NVIDIA Chat
NVIDIA LLM API is a proxy AI Inference Engine offering a wide range of models from various providers.
Spring AI integrates with the NVIDIA LLM API by reusing the existing OpenAI client.
For this you need to set the base-url to https://integrate.api.nvidia.com, select one of the provided LLM models and get an api-key for it.
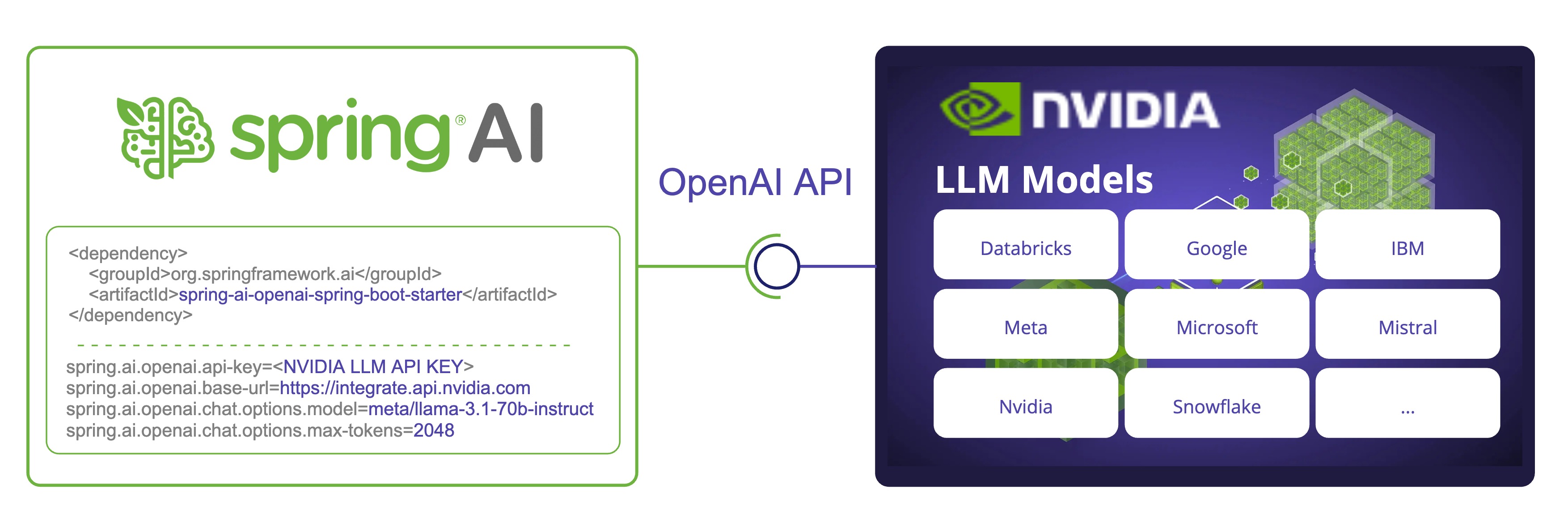
NVIDIA LLM API requires the max-tokens parameter to be explicitly set or server error will be thrown.
|
Check the NvidiaWithOpenAiChatModelIT.java tests for examples of using NVIDIA LLM API with Spring AI.
Prerequisite
-
Create NVIDIA account with sufficient credits.
-
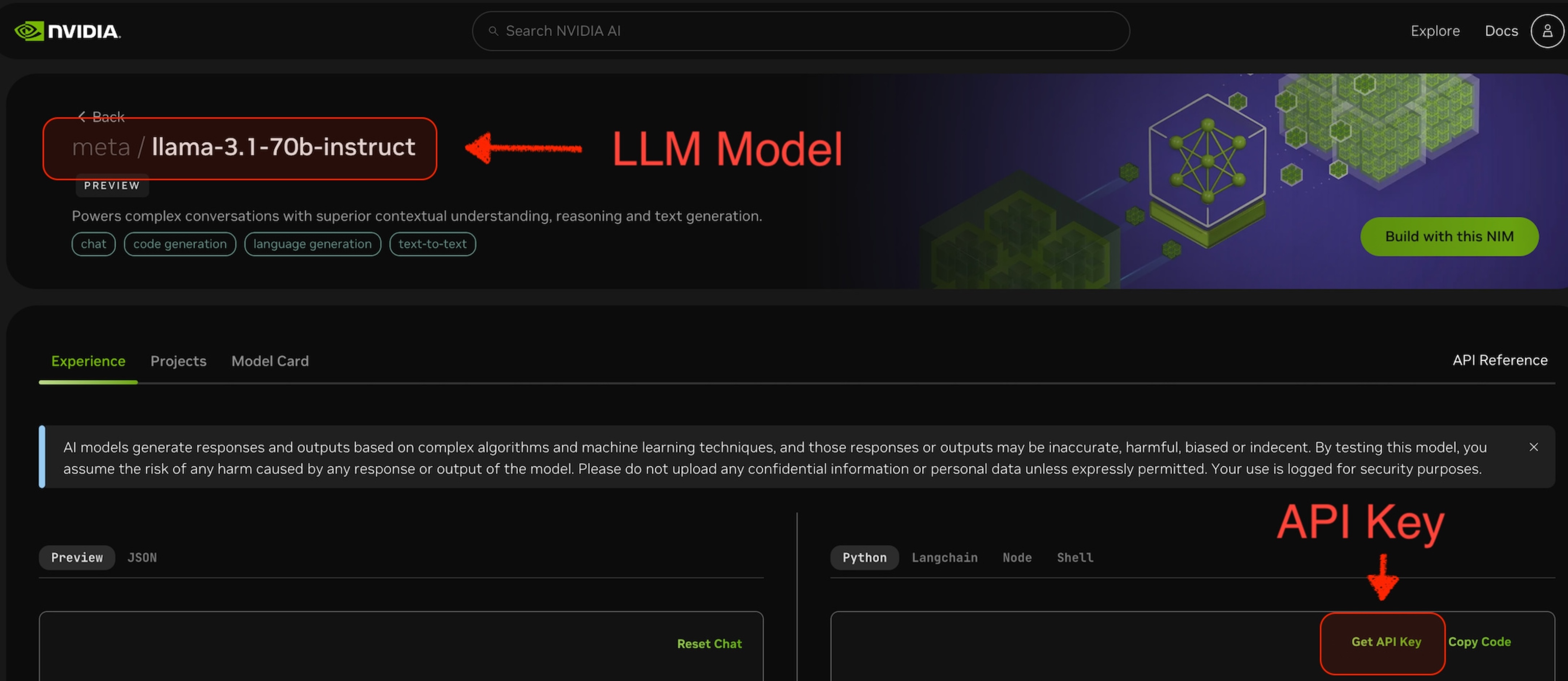
Select a LLM Model to use. For example the
meta/llama-3.1-70b-instructin the screenshot below. -
From the selected model’s page, you can get the
api-keyfor accessing this model.
Auto-configuration
|
There has been a significant change in the Spring AI auto-configuration, starter modules' artifact names. Please refer to the upgrade notes for more information. |
Spring AI provides Spring Boot auto-configuration for the OpenAI Chat Client.
To enable it add the following dependency to your project’s Maven pom.xml file:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>or to your Gradle build.gradle build file.
dependencies {
implementation 'org.springframework.ai:spring-ai-starter-model-openai'
}| Refer to the Dependency Management section to add the Spring AI BOM to your build file. |
Chat Properties
Retry Properties
The prefix spring.ai.retry is used as the property prefix that lets you configure the retry mechanism for the OpenAI chat model.
| Property | Description | Default |
|---|---|---|
spring.ai.retry.max-attempts |
Maximum number of retry attempts. |
10 |
spring.ai.retry.backoff.initial-interval |
Initial sleep duration for the exponential backoff policy. |
2 sec. |
spring.ai.retry.backoff.multiplier |
Backoff interval multiplier. |
5 |
spring.ai.retry.backoff.max-interval |
Maximum backoff duration. |
3 min. |
spring.ai.retry.on-client-errors |
If false, throw a NonTransientAiException, and do not attempt retry for |
false |
spring.ai.retry.exclude-on-http-codes |
List of HTTP status codes that should not trigger a retry (e.g. to throw NonTransientAiException). |
empty |
spring.ai.retry.on-http-codes |
List of HTTP status codes that should trigger a retry (e.g. to throw TransientAiException). |
empty |
Connection Properties
The prefix spring.ai.openai is used as the property prefix that lets you connect to OpenAI.
| Property | Description | Default |
|---|---|---|
spring.ai.openai.base-url |
The URL to connect to. Must be set to |
- |
spring.ai.openai.api-key |
The NVIDIA API Key |
- |
Configuration Properties
|
Enabling and disabling of the chat auto-configurations are now configured via top level properties with the prefix To enable, spring.ai.model.chat=openai (It is enabled by default) To disable, spring.ai.model.chat=none (or any value which doesn’t match openai) This change is done to allow configuration of multiple models. |
The prefix spring.ai.openai.chat is the property prefix that lets you configure the chat model implementation for OpenAI.
| Property | Description | Default |
|---|---|---|
spring.ai.openai.chat.enabled (Removed and no longer valid) |
Enable OpenAI chat model. |
true |
spring.ai.model.chat |
Enable OpenAI chat model. |
openai |
spring.ai.openai.chat.base-url |
Optional overrides the spring.ai.openai.base-url to provide chat specific url. Must be set to |
- |
spring.ai.openai.chat.api-key |
Optional overrides the spring.ai.openai.api-key to provide chat specific api-key |
- |
spring.ai.openai.chat.model |
The NVIDIA LLM model to use |
- |
spring.ai.openai.chat.temperature |
The sampling temperature to use that controls the apparent creativity of generated completions. Higher values will make output more random while lower values will make results more focused and deterministic. It is not recommended to modify temperature and top_p for the same completions request as the interaction of these two settings is difficult to predict. |
0.8 |
spring.ai.openai.chat.frequency-penalty |
Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the model’s likelihood to repeat the same line verbatim. |
0.0f |
spring.ai.openai.chat.max-tokens |
The maximum number of tokens to generate in the chat completion. The total length of input tokens and generated tokens is limited by the model’s context length. |
NOTE: NVIDIA LLM API requires the |
spring.ai.openai.chat.n |
How many chat completion choices to generate for each input message. Note that you will be charged based on the number of generated tokens across all of the choices. Keep n as 1 to minimize costs. |
1 |
spring.ai.openai.chat.presence-penalty |
Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model’s likelihood to talk about new topics. |
- |
spring.ai.openai.chat.response-format |
An object specifying the format that the model must output. Setting to |
- |
spring.ai.openai.chat.seed |
This feature is in Beta. If specified, our system will make a best effort to sample deterministically, such that repeated requests with the same seed and parameters should return the same result. |
- |
spring.ai.openai.chat.stop |
Up to 4 sequences where the API will stop generating further tokens. |
- |
spring.ai.openai.chat.top-p |
An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. We generally recommend altering this or temperature but not both. |
- |
spring.ai.openai.chat.tools |
A list of tools the model may call. Currently, only functions are supported as a tool. Use this to provide a list of functions the model may generate JSON inputs for. |
- |
spring.ai.openai.chat.tool-choice |
Controls which (if any) function is called by the model. none means the model will not call a function and instead generates a message. auto means the model can pick between generating a message or calling a function. Specifying a particular function via {"type: "function", "function": {"name": "my_function"}} forces the model to call that function. none is the default when no functions are present. auto is the default if functions are present. |
- |
spring.ai.openai.chat.user |
A unique identifier representing your end-user, which can help OpenAI to monitor and detect abuse. |
- |
spring.ai.openai.chat.stream-usage |
(For streaming only) Set to add an additional chunk with token usage statistics for the entire request. The |
false |
spring.ai.openai.chat.tool-callbacks |
Tool Callbacks to register with the ChatModel. |
- |
All properties prefixed with spring.ai.openai.chat can be overridden at runtime by adding a request specific Runtime Options to the Prompt call.
|
Runtime Options
The OpenAiChatOptions.java provides model configurations, such as the model to use, the temperature, the frequency penalty, etc.
On start-up, the default options can be configured with the OpenAiChatModel(api, options) constructor or the spring.ai.openai.chat.* properties.
At run-time you can override the default options by adding new, request specific, options to the Prompt call.
For example to override the default model and temperature for a specific request:
ChatResponse response = chatModel.call(
new Prompt(
"Generate the names of 5 famous pirates.",
OpenAiChatOptions.builder()
.model("mixtral-8x7b-32768")
.temperature(0.4)
.build()
));| In addition to the model specific OpenAiChatOptions you can use a portable ChatOptions instance, created with the ChatOptions#builder(). |
Function Calling
NVIDIA LLM API supports Tool/Function calling when selecting a model that supports it.
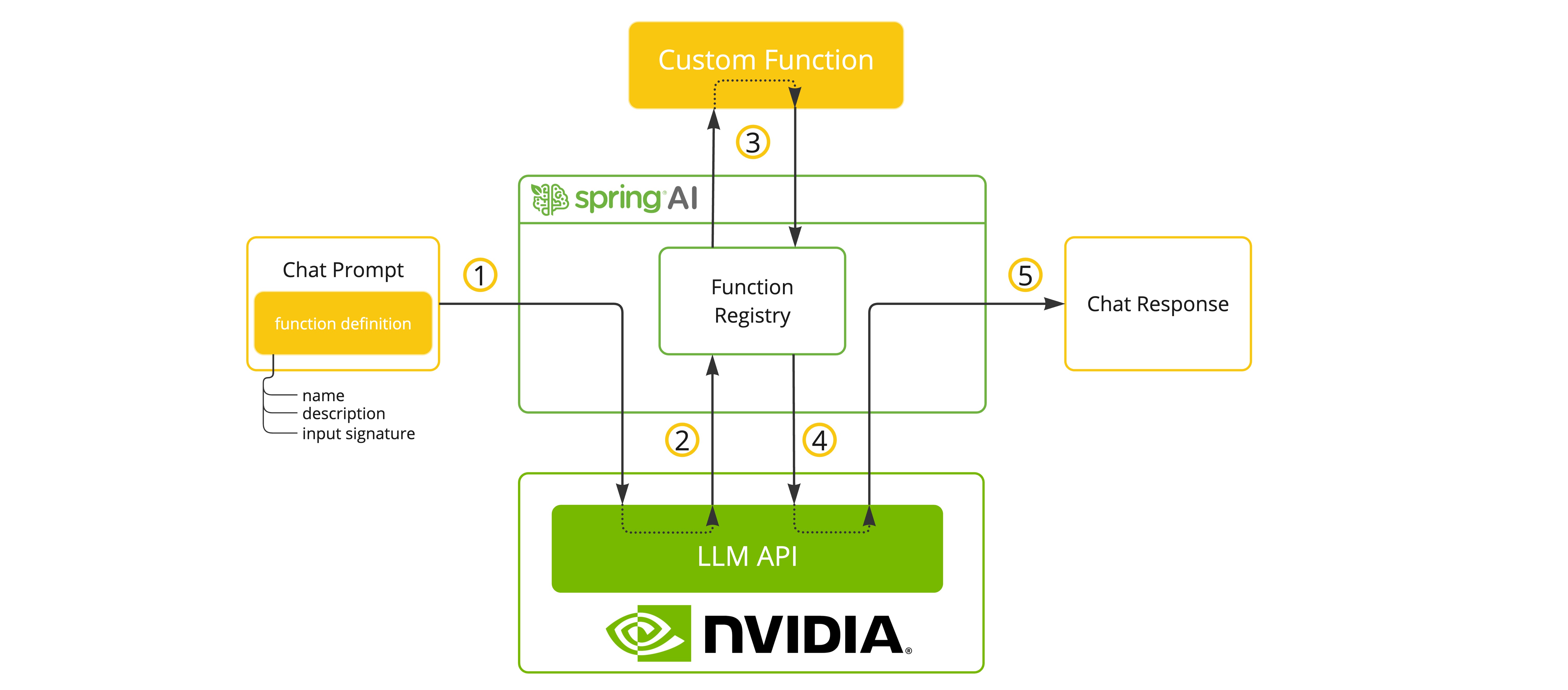
You can register custom Java functions with your ChatModel and have the provided model intelligently choose to output a JSON object containing arguments to call one or many of the registered functions. This is a powerful technique to connect the LLM capabilities with external tools and APIs.
Tool Example
Here’s a simple example of how to use NVIDIA LLM API tool calling with Spring AI:
spring.ai.openai.api-key=${NVIDIA_API_KEY}
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.model=meta/llama-3.1-70b-instruct
spring.ai.openai.chat.max-tokens=2048public class WeatherService implements Function<WeatherService.Request, WeatherService.Response> {
public record Request(String location, String unit) {}
public record Response(double temp, String unit) {}
@Override
public Response apply(Request request) {
double temperature = request.location().contains("Amsterdam") ? 20 : 25;
return new Response(temperature, request.unit);
}
}ToolCallback weatherCallback = FunctionToolCallback.builder("getCurrentWeather", new WeatherService())
.description("Get the weather in location")
.inputType(WeatherService.Request.class)
.build();
var response = chatClient.prompt()
.user("What is the weather in Amsterdam and Paris?")
.tools(weatherCallback)
.call()
.content();In this example, when the model needs weather information, it will automatically call the WeatherService, which can then fetch real-time weather data.
The expected response looks like this: "The weather in Amsterdam is currently 20 degrees Celsius, and the weather in Paris is currently 25 degrees Celsius."
Read more about Tool Calling.
Sample Controller
Create a new Spring Boot project and add the spring-ai-starter-model-openai to your pom (or gradle) dependencies.
Add a application.properties file, under the src/main/resources directory, to enable and configure the OpenAi chat model:
spring.ai.openai.api-key=${NVIDIA_API_KEY}
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.model=meta/llama-3.1-70b-instruct
# The NVIDIA LLM API doesn't support embeddings, so we need to disable it.
spring.ai.model.embedding=none
# The NVIDIA LLM API requires this parameter to be set explicitly or server internal error will be thrown.
spring.ai.openai.chat.max-tokens=2048
replace the api-key with your NVIDIA credentials.
|
NVIDIA LLM API requires the max-token parameter to be explicitly set or server error will be thrown.
|
Here is an example of a simple @Controller class that uses the chat model for text generations.
@RestController
public class ChatController {
private final OpenAiChatModel chatModel;
@Autowired
public ChatController(OpenAiChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}
