Use the aggregator application to combine multiple messages into one, based on some correlation mechanism.
This processor is fully based on the Aggregator component from Spring Integration. So, please, consult there for use-cases and functionality.
If the aggregation and correlation logic is based on the default strategies, the correlationId, sequenceNumber and sequenceSize headers must be presented in the incoming message.
Aggregator Processor is fully based on the Spring Integration’s AggregatingMessageHandler and since correlation and aggregation logic don’t require particular types, the input payload can be anything able to be transferred over the network and Spring Cloud Stream Binder.
If payload is JSON, the JsonPropertyAccessor helps to build straightforward SpEL expressions for correlation, release and aggregation functions.
Returns all headers of the incoming messages that have no conflicts among the group. An absent header on one or more messages within the group is not considered a conflict.
The aggregator processor has the following options:
- aggregator.aggregation
- SpEL expression for aggregation strategy. Default is collection of payloads (Expression, default:
<none>) - aggregator.correlation
- SpEL expression for correlation key. Default to correlationId header (Expression, default:
<none>) - aggregator.group-timeout
- SpEL expression for timeout to expiring uncompleted groups (Expression, default:
<none>) - aggregator.message-store-entity
- Persistence message store entity: table prefix in RDBMS, collection name in MongoDb, etc (String, default:
<none>) - aggregator.message-store-type
- Message store type (String, default:
<none>) - aggregator.release
- SpEL expression for release strategy. Default is based on the sequenceSize header (Expression, default:
<none>) - spring.data.mongodb.authentication-database
- Authentication database name. (String, default:
<none>) - spring.data.mongodb.database
- Database name. (String, default:
<none>) - spring.data.mongodb.field-naming-strategy
- Fully qualified name of the FieldNamingStrategy to use. (Class<?>, default:
<none>) - spring.data.mongodb.grid-fs-database
- GridFS database name. (String, default:
<none>) - spring.data.mongodb.host
- Mongo server host. Cannot be set with URI. (String, default:
<none>) - spring.data.mongodb.password
- Login password of the mongo server. Cannot be set with URI. (Character[], default:
<none>) - spring.data.mongodb.port
- Mongo server port. Cannot be set with URI. (Integer, default:
<none>) - spring.data.mongodb.uri
- Mongo database URI. Cannot be set with host, port and credentials. (String, default:
mongodb://localhost/test) - spring.data.mongodb.username
- Login user of the mongo server. Cannot be set with URI. (String, default:
<none>) - spring.datasource.continue-on-error
- Whether to stop if an error occurs while initializing the database. (Boolean, default:
false) - spring.datasource.data
- Data (DML) script resource references. (List<String>, default:
<none>) - spring.datasource.data-password
- Password of the database to execute DML scripts (if different). (String, default:
<none>) - spring.datasource.data-username
- Username of the database to execute DML scripts (if different). (String, default:
<none>) - spring.datasource.driver-class-name
- Fully qualified name of the JDBC driver. Auto-detected based on the URL by default. (String, default:
<none>) - spring.datasource.generate-unique-name
- Whether to generate a random datasource name. (Boolean, default:
false) - spring.datasource.initialization-mode
- Initialize the datasource with available DDL and DML scripts. (DataSourceInitializationMode, default:
embedded, possible values:ALWAYS,EMBEDDED,NEVER) - spring.datasource.jndi-name
- JNDI location of the datasource. Class, url, username & password are ignored when
set. (String, default:
<none>) - spring.datasource.name
- Name of the datasource. Default to "testdb" when using an embedded database. (String, default:
<none>) - spring.datasource.password
- Login password of the database. (String, default:
<none>) - spring.datasource.platform
- Platform to use in the DDL or DML scripts (such as schema-${platform}.sql or
data-${platform}.sql). (String, default:
all) - spring.datasource.schema
- Schema (DDL) script resource references. (List<String>, default:
<none>) - spring.datasource.schema-password
- Password of the database to execute DDL scripts (if different). (String, default:
<none>) - spring.datasource.schema-username
- Username of the database to execute DDL scripts (if different). (String, default:
<none>) - spring.datasource.separator
- Statement separator in SQL initialization scripts. (String, default:
;) - spring.datasource.sql-script-encoding
- SQL scripts encoding. (Charset, default:
<none>) - spring.datasource.type
- Fully qualified name of the connection pool implementation to use. By default, it
is auto-detected from the classpath. (Class<DataSource>, default:
<none>) - spring.datasource.url
- JDBC URL of the database. (String, default:
<none>) - spring.datasource.username
- Login username of the database. (String, default:
<none>) - spring.mongodb.embedded.features
- Comma-separated list of features to enable. (Set<Feature>, default:
[sync_delay]) - spring.mongodb.embedded.version
- Version of Mongo to use. (String, default:
3.2.2) - spring.redis.database
- Database index used by the connection factory. (Integer, default:
0) - spring.redis.host
- Redis server host. (String, default:
localhost) - spring.redis.password
- Login password of the redis server. (String, default:
<none>) - spring.redis.port
- Redis server port. (Integer, default:
6379) - spring.redis.ssl
- Whether to enable SSL support. (Boolean, default:
false) - spring.redis.timeout
- Connection timeout. (Duration, default:
<none>) - spring.redis.url
- Connection URL. Overrides host, port, and password. User is ignored. Example:
redis://user:[email protected]:6379 (String, default:
<none>)
By default the aggregator processor uses:
- HeaderAttributeCorrelationStrategy(IntegrationMessageHeaderAccessor.CORRELATION_ID) - for correlation;
- SequenceSizeReleaseStrategy - for release;
- DefaultAggregatingMessageGroupProcessor - for aggregation;
- SimpleMessageStore - for messageStoreType.
The aggregator application can be configured for persistent MessageGroupStore implementations.
The configuration for target technology is fully based on the Spring Boot auto-configuration.
But default JDBC, MongoDb and Redis auto-configurations are excluded.
They are @Import ed basing on the aggregator.messageStoreType configuration property.
Consult Spring Boot Reference Manual for auto-configuration for particular technology you use for aggregator.
The JDBC JdbcMessageStore requires particular tables in the target data base.
You can find schema scripts for appropriate RDBMS vendors in the org.springframework.integration.jdbc package of the spring-integration-jdbc jar.
Those scripts can be used for automatic data base initialization via Spring Boot.
For example:
java -jar aggregator-rabbit-1.0.0.RELEASE.jar
--aggregator.message-store-type=jdbc
--spring.datasource.url=jdbc:h2:mem:test
--spring.datasource.schema=org/springframework/integration/jdbc/schema-h2.sql$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one of the folders and build it:
$ ./mvnw clean package
java -jar aggregator_processor.jar
--aggregator.message-store-type=jdbc
--spring.datasource.url=jdbc:h2:mem:test
--spring.datasource.schema=org/springframework/integration/jdbc/schema-h2.sql
java -jar aggregator_processor.jar
--spring.data.mongodb.port=0
--aggregator.correlation=T(Thread).currentThread().id
--aggregator.release="!#this.?[payload == 'bar'].empty"
--aggregator.aggregation="#this.?[payload == 'foo'].![payload]"
--aggregator.message-store-type=mongodb
--aggregator.message-store-entity=aggregatorTestThis project adheres to the Contributor Covenant code of conduct. By participating, you are expected to uphold this code. Please report unacceptable behavior to [email protected].
A Processor module that returns messages that is passed by connecting just the input and output channels.
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
Use the filter module in a stream to determine whether a Message should be passed to the output channel.
The filter processor has the following options:
- filter.expression
- A SpEL expression to be evaluated against each message, to decide whether or not to accept it. (Expression, default:
true)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
A Processor application that retains or discards messages according to a predicate, expressed as a Groovy script.
The groovy-filter processor has the following options:
- groovy-filter.script
- The resource location of the groovy script (Resource, default:
<none>) - groovy-filter.variables
- Variable bindings as a new line delimited string of name-value pairs, e.g. 'foo=bar\n baz=car'. (Properties, default:
<none>) - groovy-filter.variables-location
- The location of a properties file containing custom script variable bindings. (Resource, default:
<none>)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
A Processor module that transforms messages using a Groovy script.
The groovy-transform processor has the following options:
- groovy-transformer.script
- Reference to a script used to process messages. (Resource, default:
<none>) - groovy-transformer.variables
- Variable bindings as a new line delimited string of name-value pairs, e.g. 'foo=bar\n baz=car'. (Properties, default:
<none>) - groovy-transformer.variables-location
- The location of a properties file containing custom script variable bindings. (Resource, default:
<none>)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
This processor uses gRPC to process Messages via a remote process written in any language that supports gRPC. This pattern, allows the Java app to handle the stream processing while the gRPC service handles the business logic. The service must implement the grpc service using link:. ./grpc-app-protos/src/main/proto/processor.proto[this protobuf schema].
![[Note]](images/note.png) | Note |
|---|---|
The gRPC client stub is blocking by default. Asynchronous and streaming stubs are provided. The Asynchronous stub will perform better if the server is multi-threaded however message ordering will not be guaranteed. If the server supports bidirectional streaming, use the streaming stub. |
| Note |
|---|---|
A |
Headers are available to the sidecar application via the process
schema if grpc.include-headers is true. The header value contains one or more string values to support multiple
values, e.g., the HTTP Accepts header.
The payload is a byte array as defined by the schema.
In most cases the return message should simply contain the original headers provided. The sidecar application may modify or add headers however it is recommended to only add headers if necessary.
It is expected that the payload will normally be a string or byte array. However common primitive types are supported as defined by the schema.
The grpc processor has the following options:
- grpc.host
- The gRPC host name. (String, default:
<none>) - grpc.idle-timeout
- The idle timeout in seconds. (Long, default:
0) - grpc.include-headers
- Flag to include headers in Messages to the remote process. (Boolean, default:
false) - grpc.max-message-size
- The maximum message size (bytes). (Integer, default:
0) - grpc.plain-text
- Flag to send messages in plain text. SSL configuration required otherwise. (Boolean, default:
true) - grpc.port
- The gRPC server port. (Integer, default:
0) - grpc.stub
- RPC communications style (default 'blocking'). (Stub, default:
<none>, possible values:async,blocking,streaming,riff)
Use the header-enricher app to add message headers.
The headers are provided in the form of new line delimited key value pairs, where the keys are the header names and the values are SpEL expressions.
For example --headers='foo=payload.someProperty \n bar=payload.otherProperty'
The header-enricher processor has the following options:
- header.enricher.headers
- \n separated properties representing headers in which values are SpEL expressions, e.g foo='bar' \n baz=payload.baz (Properties, default:
<none>) - header.enricher.overwrite
- set to true to overwrite any existing message headers (Boolean, default:
false)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
java -jar header-enricher-processor.jar --headers='foo=payload.someProperty \n bar=payload.otherProperty'
This project adheres to the Contributor Covenant code of conduct. By participating, you are expected to uphold this code. Please report unacceptable behavior to [email protected].
A processor app that makes requests to an HTTP resource and emits the response body as a message payload. This processor can be combined, e.g., with a time source app to periodically poll results from a HTTP resource.
Any Required HTTP headers must be explicitly set via the headers-expression property. See examples below.
Header values may also be used to construct the request body when referenced in the body-expression property.
You can set the http-method-expression property to derive the HTTP method from the inbound Message, or http-method to set it statically (defaults to GET method).
The Message payload may be any Java type.
Generally, standard Java types such as String(e.g., JSON, XML) or byte array payloads are recommended.
A Map should work without too much effort.
By default, the payload will become HTTP request body (if needed).
You may also set the body-expression property to construct a value derived from the Message, or body to use a static (literal) value.
Internally, the processor uses RestTemplate.exchange(…).
The RestTemplate supports Jackson JSON serialization to support any request and response types if necessary.
The expected-response-type property, String.class by default, may be set to any class in your application class path.
(Note user defined payload types will require adding required dependencies to your pom file)
The raw output object is ResponseEntity<?> any of its fields (e.g., body, headers) or accessor methods (statusCode) may be referenced as part of the reply-expression.
By default the outbound Message payload is the response body.
The httpclient processor has the following options:
- httpclient.body
- The (static) request body; if neither this nor bodyExpression is provided, the payload will be used. (Object, default:
<none>) - httpclient.body-expression
- A SpEL expression to derive the request body from the incoming message. (Expression, default:
<none>) - httpclient.expected-response-type
- The type used to interpret the response. (Class<?>, default:
<none>) - httpclient.headers-expression
- A SpEL expression used to derive the http headers map to use. (Expression, default:
<none>) - httpclient.http-method
- The kind of http method to use. (HttpMethod, default:
<none>, possible values:GET,HEAD,POST,PUT,PATCH,DELETE,OPTIONS,TRACE) - httpclient.http-method-expression
- A SpEL expression to derive the request method from the incoming message. (Expression, default:
<none>) - httpclient.reply-expression
- A SpEL expression used to compute the final result, applied against the whole http response. (Expression, default:
body) - httpclient.url
- The URL to issue an http request to, as a static value. (String, default:
<none>) - httpclient.url-expression
- A SpEL expression against incoming message to determine the URL to use. (Expression, default:
<none>)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
$ java -jar httpclient-processor.jar --httpclient.url=http://someurl --httpclient.http-method=POST --httpclient.headers-expression="{'Content-Type':'application/json'}" $ java -jar httpclient-processor.jar --httpclient.url=http://someurl --httpclient.reply-expression="statusCode.name()"
A processor that evaluates a machine learning model stored in PMML format.
The pmml processor has the following options:
- pmml.inputs
- How to compute model active fields from input message properties as modelField->SpEL. (Map<String, Expression>, default:
<none>) - pmml.model-location
- The location of the PMML model file. (Resource, default:
<none>) - pmml.model-name
- If the model file contains multiple models, the name of the one to use. (String, default:
<none>) - pmml.model-name-expression
- If the model file contains multiple models, the name of the one to use, as a SpEL expression. (Expression, default:
<none>) - pmml.outputs
- How to emit evaluation results in the output message as msgProperty->SpEL. (Map<String, Expression>, default:
<none>)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one of the folders and build it:
$ ./mvnw clean package
Spring Cloud Stream App Starters for integrating with python
This application invokes a REST service, similar to the standard httpclient processor. In fact, this application embeds the httpclient processor. As a convenience for Python developers, this allows you to provide a Jython wrapper script that may execute a function before and after REST call in order to perform any necessary data transformation. If you don’t require any custom transformations, just use the httpclient processor.
The diagram shows input and output adapters as conceptual components. These are actually implemented as functions defined in a single script that must conform to a simple convention:
def input(): return "Pre" + payload; def output(): return payload + "Post"; result = locals()[channel]()
The function names input and output map to the conventional channel names used by Spring Cloud Stream processors.
The last line is a bit of Python reflection magic to invoke a function by its name, given by the bound variable
channel. Implemented with Spring Integration Scripting, headers and payload are always bound to the Message
headers and payload respectively. The payload on the input side is the object you use to build the REST request.
The output side transforms the response. If you don’t need any additional processing on one side, implement the
function with pass as the body:
def output(): pass
| Note |
|---|---|
The last line in the script must be an assignment statement. The variable name doesn’t matter. This is required to bind the return value correctly. |
| Note |
|---|---|
The script is evaluated for every message. This tends to create a a lot of classes for each execution which puts
stress on the JRE |

Headers may be set by the Jython wrapper script if the output() script function returns a Message.
Whatever the `output()`wrapper script function returns.
| Note |
|---|---|
The wrapper script is intended to perform some required transformations prior to sending an HTTP request and/or after
the response is received. The return value of the input adapter will be the inbound payload of the
httpclient processor and shoud conform to its requirements. Likewise
the HTTP |
The python-http processor has the following options:
- git.basedir
- The base directory where the repository should be cloned. If not specified, a temporary directory will be
created. (File, default:
<none>) - git.clone-on-start
- Flag to indicate that the repository should be cloned on startup (not on demand).
Generally leads to slower startup but faster first query. (Boolean, default:
true) - git.label
- The label or branch to clone. (String, default:
master) - git.passphrase
- The passphrase for the remote repository. (String, default:
<none>) - git.password
- The password for the remote repository. (String, default:
<none>) - git.timeout
- Timeout (in seconds) for obtaining HTTP or SSH connection (if applicable). Default
5 seconds. (Integer, default:
5) - git.uri
- The URI of the remote repository. (String, default:
<none>) - git.username
- The username for the remote repository. (String, default:
<none>) - httpclient.body
- The (static) request body; if neither this nor bodyExpression is provided, the payload will be used. (Object, default:
<none>) - httpclient.body-expression
- A SpEL expression to derive the request body from the incoming message. (Expression, default:
<none>) - httpclient.expected-response-type
- The type used to interpret the response. (Class<?>, default:
<none>) - httpclient.headers-expression
- A SpEL expression used to derive the http headers map to use. (Expression, default:
<none>) - httpclient.http-method
- The kind of http method to use. (HttpMethod, default:
<none>, possible values:GET,HEAD,POST,PUT,PATCH,DELETE,OPTIONS,TRACE) - httpclient.reply-expression
- A SpEL expression used to compute the final result, applied against the whole http response. (Expression, default:
body) - httpclient.url
- The URL to issue an http request to, as a static value. (String, default:
<none>) - httpclient.url-expression
- A SpEL expression against incoming message to determine the URL to use. (Expression, default:
<none>) - wrapper.content-type
- Sets the Content type header for the outgoing Message. (MediaType, default:
<none>) - wrapper.delimiter
- The variable delimiter. (Delimiter, default:
<none>, possible values:COMMA,SPACE,TAB,NEWLINE) - wrapper.script
- The Python script file name. (String, default:
<none>) - wrapper.variables
- Variable bindings as a delimited string of name-value pairs, e.g. 'foo=bar,baz=car'. (String, default:
<none>)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
See httpclient processor for more examples on
httpclient properties.
$java -jar python-http-processor.jar --wrapper.script=/local/directory/build-json.py --httpclient.url=http://someurl --httpclient.http-method=POST --httpclient.headers-expression="{'Content-Type':'application/json'}" $java -jar python-http-processor.jar --git.uri=https://github.com/some-repo --wrapper.script=some-script.py --wrapper .variables=foo=0.45,bar=0.55 --httpclient.url=http://someurl
This application executes a Jython script that binds payload and headers variables to the Message payload
and headers respectively. In addition you may provide a jython.variables property containing a (comma delimited by
default) delimited string, e.g., var1=val1,var2=val2,….
This processor uses a JSR-223 compliant embedded ScriptEngine provided by www.jython.org/.
| Note |
|---|---|
The last line in the script must be an assignment statement. The variable name doesn’t matter. This is required to bind the return value correctly. |
| Note |
|---|---|
The script is evaluated for every message which may limit your performance with high message loads. This also tends
to create a a lot of classes for each execution which puts stress on the JRE |

The jython processor has the following options:
- git.basedir
- The base directory where the repository should be cloned. If not specified, a temporary directory will be
created. (File, default:
<none>) - git.clone-on-start
- Flag to indicate that the repository should be cloned on startup (not on demand).
Generally leads to slower startup but faster first query. (Boolean, default:
true) - git.label
- The label or branch to clone. (String, default:
master) - git.passphrase
- The passphrase for the remote repository. (String, default:
<none>) - git.password
- The password for the remote repository. (String, default:
<none>) - git.timeout
- Timeout (in seconds) for obtaining HTTP or SSH connection (if applicable). Default
5 seconds. (Integer, default:
5) - git.uri
- The URI of the remote repository. (String, default:
<none>) - git.username
- The username for the remote repository. (String, default:
<none>) - jython.content-type
- Sets the Content type header for the outgoing Message. (MediaType, default:
<none>) - jython.delimiter
- The variable delimiter. (Delimiter, default:
<none>, possible values:COMMA,SPACE,TAB,NEWLINE) - jython.script
- The Python script file name. (String, default:
<none>) - jython.variables
- Variable bindings as a delimited string of name-value pairs, e.g. 'foo=bar,baz=car'. (String, default:
<none>)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
A Spring Cloud Stream module that transforms messages using a script. The script body is supplied directly as a property value. The language of the script can be specified (groovy/javascript/ruby/python).
The scriptable-transform processor has the following options:
- scriptable-transformer.language
- Language of the text in the script property. Supported: groovy, javascript, ruby, python. (String, default:
<none>) - scriptable-transformer.script
- Text of the script. (String, default:
<none>) - scriptable-transformer.variables
- Variable bindings as a new line delimited string of name-value pairs, e.g. 'foo=bar\n baz=car'. (Properties, default:
<none>) - scriptable-transformer.variables-location
- The location of a properties file containing custom script variable bindings. (Resource, default:
<none>)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
The splitter app builds upon the concept of the same name in Spring Integration and allows the splitting of a single message into several distinct messages.
- splitter.apply-sequence
- Add correlation/sequence information in headers to facilitate later
aggregation. (Boolean, default:
true) - splitter.charset
- The charset to use when converting bytes in text-based files
to String. (String, default:
<none>) - splitter.delimiters
- When expression is null, delimiters to use when tokenizing
{@link String} payloads. (String, default:
<none>) - splitter.expression
- A SpEL expression for splitting payloads. (Expression, default:
<none>) - splitter.file-markers
- Set to true or false to use a {@code FileSplitter} (to split
text-based files by line) that includes
(or not) beginning/end of file markers. (Boolean, default:
<none>) - splitter.markers-json
- When 'fileMarkers == true', specify if they should be produced
as FileSplitter.FileMarker objects or JSON. (Boolean, default:
true)
When no expression, fileMarkers, or charset is provided, a DefaultMessageSplitter is configured with (optional) delimiters.
When fileMarkers or charset is provided, a FileSplitter is configured (you must provide either a fileMarkers
or charset to split files, which must be text-based - they are split into lines).
Otherwise, an ExpressionEvaluatingMessageSplitter is configured.
When splitting File payloads, the sequenceSize header is zero because the size cannot be determined at the beginning.
![[Caution]](images/caution.png) | Caution |
|---|---|
Ambiguous properties are not allowed. |
As part of the SpEL expression you can make use of the pre-registered JSON Path function. The syntax is
#jsonPath(payload, '<json path expression>').
For example, consider the following JSON:
{ "store": { "book": [ { "category": "reference", "author": "Nigel Rees", "title": "Sayings of the Century", "price": 8.95 }, { "category": "fiction", "author": "Evelyn Waugh", "title": "Sword of Honour", "price": 12.99 }, { "category": "fiction", "author": "Herman Melville", "title": "Moby Dick", "isbn": "0-553-21311-3", "price": 8.99 }, { "category": "fiction", "author": "J. R. R. Tolkien", "title": "The Lord of the Rings", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "color": "red", "price": 19.95 } }}
and an expression #jsonPath(payload, '$.store.book'); the result will be 4 messages, each with a Map payload
containing the properties of a single book.
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one of the folders and build it:
$ ./mvnw clean package
The tcp-client processor has the following options:
- tcp.buffer-size
- The buffer size used when decoding messages; larger messages will be rejected. (Integer, default:
2048) - tcp.charset
- The charset used when converting from bytes to String. (String, default:
UTF-8) - tcp.decoder
- The decoder to use when receiving messages. (Encoding, default:
<none>, possible values:CRLF,LF,NULL,STXETX,RAW,L1,L2,L4) - tcp.encoder
- The encoder to use when sending messages. (Encoding, default:
<none>, possible values:CRLF,LF,NULL,STXETX,RAW,L1,L2,L4) - tcp.host
- The host to which this sink will connect. (String, default:
localhost) - tcp.nio
- Whether or not to use NIO. (Boolean, default:
false) - tcp.port
- The port on which to listen; 0 for the OS to choose a port. (Integer, default:
1234) - tcp.retry-interval
- Retry interval (in milliseconds) to check the connection and reconnect. (Long, default:
60000) - tcp.reverse-lookup
- Perform a reverse DNS lookup on the remote IP Address; if false,
just the IP address is included in the message headers. (Boolean, default:
false) - tcp.socket-timeout
- The timeout (ms) before closing the socket when no data is received. (Integer, default:
120000) - tcp.use-direct-buffers
- Whether or not to use direct buffers. (Boolean, default:
false)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
Use the transform app in a stream to convert a Message’s content or structure.
The transform processor is used by passing a SpEL expression. The expression should return the modified message or payload.
As part of the SpEL expression you can make use of the pre-registered JSON Path function. The syntax is #jsonPath(payload,'<json path expression>')
The transform processor has the following options:
- transformer.expression
- <documentation missing> (Expression, default:
payload)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one one of the folders and build it:
$ ./mvnw clean package
A processor that evaluates a machine learning model stored in TensorFlow Protobuf format.
Following snippet shows how to export a TensorFlow model into ProtocolBuffer binary format as required by the Processor.
from tensorflow.python.framework.graph_util import convert_variables_to_constants ... SAVE_DIR = os.path.abspath(os.path.curdir) minimal_graph = convert_variables_to_constants(sess, sess.graph_def, ['<model output>']) tf.train.write_graph(minimal_graph, SAVE_DIR, 'my_graph.proto', as_text=False) tf.train.write_graph(minimal_graph, SAVE_DIR, 'my.txt', as_text=True)
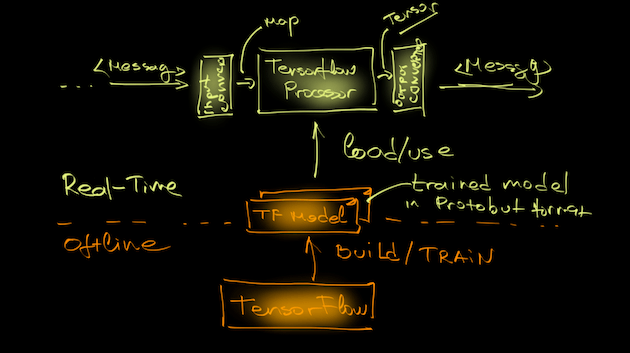
The --tensorflow.model property configures the Processor with the location of the serialized Tensorflow model.
The TensorflowInputConverter converts the input data into the format, specific for the given model.
The TensorflowOutputConverter converts the computed Tensors result into a pipeline Message.
The --tensorflow.modelFetch property defines the list of TensorFlow graph outputs to fetch the output Tensors from.
The --tensorflow.mode property defines whether the computed results are passed in the message payload or in the message header.
The TensorFlow Processor uses a TensorflowInputConverter to convert the input data into data format compliant with the
TensorFlow Model used. The input converter converts the input Messages into key/value Map, where
the Key corresponds to a model input placeholder and the content is org.tensorflow.DataType compliant value.
The default converter implementation expects either Map payload or flat json message that can be converted into a Map.
The TensorflowInputConverter can be extended and customized.
See TwitterSentimentTensorflowInputConverter.java for example.
Processor’s output uses TensorflowOutputConverter to convert the computed Tensor result into a serializable
message. The default implementation uses Tuple triple.
Custom TensorflowOutputConverter can provide more convenient data representations.
See TwitterSentimentTensorflowOutputConverter.java.
The tensorflow processor has the following options:
- tensorflow.expression
- How to obtain the input data from the input message. If empty it defaults to the input message payload. The payload.myInTupleName expression treats the input payload as a Tuple, and myInTupleName stands for a Tuple key. The headers[myHeaderName] expression to get input data from message's header using myHeaderName as a key. (Expression, default:
<none>) - tensorflow.mode
- Defines how to store the output data and if the input payload is passed through or discarded. Payload (Default) stores the output data in the outbound message payload. The input payload is discarded. Header stores the output data in outputName message's header. The the input payload is passed through. Tuple stores the output data in an Tuple payload, using the outputName key. The input payload is passed through in the same Tuple using the 'original.input.data'. If the input payload is already a Tuple that contains a 'original.input.data' key, then copy the input Tuple into the new Tuple to be returned. (OutputMode, default:
<none>, possible values:payload,tuple,header) - tensorflow.model
- The location of the pre-trained TensorFlow model file. The file, http and classpath schemas are supported. For archive locations takes the first file with '.pb' extension. Use the URI fragment parameter to specify an exact model name (e.g. https://foo/bar/model.tar.gz#frozen_inference_graph.pb) (Resource, default:
<none>) - tensorflow.model-fetch
- The TensorFlow graph model outputs. Comma separate list of TensorFlow operation names to fetch the output Tensors from. (List<String>, default:
<none>) - tensorflow.output-name
- The output data key used in the Header or Tuple modes. (String, default:
result)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one of the folders and build it:
$ ./mvnw clean package
A processor that evaluates a machine learning model stored in TensorFlow Protobuf format. It operationalizes the github.com/danielegrattarola/twitter-sentiment-cnn
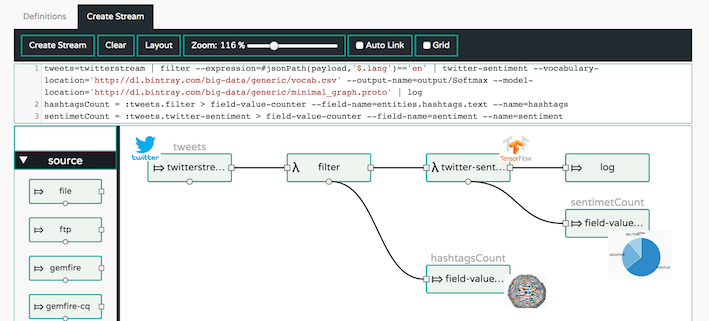
Real-time Twitter Sentiment Analytics with TensorFlow and Spring Cloud Dataflow
Decodes the evaluated result into POSITIVE, NEGATIVE and NEUTRAL values. Then creates and returns a simple JSON message with this structure:
N/A
Processor’s output uses TensorflowOutputConverter to convert the computed Tensor result into a serializable
message. The default implementation uses Tuple triple.
Custom TensorflowOutputConverter can provide more convenient data representations.
See TwitterSentimentTensorflowOutputConverter.java.
The twitter-sentiment processor has the following options:
- tensorflow.expression
- How to obtain the input data from the input message. If empty it defaults to the input message payload. The payload.myInTupleName expression treats the input payload as a Tuple, and myInTupleName stands for a Tuple key. The headers[myHeaderName] expression to get input data from message's header using myHeaderName as a key. (Expression, default:
<none>) - tensorflow.mode
- Defines how to store the output data and if the input payload is passed through or discarded. Payload (Default) stores the output data in the outbound message payload. The input payload is discarded. Header stores the output data in outputName message's header. The the input payload is passed through. Tuple stores the output data in an Tuple payload, using the outputName key. The input payload is passed through in the same Tuple using the 'original.input.data'. If the input payload is already a Tuple that contains a 'original.input.data' key, then copy the input Tuple into the new Tuple to be returned. (OutputMode, default:
<none>, possible values:payload,tuple,header) - tensorflow.model
- The location of the pre-trained TensorFlow model file. The file, http and classpath schemas are supported. For archive locations takes the first file with '.pb' extension. Use the URI fragment parameter to specify an exact model name (e.g. https://foo/bar/model.tar.gz#frozen_inference_graph.pb) (Resource, default:
<none>) - tensorflow.model-fetch
- The TensorFlow graph model outputs. Comma separate list of TensorFlow operation names to fetch the output Tensors from. (List<String>, default:
<none>) - tensorflow.output-name
- The output data key used in the Header or Tuple modes. (String, default:
result) - tensorflow.twitter.vocabulary
- The location of the word vocabulary file, used for training the model (Resource, default:
<none>)
$ ./mvnw clean install -PgenerateApps $ cd apps
You can find the corresponding binder based projects here. You can then cd into one of the folders and build it:
$ ./mvnw clean package
java -jar twitter-sentiment-processor.jar --tensorflow.twitter.vocabulary= --tensorflow.model= \
--tensorflow.modelFetch= --tensorflow.mode="And here is a sample pipeline that computes sentiments for json tweets coming from the twitterstream source and
using the pre-build minimal_graph.proto and vocab.csv:
tweets=twitterstream --access-token-secret=xxx --access-token=xxx --consumer-secret=xxx --consumer-key=xxx \ | filter --expression=#jsonPath(payload,'$.lang')=='en' \ | twitter-sentimet --vocabulary='http://dl.bintray.com/big-data/generic/vocab.csv' \ --output-name=output/Softmax --model='http://dl.bintray.com/big-data/generic/minimal_graph.proto' \ --model-fetch=output/Softmax \ | log
A processor that uses an Inception model to classify in real-time images into different categories (e.g. labels).
Model implements a deep Convolutional Neural Network that can achieve reasonable performance on hard visual recognition tasks - matching or exceeding human performance in some domains like image recognition.
The input of the model is an image as binary array.
The output is a Tuple (or JSON) message in this format:
{ "labels" : [ {"giant panda":0.98649305} ] }
Result contains the name of the recognized category (e.g. label) along with the confidence (e.g. confidence) that the image represents this category.
If the response-seize is set to value higher then 1, then the result will include the top response-seize probable labels. For example response-size=3 would return:
{ "labels": [ {"giant panda":0.98649305}, {"badger":0.010562794}, {"ice bear":0.001130851} ] }
The image-recognition processor has the following options:
- tensorflow.expression
- How to obtain the input data from the input message. If empty it defaults to the input message payload. The payload.myInTupleName expression treats the input payload as a Tuple, and myInTupleName stands for a Tuple key. The headers[myHeaderName] expression to get input data from message's header using myHeaderName as a key. (Expression, default:
<none>) - tensorflow.image.recognition.draw-labels
- When set to true it augment the input image with the predicted labels (Boolean, default:
true) - tensorflow.image.recognition.labels
- The text file containing the category names (e.g. labels) of all categories that this model is trained to recognize. Every category is on a separate line. (Resource, default:
<none>) - tensorflow.image.recognition.response-size
- Number of top K alternatives to add to the result. Only used when the responseSize > 0. (Integer, default:
1) - tensorflow.mode
- Defines how to store the output data and if the input payload is passed through or discarded. Payload (Default) stores the output data in the outbound message payload. The input payload is discarded. Header stores the output data in outputName message's header. The the input payload is passed through. Tuple stores the output data in an Tuple payload, using the outputName key. The input payload is passed through in the same Tuple using the 'original.input.data'. If the input payload is already a Tuple that contains a 'original.input.data' key, then copy the input Tuple into the new Tuple to be returned. (OutputMode, default:
<none>, possible values:payload,tuple,header) - tensorflow.model
- The location of the pre-trained TensorFlow model file. The file, http and classpath schemas are supported. For archive locations takes the first file with '.pb' extension. Use the URI fragment parameter to specify an exact model name (e.g. https://foo/bar/model.tar.gz#frozen_inference_graph.pb) (Resource, default:
<none>) - tensorflow.model-fetch
- The TensorFlow graph model outputs. Comma separate list of TensorFlow operation names to fetch the output Tensors from. (List<String>, default:
<none>) - tensorflow.output-name
- The output data key used in the Header or Tuple modes. (String, default:
result)
The new Object Detection processor provides out-of-the-box support for the TensorFlow Object Detection API. It allows for real-time localization and identification of multiple objects in a single image or image stream. The Object Detection processor uses one of the pre-trained object detection models and corresponding object labels.
If the pre-trained model is not set explicitly set then following defaults are used:
tensorflow.modelFetch:detection_scores,detection_classes,detection_boxes,num_detectionstensorflow.model:dl.bintray.com/big-data/generic/faster_rcnn_resnet101_coco_2018_01_28_frozen_inference_graph.pbtensorflow.object.detection.labels:dl.bintray.com/big-data/generic/mscoco_label_map.pbtxt
The following diagram illustrates a Spring Cloud Data Flow streaming pipeline that predicts object types from the images in real-time.
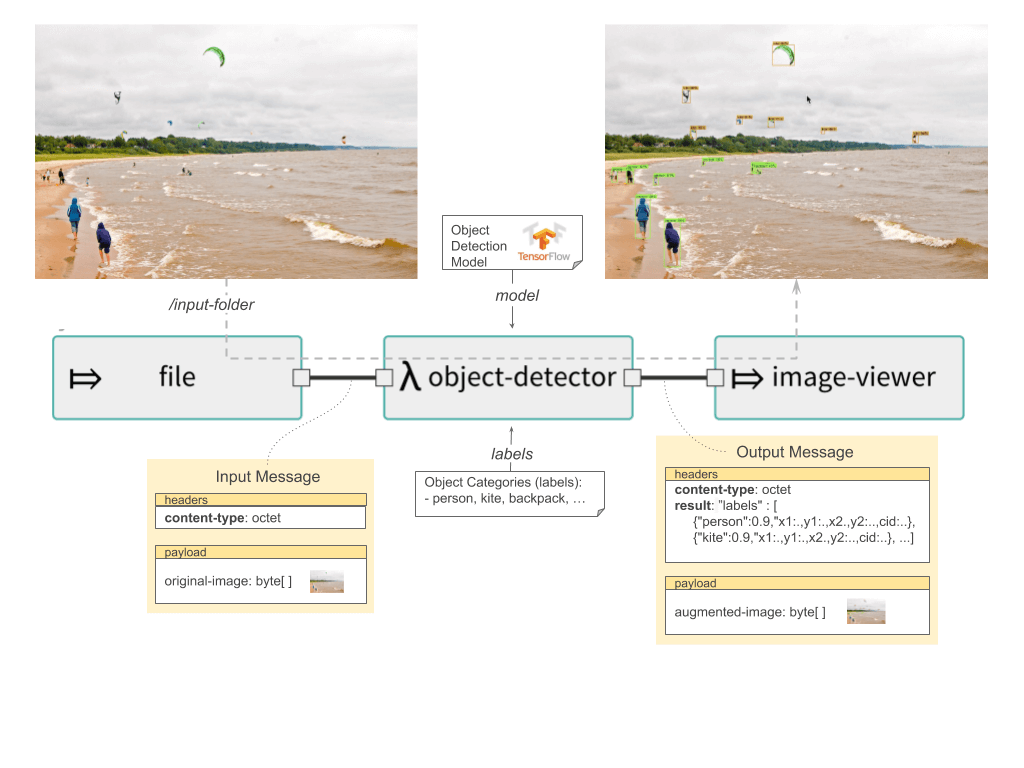
Processor’s input is an image byte array and the output is a Tuple (or JSON) message in this format:
{ "labels" : [ {"name":"person", "confidence":0.9996774,"x1":0.0,"y1":0.3940161,"x2":0.9465165,"y2":0.5592592,"cid":1}, {"name":"person", "confidence":0.9996604,"x1":0.047891676,"y1":0.03169123,"x2":0.941098,"y2":0.2085562,"cid":1}, {"name":"backpack", "confidence":0.96534747,"x1":0.15588468,"y1":0.85957795,"x2":0.5091308,"y2":0.9908878,"cid":23}, {"name":"backpack", "confidence":0.963343,"x1":0.1273736,"y1":0.57658505,"x2":0.47765,"y2":0.6986431,"cid":23} ] }
The output format is:
- object-name:confidence - human readable name of the detected object (e.g. label) with its confidence as a float between [0-1]
- x1, y1, x2, y2 - Response also provides the bounding box of the detected objects represented as (x1, y1, x2, y2). The coordinates are relative to the size of the image size.
- cid - Classification identifier as defined in the provided labels configuration file.
The object-detection processor has the following options:
- tensorflow.expression
- How to obtain the input data from the input message. If empty it defaults to the input message payload. The payload.myInTupleName expression treats the input payload as a Tuple, and myInTupleName stands for a Tuple key. The headers[myHeaderName] expression to get input data from message's header using myHeaderName as a key. (Expression, default:
<none>) - tensorflow.mode
- Defines how to store the output data and if the input payload is passed through or discarded. Payload (Default) stores the output data in the outbound message payload. The input payload is discarded. Header stores the output data in outputName message's header. The the input payload is passed through. Tuple stores the output data in an Tuple payload, using the outputName key. The input payload is passed through in the same Tuple using the 'original.input.data'. If the input payload is already a Tuple that contains a 'original.input.data' key, then copy the input Tuple into the new Tuple to be returned. (OutputMode, default:
<none>, possible values:payload,tuple,header) - tensorflow.model
- The location of the pre-trained TensorFlow model file. The file, http and classpath schemas are supported. For archive locations takes the first file with '.pb' extension. Use the URI fragment parameter to specify an exact model name (e.g. https://foo/bar/model.tar.gz#frozen_inference_graph.pb) (Resource, default:
<none>) - tensorflow.model-fetch
- The TensorFlow graph model outputs. Comma separate list of TensorFlow operation names to fetch the output Tensors from. (List<String>, default:
<none>) - tensorflow.object.detection.color-agnostic
- If disabled (default) the bounding box colors are selected as a function of the object class id. If enabled all bounding boxes are visualized with a single color. (Boolean, default:
false) - tensorflow.object.detection.confidence
- Probability threshold. Only objects detected with probability higher then the confidence threshold are accepted. Value is between 0 and 1. (Float, default:
0.4) - tensorflow.object.detection.draw-bounding-box
- When set to true, the output image will be annotated with the detected object boxes (Boolean, default:
true) - tensorflow.object.detection.draw-mask
- For models with mask support enable drawing the mask of the detected objects (Boolean, default:
true) - tensorflow.object.detection.labels
- The text file containing the category names (e.g. labels) of all categories that this model is trained to recognize. Every category is on a separate line. (Resource, default:
<none>) - tensorflow.output-name
- The output data key used in the Header or Tuple modes. (String, default:
result)