|
For the latest stable version, please use Spring Data Neo4j 8.0.3! |
Custom queries
Spring Data Neo4j, like all the other Spring Data modules, allows you to specify custom queries in you repositories. Those come in handy if you cannot express the finder logic via derived query functions.
Because Spring Data Neo4j works heavily record-oriented under the hood, it is important to keep this in mind and not build up a result set with multiple records for the same "root node".
| Please have a look in the FAQ as well to learn about alternative forms of using custom queries from repositories, especially how to use custom queries with custom mappings: Custom queries and custom mappings. |
Queries with relationships
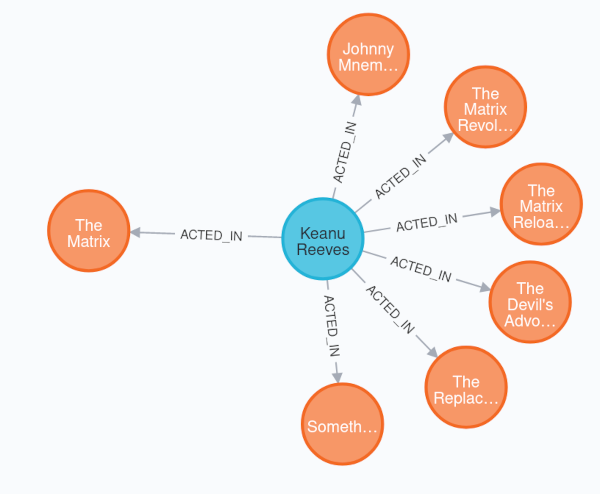
Beware of the cartesian product
Assuming you have a query like MATCH (m:Movie{title: 'The Matrix'})←[r:ACTED_IN]-(p:Person) return m,r,p that results into something like this:
+------------------------------------------------------------------------------------------+
| m | r | p |
+------------------------------------------------------------------------------------------+
| (:Movie) | [:ACTED_IN {roles: ["Emil"]}] | (:Person {name: "Emil Eifrem"}) |
| (:Movie) | [:ACTED_IN {roles: ["Agent Smith"]}] | (:Person {name: "Hugo Weaving}) |
| (:Movie) | [:ACTED_IN {roles: ["Morpheus"]}] | (:Person {name: "Laurence Fishburne"}) |
| (:Movie) | [:ACTED_IN {roles: ["Trinity"]}] | (:Person {name: "Carrie-Anne Moss"}) |
| (:Movie) | [:ACTED_IN {roles: ["Neo"]}] | (:Person {name: "Keanu Reeves"}) |
+------------------------------------------------------------------------------------------+
The result from the mapping would be most likely unusable.
If this would get mapped into a list, it will contain duplicates for the Movie but this movie will only have one relationship.
Getting one record per root node
To get the right object(s) back, it is required to collect the relationships and related nodes in the query: MATCH (m:Movie{title: 'The Matrix'})←[r:ACTED_IN]-(p:Person) return m,collect(r),collect(p)
+------------------------------------------------------------------------+ | m | collect(r) | collect(p) | +------------------------------------------------------------------------+ | (:Movie) | [[:ACTED_IN], [:ACTED_IN], ...]| [(:Person), (:Person),...] | +------------------------------------------------------------------------+
With this result as a single record it is possible for Spring Data Neo4j to add all related nodes correctly to the root node.
Reaching deeper into the graph
The example above assumes that you are only trying to fetch the first level of related nodes. This is sometimes not enough and there are maybe nodes deeper in the graph that should also be part of the mapped instance. There are two ways to achieve this: Database-side or client-side reduction.
For this the example from above should also contain Movies on the Persons that get returned with the initial Movie.
Database-side reduction
Keeping in mind that Spring Data Neo4j can only properly process record based, the result for one entity instance needs to be in one record. Using Cypher’s path capabilities is a valid option to fetch all branches in the graph.
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
RETURN p;This will result in multiple paths that are not merged within one record.
It is possible to call collect(p) but Spring Data Neo4j does not understand the concept of paths in the mapping process.
Thus, nodes and relationships needs to get extracted for the result.
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
RETURN m, nodes(p), relationships(p);Because there are multiple paths that lead from 'The Matrix' to another movie, the result still won’t be a single record. This is where Cypher’s reduce function comes into play.
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
WITH collect(p) as paths, m
WITH m,
reduce(a=[], node in reduce(b=[], c in [aa in paths | nodes(aa)] | b + c) | case when node in a then a else a + node end) as nodes,
reduce(d=[], relationship in reduce(e=[], f in [dd in paths | relationships(dd)] | e + f) | case when relationship in d then d else d + relationship end) as relationships
RETURN m, relationships, nodes;The reduce function allows us to flatten the nodes and relationships from various paths.
As a result we will get a tuple similar to Getting one record per root node but with a mixture of relationship types or nodes in the collections.
Client-side reduction
If the reduction should happen on the client-side, Spring Data Neo4j enables you to map also lists of lists of relationships or nodes. Still, the requirement applies that the returned record should contain all information to hydrate the resulting entity instance correctly.
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
RETURN m, collect(nodes(p)), collect(relationships(p));The additional collect statement creates lists in the format:
[[rel1, rel2], [rel3, rel4]]
Those lists will now get converted during the mapping process into a flat list.
Deciding if you want to go with client-side or database-side reduction depends on the amount of data that will get generated.
All the paths needs to get created in the database’s memory first when the reduce function is used.
On the other hand a large amount of data that needs to get merged on the client-side results in a higher memory usage there.
|
Using paths to populate and return a list of entities
Given are a graph that looks like this:

and a domain model as shown in the mapping (Constructors and accessors have been omitted for brevity):
@Node
public class SomeEntity {
@Id
private final Long number;
private String name;
@Relationship(type = "SOME_RELATION_TO", direction = Relationship.Direction.OUTGOING)
private Set<SomeRelation> someRelationsOut = new HashSet<>();
}
@RelationshipProperties
public class SomeRelation {
@RelationshipId
private Long id;
private String someData;
@TargetNode
private SomeEntity targetPerson;
}As you see, the relationships are only outgoing. Generated finder methods (including findById) will always try to match
a root node to be mapped. From there on onwards, all related objects will be mapped. In queries that should return only one object,
that root object is returned. In queries that return many objects, all matching objects are returned. Out- and incoming relationships
from those objects returned are of course populated.
Assume the following Cypher query:
MATCH p = (leaf:SomeEntity {number: $a})-[:SOME_RELATION_TO*]-(:SomeEntity)
RETURN leaf, collect(nodes(p)), collect(relationships(p))It follows the recommendation from Getting one record per root node and it works great for the leaf node you want to match here. However: That is only the case in all scenarios that return 0 or 1 mapped objects. While that query will populate all relationships like before, it won’t return all 4 objects.
This can be changed by returning the whole path:
MATCH p = (leaf:SomeEntity {number: $a})-[:SOME_RELATION_TO*]-(:SomeEntity)
RETURN pHere we do want to use the fact that the path p actually returns 3 rows with paths to all 4 nodes. All 4 nodes will be
populated, linked together and returned.
Parameters in custom queries
You do this exactly the same way as in a standard Cypher query issued in the Neo4j Browser or the Cypher-Shell,
with the $ syntax (from Neo4j 4.0 on upwards, the old ${foo} syntax for Cypher parameters has been removed from the database).
public interface ARepository extends Neo4jRepository<AnAggregateRoot, String> {
@Query("MATCH (a:AnAggregateRoot {name: $name}) RETURN a") (1)
Optional<AnAggregateRoot> findByCustomQuery(String name);
}| 1 | Here we are referring to the parameter by its name.
You can also use $0 etc. instead. |
You need to compile your Java 8+ project with -parameters to make named parameters work without further annotations.
The Spring Boot Maven and Gradle plugins do this automatically for you.
If this is not feasible for any reason, you can either add
@Param and specify the name explicitly or use the parameters index.
|
Mapped entities (everything with a @Node) passed as parameter to a function that is annotated with
a custom query will be turned into a nested map.
The following example represents the structure as Neo4j parameters.
Given are a Movie, Vertex and Actor classes annotated as shown in the movie model:
@Node
public final class Movie {
@Id
private final String title;
@Property("tagline")
private final String description;
@Relationship(value = "ACTED_IN", direction = Direction.INCOMING)
private final List<Actor> actors;
@Relationship(value = "DIRECTED", direction = Direction.INCOMING)
private final List<Person> directors;
}
@Node
public final class Person {
@Id @GeneratedValue
private final Long id;
private final String name;
private Integer born;
@Relationship("REVIEWED")
private List<Movie> reviewed = new ArrayList<>();
}
@RelationshipProperties
public final class Actor {
@RelationshipId
private final Long id;
@TargetNode
private final Person person;
private final List<String> roles;
}
interface MovieRepository extends Neo4jRepository<Movie, String> {
@Query("MATCH (m:Movie {title: $movie.__id__})\n"
+ "MATCH (m) <- [r:DIRECTED|REVIEWED|ACTED_IN] - (p:Person)\n"
+ "return m, collect(r), collect(p)")
Movie findByMovie(@Param("movie") Movie movie);
}Passing an instance of Movie to the repository method above, will generate the following Neo4j map parameter:
{
"movie": {
"__labels__": [
"Movie"
],
"__id__": "The Da Vinci Code",
"__properties__": {
"ACTED_IN": [
{
"__properties__": {
"roles": [
"Sophie Neveu"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 402,
"__properties__": {
"name": "Audrey Tautou",
"born": 1976
}
}
},
{
"__properties__": {
"roles": [
"Sir Leight Teabing"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 401,
"__properties__": {
"name": "Ian McKellen",
"born": 1939
}
}
},
{
"__properties__": {
"roles": [
"Dr. Robert Langdon"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 360,
"__properties__": {
"name": "Tom Hanks",
"born": 1956
}
}
},
{
"__properties__": {
"roles": [
"Silas"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 403,
"__properties__": {
"name": "Paul Bettany",
"born": 1971
}
}
}
],
"DIRECTED": [
{
"__labels__": [
"Person"
],
"__id__": 404,
"__properties__": {
"name": "Ron Howard",
"born": 1954
}
}
],
"tagline": "Break The Codes",
"released": 2006
}
}
}A node is represented by a map. The map will always contain id which is the mapped id property.
Under labels all labels, static and dynamic, will be available.
All properties - and type of relationships - appear in those maps as they would appear in the graph when the entity would
have been written by SDN.
Values will have the correct Cypher type and won’t need further conversion.
All relationships are lists of maps. Dynamic relationships will be resolved accordingly.
One-to-one relationships will also be serialized as singleton lists. So to access a one-to-one mapping
between people, you would write this das $person.__properties__.BEST_FRIEND[0].__target__.__id__.
|
If an entity has a relationship with the same type to different types of others nodes, they will all appear in the same list. If you need such a mapping and also have the need to work with those custom parameters, you have to unroll it accordingly. One way to do this are correlated subqueries (Neo4j 4.1+ required).
Spring Expression Language in custom queries
Spring Expression Language (SpEL) can be used in custom queries inside :#{}.
The colon here refers to a parameter and such an expression should be used where parameters make sense.
However, when using our literal extension you can use SpEL expression in places where standard Cypher
won’t allow parameters (such as for labels or relationship types).
This is the standard Spring Data way of defining a block of text inside a query that undergoes SpEL evaluation.
The following example basically defines the same query as above, but uses a WHERE clause to avoid even more curly braces:
public interface ARepository extends Neo4jRepository<AnAggregateRoot, String> {
@Query("MATCH (a:AnAggregateRoot) WHERE a.name = :#{#pt1 + #pt2} RETURN a")
Optional<AnAggregateRoot> findByCustomQueryWithSpEL(String pt1, String pt2);
}The SpEL blocked starts with :#{ and then refers to the given String parameters by name (#pt1).
Don’t confuse this with the above Cypher syntax!
The SpEL expression concatenates both parameters into one single value that is eventually passed on to the appendix/neo4j-client.adoc#neo4j-client.
The SpEL block ends with }.
SpEL also solves two additional problems. We provide two extensions that allow to pass in a Sort object into custom queries.
Remember faq.adoc#custom-queries-with-page-and-slice-examples from custom queries?
With the orderBy extension you can pass in a Pageable with a dynamic sort to a custom query:
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
public interface MyPersonRepository extends Neo4jRepository<Person, Long> {
@Query(""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n "
+ ":#{orderBy(#pageable)} SKIP $skip LIMIT $limit" (1)
)
Slice<Person> findSliceByName(String name, Pageable pageable);
@Query(""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n :#{orderBy(#sort)}" (2)
)
List<Person> findAllByName(String name, Sort sort);
}| 1 | A Pageable has always the name pageable inside the SpEL context. |
| 2 | A Sort has always the name sort inside the SpEL context. |
Spring Expression Language extensions
Literal extension
The literal extension can be used to make things like labels or relationship-types "dynamic" in custom queries.
Neither labels nor relationship types can be parameterized in Cypher, so they must be given literal.
interface BaseClassRepository extends Neo4jRepository<Inheritance.BaseClass, Long> {
@Query("MATCH (n:`:#{literal(#label)}`) RETURN n") (1)
List<Inheritance.BaseClass> findByLabel(String label);
}| 1 | The literal extension will be replaced with the literal value of the evaluated parameter. |
Here, the literal value has been used to match dynamically on a Label.
If you pass in SomeLabel as a parameter to the method, MATCH (n:
will be generated. Ticks have been added to correctly escape values. SDN won’t do this
for you as this is probably not what you want in all cases.SomeLabel) RETURN n
List extensions
For more than one value there are allOf and anyOf in place that would render
either a & or | concatenated list of all values.
interface BaseClassRepository extends Neo4jRepository<Inheritance.BaseClass, Long> {
@Query("MATCH (n:`:#{allOf(#label)}`) RETURN n")
List<Inheritance.BaseClass> findByLabels(List<String> labels);
@Query("MATCH (n:`:#{anyOf(#label)}`) RETURN n")
List<Inheritance.BaseClass> findByLabels(List<String> labels);
}Referring to Labels
You already know how to map a Node to a domain object:
@Node(primaryLabel = "Bike", labels = {"Gravel", "Easy Trail"})
public class BikeNode {
@Id String id;
String name;
}This node has a couple of labels, and it would be rather error prone to repeat them all the time in custom queries: You might
forget one or make a typo. We offer the following expression to mitigate this: #{#staticLabels}. Notice that this one does
not start with a colon! You use it on repository methods annotated with @Query:
#{#staticLabels} in actionpublic interface BikeRepository extends Neo4jRepository<Bike, String> {
@Query("MATCH (n:#{#staticLabels}) WHERE n.id = $nameOrId OR n.name = $nameOrId RETURN n")
Optional<Bike> findByNameOrId(@Param("nameOrId") String nameOrId);
}This query will resolve to
MATCH (n:`Bike`:`Gravel`:`Easy Trail`) WHERE n.id = $nameOrId OR n.name = $nameOrId RETURN nNotice how we used standard parameter for the nameOrId: In most cases there is no need to complicate things here by
adding a SpEL expression.

