This chapter covers the fundamentals of the programming model behind Spring Data Neo4j. It discusses the simple and advanced mapping modes, the annotations provided by Spring Data Neo4j and how to use them. Examples for this section are taken from the "IMDB" project of Spring Data Neo4j examples.
Up until recently Spring Data Neo4j supported only the more advanced and flexible AspectJ based mapping approach, see Section 20.2, “Advanced Mapping with AspectJ”. Feedback about issues with the AspectJ tooling and other implications persuaded us to add a simpler mapping (see Section 20.3, “Simple Object Graph Mapping”) to Spring Data Neo4j. Both versions work with the same annotations and provide similar API's, but differ in behaviour.
Reflection and Annotation-based metadata is collected about persistent entities in the Neo4jMappingContext
which provides it to any part of the library. The information is stored in Neo4jPersistentEntity instances
which hold all the Neo4jPersistentProperty's of the type. Each entity can be checked to determine whether it represents
a Node or a Relationship. Properties declare detailed data about their indexing and relationship information as well
as type information that also covers nested generic types. With all that information available it is simple to
select the appropriate strategy for mapping each entity and field to elements, relationships and properties of the graph.
The main difference is in the way of accessing the graph. In the simple mapping the required information is copied into the entity on load and only stored back when an explicit save operation occurs. In the advanced mapping (AspectJ-enhanced) approach a node or relationship is attached via an additional field to the entity and all read- and write-operations (inside of Transactions) happen through that.
For the simple mapping mode, declaration of fetch strategies for related entities is necessary to avoid loading
the whole graph eagerly into memory. The initial approach uses just a simple @Fetch annotations
on relationship properties. The resulting MappingPolicy is provided to the infrastructure methods to ensure
the correct loading behaviour. Both, Neo4jPersistentEntiy and Neo4jPersistentProperty
can be queried for the MappingPolicy.
Otherwise the two approaches share much of the infrastructure. E.g. for creating new entity instances from type information store in the graph (Section 20.15, “Entity type representation”), the infrastructure for mapping individual fields to graph properties and relationships and everything related to indexing and querying. A certain part of that is also exposed via the Neo4jTemplate for direct use.
Behind the scenes, Spring Data Neo4j leverages AspectJ aspects to modify the behavior of annotated POJO entities (see Chapter 26, AspectJ details). Each node entity is backed by a graph node that holds its properties and relationships to other entities. AspectJ is used for intercepting field access, so that Spring Data Neo4j can retrieve the appropriate information from the entity's backing node or relationship.
The aspect introduces an internal field (entityState) and some public methods
(see Section 20.12, “Active Record Methods for Advanced Mapping Mode”) to the entities, for instance
entity.getPersistentState() and entity.relateTo.
It also introduces some methods for graph operations that start at the current entity.
Introduced methods for equals() and hashCode() use the underlying node or relationship.
Please take the introduced field into account when serializing your entities and exclude it from the
serialization process.
Spring Data Neo4j internally uses an abstraction called EntityState that the field
access and instantiation advices of the aspect delegate to. This way, the aspect code is kept to a
minimum, focusing mainly on the pointcuts and delegation. The EntityState then uses
a number of FieldAccessorFactories to create a FieldAccessor instance per
field that does the specific handling needed for the concrete field type. There is some
caching involved as well, so it handles repeated instantiation efficiently.
To use the advanced, AspectJ based mapping, please add spring-data-neo4j-aspects as a dependency
and set up the AspectJ integration in Maven or other build tools as explained in Chapter 21, Environment setup.
Some hints for your IDE setup are described below.
As Spring Data Neo4j uses some advanced features of AspectJ, users may experience issues with their IDE reporting errors where in fact there are none. Features that might be reported wrongfully include: introduction of methods to interfaces, declaration of additional interfaces for annotated classes, and generified introduced methods.
IDEs not providing full AspectJ support might mark parts of your code as having errors.
You should rely on your build-system and tests to verify the correctness of the code. You might also have
your Entities (or their interfaces) implement the NodeBacked and RelationshipBacked
interfaces directly to benefit from completion support and error checking.
Eclipse and STS support AspectJ via the AJDT plugin which can be installed from the update-site listed at http://www.eclipse.org/ajdt/downloads/ (it might be necessary to use the latest development snapshot of the plugin). The current version that does not show incorrect errors is AspectJ 1.6.12 (included in STS 2.8.0), previous versions are reported to mislead the user. Note that AJDT (as of September 2012) requires projects to be rebuild after Eclipse is started to fully support all advanced features.
![[Note]](images/note.png) | Note |
|---|---|
There might be some issues with the eclipse maven plugin not adding AspectJ files correctly to the build path.
If you encounter issues, please try the following:
Try editing the build path to |
The AspectJ support in IntelliJ IDEA lacks some of the features. JetBrains is working on improving
the situation in their upcoming 11 release of their popular IDE. Their latest work is available
under their early access program (EAP). Building the project with the AspectJ compiler
ajc works in IDEA (Options -> Compiler -> Java Compiler should show ajc). Make sure to
give the compiler at least 512 MB of RAM.
In addition to the advanced object graph mapping using AspectJ, Spring Data Neo4j also supports a simpler mode that converts graph data into domain objects and vice versa. It does not require any additional set up and should work out of the box. The simple mapping approach uses the same annotations (???) as the advanced mapping to declare mapping meta-information.
The simple object graph mapping comes into play whenever an entity is constructed from a node or relationship.
This could be done explicitly like during the lookup- or create-operations of the repositories and the
Neo4jTemplate but also implicitly while executing
any graph operation that returns nodes or relationships and expecting mapped entities to be returned.
It uses the available meta-information about the persistent entity to iterate over its properties and relationships, fetching their data from the graph while doing so. It also executes computed fields and stores the resulting values in the properties.
We try to avoid loading the whole graph into memory by not following relationships eagerly. A dedicated
@Fetch annotation controls instead if related entities are loaded or not.
Whenever an entity is not fully loaded, then only its id is stored. Those
entities or collections of entities can then later be loaded explicitly using the template.fetch() operation.
The additional fetch information is stored in a MappingPolicy which can be retrieved via the Neo4jTemplate
for classes. Both Neo4jPersistentEntitity as well as Neo4jPersistentProperty provide access to that
information on their scope.
| Note |
|---|---|
Please note that if you have two collections in an entity pointing to the same relationship and one of them has data and the other is empty due to the nature of persisting it, one will override the other in the graph so that you might end up with no data. If you want a relationship-collection to be ignored on save set it to null. |
Example 20.1. Examples for loading entities from the graph
@Autowired Neo4jOperations template; @NodeEntity class Person { String name; @Fetch Person boss; Person spouse; @RelatedTo(type = "FRIEND", direction = BOTH) @Fetch Set<Person> friends; } Person person = template.findOne(personId); assertNotNull(person.getBoss().getName()); assertNotNull(person.getSpouse().getId()); assertNull(person.getSpouse().getName()); template.fetch(person.getSpouse()); assertNotNull(person.getSpouse().getName()); assertEquals(10,person.getFriends().size()); assertNotNull(firstFriend.getName());
| Note |
|---|---|
Both the simple mapping approach as well as the fetch strategies (MappingPolicy) debuted in Spring Data Neo4j 2.0.
So there might be rough edges and there are certainly many areas for improvement and extension. We look forward to your feedback
on this topic.
|
As we tried to encapsulate each aspect of the mapping process into a separate class the resulting fabric of responsibilities is quite
intricate. All of them are set up in the MappingInfrastructure that is part of the Neo4jTemplate setup.
Node entities are declared using the @NodeEntity annotation. Relationship entities use
the @RelationshipEntity annotation.
The @NodeEntity annotation is used to turn a POJO class into an entity backed by a node
in the graph database. Fields on the entity are by default mapped to properties of the node. Fields
referencing other node entities (or collections thereof) are linked with relationships. If the
useShortNames attribute is set to false, the property and relationship names will
have the class name of the entity prepended.
@NodeEntity annotations are inherited from super-types and interfaces. It is not necessary
to annotate your domain objects at every inheritance level.
If the partial attribute is set to true, this entity takes part in a cross-store setting,
where the entity lives in both the graph database and a JPA data source. See
Chapter 22, Cross-store persistence for more information.
Entity fields can be annotated with @GraphProperty, @RelatedTo,
@RelatedToVia, @Indexed, @GraphId, @Query and
@GraphTraversal.
For the simple mapping this is a required field which must be of type Long. It is used
by Spring Data Neo4j to store the node or relationship-id to re-connect the entity to the graph.
| Note |
|---|---|
It must not be a primitive type because then the "non-attached" case can not be represented as the
default value 0 would point to the reference node. Please make also sure that
an |
For the advanced mapping such a field is optional. Only if the underlying id has to be accessed, it is needed.
Entity equality can be a grey area, and it is debatable whether natural keys or database ids best describe equality, there is the issue of versioning over time, etc. For Spring Data Neo4j we have adopted the convention that database-issued ids are the basis for equality, and that has some consequences:
- Before you attach an entity to the database, i.e. before the entity has had its id-field populated, we suggest you rely on object identity for comparisons
- Once an entity is attached, we suggest you rely solely on the id-field for equality
- When you attach an entity, its hashcode changes - because you keep equals and hashcode consistent and rely on the database ID, and because Spring Data Neo4j populates the database ID on save
That causes problems if you had inserted the newly created entity into a hash-based collection before saving. While that can be worked around, we strongly advise you adopt a convention of not working with un-attached entities, to keep your code simple. This is best illustrated in code.
Example 20.3. Entity using id-field for equality and attaching new entity immediately
@NodeEntity public class Studio { @GraphId Long id String name; public boolean equals(Object other) { if (this == other) return true; if (id == null) return false; if (! (other instanceof Studio)) return false; return id.equals(((Studio) other).id); } public int hashCode() { return id == null ? System.identityHashCode(this) : id.hashCode(); } } ... Set<Studio> studios = new HashSet<Studio>(); Studio studio = studioRepository.save(new Studio("Ghibli")); studios.add(studio); Studio sameStudio = studioRepository.findOne(studio.id); assertThat(studio, is(equalTo(sameStudio)); assertThat(studios.contains(sameStudio), is(true); assertThat(studios.remove(sameStudio), is(true);
A work-around for the problem of un-attached entities having their hashcode change when they get saved is to cache the hashcode. The hashcode will change next time you load the entity, but at least if you have the entity sitting in a collection, you will still be able to find it:
Example 20.4. Caching hashcode
@NodeEntity public class Studio { @GraphId Long id String name; transient private Integer hash; public boolean equals(Object other) { if (this == other) return true; if (id == null) return false; if (! (other instanceof Studio)) return false; return id.equals(((Studio) other).id); } public int hashCode() { if (hash == null) hash = id == null ? System.identityHashCode(this) : id.hashCode(); return hash.hashCode(); } } ... Set<Studio> studios = new HashSet<Studio>(); Studio studio = new Studio("Ghibli") studios.add(studio); studioRepository.save(studio); assertThat(studios.contains(studio), is(true); assertThat(studios.remove(studio), is(true); Studio sameStudio = studioRepository.findOne(studio.id); assertThat(studio, is(equalTo(sameStudio)); assertThat(studio.hashCode(), is(not(equalTo(sameStudio.hashCode())));
| Note |
|---|---|
Remember, transient fields are not saved. |
It is not necessary to annotate property fields, as they are persisted by default; all fields that
contain primitive values are persisted directly to the graph. All fields convertible to a String
using the Spring conversion services will be stored as a string. Spring Data Neo4j includes a
custom conversion factory that comes with converters for Enums and Dates.
Transient fields are not persisted.
Collections of collections of primitive or convertable values are stored as well. They are converted to arrays of their type or strings respectively.
This annotation is typically used with cross-store persistence. When a node entity is configured
as partial, then all fields that should be persisted to the graph must be explicitly annotated
with @GraphProperty.
@GraphProperty can specify default values for properties that are not in the graph.
Default values are specified as String representations and will be converted to the correct target
type using the existing conversion facilities.
For example @GraphProperty(defaultValue="20") Integer age.
It is also possible to declare the type that should be used for the storage inside of Neo4j. For instance
if a Date property should be stored as an Long value instead of the default String, the
annotation would look like @GraphProperty(propertyType = Long.class) For the actual mapping of
the Field-Type to the Neo4j-Property type there has to be a Converter registered in the Spring-Config.
The @Indexed annotation can be declared on fields that are intended to be indexed by the Neo4j indexing facilities. The resulting index can be used to later retrieve nodes or relationships that contain a certain property value, e.g. a name. Often an index is used to establish the start node for a traversal. Indexes are accessed by a repository for a particular node or relationship entity type. See Section 20.6, “Indexing” and Section 20.8, “CRUD with repositories” for more information.
The @Query annotation leverages the delegation infrastructure supported by
Spring Data Neo4j. It provides dynamic fields which, when accessed, return the values
selected by the provided query language expression. The provided query must contain a placeholder named {self}
for the the current entity. For instance the query start n=node({self}) match n-[:FRIEND]->friend return friend.
Graph queries can return variable number of entities. That's why annotation can be put onto fields
with a single value, a subclass of Iterable of a concrete type or an Iterable of Map<String,Object>.
Additional parameters are taken from the params attribute of the @Query annotation.
These parameter tuples form key-value pairs that are provided to the query at execution time.
Example 20.5. @Graph on a node entity field
@NodeEntity public class Group { @Query(value = "start n=node({self}) match (n)-[r]->(friend) where r.type = {relType} return friend", params = {"relType", "FRIEND"}) private Iterable<Person> friends; }
| Note |
|---|---|
Please note that this annotation can also be used on repository methods. (Section 20.8, “CRUD with repositories”) |
The @GraphTraversal annotation also leverages the delegation infrastructure supported by
Spring Data aspects. It provides dynamic fields which, when accessed, return an Iterable
of node or relationship entities that are the result of a traversal starting at the entity containing the field.
The TraversalDescription used for this is created by the
FieldTraversalDescriptionBuilder class defined by the traversal
attribute. The class of the resulting node entities must be provided with the
elementClass attribute.
Example 20.6. @GraphTraversal from a node entity
@NodeEntity public class Group { @GraphTraversal(traversal = PeopleTraversalBuilder.class, elementClass = Person.class, params = "persons") private Iterable<Person> people; private static class PeopleTraversalBuilder implements FieldTraversalDescriptionBuilder { @Override public TraversalDescription build(NodeBacked start, Field field, String... params) { return new TraversalDescriptionImpl() .relationships(DynamicRelationshipType.withName(params[0])) .filter(Traversal.returnAllButStartNode()); } } }
Since relationships are first-class citizens in Neo4j, associations between node entities are represented by relationships. In general, relationships are categorized by a type, and start and end nodes (which imply the direction of the relationship). Relationships can have an arbitrary number of properties. Spring Data Neo4j has special support to represent Neo4j relationships as entities too, but it is often not needed.
| Note |
|---|---|
As of Neo4j 1.4.M03, circular references are allowed. Spring Data Neo4j reflects this accordingly. |
Every field of a node entity that references one or more other node entities is backed by relationships in the graph. These relationships are managed by Spring Data Neo4j automatically.
The simplest kind of relationship is a single field pointing to another node entity (1:1).
In this case, the field does not have to be annotated at all, although the annotation may be
used to control the direction and type of the relationship. When setting the field, a
relationship is created when the entity is persisted.
If the field is set to null, the relationship is removed.
It is also possible to have fields that reference a set of node entities (1:N). These fields come in
two forms, modifiable or read-only. Modifiable fields are of the type Set<T>,
and read-only fields are Iterable<T>, where T is a @NodeEntity-annotated
class.
Example 20.8. Node entity with relationships
@NodeEntity public class Actor { @RelatedTo(type = "topActor", direction = Direction.INCOMING) private Set<Movie> topActorIn; @RelatedTo(type = "ACTS_IN") private Set<Movie> movies; }
For the simple mapping, the automatic transitive loading of related entities depends on declaration of
@Fetch at the property. Otherwise the related node or relationship entities will just be initialized
with their id for later loading.
When using the advanced mapping,
Fields referencing other entities should not be manually initialized, as they are managed by
Spring Data Neo4j Aspects under the hood. 1:N fields can be accessed immediately, and Spring Data Neo4j
will provide a Set representing the relationships.
If this Set of related entities is modified, the changes are reflected in the graph,
relationships are added, removed or updated accordingly.
| Note |
|---|---|
Spring Data Neo4j ensures by default that there is only one
relationship of a given type between any two given entities. This can be circumvented by using the
|
| Note |
|---|---|
Before an entity has been persisted for the first time, it will
not have its state managed by Spring Data Neo4j. For example, given the Actor class defined above,
if |
When an Interface is used as target type for the Set and/or as elementClass
it should be marked as @NodeEntity too.
By setting direction to BOTH, relationships are created in the outgoing direction, but when the
1:N field is read, it will include relationships in both directions. A cardinality of M:N is
not necessary because relationships can be navigated in both directions.
In the advanced mapping mode, the relationships can also be accessed by using the methods
entity.getRelationshipBetween(target, type) and
entity.relateTo(target, type) available on each NodeEntity.
These methods find and create Neo4j relationships. It is also possible to manually remove
relationships by using entity.removeRelationshipTo(target, type).
Using these methods is significantly faster than adding/removing from the collection of
relationships as it doesn't have to re-synchronize a whole set of relationships with the graph.
Methods of the same semantics exist in the repositories to be used in the simple mapping mode.
| Note |
|---|---|
Other collection types than |
To access the full data model of graph relationships, POJOs can also be annotated with
@RelationshipEntity, making them relationship entities. Just as node entities represent
nodes in the graph, relationship entities represent relationships. As described above,
fields annotated with @RelatedTo provide a way to only link node entities
via relationships, but it provides no way of accessing the relationships themselves.
Relationship entities can be accessed via by @RelatedToVia-annotated (Section 20.5.3, “@RelatedToVia: Accessing relationship entities”)
fields or methods like entity.getRelationshipTo()
or template|repository.getRelationship(s)Between().
Relationship entities either be instantiated directly and set or added to
@RelatedToVia-annotated fields or created by the introduced
entity.relateTo(), template|repository.createRelationshipBetween() methods
(see alos Section 20.12, “Active Record Methods for Advanced Mapping Mode”)
Fields in relationship entities are, similarly to node entities, persisted as properties on
the relationship. For accessing the two endpoints of the relationship, two special annotations
are available: @StartNode and @EndNode. A field annotated with
one of these annotations will provide read-only access to the corresponding endpoint, depending
on the chosen annotation.
For the relationship-type a String or RelationshipType
field annotated with @RelationshipType is available.
When Relationship-Entities are instantiated directly, the relationship type has to be provided either in this
annotated field or as part of the @RelationshipEntity annotation.
Example 20.9. Relationship entity (in advanced mapping)
@NodeEntity public class Actor { public Role playedIn(Movie movie, String title) { return relateTo(movie, Role.class, "ACTS_IN"); } } @RelationshipEntity public class Role { String title; @StartNode private Actor actor; @EndNode private Movie movie; }
To provide easy programmatic access to the richer relationship entities of the data model,
the annotation @RelatedToVia can be added on fields of type
Iterable<T> or Set<T> or T, where T is a @RelationshipEntity-annotated
class. These fields provide access to relationship entities.
Example 20.10. Relationship entity (in simple mapping)
@NodeEntity public class Actor { @RelatedToVia @Set<Role> roles=new HashSet<Role>(); public Role playedIn(Movie movie, String title) { Role role=new Role(this,movie,title); roles.add(role); return role; } @RelatedToVia(type="FRIEND_OF", direction=Direction.INCOMING) Friendship bestFriend; } @RelationshipEntity(type = "ACTS_IN") public class Role { String title; @StartNode private Actor actor; @EndNode private Movie movie; } @RelationshipEntity public class Friendship { Date since; @StartNode private Actor actor; @EndNode private Person buddy; }
In the example above we show how to specify a default relationship type, and how to provide the relationship type using an annotation property. Here is an example of using the @RelationshipType annotation on a member variable on the relationship entity; we call this dynamic relationship type.
Example 20.11. Dynamic Relationship Type (simple mapping)
@RelationshipEntity(type = "colleague") public class Acquaintance { @StartNode private Actor actor; @EndNode private Person acquaintance; @RelationshipType private String connection; public Acquaintance(Actor actor, Person acquaintance, String connection) { ... Actor frankSinatra = ... Person carloGambino = ... new Acquaintance(frankSinatra, carloGambino, "its_complicated")
| Note |
|---|---|
| Because dynamic type information is, well, dynamic, it is generally not possible to read the mapping backwards using SDN. The relationship still exists, but SDN cannot help you access it because it does not know what type you gave it. Also, for this reason, we require you to specify a default relationship type, so that we can at least attempt the reverse mapping. |
Should you happen to provide conflicting relationship types, we have established the following precedence, in priority order:
- Dynamic
- Annotation-provided
- Default
In some cases, you want to model two different aspects of a conceptual relationship using the same relationship type. Here is a canonical example:
Example 20.12. Clashing Relationship Types
@NodeEntity
class Person {
@RelatedTo(type="OWNS")
Car car;
@RelatedTo(type="OWNS")
Pet pet;
...
It is clear how we can map these relationships: by looking at the type of the end node. To enable this, we have introduced an boolean annotation parameter enforceTargetType, which is disabled by default. Our example now reads:
Example 20.13. Discriminating Relationship Types Using End Node Type
@NodeEntity
class Person {
@RelatedTo(type="OWNS", enforceTargetType=true)
Car car;
@RelatedTo(type="OWNS", enforceTargetType=true)
Pet pet;
...
The example easily generalises to collections too of course, but there are a few note-worthy rules and corner cases:
You need to annotate all clashing relationships.
You can't have two fields, two collections, or a field and a collection, with the same relationship type and identical end node types. SDN does not store metadata about the origin of a relationship. So when saving the entity, the first field or collection would be overwritten by the second, with the processing order being non-deterministic.
You can have clashing relation ship types when end nodes share a supertype.
A variation on the above, you cannot have two fields or two collections with the same relationship type and substitutable end node types.
You can however have a field and a collection where end node types inherit from each other.
Indexing is used in Neo4j to quickly find nodes and relationships to start graph operations from. Either for manually traversing the graph, using the traversal framework, cypher or gremlin queries or for "global" graph operations. Indexes are also employed to ensure uniqueness of elements with certain properties.
The Neo4j graph database employs different index providers for exact lookups and fulltext searches. Lucene is the default index provider implementation. Each named index is configured to be fulltext or exact. There is also a spatial index provider for geo-searches.
When using the standard Neo4j API, nodes and relationships have to be manually indexed with
key-value pairs, typically being the property name and value. When using Spring Data Neo4j,
this task is simplified to just adding an @Indexed annotation on entity fields
by which the entity should be searchable. This will result in automatic updates of the index
every time an indexed field changes.
Numerical fields are indexed numerically so that they are available for range queries. All
other fields are indexed with their string representation. If a numeric field should not be
indexed numerically, it is possible to switch it off with @Indexed(numeric=false).
The @Indexed annotation also provides the option of using a custom index name. The default index
name is the simple class name of the entity, so that each class typically gets its own index.
It is recommended to not have two entity classes with the same class name, regardless of
package.
If a field is declared in a superclass but different indexes for subclasses are needed, the
level attribute declares what will be used as index. Level.CLASS
uses the class where the field was declared and Level.INSTANCE uses the class
that is provided or of the actual entity instance.
The indexes can be queried by using a repository (see
Section 20.8, “CRUD with repositories”).
The repository is an instance of
org.springframework.data.neo4j.repository.IndexRepository.
The methods findByPropertyValue() and findAllByPropertyValue() work on
the exact indexes and return the first or all matches. To do range queries, use
findAllByRange() (please note that currently both values are inclusive).
For providing explicit index names the repository has to extend NamedIndexRepository.
This adds the shown methods with another signature that take the index name as first parameter.
Example 20.14. Indexing entities
@NodeEntity class Person { @Indexed(indexName = "people") String name; @Indexed int age; } GraphRepository<Person> graphRepository = template.repositoryFor(Person.class); // Exact match, in named index Person mark = graphRepository.findByPropertyValue("people", "name", "mark"); // Numeric range query, index name inferred automatically for (Person middleAgedDeveloper : graphRepository.findAllByRange("age", 20, 40)) { Developer developer=middleAgedDeveloper.projectTo(Developer.class); }
Spring Data Neo4j also supports fulltext indexes. By default, indexed fields are stored in
an exact lookup index. To have them analyzed and prepared for fulltext search, the
@Indexed annotation has the type attribute which can be set to IndexType.FULLTEXT.
Please note that fulltext indexes require a separate index name as the fulltext configuration
is stored in the index itself.
Access to the fulltext index is provided by the findAllByQuery() repository method.
Wildcards like * are allowed. Generally though, the fulltext querying rules of the
underlying index provider apply. See the
Lucene documentation for more
information on this.
Example 20.15. Fulltext indexing
@NodeEntity class Person { @Indexed(indexName = "people-search", type=FULLTEXT) String name; } GraphRepository<Person> graphRepository = template.repositoryFor(Person.class); Person mark = graphRepository.findAllByQuery("people-search", "name", "ma*");
| Note |
|---|---|
Please note that indexes are currently created on demand, so whenever an index that doesn't exist is requested from a query or get operation it is created. This is subject to change but has currently the implication that those indexes won't be configured as fulltext which causes subsequent fulltext updates to those indexes to fail. |
Unique indexing with index.putIfAbsent and UniqueFactory was introduced in Neo4j 1.6.
It is also available via the REST API.
In Spring Data Neo4j this is made available via Neo4jTemplate.getOrCreateNode and
Neo4jTemplate.getOrCreateRelationship.
In an entity at most one field can be annotated with @Indexed(unique=true) regardless of the index-type used.
The uniqueness will be taken into account when creating the entity by reusing an existing entity if that unique key-combination
already exists. On saving of the field it will be cross-checked against the index and fail with a DataIntegrityViolationException
if the field was changed to an already existing unique value. Null values are no longer allowed for these properties.
| Note |
|---|---|
| This works for both Node-Entities as well as Relationship-Entities. Relationship-Uniqueness in Neo4j is global so that an existing unique instance of this relationship may connect two completely different nodes and might also have a different type. |
Example 20.16. Unique indexing
// creates or finds a node with the unique index-key-value combination // and initializes it with the properties given template.getOrCreateNode("users", "login", "mh", map("name","Michael","age",37)); @NodeEntity class Person { @Indexed(unique = true) String name; } Person mark1 = repository.save(new Person("mark")); Person mark2 = repository.save(new Person("mark")); // just one node is created assertEquals(mark1,mark2); assertEquals(1, personRepository.count()); Person thomas = repository.save(new Person("thomas")); thomas.setName("mark"); repository.save(thomas); // fails with a DataIntegrityViolationException
The index for a domain class is also available from Neo4jTemplate via
the getIndex() method. The second parameter is optional and takes the index name
if it should not be inferred from the class name. It returns the index implementation that is
provided by Neo4j.
Example 20.17. Manual index retrieval by type and name
@Autowired Neo4jTemplate template; // Default index Index<Node> personIndex = template.getIndex(null, Person.class); personIndex.query(new QueryContext(NumericRangeQuery.newÍntRange("age", 20, 40, true, true)) .sort(new Sort(new SortField("age", SortField.INT, false)))); // Named index Index<Node> namedPersonIndex = template.getIndex("people",Person.class); namedPersonIndex.get("name", "Mark"); // Fulltext index Index<Node> personFulltextIndex = template.getIndex("people-search", Person.class); personFulltextIndex.query("name", "*cha*"); personFulltextIndex.query("{name:*cha*}");
It is also possible to pass in the property name of the entity with an @Indexed annotation whose
index should be returned.
Example 20.18. Manual index retrieval by property configuration
@Autowired Neo4jTemplate template; Index<Node> personIndex = template.getIndex(Person.class, "age"); personIndex.query(new QueryContext(NumericRangeQuery.newÍntRange("age", 20, 40, true, true)) .sort(new Sort(new SortField("age", SortField.INT, false)))); // Fulltext index Index<Node> personFulltextIndex = template.getIndex(Person.class,"name"); personFulltextIndex.query("name", "*cha*"); personFulltextIndex.query("{name:*cha*}");
For querying the index, the template offers query methods that take either the exact match
parameters or a query object/expression, return the results as Result objects which
can then be converted and projected further using the result-conversion-dsl (see Section 20.7, “Neo4jTemplate”).
Neo4j allows to configure auto-indexing
for certain properties on nodes and relationships. This auto-indexing differs
from the approach used in Spring Data Neo4j because it only updates the indexes when the transaction is committed. So the
index modifications will only be available after the successful commit.
It is possible to use the specific index names node_auto_index and relationship_auto_index when
querying indexes in Spring Data Neo4j either with the query methods in template and repositories or via Cypher and Gremlin.
Spring Data Neo4j offers limited support for spatial queries using the neo4j-spatial library. See the
separate chapter Section 20.11, “Geospatial Queries” for details.
The Neo4jTemplate offers the convenient API of Spring templates for the Neo4j graph
database. The Spring Data Neo4j Object Graph mapping builds upon the core functionality of the
template to persist objects to the graph and load them in a variety of ways.
The template handles the active mapping mode (Section 20.1, “Object Graph Mapping”) transparently.
Besides methods for creating, storing and deleting entities, nodes and relationships in the graph, Neo4jTemplate
also offers a wide range of query methods. To reduce the proliferation of query methods a simple result handling
DSL was added.
For direct retrieval of nodes and relationships, the getReferenceNode(),
getNode() and getRelationship() methods can be used.
There are methods (createNode() and createRelationship()) for creating nodes and
relationships that automatically set provided properties.
Example 20.19. Neo4j template
Neo4jOperations neo = new Neo4jTemplate(graphDatabase); Node mark = neo.createNode(map("name", "Mark")); Node thomas = neo.createNode(map("name", "Thomas")); neo.createRelationshipBetween(mark, thomas, "WORKS_WITH", map("project", "spring-data")); neo.index("devs", thomas, "name", "Thomas"); assertEquals( "Mark", neo.query("start p=node({person}) match p<-[:WORKS_WITH]-other return other.name", map("person", asList(thomas.getId()))).to(String.class).single()); // Gremlin assertEquals(thomas, neo.execute("g.v(person).out('WORKS_WITH')", map("person", mark.getId())).to(Node.class).single()); // Index lookup assertEquals(thomas, neo.lookup("devs", "name", "Thomas").to(Node.class).single()); // Index lookup with Result Converter assertEquals("Thomas", neo.lookup("devs", "name", "Thomas") .to(String.class, new ResultConverter<PropertyContainer, String>() { public String convert(PropertyContainer element, Class<String> type) { return (String) element.getProperty("name"); } }).single());
Neo4jTemplate provides access to some of the methods of the Neo4j-Core-API directly. So accessing
nodes and relationships (getReferenceNode, getNode, getRelationship, getRelationshipBetween),
creating nodes and relationships (createNode, createNodeAs, createRelationshipBetween)
and deleting them (delete, deleteRelationshipBetween) are supported. It also provides access to
the underlying GraphDatabase via getGraphDatabase.
Neo4jTemplate allows to save, find(One/All), count, delete
and projectTo entities. It provides the stored type information via getStoredJavaType
and can fetch lazy-loaded entities or load them altogether.
All querying methods of the template return a uniform result type: Result<T>
which is also an Iterable<T>. The query result offers methods of converting each
element to a target type result.to(Type.class) optionally supplying a
ResultConverter<FROM,TO> which takes care of custom conversions. By default most
query methods can already handle conversions from and to: Paths, Nodes, Relationship and GraphEntities
as well as conversions backed by registered ConversionServices. A converted Result<FROM> is an
Iterable<TO>. Results can be limited to a single value using the
result.single() or result.singleOrNull()
methods. It also offers support for a pure callback function using a Handler<T>.
Adding nodes and relationships to an index is done with the index() method.
The lookup() methods either take a field/value combination to look for exact matches in the
index, or a Lucene query object or string to handle more complex queries. All lookup()
methods return a Result<PropertyContainer> to be used or transformed.
The traversal methods are at the core of graph operations.
The traverse() method covers the full traversal operation that takes a
TraversalDescription (typically built with the template.getGraphDatabase().traversalDescription()
DSL) and runs it from the given start node. traverse returns a Result<Path>
to be used or transformed.
The Neo4jTemplate also allows execution of arbitrary Cypher queries. Via the query
methods the statement and parameter-Map are provided. Cypher Queries return tabular results, so the
Result<Map<String,Object>> contains the rows which can be either used as they are
or converted as needed.
Gremlin Scripts can run with the execute method, which also takes the parameters that will be
available as variables inside the script. The result of the executions is a generic
Result<Object> fit for conversion or usage.
The Neo4jTemplate provides implicit transactions for some of its methods. For instance
save uses them. For other modifying operations please provide Spring Transaction management
using @Transactional or the TransactionTemplate.
If the template is configured to use a SpringRestGraphDatabase the operations that would
be expensive over the wire,
like traversals and querying are executed efficiently on the server side by using the REST API to forward
those calls. All the other template methods require individual network operations.
The REST-batch-mode of the SpringRestGraphDatabase is not yet exposed via the template, but it is available
via the graph database.
Neo4j Template offers basic lifecycle events via Spring's event mechanism using ApplicationListener and ApplicationEvent. The following hooks are available in the form of types of application event:
BeforeSaveEvent
AfterSaveEvent
DeleteEvent - after the event has been deleted
The following example demonstrates how to hook into the application lifecycle and register listeners that perform behaviour across types of entities during this life cycle:
Example 20.20. Auditing Entities and Generating Unique Application-level IDs
@Configuration
@EnableNeo4jRepositories
public class ApplicationConfig extends Neo4jConfiguration {
...
@Bean
ApplicationListener<BeforeSaveEvent> beforeSaveEventApplicationListener() {
return new ApplicationListener<BeforeSaveEvent>() {
@Override
public void onApplicationEvent(BeforeSaveEvent event) {
AcmeEntity entity = (AcmeEntity) event.getEntity();
entity.setUniqueId(acmeIdFactory.create());
}
};
}
@Bean
ApplicationListener<AfterSaveEvent> afterSaveEventApplicationListener() {
return new ApplicationListener<AfterSaveEvent>() {
@Override
public void onApplicationEvent(AfterSaveEvent event) {
AcmeEntity entity = (AcmeEntity) event.getEntity();
auditLog.onEventSaved(entity);
}
};
}
@Bean
ApplicationListener<DeleteEvent> deleteEventApplicationListener() {
return new ApplicationListener<DeleteEvent>() {
@Override
public void onApplicationEvent(DeleteEvent event) {
AcmeEntity entity = (AcmeEntity) event.getEntity();
auditLog.onEventDeleted(entity);
}
};
}
...
Changes made to entities in the before-save event handler are reflected in the stored entity - after-save ones are not.
The repositories provided by Spring Data Neo4j build on the composable repository infrastructure in Spring Data Commons. They allow for interface based composition of repositories consisting of provided default implementations for certain interfaces and additional custom implementations for other methods.
Spring Data Neo4j repositories support annotated and named queries for the Neo4j
Cypher query-language and
Gremlin graph DSL.
Spring Data Neo4j comes with typed repository implementations that provide methods for
locating node and relationship entities. There are several types of basic repository interfaces
and implementations. CRUDRepository provides basic operations,
IndexRepository and NamedIndexRepository delegate to Neo4j's internal
indexing subsystem for queries, and TraversalRepository handles Neo4j traversals.
With the RelationshipOperationsRepository it is possible to access, create and delete
relationships between entitites or nodes.
The SpatialRepository allows geographic searches (Section 20.11, “Geospatial Queries”)
GraphRepository is a convenience repository interface, combining CRUDRepository,
IndexRepository, and TraversalRepository. Generally, it has all the
desired repository methods. If other operations are required then the additional repository interfaces should
be added to the individual interface declaration.
CRUDRepository delegates to the configured TypeRepresentationStrategy
(see Section 20.15, “Entity type representation”)
for type based queries.
- Load an entity instance via an id
T findOne(id)- Check for existence of an id in the graph
boolean exists(id)- Iterate over all nodes of a node entity type
EndResult<T> findAll()(supported in future versions:EndResult<T> findAll(Sort)andPage<T> findAll(Pageable))- Count the instances of the repository entity type
Long count()- Save entities
T save(T)andIterable<T> save(Iterable<T>)- Delete graph entities
void delete(T),void; delete(Iterable<T>), anddeleteAll()
IndexRepository works with the indexing subsystem and provides methods to find
entities by indexed properties, ranged queries, and combinations thereof. The index key is
the name of the indexed entity field, unless overridden in the @Indexed annotation.
- Iterate over all indexed entity instances with a certain field value
EndResult<T> findAllByPropertyValue(key, value)- Get a single entity instance with a certain field value
T findByPropertyValue(key, value)- Iterate over all indexed entity instances with field values in a certain numerical range (inclusive)
EndResult<T> findAllByRange(key, from, to)- Iterate over all indexed entity instances with field values matching the given fulltext string or QueryContext query
EndResult<T> findAllByQuery(key, queryOrQueryContext)
There is also a NamedIndexRepository with the same methods, but with an additional index
name parameter, making it possible to query any index.
TraversalRepository delegates to the Neo4j traversal framework.
- Iterate over a traversal result
Iterable<T> findAllByTraversal(startEntity, traversalDescription)
Queries using the Cypher graph query language can be supplied with the @Query annotation.
That means every method annotated with @Query("start n=node:IndexName(key={node or 0}) match (n)-->(m) return m")
will use the supplied query string. The named or indexed parameter {node} will be substituted by the actual method parameter.
Node and Relationship-Entities are handled directly, Iterables thereof as well. All other parameters are
replaced directly (i.e. Strings, Longs, etc). There is special support for the Sort and Pageable
parameters from Spring Data Commons, which are supported to add programmatic paging and sorting (alternatively
static paging and sorting can be supplied in the query string itself).
For using the named parameters you have to either annotate the parameters of the method with the
@Param("node") annotation or enable debug symbols. Indexed parameters are always usable.
If it is required that paged results return the correct total count, the @Query annotation can be supplied with a count query in the countQuery
attribute. This query is executed separately after the result query and its result is used to populate the totalCount property of the returned Page.
Gremlin queries can be used similarly, the @Query annotation would just need a type=QueryType.GREMLIN attribute.
Parameters are supported in the same way.
Spring Data Neo4j also supports the notion of named queries which are externalized in property-config-files
(META-INF/neo4j-named-queries.properties). Those files have the format:
Entity.finderName=query (e.g. Person.findBoss=start p=node({0}) match (p)<-[:BOSS]-(boss) return boss).
Otherwise named queries support the same parameters as annotated queries. For count queries the lookup name is Entity.finderName.count=count-query.
The default query lookup names can be overriden by using an @Query annotation with queryName="my-query-name" or countQueryName="my-query-name".
Typical results for queries are Iterable<Type>, Iterable<Map<String,Object>>, Type and Page<Type>.
Nodes and Relationships are converted to their respective Entities (if they exist). Other values are converted
using the registered Spring conversion services (e.g. enums).
There is a screencast available showing many features of the query language. The following examples are taken from the cineasts dataset of the tutorial section.
start n=node(0) return nreturns the node with id 0
start movie=node:Movie(title='Matrix') return moviereturns the nodes which are indexed with title equal to 'Matrix'
start movie=node:Movie(title='Matrix') match (movie)<-[:ACTS_IN]-(actor) return actor.namereturns the names of the actors that have a ACTS_IN relationship to the movie node for 'Matrix'
start movie=node:Movie(title='Matrix') match (movie)<-[r:RATED]-(user) where r.stars > 3 return user.name, r.stars, r.commentreturns users names and their ratings (>3) of the movie titled 'Matrix'
start user=node:User(login='micha') match (user)-[:FRIEND]-(friend)-[r:RATED]->(movie) return movie.title, AVG(r.stars), COUNT(*) order by AVG(r.stars) desc, COUNT(*) descreturns the movies rated by the friends of the user 'micha', aggregated by movie.title, with averaged ratings and rating-counts sorted by both
Example 20.21. Examples of Cypher queries placed on repository methods with @Query where values are replaced with method parameters, as described in the the section called “Annotated queries”) section.
public interface MovieRepository extends GraphRepository<Movie> { // returns the node with id equal to idOfMovie parameter @Query("start n=node({0}) return n") Movie getMovieFromId(Integer idOfMovie); // returns the nodes which will use index named title equal to movieTitle parameter // movieTitle String must not contain any spaces, otherwise you will receive a NullPointerException. @Query("start movie=node:Movie(title={0}) return movie") Movie getMovieFromTitle(String movieTitle); // returns the Actors that have a ACTS_IN relationship to the movie node with the title equal to movieTitle parameter. // (The parenthesis around 'movie' and 'actor' in the match clause are optional.) @Query("start movie=node:Movie(title={0}) match (movie)<-[:ACTS_IN]-(actor) return actor") Page<Actor> getActorsThatActInMovieFromTitle(String movieTitle, PageRequest); // returns users who rated a movie (movie parameter) higher than rating (rating parameter) @Query("start movie=node:({0}) " + "match (movie)<-[r:RATED]-(user) " + "where r.stars > {1} " + "return user") Iterable<User> getUsersWhoRatedMovieFromTitle(Movie movie, Integer rating); // returns users who rated a movie based on movie title (movieTitle parameter) higher than rating (rating parameter) @Query("start movie=node:Movie(title={0}) " + "match (movie)<-[r:RATED]-(user) " + "where r.stars > {1} " + "return user") Iterable<User> getUsersWhoRatedMovieFromTitle(String movieTitle, Integer rating); }
As known from Rails or Grails it is possible to derive queries for domain entities from finder method names
like Iterable<Person> findByNameAndAgeGreaterThan(String name, int age).
Using the infrastructure in Spring Data Commons that allows to collect the meta information about entities and their properties a finder method
name can be split into its semantic parts and converted into a cypher query.
@Indexed fields will be converted into index-lookups of the start clause,
navigation along relationships will be reflected in the match clause properties with operators will end up as expressions in the
where clause. Order and limiting of the query will by handled by provided Pageable or Sort parameters.
The other parameters will be used in the order they appear in the method signature so they should align with the expressions stated in the method name.
Example 20.22. Some examples of methods and resulting Cypher queries of a PersonRepository
public interface PersonRepository extends GraphRepository<Person> { // start person=node:Person(id={0}) return person Person findById(String id) // start person=node:Person({0}) return person - {0} will be "id:"+name Iterable<Person> findByNameLike(String name) // start person=node:__types__("className"="com...Person") // where person.age = {0} and person.married = {1} // return person Iterable<Person> findByAgeAndMarried(int age, boolean married) // start person=node:__types__("className"="com...Person") // match person<-[:CHILD]-parent // where parent.age > {0} and person.married = {1} // return person Iterable<Person> findByParentAgeAndMarried(int age, boolean married) }
Use the meta information of your domain model classes to declare repository finders that navigate along relationships and compare properties. The path defined with the method name is used to create a Cypher query that is executed on the graph.
Example 20.23. Repository and usage of derived finder methods
@NodeEntity public static class Person { @GraphId Long id; private String name; private Group group; private Person(){} public Person(String name) { this.name = name; } } @NodeEntity public static class Group { @GraphId Long id; private String title; // incoming relationship for the person -> group @RelatedTo(type = "group", direction = Direction.INCOMING) private Set<Person> members=new HashSet<Person>(); private Group(){} public Group(String title, Person...people) { this.title = title; members.addAll(asList(people)); } } public interface PersonRepository extends GraphRepository<Person> { Iterable<Person> findByGroupTitle(String name); } @Autowired PersonRepository personRepository; Person oliver=personRepository.save(new Person("Oliver")); final Group springData = new Group("spring-data",oliver); groupRepository.save(springData); final Iterable<Person> members = personRepository.findByGroupTitle("spring-data"); assertThat(members.iterator().next().name, is(oliver.name));
Spring Data Neo4j supports the new Cypher-DSL to write Cypher queries in a statically typed way. Just by including
CypherDslRepository to your repository you get the Page<T> query(Execute query, params, Pageable page),
Page<T> query(Execute query, Execute countQuery, params, Pageable page)
and the EndResult<T> query(Execute query, params);. The result type of the Cypher-DSL builder is called
Execute.
Example 20.24. Examples for Cypher-DSL repository
import static org.neo4j.cypherdsl.CypherQuery.*; import static org.neo4j.cypherdsl.querydsl.CypherQueryDSL.*; public interface PersonRepository extends GraphRepository<Person>, CypherDslRepository<Person> {} @Autowired PersonRepository repo; // START company=node:Company(name={name}) MATCH company<-[:WORKS_AT]->person RETURN person Execute query = start( lookup( "company", "Company", "name", param("name") ) ). match( path().from( "company" ).in( "WORKS_AT" ).to( "person" )). returns( identifier( "person" )) Page<Person> people = repo.query(query , map("name","Neo4j"), new PageRequest(1,10)); QPerson person = QPerson.person; QCompany company = QCompany.company; Execute query = start( lookup( company, "Company", company.name, param("name") ) ). match( path().from( company ).in( "WORKS_AT" ).to( person ). .where(person.firstName.like("P*").and(person.age.gt(25))). returns( identifier(person) ) EndResult<Person> people = repo.query(query , map("name","Neo4j"));
To use Cypher-DSL with Query-DSL the Mysema dependencies have to be declared explicitly as they are optional in the Cypher-DSL project.
<dependency> <groupId>com.mysema.querydsl</groupId> <artifactId>querydsl-core</artifactId> <version>2.2.3</version> <optional>true</optional> </dependency> <dependency> <groupId>com.mysema.querydsl</groupId> <artifactId>querydsl-lucene</artifactId> <version>2.2.3</version> <optional>true</optional> <exclusions> <exclusion> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>com.mysema.querydsl</groupId> <artifactId>querydsl-apt</artifactId> <version>2.2.3</version> <scope>provided</scope> </dependency>
It is possible to use the Cypher-DSL along with the predicates and code generation features of the QueryDSL project. This will allow you to use Java objects as part of the query, rather than strings, for the names of properties and such. In order to get this to work you first have to add a code processor to your Maven build, which will parse your domain entities marked with @NodeEntity, and from that generate QPerson-style classes, as shown in the previous section. Here is what you need to include in your Maven POM file.
<plugin> <groupId>com.mysema.maven</groupId> <artifactId>maven-apt-plugin</artifactId> <version>1.0.2</version> <configuration> <processor>org.springframework.data.neo4j.querydsl.SDNAnnotationProcessor</processor> </configuration> <executions> <execution> <id>test-sources</id> <phase>generate-test-sources</phase> <goals> <goal>test-process</goal> </goals> <configuration> <outputDirectory>target/generated-sources/test</outputDirectory> </configuration> </execution> </executions> </plugin>
This custom QueryDSL AnnotationProcessor will generate the query classes that can be used when constructing Cypher-DSL queries, as in the previous section.
The Repository instances should normally be injected but can also be created manually via the
Neo4jTemplate.
Example 20.25. Using basic GraphRepository methods
public interface PersonRepository extends GraphRepository<Person> {} @Autowired PersonRepository repo; // OR GraphRepository<Person> repo = template .repositoryFor(Person.class); Person michael = repo.save(new Person("Michael", 36)); Person dave = repo.findOne(123); Long numberOfPeople = repo.count(); EndResult<Person> devs = graphRepository.findAllByPropertyValue("occupation", "developer"); EndResult<Person> middleAgedPeople = graphRepository.findAllByRange("age", 20, 40); EndResult<Person> aTeam = graphRepository.findAllByQuery("name", "A*"); Iterable<Person> aTeam = repo.findAllByQuery("name", "A*"); Iterable<Person> davesFriends = repo.findAllByTraversal(dave, Traversal.description().pruneAfterDepth(1) .relationships(KNOWS).filter(returnAllButStartNode()));
The recommended way of providing repositories is to define a repository interface per domain class. The mechanisms provided by the repository infrastructure will automatically detect them, along with additional implementation classes, and create an injectable repository implementation to be used in services or other spring beans.
Example 20.26. Composing repositories
public interface PersonRepository extends GraphRepository<Person>, PersonRepositoryExtension {} // configure the repositories, preferably via the neo4j:repositories namespace // (template reference is optional) <neo4j:repositories base-package="org.example.repository" graph-database-context-ref="template"/> // have it injected @Autowired PersonRepository personRepository; // or created via the template PersonRepository personRepository = template.repositoryFor(Person.class); Person michael = personRepository.save(new Person("Michael",36)); Person dave=personRepository.findOne(123); Iterable<Person> devs = personRepository.findAllByPropertyValue("occupation","developer"); Iterable<Person> aTeam = graphRepository.findAllByQuery( "name","A*"); Iterable<Person> friends = personRepository.findFriends(dave); // alternatively select some of the required repositories individually public interface PersonRepository extends CRUDGraphRepository<Node,Person>, IndexQueryExecutor<Node,Person>, TraversalQueryExecutor<Node,Person>, PersonRepositoryExtension {} // provide a custom extension if needed public interface PersonRepositoryExtension { Iterable<Person> findFriends(Person person); } public class PersonRepositoryImpl implements PersonRepositoryExtension { // optionally inject default repository, or use DirectGraphRepositoryFactory @Autowired PersonRepository baseRepository; public Iterable<Person> findFriends(Person person) { return baseRepository.findAllByTraversal(person, friendsTraversal); } } // configure the repositories, preferably via the datagraph:repositories namespace // (template reference is optional) <neo4j:repositories base-package="org.springframework.data.neo4j" graph-database-context-ref="template"/> // have it injected @Autowired PersonRepository personRepository; Person michael = personRepository.save(new Person("Michael",36)); Person dave=personRepository.findOne(123); EndResult<Person> devs = personRepository.findAllByPropertyValue("occupation","developer"); EndResult<Person> aTeam = graphRepository.findAllByQuery( "name","A*"); Iterable<Person> friends = personRepository.findFriends(dave);
| Note |
|---|---|
If you use |
Neo4jTemplate has a generic convert method which might also use projection underneath.
The same conversion facilities that are used by default in the result handling DSL are offered here for individual use.
Supported conversions are: Nodes to Paths and to Entities, Relationships to Paths and to Entities, Paths to Node (EndNode), Relationships (LastRelationship) and to EntityPaths. Entities to Nodes or Relationships.
It is also possible to provide a custom ResultConverter that additionally takes care of conversions.
For both queries executed via the result conversion DSL as well as repository methods, it is possible to specify a conversion of complex query results to POJO interfaces or objects. Those result objects are then populated with the query result data and can be serialized and sent to a different part of the applicaton, e.g. a frontend-ui.
Use an interface annotated with @QueryResult and getter methods which might be annotated with
@ResultColumn("columnName") to match the query-result column names. Or use a plain POJO, both work.
Example 20.27. Example of query result mapping
public interface MovieRepository extends GraphRepository<Movie> { @Query("START movie=node:Movie(id={0}) MATCH movie-[rating?:rating]->(), movie<-[:ACTS_IN]-actor RETURN movie, COLLECT(actor), AVG(rating.stars)") MovieData getMovieData(String movieId); @QueryResult public class MovieData { Movie movie; @ResultColumn("AVG(rating.stars)") Double rating; @ResultColumn("COLLECT(actor)") Collection<Actor> cast; } // alternatively use @QueryResult public interface MovieData { @ResultColumn("movie") Movie getMovie(); @ResultColumn("AVG(rating.stars)") Double getRating(); @ResultColumn("COLLECT(actor)") Iterable<Actor> getCast(); } }
As the underlying data model of a graph database doesn't imply and enforce strict type constraints like a relational model does, it offers much more flexibility on how to model your domain classes and which of those to use in different contexts.
For instance an order can be used in these contexts: customer, procurement, logistics, billing, fulfillment and many more. Each of those contexts requires its distinct set of attributes and operations. As Java doesn't support mixins one would put the sum of all of those into the entity class and thereby making it very big, brittle and hard to understand. Being able to take a basic order and project it to a different (not related in the inheritance hierarchy or even an interface) order type that is valid in the current context and only offers the attributes and methods needed here would be very beneficial.
Spring Data Neo4j offers initial support for projecting node and relationship entities to different target types. All instances of this projected entity share the same backing node or relationship, so changes are reflected on the same data.
This could for instance also be used to handle nodes of a traversal with a unified (simpler) type (e.g. for reporting or auditing) and only project them to a concrete, more functional target type when the business logic requires it.
Example 20.28. Projection of entities
@NodeEntity class Trainee { String name; @RelatedTo Set<Training> trainings; } for (Person person : graphRepository.findAllByPropertyValue("occupation","developer")) { Developer developer = person.projectTo(Developer.class); if (developer.isJavaDeveloper()) { trainInSpringData(developer.projectTo(Trainee.class)); } }
SpatialRepository is a dedicated Repository for spatial queries.
Spring Data Neo4j provides an optional dependency to neo4j-spatial which is an advanced library
for GIS operations. So if you include the maven dependency in your pom.xml, Neo4j-Spatial and
the required SPATIAL index provider is available.
Example 20.29. Neo4j-Spatial Dependencies
<dependency>
<groupId>org.neo4j</groupId>
<artifactId>neo4j-spatial</artifactId>
<version>0.7-SNAPSHOT</version>
</dependency>
To have your entities available for spatial index queries, please include a String property containing
a "well known text", location string.
WKT is the Well Known Text Spatial Format
eg. POINT( LON LAT ) or POLYGON (( LON1 LAT1 LON2 LAT2 LON3 LAT3 LON1 LAT1 ))
Example 20.30. Fields of Well Known Text
@NodeEntity class Venue { String name; @Indexed(type = POINT, indexName = "VenueLocation") String wkt; public void setLocation(float lon, float lat) { this.wkt = String.format("POINT( %.2f %.2f )",lon,lat); } } venue.setLocation(56,15);
After adding the SpatialRepository to your repository you can use the
findWithinBoundingBox, findWithinDistance, findWithinWellKnownText.
Example 20.31. Spatial Queries
Iterable<Person> teamMembers = personRepository.findWithinBoundingBox("personLayer", 55, 15, 57, 17); Iterable<Person> teamMembers = personRepository.findWithinWellKnownText("personLayer", "POLYGON ((15 55, 15 57, 17 57, 17 55, 15 55))"); Iterable<Person> teamMembers = personRepository.findWithinDistance("personLayer", 16,56,70);
Example 20.32. Methods of the Spatial Repository
public interface SpatialRepository<T> { ClosableIterable<T> findWithinBoundingBox(String indexName, double lowerLeftLat, double lowerLeftLon, double upperRightLat, double upperRightLon); ClosableIterable<T> findWithinDistance( final String indexName, final double lat, double lon, double distanceKm); ClosableIterable<T> findWithinWellKnownText( final String indexName, String wellKnownText); }
This chapter only applies to the advanced mapping. Currently the Aspects introduce the following methods by default, this will change in the future, there will be separate Mixin-Interfaces that can selectively be mixed into the domain entities if needed. Otherwise the AspectJ interaction will be restricted to field access interception and post-constructor handling.
The node and relationship aspects introduce (via AspectJ ITD - inter-type declaration) several methods to the entities.
- Persisting the node entity after creation and after changes outside of a transaction. Participates in an open transaction, or creates its own implicit transaction otherwise.
nodeEntity.persist()- Accessing node and relationship IDs
nodeEntity.getNodeId()andrelationshipEntity.getRelationshipId()- Accessing the node or relationship backing the entity
entity.getPersistentState()- equals() and hashCode() are delegated to the underlying state
entity.equals()andentity.hashCode()- Creating relationships to a target node entity, and returning the relationship entity instance
nodeEntity.relateTo(targetEntity, relationshipClass, relationshipType)- Retrieving a single relationship entity
nodeEntity.getRelationshipTo(targetEntity, relationshipClass, relationshipType)- Creating relationships to a target node entity and returning the relationship
nodeEntity.relateTo(targetEntity, relationshipType)- Retrieving a single relationship
nodeEntity.getRelationshipTo(targetEnttiy, relationshipType)- Removing a single relationship
nodeEntity.removeRelationshipTo(targetEntity, relationshipType)- Remove the node entity, its relationships, and all index entries for it
nodeEntity.remove()andrelationshipEntity.remove()- Project entity to a different target type, using the same backing state
entity.projectTo(targetClass)- Traverse, starting from the current node. Returns end nodes of traversal converted to the provided type.
nodeEntity.findAllByTraversal(targetType, traversalDescription)-
Traverse, starting from the current node. Returns
EntityPaths of the traversal result bound to the provided start and end-node-entity types Iterable<EntityPath> findAllPathsByTraversal(traversalDescription)- Executes the given Cypher query, providing the
{self}variable with the node-id and returning the results converted to the target type. <T> Iterable<T> NodeBacked.findAllByQuery(final String query, final Class<T> targetType)- Executes the given query, providing
{self}variable with the node-id and returning the original result, but with nodes and relationships replaced by their appropriate entities. Iterable<Map<String,Object>> NodeBacked.findAllByQuery(final String query)- Executes the given query, providing
{self}variable with the node-id and returns a single result converted to the target type. <T> T NodeBacked.findByQuery(final String query, final Class<T> targetType)
Neo4j is a transactional database, only allowing modifications to be performed within transaction
boundaries. Reading data does however not require transactions. Spring Data Neo4j integrates nicely
with both the declarative transaction support with @Transactional as well as the
manual transaction handling with TransactionTemplate. It also supports the rollback
mechanisms of the Spring Testing library.
Spring Data Neo4j integrates with transaction managers configured using Spring. The simplest
scenario of just running the graph database uses a SpringTransactionManager provided by the
Neo4j kernel to be used with Spring's JtaTransactionManager. That is, configuring Spring to
use Neo4j's transaction manager.
| Note |
|---|---|
To avoid name collisons the transaction manager configured by Spring Data Neo4j is called |
| Note |
|---|---|
The explicit XML configuration given below is encoded in the |
Example 20.33. Simple transaction manager configuration
<bean id="neo4jTransactionManager" class="org.springframework.data.neo4j.config.JtaTransactionManagerFactoryBean"> <constructor-arg ref="graphDatabaseService"/> </bean> <tx:annotation-driven mode="aspectj" transaction-manager="neo4jTransactionManager"/>
For scenarios with multiple transactional resources there are two options. The first option is to have Neo4j participate in the externally configured transaction manager using the Spring support in Neo4j by enabling the configuration parameter for your graph database. Neo4j will then use Spring's transaction manager instead of its own.
Example 20.34. Neo4j Spring integration
<context:annotation-config /> <context:spring-configured/> <bean id="transactionManager" class="org.springframework.transaction.jta.JtaTransactionManager"> <property name="transactionManager"> <bean id="jotm" class="org.springframework.data.neo4j.transaction.JotmFactoryBean"/> </property> </bean> <bean id="graphDatabaseService" class="org.neo4j.kernel.EmbeddedGraphDatabase" destroy-method="shutdown"> <constructor-arg value="target/test-db"/> <constructor-arg> <map> <entry key="tx_manager_impl" value="spring-jta"/> </map> </constructor-arg> </bean> <tx:annotation-driven mode="aspectj" transaction-manager="transactionManager"/>
One can also configure a stock XA transaction manager (e.g. Atomikos, JOTM, App-Server-TM) to be
used with Neo4j and the other resources. For a bit less secure but fast 1-phase-commit-best-effort,
use ChainedTransactionManager, which comes bundled with Spring Data Neo4j. It takes a
list of transaction managers as constructor params and will handle them in order for transaction
start and commit (or rollback) in the reverse order.
Example 20.35. ChainedTransactionManager example
<bean id="jpaTransactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"> <property name="entityManagerFactory" ref="entityManagerFactory"/> </bean> <bean id="jtaTransactionManager" class="org.springframework.data.neo4j.config.JtaTransactionManagerFactoryBean"> <constructor-arg ref="graphDatabaseService"/> </bean> <bean id="transactionManager" class="org.springframework.data.neo4j.transaction.ChainedTransactionManager"> <constructor-arg> <list> <ref bean="jpaTransactionManager"/> <ref bean="jtaTransactionManager"/> </list> </constructor-arg> </bean> <tx:annotation-driven mode="aspectj" transaction-manager="transactionManager"/>
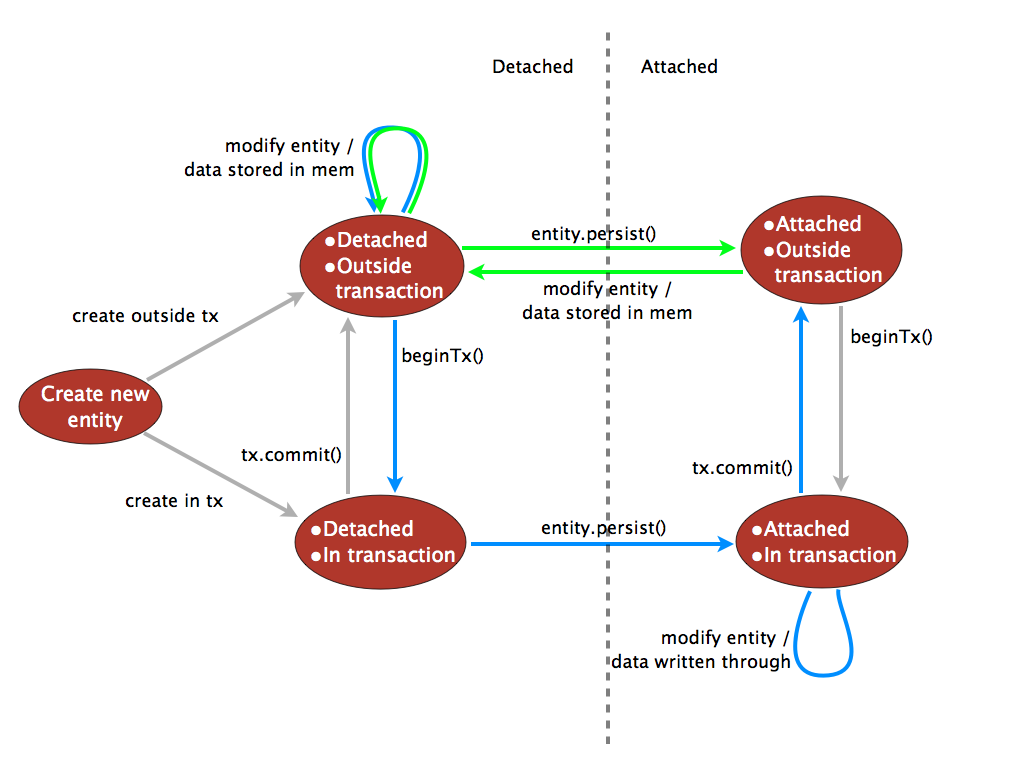
This section only applies to the advanced mapping (AspectJ-backed). The simple mapping always detaches entities on load as it copies the data out of the graph into the entities and stores it back fully too.
Node entities can be in two different persistence states: attached or detached. By default, newly created node
entities are in the detached state. When persist() or template.save() is called on the entity, it becomes
attached to the graph, and its properties and relationships are stores in the database. If
the save operation is not called within a transaction, it automatically creates an implicit
transaction only for the operation.
Changing an attached entity inside a transaction will immediately write through the changes to the datastore. Whenever an entity is changed outside of a transaction it becomes detached. The changes are stored in the entity (its fields) itself until the next call to a save operation.
All entities returned by library functions are initially in an attached state.
Just as with any other entity, changing them outside of a transaction detaches them, and they
must be reattached with persist() for the data to be saved.
Example 20.36. Persisting entities
@NodeEntity class Person { String name; Person(String name) { this.name = name; } } // Store Michael in the database. Person p = new Person("Michael").persist();
As mentioned above, an entity simply created with the new keyword starts out detached.
It also has no state assigned to it. If you create a new entity with new and then throw
it away, the database won't be touched at all.
Now consider this scenario:
Example 20.37. Relationships outside of transactions
@NodeEntity class Movie { private Actor topActor; public void setTopActor(Actor actor) { topActor = actor; } } @NodeEntity class Actor { } Movie movie = new Movie(); Actor actor = new Actor(); movie.setTopActor(actor);
Neither the actor nor the movie has been assigned a node in the graph. If we were to call
movie.persist(), then Spring Data Neo4j would first create a node for the movie.
It would then note that there is a relationship to an actor, so it would call actor.persist()
in a cascading fashion. Once the actor has been persisted, it will create the relationship
from the movie to the actor. All of this will be done atomically in one transaction.
Important to note here is that if actor.persist() is called instead, then only
the actor will be persisted. The reason for this is that the actor entity knows nothing about
the movie entity. It is the movie entity that has the reference to the actor. Also note that
this behavior is not dependent on any configured relationship direction on the annotations.
It is a matter of Java references and is not related to the data model in the database.
The save operation (merge) stores all properties of the entity to the graph database and puts the entity in attached mode. There is no need to update the reference to the Java POJO as the underlying backing node handles the read-through transparently. If multiple object instances that point to the same node are persisted, the ordering is not important as long as they contain distinct changes. For concurrent changes a concurrent modification exception is thrown (subject to be parameterized in the future).
If the relationships form a cycle, then the entities will first of all be assigned a node in
the database, and then the relationships will be created. The cascading of persist()
is however only cascaded to related entity fields that have been modified.
In the following example, the actor and the movie are both attached entites, having both been previously persisted to the graph:
In this case, even though the movie has a reference to the actor, the name change on the actor
will not be persisted by the call to movie.persist(). The reason for this is, as
mentioned above, that cascading will only be done for fields that have been modified. Since the
movie.topActor field has not been modified, it will not cascade the persist operation
to the actor.
There are several ways to represent the Java type hierarchy of the data model in the graph. In general, for all node and relationship entities, type information is needed to perform certain repository operations. Some of this type information hierarchy is saved in the graph database.
As the type information is also stored in node/relationship-properties and/or indexes it might amount to a substantial
amount of data in the graph. It is possible to use an @TypeAlias("name") annotation on nodes and relationships to have a
short constant name for each type which is (unlike the default approach) renaming-refactoring-safe.
For using the simple class name by default, register a Neo4jMappingContext bean configured with an
instance of EntityAlias.
It is also possible to opt out of storing type information using the NoopTypeRepresentationStrategies.
Implementations of TypeRepresentationStrategy take care of persisting this information during entity instance
creation. They also provide the repository methods that use this type information to perform their operations,
like findAll and count. The derived finderMethods also use the type information for graph global queries.
There are three available implementations for node entities to choose from.
IndexingNodeTypeRepresentationStrategythis is the default strategy used.Stores entity types in the integrated index. Each entity node gets indexed with its type and all supertypes and interfaces that are also
@NodeEntity-annotated. The special index used for this is named__types__. Additionally, in order to retrieve the type of an entity node, each node has a property__type__with the fully qualified type of that entity.SubReferenceNodeTypeRepresentationStrategyStores entity types in a tree in the graph representing the type and interface hierarchy. Each entity has a INSTANCE_OF relationship to a type node representing that entity's type. The type may or may not have a SUBCLASS_OF relationship to another type node.
NoopNodeTypeRepresentationStrategyDoes not store any type information, and does hence not support finding by type, counting by type, or retrieving the type of any entity.
There are two implementations for relationship entities available, with the same behavior as the corresponding ones above:
IndexingRelationshipTypeRepresentationStrategyStores relationship entity types in the integrated index. Each entity relationship gets indexed with its type and all supertypes and interfaces that are also
@RelationshipEntity-annotated. The special index used for this is named__rel_types__. Additionally, in order to retrieve the type of an entity relationship, each relationship has a property__type__with the fully qualified type of that entity.NoopRelationshipTypeRepresentationStrategy
Spring Data Neo4j will by default autodetect which are the most suitable strategies for node and relationship
entities. For new data stores, it will always opt for the indexing strategies. If a data store was created
with the olderSubReferenceNodeTypeRepresentationStrategy, then it will continue to use that
strategy for node entities. It will however in that case use the no-op strategy for relationship entities,
which means that the old data stores have no support for searching for relationship entities. The indexing
strategies are recommended for all new users.
Spring Data Neo4j supports property-based validation support. When a property is changed and persisted, it is
checked against the annotated constraints, e.g. @Min, @Max,
@Size, etc. Validation errors throw a ValidationException. The validation
support that comes with Spring is used for evaluating the constraints. To use this feature, a validator
has to be registered with the Neo4jTemplate, which is done automatically by the Neo4jConfiguration
if one is present in the Spring Config.
Example 20.39. Bean validation
@NodeEntity class Person { @Size(min = 3, max = 20) String name; @Min(0) @Max(100) int age; }
The validation supports needs the bean validation API and a reference implementation configured. Right now this is the Hibernate Validator by default (which is not integrated with Hibernate ORM). The maven dependency is:
Example 20.40. Validation setup
<dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-validator</artifactId> <version>4.2.0.Final</version> </dependency> // the application-context should contain a LocalValidatorFactoryBean <bean id="validator" class="org.springframework.validation.beanvalidation.LocalValidatorFactoryBean"/>