule, Stream, or Task)
-
The performed action (Create, Delete, Deploy, Rollback, Undeploy, or Update)
-
Correlation ID, such as the Stream or Task name
-
Audit Data
The written value of the audit data property depends on the performed audit operation and the action type. For example, when a schedule is being created, the name of the task definition, task definition properties, deployment properties, and command line arguments are written to the persistence store.
Sensitive information is sanitized prior to saving the Audit Record, in a best-effort manner. Any of the following keys are being detected and their sensitive values are masked:
-
password
-
secret
-
key
-
token
-
.*credentials.*
-
vcap_services
REST API Guide
This section describes the Spring Cloud Data Flow REST API.
42. Overview
Spring Cloud Data Flow provides a REST API that lets you access all aspects of the server. In fact, the Spring Cloud Data Flow shell is a first-class consumer of that API.
If you plan to use the REST API with Java, you should consider using the
provided Java client (DataflowTemplate) that uses the REST API internally.
|
42.1. HTTP Version
Spring Cloud Data Flow establishes a RESTful API version that is updated when there is a breaking change to the API. The API version can be seen at the end of the home page of Spring Cloud Data Flow as shown in the example below:
{
"_links": {
"dashboard": { "href" : "http://localhost:9393/dashboard" },
...
},
"api.revision":15
}The table below shows the SCDF Release version and its current RESTful API version.
| SCDF Version | API Version |
|---|---|
2.11.x |
14 |
2.10.x |
14 |
2.9.x |
14 |
2.8.x |
14 |
2.7.x |
14 |
42.2. HTTP verbs
Spring Cloud Data Flow tries to adhere as closely as possible to standard HTTP and REST conventions in its use of HTTP verbs, as described in the following table:
| Verb | Usage |
|---|---|
|
Used to retrieve a resource. |
|
Used to create a new resource. |
|
Used to update an existing resource, including partial updates. Also used for
resources that imply the concept of |
|
Used to delete an existing resource. |
42.3. HTTP Status Codes
Spring Cloud Data Flow tries to adhere as closely as possible to standard HTTP and REST conventions in its use of HTTP status codes, as shown in the following table:
| Status code | Usage |
|---|---|
|
The request completed successfully. |
|
A new resource has been created successfully. The resource’s URI is available from the response’s |
|
An update to an existing resource has been applied successfully. |
|
The request was malformed. The response body includes an error description that provides further information. |
|
The requested resource did not exist. |
|
The requested resource already exists. For example, the task already exists or the stream was already being deployed |
|
Returned in cases where the job execution cannot be stopped or restarted. |
42.4. Headers
Every response has the following headers:
| Name | Description |
|---|---|
|
The Content-Type of the payload, e.g. |
42.5. Errors
| Path | Type | Description |
|---|---|---|
|
|
The HTTP error that occurred, e.g. |
|
|
A description of the cause of the error |
|
|
The path to which the request was made |
|
|
The HTTP status code, e.g. |
|
|
The time, in milliseconds, at which the error occurred |
42.6. Hypermedia
Spring Cloud Data Flow uses hypermedia, and resources include links to other resources
in their responses.
Responses are in the Hypertext Application from resource-to-resource Language (HAL) format.
Links can be found beneath the _links key.
Users of the API should not create URIs themselves.
Instead, they should use the above-described links to navigate.
43. Resources
The API includes the following resources:
43.1. Index
The index provides the entry point into Spring Cloud Data Flow’s REST API. The following topics provide more details:
43.1.1. Accessing the index
Use a GET request to access the index.
Response Structure
| Path | Type | Description |
|---|---|---|
|
|
Links to other resources |
|
|
Incremented each time a change is implemented in this REST API |
|
|
Link to the audit records |
|
|
Link to the dashboard |
|
|
Link to the schema/versions |
|
|
Link to the schema/targets |
|
|
Link to the streams/definitions |
|
|
Link to the streams/definitions/definition |
|
|
Link streams/definitions/definition is templated |
|
|
Link to the runtime/apps |
|
|
Link to the runtime/apps/{appId} |
|
|
Link runtime/apps is templated |
|
|
Link to the runtime/apps/{appId}/instances |
|
|
Link runtime/apps/{appId}/instances is templated |
|
|
Link to the runtime/apps/{appId}/instances/{instanceId} |
|
|
Link runtime/apps/{appId}/instances/{instanceId} is templated |
|
|
Link to the runtime/apps/{appId}/instances/{instanceId}/post |
|
|
Link runtime/apps/{appId}/instances/{instanceId}/post is templated |
|
|
Link to the runtime/apps/{appId}/instances/{instanceId}/actuator |
|
|
Link runtime/apps/{appId}/instances/{instanceId}/actuator is templated |
|
|
Link to the runtime/streams |
|
|
Link runtime/streams is templated |
|
|
Link to the runtime/streams/{streamNames} |
|
|
Link runtime/streams/{streamNames} is templated |
|
|
Link to the streams/logs |
|
|
Link to the streams/logs/{streamName} |
|
|
Link to the streams/logs/{streamName}/{appName} |
|
|
Link streams/logs/{streamName} is templated |
|
|
Link streams/logs/{streamName}/{appName} is templated |
|
|
Link to streams/deployments |
|
|
Link to streams/deployments |
|
|
Link streams/deployments/{name} is templated |
|
|
Link streams/deployments/{name} is templated |
|
|
Link streams/deployments/{name} is templated |
|
|
Link streams/deployments/{name} is templated |
|
|
Link streams/deployments/{name} is templated |
|
|
Link to the streams/deployments/deployment |
|
|
Link streams/deployments/deployment is templated |
|
|
Link to the streams/deployments/manifest/{name}/{version} |
|
|
Link streams/deployments/manifest/{name}/{version} is templated |
|
|
Link to the streams/deployments/history/{name} |
|
|
Link streams/deployments/history is templated |
|
|
Link to the streams/deployments/rollback/{name}/{version} |
|
|
Link streams/deployments/rollback/{name}/{version} is templated |
|
|
Link to the streams/deployments/update/{name} |
|
|
Link streams/deployments/update/{name} is templated |
|
|
Link to the streams/deployments/platform/list |
|
|
Link to the streams/deployments/scale/{streamName}/{appName}/instances/{count} |
|
|
Link streams/deployments/scale/{streamName}/{appName}/instances/{count} is templated |
|
|
Link to the streams/validation |
|
|
Link streams/validation is templated |
|
|
Link to the tasks/platforms |
|
|
Link to the tasks/definitions |
|
|
Link to the tasks/definitions/definition |
|
|
Link tasks/definitions/definition is templated |
|
|
Link to the tasks/executions |
|
|
Link to tasks/executions/launch |
|
|
Indicates that Link tasks/executions/launch is templated |
|
|
Link to the tasks/executions/name |
|
|
Link tasks/executions/name is templated |
|
|
Link to the tasks/executions/current |
|
|
Link to the tasks/executions/execution |
|
|
Link tasks/executions/execution is templated |
|
|
Link to the tasks/executions/external |
|
|
Link tasks/executions/external is templated |
|
|
Link to the tasks/info/executions |
|
|
Link tasks/info is templated |
|
|
Link to the tasks/logs |
|
|
Link tasks/logs is templated |
|
|
Link to the tasks/thinexecutions |
|
|
Link to the tasks/executions/schedules |
|
|
Link to the tasks/schedules/instances |
|
|
Link tasks/schedules/instances is templated |
|
|
Link to the tasks/validation |
|
|
Link tasks/validation is templated |
|
|
Link to the jobs/executions |
|
|
Link to the jobs/thinexecutions |
|
|
Link to the jobs/executions/name |
|
|
Link jobs/executions/name is templated |
|
|
Link to the jobs/executions/status |
|
|
Link jobs/executions/status is templated |
|
|
Link to the jobs/thinexecutions/name |
|
|
Link jobs/executions/name is templated |
|
|
Link to the jobs/thinexecutions/jobInstanceId |
|
|
Link jobs/executions/jobInstanceId is templated |
|
|
Link to the jobs/thinexecutions/taskExecutionId |
|
|
Link jobs/executions/taskExecutionId is templated |
|
|
Link to the jobs/executions/execution |
|
|
Link jobs/executions/execution is templated |
|
|
Link to the jobs/executions/execution/steps |
|
|
Link jobs/executions/execution/steps is templated |
|
|
Link to the jobs/executions/execution/steps/step |
|
|
Link jobs/executions/execution/steps/step is templated |
|
|
Link to the jobs/executions/execution/steps/step/progress |
|
|
Link jobs/executions/execution/steps/step/progress is templated |
|
|
Link to the jobs/instances/name |
|
|
Link jobs/instances/name is templated |
|
|
Link to the jobs/instances/instance |
|
|
Link jobs/instances/instance is templated |
|
|
Link to the tools/parseTaskTextToGraph |
|
|
Link to the tools/convertTaskGraphToText |
|
|
Link to the apps |
|
|
Link to the about |
|
|
Link to the completions/stream |
|
|
Link completions/stream is templated |
|
|
Link to the completions/task |
|
|
Link completions/task is templated |
Example Response
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 8220
{
"_links" : {
"dashboard" : {
"href" : "http://localhost:9393/dashboard"
},
"audit-records" : {
"href" : "http://localhost:9393/audit-records"
},
"schema/versions" : {
"href" : "http://localhost:9393/schema/versions"
},
"schema/targets" : {
"href" : "http://localhost:9393/schema/targets"
},
"streams/definitions" : {
"href" : "http://localhost:9393/streams/definitions"
},
"streams/definitions/definition" : {
"href" : "http://localhost:9393/streams/definitions/{name}",
"templated" : true
},
"streams/validation" : {
"href" : "http://localhost:9393/streams/validation/{name}",
"templated" : true
},
"runtime/streams" : {
"href" : "http://localhost:9393/runtime/streams{?names}",
"templated" : true
},
"runtime/streams/{streamNames}" : {
"href" : "http://localhost:9393/runtime/streams/{streamNames}",
"templated" : true
},
"runtime/apps" : {
"href" : "http://localhost:9393/runtime/apps"
},
"runtime/apps/{appId}" : {
"href" : "http://localhost:9393/runtime/apps/{appId}",
"templated" : true
},
"runtime/apps/{appId}/instances" : {
"href" : "http://localhost:9393/runtime/apps/{appId}/instances",
"templated" : true
},
"runtime/apps/{appId}/instances/{instanceId}" : {
"href" : "http://localhost:9393/runtime/apps/{appId}/instances/{instanceId}",
"templated" : true
},
"runtime/apps/{appId}/instances/{instanceId}/actuator" : [ {
"href" : "http://localhost:9393/runtime/apps/{appId}/instances/{instanceId}/actuator?endpoint={endpoint}",
"templated" : true
}, {
"href" : "http://localhost:9393/runtime/apps/{appId}/instances/{instanceId}/actuator",
"templated" : true
} ],
"runtime/apps/{appId}/instances/{instanceId}/post" : {
"href" : "http://localhost:9393/runtime/apps/{appId}/instances/{instanceId}/post",
"templated" : true
},
"streams/deployments" : {
"href" : "http://localhost:9393/streams/deployments"
},
"streams/deployments/{name}{?reuse-deployment-properties}" : {
"href" : "http://localhost:9393/streams/deployments/{name}?reuse-deployment-properties=false",
"templated" : true
},
"streams/deployments/{name}" : {
"href" : "http://localhost:9393/streams/deployments/{name}",
"templated" : true
},
"streams/deployments/history/{name}" : {
"href" : "http://localhost:9393/streams/deployments/history/{name}",
"templated" : true
},
"streams/deployments/manifest/{name}/{version}" : {
"href" : "http://localhost:9393/streams/deployments/manifest/{name}/{version}",
"templated" : true
},
"streams/deployments/platform/list" : {
"href" : "http://localhost:9393/streams/deployments/platform/list"
},
"streams/deployments/rollback/{name}/{version}" : {
"href" : "http://localhost:9393/streams/deployments/rollback/{name}/{version}",
"templated" : true
},
"streams/deployments/update/{name}" : {
"href" : "http://localhost:9393/streams/deployments/update/{name}",
"templated" : true
},
"streams/deployments/deployment" : {
"href" : "http://localhost:9393/streams/deployments/{name}",
"templated" : true
},
"streams/deployments/scale/{streamName}/{appName}/instances/{count}" : {
"href" : "http://localhost:9393/streams/deployments/scale/{streamName}/{appName}/instances/{count}",
"templated" : true
},
"streams/logs" : {
"href" : "http://localhost:9393/streams/logs"
},
"streams/logs/{streamName}" : {
"href" : "http://localhost:9393/streams/logs/{streamName}",
"templated" : true
},
"streams/logs/{streamName}/{appName}" : {
"href" : "http://localhost:9393/streams/logs/{streamName}/{appName}",
"templated" : true
},
"tasks/platforms" : {
"href" : "http://localhost:9393/tasks/platforms"
},
"tasks/definitions" : {
"href" : "http://localhost:9393/tasks/definitions"
},
"tasks/definitions/definition" : {
"href" : "http://localhost:9393/tasks/definitions/{name}",
"templated" : true
},
"tasks/executions" : {
"href" : "http://localhost:9393/tasks/executions"
},
"tasks/executions/external" : {
"href" : "http://localhost:9393/tasks/executions/external/{externalExecutionId}{?platform}",
"templated" : true
},
"tasks/executions/launch" : {
"href" : "http://localhost:9393/tasks/executions/launch?name={name}{&properties,arguments}",
"templated" : true
},
"tasks/executions/name" : {
"href" : "http://localhost:9393/tasks/executions{?name}",
"templated" : true
},
"tasks/executions/current" : {
"href" : "http://localhost:9393/tasks/executions/current"
},
"tasks/executions/execution" : {
"href" : "http://localhost:9393/tasks/executions/{id}{?schemaTarget}",
"templated" : true
},
"tasks/validation" : {
"href" : "http://localhost:9393/tasks/validation/{name}",
"templated" : true
},
"tasks/info/executions" : {
"href" : "http://localhost:9393/tasks/info/executions{?completed,name,days}",
"templated" : true
},
"tasks/logs" : {
"href" : "http://localhost:9393/tasks/logs/{taskExternalExecutionId}{?platformName,schemaTarget}",
"templated" : true
},
"tasks/thinexecutions" : {
"href" : "http://localhost:9393/tasks/thinexecutions"
},
"tasks/schedules" : {
"href" : "http://localhost:9393/tasks/schedules"
},
"tasks/schedules/instances" : {
"href" : "http://localhost:9393/tasks/schedules/instances/{taskDefinitionName}",
"templated" : true
},
"jobs/executions" : {
"href" : "http://localhost:9393/jobs/executions"
},
"jobs/executions/name" : {
"href" : "http://localhost:9393/jobs/executions{?name}",
"templated" : true
},
"jobs/executions/status" : {
"href" : "http://localhost:9393/jobs/executions{?status}",
"templated" : true
},
"jobs/executions/execution" : {
"href" : "http://localhost:9393/jobs/executions/{id}",
"templated" : true
},
"jobs/executions/execution/steps" : {
"href" : "http://localhost:9393/jobs/executions/{jobExecutionId}/steps",
"templated" : true
},
"jobs/executions/execution/steps/step" : {
"href" : "http://localhost:9393/jobs/executions/{jobExecutionId}/steps/{stepId}",
"templated" : true
},
"jobs/executions/execution/steps/step/progress" : {
"href" : "http://localhost:9393/jobs/executions/{jobExecutionId}/steps/{stepId}/progress",
"templated" : true
},
"jobs/instances/name" : {
"href" : "http://localhost:9393/jobs/instances{?name}",
"templated" : true
},
"jobs/instances/instance" : {
"href" : "http://localhost:9393/jobs/instances/{id}",
"templated" : true
},
"tools/parseTaskTextToGraph" : {
"href" : "http://localhost:9393/tools"
},
"tools/convertTaskGraphToText" : {
"href" : "http://localhost:9393/tools"
},
"jobs/thinexecutions" : {
"href" : "http://localhost:9393/jobs/thinexecutions"
},
"jobs/thinexecutions/name" : {
"href" : "http://localhost:9393/jobs/thinexecutions{?name}",
"templated" : true
},
"jobs/thinexecutions/jobInstanceId" : {
"href" : "http://localhost:9393/jobs/thinexecutions{?jobInstanceId}",
"templated" : true
},
"jobs/thinexecutions/taskExecutionId" : {
"href" : "http://localhost:9393/jobs/thinexecutions{?taskExecutionId}",
"templated" : true
},
"apps" : {
"href" : "http://localhost:9393/apps"
},
"about" : {
"href" : "http://localhost:9393/about"
},
"completions/stream" : {
"href" : "http://localhost:9393/completions/stream{?start,detailLevel}",
"templated" : true
},
"completions/task" : {
"href" : "http://localhost:9393/completions/task{?start,detailLevel}",
"templated" : true
}
},
"api.revision" : 14
}Links
The main element of the index are the links, as they let you traverse the API and execute the desired functionality:
| Relation | Description |
|---|---|
|
Access meta information, including enabled features, security info, version information |
|
Access the dashboard UI |
|
Provides audit trail information |
|
Handle registered applications |
|
Exposes the DSL completion features for Stream |
|
Exposes the DSL completion features for Task |
|
Provides the JobExecution resource |
|
Provides the JobExecution thin resource with no step executions included |
|
Provides details for a specific JobExecution |
|
Provides the steps for a JobExecution |
|
Returns the details for a specific step |
|
Provides progress information for a specific step |
|
Retrieve Job Executions by Job name |
|
Retrieve Job Executions by Job status |
|
Retrieve Job Executions by Job name with no step executions included |
|
Retrieve Job Executions by Job Instance Id with no step executions included |
|
Retrieve Job Executions by Task Execution Id with no step executions included |
|
Provides the job instance resource for a specific job instance |
|
Provides the Job instance resource for a specific job name |
|
Exposes stream runtime status |
|
Exposes streams runtime status for a given stream names |
|
Provides the runtime application resource |
|
Exposes the runtime status for a specific app |
|
Provides the status for app instances |
|
Provides the status for specific app instance |
|
EXPERIMENTAL: Allows invoking Actuator endpoint on specific app instance |
|
EXPERIMENTAL: Allows POST on http sink |
|
Provides the task definition resource |
|
Provides details for a specific task definition |
|
Provides the validation for a task definition |
|
Returns Task executions |
|
Provides for launching a Task execution |
|
Returns Task execution by external id |
|
Provides the current count of running tasks |
|
Provides the task executions info |
|
Provides schedule information of tasks |
|
Provides schedule information of a specific task |
|
Returns all task executions for a given Task name |
|
Provides details for a specific task execution |
|
Provides platform accounts for launching tasks. The results can be filtered to show the platforms that support scheduling by adding a request parameter of 'schedulesEnabled=true |
|
Retrieve the task application log |
|
Returns thin Task executions |
|
List of Spring Boot related schemas |
|
List of schema targets |
|
Exposes the Streams resource |
|
Handle a specific Stream definition |
|
Provides the validation for a stream definition |
|
Provides Stream deployment operations |
|
Request deployment info for a stream definition |
|
Request deployment info for a stream definition |
|
Request (un-)deployment of an existing stream definition |
|
Return a manifest info of a release version |
|
Get stream’s deployment history as list or Releases for this release |
|
Rollback the stream to the previous or a specific version of the stream |
|
Update the stream. |
|
List of supported deployment platforms |
|
Scale up or down number of application instances for a selected stream |
|
Retrieve application logs of the stream |
|
Retrieve application logs of the stream |
|
Retrieve a specific application log of the stream |
|
Parse a task definition into a graph structure |
|
Convert a graph format into DSL text format |
43.2. Server Meta Information
The server meta information endpoint provides more information about the server itself. The following topics provide more details:
43.2.1. Retrieving information about the server
A GET request returns meta information for Spring Cloud Data Flow, including:
-
Runtime environment information
-
Information regarding which features are enabled
-
Dependency information of Spring Cloud Data Flow Server
-
Security information
Response Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 2635
{
"featureInfo" : {
"analyticsEnabled" : true,
"streamsEnabled" : true,
"tasksEnabled" : true,
"schedulesEnabled" : true,
"monitoringDashboardType" : "NONE"
},
"versionInfo" : {
"implementation" : {
"name" : "${info.app.name}",
"version" : "2.11.5"
},
"core" : {
"name" : "Spring Cloud Data Flow Core",
"version" : "2.11.5"
},
"dashboard" : {
"name" : "Spring Cloud Dataflow UI",
"version" : "3.4.6"
},
"shell" : {
"name" : "Spring Cloud Data Flow Shell",
"version" : "2.11.5",
"url" : "https://repo.maven.apache.org/maven2/org/springframework/cloud/spring-cloud-dataflow-shell/2.11.5/spring-cloud-dataflow-shell-2.11.5.jar"
}
},
"securityInfo" : {
"authenticationEnabled" : false,
"authenticated" : false,
"username" : null,
"roles" : [ ]
},
"runtimeEnvironment" : {
"appDeployer" : {
"deployerImplementationVersion" : "Test Version",
"deployerName" : "Test Server",
"deployerSpiVersion" : "2.11.5",
"javaVersion" : "1.8.0_422",
"platformApiVersion" : "",
"platformClientVersion" : "",
"platformHostVersion" : "",
"platformSpecificInfo" : {
"default" : "local"
},
"platformType" : "Skipper Managed",
"springBootVersion" : "2.7.18",
"springVersion" : "5.3.39"
},
"taskLaunchers" : [ {
"deployerImplementationVersion" : "unknown",
"deployerName" : "LocalTaskLauncher",
"deployerSpiVersion" : "unknown",
"javaVersion" : "1.8.0_422",
"platformApiVersion" : "Linux 6.5.0-1025-azure",
"platformClientVersion" : "6.5.0-1025-azure",
"platformHostVersion" : "6.5.0-1025-azure",
"platformSpecificInfo" : { },
"platformType" : "Local",
"springBootVersion" : "2.7.18",
"springVersion" : "5.3.39"
} ]
},
"monitoringDashboardInfo" : {
"url" : "",
"refreshInterval" : 15,
"dashboardType" : "NONE",
"source" : "default-scdf-source"
},
"gitAndBuildInfo" : {
"git" : {
"commit" : {
"time" : "2024-04-24T11:35:29Z",
"id" : {
"abbrev" : "fddafed",
"full" : "fddafed39b919981cbb5bd04bd7fb5266fa25309"
}
},
"branch" : "main"
},
"build" : {
"version" : "2.11.3-SNAPSHOT",
"artifact" : "spring-cloud-dataflow-server",
"name" : "Spring Cloud Data Flow Server",
"group" : "org.springframework.cloud",
"time" : "2024-04-25T12:36:37.169Z"
}
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/about"
}
}
}43.3. Registered Applications
The registered applications endpoint provides information about the applications that are registered with the Spring Cloud Data Flow server. The following topics provide more details:
43.3.1. Listing Applications
A GET request lists all of the applications known to Spring Cloud Data Flow.
The following topics provide more details:
Request Structure
GET /apps?search=&type=source&defaultVersion=true&page=0&size=10&sort=name%2CASC HTTP/1.1
Accept: application/json
Host: localhost:9393Request Parameters
| Parameter | Description |
|---|---|
|
The search string performed on the name (optional) |
|
Restrict the returned apps to the type of the app. One of [app, source, processor, sink, task] |
|
The boolean flag to set to retrieve only the apps of the default versions (optional) |
|
The zero-based page number (optional) |
|
The sort on the list (optional) |
|
The requested page size (optional) |
Example Request
$ curl 'http://localhost:9393/apps?search=&type=source&defaultVersion=true&page=0&size=10&sort=name%2CASC' -i -X GET \
-H 'Accept: application/json'Response Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1151
{
"_embedded" : {
"appRegistrationResourceList" : [ {
"name" : "http",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.0.RELEASE",
"version" : "1.2.0.RELEASE",
"defaultVersion" : true,
"bootVersion" : "2",
"versions" : [ "1.2.0.RELEASE" ],
"label" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps/source/http/1.2.0.RELEASE"
}
}
}, {
"name" : "time",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:time-source-rabbit:1.2.0.RELEASE",
"version" : "1.2.0.RELEASE",
"defaultVersion" : true,
"bootVersion" : "2",
"versions" : [ "1.2.0.RELEASE" ],
"label" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps/source/time/1.2.0.RELEASE"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps?page=0&size=10&sort=name,asc"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}43.3.2. Getting Information on a Particular Application
A GET request on /apps/<type>/<name> gets info on a particular application.
The following topics provide more details:
Request Structure
GET /apps/source/http?exhaustive=false HTTP/1.1
Accept: application/json
Host: localhost:9393Request Parameters
| Parameter | Description |
|---|---|
|
Return all application properties, including common Spring Boot properties |
Path Parameters
/apps/{type}/{name}
| Parameter | Description |
|---|---|
|
The type of application to query. One of [app, source, processor, sink, task] |
|
The name of the application to query |
Example Request
$ curl 'http://localhost:9393/apps/source/http?exhaustive=false' -i -X GET \
-H 'Accept: application/json'Response Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 382
{
"name" : "http",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.0.RELEASE",
"version" : "1.2.0.RELEASE",
"defaultVersion" : true,
"bootVersion" : "2",
"versions" : null,
"label" : null,
"options" : [ ],
"shortDescription" : null,
"inboundPortNames" : [ ],
"outboundPortNames" : [ ],
"optionGroups" : { }
}43.3.3. Registering a New Application
A POST request on /apps/<type>/<name> allows registration of a new application.
The following topics provide more details:
Request Structure
POST /apps/source/http?bootVersion=2 HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
uri=maven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASERequest Parameters
| Parameter | Description |
|---|---|
|
URI where the application bits reside |
|
URI where the application metadata jar can be found |
|
The Spring Boot version of the application.Default is 2 |
|
Must be true if a registration with the same name and type already exists, otherwise an error will occur |
Path Parameters
/apps/{type}/{name}
| Parameter | Description |
|---|---|
|
The type of application to register. One of [app, source, processor, sink, task] |
|
The name of the application to register |
43.3.4. Registering a New Application with version
A POST request on /apps/<type>/<name>/<version> allows registration of a new application.
The following topics provide more details:
Request Structure
POST /apps/source/http/1.1.0.RELEASE?bootVersion=2 HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
uri=maven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASERequest Parameters
| Parameter | Description |
|---|---|
|
URI where the application bits reside |
|
URI where the application metadata jar can be found |
|
Must be true if a registration with the same name and type already exists, otherwise an error will occur |
|
Spring Boot version. Value of 2 or 3. Must be supplied of greater than 2. |
Path Parameters
/apps/{type}/{name}/{version:.+}
| Parameter | Description |
|---|---|
|
The type of application to register. One of [app, source, processor, sink, task] (optional) |
|
The name of the application to register |
|
The version of the application to register |
43.3.5. Registering Applications in Bulk
A POST request on /apps allows registering multiple applications at once.
The following topics provide more details:
Request Structure
POST /apps HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
apps=source.http%3Dmaven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE&force=falseRequest Parameters
| Parameter | Description |
|---|---|
|
URI where a properties file containing registrations can be fetched. Exclusive with |
|
Inline set of registrations. Exclusive with |
|
Must be true if a registration with the same name and type already exists, otherwise an error will occur |
Example Request
$ curl 'http://localhost:9393/apps' -i -X POST \
-d 'apps=source.http%3Dmaven%3A%2F%2Forg.springframework.cloud.stream.app%3Ahttp-source-rabbit%3A1.1.0.RELEASE&force=false'Response Structure
HTTP/1.1 201 Created
Content-Type: application/hal+json
Content-Length: 685
{
"_embedded" : {
"appRegistrationResourceList" : [ {
"name" : "http",
"type" : "source",
"uri" : "maven://org.springframework.cloud.stream.app:http-source-rabbit:1.1.0.RELEASE",
"version" : "1.1.0.RELEASE",
"defaultVersion" : true,
"bootVersion" : "2",
"versions" : null,
"label" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps/source/http/1.1.0.RELEASE"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/apps?page=0&size=20"
}
},
"page" : {
"size" : 20,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.3.6. Set the Default Application Version
For an application with the same name and type, you can register multiple versions.
In this case, you can choose one of the versions as the default application.
The following topics provide more details:
Request Structure
PUT /apps/source/http/1.2.0.RELEASE HTTP/1.1
Accept: application/json
Host: localhost:9393Path Parameters
/apps/{type}/{name}/{version:.+}
| Parameter | Description |
|---|---|
|
The type of application. One of [app, source, processor, sink, task] |
|
The name of the application |
|
The version of the application |
43.3.7. Unregistering an Application
A DELETE request on /apps/<type>/<name> unregisters a previously registered application.
The following topics provide more details:
43.4. Schema Information
The schema information endpoint provides information about the supported Spring Boot schema versions for Task and Batch applications and the available Schema Targets.
The following topics provide more details:
43.4.1. List All Schema Versions
The schema endpoint provides for listing supported Spring Boot versions.
The following topics provide more details:
43.4.2. List All Schema Targets
The schema endpoint provides for listing supported Schema Targets.
The following topics provide more details:
Example Request
$ curl 'http://localhost:9393/schema/targets' -i -X GET \
-H 'Accept: application/json'Response Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 660
{
"defaultSchemaTarget" : "boot2",
"schemas" : [ {
"name" : "boot3",
"schemaVersion" : "3",
"taskPrefix" : "BOOT3_TASK_",
"batchPrefix" : "BOOT3_BATCH_",
"datasource" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/schema/targets/boot3"
}
}
}, {
"name" : "boot2",
"schemaVersion" : "2",
"taskPrefix" : "TASK_",
"batchPrefix" : "BATCH_",
"datasource" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/schema/targets/boot2"
}
}
} ],
"_links" : {
"self" : {
"href" : "http://localhost:9393/schema/targets"
}
}
}43.5. Audit Records
The audit records endpoint provides information about the audit records. The following topics provide more details:
43.5.1. List All Audit Records
The audit records endpoint lets you retrieve audit trail information.
The following topics provide more details:
Request Structure
GET /audit-records?page=0&size=10&operations=STREAM&actions=CREATE&fromDate=2000-01-01T00%3A00%3A00&toDate=2099-01-01T00%3A00%3A00 HTTP/1.1
Host: localhost:9393Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
|
Comma-separated list of Audit Operations (optional) |
|
Comma-separated list of Audit Actions (optional) |
|
From date filter (ex.: 2019-02-03T00:00:30) (optional) |
|
To date filter (ex.: 2019-02-03T00:00:30) (optional) |
Example Request
$ curl 'http://localhost:9393/audit-records?page=0&size=10&operations=STREAM&actions=CREATE&fromDate=2000-01-01T00%3A00%3A00&toDate=2099-01-01T00%3A00%3A00' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 680
{
"_embedded" : {
"auditRecordResourceList" : [ {
"auditRecordId" : 5,
"createdBy" : null,
"correlationId" : "timelog",
"auditData" : "time --format='YYYY MM DD' | log",
"createdOn" : "2024-09-13T10:11:46.663Z",
"auditAction" : "CREATE",
"auditOperation" : "STREAM",
"platformName" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/audit-records/5"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/audit-records?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.5.2. Retrieve Audit Record Detail
The audit record endpoint lets you get a single audit record. The following topics provide more details:
Path Parameters
/audit-records/{id}
| Parameter | Description |
|---|---|
|
The id of the audit record to query (required) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 354
{
"auditRecordId" : 5,
"createdBy" : null,
"correlationId" : "timelog",
"auditData" : "time --format='YYYY MM DD' | log",
"createdOn" : "2024-09-13T10:11:45.673Z",
"auditAction" : "CREATE",
"auditOperation" : "STREAM",
"platformName" : null,
"_links" : {
"self" : {
"href" : "http://localhost:9393/audit-records/5"
}
}
}43.5.3. List all the Audit Action Types
The audit record endpoint lets you get the action types. The following topics provide more details:
Response Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1111
[ {
"id" : 100,
"name" : "Create",
"description" : "Create an Entity",
"nameWithDescription" : "Create (Create an Entity)",
"key" : "CREATE"
}, {
"id" : 200,
"name" : "Delete",
"description" : "Delete an Entity",
"nameWithDescription" : "Delete (Delete an Entity)",
"key" : "DELETE"
}, {
"id" : 300,
"name" : "Deploy",
"description" : "Deploy an Entity",
"nameWithDescription" : "Deploy (Deploy an Entity)",
"key" : "DEPLOY"
}, {
"id" : 400,
"name" : "Rollback",
"description" : "Rollback an Entity",
"nameWithDescription" : "Rollback (Rollback an Entity)",
"key" : "ROLLBACK"
}, {
"id" : 500,
"name" : "Undeploy",
"description" : "Undeploy an Entity",
"nameWithDescription" : "Undeploy (Undeploy an Entity)",
"key" : "UNDEPLOY"
}, {
"id" : 600,
"name" : "Update",
"description" : "Update an Entity",
"nameWithDescription" : "Update (Update an Entity)",
"key" : "UPDATE"
}, {
"id" : 700,
"name" : "SuccessfulLogin",
"description" : "Successful login",
"nameWithDescription" : "SuccessfulLogin (Successful login)",
"key" : "LOGIN_SUCCESS"
} ]43.5.4. List all the Audit Operation Types
The audit record endpoint lets you get the operation types. The following topics provide more details:
Response Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 315
[ {
"id" : 100,
"name" : "App Registration",
"key" : "APP_REGISTRATION"
}, {
"id" : 200,
"name" : "Schedule",
"key" : "SCHEDULE"
}, {
"id" : 300,
"name" : "Stream",
"key" : "STREAM"
}, {
"id" : 400,
"name" : "Task",
"key" : "TASK"
}, {
"id" : 500,
"name" : "Login",
"key" : "LOGIN"
} ]43.6. Stream Definitions
The registered applications endpoint provides information about the stream definitions that are registered with the Spring Cloud Data Flow server. The following topics provide more details:
43.6.1. Creating a New Stream Definition
Creating a stream definition is achieved by creating a POST request to the stream definitions endpoint.
A curl request for a ticktock stream might resemble the following:
curl -X POST -d "name=ticktock&definition=time | log" localhost:9393/streams/definitions?deploy=falseA stream definition can also contain additional parameters. For instance, in the example shown under “Request Structure”, we also provide the date-time format.
The following topics provide more details:
Request Structure
POST /streams/definitions HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
name=timelog&definition=time+--format%3D%27YYYY+MM+DD%27+%7C+log&description=Demo+stream+for+testing&deploy=falseRequest Parameters
| Parameter | Description |
|---|---|
|
The name for the created task definitions |
|
The definition for the stream, using Data Flow DSL |
|
The description of the stream definition |
|
If true, the stream is deployed upon creation (default is false) |
Example Request
$ curl 'http://localhost:9393/streams/definitions' -i -X POST \
-d 'name=timelog&definition=time+--format%3D%27YYYY+MM+DD%27+%7C+log&description=Demo+stream+for+testing&deploy=false'Response Structure
HTTP/1.1 201 Created
Content-Type: application/hal+json
Content-Length: 410
{
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"originalDslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"description" : "Demo stream for testing",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
}43.6.2. List All Stream Definitions
The streams endpoint lets you list all the stream definitions. The following topics provide more details:
Request Structure
GET /streams/definitions?page=0&sort=name%2CASC&search=&size=10 HTTP/1.1
Host: localhost:9393Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The search string performed on the name (optional) |
|
The sort on the list (optional) |
|
The requested page size (optional) |
Example Request
$ curl 'http://localhost:9393/streams/definitions?page=0&sort=name%2CASC&search=&size=10' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 730
{
"_embedded" : {
"streamDefinitionResourceList" : [ {
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"originalDslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"description" : "",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions?page=0&size=10&sort=name,asc"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.6.3. List Related Stream Definitions
The streams endpoint lets you list related stream definitions. The following topics provide more details:
Request Structure
GET /streams/definitions/timelog/related?page=0&sort=name%2CASC&search=&size=10&nested=true HTTP/1.1
Host: localhost:9393Request Parameters
| Parameter | Description |
|---|---|
|
Should we recursively findByTaskNameContains for related stream definitions (optional) |
|
The zero-based page number (optional) |
|
The search string performed on the name (optional) |
|
The sort on the list (optional) |
|
The requested page size (optional) |
Example Request
$ curl 'http://localhost:9393/streams/definitions/timelog/related?page=0&sort=name%2CASC&search=&size=10&nested=true' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 746
{
"_embedded" : {
"streamDefinitionResourceList" : [ {
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"originalDslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"description" : "",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog/related?page=0&size=10&sort=name,asc"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.6.4. Retrieve Stream Definition Detail
The stream definition endpoint lets you get a single stream definition. The following topics provide more details:
Path Parameters
/streams/definitions/{name}
| Parameter | Description |
|---|---|
|
The name of the stream definition to query (required) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 387
{
"name" : "timelog",
"dslText" : "time --format='YYYY MM DD' | log",
"originalDslText" : "time --format='YYYY MM DD' | log",
"status" : "undeployed",
"description" : "",
"statusDescription" : "The app or group is known to the system, but is not currently deployed",
"_links" : {
"self" : {
"href" : "http://localhost:9393/streams/definitions/timelog"
}
}
}43.6.5. Delete a Single Stream Definition
The streams endpoint lets you delete a single stream definition. (See also: Delete All Stream Definitions.) The following topics provide more details:
43.6.6. Delete All Stream Definitions
The streams endpoint lets you delete all single stream definitions. (See also: Delete a Single Stream Definition.) The following topics provide more details:
43.7. Stream Validation
The stream validation endpoint lets you validate the apps in a stream definition. The following topics provide more details:
43.8. Stream Deployments
The deployment definitions endpoint provides information about the deployments that are registered with the Spring Cloud Data Flow server. The following topics provide more details:
43.8.1. Deploying Stream Definition
The stream definition endpoint lets you deploy a single stream definition. Optionally, you can pass application parameters as properties in the request body. The following topics provide more details:
Request Structure
POST /streams/deployments/timelog HTTP/1.1
Content-Type: application/json
Content-Length: 36
Host: localhost:9393
{"app.time.timestamp.format":"YYYY"}/streams/deployments/{timelog}
| Parameter | Description |
|---|---|
|
The name of an existing stream definition (required) |
43.8.2. Undeploy Stream Definition
The stream definition endpoint lets you undeploy a single stream definition. The following topics provide more details:
43.8.3. Undeploy All Stream Definitions
The stream definition endpoint lets you undeploy all single stream definitions. The following topics provide more details:
43.8.4. Update Deployed Stream
Thanks to Skipper, you can update deployed streams, and provide additional deployment properties.
Request Structure
POST /streams/deployments/update/timelog1 HTTP/1.1
Content-Type: application/json
Content-Length: 196
Host: localhost:9393
{"releaseName":"timelog1","packageIdentifier":{"repositoryName":"test","packageName":"timelog1","packageVersion":"1.0.0"},"updateProperties":{"app.time.timestamp.format":"YYYYMMDD"},"force":false}/streams/deployments/update/{timelog1}
| Parameter | Description |
|---|---|
|
The name of an existing stream definition (required) |
Example Request
$ curl 'http://localhost:9393/streams/deployments/update/timelog1' -i -X POST \
-H 'Content-Type: application/json' \
-d '{"releaseName":"timelog1","packageIdentifier":{"repositoryName":"test","packageName":"timelog1","packageVersion":"1.0.0"},"updateProperties":{"app.time.timestamp.format":"YYYYMMDD"},"force":false}'43.8.5. Rollback Stream Definition
Rollback the stream to the previous or a specific version of the stream.
Request Structure
POST /streams/deployments/rollback/timelog1/1 HTTP/1.1
Content-Type: application/json
Host: localhost:9393/streams/deployments/rollback/{name}/{version}
| Parameter | Description |
|---|---|
|
The name of an existing stream definition (required) |
|
The version to rollback to |
43.8.6. Get Manifest
Return a manifest of a released version. For packages with dependencies, the manifest includes the contents of those dependencies.
Request Structure
GET /streams/deployments/manifest/timelog1/1 HTTP/1.1
Content-Type: application/json
Host: localhost:9393/streams/deployments/manifest/{name}/{version}
| Parameter | Description |
|---|---|
|
The name of an existing stream definition (required) |
|
The version of the stream |
43.8.7. Get Deployment History
Get the stream’s deployment history.
Request Structure
GET /streams/deployments/history/timelog1 HTTP/1.1
Content-Type: application/json
Host: localhost:939343.8.8. Get Deployment Platforms
Retrieve a list of supported deployment platforms.
Request Structure
GET /streams/deployments/platform/list HTTP/1.1
Content-Type: application/json
Host: localhost:939343.8.9. Scale Stream Definition
The stream definition endpoint lets you scale a single app in a stream definition. Optionally, you can pass application parameters as properties in the request body. The following topics provide more details:
Request Structure
POST /streams/deployments/scale/timelog/log/instances/1 HTTP/1.1
Content-Type: application/json
Content-Length: 36
Host: localhost:9393
{"app.time.timestamp.format":"YYYY"}/streams/deployments/scale/{streamName}/{appName}/instances/{count}
| Parameter | Description |
|---|---|
|
the name of an existing stream definition (required) |
|
in stream application name to scale |
|
number of instances for the selected stream application (required) |
43.9. Task Definitions
The task definitions endpoint provides information about the task definitions that are registered with the Spring Cloud Data Flow server. The following topics provide more details:
43.9.1. Creating a New Task Definition
The task definition endpoint lets you create a new task definition. The following topics provide more details:
Request Structure
POST /tasks/definitions HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
name=my-task&definition=timestamp+--format%3D%27YYYY+MM+DD%27&description=Demo+task+definition+for+testingRequest Parameters
| Parameter | Description |
|---|---|
|
The name for the created task definition |
|
The definition for the task, using Data Flow DSL |
|
The description of the task definition |
Example Request
$ curl 'http://localhost:9393/tasks/definitions' -i -X POST \
-d 'name=my-task&definition=timestamp+--format%3D%27YYYY+MM+DD%27&description=Demo+task+definition+for+testing'Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 342
{
"name" : "my-task",
"dslText" : "timestamp --format='YYYY MM DD'",
"description" : "Demo task definition for testing",
"composed" : false,
"composedTaskElement" : false,
"lastTaskExecution" : null,
"status" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions/my-task"
}
}
}43.9.2. List All Task Definitions
The task definition endpoint lets you get all task definitions. The following topics provide more details:
Request Structure
GET /tasks/definitions?page=0&size=10&sort=taskName%2CASC&search=&manifest=true HTTP/1.1
Host: localhost:9393Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
|
The search string performed on the name (optional) |
|
The sort on the list (optional) |
|
The flag to include the task manifest into the latest task execution (optional) |
Example Request
$ curl 'http://localhost:9393/tasks/definitions?page=0&size=10&sort=taskName%2CASC&search=&manifest=true' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 689
{
"_embedded" : {
"taskDefinitionResourceList" : [ {
"name" : "my-task",
"dslText" : "timestamp --format='YYYY MM DD'",
"description" : "Demo task definition for testing",
"composed" : false,
"composedTaskElement" : false,
"lastTaskExecution" : null,
"status" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions/my-task"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions?page=0&size=10&sort=taskName,asc"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.9.3. Retrieve Task Definition Detail
The task definition endpoint lets you get a single task definition. The following topics provide more details:
Request Structure
GET /tasks/definitions/my-task?manifest=true HTTP/1.1
Host: localhost:9393/tasks/definitions/{my-task}
| Parameter | Description |
|---|---|
|
The name of an existing task definition (required) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 342
{
"name" : "my-task",
"dslText" : "timestamp --format='YYYY MM DD'",
"description" : "Demo task definition for testing",
"composed" : false,
"composedTaskElement" : false,
"lastTaskExecution" : null,
"status" : "UNKNOWN",
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/definitions/my-task"
}
}
}43.9.4. Delete Task Definition
The task definition endpoint lets you delete a single task definition. The following topics provide more details:
43.10. Task Scheduler
The task scheduler endpoint provides information about the task schedules that are registered with the Scheduler Implementation. The following topics provide more details:
43.10.1. Creating a New Task Schedule
The task schedule endpoint lets you create a new task schedule. The following topics provide more details:
Request Structure
POST /tasks/schedules HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
scheduleName=myschedule&taskDefinitionName=mytaskname&platform=default&properties=scheduler.cron.expression%3D00+22+17+%3F+*&arguments=--foo%3DbarRequest Parameters
| Parameter | Description |
|---|---|
|
The name for the created schedule |
|
The name of the platform the task is launched |
|
The name of the task definition to be scheduled |
|
the properties that are required to schedule and launch the task |
|
the command line arguments to be used for launching the task |
43.10.2. List All Schedules
The task schedules endpoint lets you get all task schedules. The following topics provide more details:
Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 587
{
"_embedded" : {
"scheduleInfoResourceList" : [ {
"scheduleName" : "FOO",
"taskDefinitionName" : "BAR",
"scheduleProperties" : {
"scheduler.AAA.spring.cloud.scheduler.cron.expression" : "00 41 17 ? * *"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules/FOO"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.10.3. List Filtered Schedules
The task schedules endpoint lets you get all task schedules that have the specified task definition name. The following topics provide more details:
Request Structure
GET /tasks/schedules/instances/FOO?page=0&size=10 HTTP/1.1
Host: localhost:9393/tasks/schedules/instances/{task-definition-name}
| Parameter | Description |
|---|---|
|
Filter schedules based on the specified task definition (required) |
Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
Example Request
$ curl 'http://localhost:9393/tasks/schedules/instances/FOO?page=0&size=10' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 599
{
"_embedded" : {
"scheduleInfoResourceList" : [ {
"scheduleName" : "FOO",
"taskDefinitionName" : "BAR",
"scheduleProperties" : {
"scheduler.AAA.spring.cloud.scheduler.cron.expression" : "00 41 17 ? * *"
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules/FOO"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/schedules/instances/FOO?page=0&size=1"
}
},
"page" : {
"size" : 1,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.10.4. Delete Task Schedule
The task schedule endpoint lets you delete a single task schedule. The following topics provide more details:
43.11. Task Validation
The task validation endpoint lets you validate the apps in a task definition. The following topics provide more details:
43.12. Task Executions
The task executions endpoint provides information about the task executions that are registered with the Spring Cloud Data Flow server. The following topics provide more details:
43.12.1. Launching a Task (Legacy)
Launching a task is done by requesting the creation of a new task execution. This endpoint will fail if the task is registered as a Spring Boot 3 application.
The following topics provide more details:
Request Structure
POST /tasks/executions HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
name=taskA&properties=app.my-task.foo%3Dbar%2Cdeployer.my-task.something-else%3D3&arguments=--server.port%3D8080+--foo%3DbarRequest Parameters
| Parameter | Description |
|---|---|
|
The name of the task definition to launch |
|
Application and Deployer properties to use while launching. (optional) |
|
Command line arguments to pass to the task. (optional) |
43.12.2. Launching a Task
Launching a task is done by requesting the creation of a new task execution. The response will contain an execution id and a schema target.
The following topics provide more details:
Request Structure
POST /tasks/executions/launch HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
name=taskA&properties=app.my-task.foo%3Dbar%2Cdeployer.my-task.something-else%3D3&arguments=--server.port%3D8080+--foo%3DbarRequest Parameters
| Parameter | Description |
|---|---|
|
The name of the task definition to launch |
|
Application and Deployer properties to use while launching. (optional) |
|
Command line arguments to pass to the task. (optional) |
43.12.3. Stopping a Task
Stopping a task is done by posting the id of an existing task execution. The following topics provide more details:
Path Parameters
/tasks/executions/{id}
| Parameter | Description |
|---|---|
|
The ids of an existing task execution (required) |
43.12.4. List All Task Executions
The task executions endpoint lets you list all task executions. The following topics provide more details:
Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 2497
{
"_embedded" : {
"taskExecutionResourceList" : [ {
"executionId" : 1,
"exitCode" : null,
"taskName" : "taskA",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskA-e4fc87e5-dbd7-450e-935e-69470d10afe9",
"parentExecutionId" : null,
"resourceUrl" : "org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE",
"appProperties" : {
"spring.datasource.driverClassName" : null,
"management.metrics.tags.application" : "${spring.cloud.task.name:unknown}-${spring.cloud.task.executionid:unknown}",
"format" : "yyyy MM dd",
"spring.cloud.task.name" : "taskA",
"spring.cloud.deployer.bootVersion" : "2",
"management.metrics.tags.service" : "task-application",
"spring.datasource.username" : null,
"spring.datasource.url" : null,
"spring.cloud.task.initialize-enabled" : "false",
"spring.cloud.task.schemaTarget" : "boot2",
"spring.batch.jdbc.table-prefix" : "BATCH_",
"spring.cloud.task.tablePrefix" : "TASK_"
},
"deploymentProperties" : {
"app.timestamp.spring.cloud.task.tablePrefix" : "TASK_",
"app.timestamp.spring.cloud.deployer.bootVersion" : "2",
"app.timestamp.spring.cloud.task.initialize-enabled" : "false",
"app.timestamp.spring.batch.jdbc.table-prefix" : "BATCH_",
"app.timestamp.spring.cloud.task.schemaTarget" : "boot2"
},
"platformName" : "default",
"taskExecutionStatus" : "UNKNOWN",
"schemaTarget" : "boot2",
"_links" : {
"tasks/logs" : {
"href" : "http://localhost:9393/tasks/logs/taskA-e4fc87e5-dbd7-450e-935e-69470d10afe9?platformName=default&schemaTarget=boot2"
},
"self" : {
"href" : "http://localhost:9393/tasks/executions/1?schemaTarget=boot2"
}
}
} ]
},
"_links" : {
"first" : {
"href" : "http://localhost:9393/tasks/executions?page=0&size=2"
},
"prev" : {
"href" : "http://localhost:9393/tasks/executions?page=0&size=2"
},
"self" : {
"href" : "http://localhost:9393/tasks/executions?page=1&size=2"
},
"last" : {
"href" : "http://localhost:9393/tasks/executions?page=1&size=2"
}
},
"page" : {
"size" : 2,
"totalElements" : 3,
"totalPages" : 2,
"number" : 1
}
}43.12.5. List All Task Executions With a Specified Task Name
The task executions endpoint lets you list task executions with a specified task name. The following topics provide more details:
Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
|
The name associated with the task execution |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 2222
{
"_embedded" : {
"taskExecutionResourceList" : [ {
"executionId" : 2,
"exitCode" : null,
"taskName" : "taskB",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskB-cd70929e-1495-4f72-bc22-008f919e2b5a",
"parentExecutionId" : null,
"resourceUrl" : "org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE",
"appProperties" : {
"spring.datasource.driverClassName" : null,
"management.metrics.tags.application" : "${spring.cloud.task.name:unknown}-${spring.cloud.task.executionid:unknown}",
"format" : "yyyy MM dd",
"spring.cloud.task.name" : "taskB",
"spring.cloud.deployer.bootVersion" : "2",
"management.metrics.tags.service" : "task-application",
"spring.datasource.username" : null,
"spring.datasource.url" : null,
"spring.cloud.task.initialize-enabled" : "false",
"spring.cloud.task.schemaTarget" : "boot2",
"spring.batch.jdbc.table-prefix" : "BATCH_",
"spring.cloud.task.tablePrefix" : "TASK_"
},
"deploymentProperties" : {
"app.timestamp.spring.cloud.task.tablePrefix" : "TASK_",
"app.timestamp.spring.cloud.deployer.bootVersion" : "2",
"app.timestamp.spring.cloud.task.initialize-enabled" : "false",
"app.timestamp.spring.batch.jdbc.table-prefix" : "BATCH_",
"app.timestamp.spring.cloud.task.schemaTarget" : "boot2"
},
"platformName" : "default",
"taskExecutionStatus" : "UNKNOWN",
"schemaTarget" : "boot2",
"_links" : {
"tasks/logs" : {
"href" : "http://localhost:9393/tasks/logs/taskB-cd70929e-1495-4f72-bc22-008f919e2b5a?platformName=default&schemaTarget=boot2"
},
"self" : {
"href" : "http://localhost:9393/tasks/executions/2?schemaTarget=boot2"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/tasks/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.12.6. Task Execution Detail
The task executions endpoint lets you get the details about a task execution. The following topics provide more details:
Request Structure
GET /tasks/executions/1?schemaTarget=boot2 HTTP/1.1
Host: localhost:9393/tasks/executions/{id}
| Parameter | Description |
|---|---|
|
The id of an existing task execution (required) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1767
{
"executionId" : 1,
"exitCode" : null,
"taskName" : "taskA",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskA-43aeab47-b46a-49ba-ba7b-f045dec094e4",
"parentExecutionId" : null,
"resourceUrl" : "org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE",
"appProperties" : {
"spring.datasource.driverClassName" : null,
"management.metrics.tags.application" : "${spring.cloud.task.name:unknown}-${spring.cloud.task.executionid:unknown}",
"format" : "yyyy MM dd",
"spring.cloud.task.name" : "taskA",
"spring.cloud.deployer.bootVersion" : "2",
"management.metrics.tags.service" : "task-application",
"spring.datasource.username" : null,
"spring.datasource.url" : null,
"spring.cloud.task.initialize-enabled" : "false",
"spring.cloud.task.schemaTarget" : "boot2",
"spring.batch.jdbc.table-prefix" : "BATCH_",
"spring.cloud.task.tablePrefix" : "TASK_"
},
"deploymentProperties" : {
"app.timestamp.spring.cloud.task.tablePrefix" : "TASK_",
"app.timestamp.spring.cloud.deployer.bootVersion" : "2",
"app.timestamp.spring.cloud.task.initialize-enabled" : "false",
"app.timestamp.spring.batch.jdbc.table-prefix" : "BATCH_",
"app.timestamp.spring.cloud.task.schemaTarget" : "boot2"
},
"platformName" : "default",
"taskExecutionStatus" : "UNKNOWN",
"schemaTarget" : "boot2",
"_links" : {
"tasks/logs" : {
"href" : "http://localhost:9393/tasks/logs/taskA-43aeab47-b46a-49ba-ba7b-f045dec094e4?platformName=default&schemaTarget=boot2"
},
"self" : {
"href" : "http://localhost:9393/tasks/executions/1?schemaTarget=boot2"
}
}
}43.12.7. Task Execution Detail by External Id
The task executions endpoint lets you get the details about a task execution. The following topics provide more details:
Request Structure
GET /tasks/executions/external/taskB-026bd08c-18b8-4255-ad77-c2fcc9d09bb8?platform=default HTTP/1.1
Host: localhost:9393/tasks/executions/external/{externalExecutionId}
| Parameter | Description |
|---|---|
|
The external ExecutionId of an existing task execution (required) |
Example Request
$ curl 'http://localhost:9393/tasks/executions/external/taskB-026bd08c-18b8-4255-ad77-c2fcc9d09bb8?platform=default' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1767
{
"executionId" : 2,
"exitCode" : null,
"taskName" : "taskB",
"startTime" : null,
"endTime" : null,
"exitMessage" : null,
"arguments" : [ ],
"jobExecutionIds" : [ ],
"errorMessage" : null,
"externalExecutionId" : "taskB-026bd08c-18b8-4255-ad77-c2fcc9d09bb8",
"parentExecutionId" : null,
"resourceUrl" : "org.springframework.cloud.task.app:timestamp-task:jar:1.2.0.RELEASE",
"appProperties" : {
"spring.datasource.driverClassName" : null,
"management.metrics.tags.application" : "${spring.cloud.task.name:unknown}-${spring.cloud.task.executionid:unknown}",
"format" : "yyyy MM dd",
"spring.cloud.task.name" : "taskB",
"spring.cloud.deployer.bootVersion" : "2",
"management.metrics.tags.service" : "task-application",
"spring.datasource.username" : null,
"spring.datasource.url" : null,
"spring.cloud.task.initialize-enabled" : "false",
"spring.cloud.task.schemaTarget" : "boot2",
"spring.batch.jdbc.table-prefix" : "BATCH_",
"spring.cloud.task.tablePrefix" : "TASK_"
},
"deploymentProperties" : {
"app.timestamp.spring.cloud.task.tablePrefix" : "TASK_",
"app.timestamp.spring.cloud.deployer.bootVersion" : "2",
"app.timestamp.spring.cloud.task.initialize-enabled" : "false",
"app.timestamp.spring.batch.jdbc.table-prefix" : "BATCH_",
"app.timestamp.spring.cloud.task.schemaTarget" : "boot2"
},
"platformName" : "default",
"taskExecutionStatus" : "UNKNOWN",
"schemaTarget" : "boot2",
"_links" : {
"tasks/logs" : {
"href" : "http://localhost:9393/tasks/logs/taskB-026bd08c-18b8-4255-ad77-c2fcc9d09bb8?platformName=default&schemaTarget=boot2"
},
"self" : {
"href" : "http://localhost:9393/tasks/executions/2?schemaTarget=boot2"
}
}
}43.12.8. Delete Task Execution
The task execution endpoint lets you:
-
Clean up resources used to deploy the task
-
Remove relevant task data as well as possibly associated Spring Batch job data from the persistence store
| The cleanup implementation (first option) is platform specific. Both operations can be triggered at once or separately. |
The following topics provide more details:
Please refer to the following section in regards to Deleting Task Execution Data.
Request Structure
DELETE /tasks/executions/1,2?schemaTarget=boot2&action=CLEANUP,REMOVE_DATA HTTP/1.1
Host: localhost:9393/tasks/executions/{ids}
| Parameter | Description |
|---|---|
|
Providing 2 comma separated task execution id values. |
|
You must provide task execution IDs that actually exist. Otherwise, a |
Request Parameters
This endpoint supports one optional request parameter named action. It is an enumeration and supports the following values:
-
CLEANUP
-
REMOVE_DATA
| Parameter | Description |
|---|---|
|
Using both actions CLEANUP and REMOVE_DATA simultaneously. |
|
Schema target for task. (optional) |
43.12.9. Deleting Task Execution Data
Not only can you clean up resources that were used to deploy tasks but you can also delete the data associated with task executions from the underlying persistence store. Also, if a task execution is associated with one or more batch job executions, these are removed as well.
The following example illustrates how a request can be made using multiple task execution IDs and multiple actions:
$ curl 'http://localhost:9393/tasks/executions/1,2?schemaTarget=boot2&action=CLEANUP,REMOVE_DATA' -i -X DELETE/tasks/executions/{ids}
| Parameter | Description |
|---|---|
|
Providing 2 comma separated task execution id values. |
| Parameter | Description |
|---|---|
|
Using both actions CLEANUP and REMOVE_DATA simultaneously. |
|
Schema target for task. (optional) |
When deleting data from the persistence store by using the REMOVE_DATA action parameter, you must provide
task execution IDs that represent parent task executions. When you provide child task executions (executed as part of a composed task),
a 400 (Bad Request) HTTP status is returned.
|
When deleting large number of task executions some database types limit the number of entries in the IN clause (the method Spring Cloud Data Flow uses to delete relationships for task executions).
Spring Cloud Data Flow supports the chunking of deletes for Sql Server (Maximum 2100 entries) and Oracle DBs (Maximum 1000 entries).
However, Spring Cloud Data Flow allows users to set their own chunking factor. To do this set the spring.cloud.dataflow.task.executionDeleteChunkSize property to the appropriate chunk size.
Default is 0 which means Spring Cloud Data Flow will not chunk the task execution deletes (except for Oracle and Sql Server databases).
|
43.13. Job Executions
The job executions endpoint provides information about the job executions that are registered with the Spring Cloud Data Flow server. The following topics provide more details:
-
List All Job Executions With a Specified Job Name Without Step Executions Included
-
List All Job Executions For A Specified Date Range Without Step Executions Included
-
List All Job Executions For A Specified Job Instance Id Without Step Executions Included
-
List All Job Executions For A Specified Task Execution Id Without Step Executions Included
43.13.1. List All Job Executions
The job executions endpoint lets you list all job executions. The following topics provide more details:
Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 3658
{
"_embedded" : {
"jobExecutionResourceList" : [ {
"executionId" : 2,
"stepExecutionCount" : 0,
"jobId" : 2,
"taskExecutionId" : 2,
"name" : "DOCJOB1",
"startDate" : "2024-09-13",
"startTime" : "10:11:18",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 2,
"version" : 1,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 2,
"jobName" : "DOCJOB1",
"version" : null
},
"stepExecutions" : [ ],
"status" : "STOPPED",
"startTime" : "2024-09-13T10:11:18.778+0000",
"createTime" : "2024-09-13T10:11:18.777+0000",
"endTime" : null,
"lastUpdated" : "2024-09-13T10:11:18.778+0000",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"jobConfigurationName" : null,
"failureExceptions" : [ ],
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : true,
"abandonable" : true,
"stoppable" : false,
"defined" : true,
"timeZone" : "UTC",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/2?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/2?schemaTarget=boot2&stop=true"
},
"restart" : {
"href" : "http://localhost:9393/jobs/executions/2?schemaTarget=boot2&restart=true"
}
}
}, {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "2024-09-13",
"startTime" : "10:11:18",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 1,
"version" : 1,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 1,
"jobName" : "DOCJOB",
"version" : null
},
"stepExecutions" : [ ],
"status" : "STARTED",
"startTime" : "2024-09-13T10:11:18.773+0000",
"createTime" : "2024-09-13T10:11:18.772+0000",
"endTime" : null,
"lastUpdated" : "2024-09-13T10:11:18.773+0000",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"jobConfigurationName" : null,
"failureExceptions" : [ ],
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : true,
"timeZone" : "UTC",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2&stop=true"
},
"restart" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2&restart=true"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}43.13.2. List All Job Executions Without Step Executions Included
The job executions endpoint lets you list all job executions without step executions included. The following topics provide more details:
Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1937
{
"_embedded" : {
"jobExecutionThinResourceList" : [ {
"executionId" : 2,
"stepExecutionCount" : 0,
"jobId" : 2,
"taskExecutionId" : 2,
"instanceId" : 2,
"name" : "DOCJOB1",
"startDate" : "2024-09-13",
"startTime" : "10:11:14",
"startDateTime" : "2024-09-13T10:11:14.840+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : true,
"abandonable" : true,
"stoppable" : false,
"defined" : true,
"timeZone" : "UTC",
"status" : "STOPPED",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/2?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/2?schemaTarget=boot2&stop=true"
}
}
}, {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"instanceId" : 1,
"name" : "DOCJOB",
"startDate" : "2024-09-13",
"startTime" : "10:11:14",
"startDateTime" : "2024-09-13T10:11:14.752+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : true,
"timeZone" : "UTC",
"status" : "STARTED",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2&stop=true"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}43.13.3. List All Job Executions With a Specified Job Name
The job executions endpoint lets you list all job executions. The following topics provide more details:
Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
|
The name associated with the job execution |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1964
{
"_embedded" : {
"jobExecutionResourceList" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "2024-09-13",
"startTime" : "10:11:20",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 1,
"version" : 1,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 1,
"jobName" : "DOCJOB",
"version" : null
},
"stepExecutions" : [ ],
"status" : "STARTED",
"startTime" : "2024-09-13T10:11:20.627+0000",
"createTime" : "2024-09-13T10:11:20.626+0000",
"endTime" : null,
"lastUpdated" : "2024-09-13T10:11:20.627+0000",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"jobConfigurationName" : null,
"failureExceptions" : [ ],
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : true,
"timeZone" : "UTC",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2&stop=true"
},
"restart" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2&restart=true"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.13.4. List All Job Executions With a Specified Job Name Without Step Executions Included
The job executions endpoint lets you list all job executions. The following topics provide more details:
Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
|
The name associated with the job execution |
Example Request
$ curl 'http://localhost:9393/jobs/thinexecutions?name=DOCJOB&page=0&size=10' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1108
{
"_embedded" : {
"jobExecutionThinResourceList" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"instanceId" : 1,
"name" : "DOCJOB",
"startDate" : "2024-09-13",
"startTime" : "10:11:23",
"startDateTime" : "2024-09-13T10:11:23.869+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : true,
"timeZone" : "UTC",
"status" : "STARTED",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2&stop=true"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.13.5. List All Job Executions For A Specified Date Range Without Step Executions Included
The job executions endpoint lets you list all job executions. The following topics provide more details:
Request Structure
GET /jobs/thinexecutions?page=0&size=10&fromDate=2000-09-24T17%3A00%3A45%2C000&toDate=2050-09-24T18%3A00%3A45%2C000 HTTP/1.1
Host: localhost:9393Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
|
Filter result from a starting date in the format 'yyyy-MM-dd’T’HH:mm:ss,SSS' |
|
Filter result up to the |
Example Request
$ curl 'http://localhost:9393/jobs/thinexecutions?page=0&size=10&fromDate=2000-09-24T17%3A00%3A45%2C000&toDate=2050-09-24T18%3A00%3A45%2C000' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1937
{
"_embedded" : {
"jobExecutionThinResourceList" : [ {
"executionId" : 2,
"stepExecutionCount" : 0,
"jobId" : 2,
"taskExecutionId" : 2,
"instanceId" : 2,
"name" : "DOCJOB1",
"startDate" : "2024-09-13",
"startTime" : "10:11:22",
"startDateTime" : "2024-09-13T10:11:22.807+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : true,
"abandonable" : true,
"stoppable" : false,
"defined" : true,
"timeZone" : "UTC",
"status" : "STOPPED",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/2?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/2?schemaTarget=boot2&stop=true"
}
}
}, {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"instanceId" : 1,
"name" : "DOCJOB",
"startDate" : "2024-09-13",
"startTime" : "10:11:22",
"startDateTime" : "2024-09-13T10:11:22.802+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : true,
"timeZone" : "UTC",
"status" : "STARTED",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2&stop=true"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 2,
"totalPages" : 1,
"number" : 0
}
}43.13.6. List All Job Executions For A Specified Job Instance Id Without Step Executions Included
The job executions endpoint lets you list all job executions. The following topics provide more details:
Request Structure
GET /jobs/thinexecutions?page=0&size=10&jobInstanceId=1 HTTP/1.1
Host: localhost:9393Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
|
Filter result by the job instance id |
Example Request
$ curl 'http://localhost:9393/jobs/thinexecutions?page=0&size=10&jobInstanceId=1' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1108
{
"_embedded" : {
"jobExecutionThinResourceList" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"instanceId" : 1,
"name" : "DOCJOB",
"startDate" : "2024-09-13",
"startTime" : "10:11:21",
"startDateTime" : "2024-09-13T10:11:21.794+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : true,
"timeZone" : "UTC",
"status" : "STARTED",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2&stop=true"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.13.7. List All Job Executions For A Specified Task Execution Id Without Step Executions Included
The job executions endpoint lets you list all job executions. The following topics provide more details:
Request Structure
GET /jobs/thinexecutions?page=0&size=10&taskExecutionId=1 HTTP/1.1
Host: localhost:9393Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
|
Filter result by the task execution id |
Example Request
$ curl 'http://localhost:9393/jobs/thinexecutions?page=0&size=10&taskExecutionId=1' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1108
{
"_embedded" : {
"jobExecutionThinResourceList" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"instanceId" : 1,
"name" : "DOCJOB",
"startDate" : "2024-09-13",
"startTime" : "10:11:24",
"startDateTime" : "2024-09-13T10:11:24.914+0000",
"duration" : "00:00:00",
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : true,
"timeZone" : "UTC",
"status" : "STARTED",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/1?schemaTarget=boot2&stop=true"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/thinexecutions?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.13.8. Job Execution Detail
The job executions endpoint lets you get the details about a job execution. The following topics provide more details:
Request Structure
GET /jobs/executions/2?schemaTarget=boot2 HTTP/1.1
Host: localhost:9393/jobs/executions/{id}
| Parameter | Description |
|---|---|
|
The id of an existing job execution (required) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 1460
{
"executionId" : 2,
"stepExecutionCount" : 0,
"jobId" : 2,
"taskExecutionId" : 2,
"name" : "DOCJOB1",
"startDate" : "2024-09-13",
"startTime" : "10:11:25",
"duration" : "00:00:00",
"jobExecution" : {
"id" : 2,
"version" : 1,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 2,
"jobName" : "DOCJOB1",
"version" : null
},
"stepExecutions" : [ ],
"status" : "STOPPED",
"startTime" : "2024-09-13T10:11:25.966+0000",
"createTime" : "2024-09-13T10:11:25.966+0000",
"endTime" : null,
"lastUpdated" : "2024-09-13T10:11:25.966+0000",
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"jobConfigurationName" : null,
"failureExceptions" : [ ],
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : true,
"abandonable" : true,
"stoppable" : false,
"defined" : true,
"timeZone" : "UTC",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/2?schemaTarget=boot2"
},
"stop" : {
"href" : "http://localhost:9393/jobs/executions/2?schemaTarget=boot2&stop=true"
},
"restart" : {
"href" : "http://localhost:9393/jobs/executions/2?schemaTarget=boot2&restart=true"
}
}
}43.13.9. Stop Job Execution
The job executions endpoint lets you stop a job execution. The following topics provide more details:
Request structure
PUT /jobs/executions/1?schemaTarget=boot2 HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
stop=true/jobs/executions/{id}
| Parameter | Description |
|---|---|
|
The id of an existing job execution (required) |
Request parameters
| Parameter | Description |
|---|---|
|
The schema target of the job execution |
|
Sends signal to stop the job if set to true |
43.13.10. Restart Job Execution
The job executions endpoint lets you restart a job execution. The following topics provide more details:
Request Structure
PUT /jobs/executions/2?schemaTarget=boot2 HTTP/1.1
Host: localhost:9393
Content-Type: application/x-www-form-urlencoded
restart=true/jobs/executions/{id}
| Parameter | Description |
|---|---|
|
The id of an existing job execution (required) |
Request Parameters
| Parameter | Description |
|---|---|
|
The schema target of the job execution |
|
Sends signal to restart the job if set to true |
43.14. Job Instances
The job instances endpoint provides information about the job instances that are registered with the Spring Cloud Data Flow server. The following topics provide more details:
43.14.1. List All Job Instances
The job instances endpoint lets you list all job instances. The following topics provide more details:
Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
|
The name associated with the job instance |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1807
{
"_embedded" : {
"jobInstanceResourceList" : [ {
"jobName" : "DOCJOB",
"jobInstanceId" : 1,
"jobExecutions" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "",
"startTime" : "",
"duration" : "",
"jobExecution" : {
"id" : 1,
"version" : null,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 1,
"jobName" : "DOCJOB",
"version" : null
},
"stepExecutions" : [ ],
"status" : "STARTING",
"startTime" : null,
"createTime" : "2024-09-13T10:11:41.775+0000",
"endTime" : null,
"lastUpdated" : null,
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"jobConfigurationName" : null,
"failureExceptions" : [ ],
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : true,
"timeZone" : "UTC",
"schemaTarget" : "boot2"
} ],
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/instances/1"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/instances?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.14.2. Job Instance Detail
The job instances endpoint lets you list all job instances. The following topics provide more details:
Request Structure
GET /jobs/instances/1?schemaTarget=boot2 HTTP/1.1
Host: localhost:9393/jobs/instances/{id}
| Parameter | Description |
|---|---|
|
The id of an existing job instance (required) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1312
{
"jobName" : "DOCJOB",
"jobInstanceId" : 1,
"jobExecutions" : [ {
"executionId" : 1,
"stepExecutionCount" : 0,
"jobId" : 1,
"taskExecutionId" : 1,
"name" : "DOCJOB",
"startDate" : "",
"startTime" : "",
"duration" : "",
"jobExecution" : {
"id" : 1,
"version" : null,
"jobParameters" : {
"parameters" : { }
},
"jobInstance" : {
"id" : 1,
"jobName" : "DOCJOB",
"version" : null
},
"stepExecutions" : [ ],
"status" : "STARTING",
"startTime" : null,
"createTime" : "2024-09-13T10:11:42.763+0000",
"endTime" : null,
"lastUpdated" : null,
"exitStatus" : {
"exitCode" : "UNKNOWN",
"exitDescription" : ""
},
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"jobConfigurationName" : null,
"failureExceptions" : [ ],
"allFailureExceptions" : [ ]
},
"jobParameters" : { },
"jobParametersString" : "",
"restartable" : false,
"abandonable" : false,
"stoppable" : true,
"defined" : true,
"timeZone" : "UTC",
"schemaTarget" : "boot2"
} ],
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/instances/1"
}
}
}43.15. Job Step Executions
The job step executions endpoint provides information about the job step executions that are registered with the Spring Cloud Data Flow server. The following topics provide more details:
43.15.1. List All Step Executions For a Job Execution
The job step executions endpoint lets you list all job step executions. The following topics provide more details:
Request Parameters
| Parameter | Description |
|---|---|
|
The zero-based page number (optional) |
|
The requested page size (optional) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1805
{
"_embedded" : {
"stepExecutionResourceList" : [ {
"jobExecutionId" : 1,
"stepExecution" : {
"stepName" : "DOCJOB_STEP",
"id" : 1,
"version" : 0,
"status" : "STARTING",
"readCount" : 0,
"writeCount" : 0,
"commitCount" : 0,
"rollbackCount" : 0,
"readSkipCount" : 0,
"processSkipCount" : 0,
"writeSkipCount" : 0,
"startTime" : "2024-09-13T10:11:35.706+0000",
"endTime" : null,
"lastUpdated" : "2024-09-13T10:11:35.707+0000",
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"exitStatus" : {
"exitCode" : "EXECUTING",
"exitDescription" : ""
},
"terminateOnly" : false,
"filterCount" : 0,
"jobParameters" : {
"parameters" : { }
},
"jobExecutionId" : 1,
"skipCount" : 0,
"summary" : "StepExecution: id=1, version=0, name=DOCJOB_STEP, status=STARTING, exitStatus=EXECUTING, readCount=0, filterCount=0, writeCount=0 readSkipCount=0, writeSkipCount=0, processSkipCount=0, commitCount=0, rollbackCount=0",
"failureExceptions" : [ ]
},
"stepType" : "",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1?schemaTarget=boot2"
},
"progress" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1/progress?schemaTarget=boot2"
}
}
} ]
},
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps?page=0&size=10"
}
},
"page" : {
"size" : 10,
"totalElements" : 1,
"totalPages" : 1,
"number" : 0
}
}43.15.2. Job Step Execution Detail
The job step executions endpoint lets you get details about a job step execution. The following topics provide more details:
Request Structure
GET /jobs/executions/1/steps/1?schemaTarget=boot2 HTTP/1.1
Host: localhost:9393/jobs/executions/{id}/steps/{stepid}
| Parameter | Description |
|---|---|
|
The id of an existing job execution (required) |
|
The id of an existing step execution for a specific job execution (required) |
Example Request
$ curl 'http://localhost:9393/jobs/executions/1/steps/1?schemaTarget=boot2' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 1339
{
"jobExecutionId" : 1,
"stepExecution" : {
"stepName" : "DOCJOB_STEP",
"id" : 1,
"version" : 0,
"status" : "STARTING",
"readCount" : 0,
"writeCount" : 0,
"commitCount" : 0,
"rollbackCount" : 0,
"readSkipCount" : 0,
"processSkipCount" : 0,
"writeSkipCount" : 0,
"startTime" : "2024-09-13T10:11:34.601+0000",
"endTime" : null,
"lastUpdated" : "2024-09-13T10:11:34.601+0000",
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"exitStatus" : {
"exitCode" : "EXECUTING",
"exitDescription" : ""
},
"terminateOnly" : false,
"filterCount" : 0,
"jobParameters" : {
"parameters" : { }
},
"jobExecutionId" : 1,
"skipCount" : 0,
"summary" : "StepExecution: id=1, version=0, name=DOCJOB_STEP, status=STARTING, exitStatus=EXECUTING, readCount=0, filterCount=0, writeCount=0 readSkipCount=0, writeSkipCount=0, processSkipCount=0, commitCount=0, rollbackCount=0",
"failureExceptions" : [ ]
},
"stepType" : "",
"schemaTarget" : "boot2",
"_links" : {
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1?schemaTarget=boot2"
},
"progress" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1/progress?schemaTarget=boot2"
}
}
}43.15.3. Job Step Execution Progress
The job step executions endpoint lets you get details about the progress of a job step execution. The following topics provide more details:
Request Structure
GET /jobs/executions/1/steps/1/progress HTTP/1.1
Host: localhost:9393/jobs/executions/{id}/steps/{stepid}/progress
| Parameter | Description |
|---|---|
|
The id of an existing job execution (required) |
|
The id of an existing step execution for a specific job execution (required) |
Response Structure
HTTP/1.1 200 OK
Content-Type: application/hal+json
Content-Length: 2794
{
"stepExecution" : {
"stepName" : "DOCJOB_STEP",
"id" : 1,
"version" : 0,
"status" : "STARTING",
"readCount" : 0,
"writeCount" : 0,
"commitCount" : 0,
"rollbackCount" : 0,
"readSkipCount" : 0,
"processSkipCount" : 0,
"writeSkipCount" : 0,
"startTime" : "2024-09-13T10:11:36.711+0000",
"endTime" : null,
"lastUpdated" : "2024-09-13T10:11:36.711+0000",
"executionContext" : {
"dirty" : false,
"empty" : true,
"values" : [ ]
},
"exitStatus" : {
"exitCode" : "EXECUTING",
"exitDescription" : ""
},
"terminateOnly" : false,
"filterCount" : 0,
"jobParameters" : {
"parameters" : { }
},
"jobExecutionId" : 1,
"skipCount" : 0,
"summary" : "StepExecution: id=1, version=0, name=DOCJOB_STEP, status=STARTING, exitStatus=EXECUTING, readCount=0, filterCount=0, writeCount=0 readSkipCount=0, writeSkipCount=0, processSkipCount=0, commitCount=0, rollbackCount=0",
"failureExceptions" : [ ]
},
"stepExecutionHistory" : {
"stepName" : "DOCJOB_STEP",
"count" : 0,
"commitCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"rollbackCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"readCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"writeCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"filterCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"readSkipCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"writeSkipCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"processSkipCount" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"duration" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
},
"durationPerRead" : {
"count" : 0,
"min" : 0.0,
"max" : 0.0,
"mean" : 0.0,
"standardDeviation" : 0.0
}
},
"percentageComplete" : 0.5,
"finished" : false,
"duration" : 18.0,
"_links" : {
"progress" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1/progress?schemaTarget=boot2"
},
"self" : {
"href" : "http://localhost:9393/jobs/executions/1/steps/1"
}
}
}| The following fields in the stepExecutionHistory are deprecated and will be removed in a future release: rollbackCount, readCount, writeCount, filterCount, readSkipCount, writeSkipCount, processSkipCount, durationPerRead. |
43.16. Runtime Information about Applications
You can get information about running apps known to the system, either globally or individually. The following topics provide more details:
43.16.1. Listing All Applications at Runtime
To retrieve information about all instances of all apps, query the /runtime/apps endpoint by using GET.
The following topics provide more details:
43.16.2. Querying All Instances of a Single App
To retrieve information about all instances of a particular app, query the /runtime/apps/<appId>/instances endpoint by using GET.
The following topics provide more details:
43.16.3. Querying a Single Instance of a Single App
To retrieve information about a particular instance of a particular application, query the /runtime/apps/<appId>/instances/<instanceId> endpoint by using GET.
The following topics provide more details:
43.17. Stream Logs
You can get the application logs of the stream for the entire stream or a specific application inside the stream. The following topics provide more details:
43.17.1. Get the applications' logs by the stream name
Use the HTTP GET method with the /streams/logs/<streamName> REST endpoint to retrieve all the applications' logs for the given stream name.
The following topics provide more details:
43.18. Task Logs
You can get the task execution log for a specific task execution.
The following topic provides more details:
43.18.1. Get the task execution log
To retrieve the logs of the task execution, query the /tasks/logs/<ExternalTaskExecutionId> endpoint by using the HTTP GET method..
The following topics provide more details:
Request Structure
GET /tasks/logs/taskA-69b2b37c-9d98-4f49-a43d-708c4cd2c02f?platformName=default HTTP/1.1
Host: localhost:9393Request Parameters
| Parameter | Description |
|---|---|
|
The name of the platform the task is launched. |
Example Request
$ curl 'http://localhost:9393/tasks/logs/taskA-69b2b37c-9d98-4f49-a43d-708c4cd2c02f?platformName=default' -i -X GETResponse Structure
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 277
"stdout:\n2024-09-13 10:11:29.011 INFO 9073 --- [ main] s.c.a.AnnotationConfigApplicationContext : Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@ba8a1dc: startup date [Fri Sep 13 10:11:29 UTC 2024]; root of context hierarchy\n"44. OpenAPI
The Springdoc library is integrated with the server in an opt-in fashion. Once enabled, it provides OpenAPI3 documentation and a Swagger UI.
To enable, set the following properties in your application.yml prior to launching the server:
springdoc:
api-docs:
enabled: true
swagger-ui:
enabled: trueThe properties can also be set on the command line:
-Dspringdoc.api-docs.enabled=true -Dspringdoc.swagger-ui.enabled=trueor as environment variables:
SPRINGDOC_APIDOCS_ENABLED=true
SPRINGDOC_SWAGGERUI_ENABLED=trueOnce enabled, the OpenAPI3 docs and Swagger UI are available at the /v3/api-docs and /swagger-ui/index.html URIs, respectively (eg. localhost:9393/v3/api-docs).
| The Swagger UI will be initially be blank. Type in "/v3/api-docs/" in the "Explore" bar and click "Explore". |
If you try out the API’s in the Swagger UI and get errors related to "No property string found for type" try replacing the pageable parameter with { } or removing its "sort" attribute.
|
There are a plethora of available OpenAPI and Swagger UI properties to configure the feature.
Appendices
Having trouble with Spring Cloud Data Flow, We’d like to help!
-
Ask a question. We monitor stackoverflow.com for questions tagged with
spring-cloud-dataflow. -
Report bugs with Spring Cloud Data Flow at github.com/spring-cloud/spring-cloud-dataflow/issues.
Appendix A: Data Flow Template
As described in API Guide chapter, Spring Cloud Data Flow’s functionality is completely exposed through REST endpoints. While you can use those endpoints directly, Spring Cloud Data Flow also provides a Java-based API, which makes using those REST endpoints even easier.
The central entry point is the DataFlowTemplate class in the org.springframework.cloud.dataflow.rest.client package.
This class implements the DataFlowOperations interface and delegates to the following sub-templates that provide the specific functionality for each feature-set:
| Interface | Description |
|---|---|
|
REST client for stream operations |
|
REST client for counter operations |
|
REST client for field value counter operations |
|
REST client for aggregate counter operations |
|
REST client for task operations |
|
REST client for job operations |
|
REST client for app registry operations |
|
REST client for completion operations |
|
REST Client for runtime operations |
When the DataFlowTemplate is being initialized, the sub-templates can be discovered through the REST relations, which are provided by HATEOAS (Hypermedia as the Engine of Application State).
| If a resource cannot be resolved, the respective sub-template results in NULL. A common cause is that Spring Cloud Data Flow allows for specific sets of features to be enabled or disabled when launching. For more information, see one of the local, Cloud Foundry, or Kubernetes configuration chapters, depending on where you deploy your application. |
A.1. Using the Data Flow Template
When you use the Data Flow Template, the only needed Data Flow dependency is the Spring Cloud Data Flow Rest Client, as shown in the following Maven snippet:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dataflow-rest-client</artifactId>
<version>2.11.5</version>
</dependency>With that dependency, you get the DataFlowTemplate class as well as all the dependencies needed to make calls to a Spring Cloud Data Flow server.
When instantiating the DataFlowTemplate, you also pass in a RestTemplate.
Note that the needed RestTemplate requires some additional configuration to be valid in the context of the DataFlowTemplate.
When declaring a RestTemplate as a bean, the following configuration suffices:
@Bean
public static RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate();
restTemplate.setErrorHandler(new VndErrorResponseErrorHandler(restTemplate.getMessageConverters()));
for(HttpMessageConverter<?> converter : restTemplate.getMessageConverters()) {
if (converter instanceof MappingJackson2HttpMessageConverter) {
final MappingJackson2HttpMessageConverter jacksonConverter =
(MappingJackson2HttpMessageConverter) converter;
jacksonConverter.getObjectMapper()
.registerModule(new Jackson2HalModule())
.addMixIn(JobExecution.class, JobExecutionJacksonMixIn.class)
.addMixIn(JobParameters.class, JobParametersJacksonMixIn.class)
.addMixIn(JobParameter.class, JobParameterJacksonMixIn.class)
.addMixIn(JobInstance.class, JobInstanceJacksonMixIn.class)
.addMixIn(ExitStatus.class, ExitStatusJacksonMixIn.class)
.addMixIn(StepExecution.class, StepExecutionJacksonMixIn.class)
.addMixIn(ExecutionContext.class, ExecutionContextJacksonMixIn.class)
.addMixIn(StepExecutionHistory.class, StepExecutionHistoryJacksonMixIn.class);
}
}
return restTemplate;
}
You can also get a pre-configured RestTemplate by using
DataFlowTemplate.getDefaultDataflowRestTemplate();
|
Now you can instantiate the DataFlowTemplate with the following code:
DataFlowTemplate dataFlowTemplate = new DataFlowTemplate(
new URI("http://localhost:9393/"), restTemplate); (1)
| 1 | The URI points to the ROOT of your Spring Cloud Data Flow Server. |
Depending on your requirements, you can now make calls to the server. For instance, if you want to get a list of the currently available applications, you can run the following code:
PagedResources<AppRegistrationResource> apps = dataFlowTemplate.appRegistryOperations().list();
System.out.println(String.format("Retrieved %s application(s)",
apps.getContent().size()));
for (AppRegistrationResource app : apps.getContent()) {
System.out.println(String.format("App Name: %s, App Type: %s, App URI: %s",
app.getName(),
app.getType(),
app.getUri()));
}
A.2. Data Flow Template and Security
When using the DataFlowTemplate, you can also provide all the security-related
options as if you were using the Data Flow Shell. In fact, the Data Flow Shell
uses the DataFlowTemplate for all its operations.
To let you get started, we provide a HttpClientConfigurer that uses the builder
pattern to set the various security-related options:
HttpClientConfigurer
.create(targetUri) (1)
.basicAuthCredentials(username, password) (2)
.skipTlsCertificateVerification() (3)
.withProxyCredentials(proxyUri, proxyUsername, proxyPassword) (4)
.addInterceptor(interceptor) (5)
.buildClientHttpRequestFactory() (6)
| 1 | Creates a HttpClientConfigurer with the provided target URI. |
| 2 | Sets the credentials for basic authentication (Using OAuth2 Password Grant) |
| 3 | Skip SSL certificate verification (Use for DEVELOPMENT ONLY!) |
| 4 | Configure any Proxy settings |
| 5 | Add a custom interceptor e.g. to set the OAuth2 Authorization header. This allows you to pass an OAuth2 Access Token instead of username/password credentials. |
| 6 | Builds the ClientHttpRequestFactory that can be set on the RestTemplate. |
Once the HttpClientConfigurer is configured, you can use its buildClientHttpRequestFactory
to build the ClientHttpRequestFactory and then set the corresponding
property on the RestTemplate. You can then instantiate the actual DataFlowTemplate
using that RestTemplate.
To configure Basic Authentication, the following setup is required:
RestTemplate restTemplate = DataFlowTemplate.getDefaultDataflowRestTemplate();
HttpClientConfigurer httpClientConfigurer = HttpClientConfigurer.create("http://localhost:9393");
httpClientConfigurer.basicAuthCredentials("my_username", "my_password");
restTemplate.setRequestFactory(httpClientConfigurer.buildClientHttpRequestFactory());
DataFlowTemplate dataFlowTemplate = new DataFlowTemplate("http://localhost:9393", restTemplate);
Appendix B: “How-to” guides
This section provides answers to some common ‘how do I do that…’ questions that often arise when people use Spring Cloud Data Flow.
If you have a specific problem that we do not cover here, you might want to check out stackoverflow.com to see if someone has already provided an answer.
That is also a great place to ask new questions (use the spring-cloud-dataflow tag).
We are also more than happy to extend this section. If you want to add a “how-to”, you can send us a pull request.
B.1. Configure Maven Properties
If applications are resolved by using the Maven repository you may want to configure the underlying resolver.
You can set the Maven properties, such as the local Maven repository location, remote Maven repositories, authentication credentials, and proxy server properties through command-line properties when you start the Data Flow server.
Alternatively, you can set the properties by setting the SPRING_APPLICATION_JSON environment property for the Data Flow server.
For all Data Flow server installations, the following list of remote Maven repositories are configured by default:
-
Maven Central (
repo.maven.apache.org/maven2) -
Spring Snapshots (
repo.spring.io/snapshot) -
Spring Milestones (
repo.spring.io/milestone)
If the default is already explicitly configured (exact match on the repo url) then it will not be included.
If the applications exist on another remote repository, besides the pre-configured ones, that remote repository must be configured explicitly and will be added to the pre-configured default list.
To skip the automatic default repositories behavior altogether, set the maven.include-default-remote-repos property to false.
|
To pass the properties as command-line options, run the server with a command similar to the following:
java -jar <dataflow-server>.jar --maven.localRepoitory=mylocal \
--maven.remote-repositories.repo1.url=https://repo1 \
--maven.remote-repositories.repo1.auth.username=repo1user \
--maven.remote-repositories.repo1.auth.password=repo1pass \
--maven.remote-repositories.repo2.url=https://repo2 \
--maven.proxy.host=proxyhost \
--maven.proxy.port=9018 \
--maven.proxy.auth.username=proxyuser \
--maven.proxy.auth.password=proxypassYou can also use the SPRING_APPLICATION_JSON environment property:
export SPRING_APPLICATION_JSON='{ "maven": { "local-repository": "local","remote-repositories": { "repo1": { "url": "https://repo1", "auth": { "username": "repo1user", "password": "repo1pass" } },
"repo2": { "url": "https://repo2" } }, "proxy": { "host": "proxyhost", "port": 9018, "auth": { "username": "proxyuser", "password": "proxypass" } } } }'Here is the same content in nicely formatted JSON:
SPRING_APPLICATION_JSON='{
"maven": {
"local-repository": "local",
"remote-repositories": {
"repo1": {
"url": "https://repo1",
"auth": {
"username": "repo1user",
"password": "repo1pass"
}
},
"repo2": {
"url": "https://repo2"
}
},
"proxy": {
"host": "proxyhost",
"port": 9018,
"auth": {
"username": "proxyuser",
"password": "proxypass"
}
}
}
}'You can also set the properties as individual environment variables:
export MAVEN_REMOTEREPOSITORIES_REPO1_URL=https://repo1
export MAVEN_REMOTEREPOSITORIES_REPO1_AUTH_USERNAME=repo1user
export MAVEN_REMOTEREPOSITORIES_REPO1_AUTH_PASSWORD=repo1pass
export MAVEN_REMOTEREPOSITORIES_REPO2_URL=https://repo2
export MAVEN_PROXY_HOST=proxyhost
export MAVEN_PROXY_PORT=9018
export MAVEN_PROXY_AUTH_USERNAME=proxyuser
export MAVEN_PROXY_AUTH_PASSWORD=proxypassB.3. Extending application classpath
Users may require the addition of dependencies to the existing Stream applications or specific database drivers to Dataflow and Skipper or any of the other containers provider by the project.
The Spring Cloud Dataflow repository contains scripts to help with this task. The examples below assume you have cloned the spring-cloud-dataflow repository and are executing the scripts from src/add-deps.
|
B.3.1. JAR File
We suggest you publish the updated jar it to a private Maven repository and that the Maven Coordinates of the private registry is then used to register application with SCDF.
Example
This example:
* assumes the jar is downloaded to ${appFolder}/${appName}-${appVersion}.jar
* adds the dependencies and then publishes the jar to Maven local.
./gradlew -i publishToMavenLocal \
-P appFolder="." \
-P appGroup="org.springframework.cloud" \
-P appName="spring-cloud-dataflow-server" \
-P appVersion="2.11.3" \
-P depFolder="./extra-libs"
Use the publishMavenPublicationToMavenRepository task to publish to a remote repository. Update the gradle.properties with the remote repository details. Alternatively move repoUser and repoPassword to ~/.gradle/gradle.properties
|
B.3.2. Containers
In order to create a container we suggest using paketo pack cli to create a container from the jar created in previous step.
REPO=springcloud/spring-cloud-dataflow-server
TAG=2.11.3
JAR=build/spring-cloud-dataflow-server-${TAG}.jar
JAVA_VERSION=8
pack build --builder gcr.io/paketo-buildpacks/builder:base \
--path "$JAR" \
--trust-builder --verbose \
--env BP_JVM_VERSION=${JAVA_VERSION} "$REPO:$TAG-jdk${JAVA_VERSION}-extra"| Publish the container to a private container registry and register the application docker uri with SCDF. |
B.4. Create containers for architectures not supported yet.
In the case of macOS on M1 the performance of amd64/x86_64 is unacceptable.
We provide a set of scripts that can be used to download specific versions of published artifacts.
We also provide a script that will create a container using the downloaded artifact for the host platform.
In the various projects you will find then in src/local or local folders.
| Project | Scripts | Notes |
|---|---|---|
Data Flow |
|
Download or create container for: |
Skipper |
|
Download or create container for: |
Stream Applications |
|
|
B.4.1. Scripts in spring-cloud-dataflow
src/local/download-apps.sh
Downloads all applications needed by create-containers.sh from Maven repository.
If the timestamp of snapshots matches the download will be skipped.
Usage: download-apps.sh [version]
-
versionis the dataflow-server version like2.11.3. Default is2.11.3-SNAPSHOT
src/local/create-containers.sh
Creates all containers and pushes to local docker registry.
This script requires jib-cli
Usage: create-containers.sh [version] [jre-version]
-
versionis the dataflow-server version like2.11.3. Default is2.11.3-SNAPSHOT -
jre-versionshould be one of 11, 17. Default is 11
B.4.2. Scripts in spring-cloud-skipper
local/download-app.sh
Downloads all applications needed by create-containers.sh from Maven repository.
If the timestamp of snapshots matches the download will be skipped.
Usage: download-app.sh [version]
-
versionis the skipper version like2.11.3or default is2.11.3-SNAPSHOT
local/create-container.sh
Creates all containers and pushes to local docker registry. This script requires jib-cli
Usage: create-containers.sh [version] [jre-version]
-
versionis the skipper version like2.11.3or default is2.11.3-SNAPSHOT -
jre-versionshould be one of 11, 17
B.4.3. Scripts in stream-applications
local/download-apps.sh
Downloads all applications needed by create-containers.sh from Maven repository.
If the timestamp of snapshots matches the download will be skipped.
Usage: download-apps.sh [version] [broker] [filter]
-
versionis the stream applications version like3.2.1or default is3.2.2-SNAPSHOT -
brokeris one of rabbitmq, rabbit or kafka -
filteris a name of an application or a partial name that will be matched.
local/create-containers.sh
Creates all containers and pushes to local docker registry.
This script requires jib-cli
Usage: create-containers.sh [version] [broker] [jre-version] [filter]
-
versionis the stream-applications version like3.2.1or default is3.2.2-SNAPSHOT -
brokeris one of rabbitmq, rabbit or kafka -
jre-versionshould be one of 11, 17 -
filteris a name of an application or a partial name that will be matched.
If the file is not present required to create the container the script will skip the one.
local/pack-containers.sh
Creates all containers and pushes to local docker registry.
This script requires packeto pack
Usage: pack-containers.sh [version] [broker] [jre-version] [filter]
-
versionis the stream-applications version like3.2.1or default is3.2.2-SNAPSHOT -
brokeris one of rabbitmq, rabbit or kafka -
jre-versionshould be one of 11, 17 -
filteris a name of an application or a partial name that will be matched.
If the required file is not present to create the container the script will skip that one.
| If any parameter is provided all those to the left of it should be considered required. |
B.5. Configure Kubernetes for local development or testing
B.5.1. Prerequisites
You will need to install kubectl and then kind or minikube for a local cluster.
All the examples assume you have cloned the spring-cloud-dataflow repository and are executing the scripts from deploy/k8s.
On macOS, you may need to install realpath from Macports or brew install realpath
The scripts require a shell like bash or zsh and should work on Linux, WSL 2 or macOS.
|
B.5.2. Steps
-
Choose Kubernetes provider. Kind, Minikube or remote GKE or TMC.
-
Decide the namespace to use for deployment if not
default. -
Configure Kubernetes and loadbalancer.
-
Choose Broker with
export BROKER=kafka|rabbitmq -
Build or Pull container images for Skipper and Data Flow Server.
-
Deploy and Launch Spring Cloud Data Flow.
-
Export Data Flow Server address to env.
Kubernetes Provider
How do I choose between minikube and kind? kind will generally provide quicker setup and teardown time than Minikube. There is little to choose in terms of performance between the 2 apart from being able to configure limits on CPUs and memory when deploying minikube. So in the case where you have memory constraints or need to enforce memory limitations Minikube will be a better option.
Kubectl
You will need to install kubectl in order to configure the Kubernetes cluster
Kind
Kind is Kubernetes in docker and ideal for local development.
The LoadBalancer will be installed by the configure-k8s.sh script by will require an update to a yaml file to provide the address range available to the LoadBalancer.
Minikube
Minikube uses one of a selection of drivers to provide a virtualization environment.
Delete existing Minikube installation if you have any. minikube delete
|
B.5.3. Building and loading containers.
For local development you need control of the containers used in the local environment.
In order to ensure to manage the specific versions of data flow and skipper containers you can set SKIPPER_VERSION and DATAFLOW_VERSION environmental variable and then invoke ./images/pull-dataflow.sh and ./images/pull-skipper.sh or if you want to use a locally built application you can invoke ./images/build-skipper-image.sh and ./images/build-dataflow.sh
B.5.4. Configure k8s environment
You can invoke one of the following scripts to choose the type of installation you are targeting:
./k8s/use-kind.sh [<namespace>] [<database>] [<broker>]
./k8s/use-mk-docker.sh [<namespace>] [<database>] [<broker>]
./k8s/use-mk-kvm2.sh [<namespace>] [<database>] [<broker>]
./k8s/use-mk.sh <driver> [<namespace>] [<database>] [<broker>] (1)
./k8s/use-tmc.sh <cluster-name> [<namespace>] [<database>] [<broker>]
./k8s/use-gke.sh <cluster-name> [<namespace>] [<database>] [<broker>]| 1 | <driver> must be one of kvm2, docker, vmware, virtualbox, vmwarefusion or hyperkit. docker is the recommended option for local development. |
<namespace> will be default if not provided. The default <database> is postgresql and the default <broker> is kafka.
|
Since these scripts export environmental variable they need to be executes as in the following example:
source ./k8s/use-mk-docker.sh postgresql rabbitmq --namespace test-nsTMC or GKE Cluster in Cloud
The cluster must exist before use, and you should use the relevant cli to login before executing source ./k8s/use-gke.sh
Create Local Cluster.
The following script will create the local cluster.
# Optionally add to control cpu and memory allocation.
export MK_ARGS="--cpus=8 --memory=12g"
./k8s/configure-k8s.sh-
For kind follow instruction to update
./k8s/yaml/metallb-configmap.yamland then apply usingkubectl apply -f ./k8s/yaml/metallb-configmap.yaml -
For minikube launch a new shell and execute
minikube tunnel
Deploy Spring Cloud Data Flow.
The use-* scripts will configure the values of BROKER and DATABASE.
Configure Database
export DATABASE=<database> (1)| 1 | <database> one of mariadb or postgresql |
Docker credentials need to be configured for Kubernetes to pull the various container images.
For Docker Hub you can create a personal free account and use a personal access token as your password.
Test your docker login using ./k8s/docker-login.sh
export DOCKER_SERVER=https://docker.io
export DOCKER_USER=<docker-userid>
export DOCKER_PASSWORD=<docker-password>
export DOCKER_EMAIL=<email-of-docker-use>Set the version of Spring Cloud Data Flow and Skipper.
This example shows the versions of the current development snapshot.
export DATAFLOW_VERSION=2.11.5-SNAPSHOT
export SKIPPER_VERSION=2.11.5-SNAPSHOTBefore you can install SCDF you will need to pull the following images to ensure they are present for uploading to the k8s cluster.
You can configure the before pull-app-images and install-scdf:
-
STREAM_APPS_RT_VERSIONStream Apps Release Train Version. Default is 2022.0.0. -
STREAM_APPS_VERSIONStream Apps Version. Default is 4.0.0.
Use:
./images/pull-app-images.sh
./images/pull-dataflow.sh
./images/pull-skipper.sh
./images/pull-composed-task-runner.sh./k8s/install-scdf.sh
source ./k8s/export-dataflow-ip.sh
You can now execute scripts from ./shell to deploy some simple streams and tasks. You can also run ./shell/shell.sh to run the Spring Cloud Data Flow Shell.
|
If you want to start fresh you use the following to delete the SCDF deployment and then run ./k8s/install-scdf.sh to install it again.
B.5.5. Utilities
The following list of utilities may prove useful.
| Name | Description |
|---|---|
k9s is a text based monitor to explore the Kubernetes cluster. |
|
Extra and tail the logs of various pods based on various naming criteria. |
B.5.6. Scripts
Some of the scripts apply to local containers as well and can be found in src/local, the Kubernetes specific scripts are in deploy/k8s
| Script | Description |
|---|---|
|
Build all images of Restaurant Sample Stream Apps |
|
Pull all images of Restaurant Sample Stream Apps from Docker Hub |
|
Pull dataflow from DockerHub based on |
|
Pull Dataflow Pro from Tanzu Network based on |
|
Pull Skipper from DockerHub base on the |
|
Build a docker image from the local repo of Dataflow |
|
Build a docker image from the local repo of Dataflow Pro. Set |
|
Build a docker image from the local repo of Skipper. |
|
Configure the Kubernetes environment based on your configuration of K8S_DRIVER. |
|
Delete all Kubernetes resources create by the deployment. |
|
Delete cluster, kind or minikube. |
|
Export the url of the data flow server to |
|
Export the url of the http source of a specific flow by name to |
|
Configure and deploy all the containers for Spring Cloud Dataflow |
|
Load all container images required by tests into kind or minikube to ensure you have control over what is used. |
|
Load a specific container image into local kind or minikube. |
|
Execute acceptance tests against cluster where |
|
Register the Task and Stream apps used by the unit tests. |
| Please report any errors with the scripts along with detail information about the relevant environment. |
B.6. Frequently Asked Questions
In this section, we review the frequently asked questions for Spring Cloud Data Flow. See the Frequently Asked Questions section of the microsite for more information.
Appendix C: Identity Providers
This appendix contains information how specific providers can be set up to work with Data Flow security.
At this writing, Azure is the only identity provider.
C.1. Azure
Azure AD (Active Directory) is a fully fledged identity provider that provide a wide range of features around authentication and authorization. As with any other provider, it has its own nuances, meaning care must be taken to set it up.
In this section, we go through how OAuth2 setup is done for AD and Spring Cloud Data Flow.
| You need full organization access rights to set up everything correctly. |
C.1.1. Creating a new AD Environment
To get started, create a new Active Directory environment. Choose a type as Azure Active Directory (not the b2c type) and then pick your organization name and initial domain. The following image shows the settings:

C.1.2. Creating a New App Registration
App registration is where OAuth clients are created to get used by OAuth applications. At minimum, you need to create two clients, one for the Data Flow and Skipper servers and one for the Data Flow shell, as these two have slightly different configurations. Server applications can be considered to be trusted applications while shell is not trusted (because users can see its full configuration).
NOTE: We recommend using the same OAuth client for both the Data Flow and the Skipper servers. While you can use different clients, it currently would not provide any value, as the configurations needs to be the same.
The following image shows the settings for creating a a new app registration:

A client secret, when needed, is created under Certificates & secrets in AD.
|
C.1.3. Expose Dataflow APIs
To prepare OAuth scopes, create one for each Data Flow security role. In this example, those would be
-
api://dataflow-server/dataflow.create -
api://dataflow-server/dataflow.deploy -
api://dataflow-server/dataflow.destroy -
api://dataflow-server/dataflow.manage -
api://dataflow-server/dataflow.schedule -
api://dataflow-server/dataflow.modify -
api://dataflow-server/dataflow.view
The following image shows the APIs to expose:

Previously created scopes needs to be added as API Permissions, as the following image shows:

C.1.4. Creating a Privileged Client
For the OAuth client, which is about to use password grants, the same API permissions need to be created for the OAuth client as were used for the server (described in the previous section).
| All these permissions need to be granted with admin privileges. |
The following image shows the privileged settings:

| Privileged client needs a client secret, which needs to be exposed to a client configuration when used in a shell. If you do not want to expose that secret, use the Creating a Public Client public client. |
C.1.5. Creating a Public Client
A public client is basically a client without a client secret and with its type set to public.
The following image shows the configuration of a public client:

C.1.6. Configuration Examples
This section contains configuration examples for the Data Flow and Skipper servers and the shell.
To starting a Data Flow server:
$ java -jar spring-cloud-dataflow-server.jar \
--spring.config.additional-location=dataflow-azure.ymlspring:
cloud:
dataflow:
security:
authorization:
provider-role-mappings:
dataflow-server:
map-oauth-scopes: true
role-mappings:
ROLE_VIEW: dataflow.view
ROLE_CREATE: dataflow.create
ROLE_MANAGE: dataflow.manage
ROLE_DEPLOY: dataflow.deploy
ROLE_DESTROY: dataflow.destroy
ROLE_MODIFY: dataflow.modify
ROLE_SCHEDULE: dataflow.schedule
security:
oauth2:
client:
registration:
dataflow-server:
provider: azure
redirect-uri: '{baseUrl}/login/oauth2/code/{registrationId}'
client-id: <client id>
client-secret: <client secret>
scope:
- openid
- profile
- email
- offline_access
- api://dataflow-server/dataflow.view
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.create
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0
user-name-attribute: name
resourceserver:
jwt:
jwk-set-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/discovery/v2.0/keysTo start a Skipper server:
$ java -jar spring-cloud-skipper-server.jar \
--spring.config.additional-location=skipper-azure.ymlspring:
cloud:
skipper:
security:
authorization:
provider-role-mappings:
skipper-server:
map-oauth-scopes: true
role-mappings:
ROLE_VIEW: dataflow.view
ROLE_CREATE: dataflow.create
ROLE_MANAGE: dataflow.manage
ROLE_DEPLOY: dataflow.deploy
ROLE_DESTROY: dataflow.destroy
ROLE_MODIFY: dataflow.modify
ROLE_SCHEDULE: dataflow.schedule
security:
oauth2:
client:
registration:
skipper-server:
provider: azure
redirect-uri: '{baseUrl}/login/oauth2/code/{registrationId}'
client-id: <client id>
client-secret: <client secret>
scope:
- openid
- profile
- email
- offline_access
- api://dataflow-server/dataflow.view
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.create
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0
user-name-attribute: name
resourceserver:
jwt:
jwk-set-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/discovery/v2.0/keysTo start a shell and (optionally) pass credentials as options:
$ java -jar spring-cloud-dataflow-shell.jar \
--spring.config.additional-location=dataflow-azure-shell.yml \
--dataflow.username=<USERNAME> \
--dataflow.password=<PASSWORD> security:
oauth2:
client:
registration:
dataflow-shell:
provider: azure
client-id: <client id>
client-secret: <client secret>
authorization-grant-type: password
scope:
- offline_access
- api://dataflow-server/dataflow.create
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.view
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0
A Public Client requires App Roles with the value set the same as the internal permissions [dataflow.create, dataflow.deploy, dataflow.destroy, dataflow.manage, dataflow.modify, dataflow.schedule, dataflow.view] to ensure they are added to the access token.
|
Starting a public shell and (optionally) pass credentials as options:
$ java -jar spring-cloud-dataflow-shell.jar \
--spring.config.additional-location=dataflow-azure-shell-public.yml \
--dataflow.username=<USERNAME> \
--dataflow.password=<PASSWORD>spring:
security:
oauth2:
client:
registration:
dataflow-shell:
provider: azure
client-id: <client id>
authorization-grant-type: password
client-authentication-method: post
scope:
- offline_access
- api://dataflow-server/dataflow.create
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.view
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0Appendix D: Spring Boot 3.x Support
D.1. Stream Applications
Spring Cloud Data Flow supports both Spring Boot 2.x and 3.x based Stream applications.
D.1.1. Differences in 3.x
Be aware of the following areas that have changed across versions.
Metrics Configuration Properties
| The following does NOT apply when configuring metrics for the Dataflow or Skipper server as they both run on Spring Boot 2.x. It is only applicable to applications managed by Dataflow. |
The naming of the metrics registry-specific properties differ as follows:
-
2.x:management.metrics.export.<meter-registry>.<property-path> -
3.x:management.<meter-registry>.metrics.export.<property-path>
-
2.x:management.metrics.export.prometheus.enabled=true -
3.x:management.prometheus.metrics.export.enabled=true
One exception to this rule is the Prometheus RSocket Proxy which still runs on Spring Boot 2.x and therefore expects the properties in the management.metrics.export.prometheus.rsocket.* format.
|
Be sure that you use the 2.x format when configuring 2.x based stream apps and the 3.x format when configuring 3.x based stream apps.
Dataflow Metrics Property Replication
By default, Dataflow replicates relevant metrics properties that it has been configured with to all launched stream and task applications.
This replication has been updated to target both the 2.x and 3.x expected formats.
In other words, if your 2.x stream apps are currently inheriting the Dataflow metrics configuration, they will continue to do so for your 3.x stream apps.
D.1.2. Pre-packaged Stream Applications
The default pre-packaged stream applications are based on Spring Boot 2.x.
To use the latest pre-packaged apps based on Spring Boot 3.x, you must manually register the apps (relevant coordinates below).
| Stream Applications |
|---|
| HTTP Repository Location for Apps |
|---|
D.2. Spring Cloud Task / Batch Applications
The database schemas for Spring Cloud Task 3.x and Spring Batch 5.x have been modified in the versions that forms part of Spring Boot 3.x
Spring Cloud Data Flow will create set of tables for the Boot 3.x version that is prefixed by BOOT3_ and will configure the spring.cloud.task.tablePrefix and spring.batch.jdbc.table-prefix with the correct values.
In order to know that the specific task is a Boot 3.x application the version will have to be provided as part of registration. The rest endpoints accepts a bootVersion=3 parameter and the shell commands accepts --bootVersion 3
Since there are now multiple sets of tables that represents task and batch executions, each schema has been assigned a schemaTarget name. This value form part of queries when retrieving execution data. The UI takes care of this by using the embedded resource links. If you are using the REST API directly you will need to update those requests.
D.2.1. Pre-packaged Task / Batch Applications
The default pre-packaged task / batch applications are based on Spring Boot 2.x, Spring Cloud Task 2.x, and Spring Batch 4.x.
To use the latest pre-packaged apps based on Spring Boot 3.x, Spring Cloud Task 3.x, and Spring Batch 5.x, you must manually register the apps using the properties below.
task.timestamp=maven://io.spring:timestamp-task:3.0.0
task.timestamp.bootVersion=3
task.timestamp-batch=maven://io.spring:timestamp-batch-task:3.0.0
task.timestamp-batch.bootVersion=3task.timestamp=docker:springcloudtask/timestamp-task:3.0.0
task.timestamp.bootVersion=3
task.timestamp-batch=docker:springcloudtask/timestamp-batch-task:3.0.0
task.timestamp-batch.bootVersion=3| The properties can be used when registering an app in the Dataflow UI or the Dataflow shell CLI. |