This appendix provides more detailed technical documentation about using a Zookeeper with a Spring State Machine.
Introducing a distributed state on top of a single state machine
instance running on a single jvm is a difficult and a complex topic.
Distributed State Machine is introducing a few relatively complex
problems on top of a simple state machine due to its run-to-completion
model and generally because of its single thread execution model,
though orthogonal regions can be executed parallel. One other natural
problem is that a state machine transition execution is driven by triggers
which are either event or timer based.
Distributed Spring State Machine is trying to solve problem of spanning
a generic State Machine through a jvm boundary. Here we show that a generic
State Machine concepts can be used in multiple jvm’s and Spring
Application Contexts.
We found that if Distributed State Machine abstraction is carefully chosen
and backing distributed state repository guarantees CP readiness, it is
possible to create a consistent state machine which is able to share
distributed state among other state machines in an ensemble.
Our results demonstrate that distributed state changes are consistent if backing
repository is CP. We anticipate our distributed state machine to provide
a foundation to applications which need to work with a shared distributed
states. This model aims to provide a good methods for cloud applications
to have much easier ways to communicate with each others without having
a need to explicitly build these distributed state concepts.
Spring State Machine is not forced to use a single threaded execution model because once multiple regions are uses, regions can be executed parallel if necessary configuration is applied. This is an important topic because once user wants to have a parallel state machine execution it will make state changes faster for independent regions.
When state changes are no longer driven by a trigger in a local jvm or local state machine instance, transition logic needs to be controlled externally in an arbitrary persistent storage. This storage needs to have a ways to notify participating state machines when distributed state is changed.
CAP Theorem states that
"it is impossible for a distributed computer system to simultaneously
provide all three of the following guarantees, consistency,
availability and partition tolerance ". What this means is that
whatever is chosen for a backing persistence storage is it advisable
to be CP. In this context CP means consistency and partition
tolerance. Naturally Distributed Spring Statemachine doesn’t care
about what is its CAP level but in reality consistency and
partition tolerance are more important than availability. This is
an exact reason why i.e. Zookeeper is a CP storage.
All tests presented in this article are accomplished by running custom
jepsen tests in a following environment:
- Cluster having nodes n1, n2, n3, n4 and n5.
-
Each node have a
Zookeeperinstance constructing an ensemble with all other nodes. -
Each node have a Chapter 42, Web sample installed
which will connect to a local
Zookeepernode. -
Every state machine instance will only communicate with a local
Zookeeperinstance. While connecting machine to multiple instances is possible, it is not used here. -
All state machine instances when started will create a
StateMachineEnsembleusingZookeeperensemble. -
Sample contains a custom rest api’s which
jepsenwill use to send events and check particular state machine statuses.
All jepsen tests for Spring Distributed Statemachine are available from
Jepsen
Tests.
One design decision of a Distributed State Machine was not to make
individual State Machine instance aware of that it is part of a
distributed ensemble. Because main functions and features of a
StateMachine can be accessed via its interface, it makes sense to
wrap this instance using a DistributedStateMachine, which simply
intercepts all state machine communication and collaborates with an
ensemble to orchestrate distributed state changes.
One other important concept is to be able to persist enough
information from a state machine order to reset a state machine state
from arbitrary state into a new deserialized state. This is naturally
needed when a new state machine instance is joining with an ensemble
and it needs to synchronize its own internal state with a distributed
state. Together with using concepts of distributed states and state
persisting it is possible to create a distributed state machine.
Currently only backing repository of a Distributed State Machine is
implemented using a Zookeeper.
As mentioned in Chapter 29, Using Distributed States distributed states are enabled by
wrapping an instance of a StateMachine within a
DistributedStateMachine. Specific StateMachineEnsemble
implementation is ZookeeperStateMachineEnsemble providing
integration with a Zookeeper.
We wanted to have a generic interface StateMachinePersist which is
able to persist StateMachineContext into an arbitrary storage and
ZookeeperStateMachinePersist is implementing this interface for a
Zookeeper.
While distributed state machine is using one set of serialized
contexts to update its own state, with zookeeper we’re having a
conceptual problem how these context changes can be listened. We’re
able to serialize context into a zookeeper znode and eventually
listen when znode data is modified. However Zookeeper doesn’t
guarantee that you will get notification for every data change
because registered watcher for a znode is disabled once it fires
and user need to re-register that watcher. During this short time
a znode data can be changed thus resulting missing events. It is
actually very easy to miss these events by just changing data from a
multiple threads in a concurrent manner.
Order to overcome this issue we’re keeping individual context changes
in a multiple znodes and we just use a simple integer counter to mark
which znode is a current active one. This allows us to replay missed
events. We don’t want to create more and more znodes and then later
delete old ones, instead we’re using a simple concept of a circular
set of znodes. This allows to use predefined set of znodes where
a current can be determined with a simple integer counter. We already have
this counter by tracking main znode data version which in
Zookeeper is
an integer.
Size of a circular buffer is mandated to be a power of two not to get trouble when integer is going to overflow thus we don’t need to handle any specific cases.
Order to show how a various distributed actions against a state
machine work in a real life, we’re using a set of jepsen tests to
simulate various conditions which may happen in a real distributed
cluster. These include a brain split on a network level, parallel
events with a multiple distributed state machines and changes in
an extended state variables. Jepsen tests are based on a sample
Chapter 42, Web where this sample instance is run on
multiple hosts together with a Zookeeper instance on every node
where state machine is run. Essentially every state machine sample
will connect to local Zookeeper instance which allows use, via
jepsen to simulate network conditions.
Plotted graphs below in this chapter contain states and events which directly maps to a state chart which can be found from Chapter 42, Web.
Sending an isolated single event into exactly one state machine in an ensemble is the most simplest testing scenario and demonstrates that a state change in one state machine is properly propagated into other state machines in an ensemble.
In this test we will demonstrate that a state change in one machine will eventually cause a consistent state change in other machines.
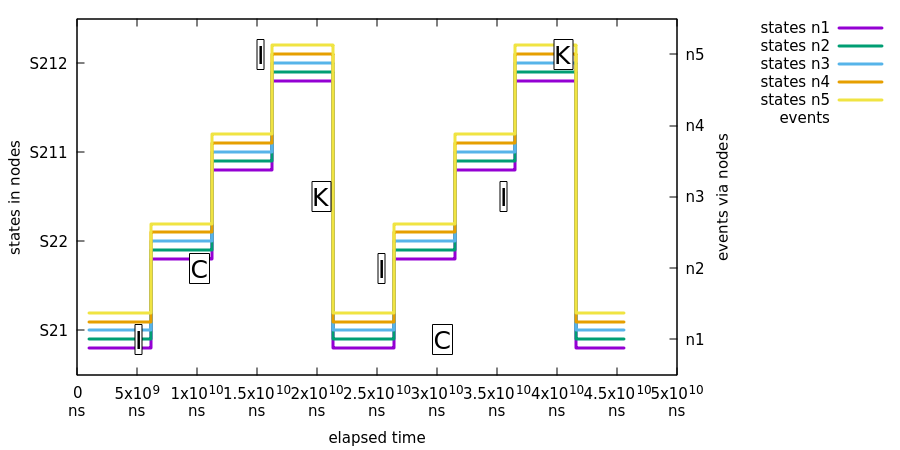
What’s happening in above chart:
-
All machines report state
S21. -
Event
Iis sent to noden1and all nodes report state change fromS21toS22. -
Event
Cis sent to noden2and all nodes report state change fromS22toS211. -
Event
Iis sent to noden5and all nodes report state change fromS211toS212. -
Event
Kis sent to noden3and all nodes report state change fromS212toS21. -
We cycle events
I,C,IandKone more time via random nodes.
Logical problem with multiple distributed state machines is that if a same event is sent into a multiple state machine exactly at a same time, only one of those events will cause a distributed state transitions. This is somewhat expected scenario because a first state machine, for this event, which is able to change a distributed state will control the distributed transition logic. Effectively all other machines receiving this same event will silently discard the event because distributed state is no longer in a state where particular event can be processed.
In this test we will demonstrate that a state change caused by a parallel events throughout an ensemble will eventually cause a consistent state change in all machines.
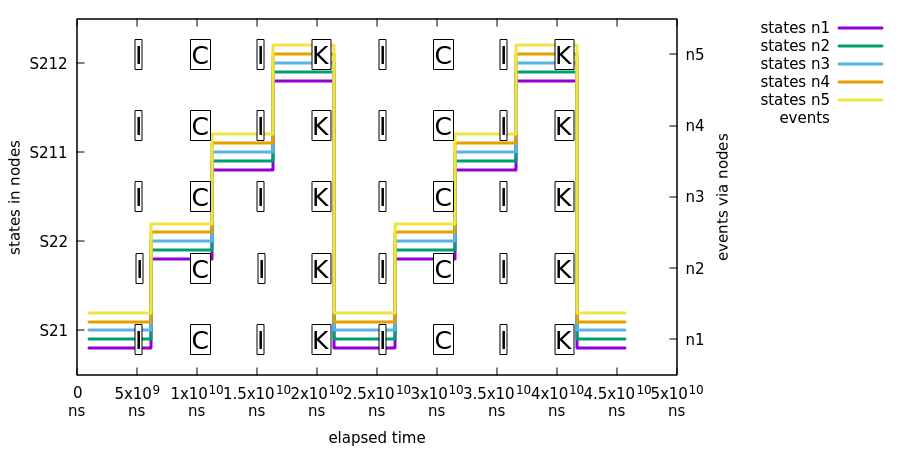
What’s happening in above chart:
- We use exactly same event flow than in previous sample Section C.6.1, “Isolated Events” with a difference that events are always sent to all nodes.
Extended state machine variables are not guaranteed to be atomic at any given time but after a distributed state change, all state machines in an ensemble should have a synchronized extended state.
In this test we will demonstrate that a change in extended state variables in one distributed state machine will eventually be consistent in all distributed state machines.
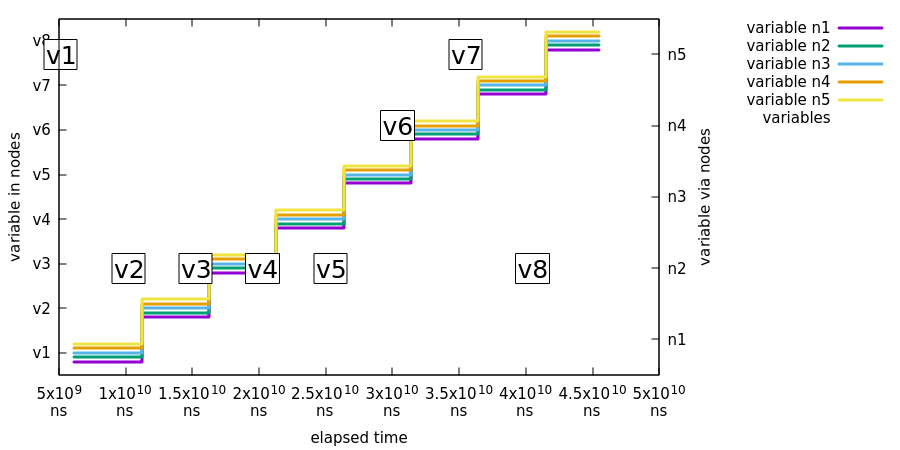
What’s happening in above chart:
-
Event
Jis send to noden5with event variabletestVariablehaving valuev1. All nodes are then reporting having variabletestVariableas valuev1. -
Event
Jis repeated from variablev2tov8doing same checks.
We need to always assume that sooner or later things in a cluster will
go bad whether it is just a crash of a Zookeeper instance, a state
machine or a network problem like a brain split. Brain split is a
situation where existing cluster members are isolated so that only
part of a hosts are able to see each others. Usual scenario is that a
brain split will create a minority and majority partitions of an
ensemble where hosts in a minority cannot participate in an ensemble
anymore until network status has been healed.
In below tests we will demonstrate that various types of brain-split’s in an ensemble will eventually cause fully synchronized state of all distributed state machines.
There are two scenarios having a one straight brain split in a
network where where Zookeeper and Statemachine instances are
split in half, assuming each Statemachine will connect into a
local Zookeeper instance:
- If current zookeeper leader is kept in a majority, all clients connected into majority will keep functioning properly.
- If current zookeeper leader is left in minority, all clients will disconnect from it and will try to connect back till previous minority members has successfully joined back to existing majority ensemble.
![[Note]](images/note.png) | Note |
|---|---|
|
In our current |
| Note |
|---|---|
|
In below plots we have mapped a state machine error state into an
|
In this first test we show that when existing zookeeper leader was kept in majority, 3 out of 5 machines will continue as is.
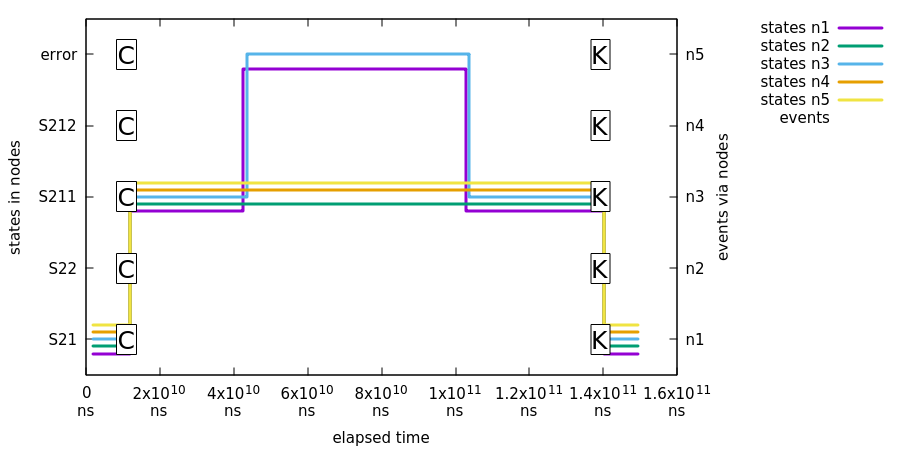
What’s happening in above chart:
-
First event
Cis sent to all machine leading a state change toS211. -
Jepsen nemesis will cause a brain-split which is causing partitions
of
n1/n2/n5andn3/n4. Nodesn3/n4are left in minority and nodesn1/n2/n5construct a new healthy majority. Nodes in majority will keep function without problems but nodes in minority will get into error state. -
Jepsen will heal network and after some time nodes
n3/n4will join back into ensemble and synchronize its distributed status. -
Lastly event
K1is sent to all state machines to ensure that ensemble is working properly. This state change will lead back to stateS21.
In this second test we show that when existing zookeeper leader was kept in minority, all machines will error out:
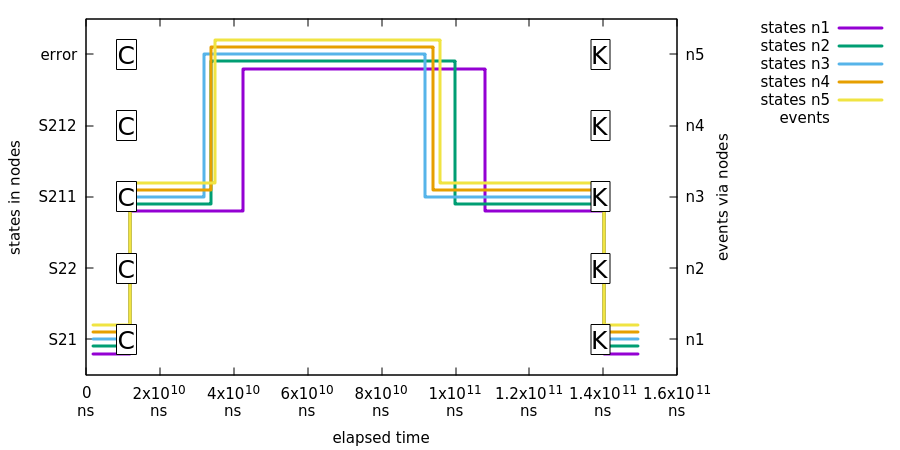
What’s happening in above chart:
-
First event
Cis sent to all machine leading a state change toS211. -
Jepsen nemesis will cause a brain-split which is causing partitions
so that existing
Zookeeperleader is kept in minority and all instances are disconnected from ensemble. - Jepsen will heal network and after some time all nodes will join back into ensemble and synchronize its distributed status.
-
Lastly event
K1is sent to all state machines to ensure that ensemble is working properly. This state change will lead back to stateS21.
In this test we will demonstrate that killing existing state machine and then joining new instance back into an ensemble will keep the distributed state healthy and newly joined state machines will synchronize their states properly.
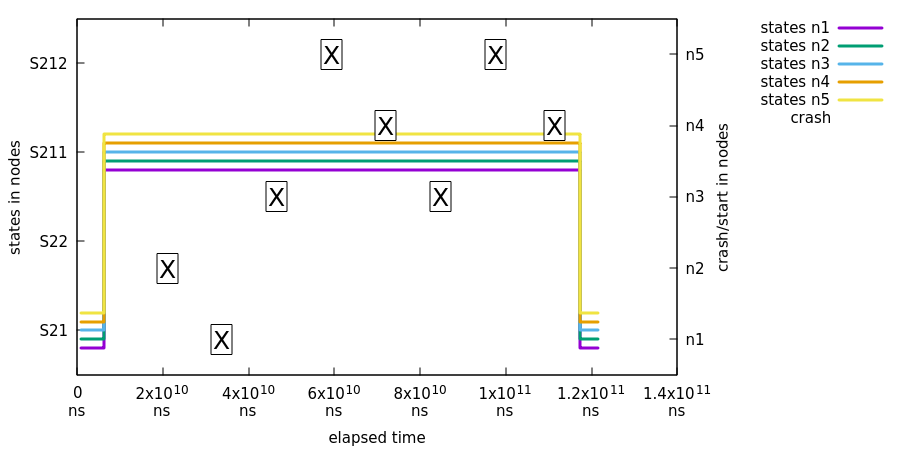
| Note |
|---|---|
|
In this test, states are not checked between first |
What’s happening in above chart:
-
All state machines are transitioned from initial state
S21intoS211so that we can test proper state synchronize during join. -
Xis marking when a specific node has been crashed and started. - At a same time we request states from all machines and plot it.
-
Finally we do a simple transition back to
S21fromS211to make sure that all state machines are still functioning properly.