|
For the latest stable version, please use Spring AI 2.0.0! |
Advisors API
The Spring AI Advisors API provides a flexible and powerful way to intercept, modify, and enhance AI-driven interactions in your Spring applications. By leveraging the Advisors API, developers can create more sophisticated, reusable, and maintainable AI components.
The key benefits include encapsulating recurring Generative AI patterns, transforming data sent to and from Large Language Models (LLMs), and providing portability across various models and use cases.
You can configure existing advisors using the ChatClient API as shown in the following example:
ChatMemory chatMemory = ... // Initialize your chat memory store
VectorStore vectorStore = ... // Initialize your vector store
var chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build(), // chat-memory advisor
QuestionAnswerAdvisor.builder(vectorStore).build() // RAG advisor
)
.build();
var conversationId = "678";
String response = this.chatClient.prompt()
// Set advisor parameters at runtime
.advisors(advisor -> advisor.param(ChatMemory.CONVERSATION_ID, conversationId))
.user(userText)
.call()
.content();It is recommend to register the advisors at build time using builder’s defaultAdvisors() method.
Advisors also participate in the Observability stack, so you can view metrics and traces related to their execution.
Core Components
The API consists of CallAdvisor and CallAdvisorChain for non-streaming scenarios, and StreamAdvisor and StreamAdvisorChain for streaming scenarios.
It also includes ChatClientRequest to represent the unsealed Prompt request, ChatClientResponse for the Chat Completion response. Both hold an advise-context to share state across the advisor chain.
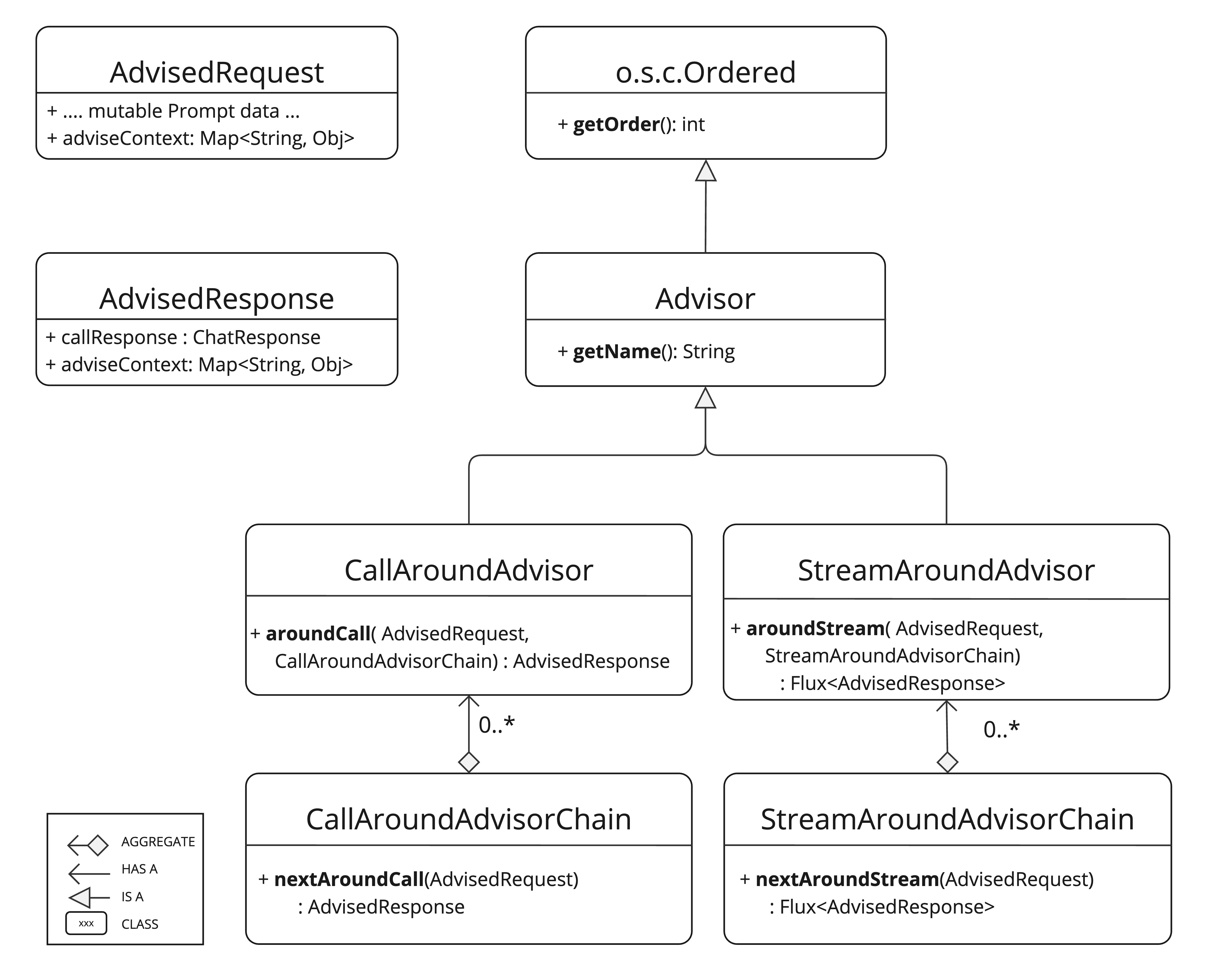
The adviseCall() and the adviseStream() are the key advisor methods, typically performing actions such as examining the unsealed Prompt data, customizing and augmenting the Prompt data, invoking the next entity in the advisor chain, optionally blocking the request, examining the chat completion response, and throwing exceptions to indicate processing errors.
In addition the getOrder() method determines advisor order in the chain, while getName() provides a unique advisor name.
The Advisor Chain, created by the Spring AI framework, allows sequential invocation of multiple advisors ordered by their getOrder() values.
The lower values are executed first.
The last advisor, added automatically, sends the request to the LLM.
Following flow diagram illustrates the interaction between the advisor chain and the Chat Model:
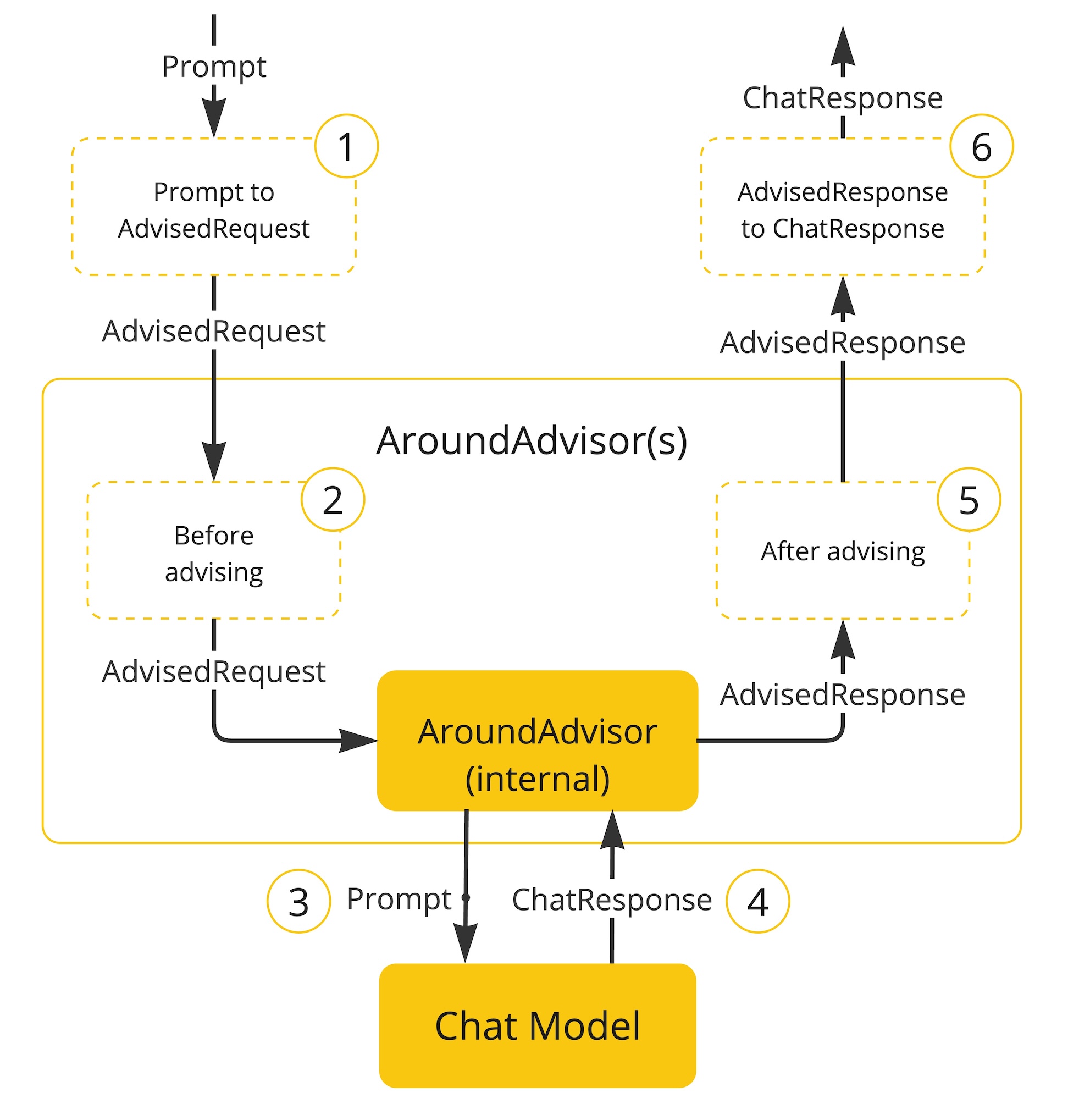
-
The Spring AI framework creates an
ChatClientRequestfrom user’sPromptalong with an empty advisorcontextobject. -
Each advisor in the chain processes the request, potentially modifying it. Alternatively, it can choose to block the request by not making the call to invoke the next entity. In the latter case, the advisor is responsible for filling out the response.
-
The final advisor, provided by the framework, sends the request to the
Chat Model. -
The Chat Model’s response is then passed back through the advisor chain and converted into
ChatClientResponse. Later includes the shared advisorcontextinstance. -
Each advisor can process or modify the response.
-
The final
ChatClientResponseis returned to the client by extracting theChatCompletion.
Advisor Order
The execution order of advisors in the chain is determined by the getOrder() method. Key points to understand:
-
Advisors with lower order values are executed first.
-
The advisor chain operates as a stack:
-
The first advisor in the chain is the first to process the request.
-
It is also the last to process the response.
-
-
To control execution order:
-
Set the order close to
Ordered.HIGHEST_PRECEDENCEto ensure an advisor is executed first in the chain (first for request processing, last for response processing). -
Set the order close to
Ordered.LOWEST_PRECEDENCEto ensure an advisor is executed last in the chain (last for request processing, first for response processing).
-
-
Higher values are interpreted as lower priority.
-
If multiple advisors have the same order value, their execution order is not guaranteed.
|
The seeming contradiction between order and execution sequence is due to the stack-like nature of the advisor chain:
|
As a reminder, here are the semantics of the Spring Ordered interface:
public interface Ordered {
/**
* Constant for the highest precedence value.
* @see java.lang.Integer#MIN_VALUE
*/
int HIGHEST_PRECEDENCE = Integer.MIN_VALUE;
/**
* Constant for the lowest precedence value.
* @see java.lang.Integer#MAX_VALUE
*/
int LOWEST_PRECEDENCE = Integer.MAX_VALUE;
/**
* Get the order value of this object.
* <p>Higher values are interpreted as lower priority. As a consequence,
* the object with the lowest value has the highest priority (somewhat
* analogous to Servlet {@code load-on-startup} values).
* <p>Same order values will result in arbitrary sort positions for the
* affected objects.
* @return the order value
* @see #HIGHEST_PRECEDENCE
* @see #LOWEST_PRECEDENCE
*/
int getOrder();
}|
For use cases that need to be first in the chain on both the input and output sides:
|
API Overview
The main Advisor interfaces are located in the package org.springframework.ai.chat.client.advisor.api. Here are the key interfaces you’ll encounter when creating your own advisor:
public interface Advisor extends Ordered {
String getName();
}The two sub-interfaces for synchronous and reactive Advisors are
public interface CallAdvisor extends Advisor {
ChatClientResponse adviseCall(
ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain);
}and
public interface StreamAdvisor extends Advisor {
Flux<ChatClientResponse> adviseStream(
ChatClientRequest chatClientRequest, StreamAdvisorChain streamAdvisorChain);
}To continue the chain of Advice, use CallAdvisorChain and StreamAdvisorChain in your Advice implementation:
The interfaces are
public interface CallAdvisorChain extends AdvisorChain {
/**
* Invokes the next {@link CallAdvisor} in the {@link CallAdvisorChain} with the given
* request.
*/
ChatClientResponse nextCall(ChatClientRequest chatClientRequest);
/**
* Returns the list of all the {@link CallAdvisor} instances included in this chain at
* the time of its creation.
*/
List<CallAdvisor> getCallAdvisors();
}and
public interface StreamAdvisorChain extends AdvisorChain {
/**
* Invokes the next {@link StreamAdvisor} in the {@link StreamAdvisorChain} with the
* given request.
*/
Flux<ChatClientResponse> nextStream(ChatClientRequest chatClientRequest);
/**
* Returns the list of all the {@link StreamAdvisor} instances included in this chain
* at the time of its creation.
*/
List<StreamAdvisor> getStreamAdvisors();
}Implementing an Advisor
To create an advisor, implement either CallAdvisor or StreamAdvisor (or both). The key method to implement is nextCall() for non-streaming or nextStream() for streaming advisors.
Examples
We will provide few hands-on examples to illustrate how to implement advisors for observing and augmenting use-cases.
Logging Advisor
We can implement a simple logging advisor that logs the ChatClientRequest before and the ChatClientResponse after the call to the next advisor in the chain.
Note that the advisor only observes the request and response and does not modify them.
This implementation support both non-streaming and streaming scenarios.
public class SimpleLoggerAdvisor implements CallAdvisor, StreamAdvisor {
private static final Logger logger = LoggerFactory.getLogger(SimpleLoggerAdvisor.class);
@Override
public String getName() { (1)
return this.getClass().getSimpleName();
}
@Override
public int getOrder() { (2)
return 0;
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
logRequest(chatClientRequest);
ChatClientResponse chatClientResponse = callAdvisorChain.nextCall(chatClientRequest);
logResponse(chatClientResponse);
return chatClientResponse;
}
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest,
StreamAdvisorChain streamAdvisorChain) {
logRequest(chatClientRequest);
Flux<ChatClientResponse> chatClientResponses = streamAdvisorChain.nextStream(chatClientRequest);
return new ChatClientMessageAggregator().aggregateChatClientResponse(chatClientResponses, this::logResponse); (3)
}
private void logRequest(ChatClientRequest request) {
logger.debug("request: {}", request);
}
private void logResponse(ChatClientResponse chatClientResponse) {
logger.debug("response: {}", chatClientResponse);
}
}| 1 | Provides a unique name for the advisor. |
| 2 | You can control the order of execution by setting the order value. Lower values execute first. |
| 3 | The MessageAggregator is a utility class that aggregates the Flux responses into a single ChatClientResponse.
This can be useful for logging or other processing that observe the entire response rather than individual items in the stream.
Note that you can not alter the response in the MessageAggregator as it is a read-only operation. |
Re-Reading (Re2) Advisor
The "Re-Reading Improves Reasoning in Large Language Models" article introduces a technique called Re-Reading (Re2) that improves the reasoning capabilities of Large Language Models. The Re2 technique requires augmenting the input prompt like this:
{Input_Query}
Read the question again: {Input_Query}
Implementing an advisor that applies the Re2 technique to the user’s input query can be done like this:
public class ReReadingAdvisor implements BaseAdvisor {
private static final String DEFAULT_RE2_ADVISE_TEMPLATE = """
{re2_input_query}
Read the question again: {re2_input_query}
""";
private final String re2AdviseTemplate;
private int order = 0;
public ReReadingAdvisor() {
this(DEFAULT_RE2_ADVISE_TEMPLATE);
}
public ReReadingAdvisor(String re2AdviseTemplate) {
this.re2AdviseTemplate = re2AdviseTemplate;
}
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) { (1)
String augmentedUserText = PromptTemplate.builder()
.template(this.re2AdviseTemplate)
.variables(Map.of("re2_input_query", chatClientRequest.prompt().getUserMessage().getText()))
.build()
.render();
return chatClientRequest.mutate()
.prompt(chatClientRequest.prompt().augmentUserMessage(augmentedUserText))
.build();
}
@Override
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
return chatClientResponse;
}
@Override
public int getOrder() { (2)
return this.order;
}
public ReReadingAdvisor withOrder(int order) {
this.order = order;
return this;
}
}| 1 | The before method augments the user’s input query applying the Re-Reading technique. |
| 2 | You can control the order of execution by setting the order value. Lower values execute first. |
Spring AI Built-in Advisors
Spring AI framework provides several built-in advisors to enhance your AI interactions. Here’s an overview of the available advisors:
Chat Memory Advisors
These advisors manage conversation history in a chat memory store:
-
MessageChatMemoryAdvisorRetrieves memory and adds it as a collection of messages to the prompt. This approach maintains the structure of the conversation history. Note, not all AI Models support this approach.
-
PromptChatMemoryAdvisorRetrieves memory and incorporates it into the prompt’s system text.
-
VectorStoreChatMemoryAdvisorRetrieves memory from a VectorStore and adds it into the prompt’s system text. This advisor is useful for efficiently searching and retrieving relevant information from large datasets.
Question Answering Advisor
-
QuestionAnswerAdvisorThis advisor uses a vector store to provide question-answering capabilities, implementing the Naive RAG (Retrieval-Augmented Generation) pattern.
-
RetrievalAugmentationAdvisorAdvisor that implements common Retrieval Augmented Generation (RAG) flows using the building blocks defined in the `org.springframework.ai.rag` package and following the Modular RAG Architecture.
Reasoning Advisor
-
ReReadingAdvisorImplements a re-reading strategy for LLM reasoning, dubbed RE2, to enhance understanding in the input phase. Based on the article: [Re-Reading Improves Reasoning in LLMs](arxiv.org/pdf/2309.06275).
Streaming vs Non-Streaming
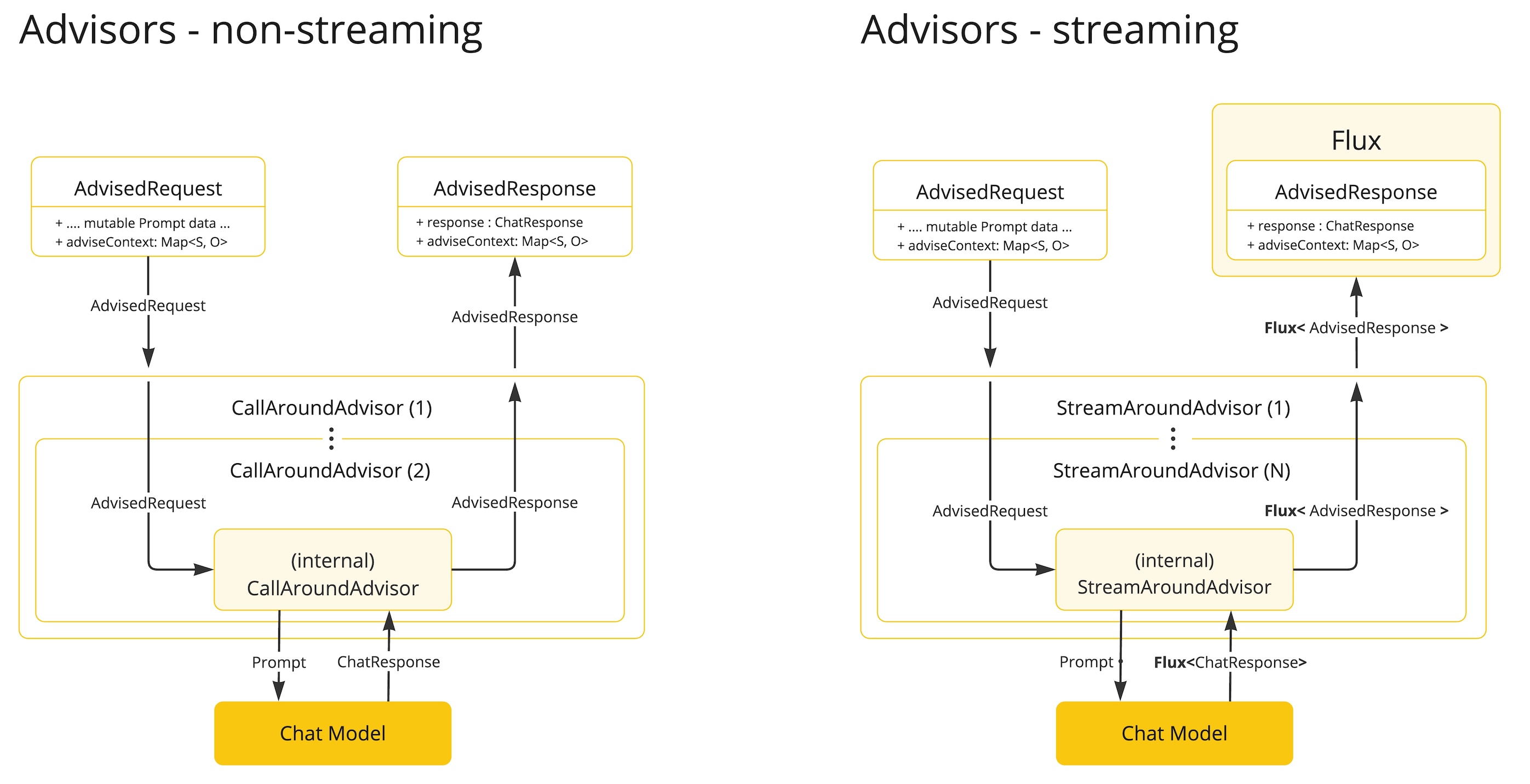
-
Non-streaming advisors work with complete requests and responses.
-
Streaming advisors handle requests and responses as continuous streams, using reactive programming concepts (e.g., Flux for responses).
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest, StreamAdvisorChain chain) {
return Mono.just(chatClientRequest)
.publishOn(Schedulers.boundedElastic())
.map(request -> {
// This can be executed by blocking and non-blocking Threads.
// Advisor before next section
})
.flatMapMany(request -> chain.nextStream(request))
.map(response -> {
// Advisor after next section
});
}Best Practices
-
Keep advisors focused on specific tasks for better modularity.
-
Use the
adviseContextto share state between advisors when necessary. -
Implement both streaming and non-streaming versions of your advisor for maximum flexibility.
-
Carefully consider the order of advisors in your chain to ensure proper data flow.
Breaking API Changes
Advisor Interfaces
-
In 1.0 M2, there were separate
RequestAdvisorandResponseAdvisorinterfaces.-
RequestAdvisorwas invoked before theChatModel.callandChatModel.streammethods. -
ResponseAdvisorwas called after these methods.
-
-
In 1.0 M3, these interfaces have been replaced with:
-
CallAroundAdvisor -
StreamAroundAdvisor
-
-
The
StreamResponseMode, previously part ofResponseAdvisor, has been removed. -
In 1.0.0 these interfaces have been replaced:
-
CallAroundAdvisor→CallAdvisor,StreamAroundAdvisor→StreamAdvisor,CallAroundAdvisorChain→CallAdvisorChainandStreamAroundAdvisorChain→StreamAdvisorChain. -
AdvisedRequest→ChatClientRequestareAdivsedResponse→ChatClientResponse.
-
Context Map Handling
-
In 1.0 M2:
-
The context map was a separate method argument.
-
The map was mutable and passed along the chain.
-
-
In 1.0 M3:
-
The context map is now part of the
AdvisedRequestandAdvisedResponserecords. -
The map is immutable.
-
To update the context, use the
updateContextmethod, which creates a new unmodifiable map with the updated contents.
-

