For using the Apache Kafka binder, you just need to add it to your Spring Cloud Stream application, using the following Maven coordinates:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-stream-binder-kafka</artifactId> </dependency>
Alternatively, you can also use the Spring Cloud Stream Kafka Starter.
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-kafka</artifactId> </dependency>
A simplified diagram of how the Apache Kafka binder operates can be seen below.
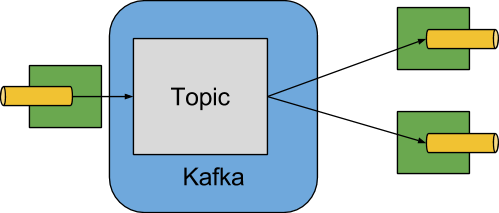
The Apache Kafka Binder implementation maps each destination to an Apache Kafka topic. The consumer group maps directly to the same Apache Kafka concept. Partitioning also maps directly to Apache Kafka partitions as well.
This section contains the configuration options used by the Apache Kafka binder.
For common configuration options and properties pertaining to binder, refer to the core documentation.
- spring.cloud.stream.kafka.binder.brokers
A list of brokers to which the Kafka binder will connect.
Default:
localhost.- spring.cloud.stream.kafka.binder.defaultBrokerPort
brokersallows hosts specified with or without port information (e.g.,host1,host2:port2). This sets the default port when no port is configured in the broker list.Default:
9092.- spring.cloud.stream.kafka.binder.zkNodes
A list of ZooKeeper nodes to which the Kafka binder can connect.
Default:
localhost.- spring.cloud.stream.kafka.binder.defaultZkPort
zkNodesallows hosts specified with or without port information (e.g.,host1,host2:port2). This sets the default port when no port is configured in the node list.Default:
2181.- spring.cloud.stream.kafka.binder.configuration
Key/Value map of client properties (both producers and consumer) passed to all clients created by the binder. Due to the fact that these properties will be used by both producers and consumers, usage should be restricted to common properties, especially security settings.
Default: Empty map.
- spring.cloud.stream.kafka.binder.headers
The list of custom headers that will be transported by the binder.
Default: empty.
- spring.cloud.stream.kafka.binder.healthTimeout
The time to wait to get partition information in seconds; default 60. Health will report as down if this timer expires.
Default: 10.
- spring.cloud.stream.kafka.binder.offsetUpdateTimeWindow
The frequency, in milliseconds, with which offsets are saved. Ignored if
0.Default:
10000.- spring.cloud.stream.kafka.binder.offsetUpdateCount
The frequency, in number of updates, which which consumed offsets are persisted. Ignored if
0. Mutually exclusive withoffsetUpdateTimeWindow.Default:
0.- spring.cloud.stream.kafka.binder.requiredAcks
The number of required acks on the broker.
Default:
1.- spring.cloud.stream.kafka.binder.minPartitionCount
Effective only if
autoCreateTopicsorautoAddPartitionsis set. The global minimum number of partitions that the binder will configure on topics on which it produces/consumes data. It can be superseded by thepartitionCountsetting of the producer or by the value ofinstanceCount*concurrencysettings of the producer (if either is larger).Default:
1.- spring.cloud.stream.kafka.binder.replicationFactor
The replication factor of auto-created topics if
autoCreateTopicsis active.Default:
1.- spring.cloud.stream.kafka.binder.autoCreateTopics
If set to
true, the binder will create new topics automatically. If set tofalse, the binder will rely on the topics being already configured. In the latter case, if the topics do not exist, the binder will fail to start. Of note, this setting is independent of theauto.topic.create.enablesetting of the broker and it does not influence it: if the server is set to auto-create topics, they may be created as part of the metadata retrieval request, with default broker settings.Default:
true.- spring.cloud.stream.kafka.binder.autoAddPartitions
If set to
true, the binder will create add new partitions if required. If set tofalse, the binder will rely on the partition size of the topic being already configured. If the partition count of the target topic is smaller than the expected value, the binder will fail to start.Default:
false.- spring.cloud.stream.kafka.binder.socketBufferSize
Size (in bytes) of the socket buffer to be used by the Kafka consumers.
Default:
2097152.- spring.cloud.stream.kafka.binder.transaction.transactionIdPrefix
Enable transactions in the binder; see
transaction.idin the Kafka documentation and Transactions in thespring-kafkadocumentation. When transactions are enabled, individualproducerproperties are ignored and all producers use thespring.cloud.stream.kafka.binder.transaction.producer.*properties.Default
null(no transactions)- spring.cloud.stream.kafka.binder.transaction.producer.*
Global producer properties for producers in a transactional binder. See
spring.cloud.stream.kafka.binder.transaction.transactionIdPrefixand Section 14.3.3, “Kafka Producer Properties” and the general producer properties supported by all binders.Default: See individual producer properties.
The following properties are available for Kafka consumers only and
must be prefixed with spring.cloud.stream.kafka.bindings.<channelName>.consumer..
- autoRebalanceEnabled
When
true, topic partitions will be automatically rebalanced between the members of a consumer group. Whenfalse, each consumer will be assigned a fixed set of partitions based onspring.cloud.stream.instanceCountandspring.cloud.stream.instanceIndex. This requires bothspring.cloud.stream.instanceCountandspring.cloud.stream.instanceIndexproperties to be set appropriately on each launched instance. The propertyspring.cloud.stream.instanceCountmust typically be greater than 1 in this case.Default:
true.- autoCommitOffset
Whether to autocommit offsets when a message has been processed. If set to
false, a header with the keykafka_acknowledgmentof the typeorg.springframework.kafka.support.Acknowledgmentheader will be present in the inbound message. Applications may use this header for acknowledging messages. See the examples section for details. When this property is set tofalse, Kafka binder will set the ack mode toorg.springframework.kafka.listener.AbstractMessageListenerContainer.AckMode.MANUAL.Default:
true.- autoCommitOnError
Effective only if
autoCommitOffsetis set totrue. If set tofalseit suppresses auto-commits for messages that result in errors, and will commit only for successful messages, allows a stream to automatically replay from the last successfully processed message, in case of persistent failures. If set totrue, it will always auto-commit (if auto-commit is enabled). If not set (default), it effectively has the same value asenableDlq, auto-committing erroneous messages if they are sent to a DLQ, and not committing them otherwise.Default: not set.
- recoveryInterval
The interval between connection recovery attempts, in milliseconds.
Default:
5000.- startOffset
The starting offset for new groups. Allowed values:
earliest,latest. If the consumer group is set explicitly for the consumer 'binding' (viaspring.cloud.stream.bindings.<channelName>.group), then 'startOffset' is set toearliest; otherwise it is set tolatestfor theanonymousconsumer group.Default: null (equivalent to
earliest).- enableDlq
When set to true, it will send enable DLQ behavior for the consumer. By default, messages that result in errors will be forwarded to a topic named
error.<destination>.<group>. The DLQ topic name can be configurable via the propertydlqName. This provides an alternative option to the more common Kafka replay scenario for the case when the number of errors is relatively small and replaying the entire original topic may be too cumbersome. See Section 14.6, “Dead-Letter Topic Processing” processing for more information. Starting with version 2.0, messages sent to the DLQ topic are enhanced with the following headers:x-original-topic,x-exception-messageandx-exception-stacktraceasbyte[].Default:
false.- configuration
Map with a key/value pair containing generic Kafka consumer properties.
Default: Empty map.
- dlqName
The name of the DLQ topic to receive the error messages.
Default: null (If not specified, messages that result in errors will be forwarded to a topic named
error.<destination>.<group>).- dlqProducerProperties
Using this, dlq specific producer properties can be set. All the properties available through kafka producer properties can be set through this property.
Default: Default Kafka producer properties.
- standardHeaders
Indicates which standard headers are populated by the inbound channel adapter.
none,id,timestamporboth. Useful if using native deserialization and the first component to receive a message needs anid(such as an aggregator that is configured to use a JDBC message store).Default:
none- converterBeanName
The name of a bean that implements
RecordMessageConverter; used in the inbound channel adapter to replace the defaultMessagingMessageConverter.Default:
null- idleEventInterval
The interval, in milliseconds between events indicating that no messages have recently been received. Use an
ApplicationListener<ListenerContainerIdleEvent>to receive these events. See the section called “Example: Pausing and Resuming the Consumer” for a usage example.Default:
30000
The following properties are available for Kafka producers only and
must be prefixed with spring.cloud.stream.kafka.bindings.<channelName>.producer..
- bufferSize
Upper limit, in bytes, of how much data the Kafka producer will attempt to batch before sending.
Default:
16384.- sync
Whether the producer is synchronous.
Default:
false.- batchTimeout
How long the producer will wait before sending in order to allow more messages to accumulate in the same batch. (Normally the producer does not wait at all, and simply sends all the messages that accumulated while the previous send was in progress.) A non-zero value may increase throughput at the expense of latency.
Default:
0.- messageKeyExpression
A SpEL expression evaluated against the outgoing message used to populate the key of the produced Kafka message. For example
headers.keyorpayload.myKey.Default:
none.- headerPatterns
A comma-delimited list of simple patterns to match spring-messaging headers to be mapped to the kafka
Headersin theProducerRecord. Patterns can begin or end with the wildcard character (asterisk). Patterns can be negated by prefixing with!; matching stops after the first match (positive or negative). For example!foo,fo*will passfoxbut notfoo.idandtimestampare never mapped.Default:
*(all headers - except theidandtimestamp)- configuration
Map with a key/value pair containing generic Kafka producer properties.
Default: Empty map.
![[Note]](images/note.png) | Note |
|---|---|
The Kafka binder will use the |
In this section, we illustrate the use of the above properties for specific scenarios.
This example illustrates how one may manually acknowledge offsets in a consumer application.
This example requires that spring.cloud.stream.kafka.bindings.input.consumer.autoCommitOffset is set to false.
Use the corresponding input channel name for your example.
@SpringBootApplication
@EnableBinding(Sink.class)
public class ManuallyAcknowdledgingConsumer {
public static void main(String[] args) {
SpringApplication.run(ManuallyAcknowdledgingConsumer.class, args);
}
@StreamListener(Sink.INPUT)
public void process(Message<?> message) {
Acknowledgment acknowledgment = message.getHeaders().get(KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class);
if (acknowledgment != null) {
System.out.println("Acknowledgment provided");
acknowledgment.acknowledge();
}
}
}Apache Kafka 0.9 supports secure connections between client and brokers.
To take advantage of this feature, follow the guidelines in the Apache Kafka Documentation as well as the Kafka 0.9 security guidelines from the Confluent documentation.
Use the spring.cloud.stream.kafka.binder.configuration option to set security properties for all clients created by the binder.
For example, for setting security.protocol to SASL_SSL, set:
spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_SSL
All the other security properties can be set in a similar manner.
When using Kerberos, follow the instructions in the reference documentation for creating and referencing the JAAS configuration.
Spring Cloud Stream supports passing JAAS configuration information to the application using a JAAS configuration file and using Spring Boot properties.
The JAAS, and (optionally) krb5 file locations can be set for Spring Cloud Stream applications by using system properties. Here is an example of launching a Spring Cloud Stream application with SASL and Kerberos using a JAAS configuration file:
java -Djava.security.auth.login.config=/path.to/kafka_client_jaas.conf -jar log.jar \ --spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \ --spring.cloud.stream.kafka.binder.zkNodes=secure.zookeeper:2181 \ --spring.cloud.stream.bindings.input.destination=stream.ticktock \ --spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT
As an alternative to having a JAAS configuration file, Spring Cloud Stream provides a mechanism for setting up the JAAS configuration for Spring Cloud Stream applications using Spring Boot properties.
The following properties can be used for configuring the login context of the Kafka client.
- spring.cloud.stream.kafka.binder.jaas.loginModule
The login module name. Not necessary to be set in normal cases.
Default:
com.sun.security.auth.module.Krb5LoginModule.- spring.cloud.stream.kafka.binder.jaas.controlFlag
The control flag of the login module.
Default:
required.- spring.cloud.stream.kafka.binder.jaas.options
Map with a key/value pair containing the login module options.
Default: Empty map.
Here is an example of launching a Spring Cloud Stream application with SASL and Kerberos using Spring Boot configuration properties:
java --spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \ --spring.cloud.stream.kafka.binder.zkNodes=secure.zookeeper:2181 \ --spring.cloud.stream.bindings.input.destination=stream.ticktock \ --spring.cloud.stream.kafka.binder.autoCreateTopics=false \ --spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT \ --spring.cloud.stream.kafka.binder.jaas.options.useKeyTab=true \ --spring.cloud.stream.kafka.binder.jaas.options.storeKey=true \ --spring.cloud.stream.kafka.binder.jaas.options.keyTab=/etc/security/keytabs/kafka_client.keytab \ --spring.cloud.stream.kafka.binder.jaas.options.principal=kafka-client-1@EXAMPLE.COM
This represents the equivalent of the following JAAS file:
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/security/keytabs/kafka_client.keytab"
principal="[email protected]";
};If the topics required already exist on the broker, or will be created by an administrator, autocreation can be turned off and only client JAAS properties need to be sent. As an alternative to setting spring.cloud.stream.kafka.binder.autoCreateTopics you can simply remove the broker dependency from the application. See the section called “Excluding Kafka broker jar from the classpath of the binder based application” for details.
| Note |
|---|---|
Do not mix JAAS configuration files and Spring Boot properties in the same application.
If the |
| Note |
|---|---|
Exercise caution when using the |
If you wish to suspend consumption, but not cause a partition rebalance, you can pause and resume the consumer.
This is facilitated by adding the Consumer as a parameter to your @StreamListener.
To resume, you need an ApplicationListener for ListenerContainerIdleEvent s; the frequency at which events are published is controlled by the idleEventInterval property.
Since the consumer is not thread-safe, you must call these methods on the calling thread.
The following simple application shows how to pause and resume.
@SpringBootApplication @EnableBinding(Sink.class) public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } @StreamListener(Sink.INPUT) public void in(String in, @Header(KafkaHeaders.CONSUMER) Consumer<?, ?> consumer) { System.out.println(in); consumer.pause(Collections.singleton(new TopicPartition("myTopic", 0))); } @Bean public ApplicationListener<ListenerContainerIdleEvent> idleListener() { return event -> { System.out.println(event); if (event.getConsumer().paused().size() > 0) { event.getConsumer().resume(event.getConsumer().paused()); } }; } }
The default Kafka support in Spring Cloud Stream Kafka binder is for Kafka version 0.10.1.1. The binder also supports connecting to other 0.10 based versions and 0.9 clients.
In order to do this, when you create the project that contains your application, include spring-cloud-starter-stream-kafka as you normally would do for the default binder.
Then add these dependencies at the top of the <dependencies> section in the pom.xml file to override the dependencies.
Here is an example for downgrading your application to 0.10.0.1. Since it is still on the 0.10 line, the default spring-kafka and spring-integration-kafka versions can be retained.
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.10.0.1</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.10.0.1</version> </dependency>
Here is another example of using 0.9.0.1 version.
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> <version>1.0.5.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.integration</groupId> <artifactId>spring-integration-kafka</artifactId> <version>2.0.1.RELEASE</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.9.0.1</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.9.0.1</version> </dependency>
| Note |
|---|---|
The versions above are provided only for the sake of the example. For best results, we recommend using the most recent 0.10-compatible versions of the projects. |
The Apache Kafka Binder uses the administrative utilities which are part of the Apache Kafka server library to create and reconfigure topics. If the inclusion of the Apache Kafka server library and its dependencies is not necessary at runtime because the application will rely on the topics being configured administratively, the Kafka binder allows for Apache Kafka server dependency to be excluded from the application.
If you use non default versions for Kafka dependencies as advised above, all you have to do is not to include the kafka broker dependency.
If you use the default Kafka version, then ensure that you exclude the kafka broker jar from the spring-cloud-starter-stream-kafka dependency as following.
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-kafka</artifactId> <exclusions> <exclusion> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> </exclusion> </exclusions> </dependency>
If you exclude the Apache Kafka server dependency and the topic is not present on the server, then the Apache Kafka broker will create the topic if auto topic creation is enabled on the server. Please keep in mind that if you are relying on this, then the Kafka server will use the default number of partitions and replication factors. On the other hand, if auto topic creation is disabled on the server, then care must be taken before running the application to create the topic with the desired number of partitions.
If you want to have full control over how partitions are allocated, then leave the default settings as they are, i.e. do not exclude the kafka broker jar and ensure that spring.cloud.stream.kafka.binder.autoCreateTopics is set to true, which is the default.
Starting with version 1.3, the binder unconditionally sends exceptions to an error channel for each consumer destination, and can be configured to send async producer send failures to an error channel too. See the section called “Message Channel Binders and Error Channels” for more information.
The payload of the ErrorMessage for a send failure is a KafkaSendFailureException with properties:
failedMessage- the spring-messagingMessage<?>that failed to be sent.record- the rawProducerRecordthat was created from thefailedMessage
There is no automatic handling of producer exceptions (such as sending to a Dead-Letter queue); you can consume these exceptions with your own Spring Integration flow.
Kafka binder module exposes the following metrics:
spring.cloud.stream.binder.kafka.someGroup.someTopic.lag - this metric indicates how many messages have not been yet consumed from given binder’s topic by given consumer group.
For example if the value of the metric spring.cloud.stream.binder.kafka.myGroup.myTopic.lag is 1000, then consumer group myGroup has 1000 messages to waiting to be consumed from topic myTopic.
This metric is particularly useful to provide auto-scaling feedback to PaaS platform of your choice.
Because it can’t be anticipated how users would want to dispose of dead-lettered messages, the framework does not provide any standard mechanism to handle them.
If the reason for the dead-lettering is transient, you may wish to route the messages back to the original topic.
However, if the problem is a permanent issue, that could cause an infinite loop.
The following spring-boot application is an example of how to route those messages back to the original topic, but moves them to a third "parking lot" topic after three attempts.
The application is simply another spring-cloud-stream application that reads from the dead-letter topic.
It terminates when no messages are received for 5 seconds.
The examples assume the original destination is so8400out and the consumer group is so8400.
There are several considerations.
- Consider only running the rerouting when the main application is not running. Otherwise, the retries for transient errors will be used up very quickly.
- Alternatively, use a two-stage approach - use this application to route to a third topic, and another to route from there back to the main topic.
- Since this technique uses a message header to keep track of retries, it won’t work with
headerMode=raw. In that case, consider adding some data to the payload (that can be ignored by the main application). x-retrieshas to be added to theheaderspropertyspring.cloud.stream.kafka.binder.headers=x-retrieson both this, and the main application so that the header is transported between the applications.- Since kafka is publish/subscribe, replayed messages will be sent to each consumer group, even those that successfully processed a message the first time around.
application.properties.
spring.cloud.stream.bindings.input.group=so8400replay spring.cloud.stream.bindings.input.destination=error.so8400out.so8400 spring.cloud.stream.bindings.output.destination=so8400out spring.cloud.stream.bindings.output.producer.partitioned=true spring.cloud.stream.bindings.parkingLot.destination=so8400in.parkingLot spring.cloud.stream.bindings.parkingLot.producer.partitioned=true spring.cloud.stream.kafka.binder.configuration.auto.offset.reset=earliest spring.cloud.stream.kafka.binder.headers=x-retries
Application.
@SpringBootApplication @EnableBinding(TwoOutputProcessor.class) public class ReRouteDlqKApplication implements CommandLineRunner { private static final String X_RETRIES_HEADER = "x-retries"; public static void main(String[] args) { SpringApplication.run(ReRouteDlqKApplication.class, args).close(); } private final AtomicInteger processed = new AtomicInteger(); @Autowired private MessageChannel parkingLot; @StreamListener(Processor.INPUT) @SendTo(Processor.OUTPUT) public Message<?> reRoute(Message<?> failed) { processed.incrementAndGet(); Integer retries = failed.getHeaders().get(X_RETRIES_HEADER, Integer.class); if (retries == null) { System.out.println("First retry for " + failed); return MessageBuilder.fromMessage(failed) .setHeader(X_RETRIES_HEADER, new Integer(1)) .setHeader(BinderHeaders.PARTITION_OVERRIDE, failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID)) .build(); } else if (retries.intValue() < 3) { System.out.println("Another retry for " + failed); return MessageBuilder.fromMessage(failed) .setHeader(X_RETRIES_HEADER, new Integer(retries.intValue() + 1)) .setHeader(BinderHeaders.PARTITION_OVERRIDE, failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID)) .build(); } else { System.out.println("Retries exhausted for " + failed); parkingLot.send(MessageBuilder.fromMessage(failed) .setHeader(BinderHeaders.PARTITION_OVERRIDE, failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID)) .build()); } return null; } @Override public void run(String... args) throws Exception { while (true) { int count = this.processed.get(); Thread.sleep(5000); if (count == this.processed.get()) { System.out.println("Idle, terminating"); return; } } } public interface TwoOutputProcessor extends Processor { @Output("parkingLot") MessageChannel parkingLot(); } }
Apache Kafka supports topic partitioning natively.
Sometimes it is advantageous to send data to specific partitions, for example when you want to strictly order message processing - all messages for a particular customer should go to the same partition.
The following illustrates how to configure the producer and consumer side:
@SpringBootApplication @EnableBinding(Source.class) public class KafkaPartitionProducerApplication { private static final Random RANDOM = new Random(System.currentTimeMillis()); private static final String[] data = new String[] { "foo1", "bar1", "qux1", "foo2", "bar2", "qux2", "foo3", "bar3", "qux3", "foo4", "bar4", "qux4", }; public static void main(String[] args) { new SpringApplicationBuilder(KafkaPartitionProducerApplication.class) .web(false) .run(args); } @InboundChannelAdapter(channel = Source.OUTPUT, poller = @Poller(fixedRate = "5000")) public Message<?> generate() { String value = data[RANDOM.nextInt(data.length)]; System.out.println("Sending: " + value); return MessageBuilder.withPayload(value) .setHeader("partitionKey", value) .build(); } }
application.yml.
spring: cloud: stream: bindings: output: destination: partitioned.topic producer: partitioned: true partition-key-expression: headers['partitionKey'] partition-count: 12
![[Important]](images/important.png) | Important |
|---|---|
The topic must be provisioned to have enough partitions to achieve the desired concurrency for all consumer groups.
The above configuration will support up to 12 consumer instances (or 6 if their |
| Note |
|---|---|
The above configuration uses the default partitioning ( |
Since partitions are natively handled by Kafka, no special configuration is needed on the consumer side. Kafka will allocate partitions across the instances.
@SpringBootApplication @EnableBinding(Sink.class) public class KafkaPartitionConsumerApplication { public static void main(String[] args) { new SpringApplicationBuilder(KafkaPartitionConsumerApplication.class) .web(false) .run(args); } @StreamListener(Sink.INPUT) public void listen(@Payload String in, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) { System.out.println(in + " received from partition " + partition); } }
application.yml.
spring: cloud: stream: bindings: input: destination: partitioned.topic group: myGroup
You can add instances as needed; Kafka will rebalance the partition allocations.
If the instance count (or instance count * concurrency) exceeds the number of partitions, some consumers will be idle.
Spring Cloud Stream Kafka support also includes a binder specifically designed for Apache Kafka Streams binding. Using this binder, applications can be written that leverage the Apache Kafka Streams API. For more information on Kafka Streams, see Kafka Streams API Developer Manual
Kafka Streams support in Spring Cloud Stream is based on the foundations provided by the Spring Kafka project. For details on that support, see Kafaka Streams Support in Spring Kafka.
Here are the maven coordinates for the Spring Cloud Stream Kafka Streams binder artifact.
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-stream-binder-kafka-streams</artifactId> </dependency>
High level streams DSL provided through the Kafka Streams API can be used through Spring Cloud Stream support. Some minimal support for writing applications using the processor API is also available through the binder. Kafka Streams applications using the Spring Cloud Stream support can be written using the processor model, i.e. messages read from an inbound topic and messages written to an outbound topic or using the sink style where it does not have an output binding.
This application will listen from a Kafka topic and write the word count for each unique word that it sees in a 5 seconds time window.
@SpringBootApplication
@EnableBinding(KStreamProcessor.class)
public class WordCountProcessorApplication {
@StreamListener("input")
@SendTo("output")
public KStream<?, WordCount> process(KStream<?, String> input) {
return input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(TimeWindows.of(5000))
.count(Materialized.as("WordCounts-multi"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))));
}
public static void main(String[] args) {
SpringApplication.run(WordCountProcessorApplication.class, args);
}If you build it as a Spring Boot uber jar, you can run the above example in the following way:
java -jar uber.jar --spring.cloud.stream.bindings.input.destination=words --spring.cloud.stream.bindings.output.destination=counts
This means that the application will listen from the incoming Kafka topic words and write to the output topic counts.
Spring Cloud Stream will ensure that the messages from both the incoming and outgoing topics are bound as KStream objects. Applications can exclusively focus on the business aspects of the code, i.e. writing the logic required in the processor rather than setting up the streams specific configuration required by the Kafka Streams infrastructure. All such infrastructure details are handled by the framework.
Spring Cloud Stream Kafka Streams binder allows the users to write applications with multiple bindings. There are use cases in which you may want to have multiple incoming KStream objects or a combination of KStream and KTable objects. Both of these flavors are supported. Here are some examples.
@EnableBinding(KStreamKTableBinding.class)
.....
.....
@StreamListener
public void process(@Input("inputStream") KStream<String, PlayEvent> playEvents,
@Input("inputTable") KTable<Long, Song> songTable) {
....
....
}
interface KStreamKTableBinding {
@Input("inputStream")
KStream<?, ?> inputStream();
@Input("inputTable")
KTable<?, ?> inputTable();
}In the above example, the application is written in a sink style, i.e. there are no output bindings and the application has to make the decision to what needs to happen. Most likely, when you write applications this way, you might want to send the information downstream or store them in a state store (See below for Queryable State Stores).
In the case of incoming KTable, if you want to materialize it as a state store, you have to express that through the following property.
spring.cloud.stream.kafka.streams.bindings.inputTable.consumer.materializedAs: all-songs
Here is an example for multiple input bindings and an output binding (processor style).
@EnableBinding(KStreamKTableBinding.class)
....
....
@StreamListener
@SendTo("output")
public KStream<String, Long> process(@Input("input") KStream<String, Long> userClicksStream,
@Input("inputTable") KTable<String, String> userRegionsTable) {
....
....
}
interface KStreamKTableBinding extends KafkaStreamsProcessor {
@Input("inputX")
KTable<?, ?> inputTable();
}Kafka Streams allow outbound data to be split into multiple topics based on some predicates.
Spring Cloud Stream Kafka Streams binder provides support for this feature without losing the overall programming model exposed through StreamListener in the end user application.
You write the application in the usual way as demonstrated above in the word count example.
When using the branching feature, you are required to do a few things.
First, you need to make sure that your return type is KStream[] instead of a regular KStream.
Then you need to use the SendTo annotation containing the output bindings in the order (example below).
For each of these output bindings, you need to configure destination, content-type etc. as required by any other standard Spring Cloud Stream application
Here is an example:
@EnableBinding(KStreamProcessorWithBranches.class)
@EnableAutoConfiguration
public static class WordCountProcessorApplication {
@Autowired
private TimeWindows timeWindows;
@StreamListener("input")
@SendTo({"output1","output2","output3})
public KStream<?, WordCount>[] process(KStream<Object, String> input) {
Predicate<Object, WordCount> isEnglish = (k, v) -> v.word.equals("english");
Predicate<Object, WordCount> isFrench = (k, v) -> v.word.equals("french");
Predicate<Object, WordCount> isSpanish = (k, v) -> v.word.equals("spanish");
return input
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
.groupBy((key, value) -> value)
.windowedBy(timeWindows)
.count(Materialized.as("WordCounts-1"))
.toStream()
.map((key, value) -> new KeyValue<>(null, new WordCount(key.key(), value, new Date(key.window().start()), new Date(key.window().end()))))
.branch(isEnglish, isFrench, isSpanish);
}
interface KStreamProcessorWithBranches {
@Input("input")
KStream<?, ?> input();
@Output("output1")
KStream<?, ?> output1();
@Output("output2")
KStream<?, ?> output2();
@Output("output3")
KStream<?, ?> output3();
}
}Then in the properties:
spring.cloud.stream.bindings.output1.contentType: application/json
spring.cloud.stream.bindings.output2.contentType: application/json
spring.cloud.stream.bindings.output3.contentType: application/json
spring.cloud.stream.kafka.streams.binder.configuration.commit.interval.ms: 1000
spring.cloud.stream.kafka.streams.binder.configuration:
default.key.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
default.value.serde: org.apache.kafka.common.serialization.Serdes$StringSerde
spring.cloud.stream.bindings.output1:
destination: foo
producer:
headerMode: raw
spring.cloud.stream.bindings.output2:
destination: bar
producer:
headerMode: raw
spring.cloud.stream.bindings.output3:
destination: fox
producer:
headerMode: raw
spring.cloud.stream.bindings.input:
destination: words
consumer:
headerMode: rawSpring Cloud Stream Kafka Streams binder allows the usage of usual patterns for content type conversions as in other message channel based binder applications. Many Kafka Streams operations - that are part of the actual application and not at the inbound and outbound - need to know the type of SerDe’s used to correctly transform key and value data. Therefore, it may be more natural to rely on the SerDe facilities provided by the Apache Kafka Streams library itself for inbound and outbound conversions rather than using the content type conversions offered by the framework. On the other hand, you might be already familiar with the content type conversion patterns in spring cloud stream and want to keep using them for inbound and outbound conversions. Both options are supported in the Spring Cloud Stream binder for Apache Kafka Streams.
If native encoding is disabled (which is the default), then the framework will convert the message using the contentType set by the user (or the default content type of application/json). It will ignore any Serde set on the outbound in this case for outbound serialization.
Here is the property to set the contentType on the outbound.
spring.cloud.stream.bindings.output.contentType: application/json
Here is the property to enable native encoding.
spring.cloud.stream.bindings.output.nativeEncoding: true
If native encoding is enabled on the output binding (user has to explicitly enable it as above), then the framework will skip doing any message conversion on the outbound.
In that case, it will use the Serde set by the user.
First, it checks for the valueSerde property set on the actual output binding. Here is an example
spring.cloud.stream.kafka.streams.bindings.output.producer.valueSerde: org.apache.kafka.common.serialization.Serdes$StringSerde
If this property is not set, then it will default to the common value Serde - spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde.
It is worth to mention that Spring Cloud Stream Kafka Streams binder does not serialize the keys on outbound, rather it is always done by Kafka itself. Therefore, you either have to specify the keySerde property on the binding or it will default to the application wide common keySerde set on the streams configuration.
Binding level key serde:
spring.cloud.stream.kafka.streams.bindings.output.producer.keySerde
Common Key serde:
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde
If branching is used, then you need to use multiple output bindings. For example,
interface KStreamProcessorWithBranches {
@Input("input")
KStream<?, ?> input();
@Output("output1")
KStream<?, ?> output1();
@Output("output2")
KStream<?, ?> output2();
@Output("output3")
KStream<?, ?> output3();
}If nativeEncoding is set, then you can set different Serde values on these individual output bindings as below.
spring.cloud.stream.kstream.bindings.output1.producer.valueSerde=IntegerSerde spring.cloud.stream.kstream.bindings.outpu2t.producer.valueSerde=StringSerde spring.cloud.stream.kstream.bindings.output3.producer.valueSerde=JsonSerde
Then if you have SendTo like this, @SendTo({"output1", "output2", "output3"}), the KStream[] from the branches are applied with proper Serde objects as defined above.
If you are not enabling nativeEncoding, you can then set different contentType values on the output bindings as below.
In that case, the framework will use the appropriate message converter to convert the messages before sending to Kafka.
spring.cloud.stream.bindings.output1.contentType: application/json spring.cloud.stream.bindings.output2.contentType: application/java-serialzied-object spring.cloud.stream.bindings.output3.contentType: application/octet-stream
Similar rules apply to data deserialization on the inbound as in the case of outbound serialization.
If native decoding is disabled (which is the default), then the framework will convert the message using the contentType set by the user (or the default content type of application/json). It will ignore any Serde set on the inbound in this case for inbound dserialization.
Here is the property to set the contentType on the inbound.
spring.cloud.stream.bindings.input.contentType: application/json
Here is the property to enable native decoding.
spring.cloud.stream.bindings.input.nativeDecoding: true
If native decoding is enabled on the input binding (user has to explicitly enable it as above), then the framework will skip doing any message conversion on the inbound.
In that case, it will use the Serde set by the user.
First, it checks for the valueSerde property set on the actual input binding. Here is an example
spring.cloud.stream.kafka.streams.bindings.input.consumer.valueSerde: org.apache.kafka.common.serialization.Serdes$StringSerde
If this property is not set, then it will default to the common value Serde - spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde.
It is worth to mention that Spring Cloud Stream Kafka Streams binder does not deserialize the keys on inbound, rather it is always done by Kafka itself. Therefore, you either have to specify the keySerde property on the binding or it will default to the application wide common keySerde set on the streams configuration.
Binding level key serde:
spring.cloud.stream.kafka.streams.bindings.input.consumer.keySerde
Common Key serde:
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde
As in the case of KStream branching on the outbound, the benefit of setting value Serde per binding is that if you have multiple input bindings (multiple KStreams) and they all require separate value Serdes, then you can configure them individually. If you use the common configuration approach, then that is not possible.
Apache Kafka Streams now provide the capability for natively handling exceptions from deserialization errors. For details on this support, please see this Out of the box, Apache Kafka Streams provide two kinds of deserialization exception handlers - logAndContinue and logAndFail. As the name indicates, the former will log the error and continue processing next records and the latter will log the error and fai.. LogAndFail is the default deserialization exception handler.
Spring Cloud Stream binder for Apache Kafka Streams allows to specify these exception handlers through the following properties.
spring.cloud.stream.kafka.streams.binder.serdeError: logAndContinue
In addition to the above two deserialization exception handlers, the binder also provides a third one for sending the bad records (poison pills) to a DLQ topic. Here is how you enable this DLQ exception handler.
spring.cloud.stream.kafka.streams.binder.serdeError: sendToDlq
When the above property is set, then all records in error from deserialization are sent to the DLQ topic.
First it checks, if there is a dlqName property is set on the binding itself using the following property.
spring.cloud.stream.kafka.streams.bindings.input.consumer.dlqName: foo-dlq
If this is set, then the records in error are sent to the topic foo-dlq.
If this is not set, then it will create a DLQ topic called error.<input-topic-name>.<group-name>.
A couple of things to keep in mind when using the exception handling feature through Spring Cloud Stream binder for Apache Kafka Streams.
- The property
spring.cloud.stream.kafka.streams.binder.serdeErroris applicable for the entire application. This implies that if there are multipleStreamListenermethods in the same application, this property is applied to all of them. - The exception handling for deserialization works consistently with native deserialization and framework provided message conversion.
Other kinds of error handling is limited in Apache Kafka Streams currently and it is up to the end user applications to handle any such application level errors. One side effect of providing a DLQ for deserialization exception handlers as above is that, it provides a way to get access to the DLQ sending bean directly from your application. Once you get access to that bean, you can programmatically send any exception records from your application to the DLQ. Here is an example for how you may do that. Keep in mind that, this approach only works out of the box when you use the low level processor API in your application as below. It still remains hard to achieve the same using the high level DSL without the library natively providing error handling support, but this example provides some hints to work around.
@Autowired
private SendToDlqAndContinue dlqHandler;
@StreamListener("input")
@SendTo("output")
public KStream<?, WordCount> process(KStream<Object, String> input) {
input.process(() -> new Processor() {
ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(Object o, Object o2) {
try {
.....
.....
}
catch(Exception e) {
//explicitly provide the kafka topic corresponding to the input binding as the first argument.
//DLQ handler will correctly map to the dlq topic from the actual incoming destination.
dlqHandler.sendToDlq("topic-name", (byte[]) o1, (byte[]) o2, context.partition());
}
}
.....
.....
});
}As part of the public API of the binder, it now exposes a class called QueryableStoreRegistry.
You can access this as a Spring bean in your application.
One easy way to get access to this bean from your application is to autowire the bean as below.
@Autowired private QueryableStoreRegistry queryableStoreRegistry;
Once you gain access to this bean, then you can find out the particular state store that you are interested in. Here is an example:
ReadOnlyKeyValueStore<Object, Object> keyValueStore =
queryableStoreRegistry.getQueryableStoreType("my-store", QueryableStoreTypes.keyValueStore());Then you can retrieve the data that you stored in this store during the execution of your application.
We covered all the relevant properties that you need when writing Kafka Streams applications using Spring Cloud Stream, scattered in the above sections, but here they are again.
The following properties are available at the binder level and must be prefixed with spring.cloud.stream.kafka.binder..
- configuration
- Map with a key/value pair containing properties pertaining to Apache Kafka Streams API.
This property must be prefixed with
spring.cloud.stream.kafka.streams.binder.. Following are some examples of using this property.
spring.cloud.stream.kafka.streams.binder.configuration.default.key.serde=org.apache.kafka.common.serialization.Serdes$StringSerde spring.cloud.stream.kafka.streams.binder.configuration.default.value.serde=org.apache.kafka.common.serialization.Serdes$StringSerde spring.cloud.stream.kafka.streams.binder.configuration.commit.interval.ms=1000
For more information about all the properties that may go into streams configuration, see StreamsConfig JavaDocs in Apache Kafka Streams docs.
- brokers
Broker URL
Default:
localhost- zkNodes
Zookeeper URL
Default:
localhost- serdeError
Deserialization error handler type. Possible values are -
logAndContinue,logAndFailorsendToDlqDefault:
logAndFail- applicationId
Application ID for all the stream configurations in the current application context. You can override the application id for an individual
StreamListenermethod using thegroupproperty on the binding. You have to ensure that you are using the same group name for all input bindings in the case of multiple inputs on the same methods.Default:
default
The following properties are available for Kafka Streams producers only and must be prefixed with spring.cloud.stream.kafka.streams.bindings.<binding name>.producer..
- keySerde
key serde to use
Default:
none.- valueSerde
value serde to use
Default:
none.- useNativeEncoding
flag to enable native encoding
Default:
false.
The following properties are available for Kafka Streams consumers only and must be prefixed with spring.cloud.stream.kafka.streams.bindings.<binding name>.consumer..
- keySerde
key serde to use
Default:
none.- valueSerde
value serde to use
Default:
none.- materializedAs
state store to materialize when using incoming KTable types
Default:
none.- useNativeDecoding
flag to enable native decoding
Default:
false.- dlqName
DLQ topic name.
Default:
none.
Other common properties used from core Spring Cloud Stream.
spring.cloud.stream.bindings.<binding name>.destination spring.cloud.stream.bindings.<binding name>.group
TimeWindow properties:
Windowing is an important concept in stream processing applications. Following properties are available for configuring time windows.
- spring.cloud.stream.kafka.streams.timeWindow.length
When this property is given, you can autowire a
TimeWindowsbean into the application. The value is expressed in milliseconds.Default:
none.- spring.cloud.stream.kstream.timeWindow.advanceBy
Value is given in milliseconds.
Default:
none.