|
This version is still in development and is not considered stable yet. For the latest stable version, please use Spring AMQP 4.0.0! |
Connection and Resource Management
Whereas the AMQP model we described in the previous section is generic and applicable to all implementations, when we get into the management of resources, the details are specific to the broker implementation. Therefore, in this section, we focus on code that exists only within our “spring-rabbit” module since, at this point, RabbitMQ is the only supported implementation.
The central component for managing a connection to the RabbitMQ broker is the ConnectionFactory interface.
The responsibility of a ConnectionFactory implementation is to provide an instance of org.springframework.amqp.rabbit.connection.Connection, which is a wrapper for com.rabbitmq.client.Connection.
Choosing a Connection Factory
There are three connection factories to chose from
-
PooledChannelConnectionFactory -
ThreadChannelConnectionFactory -
CachingConnectionFactory
The first two were added in version 2.3.
For most use cases, the CachingConnectionFactory should be used.
The ThreadChannelConnectionFactory can be used if you want to ensure strict message ordering without the need to use Scoped Operations.
The PooledChannelConnectionFactory is similar to the CachingConnectionFactory in that it uses a single connection and a pool of channels.
It’s implementation is simpler but it doesn’t support correlated publisher confirmations.
Simple publisher confirmations are supported by all three factories.
When configuring a RabbitTemplate to use a separate connection, you can now, starting with version 2.3.2, configure the publishing connection factory to be a different type.
By default, the publishing factory is the same type and any properties set on the main factory are also propagated to the publishing factory.
Starting with version 3.1, the AbstractConnectionFactory includes the connectionCreatingBackOff property, which supports a backoff policy in the connection module.
Currently, there is support in the behavior of createChannel() to handle exceptions that occur when the channelMax limit is reached, implementing a backoff strategy based on attempts and intervals.
PooledChannelConnectionFactory
This factory manages a single connection and two pools of channels, based on the Apache Pool2.
One pool is for transactional channels, the other is for non-transactional channels.
The pools are GenericObjectPool s with default configuration; a callback is provided to configure the pools; refer to the Apache documentation for more information.
The Apache commons-pool2 jar must be on the class path to use this factory.
@Bean
PooledChannelConnectionFactory pcf() throws Exception {
ConnectionFactory rabbitConnectionFactory = new ConnectionFactory();
rabbitConnectionFactory.setHost("localhost");
PooledChannelConnectionFactory pcf = new PooledChannelConnectionFactory(rabbitConnectionFactory);
pcf.setPoolConfigurer((pool, tx) -> {
if (tx) {
// configure the transactional pool
}
else {
// configure the non-transactional pool
}
});
return pcf;
}ThreadChannelConnectionFactory
This factory manages a single connection and two ThreadLocal s, one for transactional channels, the other for non-transactional channels.
This factory ensures that all operations on the same thread use the same channel (as long as it remains open).
This facilitates strict message ordering without the need for Scoped Operations.
To avoid memory leaks, if your application uses many short-lived threads, you must call the factory’s closeThreadChannel() to release the channel resource.
Starting with version 2.3.7, a thread can transfer its channel(s) to another thread.
See Strict Message Ordering in a Multi-Threaded Environment for more information.
CachingConnectionFactory
The third implementation provided is the CachingConnectionFactory, which, by default, establishes a single connection proxy that can be shared by the application.
Sharing of the connection is possible since the “unit of work” for messaging with AMQP is actually a “channel” (in some ways, this is similar to the relationship between a connection and a session in JMS).
The connection instance provides a createChannel method.
The CachingConnectionFactory implementation supports caching of those channels, and it maintains separate caches for channels based on whether they are transactional.
When creating an instance of CachingConnectionFactory, you can provide the 'hostname' through the constructor.
You should also provide the 'username' and 'password' properties.
To configure the size of the channel cache (the default is 25), you can call the
setChannelCacheSize() method.
Starting with version 1.3, you can configure the CachingConnectionFactory to cache connections as well as only channels.
In this case, each call to createConnection() creates a new connection (or retrieves an idle one from the cache).
Closing a connection returns it to the cache (if the cache size has not been reached).
Channels created on such connections are also cached.
The use of separate connections might be useful in some environments, such as consuming from an HA cluster, in
conjunction with a load balancer, to connect to different cluster members, and others.
To cache connections, set the cacheMode to CacheMode.CONNECTION.
| This does not limit the number of connections. Rather, it specifies how many idle open connections are allowed. |
Starting with version 1.5.5, a new property called connectionLimit is provided.
When this property is set, it limits the total number of connections allowed.
When set, if the limit is reached, the channelCheckoutTimeLimit is used to wait for a connection to become idle.
If the time is exceeded, an AmqpTimeoutException is thrown.
|
When the cache mode is Also, at the time of this writing, the |
It is important to understand that the cache size is (by default) not a limit but is merely the number of channels that can be cached. With a cache size of, say, 10, any number of channels can actually be in use. If more than 10 channels are being used and they are all returned to the cache, 10 go in the cache. The remainder are physically closed.
Starting with version 1.6, the default channel cache size has been increased from 1 to 25. In high volume, multi-threaded environments, a small cache means that channels are created and closed at a high rate. Increasing the default cache size can avoid this overhead. You should monitor the channels in use through the RabbitMQ Admin UI and consider increasing the cache size further if you see many channels being created and closed. The cache grows only on-demand (to suit the concurrency requirements of the application), so this change does not impact existing low-volume applications.
Starting with version 1.4.2, the CachingConnectionFactory has a property called channelCheckoutTimeout.
When this property is greater than zero, the channelCacheSize becomes a limit on the number of channels that can be created on a connection.
If the limit is reached, calling threads block until a channel is available or this timeout is reached, in which case a AmqpTimeoutException is thrown.
Channels used within the framework (for example,
RabbitTemplate) are reliably returned to the cache.
If you create channels outside of the framework, (for example,
by accessing the connections directly and invoking createChannel()), you must return them (by closing) reliably, perhaps in a finally block, to avoid running out of channels.
|
The following example shows how to create a new connection:
CachingConnectionFactory connectionFactory = new CachingConnectionFactory("somehost");
connectionFactory.setUsername("guest");
connectionFactory.setPassword("guest");
Connection connection = connectionFactory.createConnection();When using XML, the configuration might look like the following example:
<bean id="connectionFactory"
class="org.springframework.amqp.rabbit.connection.CachingConnectionFactory">
<constructor-arg value="somehost"/>
<property name="username" value="guest"/>
<property name="password" value="guest"/>
</bean>
There is also a SingleConnectionFactory implementation that is available only in the unit test code of the framework.
It is simpler than CachingConnectionFactory, since it does not cache channels, but it is not intended for practical usage outside of simple tests due to its lack of performance and resilience.
If you need to implement your own ConnectionFactory for some reason, the AbstractConnectionFactory base class may provide a nice starting point.
|
A ConnectionFactory can be created quickly and conveniently by using the rabbit namespace, as follows:
<rabbit:connection-factory id="connectionFactory"/>In most cases, this approach is preferable, since the framework can choose the best defaults for you.
The created instance is a CachingConnectionFactory.
Keep in mind that the default cache size for channels is 25.
If you want more channels to be cached, set a larger value by setting the 'channelCacheSize' property.
In XML it would look like as follows:
<bean id="connectionFactory"
class="org.springframework.amqp.rabbit.connection.CachingConnectionFactory">
<constructor-arg value="somehost"/>
<property name="username" value="guest"/>
<property name="password" value="guest"/>
<property name="channelCacheSize" value="50"/>
</bean>Also, with the namespace, you can add the 'channel-cache-size' attribute, as follows:
<rabbit:connection-factory
id="connectionFactory" channel-cache-size="50"/>The default cache mode is CHANNEL, but you can configure it to cache connections instead.
In the following example, we use connection-cache-size:
<rabbit:connection-factory
id="connectionFactory" cache-mode="CONNECTION" connection-cache-size="25"/>You can provide host and port attributes by using the namespace, as follows:
<rabbit:connection-factory
id="connectionFactory" host="somehost" port="5672"/>Alternatively, if running in a clustered environment, you can use the addresses attribute, as follows:
<rabbit:connection-factory
id="connectionFactory" addresses="host1:5672,host2:5672" address-shuffle-mode="RANDOM"/>See Connecting to a Cluster for information about address-shuffle-mode.
The following example with a custom thread factory that prefixes thread names with rabbitmq-:
<rabbit:connection-factory id="multiHost" virtual-host="/bar" addresses="host1:1234,host2,host3:4567"
thread-factory="tf"
channel-cache-size="10" username="user" password="password" />
<bean id="tf" class="org.springframework.scheduling.concurrent.CustomizableThreadFactory">
<constructor-arg value="rabbitmq-" />
</bean>AddressResolver
Starting with version 2.1.15, you can now use an AddressResolver to resolve the connection address(es).
This will override any settings of the addresses and host/port properties.
Naming Connections
Starting with version 1.7, a ConnectionNameStrategy is provided for the injection into the AbstractionConnectionFactory.
The generated name is used for the application-specific identification of the target RabbitMQ connection.
The connection name is displayed in the management UI if the RabbitMQ server supports it.
This value does not have to be unique and cannot be used as a connection identifier — for example, in HTTP API requests.
This value is supposed to be human-readable and is a part of ClientProperties under the connection_name key.
You can use a simple Lambda, as follows:
connectionFactory.setConnectionNameStrategy(connectionFactory -> "MY_CONNECTION");The ConnectionFactory argument can be used to distinguish target connection names by some logic.
By default, the beanName of the AbstractConnectionFactory, a hex string representing the object, and an internal counter are used to generate the connection_name.
The <rabbit:connection-factory> namespace component is also supplied with the connection-name-strategy attribute.
An implementation of SimplePropertyValueConnectionNameStrategy sets the connection name to an application property.
You can declare it as a @Bean and inject it into the connection factory, as the following example shows:
@Bean
public SimplePropertyValueConnectionNameStrategy cns() {
return new SimplePropertyValueConnectionNameStrategy("spring.application.name");
}
@Bean
public ConnectionFactory rabbitConnectionFactory(ConnectionNameStrategy cns) {
CachingConnectionFactory connectionFactory = new CachingConnectionFactory();
...
connectionFactory.setConnectionNameStrategy(cns);
return connectionFactory;
}The property must exist in the application context’s Environment.
When using Spring Boot and its autoconfigured connection factory, you need only declare the ConnectionNameStrategy @Bean.
Boot auto-detects the bean and wires it into the factory.
|
Blocked Connections and Resource Constraints
The connection might be blocked for interaction from the broker that corresponds to the Memory Alarm.
Starting with version 2.0, the org.springframework.amqp.rabbit.connection.Connection can be supplied with com.rabbitmq.client.BlockedListener instances to be notified for connection blocked and unblocked events.
In addition, the AbstractConnectionFactory emits a ConnectionBlockedEvent and ConnectionUnblockedEvent, respectively, through its internal BlockedListener implementation.
These let you provide application logic to react appropriately to problems on the broker and (for example) take some corrective actions.
When the application is configured with a single CachingConnectionFactory, as it is by default with Spring Boot auto-configuration, the application stops working when the connection is blocked by the Broker.
And when it is blocked by the Broker, any of its clients stop to work.
If we have producers and consumers in the same application, we may end up with a deadlock when producers are blocking the connection (because there are no resources on the Broker any more) and consumers cannot free them (because the connection is blocked).
To mitigate the problem, we suggest having one more separate CachingConnectionFactory instance with the same options — one for producers and one for consumers.
A separate CachingConnectionFactory is not possible for transactional producers that execute on a consumer thread, since they should reuse the Channel associated with the consumer transactions.
|
Starting with version 2.0.2, the RabbitTemplate has a configuration option to automatically use a second connection factory, unless transactions are being used.
See Using a Separate Connection for more information.
The ConnectionNameStrategy for the publisher connection is the same as the primary strategy with .publisher appended to the result of calling the method.
Starting with version 1.7.7, an AmqpResourceNotAvailableException is provided, which is thrown when SimpleConnection.createChannel() cannot create a Channel (for example, because the channelMax limit is reached and there are no available channels in the cache).
You can use this exception in the RetryPolicy to recover the operation after some back-off.
Configuring the Underlying Client Connection Factory
The CachingConnectionFactory uses an instance of the Rabbit client ConnectionFactory.
A number of configuration properties are passed through (host, port, userName, password, requestedHeartBeat, and connectionTimeout for example) when setting the equivalent property on the CachingConnectionFactory.
To set other properties (clientProperties, for example), you can define an instance of the Rabbit factory and provide a reference to it by using the appropriate constructor of the CachingConnectionFactory.
When using the namespace (as described earlier), you need to provide a reference to the configured factory in the connection-factory attribute.
For convenience, a factory bean is provided to assist in configuring the connection factory in a Spring application context, as discussed in the next section.
<rabbit:connection-factory
id="connectionFactory" connection-factory="rabbitConnectionFactory"/>
The 4.0.x client enables automatic recovery by default.
While compatible with this feature, Spring AMQP has its own recovery mechanisms and the client recovery feature generally is not needed.
We recommend disabling amqp-client automatic recovery, to avoid getting AutoRecoverConnectionNotCurrentlyOpenException instances when the broker is available but the connection has not yet recovered.
You may notice this exception, for example, when a RetryTemplate is configured in a RabbitTemplate, even when failing over to another broker in a cluster.
Since the auto-recovering connection recovers on a timer, the connection may be recovered more quickly by using Spring AMQP’s recovery mechanisms.
Starting with version 1.7.1, Spring AMQP disables amqp-client automatic recovery unless you explicitly create your own RabbitMQ connection factory and provide it to the CachingConnectionFactory.
RabbitMQ ConnectionFactory instances created by the RabbitConnectionFactoryBean also have the option disabled by default.
|
RabbitConnectionFactoryBean and Configuring SSL
Starting with version 1.4, a convenient RabbitConnectionFactoryBean is provided to enable convenient configuration of SSL properties on the underlying client connection factory by using dependency injection.
Other setters delegate to the underlying factory.
Previously, you had to configure the SSL options programmatically.
The following example shows how to configure a RabbitConnectionFactoryBean:
@Bean
RabbitConnectionFactoryBean rabbitConnectionFactory() {
RabbitConnectionFactoryBean factoryBean = new RabbitConnectionFactoryBean();
factoryBean.setUseSSL(true);
factoryBean.setSslPropertiesLocation(new ClassPathResource("secrets/rabbitSSL.properties"));
return factoryBean;
}
@Bean
CachingConnectionFactory connectionFactory(ConnectionFactory rabbitConnectionFactory) {
CachingConnectionFactory ccf = new CachingConnectionFactory(rabbitConnectionFactory);
ccf.setHost("...");
// ...
return ccf;
}spring.rabbitmq.ssl.enabled:true
spring.rabbitmq.ssl.keyStore=...
spring.rabbitmq.ssl.keyStoreType=jks
spring.rabbitmq.ssl.keyStorePassword=...
spring.rabbitmq.ssl.trustStore=...
spring.rabbitmq.ssl.trustStoreType=jks
spring.rabbitmq.ssl.trustStorePassword=...
spring.rabbitmq.host=...
...<rabbit:connection-factory id="rabbitConnectionFactory"
connection-factory="clientConnectionFactory"
host="${host}"
port="${port}"
virtual-host="${vhost}"
username="${username}" password="${password}" />
<bean id="clientConnectionFactory"
class="org.springframework.amqp.rabbit.connection.RabbitConnectionFactoryBean">
<property name="useSSL" value="true" />
<property name="sslPropertiesLocation" value="classpath:secrets/rabbitSSL.properties"/>
</bean>See the RabbitMQ Documentation for information about configuring SSL.
Omit the keyStore and trustStore configuration to connect over SSL without certificate validation.
The next example shows how you can provide key and trust store configuration.
The sslPropertiesLocation property is a Spring Resource pointing to a properties file containing the following keys:
keyStore=file:/secret/keycert.p12
trustStore=file:/secret/trustStore
keyStore.passPhrase=secret
trustStore.passPhrase=secretThe keyStore and truststore are Spring Resources pointing to the stores.
Typically this properties file is secured by the operating system with the application having read access.
Starting with Spring AMQP version 1.5,you can set these properties directly on the factory bean.
If both discrete properties and sslPropertiesLocation is provided, properties in the latter override the
discrete values.
Starting with version 2.0, the server certificate is validated by default because it is more secure.
If you wish to skip this validation for some reason, set the factory bean’s skipServerCertificateValidation property to true.
Starting with version 2.1, the RabbitConnectionFactoryBean now calls enableHostnameVerification() by default.
To revert to the previous behavior, set the enableHostnameVerification property to false.
|
Starting with version 2.2.5, the factory bean will always use TLS v1.2 by default; previously, it used v1.1 in some cases and v1.2 in others (depending on other properties).
If you need to use v1.1 for some reason, set the sslAlgorithm property: setSslAlgorithm("TLSv1.1").
|
Connecting to a Cluster
To connect to a cluster, configure the addresses property on the CachingConnectionFactory:
@Bean
public CachingConnectionFactory ccf() {
CachingConnectionFactory ccf = new CachingConnectionFactory();
ccf.setAddresses("host1:5672,host2:5672,host3:5672");
return ccf;
}Starting with version 3.0, the underlying connection factory will attempt to connect to a host, by choosing a random address, whenever a new connection is established.
To revert to the previous behavior of attempting to connect from first to last, set the addressShuffleMode property to AddressShuffleMode.NONE.
Starting with version 2.3, the INORDER shuffle mode was added, which means the first address is moved to the end after a connection is created.
You may wish to use this mode with the RabbitMQ Sharding Plugin with CacheMode.CONNECTION and suitable concurrency if you wish to consume from all shards on all nodes.
@Bean
public CachingConnectionFactory ccf() {
CachingConnectionFactory ccf = new CachingConnectionFactory();
ccf.setAddresses("host1:5672,host2:5672,host3:5672");
ccf.setAddressShuffleMode(AddressShuffleMode.INORDER);
return ccf;
}Routing Connection Factory
Starting with version 1.3, the AbstractRoutingConnectionFactory has been introduced.
This factory provides a mechanism to configure mappings for several ConnectionFactories and determine a target ConnectionFactory by some lookupKey at runtime.
Typically, the implementation checks a thread-bound context.
For convenience, Spring AMQP provides the SimpleRoutingConnectionFactory, which gets the current thread-bound lookupKey from the SimpleResourceHolder.
The following examples shows how to configure a SimpleRoutingConnectionFactory in both XML and Java:
<bean id="connectionFactory"
class="org.springframework.amqp.rabbit.connection.SimpleRoutingConnectionFactory">
<property name="targetConnectionFactories">
<map>
<entry key="#{connectionFactory1.virtualHost}" ref="connectionFactory1"/>
<entry key="#{connectionFactory2.virtualHost}" ref="connectionFactory2"/>
</map>
</property>
</bean>
<rabbit:template id="template" connection-factory="connectionFactory" />public class MyService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void service(String vHost, String payload) {
SimpleResourceHolder.bind(rabbitTemplate.getConnectionFactory(), vHost);
rabbitTemplate.convertAndSend(payload);
SimpleResourceHolder.unbind(rabbitTemplate.getConnectionFactory());
}
}It is important to unbind the resource after use.
For more information, see the JavaDoc for AbstractRoutingConnectionFactory.
Starting with version 1.4, RabbitTemplate supports the SpEL sendConnectionFactorySelectorExpression and receiveConnectionFactorySelectorExpression properties, which are evaluated on each AMQP protocol interaction operation (send, sendAndReceive, receive, or receiveAndReply), resolving to a lookupKey value for the provided AbstractRoutingConnectionFactory.
You can use bean references, such as @vHostResolver.getVHost(#root) in the expression.
For send operations, the message to be sent is the root evaluation object.
For receive operations, the queueName is the root evaluation object.
The routing algorithm is as follows: If the selector expression is null or is evaluated to null or the provided ConnectionFactory is not an instance of AbstractRoutingConnectionFactory, everything works as before, relying on the provided ConnectionFactory implementation.
The same occurs if the evaluation result is not null, but there is no target ConnectionFactory for that lookupKey and the AbstractRoutingConnectionFactory is configured with lenientFallback = true.
In the case of an AbstractRoutingConnectionFactory, it does fallback to its routing implementation based on determineCurrentLookupKey().
However, if lenientFallback = false, an IllegalStateException is thrown.
The namespace support also provides the send-connection-factory-selector-expression and receive-connection-factory-selector-expression attributes on the <rabbit:template> component.
Also, starting with version 1.4, you can configure a routing connection factory in a listener container.
In that case, the list of queue names is used as the lookup key.
For example, if you configure the container with setQueueNames("thing1", "thing2"), the lookup key is [thing1,thing]" (note that there is no space in the key).
Starting with version 1.6.9, you can add a qualifier to the lookup key by using setLookupKeyQualifier on the listener container.
Doing so enables, for example, listening to queues with the same name but in a different virtual host (where you would have a connection factory for each).
For example, with lookup key qualifier thing1 and a container listening to queue thing2, the lookup key you could register the target connection factory with could be thing1[thing2].
| The target (and default, if provided) connection factories must have the same settings for publisher confirms and returns. See Publisher Confirms and Returns. |
Starting with version 2.4.4, this validation can be disabled.
If you have a case that the values between confirms and returns need to be unequal, you can use AbstractRoutingConnectionFactory#setConsistentConfirmsReturns to turn of the validation.
Note that the first connection factory added to AbstractRoutingConnectionFactory will determine the general values of confirms and returns.
It may be useful if you have a case that certain messages you would to check confirms/returns and others you don’t. For example:
@Bean
public RabbitTemplate rabbitTemplate() {
final com.rabbitmq.client.ConnectionFactory cf = new com.rabbitmq.client.ConnectionFactory();
cf.setHost("localhost");
cf.setPort(5672);
CachingConnectionFactory cachingConnectionFactory = new CachingConnectionFactory(cf);
cachingConnectionFactory.setPublisherConfirmType(CachingConnectionFactory.ConfirmType.CORRELATED);
PooledChannelConnectionFactory pooledChannelConnectionFactory = new PooledChannelConnectionFactory(cf);
final Map<Object, ConnectionFactory> connectionFactoryMap = new HashMap<>(2);
connectionFactoryMap.put("true", cachingConnectionFactory);
connectionFactoryMap.put("false", pooledChannelConnectionFactory);
final AbstractRoutingConnectionFactory routingConnectionFactory = new SimpleRoutingConnectionFactory();
routingConnectionFactory.setConsistentConfirmsReturns(false);
routingConnectionFactory.setDefaultTargetConnectionFactory(pooledChannelConnectionFactory);
routingConnectionFactory.setTargetConnectionFactories(connectionFactoryMap);
final RabbitTemplate rabbitTemplate = new RabbitTemplate(routingConnectionFactory);
final Expression sendExpression = new SpelExpressionParser().parseExpression(
"messageProperties.headers['x-use-publisher-confirms'] ?: false");
rabbitTemplate.setSendConnectionFactorySelectorExpression(sendExpression);
}This way messages with the header x-use-publisher-confirms: true will be sent through the caching connection, and you can ensure the message delivery.
See Publisher Confirms and Returns for more information about ensuring message delivery.
Queue Affinity and the LocalizedQueueConnectionFactory
When using HA queues in a cluster, for the best performance, you may want to connect to the physical broker
where the lead queue resides.
The CachingConnectionFactory can be configured with multiple broker addresses.
This is to fail over and the client attempts to connect in accordance with the configured AddressShuffleMode order.
The LocalizedQueueConnectionFactory uses the REST API provided by the management plugin to determine which node is the lead for the queue.
It then creates (or retrieves from a cache) a CachingConnectionFactory that connects to just that node.
If the connection fails, the new lead node is determined and the consumer connects to it.
The LocalizedQueueConnectionFactory is configured with a default connection factory, in case the physical location of the queue cannot be determined, in which case it connects as normal to the cluster.
The LocalizedQueueConnectionFactory is a RoutingConnectionFactory and the SimpleMessageListenerContainer uses the queue names as the lookup key as discussed in Routing Connection Factory above.
For this reason (the use of the queue name for the lookup), the LocalizedQueueConnectionFactory can only be used if the container is configured to listen to a single queue.
|
| The RabbitMQ management plugin must be enabled on each node. |
This connection factory is intended for long-lived connections, such as those used by the SimpleMessageListenerContainer.
It is not intended for short connection use, such as with a RabbitTemplate because of the overhead of invoking the REST API before making the connection.
Also, for publish operations, the queue is unknown, and the message is published to all cluster members anyway, so the logic of looking up the node has little value.
|
The following example configuration shows how to configure the factories:
@Autowired
private ConfigurationProperties props;
@Bean
public CachingConnectionFactory defaultConnectionFactory() {
CachingConnectionFactory cf = new CachingConnectionFactory();
cf.setAddresses(this.props.getAddresses());
cf.setUsername(this.props.getUsername());
cf.setPassword(this.props.getPassword());
cf.setVirtualHost(this.props.getVirtualHost());
return cf;
}
@Bean
public LocalizedQueueConnectionFactory queueAffinityCF(
@Qualifier("defaultConnectionFactory") ConnectionFactory defaultCF) {
return new LocalizedQueueConnectionFactory(defaultCF,
StringUtils.commaDelimitedListToStringArray(this.props.getAddresses()),
StringUtils.commaDelimitedListToStringArray(this.props.getAdminUris()),
StringUtils.commaDelimitedListToStringArray(this.props.getNodes()),
this.props.getVirtualHost(), this.props.getUsername(), this.props.getPassword(),
false, null);
}Notice that the first three parameters are arrays of addresses, adminUris, and nodes.
These are positional in that, when a container attempts to connect to a queue, it uses the admin API to determine which node is the lead for the queue and connects to the address in the same array position as that node.
Starting with version 3.0, the RabbitMQ http-client is no longer used to access the Rest API.
Instead, by default, the WebClient from Spring Webflux is used if spring-webflux is on the class path; otherwise a RestTemplate is used.
|
To add WebFlux to the class path:
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>compile 'org.springframework.amqp:spring-rabbit'You can also use other REST technology by implementing LocalizedQueueConnectionFactory.NodeLocator and overriding its createClient, ``restCall, and optionally, close methods.
lqcf.setNodeLocator(new NodeLocator<MyClient>() {
@Override
public MyClient createClient(String userName, String password) {
...
}
@Override
public HashMap<String, Object> restCall(MyClient client, URI uri) {
...
});
});The framework provides the WebFluxNodeLocator and RestTemplateNodeLocator, with the default as discussed above.
Publisher Confirms and Returns
Confirmed (with correlation) and returned messages are supported by setting the CachingConnectionFactory property publisherConfirmType to ConfirmType.CORRELATED and the publisherReturns property to 'true'.
When these options are set, Channel instances created by the factory are wrapped in an PublisherCallbackChannel, which is used to facilitate the callbacks.
When such a channel is obtained, the client can register a PublisherCallbackChannel.Listener with the Channel.
The PublisherCallbackChannel implementation contains logic to route a confirm or return to the appropriate listener.
These features are explained further in the following sections.
See also Correlated Publisher Confirms and Returns and simplePublisherConfirms in Scoped Operations.
| For some more background information, see the blog post by the RabbitMQ team titled Introducing Publisher Confirms. |
Connection and Channel Listeners
The connection factory supports registering ConnectionListener and ChannelListener implementations.
This allows you to receive notifications for connection and channel related events.
(A ConnectionListener is used by the RabbitAdmin to perform declarations when the connection is established - see Automatic Declaration of Exchanges, Queues, and Bindings for more information).
The following listing shows the ConnectionListener interface definition:
@FunctionalInterface
public interface ConnectionListener {
void onCreate(Connection connection);
default void onClose(Connection connection) {
}
default void onShutDown(ShutdownSignalException signal) {
}
}Starting with version 2.0, the org.springframework.amqp.rabbit.connection.Connection object can be supplied with com.rabbitmq.client.BlockedListener instances to be notified for connection blocked and unblocked events.
The following example shows the ChannelListener interface definition:
@FunctionalInterface
public interface ChannelListener {
void onCreate(Channel channel, boolean transactional);
default void onShutDown(ShutdownSignalException signal) {
}
}See Publishing is Asynchronous — How to Detect Successes and Failures for one scenario where you might want to register a ChannelListener.
Logging Channel Close Events
Version 1.5 introduced a mechanism to enable users to control logging levels.
The AbstractConnectionFactory uses a default strategy to log channel closures as follows:
-
Normal channel closes (200 OK) are not logged.
-
If a channel is closed due to a failed passive queue declaration, it is logged at DEBUG level.
-
If a channel is closed because the
basic.consumeis refused due to an exclusive consumer condition, it is logged at DEBUG level (since 3.1, previously INFO). -
All others are logged at ERROR level.
To modify this behavior, you can inject a custom ConditionalExceptionLogger into the
CachingConnectionFactory in its closeExceptionLogger property.
Also, the AbstractConnectionFactory.DefaultChannelCloseLogger is now public, allowing it to be sub classed.
See also Consumer Events.
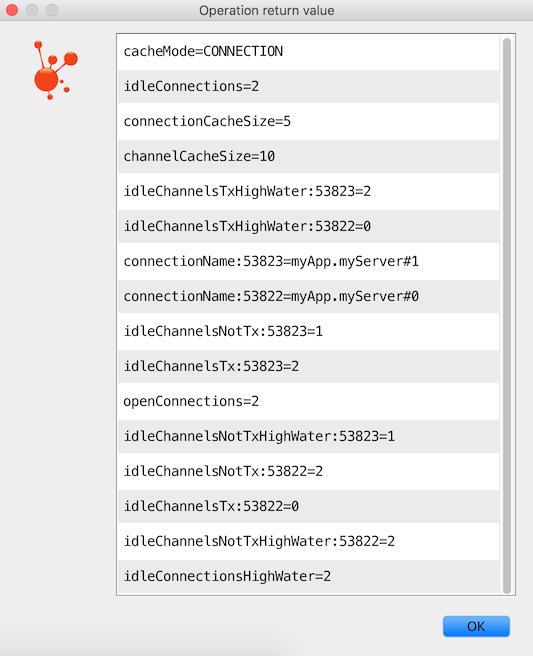
Runtime Cache Properties
Staring with version 1.6, the CachingConnectionFactory now provides cache statistics through the getCacheProperties()
method.
These statistics can be used to tune the cache to optimize it in production.
For example, the high water marks can be used to determine whether the cache size should be increased.
If it equals the cache size, you might want to consider increasing further.
The following table describes the CacheMode.CHANNEL properties:
| Property | Meaning |
|---|---|
connectionName |
The name of the connection generated by the |
channelCacheSize |
The currently configured maximum channels that are allowed to be idle. |
localPort |
The local port for the connection (if available). This can be used to correlate with connections and channels on the RabbitMQ Admin UI. |
idleChannelsTx |
The number of transactional channels that are currently idle (cached). |
idleChannelsNotTx |
The number of non-transactional channels that are currently idle (cached). |
idleChannelsTxHighWater |
The maximum number of transactional channels that have been concurrently idle (cached). |
idleChannelsNotTxHighWater |
The maximum number of non-transactional channels have been concurrently idle (cached). |
The following table describes the CacheMode.CONNECTION properties:
| Property | Meaning |
|---|---|
connectionName:<localPort> |
The name of the connection generated by the |
openConnections |
The number of connection objects representing connections to brokers. |
channelCacheSize |
The currently configured maximum channels that are allowed to be idle. |
connectionCacheSize |
The currently configured maximum connections that are allowed to be idle. |
idleConnections |
The number of connections that are currently idle. |
idleConnectionsHighWater |
The maximum number of connections that have been concurrently idle. |
idleChannelsTx:<localPort> |
The number of transactional channels that are currently idle (cached) for this connection.
You can use the |
idleChannelsNotTx:<localPort> |
The number of non-transactional channels that are currently idle (cached) for this connection.
The |
idleChannelsTxHighWater:<localPort> |
The maximum number of transactional channels that have been concurrently idle (cached). The localPort part of the property name can be used to correlate with connections and channels on the RabbitMQ Admin UI. |
idleChannelsNotTxHighWater:<localPort> |
The maximum number of non-transactional channels have been concurrently idle (cached).
You can use the |
The cacheMode property (CHANNEL or CONNECTION) is also included.
RabbitMQ Automatic Connection/Topology recovery
Since the first version of Spring AMQP, the framework has provided its own connection and channel recovery in the event of a broker failure.
Also, as discussed in Configuring the Broker, the RabbitAdmin re-declares any infrastructure beans (queues and others) when the connection is re-established.
It therefore does not rely on the auto-recovery that is now provided by the amqp-client library.
The amqp-client, has auto recovery enabled by default.
There are some incompatibilities between the two recovery mechanisms so, by default, Spring sets the automaticRecoveryEnabled property on the underlying RabbitMQ connectionFactory to false.
Even if the property is true, Spring effectively disables it, by immediately closing any recovered connections.
| By default, only elements (queues, exchanges, bindings) that are defined as beans will be re-declared after a connection failure. See Recovering Auto-Delete Declarations for how to change that behavior. |

