Partitioning
Spring Cloud Stream provides support for partitioning data between multiple instances of a given application. In a partitioned scenario, the physical communication medium (such as the broker topic) is viewed as being structured into multiple partitions. One or more producer application instances send data to multiple consumer application instances and ensure that data identified by common characteristics are processed by the same consumer instance.
Spring Cloud Stream provides a common abstraction for implementing partitioned processing use cases in a uniform fashion. Partitioning can thus be used whether the broker itself is naturally partitioned (for example, Kafka) or not (for example, RabbitMQ).
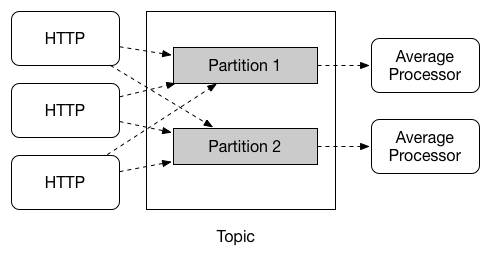
Partitioning is a critical concept in stateful processing, where it is critical (for either performance or consistency reasons) to ensure that all related data is processed together. For example, in the time-windowed average calculation example, it is important that all measurements from any given sensor are processed by the same application instance.
| To set up a partitioned processing scenario, you must configure both the data-producing and the data-consuming ends. |
Partitioning in Spring Cloud Stream consists of two tasks:
Configuring Output Bindings for Partitioning
You can configure an output binding to send partitioned data by setting one and only one of its partitionKeyExpression or partitionKeyExtractorName properties, as well as its partitionCount property.
For example, the following is a valid and typical configuration:
spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExpression=headers.id spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
Based on that example configuration, data is sent to the target partition by using the following logic.
A partition key’s value is calculated for each message sent to a partitioned output binding based on the partitionKeyExpression.
The partitionKeyExpression is a SpEL expression that is evaluated against the outbound message (in the preceding example it’s the value of the id from message headers) for extracting the partitioning key.
If a SpEL expression is not sufficient for your needs, you can instead calculate the partition key value by providing an implementation of org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy and configuring it as a bean (by using the @Bean annotation).
If you have more then one bean of type org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy available in the Application Context, you can further filter it by specifying its name with the partitionKeyExtractorName property, as shown in the following example:
--spring.cloud.stream.bindings.func-out-0.producer.partitionKeyExtractorName=customPartitionKeyExtractor
--spring.cloud.stream.bindings.func-out-0.producer.partitionCount=5
. . .
@Bean
public CustomPartitionKeyExtractorClass customPartitionKeyExtractor() {
return new CustomPartitionKeyExtractorClass();
}
In previous versions of Spring Cloud Stream, you could specify the implementation of org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy by setting the spring.cloud.stream.bindings.output.producer.partitionKeyExtractorClass property.
Since version 3.0, this property is removed.
|
Once the message key is calculated, the partition selection process determines the target partition as a value between 0 and partitionCount - 1.
The default calculation, applicable in most scenarios, is based on the following formula: key.hashCode() % partitionCount.
This can be customized on the binding, either by setting a SpEL expression to be evaluated against the 'key' (through the partitionSelectorExpression property) or by configuring an implementation of org.springframework.cloud.stream.binder.PartitionSelectorStrategy as a bean (by using the @Bean annotation).
Similar to the PartitionKeyExtractorStrategy, you can further filter it by using the spring.cloud.stream.bindings.output.producer.partitionSelectorName property when more than one bean of this type is available in the Application Context, as shown in the following example:
--spring.cloud.stream.bindings.func-out-0.producer.partitionSelectorName=customPartitionSelector
. . .
@Bean
public CustomPartitionSelectorClass customPartitionSelector() {
return new CustomPartitionSelectorClass();
}
In previous versions of Spring Cloud Stream you could specify the implementation of org.springframework.cloud.stream.binder.PartitionSelectorStrategy by setting the spring.cloud.stream.bindings.output.producer.partitionSelectorClass property.
Since version 3.0, this property is removed.
|
Configuring Input Bindings for Partitioning
An input binding (with the binding name uppercase-in-0) is configured to receive partitioned data by setting its partitioned
property, as well as the instanceIndex and instanceCount properties on the application itself, as shown in the following example:
spring.cloud.stream.bindings.uppercase-in-0.consumer.partitioned=true spring.cloud.stream.instanceIndex=3 spring.cloud.stream.instanceCount=5
The instanceCount value represents the total number of application instances between which the data should be partitioned.
The instanceIndex must be a unique value across the multiple instances, with a value between 0 and instanceCount - 1.
The instance index helps each application instance to identify the unique partition(s) from which it receives data.
It is required by binders using technology that does not support partitioning natively.
For example, with RabbitMQ, there is a queue for each partition, with the queue name containing the instance index.
With Kafka, if autoRebalanceEnabled is true (default), Kafka takes care of distributing partitions across instances, and these properties are not required.
If autoRebalanceEnabled is set to false, the instanceCount and instanceIndex are used by the binder to determine which partition(s) the instance subscribes to (you must have at least as many partitions as there are instances).
The binder allocates the partitions instead of Kafka.
This might be useful if you want messages for a particular partition to always go to the same instance.
When a binder configuration requires them, it is important to set both values correctly in order to ensure that all of the data is consumed and that the application instances receive mutually exclusive datasets.
While a scenario in which using multiple instances for partitioned data processing may be complex to set up in a standalone case, Spring Cloud Dataflow can simplify the process significantly by populating both the input and output values correctly and by letting you rely on the runtime infrastructure to provide information about the instance index and instance count.

