Ollama Chat
With Ollama you can run various Large Language Models (LLMs) locally and generate text from them.
Spring AI supports the Ollama text generation with OllamaChatClient.
Prerequisites
You first need to run Ollama on your local machine. Refer to the official Ollama project README to get started running models on your local machine.
installing ollama run llama2 will download a 4GB docker image.
|
Add Repositories and BOM
Spring AI artifacts are published in Spring Milestone and Snapshot repositories. Refer to the Repositories section to add these repositories to your build system.
To help with dependency management, Spring AI provides a BOM (bill of materials) to ensure that a consistent version of Spring AI is used throughout the entire project. Refer to the Dependency Management section to add the Spring AI BOM to your build system.
Auto-configuration
Spring AI provides Spring Boot auto-configuration for the Ollama Chat Client.
To enable it add the following dependency to your project’s Maven pom.xml file:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>or to your Gradle build.gradle build file.
dependencies {
implementation 'org.springframework.ai:spring-ai-ollama-spring-boot-starter'
}| Refer to the Dependency Management section to add the Spring AI BOM to your build file. |
Chat Properties
The prefix spring.ai.ollama is the property prefix to configure the connection to Ollama
| Property | Description | Default |
|---|---|---|
spring.ai.ollama.base-url |
Base URL where Ollama API server is running. |
The prefix spring.ai.ollama.chat.options is the property prefix that configures the chat client implementation for Ollama.
The options properties are based on the Ollama Valid Parameters and Values and Ollama Types. The default values are based on: Ollama type defaults.
|
| Property | Description | Default |
|---|---|---|
spring.ai.ollama.chat.enabled |
Enable Ollama chat client. |
true |
spring.ai.ollama.chat.options.model |
The name of the supported models to use. |
mistral |
spring.ai.ollama.chat.options.numa |
Whether to use NUMA. |
false |
spring.ai.ollama.chat.options.num-ctx |
Sets the size of the context window used to generate the next token. |
2048 |
spring.ai.ollama.chat.options.num-batch |
??? |
512 |
spring.ai.ollama.chat.options.num-gqa |
The number of GQA groups in the transformer layer. Required for some models, for example, it is 8 for llama2:70b. |
1 |
spring.ai.ollama.chat.options.num-gpu |
The number of layers to send to the GPU(s). On macOS it defaults to 1 to enable metal support, 0 to disable. 1 here indicates that NumGPU should be set dynamically |
-1 |
spring.ai.ollama.chat.options.main-gpu |
??? |
- |
spring.ai.ollama.chat.options.low-vram |
??? |
false |
spring.ai.ollama.chat.options.f16-kv |
??? |
true |
spring.ai.ollama.chat.options.logits-all |
??? |
- |
spring.ai.ollama.chat.options.vocab-only |
??? |
- |
spring.ai.ollama.chat.options.use-mmap |
??? |
true |
spring.ai.ollama.chat.options.use-mlock |
??? |
false |
spring.ai.ollama.chat.options.embedding-only |
??? |
false |
spring.ai.ollama.chat.options.rope-frequency-base |
??? |
10000.0 |
spring.ai.ollama.chat.options.rope-frequency-scale |
??? |
1.0 |
spring.ai.ollama.chat.options.num-thread |
Sets the number of threads to use during computation. By default, Ollama will detect this for optimal performance. It is recommended to set this value to the number of physical CPU cores your system has (as opposed to the logical number of cores). 0 = let the runtime decide |
0 |
spring.ai.ollama.chat.options.num-keep |
??? |
0 |
spring.ai.ollama.chat.options.seed |
Sets the random number seed to use for generation. Setting this to a specific number will make the model generate the same text for the same prompt. |
-1 |
spring.ai.ollama.chat.options.num-predict |
Maximum number of tokens to predict when generating text. (-1 = infinite generation, -2 = fill context) |
-1 |
spring.ai.ollama.chat.options.top-k |
Reduces the probability of generating nonsense. A higher value (e.g., 100) will give more diverse answers, while a lower value (e.g., 10) will be more conservative. |
40 |
spring.ai.ollama.chat.options.top-p |
Works together with top-k. A higher value (e.g., 0.95) will lead to more diverse text, while a lower value (e.g., 0.5) will generate more focused and conservative text. |
0.9 |
spring.ai.ollama.chat.options.tfs-z |
Tail-free sampling is used to reduce the impact of less probable tokens from the output. A higher value (e.g., 2.0) will reduce the impact more, while a value of 1.0 disables this setting. |
1.0 |
spring.ai.ollama.chat.options.typical-p |
??? |
1.0 |
spring.ai.ollama.chat.options.repeat-last-n |
Sets how far back for the model to look back to prevent repetition. (Default: 64, 0 = disabled, -1 = num_ctx) |
64 |
spring.ai.ollama.chat.options.temperature |
The temperature of the model. Increasing the temperature will make the model answer more creatively. |
0.8 |
spring.ai.ollama.chat.options.repeat-penalty |
Sets how strongly to penalize repetitions. A higher value (e.g., 1.5) will penalize repetitions more strongly, while a lower value (e.g., 0.9) will be more lenient. |
1.1 |
spring.ai.ollama.chat.options.presence-penalty |
??? |
0.0 |
spring.ai.ollama.chat.options.frequency-penalty |
??? |
0.0 |
spring.ai.ollama.chat.options.mirostat |
Enable Mirostat sampling for controlling perplexity. (default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0) |
0 |
spring.ai.ollama.chat.options.mirostat-tau |
Influences how quickly the algorithm responds to feedback from the generated text. A lower learning rate will result in slower adjustments, while a higher learning rate will make the algorithm more responsive. |
5.0 |
spring.ai.ollama.chat.options.mirostat-eta |
Controls the balance between coherence and diversity of the output. A lower value will result in more focused and coherent text. |
0.1 |
spring.ai.ollama.chat.options.penalize-newline |
??? |
true |
spring.ai.ollama.chat.options.stop |
Sets the stop sequences to use. When this pattern is encountered the LLM will stop generating text and return. Multiple stop patterns may be set by specifying multiple separate stop parameters in a modelfile. |
- |
| The list of options for chat is to be reviewed. This issue will track progress. |
All properties prefixed with spring.ai.ollama.chat.options can be overridden at runtime by adding a request specific Chat Options to the Prompt call.
|
Chat Options
The OllamaOptions.java provides model configurations, such as the model to use, the temperature, etc.
On start-up, the default options can be configured with the OllamaChatClient(api, options) constructor or the spring.ai.ollama.chat.options.* properties.
At run-time you can override the default options by adding new, request specific, options to the Prompt call.
For example to override the default model and temperature for a specific request:
ChatResponse response = chatClient.call(
new Prompt(
"Generate the names of 5 famous pirates.",
OllamaOptions.create()
.withModel("llama2")
.withTemperature(0.4)
));| In addition to the model specific OllamaOptions you can use a portable ChatOptions instance, created with the ChatOptionsBuilder#builder(). |
Sample Controller (Auto-configuration)
Create a new Spring Boot project and add the spring-ai-openai-spring-boot-starter to your pom (or gradle) dependencies.
Add a application.properties file, under the src/main/resources directory, to enable and configure the OpenAi Chat client:
spring.ai.ollama.base-url=http://localhost:11434
spring.ai.ollama.chat.options.model=mistral
spring.ai.ollama.chat.options.temperature=0.7
replace the base-url with your Ollama server URL.
|
This will create a OllamaChatClient implementation that you can inject into your class.
Here is an example of a simple @Controller class that uses the chat client for text generations.
@RestController
public class ChatController {
private final OllamaChatClient chatClient;
@Autowired
public ChatController(OllamaChatClient chatClient) {
this.chatClient = chatClient;
}
@GetMapping("/ai/generate")
public Map generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", chatClient.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return chatClient.stream(prompt);
}
}Manual Configuration
If you don’t want to use the Spring Boot auto-configuration, you can manually configure the OllamaChatClient in your application.
The OllamaChatClient implements the ChatClient and StreamingChatClient and uses the Low-level OpenAiApi Client to connect to the Ollama service.
To use it add the spring-ai-ollama dependency to your project’s Maven pom.xml file:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama</artifactId>
</dependency>or to your Gradle build.gradle build file.
dependencies {
implementation 'org.springframework.ai:spring-ai-ollama'
}| Refer to the Dependency Management section to add the Spring AI BOM to your build file. |
The spring-ai-ollama dependency provides access also to the OllamaEmbeddingClient.
For more information about the OllamaEmbeddingClient refer to the Ollama Embedding Client section.
|
Next, create an OllamaChatClient instance and use it to text generations requests:
var ollamaApi = new OllamaApi();
var chatClient = new OllamaChatClient(ollamaApi).withModel(MODEL)
.withDefaultOptions(OllamaOptions.create()
.withModel(OllamaOptions.DEFAULT_MODEL)
.withTemperature(0.9f));
ChatResponse response = chatClient.call(
new Prompt("Generate the names of 5 famous pirates."));
// Or with streaming responses
Flux<ChatResponse> response = chatClient.stream(
new Prompt("Generate the names of 5 famous pirates."));The OllamaOptions provides the configuration information for all chat requests.
Low-level OpenAiApi Client
The OllamaApi provides is lightweight Java client for Ollama Chat API Ollama Chat Completion API.
Following class diagram illustrates the OllamaApi chat interfaces and building blocks:
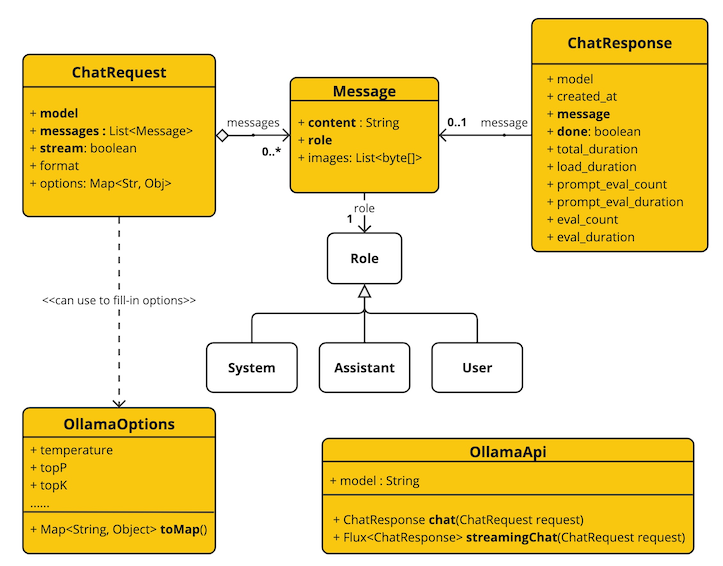
Here is a simple snippet how to use the api programmatically:
OllamaApi ollamaApi =
new OllamaApi("YOUR_HOST:YOUR_PORT");
// Sync request
var request = ChatRequest.builder("orca-mini")
.withStream(false) // not streaming
.withMessages(List.of(
Message.builder(Role.SYSTEM)
.withContent("You are geography teacher. You are talking to a student.")
.build(),
Message.builder(Role.USER)
.withContent("What is the capital of Bulgaria and what is the size? "
+ "What it the national anthem?")
.build()))
.withOptions(OllamaOptions.create().withTemperature(0.9f))
.build();
ChatResponse response = ollamaApi.chat(request);
// Streaming request
var request2 = ChatRequest.builder("orca-mini")
.withStream(true) // streaming
.withMessages(List.of(Message.builder(Role.USER)
.withContent("What is the capital of Bulgaria and what is the size? " + "What it the national anthem?")
.build()))
.withOptions(OllamaOptions.create().withTemperature(0.9f).toMap())
.build();
Flux<ChatResponse> streamingResponse = ollamaApi.streamingChat(request2);
