|
This version is still in development and is not considered stable yet. For the latest stable version, please use Spring Data Neo4j 8.0.5! |
FAQ
How does SDN relate to Neo4j-OGM?
Neo4j-OGM is an Object Graph Mapping library, which is mainly used by previous versions of Spring Data Neo4j as its backend for the heavy lifting of mapping nodes and relationships into domain object. The current SDN does not need and does not support Neo4j-OGM. SDN uses Spring Data’s mapping context exclusively for scanning classes and building the meta model.
While this pins SDN to the Spring ecosystem, it has several advantages, among them the smaller footprint regarding CPU and memory usage and especially, all the features of Spring’s mapping context.
Why should I use SDN in favor of SDN+OGM
SDN has several features not present in SDN+OGM, notably
-
Full support for Springs reactive story, including reactive transaction
-
Full support for Query By Example
-
Full support for fully immutable entities
-
Support for all modifiers and variations of derived finder methods, including spatial queries
Does SDN support embedded Neo4j?
Embedded Neo4j has multiple facets to it:
Does SDN interact directly with an embedded instance?
No.
An embedded database is usually represented by an instance of org.neo4j.graphdb.GraphDatabaseService and has no Bolt connector out of the box.
SDN can however work very much with Neo4j’s test harness, the test harness is specially meant to be a drop-in replacement for the real database.
Support for Neo4j 3.5, 4.x and 5.x test harness is implemented via the Spring Boot starter for the driver.
Have a look at the corresponding module org.neo4j.driver:neo4j-java-driver-test-harness-spring-boot-autoconfigure.
Which Neo4j Java Driver can be used and how?
SDN relies on the Neo4j Java Driver. Each SDN release uses a Neo4j Java Driver version compatible with the latest Neo4j available at the time of its release. While patch versions of the Neo4j Java Driver are usually drop-in replacements, SDN makes sure that even minor versions are interchangeable as it checks for the presence or absence of methods or interface changes if necessary.
Therefore, you are able to use any 4.x Neo4j Java Driver with any SDN 6.x version, and any 5.x Neo4j Driver with any SDN 7.x version.
With Spring Boot
These days, a Spring boot deployment is the most likely deployment of a Spring Data based applications. Please use Spring Boots dependency management to change the driver version like this:
<properties>
<neo4j-java-driver.version>5.4.0</neo4j-java-driver.version>
</properties>Or
neo4j-java-driver.version = 5.4.0Without Spring Boot
Without Spring Boot, you would just manually declare the dependency. For Maven, we recommend using the <dependencyManagement />
section like this:
<dependencyManagement>
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>5.4.0</version>
</dependency>
</dependencyManagement>
Neo4j 4 supports multiple databases - How can I use them?
You can either statically configure the database name or run your own database name provider. Bear in mind that SDN will not create the databases for you. You can do this with the help of a migrations tool or of course with a simple script upfront.
Statically configured
Configure the database name to use in your Spring Boot configuration like this (the same property applies of course for YML or environment based configuration, with Spring Boot’s conventions applied):
spring.data.neo4j.database = yourDatabaseWith that configuration in place, all queries generated by all instances of SDN repositories (both reactive and imperative) and by the ReactiveNeo4jTemplate respectively Neo4jTemplate will be executed against the database yourDatabase.
Dynamically configured
Provide a bean with the type Neo4jDatabaseNameProvider or ReactiveDatabaseSelectionProvider depending on the type of your Spring application.
That bean could use for example Spring’s security context to retrieve a tenant. Here is a working example for an imperative application secured with Spring Security:
import org.neo4j.springframework.data.core.DatabaseSelection;
import org.neo4j.springframework.data.core.DatabaseSelectionProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.core.Authentication;
import org.springframework.security.core.context.SecurityContext;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.security.core.userdetails.User;
@Configuration
public class Neo4jConfig {
@Bean
DatabaseSelectionProvider databaseSelectionProvider() {
return () -> Optional.ofNullable(SecurityContextHolder.getContext())
.map(SecurityContext::getAuthentication)
.filter(Authentication::isAuthenticated)
.map(Authentication::getPrincipal)
.map(User.class::cast)
.map(User::getUsername)
.map(DatabaseSelection::byName)
.orElseGet(DatabaseSelection::undecided);
}
}| Be careful that you don’t mix up entities retrieved from one database with another database. The database name is requested for each new transaction, so you might end up with less or more entities than expected when changing the database name in between calls. Or worse, you could inevitably store the wrong entities in the wrong database. |
The Spring Boot Neo4j health indicator targets the default database, how can I change that?
Spring Boot comes with both imperative and reactive Neo4j health indicators.
Both variants are able to detect multiple beans of org.neo4j.driver.Driver inside the application context and provide
a contribution to the overall health for each instance.
The Neo4j driver however does connect to a server and not to a specific database inside that server.
Spring Boot is able to configure the driver without Spring Data Neo4j and as the information which database is to be used
is tied to Spring Data Neo4j, this information is not available to the built-in health indicator.
This is most likely not a problem in many deployment scenarios. However, if configured database user does not have at least access rights to the default database, the health checks will fail.
This can be mitigated by custom Neo4j health contributors that are aware of the database selection.
Imperative variant
import java.util.Optional;
import org.neo4j.driver.Driver;
import org.neo4j.driver.Result;
import org.neo4j.driver.SessionConfig;
import org.neo4j.driver.summary.DatabaseInfo;
import org.neo4j.driver.summary.ResultSummary;
import org.neo4j.driver.summary.ServerInfo;
import org.springframework.boot.actuate.health.AbstractHealthIndicator;
import org.springframework.boot.actuate.health.Health;
import org.springframework.data.neo4j.core.DatabaseSelection;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.util.StringUtils;
public class DatabaseSelectionAwareNeo4jHealthIndicator extends AbstractHealthIndicator {
private final Driver driver;
private final DatabaseSelectionProvider databaseSelectionProvider;
public DatabaseSelectionAwareNeo4jHealthIndicator(
Driver driver, DatabaseSelectionProvider databaseSelectionProvider
) {
this.driver = driver;
this.databaseSelectionProvider = databaseSelectionProvider;
}
@Override
protected void doHealthCheck(Health.Builder builder) {
try {
SessionConfig sessionConfig = Optional
.ofNullable(databaseSelectionProvider.getDatabaseSelection())
.filter(databaseSelection -> databaseSelection != DatabaseSelection.undecided())
.map(DatabaseSelection::getValue)
.map(v -> SessionConfig.builder().withDatabase(v).build())
.orElseGet(SessionConfig::defaultConfig);
class Tuple {
String edition;
ResultSummary resultSummary;
Tuple(String edition, ResultSummary resultSummary) {
this.edition = edition;
this.resultSummary = resultSummary;
}
}
String query =
"CALL dbms.components() YIELD name, edition WHERE name = 'Neo4j Kernel' RETURN edition";
Tuple health = driver.session(sessionConfig)
.writeTransaction(tx -> {
Result result = tx.run(query);
String edition = result.single().get("edition").asString();
return new Tuple(edition, result.consume());
});
addHealthDetails(builder, health.edition, health.resultSummary);
} catch (Exception ex) {
builder.down().withException(ex);
}
}
static void addHealthDetails(Health.Builder builder, String edition, ResultSummary resultSummary) {
ServerInfo serverInfo = resultSummary.server();
builder.up()
.withDetail(
"server", serverInfo.version() + "@" + serverInfo.address())
.withDetail("edition", edition);
DatabaseInfo databaseInfo = resultSummary.database();
if (StringUtils.hasText(databaseInfo.name())) {
builder.withDetail("database", databaseInfo.name());
}
}
}This uses the available database selection to run the same query that Boot runs to check whether a connection is healthy or not. Use the following configuration to apply it:
import java.util.Map;
import org.neo4j.driver.Driver;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.boot.actuate.health.CompositeHealthContributor;
import org.springframework.boot.actuate.health.HealthContributor;
import org.springframework.boot.actuate.health.HealthContributorRegistry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
@Configuration(proxyBeanMethods = false)
public class Neo4jHealthConfig {
@Bean (1)
DatabaseSelectionAwareNeo4jHealthIndicator databaseSelectionAwareNeo4jHealthIndicator(
Driver driver, DatabaseSelectionProvider databaseSelectionProvider
) {
return new DatabaseSelectionAwareNeo4jHealthIndicator(driver, databaseSelectionProvider);
}
@Bean (2)
HealthContributor neo4jHealthIndicator(
Map<String, DatabaseSelectionAwareNeo4jHealthIndicator> customNeo4jHealthIndicators) {
return CompositeHealthContributor.fromMap(customNeo4jHealthIndicators);
}
@Bean (3)
InitializingBean healthContributorRegistryCleaner(
HealthContributorRegistry healthContributorRegistry,
Map<String, DatabaseSelectionAwareNeo4jHealthIndicator> customNeo4jHealthIndicators
) {
return () -> customNeo4jHealthIndicators.keySet()
.stream()
.map(HealthContributorNameFactory.INSTANCE)
.forEach(healthContributorRegistry::unregisterContributor);
}
}| 1 | If you have multiple drivers and database selection providers, you would need to create one indicator per combination |
| 2 | This makes sure that all of those indicators are grouped under Neo4j, replacing the default Neo4j health indicator |
| 3 | This prevents the individual contributors showing up in the health endpoint directly |
Reactive variant
The reactive variant is basically the same, using reactive types and the corresponding reactive infrastructure classes:
import reactor.core.publisher.Mono;
import reactor.util.function.Tuple2;
import org.neo4j.driver.Driver;
import org.neo4j.driver.SessionConfig;
import org.neo4j.driver.reactivestreams.RxResult;
import org.neo4j.driver.reactivestreams.RxSession;
import org.neo4j.driver.summary.DatabaseInfo;
import org.neo4j.driver.summary.ResultSummary;
import org.neo4j.driver.summary.ServerInfo;
import org.reactivestreams.Publisher;
import org.springframework.boot.actuate.health.AbstractReactiveHealthIndicator;
import org.springframework.boot.actuate.health.Health;
import org.springframework.data.neo4j.core.DatabaseSelection;
import org.springframework.data.neo4j.core.ReactiveDatabaseSelectionProvider;
import org.springframework.util.StringUtils;
public final class DatabaseSelectionAwareNeo4jReactiveHealthIndicator
extends AbstractReactiveHealthIndicator {
private final Driver driver;
private final ReactiveDatabaseSelectionProvider databaseSelectionProvider;
public DatabaseSelectionAwareNeo4jReactiveHealthIndicator(
Driver driver,
ReactiveDatabaseSelectionProvider databaseSelectionProvider
) {
this.driver = driver;
this.databaseSelectionProvider = databaseSelectionProvider;
}
@Override
protected Mono<Health> doHealthCheck(Health.Builder builder) {
String query =
"CALL dbms.components() YIELD name, edition WHERE name = 'Neo4j Kernel' RETURN edition";
return databaseSelectionProvider.getDatabaseSelection()
.map(databaseSelection -> databaseSelection == DatabaseSelection.undecided() ?
SessionConfig.defaultConfig() :
SessionConfig.builder().withDatabase(databaseSelection.getValue()).build()
)
.flatMap(sessionConfig ->
Mono.usingWhen(
Mono.fromSupplier(() -> driver.rxSession(sessionConfig)),
s -> {
Publisher<Tuple2<String, ResultSummary>> f = s.readTransaction(tx -> {
RxResult result = tx.run(query);
return Mono.from(result.records())
.map((record) -> record.get("edition").asString())
.zipWhen((edition) -> Mono.from(result.consume()));
});
return Mono.fromDirect(f);
},
RxSession::close
)
).map((result) -> {
addHealthDetails(builder, result.getT1(), result.getT2());
return builder.build();
});
}
static void addHealthDetails(Health.Builder builder, String edition, ResultSummary resultSummary) {
ServerInfo serverInfo = resultSummary.server();
builder.up()
.withDetail(
"server", serverInfo.version() + "@" + serverInfo.address())
.withDetail("edition", edition);
DatabaseInfo databaseInfo = resultSummary.database();
if (StringUtils.hasText(databaseInfo.name())) {
builder.withDetail("database", databaseInfo.name());
}
}
}And of course, the reactive variant of the configuration. It needs two different registry cleaners, as Spring Boot will wrap existing reactive indicators to be used with the non-reactive actuator endpoint, too.
import java.util.Map;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.boot.actuate.health.CompositeReactiveHealthContributor;
import org.springframework.boot.actuate.health.HealthContributorNameFactory;
import org.springframework.boot.actuate.health.HealthContributorRegistry;
import org.springframework.boot.actuate.health.ReactiveHealthContributor;
import org.springframework.boot.actuate.health.ReactiveHealthContributorRegistry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration(proxyBeanMethods = false)
public class Neo4jHealthConfig {
@Bean
ReactiveHealthContributor neo4jHealthIndicator(
Map<String, DatabaseSelectionAwareNeo4jReactiveHealthIndicator> customNeo4jHealthIndicators) {
return CompositeReactiveHealthContributor.fromMap(customNeo4jHealthIndicators);
}
@Bean
InitializingBean healthContributorRegistryCleaner(HealthContributorRegistry healthContributorRegistry,
Map<String, DatabaseSelectionAwareNeo4jReactiveHealthIndicator> customNeo4jHealthIndicators) {
return () -> customNeo4jHealthIndicators.keySet()
.stream()
.map(HealthContributorNameFactory.INSTANCE)
.forEach(healthContributorRegistry::unregisterContributor);
}
@Bean
InitializingBean reactiveHealthContributorRegistryCleaner(
ReactiveHealthContributorRegistry healthContributorRegistry,
Map<String, DatabaseSelectionAwareNeo4jReactiveHealthIndicator> customNeo4jHealthIndicators) {
return () -> customNeo4jHealthIndicators.keySet()
.stream()
.map(HealthContributorNameFactory.INSTANCE)
.forEach(healthContributorRegistry::unregisterContributor);
}
}Neo4j 4.4+ supports impersonation of different users - How can I use them?
User impersonation is especially interesting in big multi-tenant settings, in which one physically connected (or technical) user can impersonate many tenants. Depending on your setup this will drastically reduce the number of physical driver instances needed.
The feature requires Neo4j Enterprise 4.4+ on the server side and a 4.4+ driver on the client side (org.neo4j.driver:neo4j-java-driver:4.4.0 or higher).
For both imperative and reactive versions you need to provide a UserSelectionProvider respectively a ReactiveUserSelectionProvider.
The same instance needs to be passed along to the Neo4Client and Neo4jTransactionManager respectively their reactive variants.
In Bootless imperative and reactive configurations you just need to provide a bean of the type in question:
import org.springframework.data.neo4j.core.UserSelection;
import org.springframework.data.neo4j.core.UserSelectionProvider;
public class CustomConfig {
@Bean
public UserSelectionProvider getUserSelectionProvider() {
return () -> UserSelection.impersonate("someUser");
}
}In a typical Spring Boot scenario this feature requires a bit more work, as Boot supports also SDN versions without that feature. So given the bean in User selection provider bean you would need fully customize the client and transaction manager:
import org.neo4j.driver.Driver;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.data.neo4j.core.Neo4jClient;
import org.springframework.data.neo4j.core.UserSelectionProvider;
import org.springframework.data.neo4j.core.transaction.Neo4jTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
public class CustomConfig {
@Bean
public Neo4jClient neo4jClient(
Driver driver,
DatabaseSelectionProvider databaseSelectionProvider,
UserSelectionProvider userSelectionProvider
) {
return Neo4jClient.with(driver)
.withDatabaseSelectionProvider(databaseSelectionProvider)
.withUserSelectionProvider(userSelectionProvider)
.build();
}
@Bean
public PlatformTransactionManager transactionManager(
Driver driver,
DatabaseSelectionProvider databaseSelectionProvider,
UserSelectionProvider userSelectionProvider
) {
return Neo4jTransactionManager
.with(driver)
.withDatabaseSelectionProvider(databaseSelectionProvider)
.withUserSelectionProvider(userSelectionProvider)
.build();
}
}Using a Neo4j cluster instance from Spring Data Neo4j
The following questions apply to Neo4j AuraDB as well as to Neo4j on-premise cluster instances.
Do I need specific configuration so that transactions work seamless with a Neo4j Causal Cluster?
No, you don’t. SDN uses Neo4j Causal Cluster bookmarks internally without any configuration on your side required. Transactions in the same thread or the same reactive stream following each other will be able to read their previously changed values as you would expect.
Is it important to use read-only transactions for Neo4j cluster?
Yes, it is. The Neo4j cluster architecture is a causal clustering architecture, and it distinguishes between primary and secondary servers. Primary server either are single instances or core instances. Both of them can answer to read and write operations. Write operations are propagated from the core instances to read replicas or more generally, followers, inside the cluster. Those followers are secondary servers. Secondary servers don’t answer to write operations.
In a standard deployment scenario you’ll have some core instances and many read replicas inside a cluster. Therefore, it is important to mark operations or queries as read-only to scale your cluster in such a way that leaders are never overwhelmed and queries are propagated as much as possible to read replicas.
Neither Spring Data Neo4j nor the underlying Java driver do Cypher parsing and both building blocks assume write operations by default. This decision has been made to support all operations out of the box. If something in the stack would assume read-only by default, the stack might end up sending write queries to read replicas and fail on executing them.
All findById, findAllById, findAll and predefined existential methods are marked as read-only by default.
|
Some options are described below:
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.transaction.annotation.Transactional;
@Transactional(readOnly = true)
interface PersonRepository extends Neo4jRepository<Person, Long> {
}import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
import org.springframework.transaction.annotation.Transactional;
interface PersonRepository extends Neo4jRepository<Person, Long> {
@Transactional(readOnly = true)
Person findOneByName(String name); (1)
@Transactional(readOnly = true)
@Query("""
CALL apoc.search.nodeAll('{Person: "name",Movie: ["title","tagline"]}','contains','her')
YIELD node AS n RETURN n""")
Person findByCustomQuery(); (2)
}| 1 | Why isn’t this read-only be default? While it would work for the derived finder above (which we actually know to be read-only),
we often have seen cases in which user add a custom @Query and implement it via a MERGE construct,
which of course is a write operation. |
| 2 | Custom procedures can do all kinds of things, there’s no way at the moment to check for read-only vs write here for us. |
import java.util.Optional;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.transaction.annotation.Transactional;
interface PersonRepository extends Neo4jRepository<Person, Long> {
}
interface MovieRepository extends Neo4jRepository<Movie, Long> {
List<Movie> findByLikedByPersonName(String name);
}
public class PersonService {
private final PersonRepository personRepository;
private final MovieRepository movieRepository;
public PersonService(PersonRepository personRepository,
MovieRepository movieRepository) {
this.personRepository = personRepository;
this.movieRepository = movieRepository;
}
@Transactional(readOnly = true)
public Optional<PersonDetails> getPerson(Long id) { (1)
return this.repository.findById(id)
.map(person -> {
var movies = this.movieRepository
.findByLikedByPersonName(person.getName());
return new PersonDetails(person, movies);
});
}
}| 1 | Here, several calls to multiple repositories are wrapped in one single, read-only transaction. |
TransactionTemplate inside private service methods and / or with the Neo4j clientimport java.util.Collection;
import org.neo4j.driver.types.Node;
import org.springframework.data.neo4j.core.Neo4jClient;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.support.TransactionTemplate;
public class PersonService {
private final TransactionTemplate readOnlyTx;
private final Neo4jClient neo4jClient;
public PersonService(PlatformTransactionManager transactionManager, Neo4jClient neo4jClient) {
this.readOnlyTx = new TransactionTemplate(transactionManager, (1)
new TransactionDefinition() {
@Override public boolean isReadOnly() {
return true;
}
}
);
this.neo4jClient = neo4jClient;
}
void internalOperation() { (2)
Collection<Node> nodes = this.readOnlyTx.execute(state -> {
return neo4jClient.query("MATCH (n) RETURN n").fetchAs(Node.class) (3)
.mappedBy((types, record) -> record.get(0).asNode())
.all();
});
}
}| 1 | Create an instance of the TransactionTemplate with the characteristics you need.
Of course, this can be a global bean, too. |
| 2 | Reason number one for using the transaction template: Declarative transactions don’t work
in package private or private methods and also not in inner method calls (imagine another method
in this service calling internalOperation) due to their nature being implemented with Aspects
and proxies. |
| 3 | The Neo4jClient is a fixed utility provided by SDN. It cannot be annotated, but it integrates with Spring.
So it gives you everything you would do with the pure driver and without automatic mapping and with
transactions. It also obeys declarative transactions. |
Can I retrieve the latest Bookmarks or seed the transaction manager?
As mentioned briefly in Bookmark Management, there is no need to configure anything with regard to bookmarks.
It may however be useful to retrieve the latest bookmark the SDN transaction system received from a database.
You can add a @Bean like BookmarkCapture to do this:
import java.util.Set;
import org.neo4j.driver.Bookmark;
import org.springframework.context.ApplicationListener;
public final class BookmarkCapture
implements ApplicationListener<Neo4jBookmarksUpdatedEvent> {
@Override
public void onApplicationEvent(Neo4jBookmarksUpdatedEvent event) {
// We make sure that this event is called only once,
// the thread safe application of those bookmarks is up to your system.
Set<Bookmark> latestBookmarks = event.getBookmarks();
}
}For seeding the transaction system, a customized transaction manager like the following is required:
import java.util.Set;
import java.util.function.Supplier;
import org.neo4j.driver.Bookmark;
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.data.neo4j.core.transaction.Neo4jBookmarkManager;
import org.springframework.data.neo4j.core.transaction.Neo4jTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
public class BookmarkSeedingConfig {
@Bean
public PlatformTransactionManager transactionManager(
Driver driver, DatabaseSelectionProvider databaseNameProvider) { (1)
Supplier<Set<Bookmark>> bookmarkSupplier = () -> { (2)
Bookmark a = null;
Bookmark b = null;
return Set.of(a, b);
};
Neo4jBookmarkManager bookmarkManager =
Neo4jBookmarkManager.create(bookmarkSupplier); (3)
return new Neo4jTransactionManager(
driver, databaseNameProvider, bookmarkManager); (4)
}
}| 1 | Let Spring inject those |
| 2 | This supplier can be anything that holds the latest bookmarks you want to bring into the system |
| 3 | Create the bookmark manager with it |
| 4 | Pass it on to the customized transaction manager |
| There is no need to do any of these things above, unless your application has the need to access or provide this data. If in doubt, don’t do either. |
Can I disable bookmark management?
We provide a Noop bookmark manager that effectively disables bookmark management.
| Use this bookmark manager at your own risk, it will effectively disable any bookmark management by dropping all bookmarks and never supplying any. In a cluster you will be at a high risk of experiencing stale reads. In a single instance it will most likely not make any difference. |
+ In a cluster this can be a sensible approach only and if only you can tolerate stale reads and are not in danger of overwriting old data.
The following configuration creates a "noop" variant of the bookmark manager that will be picked up from relevant classes.
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.transaction.Neo4jBookmarkManager;
@Configuration
public class BookmarksDisabledConfig {
@Bean
public Neo4jBookmarkManager neo4jBookmarkManager() {
return Neo4jBookmarkManager.noop();
}
}You can configure the pairs of Neo4jTransactionManager/Neo4jClient and ReactiveNeo4jTransactionManager/ReactiveNeo4jClient individually, but we recommend in doing so only when you already configuring them for specific database selection needs.
Do I need to use Neo4j specific annotations?
No. You are free to use the following, equivalent Spring Data annotations:
| SDN specific annotation | Spring Data common annotation | Purpose | Difference |
|---|---|---|---|
|
|
Marks the annotated attribute as the unique id. |
Specific annotation has no additional features. |
|
|
Marks the class as persistent entity. |
|
How do I use assigned ids?
Just use @Id without @GeneratedValue and fill your id attribute via a constructor parameter or a setter or wither.
See this blog post for some general remarks about finding good ids.
How do I use externally generated ids?
We provide the interface org.springframework.data.neo4j.core.schema.IdGenerator.
Implement it in any way you want and configure your implementation like this:
@Node
public class ThingWithGeneratedId {
@Id @GeneratedValue(TestSequenceGenerator.class)
private String theId;
}If you pass in the name of a class to @GeneratedValue, this class must have a no-args default constructor.
You can however use a string as well:
@Node
public class ThingWithIdGeneratedByBean {
@Id @GeneratedValue(generatorRef = "idGeneratingBean")
private String theId;
}With that, idGeneratingBean refers to a bean in the Spring context.
This might be useful for sequence generating.
| Setters are not required on non-final fields for the id. |
Do I have to create repositories for each domain class?
No.
Have a look at the SDN building blocks and find the Neo4jTemplate or the ReactiveNeo4jTemplate.
Those templates know your domain and provide all necessary basic CRUD methods for retrieving, writing and counting entities.
This is our canonical movie example with the imperative template:
import java.util.Collections;
import java.util.Optional;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.data.neo4j.DataNeo4jTest;
import org.springframework.data.neo4j.core.Neo4jTemplate;
import org.springframework.data.neo4j.documentation.domain.MovieEntity;
import org.springframework.data.neo4j.documentation.domain.PersonEntity;
import org.springframework.data.neo4j.documentation.domain.Roles;
import org.springframework.data.neo4j.test.Neo4jIntegrationTest;
import static org.assertj.core.api.Assertions.assertThat;
@Neo4jIntegrationTest
@DataNeo4jTest
public class TemplateExampleTest {
@Test
void shouldSaveAndReadEntities(@Autowired Neo4jTemplate neo4jTemplate) {
MovieEntity movie = new MovieEntity("The Love Bug",
"A movie that follows the adventures of Herbie, Herbie's driver, "
+ "Jim Douglas (Dean Jones), and Jim's love interest, " + "Carole Bennett (Michele Lee)");
Roles roles1 = new Roles(new PersonEntity(1931, "Dean Jones"), Collections.singletonList("Didi"));
Roles roles2 = new Roles(new PersonEntity(1942, "Michele Lee"), Collections.singletonList("Michi"));
movie.getActorsAndRoles().add(roles1);
movie.getActorsAndRoles().add(roles2);
MovieEntity result = neo4jTemplate.save(movie);
assertThat(result.getActorsAndRoles()).allSatisfy(relationship -> assertThat(relationship.getId()).isNotNull());
Optional<PersonEntity> person = neo4jTemplate.findById("Dean Jones", PersonEntity.class);
assertThat(person).map(PersonEntity::getBorn).hasValue(1931);
assertThat(neo4jTemplate.count(PersonEntity.class)).isEqualTo(2L);
}
}And here is the reactive version, omitting the setup for brevity:
import java.util.Collections;
import org.junit.jupiter.api.Test;
import org.testcontainers.neo4j.Neo4jContainer;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
import reactor.test.StepVerifier;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.data.neo4j.DataNeo4jTest;
import org.springframework.data.neo4j.core.ReactiveNeo4jTemplate;
import org.springframework.data.neo4j.documentation.domain.MovieEntity;
import org.springframework.data.neo4j.documentation.domain.PersonEntity;
import org.springframework.data.neo4j.documentation.domain.Roles;
import org.springframework.test.context.DynamicPropertyRegistry;
import org.springframework.test.context.DynamicPropertySource;
@Testcontainers
@DataNeo4jTest
class ReactiveTemplateExampleTest {
@Container
private static Neo4jContainer neo4jContainer = new Neo4jContainer("neo4j:5");
@DynamicPropertySource
static void neo4jProperties(DynamicPropertyRegistry registry) {
registry.add("org.neo4j.driver.uri", neo4jContainer::getBoltUrl);
registry.add("org.neo4j.driver.authentication.username", () -> "neo4j");
registry.add("org.neo4j.driver.authentication.password", neo4jContainer::getAdminPassword);
}
@Test
void shouldSaveAndReadEntities(@Autowired ReactiveNeo4jTemplate neo4jTemplate) {
MovieEntity movie = new MovieEntity("The Love Bug",
"A movie that follows the adventures of Herbie, Herbie's driver, Jim Douglas (Dean Jones), and Jim's love interest, Carole Bennett (Michele Lee)");
Roles role1 = new Roles(new PersonEntity(1931, "Dean Jones"), Collections.singletonList("Didi"));
Roles role2 = new Roles(new PersonEntity(1942, "Michele Lee"), Collections.singletonList("Michi"));
movie.getActorsAndRoles().add(role1);
movie.getActorsAndRoles().add(role2);
StepVerifier.create(neo4jTemplate.save(movie)).expectNextCount(1L).verifyComplete();
StepVerifier.create(neo4jTemplate.findById("Dean Jones", PersonEntity.class).map(PersonEntity::getBorn))
.expectNext(1931)
.verifyComplete();
StepVerifier.create(neo4jTemplate.count(PersonEntity.class)).expectNext(2L).verifyComplete();
}
}Please note that both examples use @DataNeo4jTest from Spring Boot.
How do I use custom queries with repository methods returning Page<T> or Slice<T>?
While you don’t have to provide anything else apart a Pageable as a parameter on derived finder methods
that return a Page<T> or a Slice<T>, you must prepare your custom query to handle the pageable.
Pages and Slices gives you an overview about what’s needed.
import org.springframework.data.domain.Pageable;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
public interface MyPersonRepository extends Neo4jRepository<Person, Long> {
Page<Person> findByName(String name, Pageable pageable); (1)
@Query(""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n "
+ "ORDER BY n.name ASC SKIP $skip LIMIT $limit"
)
Slice<Person> findSliceByName(String name, Pageable pageable); (2)
@Query(
value = ""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n "
+ "ORDER BY n.name ASC SKIP $skip LIMIT $limit",
countQuery = ""
+ "MATCH (n:Person) WHERE n.name = $name RETURN count(n)"
)
Page<Person> findPageByName(String name, Pageable pageable); (3)
}| 1 | A derived finder method that creates a query for you.
It handles the Pageable for you.
You should use a sorted pageable. |
| 2 | This method uses @Query to define a custom query. It returns a Slice<Person>.
A slice does not know about the total number of pages, so the custom query
doesn’t need a dedicated count query. SDN will notify you that it estimates the next slice.
The Cypher template must spot both $skip and $limit Cypher parameter.
If you omit them, SDN will issue a warning. The will probably not match your expectations.
Also, the Pageable should be unsorted and you should provide a stable order.
We won’t use the sorting information from the pageable. |
| 3 | This method returns a page. A page knows about the exact number of total pages. Therefore, you must specify an additional count query. All other restrictions from the second method apply. |
Can I map named paths?
A series of connected nodes and relationships is called a "path" in Neo4j. Cypher allows paths to be named using an identifier, as exemplified by:
p = (a)-[*3..5]->(b)or as in the infamous Movie graph, that includes the following path (in that case, one of the shortest path between two actors):
MATCH p=shortestPath((bacon:Person {name:"Kevin Bacon"})-[*]-(meg:Person {name:"Meg Ryan"}))
RETURN pWhich looks like this:
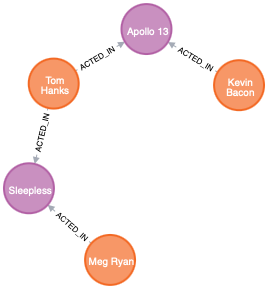
We find 3 nodes labeled Vertex and 2 nodes labeled Movie. Both can be mapped with a custom query.
Assume there’s a node entity for both Vertex and Movie as well as Actor taking care of the relationship:
@Node
public final class Person {
@Id @GeneratedValue
private final Long id;
private final String name;
private Integer born;
@Relationship("REVIEWED")
private List<Movie> reviewed = new ArrayList<>();
}
@RelationshipProperties
public final class Actor {
@RelationshipId
private final Long id;
@TargetNode
private final Person person;
private final List<String> roles;
}
@Node
public final class Movie {
@Id
private final String title;
@Property("tagline")
private final String description;
@Relationship(value = "ACTED_IN", direction = Direction.INCOMING)
private final List<Actor> actors;
}When using a query as shown in The "Bacon" distance for a domain class of type Vertex like this
interface PeopleRepository extends Neo4jRepository<Person, Long> {
@Query(""
+ "MATCH p=shortestPath((bacon:Person {name: $person1})-[*]-(meg:Person {name: $person2}))\n"
+ "RETURN p"
)
List<Person> findAllOnShortestPathBetween(@Param("person1") String person1, @Param("person2") String person2);
}it will retrieve all people from the path and map them.
If there are relationship types on the path like REVIEWED that are also present on the domain, these
will be filled accordingly from the path.
| Take special care when you use nodes hydrated from a path based query to save data. If not all relationships are hydrated, data will be lost. |
The other way round works as well. The same query can be used with the Movie entity.
It then will only populate movies.
The following listing shows how todo this as well as how the query can be enriched with additional data
not found on the path. That data is used to correctly populate the missing relationships (in that case, all the actors)
interface MovieRepository extends Neo4jRepository<Movie, String> {
@Query(""
+ "MATCH p=shortestPath(\n"
+ "(bacon:Person {name: $person1})-[*]-(meg:Person {name: $person2}))\n"
+ "WITH p, [n IN nodes(p) WHERE n:Movie] AS x\n"
+ "UNWIND x AS m\n"
+ "MATCH (m) <-[r:DIRECTED]-(d:Person)\n"
+ "RETURN p, collect(r), collect(d)"
)
List<Movie> findAllOnShortestPathBetween(@Param("person1") String person1, @Param("person2") String person2);
}The query returns the path plus all relationships and related nodes collected so that the movie entities are fully hydrated.
The path mapping works for single paths as well for multiple records of paths (which are returned by the allShortestPath function.)
| Named paths can be used efficiently to populate and return more than just a root node, see appendix/custom-queries.adoc#custom-query.paths. |
Is @Query the only way to use custom queries?
No, @Query is not the only way to run custom queries.
The annotation is comfortable in situations in which your custom query fills your domain completely.
Please remember that SDN assumes your mapped domain model to be the truth.
That means if you use a custom query via @Query that only fills a model partially, you are in danger of using the same
object to write the data back which will eventually erase or overwrite data you didn’t consider in your query.
So, please use repositories and declarative methods with @Query in all cases where the result is shaped like your domain
model or you are sure you don’t use a partially mapped model for write commands.
What are the alternatives?
-
Projections might be already enough to shape your view on the graph: They can be used to define the depth of fetching properties and related entities in an explicit way: By modelling them.
-
If your goal is to make only the conditions of your queries dynamic, then have a look at the
QuerydslPredicateExecutorbut especially our own variant of it, theCypherdslConditionExecutor. Both mixins allow adding conditions to the full queries we create for you. Thus, you will have the domain fully populated together with custom conditions. Of course, your conditions must work with what we generate. Find the names of the root node, the related nodes and more here. -
Use the Cypher-DSL via the
CypherdslStatementExecutoror theReactiveCypherdslStatementExecutor. The Cypher-DSL is predestined to create dynamic queries. In the end, it’s what SDN uses under the hood anyway. The corresponding mixins work both with the domain type of repository itself and with projections (something that the mixins for adding conditions don’t).
If you think that you can solve your problem with a partially dynamic query or a full dynamic query together with a projection, please jump back now to the chapter about Spring Data Neo4j Mixins.
Otherwise, please read up on two things: custom repository fragments the levels of abstractions we offer in SDN.
Why speaking about custom repository fragments now?
-
You might have more complex situation in which more than one dynamic query is required, but the queries still belong conceptually in a repository and not in the service layer
-
Your custom queries return a graph shaped result that fits not quite to your domain model and therefore the custom query should be accompanied by a custom mapping as well
-
You have the need for interacting with the driver, i.e. for bulk loads that should not go through object mapping.
Assume the following repository declaration that basically aggregates one base repository plus 3 fragments:
import org.springframework.data.neo4j.documentation.domain.MovieEntity;
import org.springframework.data.neo4j.repository.Neo4jRepository;
public interface MovieRepository
extends Neo4jRepository<MovieEntity, String>, DomainResults, NonDomainResults, LowlevelInteractions {
}The repository contains Movies as shown in the getting started section.
The additional interface from which the repository extends (DomainResults, NonDomainResults and LowlevelInteractions)
are the fragments that addresses all the concerns above.
Using complex, dynamic custom queries but still returning domain types
The fragment DomainResults declares one additional method findMoviesAlongShortestPath:
import java.util.List;
import org.springframework.data.neo4j.documentation.domain.MovieEntity;
import org.springframework.data.neo4j.documentation.domain.PersonEntity;
import org.springframework.transaction.annotation.Transactional;
interface DomainResults {
@Transactional(readOnly = true)
List<MovieEntity> findMoviesAlongShortestPath(PersonEntity from, PersonEntity to);
}This method is annotated with @Transactional(readOnly = true) to indicate that readers can answer it.
It cannot be derived by SDN but would need a custom query.
This custom query is provided by the one implementation of that interface.
The implementation has the same name with the suffix Impl:
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.neo4j.cypherdsl.core.Cypher;
import org.springframework.data.neo4j.core.Neo4jTemplate;
import org.springframework.data.neo4j.documentation.domain.MovieEntity;
import org.springframework.data.neo4j.documentation.domain.PersonEntity;
import static org.neo4j.cypherdsl.core.Cypher.anyNode;
import static org.neo4j.cypherdsl.core.Cypher.listWith;
import static org.neo4j.cypherdsl.core.Cypher.name;
import static org.neo4j.cypherdsl.core.Cypher.node;
import static org.neo4j.cypherdsl.core.Cypher.parameter;
class DomainResultsImpl implements DomainResults {
private final Neo4jTemplate neo4jTemplate; (1)
DomainResultsImpl(Neo4jTemplate neo4jTemplate) {
this.neo4jTemplate = neo4jTemplate;
}
@Override
public List<MovieEntity> findMoviesAlongShortestPath(PersonEntity from, PersonEntity to) {
var p1 = node("Person").withProperties("name", parameter("person1"));
var p2 = node("Person").withProperties("name", parameter("person2"));
var shortestPath = Cypher.shortestK(1).named("p").definedBy(p1.relationshipBetween(p2).unbounded());
var p = shortestPath.getRequiredSymbolicName();
var statement = Cypher.match(shortestPath)
.with(p, listWith(name("n")).in(Cypher.nodes(shortestPath))
.where(anyNode().named("n").hasLabels("Movie"))
.returning()
.as("mn"))
.unwind(name("mn"))
.as("m")
.with(p, name("m"))
.match(node("Person").named("d").relationshipTo(anyNode("m"), "DIRECTED").named("r"))
.returning(p, Cypher.collect(name("r")), Cypher.collect(name("d")))
.build();
Map<String, Object> parameters = new HashMap<>();
parameters.put("person1", from.getName());
parameters.put("person2", to.getName());
return this.neo4jTemplate.findAll(statement, parameters, MovieEntity.class); (2)
}
}| 1 | The Neo4jTemplate is injected by the runtime through the constructor of DomainResultsImpl. No need for @Autowired. |
| 2 | The Cypher-DSL is used to build a complex statement (pretty much the same as shown in path mapping.) The statement can be passed directly to the template. |
The template has overloads for String-based queries as well, so you could write down the query as String as well. The important takeaway here is:
-
The template "knows" your domain objects and maps them accordingly
-
@Queryis not the only option to define custom queries -
They can be generated in various ways
-
The
@Transactionalannotation is respected
Using custom queries and custom mappings
Often times a custom query indicates custom results.
Should all of those results be mapped as @Node? Of course not! Many times those objects represents read commands
and are not meant to be used as write commands.
It is also not unlikely that SDN cannot or want not map everything that is possible with Cypher.
It does however offer several hooks to run your own mapping: On the Neo4jClient.
The benefit of using the SDN Neo4jClient over the driver:
-
The
Neo4jClientis integrated with Springs transaction management -
It has a fluent API for binding parameters
-
It has a fluent API exposing both the records and the Neo4j type system so that you can access everything in your result to execute the mapping
Declaring the fragment is exactly the same as before:
import java.util.Collection;
import org.springframework.data.neo4j.documentation.domain.MovieEntity;
import org.springframework.transaction.annotation.Transactional;
interface NonDomainResults {
@Transactional(readOnly = true)
Collection<Result> findRelationsToMovie(MovieEntity movie); (1)
class Result {
(2)
public final String name;
public final String typeOfRelation;
Result(String name, String typeOfRelation) {
this.name = name;
this.typeOfRelation = typeOfRelation;
}
}
}| 1 | This is a made up non-domain result. A real world query result would probably look more complex. |
| 2 | The method this fragment adds. Again, the method is annotated with Spring’s @Transactional |
Without an implementation for that fragment, startup would fail, so here it is:
import java.util.Collection;
import org.springframework.data.neo4j.core.Neo4jClient;
import org.springframework.data.neo4j.documentation.domain.MovieEntity;
class NonDomainResultsImpl implements NonDomainResults {
private final Neo4jClient neo4jClient; (1)
NonDomainResultsImpl(Neo4jClient neo4jClient) {
this.neo4jClient = neo4jClient;
}
@Override
public Collection<Result> findRelationsToMovie(MovieEntity movie) {
return this.neo4jClient
.query("" + "MATCH (people:Person)-[relatedTo]-(:Movie {title: $title}) " + "RETURN people.name AS name, "
+ " Type(relatedTo) as typeOfRelation") (2)
.bind(movie.getTitle())
.to("title") (3)
.fetchAs(Result.class) (4)
.mappedBy((typeSystem, record) -> new Result(record.get("name").asString(),
record.get("typeOfRelation").asString())) (5)
.all(); (6)
}
}| 1 | Here we use the Neo4jClient, as provided by the infrastructure. |
| 2 | The client takes only in Strings, but the Cypher-DSL can still be used when rendering into a String |
| 3 | Bind one single value to a named parameter. There’s also an overload to bind a whole map of parameters |
| 4 | This is the type of the result you want |
| 5 | And finally, the mappedBy method, exposing one Record for each entry in the result plus the drivers type system if needed.
This is the API in which you hook in for your custom mappings |
The whole query runs in the context of a Spring transaction, in this case, a read-only one.
Low level interactions
Sometimes you might want to do bulk loadings from a repository or delete whole subgraphs or interact in very specific ways with the Neo4j Java-Driver. This is possible as well. The following example shows how:
interface LowlevelInteractions {
int deleteGraph();
}
import org.neo4j.driver.Driver;
import org.neo4j.driver.Session;
import org.neo4j.driver.summary.SummaryCounters;
class LowlevelInteractionsImpl implements LowlevelInteractions {
private final Driver driver; (1)
LowlevelInteractionsImpl(Driver driver) {
this.driver = driver;
}
@Override
public int deleteGraph() {
try (Session session = this.driver.session()) {
SummaryCounters counters = session.executeWrite(tx -> tx.run("MATCH (n) DETACH DELETE n").consume()) (2)
.counters();
return counters.nodesDeleted() + counters.relationshipsDeleted();
}
}
}| 1 | Work with the driver directly. As with all the examples: There is no need for @Autowired magic. All the fragments
are actually testable on their own. |
| 2 | The use case is made up. Here we use a driver managed transaction deleting the whole graph and return the number of deleted nodes and relationships |
This interaction does of course not run in a Spring transaction, as the driver does not know about Spring.
Putting it all together, this test succeeds:
@Test
void customRepositoryFragmentsShouldWork(@Autowired PersonRepository people, @Autowired MovieRepository movies) {
PersonEntity meg = people.findById("Meg Ryan").get();
PersonEntity kevin = people.findById("Kevin Bacon").get();
List<MovieEntity> moviesBetweenMegAndKevin = movies.findMoviesAlongShortestPath(meg, kevin);
assertThat(moviesBetweenMegAndKevin).isNotEmpty();
Collection<NonDomainResults.Result> relatedPeople = movies
.findRelationsToMovie(moviesBetweenMegAndKevin.get(0));
assertThat(relatedPeople).isNotEmpty();
assertThat(movies.deleteGraph()).isGreaterThan(0);
assertThat(movies.findAll()).isEmpty();
assertThat(people.findAll()).isEmpty();
}As a final word: All three interfaces and implementations are picked up by Spring Data Neo4j automatically. There is no need for further configuration. Also, the same overall repository could have been created with only one additional fragment (the interface defining all three methods) and one implementation. The implementation would than have had all three abstractions injected (template, client and driver).
All of this applies of course to reactive repositories as well.
They would work with the ReactiveNeo4jTemplate and ReactiveNeo4jClient and the reactive session provided by the driver.
If you have recurring methods for all repositories, you could swap out the default repository implementation.
How do I use custom Spring Data Neo4j base repositories?
Basically the same ways as the shared Spring Data Commons documentation shows for Spring Data JPA in Customize the Base Repository. Only that in our case you would extend from
public static class MyRepositoryImpl<T, ID> extends SimpleNeo4jRepository<T, ID> {
MyRepositoryImpl(Neo4jOperations neo4jOperations, Neo4jEntityInformation<T, ID> entityInformation) {
super(neo4jOperations, entityInformation); (1)
}
@Override
public List<T> findAll() {
throw new UnsupportedOperationException("This implementation does not support `findAll`");
}
}| 1 | This signature is required by the base class. Take the Neo4jOperations (the actual specification of the Neo4jTemplate)
and the entity information and store them on an attribute if needed. |
In this example we forbid the use of the findAll method.
You could add methods taking in a fetch depth and run custom queries based on that depth.
One way to do this is shown in DomainResults fragment.
To enable this base repository for all declared repositories enable Neo4j repositories with: @EnableNeo4jRepositories(repositoryBaseClass = MyRepositoryImpl.class).
How do I audit entities?
All Spring Data annotations are supported. Those are
-
org.springframework.data.annotation.CreatedBy -
org.springframework.data.annotation.CreatedDate -
org.springframework.data.annotation.LastModifiedBy -
org.springframework.data.annotation.LastModifiedDate
Auditing gives you a general view how to use auditing in the bigger context of Spring Data Commons. The following listing presents every configuration option provided by Spring Data Neo4j:
@Configuration
@EnableNeo4jAuditing(modifyOnCreate = false, (1)
auditorAwareRef = "auditorProvider", (2)
dateTimeProviderRef = "fixedDateTimeProvider" (3)
)
class AuditingConfig {
@Bean
AuditorAware<String> auditorProvider() {
return () -> Optional.of("A user");
}
@Bean
DateTimeProvider fixedDateTimeProvider() {
return () -> Optional.of(AuditingITBase.DEFAULT_CREATION_AND_MODIFICATION_DATE);
}
}| 1 | Set to true if you want the modification data to be written during creating as well |
| 2 | Use this attribute to specify the name of the bean that provides the auditor (i.e. a user name) |
| 3 | Use this attribute to specify the name of a bean that provides the current date. In this case a fixed date is used as the above configuration is part of our tests |
The reactive version is basically the same apart from the fact the auditor aware bean is of type ReactiveAuditorAware,
so that the retrieval of an auditor is part of the reactive flow.
In addition to those auditing mechanism you can add as many beans implementing BeforeBindCallback<T> or ReactiveBeforeBindCallback<T>
to the context. These beans will be picked up by Spring Data Neo4j and called in order (in case they implement Ordered or
are annotated with @Order) just before an entity is persisted.
They can modify the entity or return a completely new one. The following example adds one callback to the context that changes one attribute before the entity is persisted:
import java.util.UUID;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.mapping.callback.AfterConvertCallback;
import org.springframework.data.neo4j.core.mapping.callback.BeforeBindCallback;
import org.springframework.data.neo4j.integration.shared.common.ThingWithAssignedId;
@Configuration
class CallbacksConfig {
@Bean
BeforeBindCallback<ThingWithAssignedId> nameChanger() {
return entity -> {
ThingWithAssignedId updatedThing = new ThingWithAssignedId(entity.getTheId(),
entity.getName() + " (Edited)");
return updatedThing;
};
}
@Bean
AfterConvertCallback<ThingWithAssignedId> randomValueAssigner() {
return (entity, definition, source) -> {
entity.setRandomValue(UUID.randomUUID().toString());
return entity;
};
}
}No additional configuration is required.
How do I use "Find by example"?
"Find by example" is a new feature in SDN.
You instantiate an entity or use an existing one.
With this instance you create an org.springframework.data.domain.Example.
If your repository extends org.springframework.data.neo4j.repository.Neo4jRepository or org.springframework.data.neo4j.repository.ReactiveNeo4jRepository, you can immediately use the available findBy methods taking in an example, like shown in findByExample.
Example<MovieEntity> movieExample = Example.of(new MovieEntity("The Matrix", null));
Flux<MovieEntity> movies = this.movieRepository.findAll(movieExample);
movieExample = Example.of(
new MovieEntity("Matrix", null),
ExampleMatcher
.matchingAny()
.withMatcher(
"title",
ExampleMatcher.GenericPropertyMatcher.of(ExampleMatcher.StringMatcher.CONTAINING)
)
);
movies = this.movieRepository.findAll(movieExample);You can also negate individual properties. This will add an appropriate NOT operation, thus turning an = into a <>.
All scalar datatypes and all string operators are supported:
Example<MovieEntity> movieExample = Example.of(
new MovieEntity("Matrix", null),
ExampleMatcher
.matchingAny()
.withMatcher(
"title",
ExampleMatcher.GenericPropertyMatcher.of(ExampleMatcher.StringMatcher.CONTAINING)
)
.withTransformer("title", Neo4jPropertyValueTransformers.notMatching())
);
Flux<MovieEntity> allMoviesThatNotContainMatrix = this.movieRepository.findAll(movieExample);Do I need Spring Boot to use Spring Data Neo4j?
No, you don’t. While the automatic configuration of many Spring aspects through Spring Boot takes away a lot of manual cruft and is the recommended approach for setting up new Spring projects, you don’t need to have to use this.
The following dependency is required for the solutions described above:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-neo4j</artifactId>
<version>8.0.6-SNAPSHOT</version>
</dependency>The coordinates for a Gradle setup are the same.
To select a different database - either statically or dynamically - you can add a Bean of type DatabaseSelectionProvider as explained in Neo4j 4 supports multiple databases - How can I use them?.
For a reactive scenario, we provide ReactiveDatabaseSelectionProvider.
Using Spring Data Neo4j inside a Spring context without Spring Boot
We provide two abstract configuration classes to support you in bringing in the necessary beans:
org.springframework.data.neo4j.config.AbstractNeo4jConfig for imperative database access and
org.springframework.data.neo4j.config.AbstractReactiveNeo4jConfig for the reactive version.
They are meant to be used with @EnableNeo4jRepositories and @EnableReactiveNeo4jRepositories respectively.
See Enabling Spring Data Neo4j infrastructure for imperative database access and Enabling Spring Data Neo4j infrastructure for reactive database access for an example usage.
Both classes require you to override driver() in which you are supposed to create the driver.
To get the imperative version of the Neo4j client, the template and support for imperative repositories, use something similar as shown here:
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import org.springframework.data.neo4j.config.AbstractNeo4jConfig;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.data.neo4j.repository.config.EnableNeo4jRepositories;
@Configuration
@EnableNeo4jRepositories
@EnableTransactionManagement
class MyConfiguration extends AbstractNeo4jConfig {
@Override @Bean
public Driver driver() { (1)
return GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"));
}
@Override
protected Collection<String> getMappingBasePackages() {
return Collections.singletonList(Person.class.getPackage().getName());
}
@Override @Bean (2)
protected DatabaseSelectionProvider databaseSelectionProvider() {
return DatabaseSelectionProvider.createStaticDatabaseSelectionProvider("yourDatabase");
}
}| 1 | The driver bean is required. |
| 2 | This statically selects a database named yourDatabase and is optional. |
The following listing provides the reactive Neo4j client and template, enables reactive transaction management and discovers Neo4j related repositories:
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.config.AbstractReactiveNeo4jConfig;
import org.springframework.data.neo4j.repository.config.EnableReactiveNeo4jRepositories;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@Configuration
@EnableReactiveNeo4jRepositories
@EnableTransactionManagement
class MyConfiguration extends AbstractReactiveNeo4jConfig {
@Bean
@Override
public Driver driver() {
return GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"));
}
@Override
protected Collection<String> getMappingBasePackages() {
return Collections.singletonList(Person.class.getPackage().getName());
}
}Using Spring Data Neo4j in a CDI 2.0 environment
For your convenience we provide a CDI extension with Neo4jCdiExtension.
When run in a compatible CDI 2.0 container, it will be automatically be registered and loaded through Java’s service loader SPI.
The only thing you have to bring into your application is an annotated type that produces the Neo4j Java Driver:
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
public class Neo4jConfig {
@Produces @ApplicationScoped
public Driver driver() { (1)
return GraphDatabase
.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"));
}
public void close(@Disposes Driver driver) {
driver.close();
}
@Produces @Singleton
public DatabaseSelectionProvider getDatabaseSelectionProvider() { (2)
return DatabaseSelectionProvider.createStaticDatabaseSelectionProvider("yourDatabase");
}
}| 1 | Same as with plain Spring in Enabling Spring Data Neo4j infrastructure for imperative database access, but annotated with the corresponding CDI infrastructure. |
| 2 | This is optional. However, if you run a custom database selection provider, you must not qualify this bean. |
If you are running in a SE Container - like the one Weld provides for example, you can enable the extension like that:
import javax.enterprise.inject.se.SeContainer;
import javax.enterprise.inject.se.SeContainerInitializer;
import org.springframework.data.neo4j.config.Neo4jCdiExtension;
public class SomeClass {
void someMethod() {
try (SeContainer container = SeContainerInitializer.newInstance()
.disableDiscovery()
.addExtensions(Neo4jCdiExtension.class)
.addBeanClasses(YourDriverFactory.class)
.addPackages(Package.getPackage("your.domain.package"))
.initialize()
) {
SomeRepository someRepository = container.select(SomeRepository.class).get();
}
}
}
