VertexAI PaLM2 Chat
WARNING:
As of February 15, 2024, the PaLM2 API for use with Google AI services and tooling is deprecated. In 6 months, the PaLM API will be decommissioned, meaning that users won’t be able to use a PaLM model in a prompt, tune a new PaLM model, or run inference on PaLM-tuned models.
The Generative Language PaLM API allows developers to build generative AI applications using the PaLM model. Large Language Models (LLMs) are a powerful, versatile type of machine learning model that enables computers to comprehend and generate natural language through a series of prompts. The PaLM API is based on Google’s next generation LLM, PaLM. It excels at a variety of different tasks like code generation, reasoning, and writing. You can use the PaLM API to build generative AI applications for use cases like content generation, dialogue agents, summarization and classification systems, and more.
Based on the Models REST API.
Prerequisites
To access the PaLM2 REST API you need to obtain an access API KEY form makersuite.
| Currently the PaLM API it is not available outside US, but you can use VPN for testing. |
The Spring AI project defines a configuration property named spring.ai.vertex.ai.api-key that you should set to the value of the API Key obtained.
Exporting an environment variable is one way to set that configuration property:
export SPRING_AI_VERTEX_AI_API_KEY=<INSERT KEY HERE>Add Repositories and BOM
Spring AI artifacts are published in Spring Milestone and Snapshot repositories. Refer to the Repositories section to add these repositories to your build system.
To help with dependency management, Spring AI provides a BOM (bill of materials) to ensure that a consistent version of Spring AI is used throughout the entire project. Refer to the Dependency Management section to add the Spring AI BOM to your build system.
Auto-configuration
Spring AI provides Spring Boot auto-configuration for the VertexAI Chat Client.
To enable it add the following dependency to your project’s Maven pom.xml file:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-vertex-ai-palm2-spring-boot-starter</artifactId>
</dependency>or to your Gradle build.gradle build file.
dependencies {
implementation 'org.springframework.ai:spring-ai-vertex-ai-palm2-spring-boot-starter'
}| Refer to the Dependency Management section to add the Spring AI BOM to your build file. |
Chat Properties
The prefix spring.ai.vertex.ai is used as the property prefix that lets you connect to VertexAI.
| Property | Description | Default |
|---|---|---|
spring.ai.vertex.ai.ai.base-url |
The URL to connect to |
|
spring.ai.vertex.ai.api-key |
The API Key |
- |
The prefix spring.ai.vertex.ai.chat is the property prefix that lets you configure the chat model implementation for VertexAI Chat.
| Property | Description | Default |
|---|---|---|
spring.ai.vertex.ai.chat.enabled |
Enable Vertex AI PaLM API chat model. |
true |
spring.ai.vertex.ai.chat.model |
This is the Vertex Chat model to use |
chat-bison-001 |
spring.ai.vertex.ai.chat.options.temperature |
Controls the randomness of the output. Values can range over [0.0,1.0], inclusive. A value closer to 1.0 will produce responses that are more varied, while a value closer to 0.0 will typically result in less surprising responses from the generative. This value specifies default to be used by the backend while making the call to the generative. |
0.7 |
spring.ai.vertex.ai.chat.options.topK |
The maximum number of tokens to consider when sampling. The generative uses combined Top-k and nucleus sampling. Top-k sampling considers the set of topK most probable tokens. |
20 |
spring.ai.vertex.ai.chat.options.topP |
The maximum cumulative probability of tokens to consider when sampling. The generative uses combined Top-k and nucleus sampling. Nucleus sampling considers the smallest set of tokens whose probability sum is at least topP. |
- |
spring.ai.vertex.ai.chat.options.candidateCount |
The number of generated response messages to return. This value must be between [1, 8], inclusive. Defaults to 1. |
1 |
All properties prefixed with spring.ai.vertex.ai.chat.options can be overridden at runtime by adding a request specific Runtime Options to the Prompt call.
|
Runtime Options
The VertexAiPaLm2ChatOptions.java provides model configurations, such as the temperature, the topK, etc.
On start-up, the default options can be configured with the VertexAiPaLm2ChatModel(api, options) constructor or the spring.ai.vertex.ai.chat.options.* properties.
At run-time you can override the default options by adding new, request specific, options to the Prompt call.
For example to override the default temperature for a specific request:
ChatResponse response = chatModel.call(
new Prompt(
"Generate the names of 5 famous pirates.",
VertexAiPaLm2ChatOptions.builder()
.withTemperature(0.4)
.build()
));
In addition to the model specific VertexAiPaLm2ChatOptions you can use a portable ChatOptions instance, created with the ChatOptionsBuilder#builder().
|
Sample Controller
Create a new Spring Boot project and add the spring-ai-vertex-ai-palm2-spring-boot-starter to your pom (or gradle) dependencies.
Add a application.properties file, under the src/main/resources directory, to enable and configure the VertexAi chat model:
spring.ai.vertex.ai.api-key=YOUR_API_KEY
spring.ai.vertex.ai.chat.model=chat-bison-001
spring.ai.vertex.ai.chat.options.temperature=0.5
replace the api-key with your VertexAI credentials.
|
This will create a VertexAiPaLm2ChatModel implementation that you can inject into your class.
Here is an example of a simple @Controller class that uses the chat model for text generations.
@RestController
public class ChatController {
private final VertexAiPaLm2ChatModel chatModel;
@Autowired
public ChatController(VertexAiPaLm2ChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}Manual Configuration
The VertexAiPaLm2ChatModel implements the ChatModel and uses the Low-level VertexAiPaLm2Api Client to connect to the VertexAI service.
Add the spring-ai-vertex-ai-palm2 dependency to your project’s Maven pom.xml file:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-vertex-ai-palm2</artifactId>
</dependency>or to your Gradle build.gradle build file.
dependencies {
implementation 'org.springframework.ai:spring-ai-vertex-ai-palm'
}| Refer to the Dependency Management section to add the Spring AI BOM to your build file. |
Next, create a VertexAiPaLm2ChatModel and use it for text generations:
VertexAiPaLm2Api vertexAiApi = new VertexAiPaLm2Api(< YOUR PALM_API_KEY>);
var chatModel = new VertexAiPaLm2ChatModel(this.vertexAiApi,
VertexAiPaLm2ChatOptions.builder()
.withTemperature(0.4)
.build());
ChatResponse response = this.chatModel.call(
new Prompt("Generate the names of 5 famous pirates."));The VertexAiPaLm2ChatOptions provides the configuration information for the chat requests.
The VertexAiPaLm2ChatOptions.Builder is fluent options builder.
Low-level VertexAiPaLm2Api Client
The VertexAiPaLm2Api provides is lightweight Java client for VertexAiPaLm2Api Chat API.
Following class diagram illustrates the VertexAiPaLm2Api chat interfaces and building blocks:
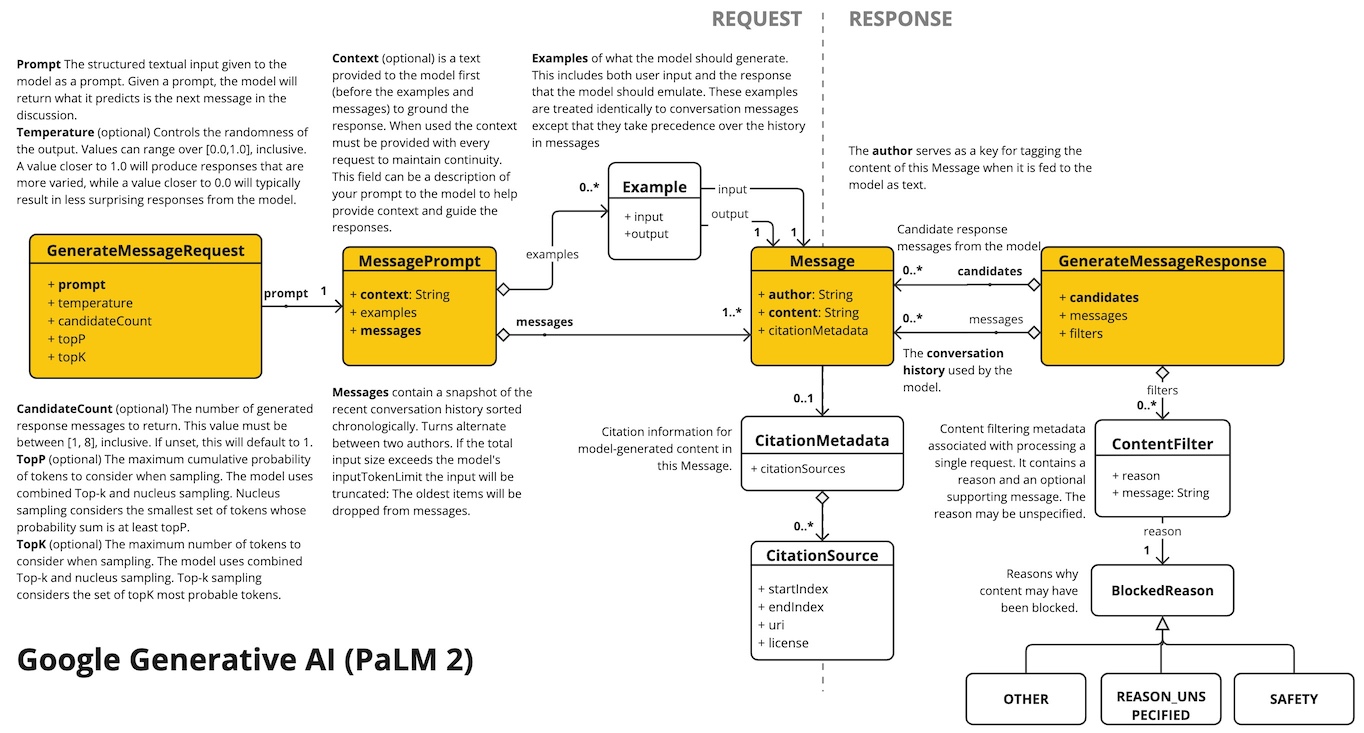
Here is a simple snippet how to use the api programmatically:
VertexAiPaLm2Api vertexAiApi = new VertexAiPaLm2Api(< YOUR PALM_API_KEY>);
// Generate
var prompt = new MessagePrompt(List.of(new Message("0", "Hello, how are you?")));
GenerateMessageRequest request = new GenerateMessageRequest(this.prompt);
GenerateMessageResponse response = this.vertexAiApi.generateMessage(this.request);
// Embed text
Embedding embedding = this.vertexAiApi.embedText("Hello, how are you?");
// Batch embedding
List<Embedding> embeddings = this.vertexAiApi.batchEmbedText(List.of("Hello, how are you?", "I am fine, thank you!"));
