Mark Fisher, Dave Syer, Oleg Zhurakousky, Anshul Mehra, Dan Dobrin
3.2.12-SNAPSHOT
Introduction
Spring Cloud Function is a project with the following high-level goals:
-
Promote the implementation of business logic via functions.
-
Decouple the development lifecycle of business logic from any specific runtime target so that the same code can run as a web endpoint, a stream processor, or a task.
-
Support a uniform programming model across serverless providers, as well as the ability to run standalone (locally or in a PaaS).
-
Enable Spring Boot features (auto-configuration, dependency injection, metrics) on serverless providers.
It abstracts away all of the transport details and infrastructure, allowing the developer to keep all the familiar tools and processes, and focus firmly on business logic.
Here’s a complete, executable, testable Spring Boot application (implementing a simple string manipulation):
@SpringBootApplication
public class Application {
@Bean
public Function<Flux<String>, Flux<String>> uppercase() {
return flux -> flux.map(value -> value.toUpperCase());
}
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
It’s just a Spring Boot application, so it can be built, run and
tested, locally and in a CI build, the same way as any other Spring
Boot application. The Function is from java.util and Flux is a
Reactive Streams Publisher from
Project Reactor. The function can be
accessed over HTTP or messaging.
Spring Cloud Function has 4 main features:
In the nutshell Spring Cloud Function provides the following features:
1. Wrappers for @Beans of type Function, Consumer and
Supplier, exposing them to the outside world as either HTTP
endpoints and/or message stream listeners/publishers with RabbitMQ, Kafka etc.
-
Choice of programming styles - reactive, imperative or hybrid.
-
Function composition and adaptation (e.g., composing imperative functions with reactive).
-
Support for reactive function with multiple inputs and outputs allowing merging, joining and other complex streaming operation to be handled by functions.
-
Transparent type conversion of inputs and outputs.
-
Packaging functions for deployments, specific to the target platform (e.g., Project Riff, AWS Lambda and more)
-
Adapters to expose function to the outside world as HTTP endpoints etc.
-
Deploying a JAR file containing such an application context with an isolated classloader, so that you can pack them together in a single JVM.
-
Adapters for AWS Lambda, Azure, Google Cloud Functions, Apache OpenWhisk and possibly other "serverless" service providers.
| Spring Cloud is released under the non-restrictive Apache 2.0 license. If you would like to contribute to this section of the documentation or if you find an error, please find the source code and issue trackers in the project at github. |
Getting Started
Build from the command line (and "install" the samples):
$ ./mvnw clean install
(If you like to YOLO add -DskipTests.)
Run one of the samples, e.g.
$ java -jar spring-cloud-function-samples/function-sample/target/*.jar
This runs the app and exposes its functions over HTTP, so you can convert a string to uppercase, like this:
$ curl -H "Content-Type: text/plain" localhost:8080/uppercase -d Hello HELLO
You can convert multiple strings (a Flux<String>) by separating them
with new lines
$ curl -H "Content-Type: text/plain" localhost:8080/uppercase -d 'Hello > World' HELLOWORLD
(You can use QJ in a terminal to insert a new line in a literal
string like that.)
Programming model
Function Catalog and Flexible Function Signatures
One of the main features of Spring Cloud Function is to adapt and support a range of type signatures for user-defined functions,
while providing a consistent execution model.
That’s why all user defined functions are transformed into a canonical representation by FunctionCatalog.
While users don’t normally have to care about the FunctionCatalog at all, it is useful to know what
kind of functions are supported in user code.
It is also important to understand that Spring Cloud Function provides first class support for reactive API
provided by Project Reactor allowing reactive primitives such as Mono and Flux
to be used as types in user defined functions providing greater flexibility when choosing programming model for
your function implementation.
Reactive programming model also enables functional support for features that would be otherwise difficult to impossible to implement
using imperative programming style. For more on this please read Function Arity section.
Java 8 function support
Spring Cloud Function embraces and builds on top of the 3 core functional interfaces defined by Java and available to us since Java 8.
-
Supplier<O>
-
Function<I, O>
-
Consumer<I>
In a nutshell, any bean in your Application Context that is of type Supplier, Function or Consumer could be registered with FunctionCatalog.
This means that it could benefit from all the features described in this reference manual.
Filtering ineligible functions
A typical Application Context may include beans that are valid java functions, but not intended to be candidates to be registered with FunctionCatalog.
Such beans could be auto-configurations from other projects or any other beans that qualify to be Java functions.
The framework provides default filtering of known beans that should not be candidates for registration with function catalog.
You can also add to this list additional beans by providing coma delimited list of bean definition names using
spring.cloud.function.ineligible-definitions property
For example,
spring.cloud.function.ineligible-definitions=foo,barSupplier
Supplier can be reactive - Supplier<Flux<T>>
or imperative - Supplier<T>. From the invocation standpoint this should make no difference
to the implementor of such Supplier. However, when used within frameworks
(e.g., Spring Cloud Stream), Suppliers, especially reactive,
often used to represent the source of the stream, therefore they are invoked once to get the stream (e.g., Flux)
to which consumers can subscribe to. In other words such suppliers represent an equivalent of an infinite stream.
However, the same reactive suppliers can also represent finite stream(s) (e.g., result set on the polled JDBC data).
In those cases such reactive suppliers must be hooked up to some polling mechanism of the underlying framework.
To assist with that Spring Cloud Function provides a marker annotation
org.springframework.cloud.function.context.PollableSupplier to signal that such supplier produces a
finite stream and may need to be polled again. That said, it is important to understand that Spring Cloud Function itself
provides no behavior for this annotation.
In addition PollableSupplier annotation exposes a splittable attribute to signal that produced stream
needs to be split (see Splitter EIP)
Here is the example:
@PollableSupplier(splittable = true)
public Supplier<Flux<String>> someSupplier() {
return () -> {
String v1 = String.valueOf(System.nanoTime());
String v2 = String.valueOf(System.nanoTime());
String v3 = String.valueOf(System.nanoTime());
return Flux.just(v1, v2, v3);
};
}
Function
Function can also be written in imperative or reactive way, yet unlike Supplier and Consumer there are no special considerations for the implementor other then understanding that when used within frameworks such as Spring Cloud Stream and others, reactive function is invoked only once to pass a reference to the stream (Flux or Mono) and imperative is invoked once per event.
Consumer
Consumer is a little bit special because it has a void return type,
which implies blocking, at least potentially. Most likely you will not
need to write Consumer<Flux<?>>, but if you do need to do that,
remember to subscribe to the input flux.
Function Composition
Function Composition is a feature that allows one to compose several functions into one. The core support is based on function composition feature available with Function.andThen(..) support available since Java 8. However on top of it, we provide few additional features.
Declarative Function Composition
This feature allows you to provide composition instruction in a declarative way using | (pipe) or , (comma) delimiter
when providing spring.cloud.function.definition property.
For example
--spring.cloud.function.definition=uppercase|reverse
Here we effectively provided a definition of a single function which itself is a composition of
function uppercase and function reverse. In fact that is one of the reasons why the property name is definition and not name,
since the definition of a function can be a composition of several named functions.
And as mentioned you can use , instead of pipe (such as …definition=uppercase,reverse).
Composing non-Functions
Spring Cloud Function also supports composing Supplier with Consumer or Function as well as Function with Consumer.
What’s important here is to understand the end product of such definitions.
Composing Supplier with Function still results in Supplier while composing Supplier with Consumer will effectively render Runnable.
Following the same logic composing Function with Consumer will result in Consumer.
And of course you can’t compose uncomposable such as Consumer and Function, Consumer and Supplier etc.
Function Routing and Filtering
Since version 2.2 Spring Cloud Function provides routing feature allowing you to invoke a single function which acts as a router to an actual function you wish to invoke This feature is very useful in certain FAAS environments where maintaining configurations for several functions could be cumbersome or exposing more then one function is not possible.
The RoutingFunction is registered in FunctionCatalog under the name functionRouter. For simplicity
and consistency you can also refer to RoutingFunction.FUNCTION_NAME constant.
This function has the following signature:
public class RoutingFunction implements Function<Object, Object> {
. . .
}
The routing instructions could be communicated in several ways. We support providing instructions via Message headers, System properties as well as pluggable strategy. So let’s look at some of the details
MessageRoutingCallback
The MessageRoutingCallback is a strategy to assist with determining the name of the route-to function definition.
public interface MessageRoutingCallback {
FunctionRoutingResult routingResult(Message<?> message);
. . .
}
All you need to do is implement and register it as a bean to be picked up by the RoutingFunction.
For example:
@Bean
public MessageRoutingCallback customRouter() {
return new MessageRoutingCallback() {
@Override
FunctionRoutingResult routingResult(Message<?> message) {
return new FunctionRoutingResult((String) message.getHeaders().get("func_name"));
}
};
}
In the preceding example you can see a very simple implementation of MessageRoutingCallback which determines the function definition from
func_name Message header of the incoming Message and returns the instance of FunctionRoutingResult containing the definition of function to invoke.
Additionally, the FunctionRoutingResult provides another constructor allowing you to provide an instance of Message as second argument to be used down stream.
This is primarily for runtime optimizations. To better understand this case let’s look at the following scenario.
You need to route based on the payoload type. However, an input Message typically comes in as let’s say JSON payload (as byte[]) . In order
to determine the route-to function definition you need to first process such JSON and potentially create an instance of the target type.
Once that determination is done you can pass it to RoutingFunction which still has a reference to the original Message with un-processed payload
This means that somewhere downstream, type conversion/transformation would need to be repeated.
Allowing you to create a new Message with converted payload as part of the FunctionRoutingResult will instruct RoutingFunction to use such Message
downstream. So effectively you letting the framework to benefit from the work you already did.
Message Headers
If the input argument is of type Message<?>, you can communicate routing instruction by setting one of
spring.cloud.function.definition or spring.cloud.function.routing-expression Message headers.
As the name of the property suggests spring.cloud.function.routing-expression relies on Spring Expression Language (SpEL).
For more static cases you can use spring.cloud.function.definition header which allows you to provide
the name of a single function (e.g., …definition=foo) or a composition instruction (e.g., …definition=foo|bar|baz).
For more dynamic cases you can use spring.cloud.function.routing-expression header and provide SpEL expression that should resolve
into definition of a function (as described above).
SpEL evaluation context’s root object is the
actual input argument, so in the case of Message<?> you can construct expression that has access
to both payload and headers (e.g., spring.cloud.function.routing-expression=headers.function_name).
|
SpEL allows user to provide string representation of Java code to be executed. Given that the spring.cloud.function.routing-expression could be provided via Message headers means that ability to set such expression could be exposed to the end user (i.e., HTTP Headers when using web module) which could result in some problems (e.g., malicious code). To manage that, all expressions coming via Message headers will only be evaluated against SimpleEvaluationContext which has limited functionality and designed to only evaluate the context object (Message in our case). On the other hand, all expressions that are set via property or system variable are evaluated against StandardEvaluationContext, which allows for full flexibility of Java language.
While setting expression via system/application property or environment variable is generally considered to be secure as it is not exposed to the end user in normal cases, there are cases where visibility as well as capability to update system, application and environment variables are indeed exposed to the end user via Spring Boot Actuator endpoints provided either by some of the Spring projects or third parties or custom implementation by the end user. Such endpoints must be secured using industry standard web security practices.
Spring Cloud Function does not expose any of such endpoints.
|
In specific execution environments/models the adapters are responsible to translate and communicate
spring.cloud.function.definition and/or spring.cloud.function.routing-expression via Message header.
For example, when using spring-cloud-function-web you can provide spring.cloud.function.definition as an HTTP
header and the framework will propagate it as well as other HTTP headers as Message headers.
Application Properties
Routing instruction can also be communicated via spring.cloud.function.definition
or spring.cloud.function.routing-expression as application properties. The rules described in the
previous section apply here as well. The only difference is you provide these instructions as
application properties (e.g., --spring.cloud.function.definition=foo).
It is important to understand that providing spring.cloud.function.definition
or spring.cloud.function.routing-expression as Message headers will only work for imperative functions (e.g., Function<Foo, Bar>).
That is to say that we can only route per-message with imperative functions. With reactive functions we can not route
per-message. Therefore you can only provide your routing instructions as Application Properties.
It’s all about unit-of-work. In imperative function unit of work is Message so we can route based on such unit-of-work.
With reactive function unit-of-work is the entire stream, so we’ll act only on the instruction provided via application
properties and route the entire stream.
|
Order of priority for routing instructions
Given that we have several mechanisms of providing routing instructions it is important to understand the priorities for conflict resolutions in the event multiple mechanisms are used at the same time, so here is the order:
-
MessageRoutingCallback(If function is imperative will take over regardless if anything else is defined) -
Message Headers (If function is imperative and no
MessageRoutingCallbackprovided) -
Application Properties (Any function)
Unroutable Messages
In the event route-to function is not available in catalog you will get an exception stating that.
There are cases when such behavior is not desired and you may want to have some "catch-all" type function which can handle such messages.
To accomplish that, framework provides org.springframework.cloud.function.context.DefaultMessageRoutingHandler strategy. All you need to do is register it as a bean.
Its default implementation will simply log the fact that the message is un-routable, but will allow message flow to proceed without the exception, effectively dropping the un-routable message.
If you want something more sophisticated all you need to do is provide your own implementation of this strategy and register it as a bean.
@Bean
public DefaultMessageRoutingHandler defaultRoutingHandler() {
return new DefaultMessageRoutingHandler() {
@Override
public void accept(Message<?> message) {
// do something really cool
}
};
}
Function Filtering
Filtering is the type of routing where there are only two paths - 'go' or 'discard'. In terms of functions it mean you only want to invoke a certain function if some condition returns 'true', otherwise you want to discard input. However, when it comes to discarding input there are many interpretation of what it could mean in the context of your application. For example, you may want to log it, or you may want to maintain the counter of discarded messages. you may also want to do nothing at all. Because of these different paths, we do not provide a general configuration option for how to deal with discarded messages. Instead we simply recommend to define a simple Consumer which would signify the 'discard' path:
@Bean
public Consumer<?> devNull() {
// log, count or whatever
}
Now you can have routing expression that really only has two paths effectively becoming a filter. For example:
--spring.cloud.function.routing-expression=headers.contentType.toString().equals('text/plain') ? 'echo' : 'devNull'Every message that does not fit criteria to go to 'echo' function will go to 'devNull' where you can simply do nothing with it.
The signature Consumer<?> will also ensure that no type conversion will be attempted resulting in almost no execution overhead.
| When dealing with reactive inputs (e.g., Publisher), routing instructions must only be provided via Function properties. This is due to the nature of the reactive functions which are invoked only once to pass a Publisher and the rest is handled by the reactor, hence we can not access and/or rely on the routing instructions communicated via individual values (e.g., Message). |
Multiple Routers
By default the framework will always have a single routing function configured as described in previous sections. However, there are times when you may need more then one routing function.
In that case you can create your own instance of the RoutingFunction bean in addition to the existing one as long as you give it a name other than functionRouter.
You can pass spring.cloud.function.routing-expression or spring.cloud.function.definition to RoutinFunction as key/value pairs in the map.
Here is a simple example
@Configuration
protected static class MultipleRouterConfiguration {
@Bean
RoutingFunction mySpecialRouter(FunctionCatalog functionCatalog, BeanFactory beanFactory, @Nullable MessageRoutingCallback routingCallback) {
Map<String, String> propertiesMap = new HashMap<>();
propertiesMap.put(FunctionProperties.PREFIX + ".routing-expression", "'reverse'");
return new RoutingFunction(functionCatalog, propertiesMap, new BeanFactoryResolver(beanFactory), routingCallback);
}
@Bean
public Function<String, String> reverse() {
return v -> new StringBuilder(v).reverse().toString();
}
@Bean
public Function<String, String> uppercase() {
return String::toUpperCase;
}
}
and a test that demonstrates how it works
`
@Test
public void testMultipleRouters() {
System.setProperty(FunctionProperties.PREFIX + ".routing-expression", "'uppercase'");
FunctionCatalog functionCatalog = this.configureCatalog(MultipleRouterConfiguration.class);
Function function = functionCatalog.lookup(RoutingFunction.FUNCTION_NAME);
assertThat(function).isNotNull();
Message<String> message = MessageBuilder.withPayload("hello").build();
assertThat(function.apply(message)).isEqualTo("HELLO");
function = functionCatalog.lookup("mySpecialRouter");
assertThat(function).isNotNull();
message = MessageBuilder.withPayload("hello").build();
assertThat(function.apply(message)).isEqualTo("olleh");
}
Input/Output Enrichment
There are often times when you need to modify or refine an incoming or outgoing Message and to keep your code clean of non-functional concerns. You don’t want to do it inside of your business logic.
You can always accomplish it via Function Composition. Such approach provides several benefits:
-
It allows you to isolate this non-functional concern into a separate function which you can compose with the business function as function definition.
-
It provides you with complete freedom (and danger) as to what you can modify before incoming message reaches the actual business function.
@Bean
public Function<Message<?>, Message<?>> enrich() {
return message -> MessageBuilder.fromMessage(message).setHeader("foo", "bar").build();
}
@Bean
public Function<Message<?>, Message<?>> myBusinessFunction() {
// do whatever
}
And then compose your function by providing the following function definition enrich|myBusinessFunction.
While the described approach is the most flexible, it is also the most involved as it requires you to write some code, make it a bean or manually register it as a function before you can compose it with the business function as you can see from the preceding example.
But what if modifications (enrichments) you are trying to make are trivial as they are in the preceding example? Is there a simpler and more dynamic and configurable mechanism to accomplish the same?
Since version 3.1.3, the framework allows you to provide SpEL expression to enrich individual message headers for both input going into function and and output coming out of it. Let’s look at one of the tests as the example.
@Test
public void testMixedInputOutputHeaderMapping() throws Exception {
try (ConfigurableApplicationContext context = new SpringApplicationBuilder(
SampleFunctionConfiguration.class).web(WebApplicationType.NONE).run(
"--logging.level.org.springframework.cloud.function=DEBUG",
"--spring.main.lazy-initialization=true",
"--spring.cloud.function.configuration.split.output-header-mapping-expression.keyOut1='hello1'",
"--spring.cloud.function.configuration.split.output-header-mapping-expression.keyOut2=headers.contentType",
"--spring.cloud.function.configuration.split.input-header-mapping-expression.key1=headers.path.split('/')[0]",
"--spring.cloud.function.configuration.split.input-header-mapping-expression.key2=headers.path.split('/')[1]",
"--spring.cloud.function.configuration.split.input-header-mapping-expression.key3=headers.path")) {
FunctionCatalog functionCatalog = context.getBean(FunctionCatalog.class);
FunctionInvocationWrapper function = functionCatalog.lookup("split");
Message<byte[]> result = (Message<byte[]>) function.apply(MessageBuilder.withPayload("helo")
.setHeader(MessageHeaders.CONTENT_TYPE, "application/json")
.setHeader("path", "foo/bar/baz").build());
assertThat(result.getHeaders().containsKey("keyOut1")).isTrue();
assertThat(result.getHeaders().get("keyOut1")).isEqualTo("hello1");
assertThat(result.getHeaders().containsKey("keyOut2")).isTrue();
assertThat(result.getHeaders().get("keyOut2")).isEqualTo("application/json");
}
}
Here you see a properties called input-header-mapping-expression and output-header-mapping-expression preceded by the name of the function (i.e., split) and followed by the name of the message header key you want to set and the value as SpEL expression. The first expression (for 'keyOut1') is literal SpEL expressions enclosed in single quotes, effectively setting 'keyOut1' to value hello1. The keyOut2 is set to the value of existing 'contentType' header.
You can also observe some interesting features in the input header mapping where we actually splitting a value of the existing header 'path', setting individual values of key1 and key2 to the values of split elements based on the index.
| if for whatever reason the provided expression evaluation fails, the execution of the function will proceed as if nothing ever happen. However you will see the WARN message in your logs informing you about it |
o.s.c.f.context.catalog.InputEnricher : Failed while evaluating expression "hello1" on incoming message. . .In the event you are dealing with functions that have multiple inputs (next section), you can use index immediately after input-header-mapping-expression
--spring.cloud.function.configuration.echo.input-header-mapping-expression[0].key1=‘hello1'
--spring.cloud.function.configuration.echo.input-header-mapping-expression[1].key2='hello2'Function Arity
There are times when a stream of data needs to be categorized and organized. For example, consider a classic big-data use case of dealing with unorganized data containing, let’s say, ‘orders’ and ‘invoices’, and you want each to go into a separate data store. This is where function arity (functions with multiple inputs and outputs) support comes to play.
Let’s look at an example of such a function (full implementation details are available here),
@Bean
public Function<Flux<Integer>, Tuple2<Flux<String>, Flux<String>>> organise() {
return flux -> ...;
}
Given that Project Reactor is a core dependency of SCF, we are using its Tuple library. Tuples give us a unique advantage by communicating to us both cardinality and type information. Both are extremely important in the context of SCSt. Cardinality lets us know how many input and output bindings need to be created and bound to the corresponding inputs and outputs of a function. Awareness of the type information ensures proper type conversion.
Also, this is where the ‘index’ part of the naming convention for binding
names comes into play, since, in this function, the two output binding
names are organise-out-0 and organise-out-1.
IMPORTANT: At the moment, function arity is only supported for reactive functions
(Function<TupleN<Flux<?>…>, TupleN<Flux<?>…>>) centered on Complex event processing
where evaluation and computation on confluence of events typically requires view into a
stream of events rather than single event.
|
Input Header propagation
In a typical scenario input Message headers are not propagated to output and rightfully so, since the output of a function may be an input to something else requiring it’s own set of Message headers. However, there are times when such propagation may be necessary so Spring Cloud Function provides several mechanisms to accomplish this.
First you can always copy headers manually. For example, if you have a Function with the signature that takes Message and returns Message (i.e., Function<Message, Message>), you can simply and selectively copy headers yourselves. Remember, if your function returns Message, the framework will not do anything to it other then properly converting its payload.
However, such approach may prove to be a bit tedious, especially in cases when you simply want to copy all headers.
To assist with cases like this we provide a simple property that would allow you to set a boolean flag on a function where you want input headers to be propagated.
The property is copy-input-headers.
For example, let’s assume you have the following configuration:
@EnableAutoConfiguration
@Configuration
protected static class InputHeaderPropagationConfiguration {
@Bean
public Function<String, String> uppercase() {
return x -> x.toUpperCase();
}
}
As you know you can still invoke this function by sending a Message to it (framework will take care of type conversion and payload extraction)
By simply setting spring.cloud.function.configuration.uppercase.copy-input-headers to true, the following assertion will be true as well
Function<Message<String>, Message<byte[]>> uppercase = catalog.lookup("uppercase", "application/json");
Message<byte[]> result = uppercase.apply(MessageBuilder.withPayload("bob").setHeader("foo", "bar").build());
assertThat(result.getHeaders()).containsKey("foo");
Type conversion (Content-Type negotiation)
Content-Type negotiation is one of the core features of Spring Cloud Function as it allows to not only transform the incoming data to the types declared by the function signature, but to do the same transformation during function composition making otherwise un-composable (by type) functions composable.
To better understand the mechanics and the necessity behind content-type negotiation, we take a look at a very simple use case by using the following function as an example:
@Bean
public Function<Person, String> personFunction {..}
The function shown in the preceding example expects a Person object as an argument and produces a String type as an output. If such function is
invoked with the type Person, than all works fine. But typically function plays a role of a handler for the incoming data which most often comes
in the raw format such as byte[], JSON String etc. In order for the framework to succeed in passing the incoming data as an argument to
this function, it has to somehow transform the incoming data to a Person type.
Spring Cloud Function relies on two native to Spring mechanisms to accomplish that.
-
MessageConverter - to convert from incoming Message data to a type declared by the function.
-
ConversionService - to convert from incoming non-Message data to a type declared by the function.
This means that depending on the type of the raw data (Message or non-Message) Spring Cloud Function will apply one or the other mechanisms.
For most cases when dealing with functions that are invoked as part of some other request (e.g., HTTP, Messaging etc) the framework relies on MessageConverters,
since such requests already converted to Spring Message. In other words, the framework locates and applies the appropriate MessageConverter.
To accomplish that, the framework needs some instructions from the user. One of these instructions is already provided by the signature of the function
itself (Person type). Consequently, in theory, that should be (and, in some cases, is) enough. However, for the majority of use cases, in order to
select the appropriate MessageConverter, the framework needs an additional piece of information. That missing piece is contentType header.
Such header usually comes as part of the Message where it is injected by the corresponding adapter that created such Message in the first place.
For example, HTTP POST request will have its content-type HTTP header copied to contentType header of the Message.
For cases when such header does not exist framework relies on the default content type as application/json.
Content Type versus Argument Type
As mentioned earlier, for the framework to select the appropriate MessageConverter, it requires argument type and, optionally, content type information.
The logic for selecting the appropriate MessageConverter resides with the argument resolvers which trigger right before the invocation of the user-defined
function (which is when the actual argument type is known to the framework).
If the argument type does not match the type of the current payload, the framework delegates to the stack of the
pre-configured MessageConverters to see if any one of them can convert the payload.
The combination of contentType and argument type is the mechanism by which framework determines if message can be converted to a target type by locating
the appropriate MessageConverter.
If no appropriate MessageConverter is found, an exception is thrown, which you can handle by adding a custom MessageConverter
(see User-defined Message Converters).
Do not expect Message to be converted into some other type based only on the contentType.
Remember that the contentType is complementary to the target type.
It is a hint, which MessageConverter may or may not take into consideration.
|
Message Converters
MessageConverters define two methods:
Object fromMessage(Message<?> message, Class<?> targetClass);
Message<?> toMessage(Object payload, @Nullable MessageHeaders headers);
It is important to understand the contract of these methods and their usage, specifically in the context of Spring Cloud Stream.
The fromMessage method converts an incoming Message to an argument type.
The payload of the Message could be any type, and it is
up to the actual implementation of the MessageConverter to support multiple types.
Provided MessageConverters
As mentioned earlier, the framework already provides a stack of MessageConverters to handle most common use cases.
The following list describes the provided MessageConverters, in order of precedence (the first MessageConverter that works is used):
-
JsonMessageConverter: Supports conversion of the payload of theMessageto/from POJO for cases whencontentTypeisapplication/jsonusing Jackson or Gson libraries (DEFAULT). -
ByteArrayMessageConverter: Supports conversion of the payload of theMessagefrombyte[]tobyte[]for cases whencontentTypeisapplication/octet-stream. It is essentially a pass through and exists primarily for backward compatibility. -
StringMessageConverter: Supports conversion of any type to aStringwhencontentTypeistext/plain.
When no appropriate converter is found, the framework throws an exception. When that happens, you should check your code and configuration and ensure you did
not miss anything (that is, ensure that you provided a contentType by using a binding or a header).
However, most likely, you found some uncommon case (such as a custom contentType perhaps) and the current stack of provided MessageConverters
does not know how to convert. If that is the case, you can add custom MessageConverter. See User-defined Message Converters.
User-defined Message Converters
Spring Cloud Function exposes a mechanism to define and register additional MessageConverters.
To use it, implement org.springframework.messaging.converter.MessageConverter, configure it as a @Bean.
It is then appended to the existing stack of `MessageConverter`s.
It is important to understand that custom MessageConverter implementations are added to the head of the existing stack.
Consequently, custom MessageConverter implementations take precedence over the existing ones, which lets you override as well as add to the existing converters.
|
The following example shows how to create a message converter bean to support a new content type called application/bar:
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter customMessageConverter() {
return new MyCustomMessageConverter();
}
}
public class MyCustomMessageConverter extends AbstractMessageConverter {
public MyCustomMessageConverter() {
super(new MimeType("application", "bar"));
}
@Override
protected boolean supports(Class<?> clazz) {
return (Bar.class.equals(clazz));
}
@Override
protected Object convertFromInternal(Message<?> message, Class<?> targetClass, Object conversionHint) {
Object payload = message.getPayload();
return (payload instanceof Bar ? payload : new Bar((byte[]) payload));
}
}
Note on JSON options
In Spring Cloud Function we support Jackson and Gson mechanisms to deal with JSON.
And for your benefit have abstracted it under org.springframework.cloud.function.json.JsonMapper which itself is aware of two mechanisms and will use the one selected
by you or following the default rule.
The default rules are as follows:
-
Whichever library is on the classpath that is the mechanism that is going to be used. So if you have
com.fasterxml.jackson.*to the classpath, Jackson is going to be used and if you havecom.google.code.gson, then Gson will be used. -
If you have both, then Gson will be the default, or you can set
spring.cloud.function.preferred-json-mapperproperty with either of two values:gsonorjackson.
That said, the type conversion is usually transparent to the developer, however given that org.springframework.cloud.function.json.JsonMapper is also registered as a bean
you can easily inject it into your code if needed.
Kotlin Lambda support
We also provide support for Kotlin lambdas (since v2.0). Consider the following:
@Bean
open fun kotlinSupplier(): () -> String {
return { "Hello from Kotlin" }
}
@Bean
open fun kotlinFunction(): (String) -> String {
return { it.toUpperCase() }
}
@Bean
open fun kotlinConsumer(): (String) -> Unit {
return { println(it) }
}
The above represents Kotlin lambdas configured as Spring beans. The signature of each maps to a Java equivalent of
Supplier, Function and Consumer, and thus supported/recognized signatures by the framework.
While mechanics of Kotlin-to-Java mapping are outside of the scope of this documentation, it is important to understand that the
same rules for signature transformation outlined in "Java 8 function support" section are applied here as well.
To enable Kotlin support all you need is to add Kotlin SDK libraries on the classpath which will trigger appropriate autoconfiguration and supporting classes.
Function Component Scan
Spring Cloud Function will scan for implementations of Function, Consumer and Supplier in a package called functions if it exists. Using this
feature you can write functions that have no dependencies on Spring - not even the @Component annotation is needed. If you want to use a different
package, you can set spring.cloud.function.scan.packages. You can also use spring.cloud.function.scan.enabled=false to switch off the scan completely.
Standalone Web Applications
Functions could be automatically exported as HTTP endpoints.
The spring-cloud-function-web module has autoconfiguration that
activates when it is included in a Spring Boot web application (with
MVC support). There is also a spring-cloud-starter-function-web to
collect all the optional dependencies in case you just want a simple
getting started experience.
With the web configurations activated your app will have an MVC
endpoint (on "/" by default, but configurable with
spring.cloud.function.web.path) that can be used to access the
functions in the application context where function name becomes part of the URL path. The supported content types are
plain text and JSON.
| Method | Path | Request | Response | Status |
|---|---|---|---|---|
GET |
/{supplier} |
- |
Items from the named supplier |
200 OK |
POST |
/{consumer} |
JSON object or text |
Mirrors input and pushes request body into consumer |
202 Accepted |
POST |
/{consumer} |
JSON array or text with new lines |
Mirrors input and pushes body into consumer one by one |
202 Accepted |
POST |
/{function} |
JSON object or text |
The result of applying the named function |
200 OK |
POST |
/{function} |
JSON array or text with new lines |
The result of applying the named function |
200 OK |
GET |
/{function}/{item} |
- |
Convert the item into an object and return the result of applying the function |
200 OK |
As the table above shows the behavior of the endpoint depends on the method and also the type of incoming request data. When the incoming data is single valued, and the target function is declared as obviously single valued (i.e. not returning a collection or Flux), then the response will also contain a single value.
For multi-valued responses the client can ask for a server-sent event stream by sending `Accept: text/event-stream".
Functions and consumers that are declared with input and output in Message<?> will see the request headers as message headers, and the output message headers will be converted to HTTP headers.
The payload of the Message will be a body or empty string if there is no body or it is null.
When POSTing text the response format might be different with Spring Boot 2.0 and older versions, depending on the content negotiation (provide content type and accept headers for the best results).
See Testing Functional Applications to see the details and example on how to test such application.
HTTP Request Parameters
As you have noticed from the previous table, you can pass an argument to a function as path variable (i.e., /{function}/{item}).
For example, http://localhost:8080/uppercase/foo will result in calling uppercase function with its input parameter being foo.
While this is the recommended approach and the one that fits most use cases cases, there are times when you have to deal with HTTP request parameters (e.g., http://localhost:8080/uppercase/foo?name=Bill)
The framework will treat HTTP request parameters similar to the HTTP headers by storing them in the Message headers under the header key http_request_param
with its value being a Map of request parameters, so in order to access them your function input signature should accept Message type (e.g., Function<Message<String>, String>). For convenience we provide HeaderUtils.HTTP_REQUEST_PARAM constant.
Function Mapping rules
If there is only a single function (consumer etc.) in the catalog, the name in the path is optional.
In other words, providing you only have uppercase function in catalog
curl -H "Content-Type: text/plain" localhost:8080/uppercase -d hello and curl -H "Content-Type: text/plain" localhost:8080/ -d hello calls are identical.
Composite functions can be addressed using pipes or commas to separate function names (pipes are legal in URL paths, but a bit awkward to type on the command line).
For example, curl -H "Content-Type: text/plain" localhost:8080/uppercase,reverse -d hello.
For cases where there is more then a single function in catalog, each function will be exported and mapped with function name being
part of the path (e.g., localhost:8080/uppercase).
In this scenario you can still map specific function or function composition to the root path by providing
spring.cloud.function.definition property
For example,
--spring.cloud.function.definition=foo|bar
The above property will compose 'foo' and 'bar' function and map the composed function to the "/" path.
The same property will also work for cases where function can not be resolved via URL. For example, your URL may be localhost:8080/uppercase, but there is no uppercase function.
However there are function foo and bar. So, in this case localhost:8080/uppercase will resolve to foo|bar.
This could be useful especially for cases when URL is used to communicate certain information since there will be Message header called uri with the value
of the actual URL, giving user ability to use it for evaluation and computation.
Function Filtering rules
In situations where there are more then one function in catalog there may be a need to only export certain functions or function compositions. In that case you can use
the same spring.cloud.function.definition property listing functions you intend to export delimited by ;.
Note that in this case nothing will be mapped to the root path and functions that are not listed (including compositions) are not going to be exported
For example,
--spring.cloud.function.definition=foo;bar
This will only export function foo and function bar regardless how many functions are available in catalog (e.g., localhost:8080/foo).
--spring.cloud.function.definition=foo|bar;baz
This will only export function composition foo|bar and function baz regardless how many functions are available in catalog (e.g., localhost:8080/foo,bar).
Standalone Streaming Applications
To send or receive messages from a broker (such as RabbitMQ or Kafka) you can leverage spring-cloud-stream project and it’s integration with Spring Cloud Function.
Please refer to Spring Cloud Function section of the Spring Cloud Stream reference manual for more details and examples.
Deploying a Packaged Function
Spring Cloud Function provides a "deployer" library that allows you to launch a jar file (or exploded archive, or set of jar files) with an isolated class loader and expose the functions defined in it. This is quite a powerful tool that would allow you to, for instance, adapt a function to a range of different input-output adapters without changing the target jar file. Serverless platforms often have this kind of feature built in, so you could see it as a building block for a function invoker in such a platform (indeed the Riff Java function invoker uses this library).
The standard entry point is to add spring-cloud-function-deployer to the classpath, the deployer kicks in and looks for some configuration to tell it where to find the function jar.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-deployer</artifactId>
<version>${spring.cloud.function.version}</version>
</dependency>At a minimum the user has to provide a spring.cloud.function.location which is a URL or resource location for the archive containing
the functions. It can optionally use a maven: prefix to locate the artifact via a dependency lookup (see FunctionProperties
for complete details). A Spring Boot application is bootstrapped from the jar file, using the MANIFEST.MF to locate a start class, so
that a standard Spring Boot fat jar works well, for example. If the target jar can be launched successfully then the result is a function
registered in the main application’s FunctionCatalog. The registered function can be applied by code in the main application, even though
it was created in an isolated class loader (by deault).
Here is the example of deploying a JAR which contains an 'uppercase' function and invoking it .
@SpringBootApplication
public class DeployFunctionDemo {
public static void main(String[] args) {
ApplicationContext context = SpringApplication.run(DeployFunctionDemo.class,
"--spring.cloud.function.location=..../target/uppercase-0.0.1-SNAPSHOT.jar",
"--spring.cloud.function.definition=uppercase");
FunctionCatalog catalog = context.getBean(FunctionCatalog.class);
Function<String, String> function = catalog.lookup("uppercase");
System.out.println(function.apply("hello"));
}
}
And here is the example using Maven URI (taken from one of the tests in FunctionDeployerTests):
@SpringBootApplication
public class DeployFunctionDemo {
public static void main(String[] args) {
String[] args = new String[] {
"--spring.cloud.function.location=maven://oz.demo:demo-uppercase:0.0.1-SNAPSHOT",
"--spring.cloud.function.function-class=oz.demo.uppercase.MyFunction" };
ApplicationContext context = SpringApplication.run(DeployerApplication.class, args);
FunctionCatalog catalog = context.getBean(FunctionCatalog.class);
Function<String, String> function = catalog.lookup("myFunction");
assertThat(function.apply("bob")).isEqualTo("BOB");
}
}
Keep in mind that Maven resource such as local and remote repositories, user, password and more are resolved using default MavenProperties which
effectively use local defaults and will work for majority of cases. However if you need to customize you can simply provide a bean of type
MavenProperties where you can set additional properties (see example below).
@Bean
public MavenProperties mavenProperties() {
MavenProperties properties = new MavenProperties();
properties.setLocalRepository("target/it/");
return properties;
}
Supported Packaging Scenarios
Currently Spring Cloud Function supports several packaging scenarios to give you the most flexibility when it comes to deploying functions.
Simple JAR
This packaging option implies no dependency on anything related to Spring. For example; Consider that such JAR contains the following class:
package function.example;
. . .
public class UpperCaseFunction implements Function<String, String> {
@Override
public String apply(String value) {
return value.toUpperCase();
}
}
All you need to do is specify location and function-class properties when deploying such package:
--spring.cloud.function.location=target/it/simplestjar/target/simplestjar-1.0.0.RELEASE.jar
--spring.cloud.function.function-class=function.example.UpperCaseFunctionIt’s conceivable in some cases that you might want to package multiple functions together. For such scenarios you can use
spring.cloud.function.function-class property to list several classes delimiting them by ;.
For example,
--spring.cloud.function.function-class=function.example.UpperCaseFunction;function.example.ReverseFunctionHere we are identifying two functions to deploy, which we can now access in function catalog by name (e.g., catalog.lookup("reverseFunction");).
For more details please reference the complete sample available here. You can also find a corresponding test in FunctionDeployerTests.
-
Component Scanning *
Since version 3.1.4 you can simplify your configuration thru component scanning feature described in Function Component Scan. If you place your functional class in
package named functions, you can omit spring.cloud.function.function-class property as framework will auto-discover functional classes loading them in function catalog.
Keep in mind the naming convention to follow when doing function lookup. For example function class functions.UpperCaseFunction will be available in FunctionCatalog
under the name upperCaseFunction.
Spring Boot JAR
This packaging option implies there is a dependency on Spring Boot and that the JAR was generated as Spring Boot JAR. That said, given that the deployed JAR runs in the isolated class loader, there will not be any version conflict with the Spring Boot version used by the actual deployer. For example; Consider that such JAR contains the following class (which could have some additional Spring dependencies providing Spring/Spring Boot is on the classpath):
package function.example;
. . .
public class UpperCaseFunction implements Function<String, String> {
@Override
public String apply(String value) {
return value.toUpperCase();
}
}
As before all you need to do is specify location and function-class properties when deploying such package:
--spring.cloud.function.location=target/it/simplestjar/target/simplestjar-1.0.0.RELEASE.jar
--spring.cloud.function.function-class=function.example.UpperCaseFunctionFor more details please reference the complete sample available here. You can also find a corresponding test in FunctionDeployerTests.
Spring Boot Application
This packaging option implies your JAR is complete stand alone Spring Boot application with functions as managed Spring beans. As before there is an obvious assumption that there is a dependency on Spring Boot and that the JAR was generated as Spring Boot JAR. That said, given that the deployed JAR runs in the isolated class loader, there will not be any version conflict with the Spring Boot version used by the actual deployer. For example; Consider that such JAR contains the following class:
package function.example;
. . .
@SpringBootApplication
public class SimpleFunctionAppApplication {
public static void main(String[] args) {
SpringApplication.run(SimpleFunctionAppApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}
Given that we’re effectively dealing with another Spring Application context and that functions are spring managed beans,
in addition to the location property we also specify definition property instead of function-class.
--spring.cloud.function.location=target/it/bootapp/target/bootapp-1.0.0.RELEASE-exec.jar
--spring.cloud.function.definition=uppercaseFor more details please reference the complete sample available here. You can also find a corresponding test in FunctionDeployerTests.
| This particular deployment option may or may not have Spring Cloud Function on it’s classpath. From the deployer perspective this doesn’t matter. |
Functional Bean Definitions
Spring Cloud Function supports a "functional" style of bean declarations for small apps where you need fast startup. The functional style of bean declaration was a feature of Spring Framework 5.0 with significant enhancements in 5.1.
Comparing Functional with Traditional Bean Definitions
Here’s a vanilla Spring Cloud Function application from with the
familiar @Configuration and @Bean declaration style:
@SpringBootApplication
public class DemoApplication {
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
Now for the functional beans: the user application code can be recast into "functional" form, like this:
@SpringBootConfiguration
public class DemoApplication implements ApplicationContextInitializer<GenericApplicationContext> {
public static void main(String[] args) {
FunctionalSpringApplication.run(DemoApplication.class, args);
}
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
@Override
public void initialize(GenericApplicationContext context) {
context.registerBean("demo", FunctionRegistration.class,
() -> new FunctionRegistration<>(uppercase())
.type(FunctionTypeUtils.functionType(String.class, String.class)));
}
}
The main differences are:
-
The main class is an
ApplicationContextInitializer. -
The
@Beanmethods have been converted to calls tocontext.registerBean() -
The
@SpringBootApplicationhas been replaced with@SpringBootConfigurationto signify that we are not enabling Spring Boot autoconfiguration, and yet still marking the class as an "entry point". -
The
SpringApplicationfrom Spring Boot has been replaced with aFunctionalSpringApplicationfrom Spring Cloud Function (it’s a subclass).
The business logic beans that you register in a Spring Cloud Function app are of type FunctionRegistration.
This is a wrapper that contains both the function and information about the input and output types. In the @Bean
form of the application that information can be derived reflectively, but in a functional bean registration some of
it is lost unless we use a FunctionRegistration.
An alternative to using an ApplicationContextInitializer and FunctionRegistration is to make the application
itself implement Function (or Consumer or Supplier). Example (equivalent to the above):
@SpringBootConfiguration
public class DemoApplication implements Function<String, String> {
public static void main(String[] args) {
FunctionalSpringApplication.run(DemoApplication.class, args);
}
@Override
public String apply(String value) {
return value.toUpperCase();
}
}
It would also work if you add a separate, standalone class of type Function and register it with
the SpringApplication using an alternative form of the run() method. The main thing is that the generic
type information is available at runtime through the class declaration.
Suppose you have
@Component
public class CustomFunction implements Function<Flux<Foo>, Flux<Bar>> {
@Override
public Flux<Bar> apply(Flux<Foo> flux) {
return flux.map(foo -> new Bar("This is a Bar object from Foo value: " + foo.getValue()));
}
}
You register it as such:
@Override
public void initialize(GenericApplicationContext context) {
context.registerBean("function", FunctionRegistration.class,
() -> new FunctionRegistration<>(new CustomFunction()).type(CustomFunction.class));
}
Limitations of Functional Bean Declaration
Most Spring Cloud Function apps have a relatively small scope compared to the whole of Spring Boot,
so we are able to adapt it to these functional bean definitions easily. If you step outside that limited scope,
you can extend your Spring Cloud Function app by switching back to @Bean style configuration, or by using a hybrid
approach. If you want to take advantage of Spring Boot autoconfiguration for integrations with external datastores,
for example, you will need to use @EnableAutoConfiguration. Your functions can still be defined using the functional
declarations if you want (i.e. the "hybrid" style), but in that case you will need to explicitly switch off the "full
functional mode" using spring.functional.enabled=false so that Spring Boot can take back control.
Function visualization and control
Spring Cloud Function supports visualization of functions available in FunctionCatalog through Actuator endpoints as well as programmatic way.
Programmatic way
To see function available within your application context programmatically all you need is access to FunctionCatalog. There you can
finds methods to get the size of the catalog, lookup functions as well as list the names of all the available functions.
For example,
FunctionCatalog functionCatalog = context.getBean(FunctionCatalog.class);
int size = functionCatalog.size(); // will tell you how many functions available in catalog
Set<String> names = functionCatalog.getNames(null); will list the names of all the Function, Suppliers and Consumers available in catalog
. . .
Actuator
Since actuator and web are optional, you must first add one of the web dependencies as well as add the actuator dependency manually. The following example shows how to add the dependency for the Web framework:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>The following example shows how to add the dependency for the WebFlux framework:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>You can add the Actuator dependency as follows:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>You must also enable the functions actuator endpoints by setting the following property: --management.endpoints.web.exposure.include=functions.
Access the following URL to see the functions in FunctionCatalog:
http://<host>:<port>/actuator/functions
For example,
curl http://localhost:8080/actuator/functionsYour output should look something like this:
{"charCounter":
{"type":"FUNCTION","input-type":"string","output-type":"integer"},
"logger":
{"type":"CONSUMER","input-type":"string"},
"functionRouter":
{"type":"FUNCTION","input-type":"object","output-type":"object"},
"words":
{"type":"SUPPLIER","output-type":"string"}. . .Testing Functional Applications
Spring Cloud Function also has some utilities for integration testing that will be very familiar to Spring Boot users.
Suppose this is your application:
@SpringBootApplication
public class SampleFunctionApplication {
public static void main(String[] args) {
SpringApplication.run(SampleFunctionApplication.class, args);
}
@Bean
public Function<String, String> uppercase() {
return v -> v.toUpperCase();
}
}
Here is an integration test for the HTTP server wrapping this application:
@SpringBootTest(classes = SampleFunctionApplication.class,
webEnvironment = WebEnvironment.RANDOM_PORT)
public class WebFunctionTests {
@Autowired
private TestRestTemplate rest;
@Test
public void test() throws Exception {
ResponseEntity<String> result = this.rest.exchange(
RequestEntity.post(new URI("/uppercase")).body("hello"), String.class);
System.out.println(result.getBody());
}
}
or when function bean definition style is used:
@FunctionalSpringBootTest
public class WebFunctionTests {
@Autowired
private TestRestTemplate rest;
@Test
public void test() throws Exception {
ResponseEntity<String> result = this.rest.exchange(
RequestEntity.post(new URI("/uppercase")).body("hello"), String.class);
System.out.println(result.getBody());
}
}
This test is almost identical to the one you would write for the @Bean version of the same app - the only difference
is the @FunctionalSpringBootTest annotation, instead of the regular @SpringBootTest. All the other pieces,
like the @Autowired TestRestTemplate, are standard Spring Boot features.
And to help with correct dependencies here is the excerpt from POM
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.15</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
. . . .
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-web</artifactId>
<version>3.2.12-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>Or you could write a test for a non-HTTP app using just the FunctionCatalog. For example:
@FunctionalSpringBootTest
public class FunctionalTests {
@Autowired
private FunctionCatalog catalog;
@Test
public void words() {
Function<String, String> function = catalog.lookup(Function.class,
"uppercase");
assertThat(function.apply("hello")).isEqualTo("HELLO");
}
}
Serverless Platform Adapters
As well as being able to run as a standalone process, a Spring Cloud Function application can be adapted to run one of the existing serverless platforms. In the project there are adapters for AWS Lambda, Azure, and Apache OpenWhisk. The Oracle Fn platform has its own Spring Cloud Function adapter. And Riff supports Java functions and its Java Function Invoker acts natively is an adapter for Spring Cloud Function jars.
AWS Lambda
The AWS adapter takes a Spring Cloud Function app and converts it to a form that can run in AWS Lambda.
The details of how to get stared with AWS Lambda is out of scope of this document, so the expectation is that user has some familiarity with AWS and AWS Lambda and wants to learn what additional value spring provides.
Getting Started
One of the goals of Spring Cloud Function framework is to provide necessary infrastructure elements to enable a simple function application to interact in a certain way in a particular environment. A simple function application (in context or Spring) is an application that contains beans of type Supplier, Function or Consumer. So, with AWS it means that a simple function bean should somehow be recognised and executed in AWS Lambda environment.
Let’s look at the example:
@SpringBootApplication
public class FunctionConfiguration {
public static void main(String[] args) {
SpringApplication.run(FunctionConfiguration.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}
It shows a complete Spring Boot application with a function bean defined in it. What’s interesting is that on the surface this is just another boot app, but in the context of AWS Adapter it is also a perfectly valid AWS Lambda application. No other code or configuration is required. All you need to do is package it and deploy it, so let’s look how we can do that.
To make things simpler we’ve provided a sample project ready to be built and deployed and you can access it here.
You simply execute ./mvnw clean package to generate JAR file. All the necessary maven plugins have already been setup to generate
appropriate AWS deployable JAR file. (You can read more details about JAR layout in Notes on JAR Layout).
Then you have to upload the JAR file (via AWS dashboard or AWS CLI) to AWS.
When ask about handler you specify org.springframework.cloud.function.adapter.aws.FunctionInvoker::handleRequest which is a generic request handler.
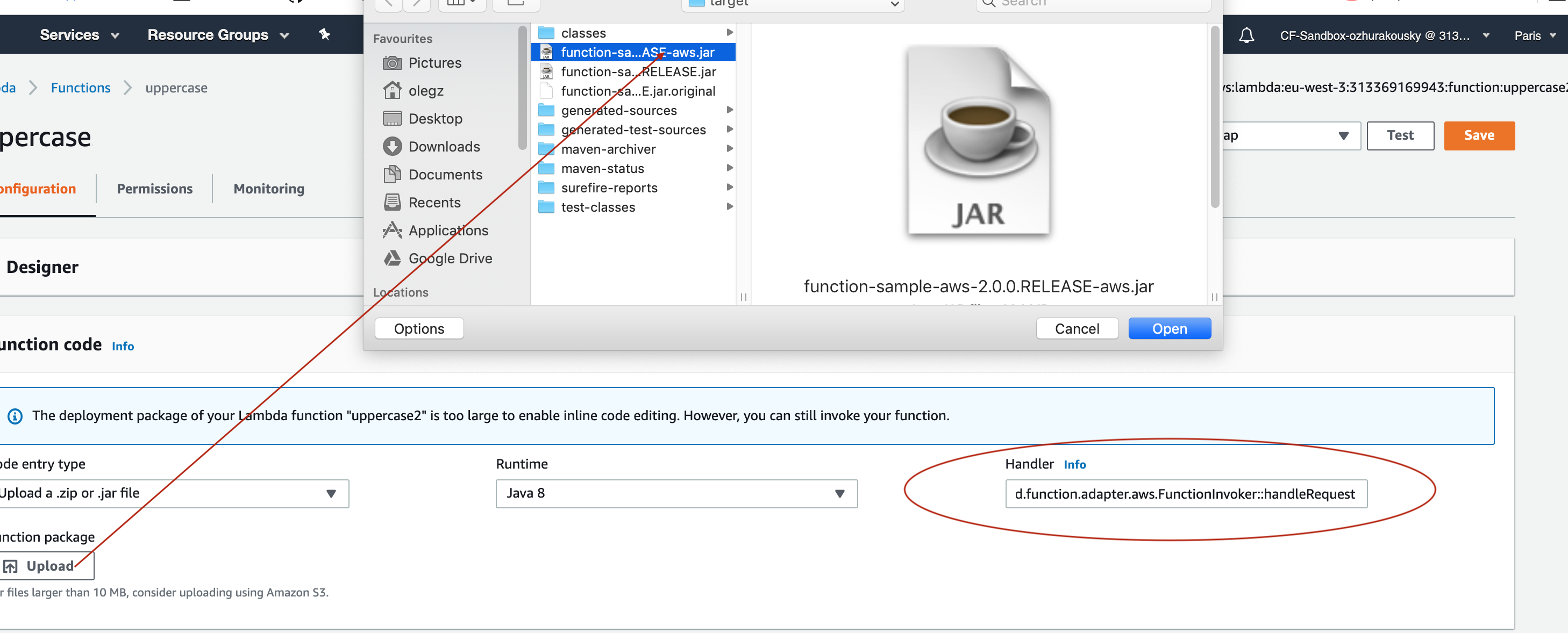
That is all. Save and execute the function with some sample data which for this function is expected to be a String which function will uppercase and return back.
While org.springframework.cloud.function.adapter.aws.FunctionInvoker is a general purpose AWS’s RequestHandler implementation aimed at completely
isolating you from the specifics of AWS Lambda API, for some cases you may want to specify which specific AWS’s RequestHandler you want
to use. The next section will explain you how you can accomplish just that.
AWS Request Handlers
The adapter has a couple of generic request handlers that you can use. The most generic is (and the one we used in the Getting Started section)
is org.springframework.cloud.function.adapter.aws.FunctionInvoker which is the implementation of AWS’s RequestStreamHandler.
User doesn’t need to do anything other then specify it as 'handler' on AWS dashboard when deploying function.
It will handle most of the case including Kinesis, streaming etc. .
If your app has more than one @Bean of type Function etc. then you can choose the one to use by configuring spring.cloud.function.definition
property or environment variable. The functions are extracted from the Spring Cloud FunctionCatalog. In the event you don’t specify spring.cloud.function.definition
the framework will attempt to find a default following the search order where it searches first for Function then Consumer and finally Supplier).
AWS Function Routing
One of the core features of Spring Cloud Function is routing - an ability to have one special function to delegate to other functions based on the user provided routing instructions.
In AWS Lambda environment this feature provides one additional benefit, as it allows you to bind a single function (Routing Function) as AWS Lambda and thus a single HTTP endpoint for API Gateway. So in the end you only manage one function and one endpoint, while benefiting from many function that can be part of your application.
More details are available in the provided sample, yet few general things worth mentioning.
Routing capabilities will be enabled by default whenever there is more then one function in your application as org.springframework.cloud.function.adapter.aws.FunctionInvoker
can not determine which function to bind as AWS Lambda, so it defaults to RoutingFunction.
This means that all you need to do is provide routing instructions which you can do using several mechanisms
(see sample for more details).
Also, note that since AWS does not allow dots . and/or hyphens`-` in the name of the environment variable, you can benefit from boot support and simply substitute
dots with underscores and hyphens with camel case. So for example spring.cloud.function.definition becomes spring_cloud_function_definition
and spring.cloud.function.routing-expression becomes spring_cloud_function_routingExpression.
AWS Function Routing with Custom Runtime
When using [Custom Runtime] Function Routing works the same way. All you need is to specify functionRouter as AWS Handler the same way you would use the name of the function as handler.
Notes on JAR Layout
You don’t need the Spring Cloud Function Web or Stream adapter at runtime in Lambda, so you might
need to exclude those before you create the JAR you send to AWS. A Lambda application has to be
shaded, but a Spring Boot standalone application does not, so you can run the same app using 2
separate jars (as per the sample). The sample app creates 2 jar files, one with an aws
classifier for deploying in Lambda, and one executable (thin) jar that includes spring-cloud-function-web
at runtime. Spring Cloud Function will try and locate a "main class" for you from the JAR file
manifest, using the Start-Class attribute (which will be added for you by the Spring Boot
tooling if you use the starter parent). If there is no Start-Class in your manifest you can
use an environment variable or system property MAIN_CLASS when you deploy the function to AWS.
If you are not using the functional bean definitions but relying on Spring Boot’s auto-configuration, then additional transformers must be configured as part of the maven-shade-plugin execution.
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.7.1</version>
</dependency>
</dependencies>
<executions>
<execution>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>aws</shadedClassifierName>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.handlers</resource>
</transformer>
<transformer implementation="org.springframework.boot.maven.PropertiesMergingResourceTransformer">
<resource>META-INF/spring.factories</resource>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.schemas</resource>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.components</resource>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>Build file setup
In order to run Spring Cloud Function applications on AWS Lambda, you can leverage Maven or Gradle plugins offered by the cloud platform provider.
Maven
In order to use the adapter plugin for Maven, add the plugin dependency to your pom.xml
file:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-adapter-aws</artifactId>
</dependency>
</dependencies>As pointed out in the Notes on JAR Layout, you will need a shaded jar in order to upload it to AWS Lambda. You can use the Maven Shade Plugin for that. The example of the setup can be found above.
You can use theSpring Boot Maven Plugin to generate the thin jar.
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot.experimental</groupId>
<artifactId>spring-boot-thin-layout</artifactId>
<version>${wrapper.version}</version>
</dependency>
</dependencies>
</plugin>You can find the entire sample pom.xml file for deploying Spring Cloud Function
applications to AWS Lambda with Maven here.
Gradle
In order to use the adapter plugin for Gradle, add the dependency to your build.gradle file:
dependencies {
compile("org.springframework.cloud:spring-cloud-function-adapter-aws:${version}")
}
As pointed out in Notes on JAR Layout, you will need a shaded jar in order to upload it to AWS Lambda. You can use the Gradle Shadow Plugin for that:
buildscript {
dependencies {
classpath "com.github.jengelman.gradle.plugins:shadow:${shadowPluginVersion}"
}
}
apply plugin: 'com.github.johnrengelman.shadow'
assemble.dependsOn = [shadowJar]
shadowJar {
classifier = 'aws'
dependencies {
exclude(
dependency("org.springframework.cloud:spring-cloud-function-web:${springCloudFunctionVersion}"))
}
// Required for Spring
mergeServiceFiles()
append 'META-INF/spring.handlers'
append 'META-INF/spring.schemas'
append 'META-INF/spring.tooling'
transform(PropertiesFileTransformer) {
paths = ['META-INF/spring.factories']
mergeStrategy = "append"
}
}
You can use the Spring Boot Gradle Plugin and Spring Boot Thin Gradle Plugin to generate the thin jar.
buildscript {
dependencies {
classpath("org.springframework.boot.experimental:spring-boot-thin-gradle-plugin:${wrapperVersion}")
classpath("org.springframework.boot:spring-boot-gradle-plugin:${springBootVersion}")
}
}
apply plugin: 'org.springframework.boot'
apply plugin: 'org.springframework.boot.experimental.thin-launcher'
assemble.dependsOn = [thinJar]
You can find the entire sample build.gradle file for deploying Spring Cloud Function
applications to AWS Lambda with Gradle here.
Upload
Build the sample under spring-cloud-function-samples/function-sample-aws and upload the -aws jar file to Lambda. The handler can be example.Handler or org.springframework.cloud.function.adapter.aws.SpringBootStreamHandler (FQN of the class, not a method reference, although Lambda does accept method references).
./mvnw -U clean package
Using the AWS command line tools it looks like this:
aws lambda create-function --function-name Uppercase --role arn:aws:iam::[USERID]:role/service-role/[ROLE] --zip-file fileb://function-sample-aws/target/function-sample-aws-2.0.0.BUILD-SNAPSHOT-aws.jar --handler org.springframework.cloud.function.adapter.aws.SpringBootStreamHandler --description "Spring Cloud Function Adapter Example" --runtime java8 --region us-east-1 --timeout 30 --memory-size 1024 --publish
The input type for the function in the AWS sample is a Foo with a single property called "value". So you would need this to test it:
{
"value": "test"
}
The AWS sample app is written in the "functional" style (as an ApplicationContextInitializer). This is much faster on startup in Lambda than the traditional @Bean style, so if you don’t need @Beans (or @EnableAutoConfiguration) it’s a good choice. Warm starts are not affected.
|
Type Conversion
Spring Cloud Function will attempt to transparently handle type conversion between the raw input stream and types declared by your function.
For example, if your function signature is as such Function<Foo, Bar> we will attempt to convert
incoming stream event to an instance of Foo.
In the event type is not known or can not be determined (e.g., Function<?, ?>) we will attempt to
convert an incoming stream event to a generic Map.
Raw Input
There are times when you may want to have access to a raw input. In this case all you need is to declare your
function signature to accept InputStream. For example, Function<InputStream, ?>. In this case
we will not attempt any conversion and will pass the raw input directly to a function.
Microsoft Azure
The Azure adapter bootstraps a Spring Cloud Function context and channels function calls from the Azure
framework into the user functions, using Spring Boot configuration where necessary. Azure Functions has quite a unique and
invasive programming model, involving annotations in user code that are specific to the Azure platform.
However, it is important to understand that because of the style of integration provided by Spring Cloud Function, specifically org.springframework.cloud.function.adapter.azure.FunctionInvoker, this annotation-based programming model is simply a type-safe way to configure
your simple java function (function that has no awareness of Azure) to be recognized as Azure function.
All you need to do is create a handler that extends FunctionInvoker, define and configure your function handler method and
make a callback to handleRequest(..) method. This handler method provides input and output types as annotated method parameters
(enabling Azure to inspect the class and create JSON bindings).
public class UppercaseHandler extends FunctionInvoker<Message<String>, String> {
@FunctionName("uppercase")
public String execute(@HttpTrigger(name = "req", methods = {HttpMethod.GET,
HttpMethod.POST}, authLevel = AuthorizationLevel.ANONYMOUS) HttpRequestMessage<Optional<String>> request,
ExecutionContext context) {
Message<String> message = MessageBuilder.withPayload(request.getBody().get()).copyHeaders(request.getHeaders()).build();
return handleRequest(message, context);
}
}
Note that aside form providing configuration via Azure annotation we create an instance of Message inside the body of this handler method and make a callback to handleRequest(..) method returning its result.
The actual user function you’re delagating to looks like this
@Bean
public Function<String, String> uppercase() {
return payload -> payload.toUpperCase();
}
OR
@Bean
public Function<Message<String>, String> uppercase() {
return message -> message.getPayload().toUpperCase();
}
Note that when creating a Message you can copy HTTP headers effectively making them available to you if necessary.
The org.springframework.cloud.function.adapter.azure.FunctionInvoker class has two useful
methods (handleRequest and handleOutput) to which you can delegate the actual function call, so mostly the function will only ever have one line.
The function name (definition) will be retrieved from Azure’s ExecutionContext.getFunctionName() method, effectively supporting multiple function in the application context.
Accessing Azure ExecutionContext
Some time there is a need to access the target execution context provided by the Azure runtime in the form of com.microsoft.azure.functions.ExecutionContext.
For example one of such needs is logging, so it can appear in the Azure console.
For that purpose the FunctionInvoker will add an instance of the ExecutionContext as a Message header so you can retrieve it via executionContext key.
@Bean
public Function<Message<String>, String> uppercase(JsonMapper mapper) {
return message -> {
String value = message.getPayload();
ExecutionContext context = (ExecutionContext) message.getHeaders().get("executionContext");
. . .
}
}Notes on JAR Layout
You don’t need the Spring Cloud Function Web at runtime in Azure, so you can exclude this before you create the JAR you deploy to Azure, but it won’t be used if you include it, so it doesn’t hurt to leave it in. A function application on Azure is an archive generated by the Maven plugin. The function lives in the JAR file generated by this project. The sample creates it as an executable jar, using the thin layout, so that Azure can find the handler classes. If you prefer you can just use a regular flat JAR file. The dependencies should not be included.
Build file setup
In order to run Spring Cloud Function applications on Microsoft Azure, you can leverage the Maven plugin offered by the cloud platform provider.
In order to use the adapter plugin for Maven, add the plugin dependency to your pom.xml
file:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-adapter-azure</artifactId>
</dependency>
</dependencies>Then, configure the plugin. You will need to provide Azure-specific configuration for your
application, specifying the resourceGroup, appName and other optional properties, and
add the package goal execution so that the function.json file required by Azure is
generated for you. Full plugin documentation can be found in the plugin repository.
<plugin>
<groupId>com.microsoft.azure</groupId>
<artifactId>azure-functions-maven-plugin</artifactId>
<configuration>
<resourceGroup>${functionResourceGroup}</resourceGroup>
<appName>${functionAppName}</appName>
</configuration>
<executions>
<execution>
<id>package-functions</id>
<goals>
<goal>package</goal>
</goals>
</execution>
</executions>
</plugin>You will also have to ensure that the files to be scanned by the plugin can be found in the Azure functions staging directory (see the plugin repository for more details on the staging directory and it’s default location).
You can find the entire sample pom.xml file for deploying Spring Cloud Function
applications to Microsoft Azure with Maven here.
| As of yet, only Maven plugin is available. Gradle plugin has not been created by the cloud platform provider. |
Build
./mvnw -U clean package
Running the sample
You can run the sample locally, just like the other Spring Cloud Function samples:
and curl -H "Content-Type: text/plain" localhost:8080/api/uppercase -d '{"value": "hello foobar"}'.
You will need the az CLI app (see https://docs.microsoft.com/en-us/azure/azure-functions/functions-create-first-java-maven for more detail). To deploy the function on Azure runtime:
$ az login $ mvn azure-functions:deploy
On another terminal try this: curl https://<azure-function-url-from-the-log>/api/uppercase -d '{"value": "hello foobar!"}'. Please ensure that you use the right URL for the function above. Alternatively you can test the function in the Azure Dashboard UI (click on the function name, go to the right hand side and click "Test" and to the bottom right, "Run").
The input type for the function in the Azure sample is a Foo with a single property called "value". So you need this to test it with something like below:
{
"value": "foobar"
}
The Azure sample app is written in the "non-functional" style (using @Bean). The functional style (with just Function or ApplicationContextInitializer) is much faster on startup in Azure than the traditional @Bean style, so if you don’t need @Beans (or @EnableAutoConfiguration) it’s a good choice. Warm starts are not affected.
:branch: master
|
Google Cloud Functions
The Google Cloud Functions adapter enables Spring Cloud Function apps to run on the Google Cloud Functions serverless platform. You can either run the function locally using the open source Google Functions Framework for Java or on GCP.
Project Dependencies
Start by adding the spring-cloud-function-adapter-gcp dependency to your project.
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-adapter-gcp</artifactId>
</dependency>
...
</dependencies>In addition, add the spring-boot-maven-plugin which will build the JAR of the function to deploy.
Notice that we also reference spring-cloud-function-adapter-gcp as a dependency of the spring-boot-maven-plugin. This is necessary because it modifies the plugin to package your function in the correct JAR format for deployment on Google Cloud Functions.
|
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<outputDirectory>target/deploy</outputDirectory>
</configuration>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-adapter-gcp</artifactId>
</dependency>
</dependencies>
</plugin>Finally, add the Maven plugin provided as part of the Google Functions Framework for Java.
This allows you to test your functions locally via mvn function:run.
The function target should always be set to org.springframework.cloud.function.adapter.gcp.GcfJarLauncher; this is an adapter class which acts as the entry point to your Spring Cloud Function from the Google Cloud Functions platform.
|
<plugin>
<groupId>com.google.cloud.functions</groupId>
<artifactId>function-maven-plugin</artifactId>
<version>0.9.1</version>
<configuration>
<functionTarget>org.springframework.cloud.function.adapter.gcp.GcfJarLauncher</functionTarget>
<port>8080</port>
</configuration>
</plugin>A full example of a working pom.xml can be found in the Spring Cloud Functions GCP sample.
HTTP Functions
Google Cloud Functions supports deploying HTTP Functions, which are functions that are invoked by HTTP request. The sections below describe instructions for deploying a Spring Cloud Function as an HTTP Function.
Getting Started
Let’s start with a simple Spring Cloud Function example:
@SpringBootApplication
public class CloudFunctionMain {
public static void main(String[] args) {
SpringApplication.run(CloudFunctionMain.class, args);
}
@Bean
public Function<String, String> uppercase() {
return value -> value.toUpperCase();
}
}
Specify your configuration main class in resources/META-INF/MANIFEST.MF.
Main-Class: com.example.CloudFunctionMainThen run the function locally.
This is provided by the Google Cloud Functions function-maven-plugin described in the project dependencies section.
mvn function:run
Invoke the HTTP function:
curl http://localhost:8080/ -d "hello"
Deploy to GCP
Start by packaging your application.
mvn package
If you added the custom spring-boot-maven-plugin plugin defined above, you should see the resulting JAR in target/deploy directory.
This JAR is correctly formatted for deployment to Google Cloud Functions.
Next, make sure that you have the Cloud SDK CLI installed.
From the project base directory run the following command to deploy.
gcloud functions deploy function-sample-gcp-http \ --entry-point org.springframework.cloud.function.adapter.gcp.GcfJarLauncher \ --runtime java11 \ --trigger-http \ --source target/deploy \ --memory 512MB
Invoke the HTTP function:
curl https://REGION-PROJECT_ID.cloudfunctions.net/function-sample-gcp-http -d "hello"
Background Functions
Google Cloud Functions also supports deploying Background Functions which are invoked indirectly in response to an event, such as a message on a Cloud Pub/Sub topic, a change in a Cloud Storage bucket, or a Firebase event.
The spring-cloud-function-adapter-gcp allows for functions to be deployed as background functions as well.
The sections below describe the process for writing a Cloud Pub/Sub topic background function. However, there are a number of different event types that can trigger a background function to execute which are not discussed here; these are described in the Background Function triggers documentation.
Getting Started
Let’s start with a simple Spring Cloud Function which will run as a GCF background function:
@SpringBootApplication
public class BackgroundFunctionMain {
public static void main(String[] args) {
SpringApplication.run(BackgroundFunctionMain.class, args);
}
@Bean
public Consumer<PubSubMessage> pubSubFunction() {
return message -> System.out.println("The Pub/Sub message data: " + message.getData());
}
}
In addition, create PubSubMessage class in the project with the below definition.
This class represents the Pub/Sub event structure which gets passed to your function on a Pub/Sub topic event.
public class PubSubMessage {
private String data;
private Map<String, String> attributes;
private String messageId;
private String publishTime;
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
public Map<String, String> getAttributes() {
return attributes;
}
public void setAttributes(Map<String, String> attributes) {
this.attributes = attributes;
}
public String getMessageId() {
return messageId;
}
public void setMessageId(String messageId) {
this.messageId = messageId;
}
public String getPublishTime() {
return publishTime;
}
public void setPublishTime(String publishTime) {
this.publishTime = publishTime;
}
}
Specify your configuration main class in resources/META-INF/MANIFEST.MF.
Main-Class: com.example.BackgroundFunctionMainThen run the function locally.
This is provided by the Google Cloud Functions function-maven-plugin described in the project dependencies section.
mvn function:run
Invoke the HTTP function:
curl localhost:8080 -H "Content-Type: application/json" -d '{"data":"hello"}'
Verify that the function was invoked by viewing the logs.
Deploy to GCP
In order to deploy your background function to GCP, first package your application.
mvn package
If you added the custom spring-boot-maven-plugin plugin defined above, you should see the resulting JAR in target/deploy directory.
This JAR is correctly formatted for deployment to Google Cloud Functions.
Next, make sure that you have the Cloud SDK CLI installed.
From the project base directory run the following command to deploy.
gcloud functions deploy function-sample-gcp-background \ --entry-point org.springframework.cloud.function.adapter.gcp.GcfJarLauncher \ --runtime java11 \ --trigger-topic my-functions-topic \ --source target/deploy \ --memory 512MB
Google Cloud Function will now invoke the function every time a message is published to the topic specified by --trigger-topic.
For a walkthrough on testing and verifying your background function, see the instructions for running the GCF Background Function sample.
Sample Functions
The project provides the following sample functions as reference:
-
The function-sample-gcp-http is an HTTP Function which you can test locally and try deploying.
-
The function-sample-gcp-background shows an example of a background function that is triggered by a message being published to a specified Pub/Sub topic.