|
This version is still in development and is not considered stable yet. For the latest stable version, please use Spring Framework 7.0.8! |
Overview
Why was Spring WebFlux created?
Part of the answer is the need for a non-blocking web stack to handle concurrency with a
small number of threads and scale with fewer hardware resources. Servlet non-blocking I/O
leads away from the rest of the Servlet API, where contracts are synchronous
(Filter, Servlet) or blocking (getParameter, getPart). This was the motivation
for a new common API to serve as a foundation across any non-blocking runtime. That is
important because of servers (such as Netty) that are well-established in the async,
non-blocking space.
The other part of the answer is functional programming. Much as the addition of annotations
in Java 5 created opportunities (such as annotated REST controllers or unit tests), the
addition of lambda expressions in Java 8 created opportunities for functional APIs in Java.
This is a boon for non-blocking applications and continuation-style APIs (as popularized
by CompletableFuture and ReactiveX) that allow declarative
composition of asynchronous logic. At the programming-model level, Java 8 enabled Spring
WebFlux to offer functional web endpoints alongside annotated controllers.
Define “Reactive”
We touched on “non-blocking” and “functional” but what does reactive mean?
The term, “reactive,” refers to programming models that are built around reacting to change — network components reacting to I/O events, UI controllers reacting to mouse events, and others. In that sense, non-blocking is reactive, because, instead of being blocked, we are now in the mode of reacting to notifications as operations complete or data becomes available.
There is also another important mechanism that we on the Spring team associate with “reactive” and that is non-blocking back pressure. In synchronous, imperative code, blocking calls serve as a natural form of back pressure that forces the caller to wait. In non-blocking code, it becomes important to control the rate of events so that a fast producer does not overwhelm its destination.
Reactive Streams is a small spec (also adopted in Java 9) that defines the interaction between asynchronous components with back pressure. For example a data repository (acting as Publisher) can produce data that an HTTP server (acting as Subscriber) can then write to the response. The main purpose of Reactive Streams is to let the subscriber control how quickly or how slowly the publisher produces data.
|
Common question: what if a publisher cannot slow down? The purpose of Reactive Streams is only to establish the mechanism and a boundary. If a publisher cannot slow down, it has to decide whether to buffer, drop, or fail. |
Reactive API
Reactive Streams plays an important role for interoperability. It is of interest to libraries
and infrastructure components but less useful as an application API, because it is too
low-level. Applications need a higher-level and richer, functional API to
compose async logic — similar to the Java Stream API but not only for collections.
This is the role that reactive libraries play.
Reactor is the reactive library of choice for
Spring WebFlux. It provides the
Mono and
Flux API types
to work on data sequences of 0..1 (Mono) and 0..N (Flux) through a rich set of operators aligned with the
ReactiveX vocabulary of operators.
Reactor is a Reactive Streams library and, therefore, all of its operators support non-blocking back pressure.
Reactor has a strong focus on server-side Java. It is developed in close collaboration
with Spring.
WebFlux requires Reactor as a core dependency but it is interoperable with other reactive
libraries via Reactive Streams. As a general rule, a WebFlux API accepts a plain Publisher
as input, adapts it to a Reactor type internally, uses that, and returns either a
Flux or a Mono as output. So, you can pass any Publisher as input and you can apply
operations on the output, but you need to adapt the output for use with another reactive library.
Whenever feasible (for example, annotated controllers), WebFlux adapts transparently to the use
of RxJava or another reactive library. See Reactive Libraries for more details.
| In addition to Reactive APIs, WebFlux can also be used with Coroutines APIs in Kotlin which provides a more imperative style of programming. The following Kotlin code samples will be provided with Coroutines APIs. |
Programming Models
The spring-web module contains the reactive foundation that underlies Spring WebFlux,
including HTTP abstractions, Reactive Streams adapters
for supported servers, codecs, and a core
WebHandler API comparable to
the Servlet API but with non-blocking contracts.
On that foundation, Spring WebFlux provides a choice of two programming models:
-
Annotated Controllers: Consistent with Spring MVC and based on the same annotations from the
spring-webmodule. Both Spring MVC and WebFlux controllers support reactive (Reactor and RxJava) return types, and, as a result, it is not easy to tell them apart. One notable difference is that WebFlux also supports reactive@RequestBodyarguments. -
Functional Endpoints: Lambda-based, lightweight, and functional programming model. You can think of this as a small library or a set of utilities that an application can use to route and handle requests. The big difference with annotated controllers is that the application is in charge of request handling from start to finish versus declaring intent through annotations and being called back.
Applicability
Spring MVC or WebFlux?
A natural question to ask but one that sets up an unsound dichotomy. Actually, both work together to expand the range of available options. The two are designed for continuity and consistency with each other, they are available side by side, and feedback from each side benefits both sides. The following diagram shows how the two relate, what they have in common, and what each supports uniquely:
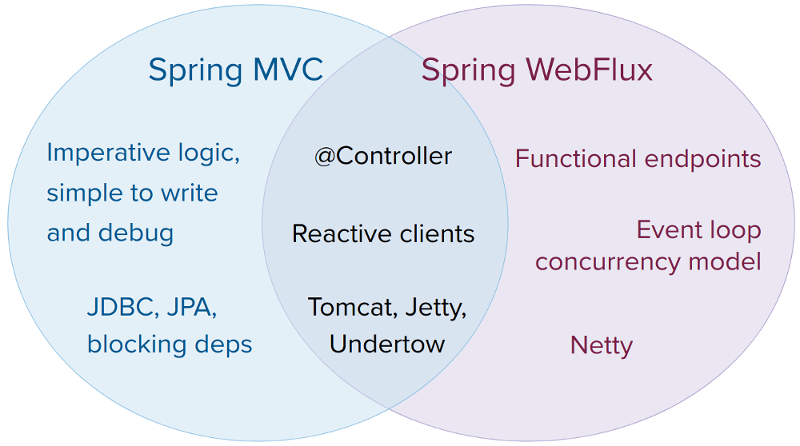
We suggest that you consider the following specific points:
-
If you have a Spring MVC application that works fine, there is no need to change. Imperative programming is the easiest way to write, understand, and debug code. You have maximum choice of libraries, since, historically, most are blocking.
-
If you are already shopping for a non-blocking web stack, Spring WebFlux offers the same execution model benefits as others in this space and also provides a choice of servers (Netty, Tomcat, Jetty, and Servlet containers), a choice of programming models (annotated controllers and functional web endpoints), and a choice of reactive libraries (Reactor, RxJava, or other).
-
If you are interested in a lightweight, functional web framework for use with Java or Kotlin, you can use the Spring WebFlux functional web endpoints. That can also be a good choice for smaller applications or microservices with less complex requirements that can benefit from greater transparency and control.
-
In a microservice architecture, you can have a mix of applications with either Spring MVC or Spring WebFlux controllers or with Spring WebFlux functional endpoints. Having support for the same annotation-based programming model in both frameworks makes it easier to re-use knowledge while also selecting the right tool for the right job.
-
A simple way to evaluate an application is to check its dependencies. If you have blocking persistence APIs (JPA, JDBC) or networking APIs to use, Spring MVC is the best choice for common architectures at least. It is technically feasible with both Reactor and RxJava to perform blocking calls on a separate thread but you would not be making the most of a non-blocking web stack.
-
If you have a Spring MVC application with calls to remote services, try the reactive
WebClient. You can return reactive types (Reactor, RxJava, or other) directly from Spring MVC controller methods. The greater the latency per call or the interdependency among calls, the more dramatic the benefits. Spring MVC controllers can call other reactive components too. -
If you have a large team, keep in mind the steep learning curve in the shift to non-blocking, functional, and declarative programming. A practical way to start without a full switch is to use the reactive
WebClient. Beyond that, start small and measure the benefits. We expect that, for a wide range of applications, the shift is unnecessary. If you are unsure what benefits to look for, start by learning about how non-blocking I/O works (for example, concurrency on single-threaded Node.js) and its effects.
Servers
Spring WebFlux is supported on Tomcat, Jetty, Servlet containers, as well as on non-Servlet runtimes such as Netty. All servers are adapted to a low-level, common API so that higher-level programming models can be supported across servers.
Spring WebFlux does not have built-in support to start or stop a server. However, it is easy to assemble an application from Spring configuration and WebFlux infrastructure and run it with a few lines of code.
Spring Boot has a WebFlux starter that automates these steps. By default, the starter uses Netty, but it is easy to switch to Tomcat, or Jetty by changing your Maven or Gradle dependencies. Spring Boot defaults to Netty, because it is more widely used in the asynchronous, non-blocking space and lets a client and a server share resources.
Tomcat and Jetty can be used with both Spring MVC and WebFlux. Keep in mind, however, that the way they are used is very different. Spring MVC relies on Servlet blocking I/O and lets applications use the Servlet API directly if they need to. Spring WebFlux relies on Servlet non-blocking I/O and uses the Servlet API behind a low-level adapter. It is not exposed for direct use.
| It is strongly advised not to map Servlet filters or directly manipulate the Servlet API in the context of a WebFlux application. For the reasons listed above, mixing blocking I/O and non-blocking I/O in the same context will cause runtime issues. |
Performance
Performance has many characteristics and meanings. Reactive and non-blocking generally
do not make applications run faster. They can in some cases – for example, if using the
WebClient to run remote calls in parallel. However, it requires more work to do
things the non-blocking way, and that can slightly increase the required processing time.
The key expected benefit of reactive and non-blocking is the ability to scale with a small, fixed number of threads and less memory. That makes applications more resilient under load, because they scale in a more predictable way. In order to observe those benefits, however, you need to have some latency (including a mix of slow and unpredictable network I/O). That is where the reactive stack begins to show its strengths, and the differences can be dramatic.
Concurrency Model
Both Spring MVC and Spring WebFlux support annotated controllers, but there is a key difference in the concurrency model and the default assumptions for blocking and threads.
In Spring MVC (and servlet applications in general), it is assumed that applications can block the current thread, (for example, for remote calls). For this reason, servlet containers use a large thread pool to absorb potential blocking during request handling.
In Spring WebFlux (and non-blocking servers in general), it is assumed that applications do not block. Therefore, non-blocking servers use a small, fixed-size thread pool (event loop workers) to handle requests.
| “To scale” and “small number of threads” may sound contradictory, but to never block the current thread (and rely on callbacks instead) means that you do not need extra threads, as there are no blocking calls to absorb. |
Invoking a Blocking API
What if you do need to use a blocking library? Both Reactor and RxJava provide the
publishOn operator to continue processing on a different thread. That means there is an
easy escape hatch. Keep in mind, however, that blocking APIs are not a good fit for
this concurrency model.
Mutable State
In Reactor and RxJava, you declare logic through operators. At runtime, a reactive pipeline is formed where data is processed sequentially, in distinct stages. A key benefit of this is that it frees applications from having to protect mutable state because application code within that pipeline is never invoked concurrently.
Threading Model
What threads should you expect to see on a server running with Spring WebFlux?
-
On a “vanilla” Spring WebFlux server (for example, no data access or other optional dependencies), you can expect one thread for the server and several others for request processing (typically as many as the number of CPU cores). Servlet containers, however, may start with more threads (for example, 10 on Tomcat), in support of both servlet (blocking) I/O and servlet 3.1 (non-blocking) I/O usage.
-
The reactive
WebClientoperates in event loop style. So you can see a small, fixed number of processing threads related to that (for example,reactor-http-nio-with the Reactor Netty connector). However, if Reactor Netty is used for both client and server, the two share event loop resources by default. -
Reactor and RxJava provide thread pool abstractions, called schedulers, to use with the
publishOnoperator that is used to switch processing to a different thread pool. The schedulers have names that suggest a specific concurrency strategy — for example, “parallel” (for CPU-bound work with a limited number of threads) or “elastic” (for I/O-bound work with a large number of threads). If you see such threads, it means some code is using a specific thread poolSchedulerstrategy. -
Data access libraries and other third party dependencies can also create and use threads of their own.
Configuring
The Spring Framework does not provide support for starting and stopping
servers. To configure the threading model for a server,
you need to use server-specific configuration APIs, or, if you use Spring Boot,
check the Spring Boot configuration options for each server. You can
configure the WebClient directly.
For all other libraries, see their respective documentation.

